SAM2を使用したYOLOデータセット自動生成:手動アノテーション作業を95%削減する
1. はじめに
製造ビジネステクノロジー部の平内(SIN)です。
機械学習プロジェクトで最も時間とコストがかかるのは、アノテーション作業です。特にセグメンテーションモデル用のデータセット作成は、膨大な作業量だと思います。
従来、1つの画像に対して10-30分のアノテーション時間が必要で、10,000枚規模のデータセットを作成するには、数千時間の作業が発生していました。さらに、アノテーター間の一貫性確保やヒューマンエラーによる品質低下も深刻な課題でした。
本記事では、Meta社の「SAM2(Segment Anything Model 2)」を使用し、この課題を解決するプログラムを紹介させていただきます。これにより、手動アノテーション作業を大幅に削減し、従来よりも効率的に高品質なYOLOv8用データセットを自動生成できるようになりました。
SAMを利用したデータセット作成は、既に、いくつかのブログでも紹介されていますが、本記事では、一連の作業を可能な限り自動化しました。
※ すべてのコードは、下記に置きました。
https://github.com/furuya02/create-dataset-with-sam2
2. システム概要と技術スタック
2.1 全体アーキテクチャ
本システムは5つの段階的なフェーズで構成されています:
Phase 1: 動画入力 → SAM2による自動セグメンテーション → アノテーションデータ
Phase 2: アノテーションデータ → 背景合成による拡張 → 合成データセット
Phase 3: 合成データセット → YOLO形式変換 → YOLOデータセット
Phase 4: YOLOデータセット → YOLOv8学習 → 学習済みモデル
Phase 5: 学習済みモデル → 推論テスト → 性能評価
2.2 使用技術スタック
核心技術
- SAM2: Meta社の最新セグメンテーションモデル、ビデオトラッキング機能内蔵
- YOLOv8: Ultralyticsの物体検出・セグメンテーション統合フレームワーク
- OpenCV: 画像処理とコンピュータビジョン
- FFmpeg: 高性能ビデオ処理エンジン
インフラ・環境
- PyTorch: 深層学習フレームワーク、CUDA統合
- Docker: 完全な環境隔離と再現性確保
- SuperVision: 高品質アノテーション可視化
- NumPy/Matplotlib: 数値計算と可視化
3. 環境構築とDocker環境の準備
3.1 必要な前提条件
- Docker及びNVIDIA Docker Runtime
- NVIDIA GPU(推奨:8GB以上のVRAM)
- 十分なストレージ容量(20GB以上推奨)
3.2 Dockerイメージのビルド
プロジェクトには、Jetson AGX Orin(JetPack 6.2 L4T 36.4)で動作確認したDockerfileが含まれています。
dustynv/l4t-pytorch:r36.4.0 をベースイメージとし、SAM2と必要なライブラリをセットアップしています。
dockerfile(抜粋)
FROM dustynv/l4t-pytorch:r36.4.0
・・・略・・・
# SAM2に必要なPythonパッケージ
RUN pip install numpy==1.26.4 opencv-python tqdm matplotlib hydra-core omegaconf
RUN pip install iopath pillow
# SAM2のクローンとセットアップ
RUN git clone https://github.com/facebookresearch/segment-anything-2.git
ENV SAM2_HOME=/segment-anything-2
WORKDIR ${SAM2_HOME}/
# PyTorchバージョン競合回避
RUN sed -i -e '/^[[:space:]]*"torch>=2.5.1",/d' -e '/^[[:space:]]*"torchvision>=0.20.1",/d' setup.py
# SAM2インストール
RUN pip install -e . --no-deps --force-reinstall -q
RUN python3 setup.py build_ext --inplace
3.3 環境の起動と動作確認
DockerイメージのBuildと、起動には、専用のシェルを置きました。
# Dockerイメージのビルド
$ cd home
$ chmod +x docker-build.sh
$ ./docker-build.sh
# Docker環境の起動
$ chmod +x docker-run.sh
$ ./docker-run.sh
# 動作確認
$ python3 -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"
4. 作業手順
一連の作業は、以下のとおりです。
| 手順 | 作業内容 | プログラム |
|---|---|---|
| Phase 1 | SAM2による動画からアノテーションデータ作成 | video_2_annotation.py |
| Phase 2 | アノテーションデータから合成データ作成 | annotation_2_marge.py |
| Phase 3 | 合成データからyoloデータセット作成 | merge_2_dataset.py |
| Phase 4 | ファインチューニングによるモデル作成 | セグメンテーション:train_seg.py 物体検出:train_od.py |
| Phase 5 | 推論確認 | check_inference.py |
4.1 [Phase 1] SAM2による動画からアノテーションデータ作成
SAM2は、Metaが開発した革新的なセグメンテーションモデルで、以下の特徴を持ちます:
- ゼロショット学習: 事前学習不要で任意のオブジェクトをセグメンテーション
