
SIMD とは何か - C++ で音声バッファのゲイン処理を高速化してみる
はじめに
本記事では、C++ で 音声処理などを書くときによく耳にする SIMD(Single Instruction Multiple Data)について、ざっくり仕組みをおさらいしつつ、実際にどれくらい処理速度が変わるかを簡単なベンチマークで確認します。「バッファ全体にゲインを掛ける」というシンプルな処理を題材に、コンパイルオプションの違いによる挙動の変化も合わせて観察します。
対象読者
- 音声処理アプリケーションを C++ で書いている方
- SIMD という言葉は知っているが、実際にどれくらい速くなるのか感覚を掴みたい方
参考
- /O オプション(コードの最適化) - Visual Studio / MSVC C++
- /arch(x64) - 拡張命令セットを有効にする
- Intel® Intrinsics Guide
- SIMD 入門(C 言語 SIMD 入門:目次)
- Intro to practical SIMD for graphics
SIMD とは何か
なぜ音声処理と相性が良いのか
リアルタイム音声処理などでは、バッファ内の全サンプルに対して同じ計算を繰り返す処理が非常に多く登場します。代表的な例としては、次のようなものがあります。
- オーディオバッファに一定のゲインを掛ける
- 複数トラックを加算してミックスする
- エンベロープやフィルタ係数を全サンプルに乗算する
素直に C++ で書くと、典型的には次のような for ループになります。
// スカラー版のゲイン処理
void applyGainScalar(float* buffer, size_t n, float gain) {
for (size_t i = 0; i < n; ++i) {
buffer[i] *= gain;
}
}
この場合、CPU は概念的には 1 回のループで 1 サンプルを処理しています。メモリから値を 1 つ読み込み、乗算し、結果を 1 つ書き戻す、という流れをサンプル数だけ淡々と繰り返すイメージです。
SIMD(Single Instruction Multiple Data)は、この「1 命令で 1 データ」という前提を崩し、1 命令で複数データをまとめて処理するための仕組み です。CPU の中には 128bit や 256bit の幅を持つベクトルレジスタがあり、32bit float であれば 4 個や 8 個の値を 1 本のレジスタに詰めて、まとめて加算・乗算できます。例えば AVX2 の 256bit レジスタの場合、32bit float を 8 個扱えるので、8 サンプルぶんの掛け算を 1 命令で同時に実行できます。
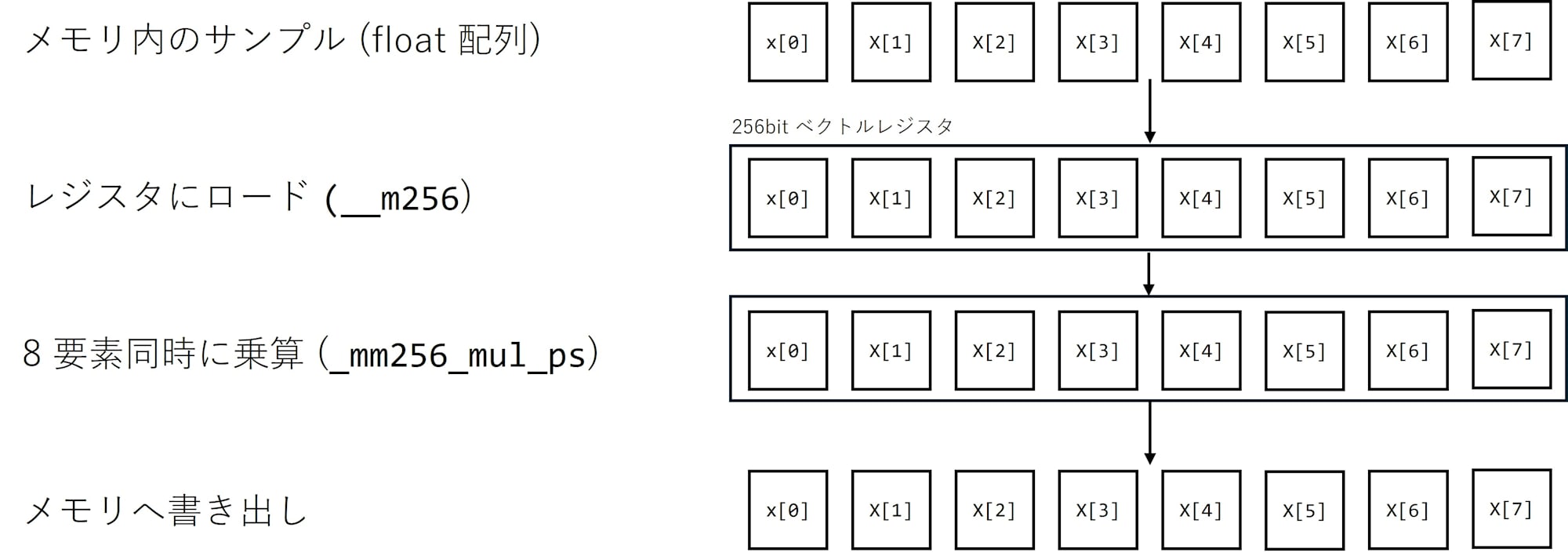
SIMD をどうやって使うか
C++ から SIMD を使う方法は、大きく分けて次の 2 つです。
-
コンパイラの最適化に任せる方法
素直な for ループを書き、/O2や/Otなどの最適化オプションを有効にすると、条件が揃っているループはコンパイラが自動的にベクトル化してくれます。最近のコンパイラはかなり賢く、何も意識していなくても裏側で SSE / AVX 命令に置き換えられていることがよくあります。 -
イントリンシック関数で明示的にベクトル命令を叩く方法
#include <immintrin.h>などをインクルードし、_mm256_set1_ps,_mm256_mul_ps,_mm256_loadu_psといった関数を使って、8 要素をまとめて読み込み・掛け算・書き戻しといった処理を自分で記述します。
今回の記事では後者の例として、AVX2 を使ったゲイン処理を次のように書いてみます。
#include <immintrin.h>
// AVX2 を使って 8 サンプルずつゲインを掛ける例
void applyGainAvx(float* buffer, size_t n, float gain) {
__m256 g = _mm256_set1_ps(gain); // gain を 8 要素ベクトルに展開
size_t i = 0;
size_t simdN = n & ~size_t(7); // 8 の倍数に切り下げ
for (; i < simdN; i += 8) {
__m256 x = _mm256_loadu_ps(&buffer[i]); // 8 サンプル読み込み
__m256 y = _mm256_mul_ps(x, g); // 8 サンプル同時に乗算
_mm256_storeu_ps(&buffer[i], y); // 書き戻し
}
// 端数分はスカラーで処理
for (; i < n; ++i) {
buffer[i] *= gain;
}
}
コードはやや読みにくくなりますが、「このループは必ず AVX2 を使う」と明示できるのが利点です。音声処理のような連続した配列に対して、全サンプル同じ計算をするループは SIMD と非常に相性が良いといえます。
