
【新機能】Databricks Data Classificationが一般提供となったので試してみた
かわばたです。
2026年4月20日にDatabricks Data Classificationが一般提供となりました。
Data Classificationはテーブル内の機密データを AI ベースで自動的に検出・分類し、タグ付けすることができます。
本記事では、Data Classification の有効化から分類結果の確認、自動タグ付け、ABAC ポリシーによるマスキング連携、コスト確認まで一通り検証します。
概要
背景
データガバナンスの観点から、組織が保有するデータの中に どのような機密情報が含まれているか を把握することは非常に重要です。しかし、以下のような課題がありました。
- テーブル数が増えると、手動での機密データ特定は現実的でない
- カラム名だけでは実際のデータ内容(個人情報、クレジットカード番号など)を判断できない
- GDPR・個人情報保護法などのコンプライアンス要件に対応するため、機密データの所在を把握する必要がある
機能の内容
Unity Catalog の Data Classification は、AI を活用してテーブル内のデータを自動的にスキャン・分類します。
| 機能 | 説明 |
|---|---|
| 自動分類 | AI がカラムのデータ内容を分析し、機密データの種類を検出 |
| 自動タグ付け | 検出結果に基づき Unity Catalog タグを自動適用 |
| インクリメンタルスキャン | 新規テーブル・新規カラムは、通常24時間以内に自動分類(初回以降はコスト最適化) |
| 誤検出の除外 | 誤った検出を除外し、今後の精度を向上 |
| ABAC 連携 | 分類タグに基づく属性ベースアクセス制御(マスキングなど)が可能 |
前提条件
- ワークスペースで サーバーレスコンピュート が利用可能であること
- 以下の権限が必要:
USE CATALOG権限MANAGE権限(カタログレベル、分類の有効化用)APPLY TAG権限(自動タグ付け用)ASSIGN権限(Data Classification の system governed tag を割り当てるために必要)
注意: Data Classification の system governed tag は、デフォルトでは account admin のみが
MANAGE/ASSIGN権限を持ちます。実運用では account admin から governed tag の権限委譲が必要な場合があります。