- ビデオトラッキング: フレーム間でのオブジェクト追跡機能
- リアルタイム処理: 効率的なTransformerアーキテクチャ
本プログラムは、このトラッキング機能を利用して、アノテーションデータを生成しています。
4.1.1 実行コマンド
実行コマンドは、以下のとおりです。
コマンドラインで指定する引数は、対象の動画(必須)、フレーム解像度のスケーリング係数(デフォルト: 0.8)及び、フレーム抽出レート(デフォルト: 10fps)です。
# 基本実行
$ python3 video_2_annotation.py SAMPLE.mp4
# パラメータ指定
$ python3 video_2_annotation.py SAMPLE.mp4 --scale 0.5 --fps 5
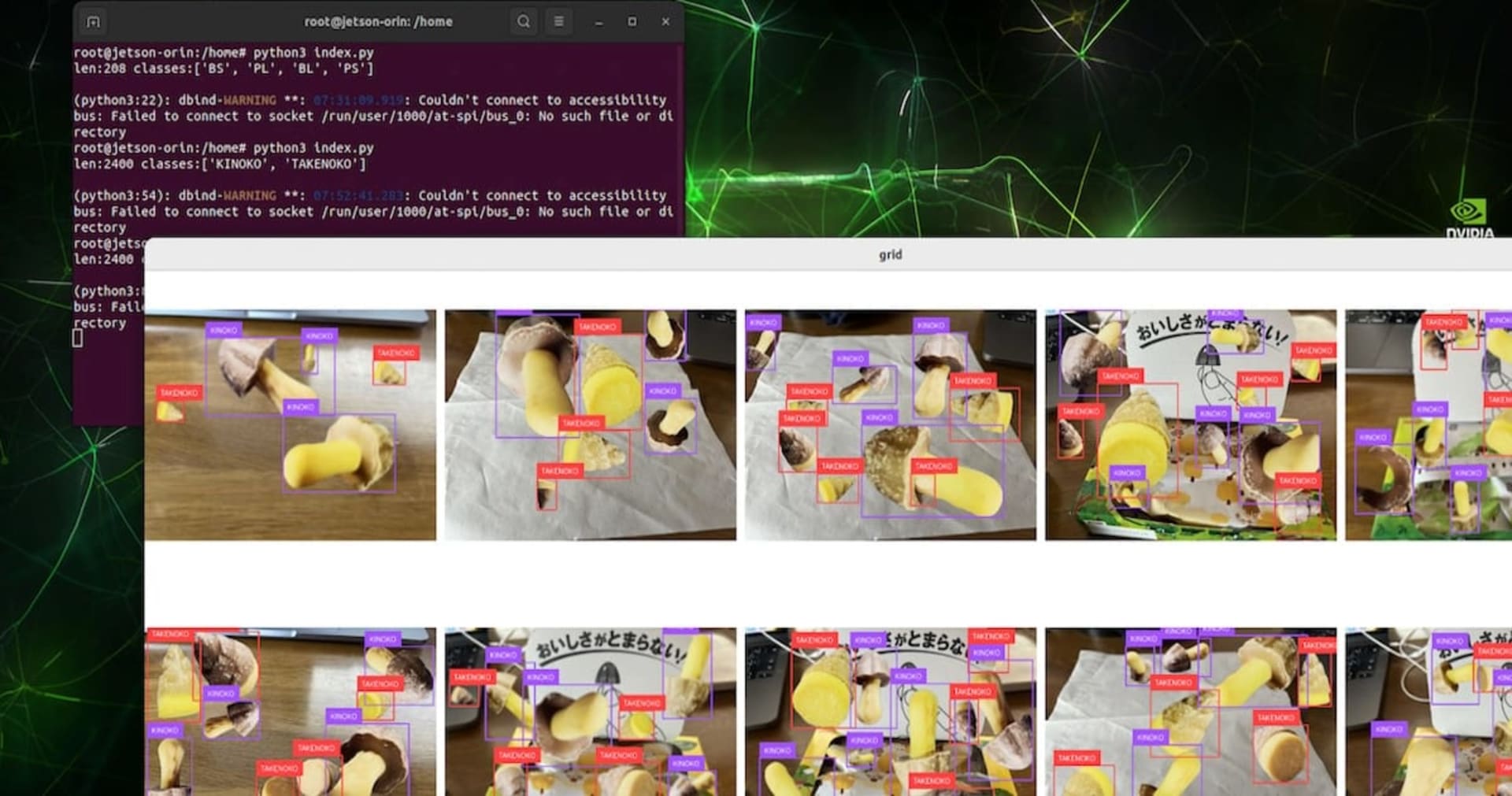
次の動画は、対象オブジェクトとして、アヒルを机の上で撮影した動画です。このような動画が、データセットの元動画となります。
video_2_annotation.pyを実行している様子です。
4.1.2 主要コンポーネント
以下、video_2_annotation.pyの主要コンポーネントの解説です。
SAM2モデルの初期化
SAM2モデルの初期化は、VideoAnnotatorクラスのsetup_sam2_modelで行われています。
class VideoAnnotator:
"""SAM2統合ビデオアノテーションエンジン"""
def setup_sam2_model(self):
"""SAM2モデルの初期化プロセス"""
try:
# メモリクリーンアップ
self._cleanup_memory("pre_model_load")
# SAM2モデルローディング
self.logger.info(f"Loading SAM2 model from {self.config.checkpoint}")
self.sam2_model = build_sam2_video_predictor(
config_path=self.config.config,
ckpt_path=self.config.checkpoint,
device=self.device
)
# 推論状態初期化
self.inference_state = self.sam2_model.init_state(
video_path=self.video_config.frame_path,
offload_video_to_cpu=True, # メモリ効率化
async_loading_frames=True # 非同期ローディング
)
self.sam2_model.reset_state(self.inference_state)
except RuntimeError as e:
if "out of memory" in str(e).lower():
self._handle_oom_error(e)
else:
raise
インタラクティブなターゲット選択
video_2_annotation.pyが起動すると、動画の最初のフレームを表示して、対象オブジェクトを指定するプロンプト状態となります。ユーザーはマウス操作で検出対象を選択します。
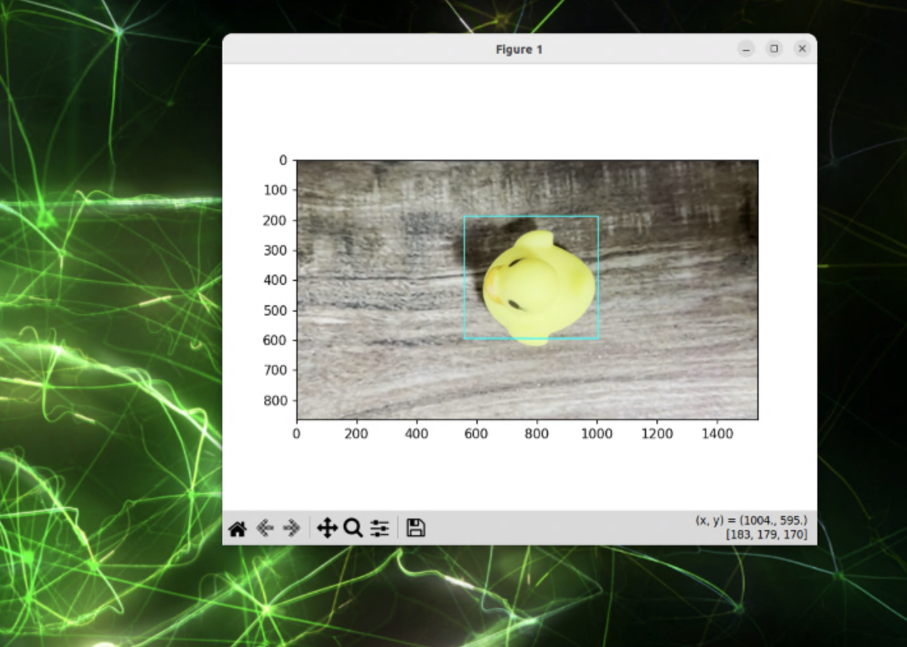
class BoundingBox:
"""インタラクティブターゲット選択インターフェース"""
def get_box(self, image_path: str) -> Tuple[int, int, int, int]:
"""マウス操作によるバウンディングボックス選択"""
self.image = cv2.imread(image_path)
# Matplotlib設定
fig, ax = plt.subplots(figsize=(12, 8))
fig.canvas.set_window_title('SAM2 Target Selection - Drag to select object')
# イベントハンドラー接続
self._connect_events(fig)
# 画像表示とヘルプテキスト
self._update_display(ax)
self._show_help_text(ax)
plt.show()
return self._validate_selection()
FFmpegによる高性能フレーム抽出
SAM2では、フレームから外に出たオブジェクトの追跡も可能ですが、その仕組は、最初に動画全体のフレームを読み込んで処理するからです。
フレームは、JPEG形式で渡す必要がありますが、ffpegを使用して、その切り出しを行っています。
def create_frames_using_ffmpeg(video_path: str, output_path: str,
frame_width: int, frame_height: int, fps: int) -> List[str]:
"""FFmpegを使用した最適化されたフレーム抽出"""
# ハードウェアアクセラレーション検出
hw_accel = _detect_hardware_acceleration()
# FFmpegコマンド構築
cmd = ['ffmpeg', '-y']
if hw_accel['decoder']:
cmd.extend(hw_accel['decoder'].split())
cmd.extend(['-i', video_path])
# 高品質スケーリングフィルター
filters = [
f'scale={frame_width}:{frame_height}:flags=lanczos',
f'fps={fps}'
]
cmd.extend(['-vf', ','.join(filters)])
cmd.extend(['-q:v', '2', '-pix_fmt', 'yuv420p', '-start_number', '0'])
cmd.append(f'{output_path}/%05d.jpeg')