実際に計測してみた
ベンチマークの条件
ここからは、先ほどの applyGainScalar と applyGainAvx を使って、実際にどれくらい処理時間が変わるかを簡単に計測してみます。
ベンチマークの条件は次のとおりです。
- コンパイラ・IDE: Visual Studio 2022 / MSVC
- ビルド構成: Release / x64
- 実行方法: 「デバッグなしで開始」(Ctrl + F5)
- サンプル数: 1,048,576 サンプル(
1 << 20) - ループ回数: 各実装を 200 回繰り返し
- ゲイン値:
0.5f
ベンチマーク用コード
#include <immintrin.h>
#include <chrono>
#include <functional>
#include <iostream>
#include <vector>
#include <random>
#include <algorithm>
// スカラー版
void applyGainScalar(float* buffer, size_t n, float gain) {
for (size_t i = 0; i < n; ++i) {
buffer[i] *= gain;
}
}
// SIMD 版(AVX2)
void applyGainAvx(float* buffer, size_t n, float gain) {
__m256 g = _mm256_set1_ps(gain);
size_t i = 0;
size_t simdN = n & ~size_t(7); // 8 の倍数に切り下げ
for (; i < simdN; i += 8) {
__m256 x = _mm256_loadu_ps(&buffer[i]);
__m256 y = _mm256_mul_ps(x, g);
_mm256_storeu_ps(&buffer[i], y);
}
for (; i < n; ++i) {
buffer[i] *= gain;
}
}
// ベンチマークヘルパ
double bench(const std::function<void()>& f, int iterations) {
using clock = std::chrono::high_resolution_clock;
// ウォームアップ
for (int i = 0; i < 5; ++i) {
f();
}
auto start = clock::now();
for (int i = 0; i < iterations; ++i) {
f();
}
auto end = clock::now();
std::chrono::duration<double> diff = end - start;
return diff.count();
}
int main() {
const size_t N = 1 << 20; // 1M samples
const int iterations = 200;
const float gain = 0.5f;
std::vector<float> buffer(N);
// 適当に乱数を入れておく
std::mt19937 rng(12345);
std::uniform_real_distribution<float> dist(-1.0f, 1.0f);
for (auto& v : buffer) {
v = dist(rng);
}
// スカラー版のベンチマーク(毎回 buffer をリセット)
std::vector<float> bufScalar = buffer;
double tScalar = bench([&] {
std::copy(buffer.begin(), buffer.end(), bufScalar.begin());
applyGainScalar(bufScalar.data(), bufScalar.size(), gain);
}, iterations);
// SIMD 版のベンチマーク
std::vector<float> bufSimd = buffer;
double tSimd = bench([&] {
std::copy(buffer.begin(), buffer.end(), bufSimd.begin());
applyGainAvx(bufSimd.data(), bufSimd.size(), gain);
}, iterations);
std::cout << "Scalar: " << tScalar << " sec" << std::endl;
std::cout << "SIMD : " << tSimd << " sec" << std::endl;
std::cout << "Speedup: " << (tScalar / tSimd) << "x" << std::endl;
}
