
LangGraphで AIエージェントをまなんでいく - その6 エージェントのメモリに外部データベースを使う-
2025.01.29
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
前の記事でMemorySaverを用いたチェックポイントを使ってメモリ内にグラフの状態(ここではメッセージ)を保存する方法を試しました。
今回は外部のデータベースを使ってグラフの状態を保存してみることを試したいと思います。
またlangchain-academyを利用して動作を見ていきます。
SqliteSaver
インストール
LangGraphの標準パッケージには組み込まれていないので、別途インストールする必要があります。
pip install langgraph-checkpoint-sqlite
組み込み
ファイルパスを指定することで、ローカルにDBを作成して扱えるようになります。
mkdir -p state_db
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
db_path = "state_db/hoge.db"
conn = sqlite3.connect(db_path, check_same_thread=False)
memory = SqliteSaver(conn)
チャットボットの実装は以下です。
以下のようなフローで動作します:
- 会話の履歴(messages)を保持。
- 必要に応じて会話内容を要約(summary)として保存。
- 要約が存在する場合は、それを基に会話の文脈を維持。
- メッセージが一定数を超えた場合に会話履歴を要約し、最新の履歴だけを残す。
これにより、長い会話でも効率的に文脈を保持しつつ、処理負荷を低減できます
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import SystemMessage, HumanMessage, RemoveMessage
from langgraph.graph import END
from langgraph.graph import MessagesState
model = ChatGoogleGenerativeAI(model="gemini-1.5-flash",temperature=0)
class State(MessagesState):
summary: str
# Define the logic to call the model
def call_model(state: State):
# Get summary if it exists
summary = state.get("summary", "")
# If there is summary, then we add it
if summary:
# Add summary to system message
system_message = f"Summary of conversation earlier: {summary}"
# Append summary to any newer messages
messages = [SystemMessage(content=system_message)] + state["messages"]
else:
messages = state["messages"]
response = model.invoke(messages)
return {"messages": response}
def summarize_conversation(state: State):
# First, we get any existing summary
summary = state.get("summary", "")
# Create our summarization prompt
if summary:
# A summary already exists
summary_message = (
f"This is summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above:"
)
else:
summary_message = "Create a summary of the conversation above:"
# Add prompt to our history
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
# Determine whether to end or summarize the conversation
def should_continue(state: State):
"""Return the next node to execute."""
messages = state["messages"]
# If there are more than six messages, then we summarize the conversation
if len(messages) > 6:
return "summarize_conversation"
# Otherwise we can just end
return END
グラフの作成
sqlite checkpointerを使ってグラフを作成します。
from IPython.display import Image, display
from langgraph.graph import StateGraph, START
# Define a new graph
workflow = StateGraph(State)
workflow.add_node("conversation", call_model)
workflow.add_node(summarize_conversation)
# Set the entrypoint as conversation
workflow.add_edge(START, "conversation")
workflow.add_conditional_edges("conversation", should_continue)
workflow.add_edge("summarize_conversation", END)
# Compile
graph = workflow.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
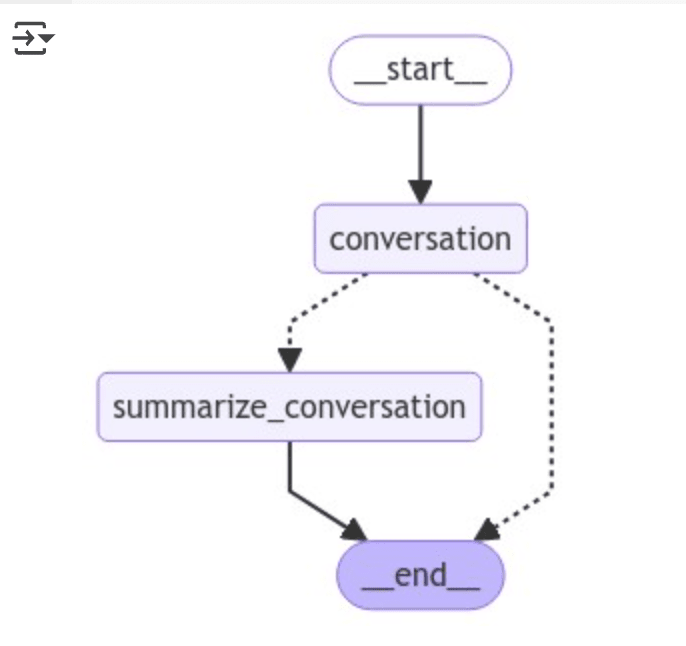
グラフ実行
スレッドを開始します。
# Create a thread
config = {"configurable": {"thread_id": "1"}}
# Start conversation
input_message = HumanMessage(content="やあ、私はハンターです")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()

会話内容を覚えているか確認してみます。
input_message = HumanMessage(content="私の名前は何ですか?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()

ちゃんと最初の会話で言った名前を返してくれました。
何か適当な質問をしてみる。
input_message = HumanMessage(content="動画生成ができるAIサービスについて教えて")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()

グラフの状態を確認する
以下のコードで保存されたスレッドの内容を確認できます。
config = {"configurable": {"thread_id": "1"}}
graph_state = graph.get_state(config)
graph_state

外部のデータベースに保存したので、プロセスやランタイムを再起動してもアクセスできます。
input_message = HumanMessage(content="どこまで話していたっけ?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()