# 実行とエラーハンドリング
result = subprocess.run(cmd, capture_output=True, text=True, timeout=3600)
if result.returncode != 0:
raise RuntimeError(f"FFmpeg failed: {result.stderr}")
return sorted(glob.glob(f"{output_path}/*.jpeg"))
透過PNG生成の仕組み
透過PNGは、背景を完全に除去したオブジェクトのみの画像です:
class MaskUtil:
"""マスクデータから透過画像とセグメンテーション座標を生成"""
def __create_transparent_image(self):
"""透過PNG画像の生成"""
# マスクの範囲でフレームを切り取り
copy_image = self.frame.copy()
cropped_image = copy_image[
self.box[1]:self.box[3],
self.box[0]:self.box[2]
]
# マスク部分も切り取り
cropped_mask = self.masks[
self.box[1]:self.box[3],
self.box[0]:self.box[2]
]
# BGRA形式に変換してアルファチャンネル追加
transparent_image = cv2.cvtColor(cropped_image, cv2.COLOR_BGR2BGRA)
# マスク外の領域を透明に設定
transparent_image[np.logical_not(cropped_mask), 3] = 0
self.transparent_image = transparent_image
セグメンテーション座標データ
各フレームのオブジェクト輪郭座標がテキストファイルに保存されます:
def __create_segmentation_data(self):
"""高品質なセグメンテーション座標の生成"""
height, width, _ = self.frame.shape
# マスクから白黒2値画像を生成
binary_image = np.full([height, width, 1], 0, dtype=np.uint8)
white_image = np.full([height, width, 1], 255, dtype=np.uint8)
binary_image[:] = np.where(
self.masks[:height, :width, np.newaxis] == True,
white_image,
binary_image
)
# 輪郭検出(ノイズ除去)
contours, _ = cv2.findContours(
binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
# 最大面積の輪郭を選択
max_contour = max(contours, key=lambda x: cv2.contourArea(x))
# 座標データをテキスト形式で保存
text = ""
for point in max_contour.tolist():
x, y = point[0]
text += f"{x},{y},"
self.text = text
プレビュー画像の活用
プレビュー画像は、アノテーション結果の品質確認に使用されます。
class Annotator:
"""SuperVisionを使用したアノテーション可視化"""
def set_mask(self, frame_org, masks, object_ids):
"""マスクの可視化とバウンディングボックス描画"""
frame = frame_org.copy()
# マスクの3次元化
masks = self.__ensure_3d_masks(masks)
# SuperVision Detection形式に変換
detections = sv.Detections(
xyxy=sv.mask_to_xyxy(masks=masks),
mask=masks,
class_id=np.array(object_ids)
)
# マスクアノテーション描画
frame = self.mask_annotator.annotate(scene=frame, detections=detections)
# バウンディングボックス追加
frame = self.__annotate_with_rectangle(frame, detections)
return frame
4.1.3 生成されるデータ
生成されるアノテーションデータは、以下の構造で出力されます。
なお、物体検出用のアノテーション(矩形座標)は、png(透過マスク画像)のサイズを利用するので、ここでは、特に出力されていません。
annotation/クラス名/
├── frame/ # SAM2用フレーム画像(00000.jpeg形式)
│ ├── 00000.jpeg
│ ├── 00001.jpeg
│ └── ...
├── png/ # 透過マスク画像(透過PNG)
│ ├── クラス名_00000.png
│ ├── クラス名_00001.png
│ └── ...
├── preview/ # アノテーション確認用プレビュー画像
│ ├── クラス名_00000.png
│ ├── クラス名_00001.png
│ └── ...
└── seg/ # セグメンテーション座標データ
├── クラス名_00000.txt
├── クラス名_00001.txt
└── ...
- frame SAM2用フレーム画像(00000.jpeg形式)

- png 透過マスク画像(透過PNG)

- preview アノテーション確認用プレビュー画像

- seg セグメンテーション座標データ
4.2 [Phase 2] アノテーションデータから合成データ作成
アノテーションデータと、背景画像を合成し、データセットを作成します。