ここでは毎回 buffer から bufScalar / bufSimd にコピーしてから処理を走らせています。これは、スカラー版と SIMD 版でまったく同じ入力データを処理するため、および、処理の順番によってキャッシュの状態が偏るのをある程度避けるためです。厳密なベンチマークではありませんが、傾向を見るにはこの程度で十分です。
コンパイルオプションとしては、次の 2 パターンを比較しました。
- コード最適化オプションなし:
/Odすべてのオプション
/permissive- /ifcOutput "TestSimd\x64\Release\" /GS /GL /W3 /Gy /Zc:wchar_t /Zi /Gm- /Od /Ob2 /sdl /Fd"TestSimd\x64\Release\vc143.pdb" /Zc:inline /fp:precise /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /errorReport:prompt /WX- /Zc:forScope /arch:AVX2 /Gd /Oi /MD /FC /Fa"TestSimd\x64\Release\" /EHsc /nologo /Fo"TestSimd\x64\Release\" /Ot /Fp"TestSimd\x64\Release\TestSimd.pch" /diagnostics:column - 最大速度優先:
/O2すべてのオプション
/permissive- /ifcOutput "TestSimd\x64\Release\" /GS /GL /W3 /Gy /Zc:wchar_t /Zi /Gm- /O2 /Ob2 /sdl /Fd"TestSimd\x64\Release\vc143.pdb" /Zc:inline /fp:precise /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /errorReport:prompt /WX- /Zc:forScope /arch:AVX2 /Gd /Oi /MD /FC /Fa"TestSimd\x64\Release\" /EHsc /nologo /Fo"TestSimd\x64\Release\" /Ot /Fp"TestSimd\x64\Release\TestSimd.pch" /diagnostics:column
どちらも「構成: Release / x64」は固定し、最適化レベルだけを切り替えて 計測しています。
計測結果とその解釈
| 最適化オプション | Scalar 所要時間 [s] | SIMD 所要時間 [s] | Speedup |
|---|---|---|---|
/Od |
0.295703 | 0.109595 | 2.70x |
/O2 |
0.077822 | 0.067121 | 1.16x |
コード最適化オプションを無効にした /Od の場合、スカラー実装は本当に「1 サンプルずつ順番に処理する」ループになり、SIMD 実装だけが AVX2 で 8 サンプルずつ処理を行います。その結果、約 2.7 倍という、期待どおりの速度差が確認できました。
一方、/O2 で最適化を有効にすると、スカラー実装のループもコンパイラによる自動ベクトル化の対象になります。/arch:AVX2 を指定しているため、コンパイラは AVX2 命令を自由に使える状態であり、単純なループであれば自動的に vmulps などのベクトル命令に置き換えてくれます。その結果、スカラー実装と手書き SIMD 実装の中身の機械語がかなり似たものになり、両者の差は約 1.16 倍とかなり小さくなりました。ベンチマークの中で行っている std::copy(メモリコピー)のコストも両者共通で効いているため、ゲイン演算そのものだけを切り出して見た場合の差が、全体の処理時間の中では相対的に小さくなっていると考えられます。
この 2 パターンの検証から、次のようなことが分かります。
- SIMD 自体は、最適化なしの状態でも 2〜3 倍程度の効果が期待できる
- Release ビルドではコンパイラがかなり積極的にベクトル化してくれるため、手書き SIMD の追加効果はそこまで劇的ではなくなることがある
- 実際のプロジェクトでは、「まずは素直な C++ コードを書き、最適化と auto-vectorization に任せ、それでも重いホットスポットだけ手書き SIMD を検討する」というアプローチが現実的である
おわりに
本記事では、SIMD のざっくりした概要と、ゲイン処理を題材にした簡単なベンチマークを通じて、実際にどれくらい速度が変わるのかを確認しました。最適化なしの状態では 2〜3 倍の差が見える一方で、Release ビルドではコンパイラが自動的にベクトル化してくれるため、手書き SIMD の追加効果は 1 割程度に留まる場合もあるということが分かりました。
実務では、まずは素直なループを書いてプロファイルし、本当にボトルネックになっている箇所だけを SIMD で丁寧にチューニングする、くらいの距離感で付き合うのがちょうど良さそうです。