前の続きから会話をスタートすることもできました。
DBの中身
SQLiteの中身も確認してみました。
ライブラリのコード を確認したところ、2つのテーブルが作成されるようです。
checkpoints
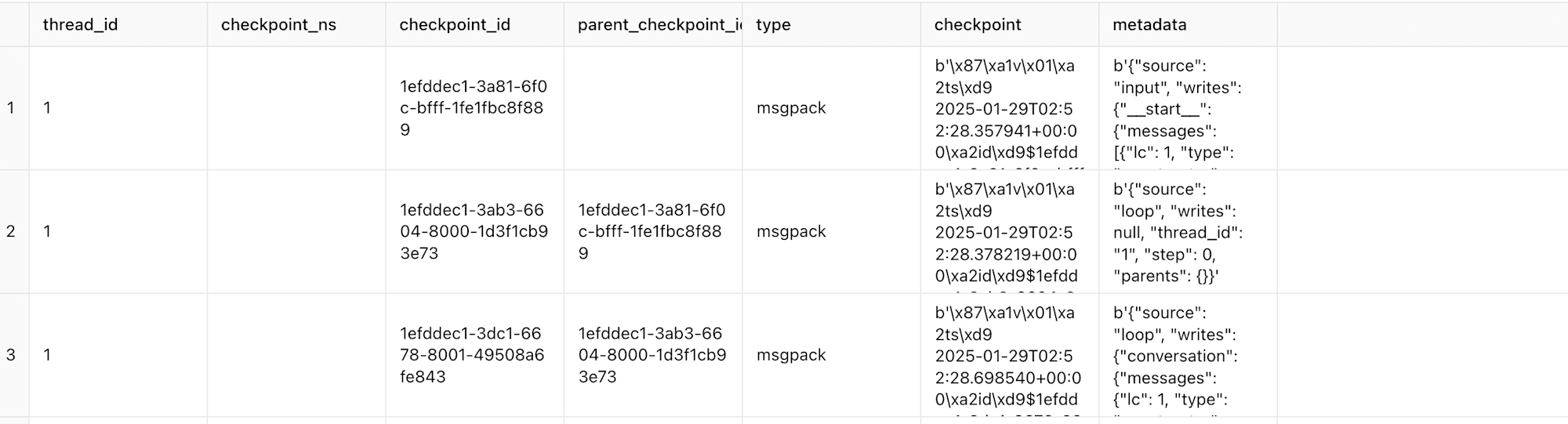
主なカラム:
- thread_id: スレッド識別子
- checkpoint_ns: チェックポイントのタイムスタンプ
- checkpoint_id: 各チェックポイントのユニークID
- parent_checkpoint_id: 親のチェックポイント
- type: msgpack(データのフォーマット)
- checkpoint: バイナリデータ(エンコードされた詳細情報)
- metadata: JSON形式のメタデータ(書き込み情報や入力情報など)
writes
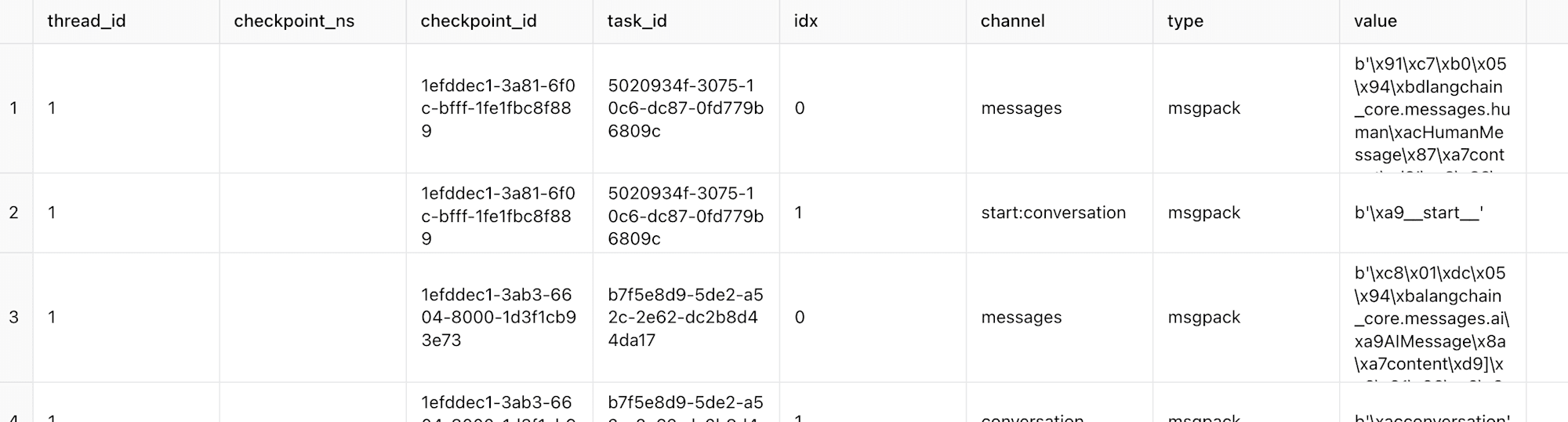
- thread_id: スレッド識別子
- checkpoint_ns: チェックポイントのタイムスタンプ
- checkpoint_id: 各チェックポイントのID
- task_id: タスクのID
- idx: インデックス
- channel: メッセージチャネル(例: messages, conversation など)
- type: データの種類(例: msgpack)
- value: メッセージの実際の内容(エンコードされたデータ)