4.2.1 実行コマンド
実行コマンドは、以下のとおりです。
$ python3 annotation_2_marge.py
以下の動画は、合成している様子です。
4.2.2 主要コンポーネント
以下、annotation_2_marge.pyの主要コンポーネントの解説です。
■ 背景合成アルゴリズム
透過PNGと背景画像を合成してデータセットを拡張します。
class Transformer:
"""画像変換とデータ拡張処理"""
def warp(self, target_image):
"""ランダム変換による画像拡張"""
# ランダムスケーリング(0.3〜1.0倍)
scale = random.uniform(self.__min_scale, self.__max_scale)
h, w, _ = target_image.shape
target_image = cv2.resize(target_image, (int(w * scale), int(h * scale)))
# ランダム配置
new_h, new_w, _ = target_image.shape
left = random.randint(0, self.__width - new_w)
top = random.randint(0, self.__height - new_h)
# 配置位置情報
rect = ((left, top), (left + new_w, top + new_h))
# 背景との合成
synthesized_image = self.__synthesize(target_image, left, top)
return synthesized_image, rect, scale
def __synthesize(self, target_image, left, top):
"""PIL使用による高品質合成"""
background = np.zeros((self.__height, self.__width, 4), np.uint8)
back_pil = Image.fromarray(background)
front_pil = Image.fromarray(target_image)
# アルファブレンディング
back_pil.paste(front_pil, (left, top), front_pil)
return np.array(back_pil)
■ IoU制御による重複管理
複数オブジェクトの配置時、重複を制御して自然な配置を実現しています。
class MergeData:
"""1画像分の合成データ管理"""
def append(self, target_image, rect, class_id):
"""IoU制御による配置判定"""
# 既存オブジェクトとの重複チェック
for existing_rect in self.__rects:
iou = self.__calculate_iou(existing_rect, rect)
if iou > self.__overlap_threshold: # デフォルト10%
return False # 配置失敗
# 配置成功
self.__rects.append(rect)
self.__images.append(target_image)
self.__class_ids.append(class_id)
return True
def __calculate_iou(self, rect_a, rect_b):
"""IoU(Intersection over Union)計算"""
(ax1, ay1), (ax2, ay2) = rect_a
(bx1, by1), (bx2, by2) = rect_b
# 交差領域の計算
intersection_x1 = max(ax1, bx1)
intersection_y1 = max(ay1, by1)
intersection_x2 = min(ax2, bx2)
intersection_y2 = min(ay2, by2)
intersection_area = max(0, intersection_x2 - intersection_x1) * \
max(0, intersection_y2 - intersection_y1)
# 各矩形の面積
area_a = (ax2 - ax1) * (ay2 - ay1)
area_b = (bx2 - bx1) * (by2 - by1)
# IoU計算
union_area = area_a + area_b - intersection_area
return intersection_area / union_area if union_area > 0 else 0
■ クラスバランス自動調整
データセットの各クラスが均等になるよう自動調整します。
class Counter:
"""クラス間データバランス管理"""
def __init__(self, num_classes):
self.__counter = np.zeros(num_classes)
def get_next_class(self):
"""最も少ないクラスIDを返す"""
return int(np.argmin(self.__counter))
def increment(self, class_id):
"""指定クラスのカウントを増加"""
self.__counter[class_id] += 1
def get_distribution(self):
"""現在のクラス分布を返す"""
return self.__counter.copy()
■ エフェクト処理による多様化
ノイズ追加と、ガウシアンブラー適用で、アノテーションデータにバリエーションを追加しています。
class Effecter:
"""画像エフェクト処理"""
def apply_gaussian_blur(self, image, level):
"""ガウシアンブラー適用"""
kernel_size = level * 2 + 1