検証環境
| 項目 | 値 |
|---|---|
| プラットフォーム | Databricks on AWS |
| カタログ | workspace |
| スキーマ | default |
| コンピュート | Serverless |
| データ | 個人情報を含むテスト用テーブル(自作) |
サンプルデータの準備
検証用に、個人情報を含むテストテーブルを作成します。
-- 個人情報を含むテスト用テーブルを作成
CREATE OR REPLACE TABLE workspace.default.sample_customers (
customer_id INT,
full_name STRING,
email STRING,
phone_number STRING,
address STRING,
credit_card_number STRING,
ssn STRING,
date_of_birth DATE,
annual_income DECIMAL(12, 2),
notes STRING
);
-- テストデータを挿入
INSERT INTO workspace.default.sample_customers VALUES
(1, 'Taro Yamada', 'taro.yamada@example.com', '090-1234-5678', '東京都千代田区丸の内1-1-1', '4111111111111111', '123-45-6789', '1990-01-15', 5000000.00, '通常顧客'),
(2, 'Hanako Suzuki', 'hanako.suzuki@example.com', '080-9876-5432', '大阪府大阪市北区梅田2-2-2', '5500000000000004', '987-65-4321', '1985-06-20', 7500000.00, 'VIP顧客'),
(3, 'Jiro Tanaka', 'jiro.tanaka@example.com', '070-1111-2222', '愛知県名古屋市中区栄3-3-3', '340000000000009', '456-78-9012', '1978-11-30', 10000000.00, '法人担当'),
(4, 'Yuki Sato', 'yuki.sato@example.com', '090-3333-4444', '福岡県福岡市博多区博多駅前4-4-4', '6011111111111117', '321-54-9876', '1995-03-10', 3500000.00, '新規顧客'),