return cv2.blur(image, (kernel_size, kernel_size))
def add_noise(self, image):
"""リアルなノイズ追加"""
image_float = image.astype('float64')
# チャンネル別ノイズ処理
for channel in range(3):
noise = np.random.normal(0, random.randint(1, 100),
image_float[:, :, channel].shape)
noise = (noise - noise.min()) / (noise.max() - noise.min())
# 適応的ノイズ強度
diff = 255 - image_float[:, :, channel].max()
adjusted_noise = diff * noise
image_float[:, :, channel] += adjusted_noise
return np.clip(image_float, 0, 255).astype('uint8')
4.2.3 生成されるデータ
生成される合成データは、以下の構造で出力されます。
merge
├── 00001.png # 画像データ
├── 00001.od. # 物体検出用のアノテーションデータ
├── 00001.seg # セグメンテーション用のアノテーションデータ
├── 00002.png
├── 00002.od
├── 00002.seg
├── 00003.png
├── 00003.od
├── 00003.seg
・・・略・・・
├── 02998.png
├── 02998.od
├── 02998.seg
├── 02999.png
├── 02999.od
├── 02999.seg
- xxxx.png 画像データ

- xxxx.od 物体検出用のアノテーションデータ
0 0.617188 0.328125 0.256250 0.322917
0 0.242969 0.682292 0.260937 0.339583
0 0.250000 0.377083 0.240625 0.325000
0 0.531250 0.831250 0.203125 0.279167
0 0.639844 0.581250 0.192188 0.258333
0 0.437500 0.546875 0.175000 0.243750
0 0.834375 0.197917 0.275000 0.379167
0 0.855469 0.646875 0.210938 0.277083
- xxxx.seg セグメンテーション用のアノテーションデータ
0 0.62813 0.16667 0.62813 0.16667 0.62187 0.16667 0.62187 0.16667 0.61875 0.16667 0.61875 0.16875 0.61719 0.16875 0.61562 0.16875 0.61406 0.16875 0.61406 0.16875 0.61250 0.16875 0.61250 0.17083 0.61094 0.17083 0.60938 0.17083 0.60938 0.17083 0.60781 0.17292 0.60781 0.17292 0.60781 0.17292 0.60625 0.17292 0.60469 0.17500 0.60469 0.17500 0.60469 0.17500 0.60313 0.17500 0.60313 0.17500 0.
4.3 [Phase 3] 合成データからyoloデータセット作成
合成データから、YOLOv8で使用可能な2つの形式を生成します:
- セグメンテーション形式: ポリゴン座標(正規化済み)
- 物体検出形式: バウンディングボックス(中心座標+幅・高さ)
4.3.1 実行コマンド
実行コマンドは、以下のとおりです。
$ python3 merge_2_dataset.py
4.3.2 主要コンポーネント
以下、merge_2_dataset.pyの主要コンポーネントの解説です。
■ セグメンテーションデータ形式
背景に貼り付けた透過pngの位置からアノテーションデータを再計算し、出力しています。
def generate_segmentation_label(class_id, contour_points, image_width, image_height):
"""YOLO形式セグメンテーションラベル生成"""
label = f"{class_id}"
for point in contour_points:
x, y = point
# 正規化座標(0-1範囲)
x_norm = x / image_width
y_norm = y / image_height
label += f" {x_norm:.6f} {y_norm:.6f}"
return label + "\n"
# 例:クラス0のオブジェクト
# 0 0.423156 0.158203 0.441250 0.154687 0.459844 0.156250 ...
■ 物体検出データ形式
背景に貼り付けた透過pngの位置からpngの画像サイズを再計算し、出力しています。
def generate_detection_label(class_id, bbox, image_width, image_height):
"""YOLO形式物体検出ラベル生成"""
x1, y1, x2, y2 = bbox
# 中心座標と幅・高さの計算
center_x = (x1 + x2) / 2.0 / image_width
center_y = (y1 + y2) / 2.0 / image_height
bbox_width = (x2 - x1) / image_width
bbox_height = (y2 - y1) / image_height
return f"{class_id} {center_x:.6f} {center_y:.6f} {bbox_width:.6f} {bbox_height:.6f}\n"
# 例:クラス0のオブジェクト
# 0 0.512500 0.387500 0.125000 0.175000
■ データセット分割戦略
データは、学習用と検証用で8:2に分割されます。
def split_dataset(input_path, output_path, train_ratio=0.8):
"""データセットの自動分割"""
image_files = glob.glob(f"{input_path}/*.png")
for i, image_file in enumerate(image_files):
basename = os.path.splitext(os.path.basename(image_file))[0]
# 8:2で学習・検証データに分割
stage = "train" if i % 10 < 8 else "val"
# ファイルコピー
shutil.copy(image_file, f"{output_path}/{stage}/images/{basename}.png")
# 対応するラベルファイル
for ext in ['seg', 'od']: # セグメンテーション・検出両対応
label_file = f"{input_path}/{basename}.{ext}"
if os.path.exists(label_file):
shutil.copy(label_file, f"{output_path}_{ext}/{stage}/labels/{basename}.txt")
■ data.yaml自動生成
YOLOでデータセットの配置を指定するためのyamlは、自動的に生成されます。
def create_data_yaml(output_path, class_names):
"""YOLOv8用データセット設定ファイル生成"""
docker_path = "/src/dataset/yolo_seg" # Docker環境パス
yaml_content = f"""# YOLO dataset configuration
path: {docker_path} # dataset root dir
train: train/images # train images (relative to 'path')
val: val/images # val images (relative to 'path')
# Classes
nc: {len(class_names)} # number of classes
names: {class_names} # class names
"""
with open(f"{output_path}/data.yaml", "w", encoding="utf-8") as f:
f.write(yaml_content)
print(f"Generated data.yaml with {len(class_names)} classes: {class_names}")
■ 自動クラス検出機能
data.yamlに必要なクラス名は、アノテーションデータを作成した時点でのフォルダ構成から自動的に検出しています。
def get_class_names_from_annotation():
"""annotationフォルダから自動的にクラス名を検出"""
annotation_path = "./dataset/annotation"
if not os.path.exists(annotation_path):
return ["object"] # デフォルトクラス
class_names = []
for item in os.listdir(annotation_path):
item_path = os.path.join(annotation_path, item)
if os.path.isdir(item_path):
class_names.append(item)
if not class_names:
return ["object"]
class_names.sort() # アルファベット順ソート
print(f"Detected classes: {class_names}")
return class_names
4.4 [Phase 4] ファインチューニングによるモデル作成
実行コマンドです。
# 物体検出
$ python3 train_od.py
# セグメンテーション
$ python3 train_seg.py
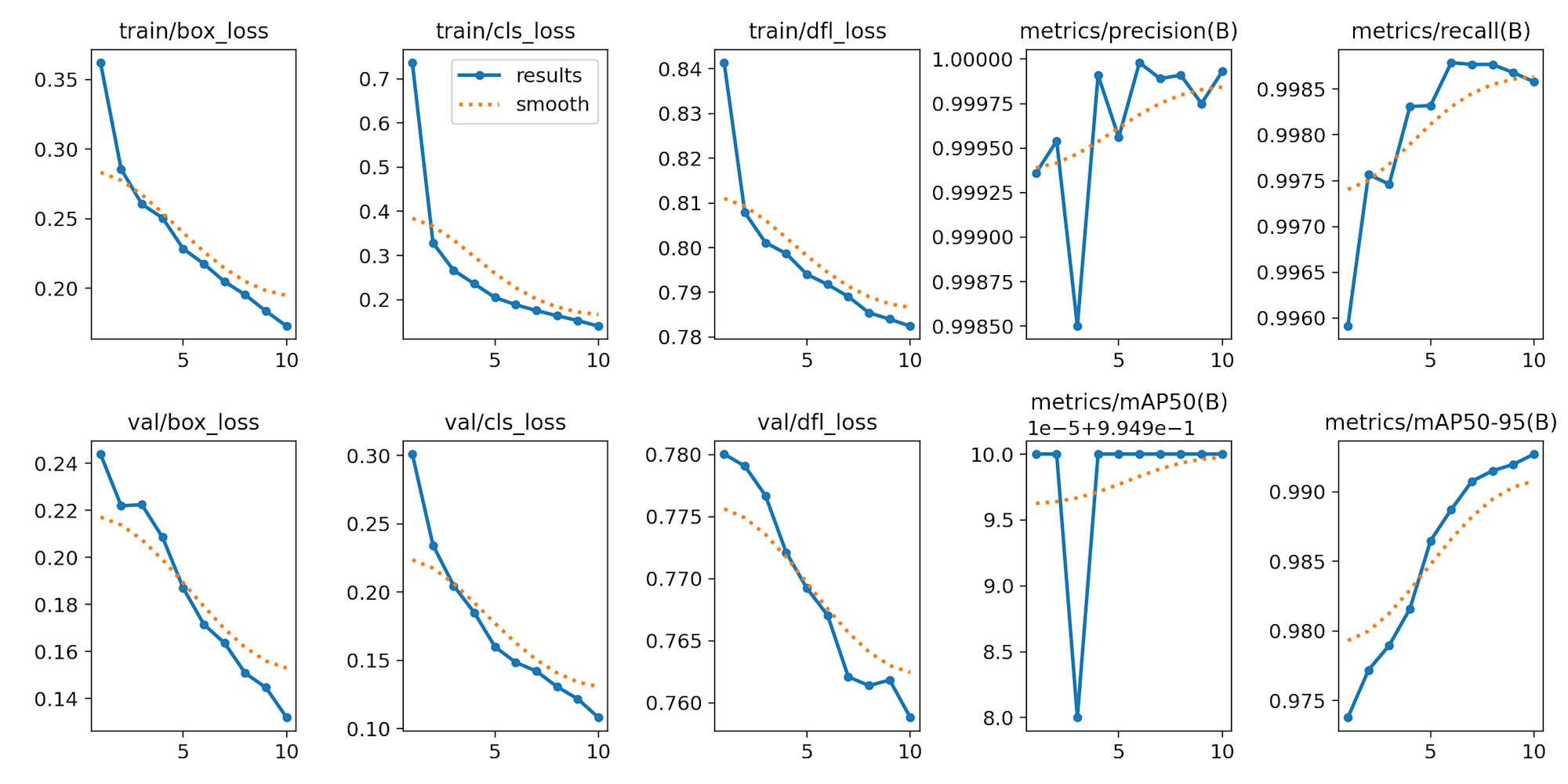
4.4.1 物体検出
ultralyticsでは、以下のような簡単なコマンドで、ファインチューニングが可能です。
train_od.py
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.train(data="./dataset/yolo_od/data.yaml", epochs=10, batch=8, workers=4)
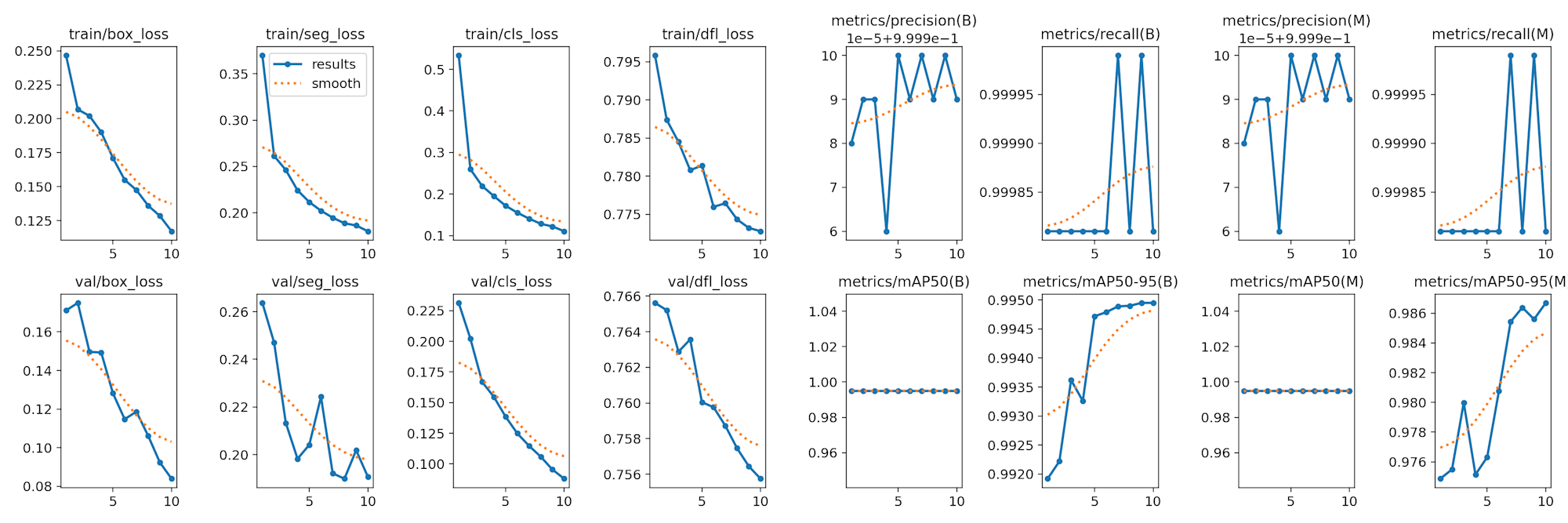
4.4.2 セグメンテーション
train_seg.py
from ultralytics import YOLO
model = YOLO("yolov8n-seg.pt")
model.train(data="./dataset/yolo_seg/data.yaml", epochs=10, batch=8, workers=4)
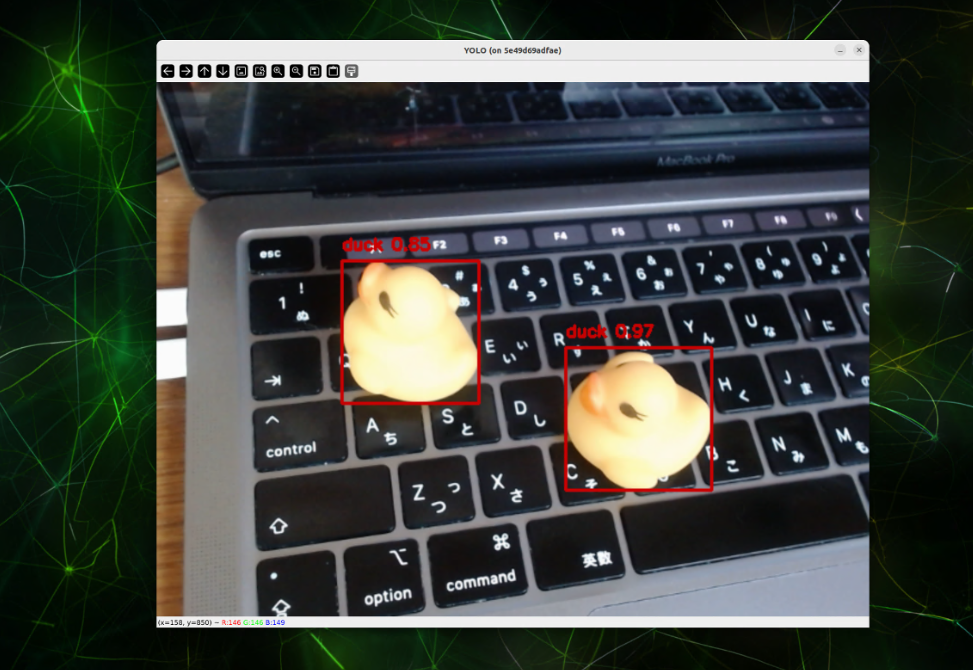
4.5 [Phase 5] 推論確認
以下のコマンドで確認できます。
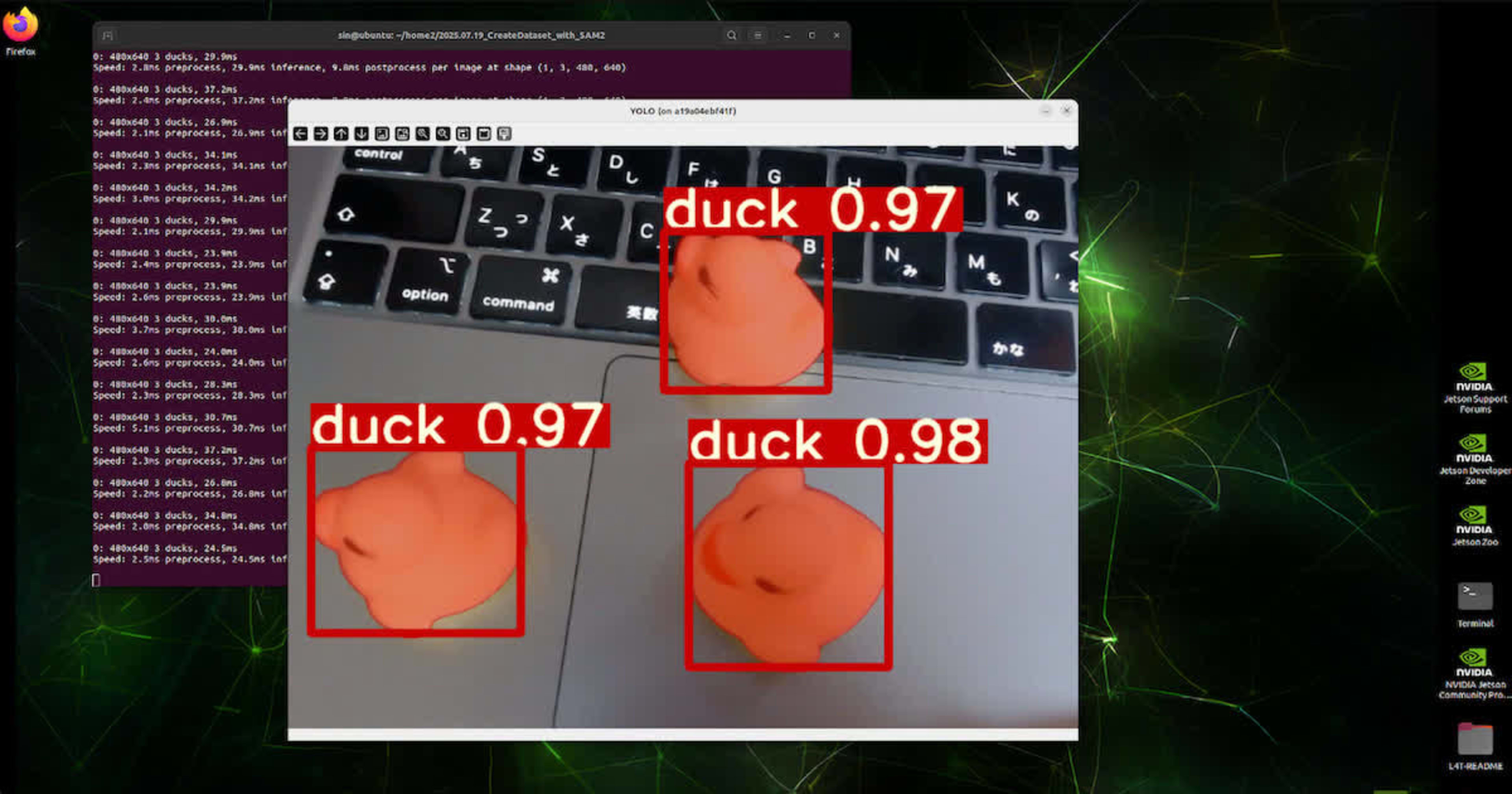
4.5.1 物体検出
$ python3 inference_od.py
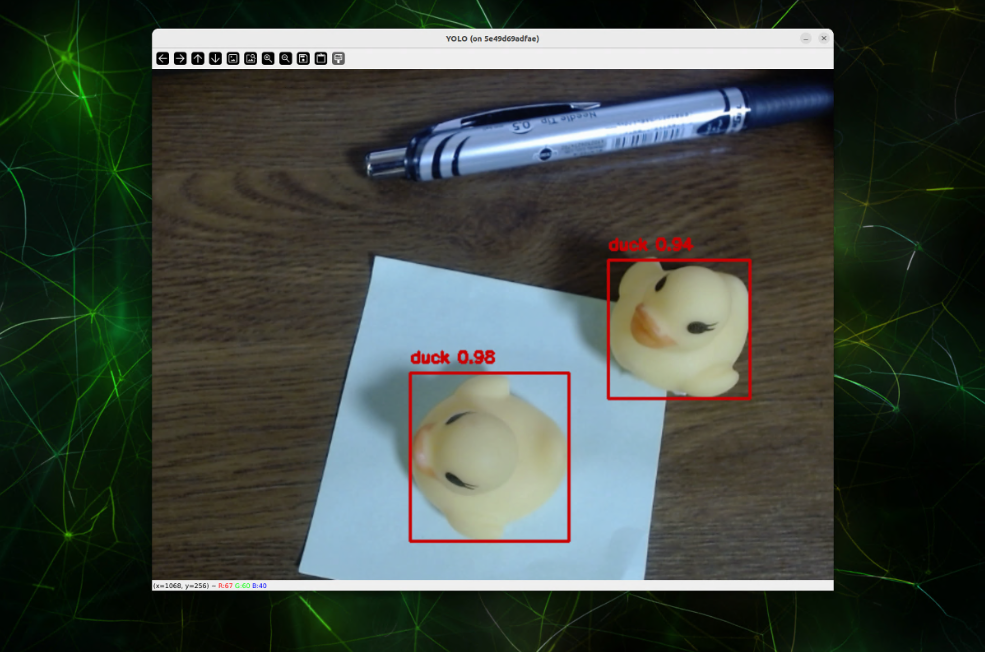
inference_od.py