(5, 'Kenji Watanabe', 'kenji.watanabe@example.com', '080-5555-6666', '北海道札幌市中央区大通5-5-5', '3530111333300000', '654-32-1098', '1982-09-25', 6000000.00, '長期顧客');
-- 機密情報を含まない比較用テーブルも作成
CREATE OR REPLACE TABLE workspace.default.sample_products (
product_id INT,
product_name STRING,
category STRING,
price DECIMAL(10, 2),
stock_quantity INT
);
INSERT INTO workspace.default.sample_products VALUES
(1, 'ノートPC', '電子機器', 120000.00, 50),
(2, 'ワイヤレスマウス', '周辺機器', 3500.00, 200),
(3, 'USBケーブル', 'アクセサリ', 800.00, 500);
Data Classification の有効化
カタログレベルでの有効化
- Databricks ワークスペースの左メニューから Catalog を開く
- Catalog Explorer で対象のカタログ(
workspace)を選択 - Details 画面の Data Classification 設定から Enable classification をクリック
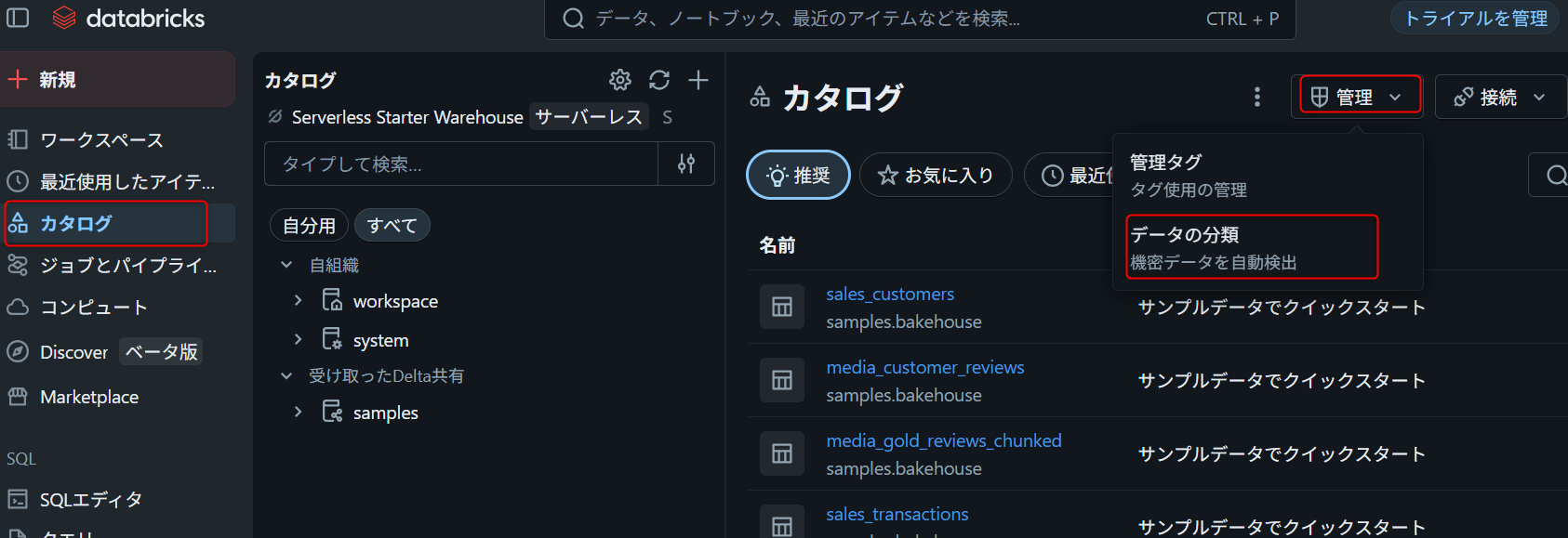
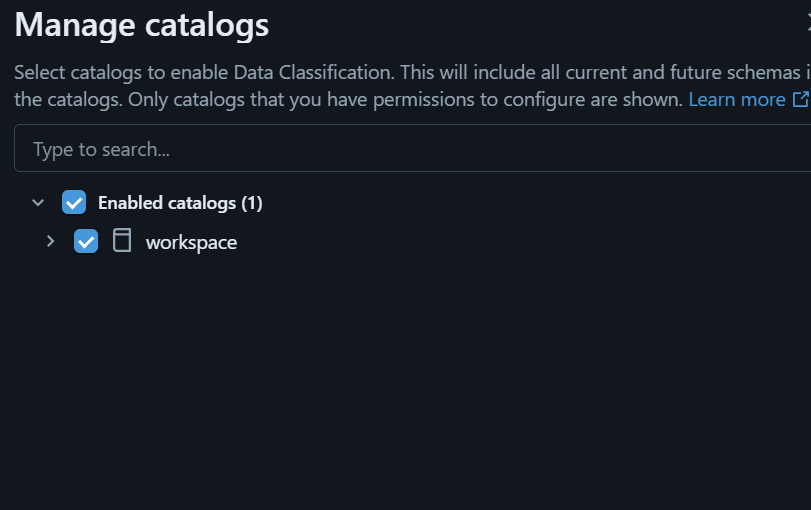
分類結果の確認
Data Classification を有効化すると、新規テーブル・新規カラムは通常24時間以内に自動分類されます。
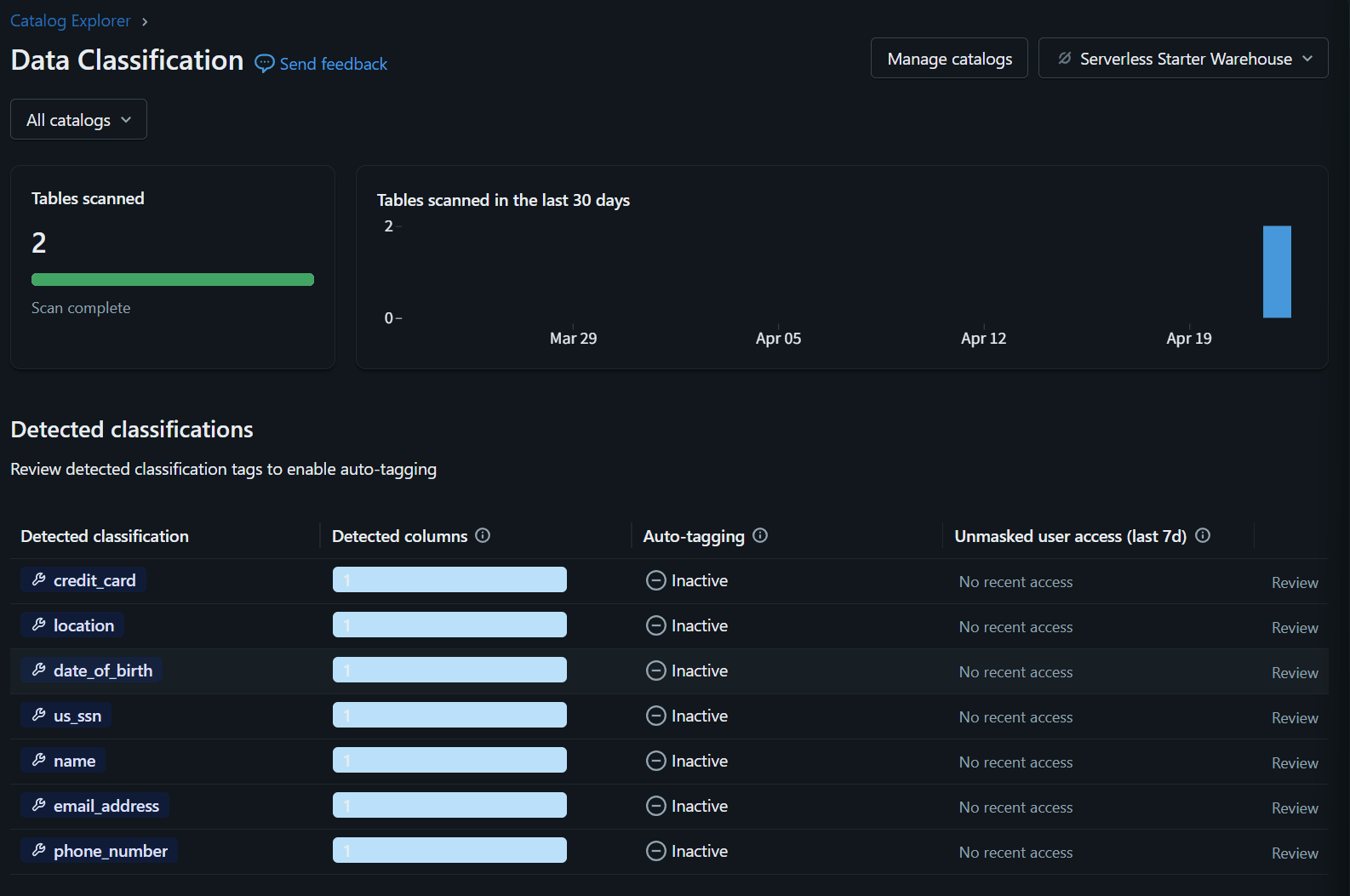
期待される検出結果
| カラム名 | 期待される system tag |
|---|---|
full_name |
class.name |
email |
class.email_address |
phone_number |
class.phone_number |
address |
class.location |
credit_card_number |
class.credit_card |