import cv2
import numpy as np
from ultralytics import YOLO
MODEL_PATH = "./best.pt"
CONF_THRESHOLD = 0.80
IOU_THRESHOLD = 0.5
CAMERA_ID = 0
FRAME_WIDTH = 640
FRAME_HEIGHT = 480
COLORS = [
(0, 0, 200),
(0, 200, 0),
(200, 0, 0),
(200, 200, 0),
(0, 200, 200),
(200, 0, 200),
]
LINE_WIDTH = 5
FONT_SCALE = 1.5
FONT_FACE = cv2.FONT_HERSHEY_SIMPLEX
THICKNESS = 5
def draw_label(box, img, color, label, line_thickness=3):
x1, y1, x2, y2 = map(int, box)
text_size = cv2.getTextSize(
label, 0, fontScale=FONT_SCALE, thickness=line_thickness
)[0]
cv2.rectangle(img, (x1, y1), (x1 + text_size[0], y1 - text_size[1] - 2), color, -1)
cv2.putText(
img,
label,
(x1, y1 - 3),
FONT_FACE,
FONT_SCALE,
[225, 255, 255],
thickness=line_thickness,
lineType=cv2.LINE_AA,
)
cv2.rectangle(img, (x1, y1), (x2, y2), color, LINE_WIDTH)
def main():
model = YOLO(MODEL_PATH)
cap = cv2.VideoCapture(CAMERA_ID)
if not cap.isOpened():
raise IOError("カメラが開けません")
cap.set(cv2.CAP_PROP_FRAME_WIDTH, FRAME_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, FRAME_HEIGHT)
ret, frame = cap.read()
if not ret or frame is None:
raise IOError("カメラから画像が取得できません")
print(f"frame.shape: {frame.shape}")
print(f"Camera resolution is sufficient: {frame.shape}")
while True:
try:
ret, img = cap.read()
if ret is False:
raise IOError("カメラから画像が取得できません")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = model(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
names = results[0].names
classes = results[0].boxes.cls
confs = results[0].boxes.conf
boxes = results[0].boxes
for box, cls, conf in zip(boxes, classes, confs):
if conf < CONF_THRESHOLD:
continue
name = names[int(cls)]
x1, y1, x2, y2 = [int(i) for i in box.xyxy[0]]
cv2.rectangle(
img, (x1, y1), (x2, y2), COLORS[int(cls) % len(COLORS)], 2
)
cv2.putText(
img,
f"{name} {conf:.2f}",
(x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
COLORS[int(cls) % len(COLORS)],
2,
)
image_resized = cv2.resize(img, (FRAME_WIDTH * 2, FRAME_HEIGHT * 2))
cv2.imshow("YOLO", image_resized)
cv2.waitKey(1)
except KeyboardInterrupt:
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
4.5.2 セグメンテーション
$ python3 inference_seg.py
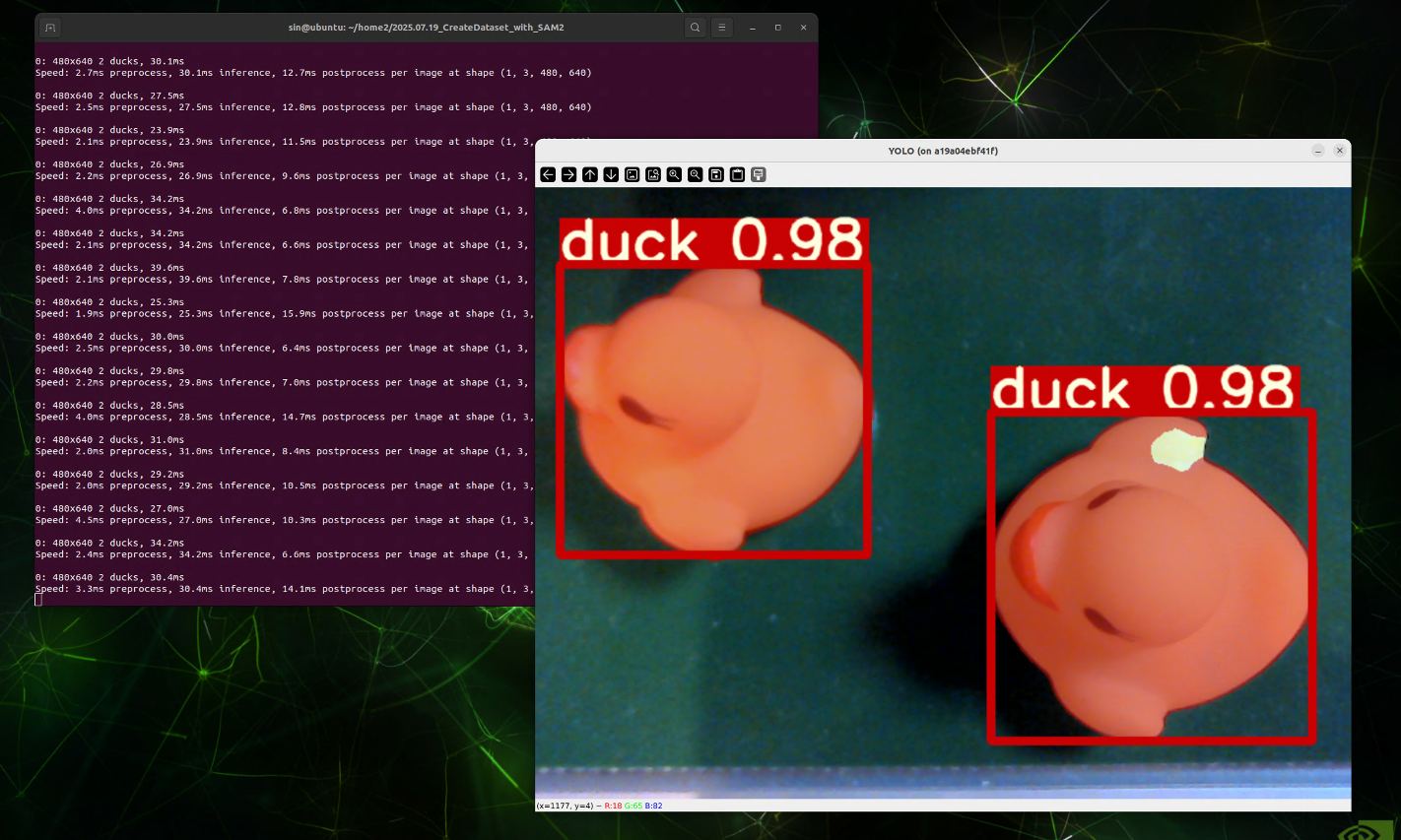
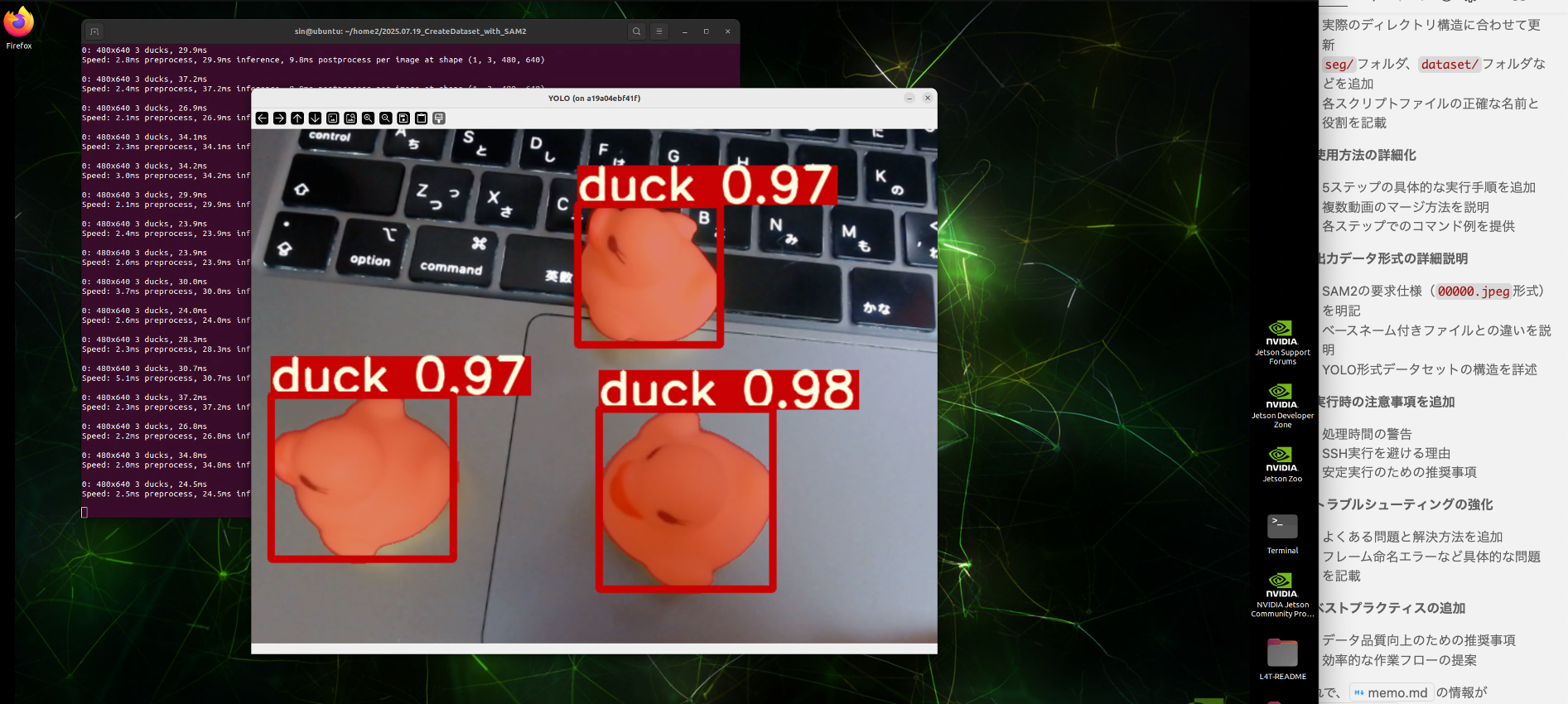
inference_seg.py
import cv2
import numpy as np
from ultralytics import YOLO
MODEL_PATH = "./best.pt"
CONF_THRESHOLD = 0.85
IOU_THRESHOLD = 0.5
CAMERA_ID = 0
FRAME_WIDTH = 640
FRAME_HEIGHT = 480
COLORS = [
(0, 0, 200),
(0, 200, 0),
(200, 0, 0),
(200, 200, 0),
(0, 200, 200),
(200, 0, 200),
]
LINE_WIDTH = 5
FONT_SCALE = 1.5
FONT_FACE = cv2.FONT_HERSHEY_SIMPLEX
THICKNESS = 5
def overlay(image, mask, color, alpha, resize=None):
"""マスクを画像に重ねる"""
colored_mask = np.expand_dims(mask, 0).repeat(3, axis=0)
colored_mask = np.moveaxis(colored_mask, 0, -1)
masked = np.ma.MaskedArray(image, mask=colored_mask, fill_value=color)
image_overlay = masked.filled()
if resize is not None:
image = cv2.resize(image.transpose(1, 2, 0), resize)
image_overlay = cv2.resize(image_overlay.transpose(1, 2, 0), resize)
image_combined = cv2.addWeighted(image, 1 - alpha, image_overlay, alpha, 0)
return image_combined
def draw_label(box, img, color, label, line_thickness=3):
x1, y1, x2, y2 = map(int, box)
text_size = cv2.getTextSize(
label, 0, fontScale=FONT_SCALE, thickness=line_thickness
)[0]
cv2.rectangle(img, (x1, y1), (x1 + text_size[0], y1 - text_size[1] - 2), color, -1)
cv2.putText(
img,
label,
(x1, y1 - 3),
FONT_FACE,
FONT_SCALE,
[225, 255, 255],
thickness=line_thickness,
lineType=cv2.LINE_AA,
)
cv2.rectangle(img, (x1, y1), (x2, y2), color, LINE_WIDTH)
def main():
model = YOLO(MODEL_PATH)
cap = cv2.VideoCapture(CAMERA_ID)
if not cap.isOpened():
raise IOError("カメラが開けません")
cap.set(cv2.CAP_PROP_FRAME_WIDTH, FRAME_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, FRAME_HEIGHT)
ret, frame = cap.read()
if not ret or frame is None:
raise IOError("カメラから画像が取得できません")
print(f"frame.shape: {frame.shape}")
print(f"Camera resolution is sufficient: {frame.shape}")
try:
while True:
ret, frame = cap.read()
if not ret:
raise IOError("カメラから画像が取得できません")
h, w, _ = frame.shape
results = model(frame, conf=CONF_THRESHOLD, iou=IOU_THRESHOLD)
result = results[0]
image = frame.copy()
if result.masks is not None:
for r in results:
boxes = r.boxes
conf_list = r.boxes.conf.tolist()
for i, (seg, box) in enumerate(
zip(result.masks.data.cpu().numpy(), boxes)
):
seg = cv2.resize(seg, (w, h))
color = COLORS[int(box.cls) % len(COLORS)]
image = overlay(image, seg, color, 0.5)
class_id = int(box.cls)
box_xyxy = box.xyxy.tolist()[0]
class_name = result.names[class_id]
draw_label(
box_xyxy,
image,
color,
f"{class_name} {conf_list[i]:.2f}",
line_thickness=3,
)
image_resized = cv2.resize(image, (FRAME_WIDTH * 2, FRAME_HEIGHT * 2))
cv2.imshow("YOLO", image_resized)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
except KeyboardInterrupt:
pass
finally:
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
5 最後に
ちょっと、乱暴ですが、既存の方法と、SAM2を使用した自動生成で、工数を比較してみました。
| 処理段階 | 従来手法 | SAM2システム | 改善倍率 |
|---|---|---|---|
| 1画像アノテーション | 15分 | 0.3分 | 50倍高速 |
| 1000画像データセット | 250時間 | 5時間 | 50倍高速 |
| 品質チェック | 40時間 | 1時間 | 40倍高速 |
| 総合 | 290時間 | 6時間 | 48倍高速 |
本記事の主要なポイントは、SAM2を用いた自動アノテーションにより、従来の手動アノテーションに比べて95%以上の作業削減を実現したこと、そして高品質なデータセットを効率的に生成できたことです。
AI技術の急速な発展により、従来不可能だった作業の自動化が、次々の現実のものとなっています。SAM2を活用したこのようなシステムも、その一例と言えると思います。