ssn |
class.us_ssn |
date_of_birth |
class.date_of_birth |
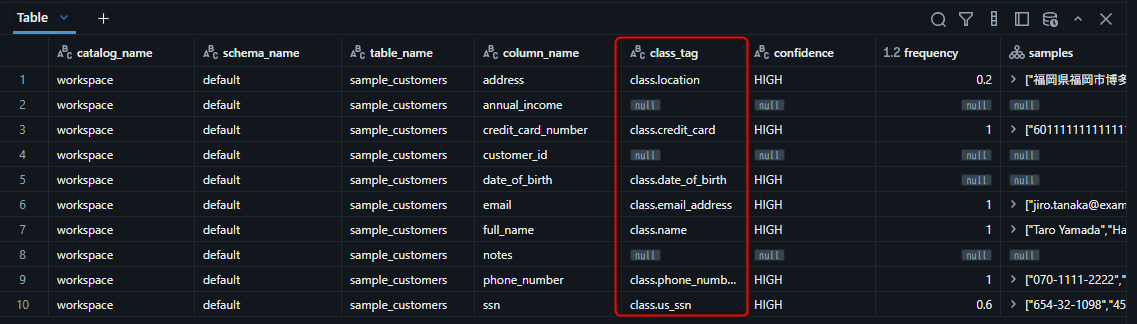
SQL での確認(system.data_classification.results)
分類結果そのものは system.data_classification.results テーブルに保存されます。
注意: このシステムテーブルはデフォルトで account admin のみ がアクセス可能であり、サーバーレスコンピュートでのみ クエリを実行できます。
-- 分類結果を確認(分類されたかどうかの確認に最適)
SELECT
catalog_name,
schema_name,
table_name,
column_name,
class_tag,
confidence,
frequency,
samples
FROM system.data_classification.results
WHERE catalog_name = 'workspace'
AND schema_name = 'default'
AND table_name = 'sample_customers'
ORDER BY column_name, class_tag;
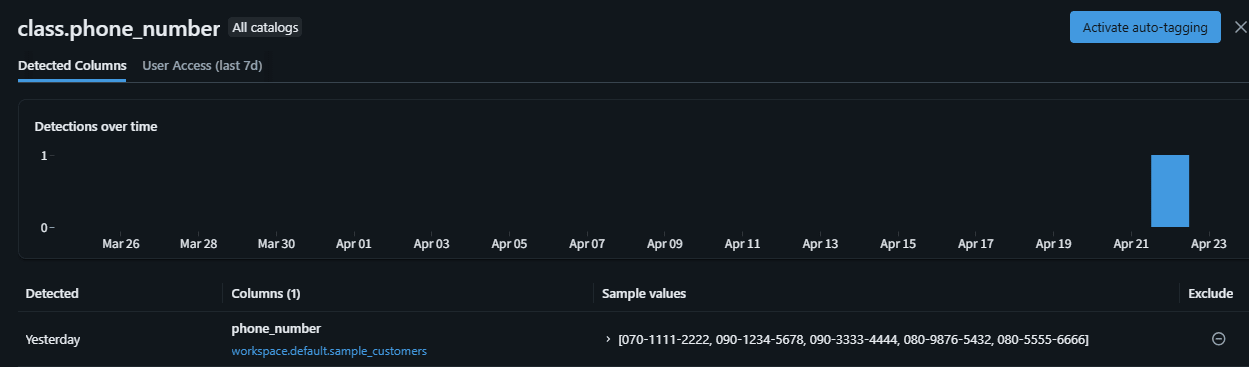
自動タグ付け(Auto-Tagging)の有効化
分類結果に基づいて、Unity Catalog のタグを自動的にカラムに適用することができます。
有効化手順
- Data Classification の結果ページで Auto-tagging を有効化
- 有効化以後の新規検出は即時タグ付けされる。既存の検出結果は 次回スキャン時 に反映される(通常24時間以内)
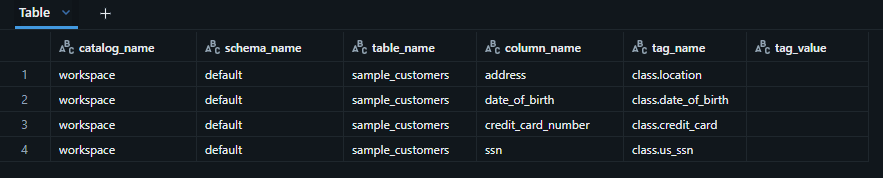
タグ付け結果の確認
-- カラムに適用されたタグを確認(Auto-tagging が列へ実際に反映されたかの確認)
SELECT
catalog_name,
schema_name,
table_name,
column_name,
tag_name,
tag_value
FROM system.information_schema.column_tags
WHERE catalog_name = 'workspace'
AND schema_name = 'default'
AND table_name = 'sample_customers';
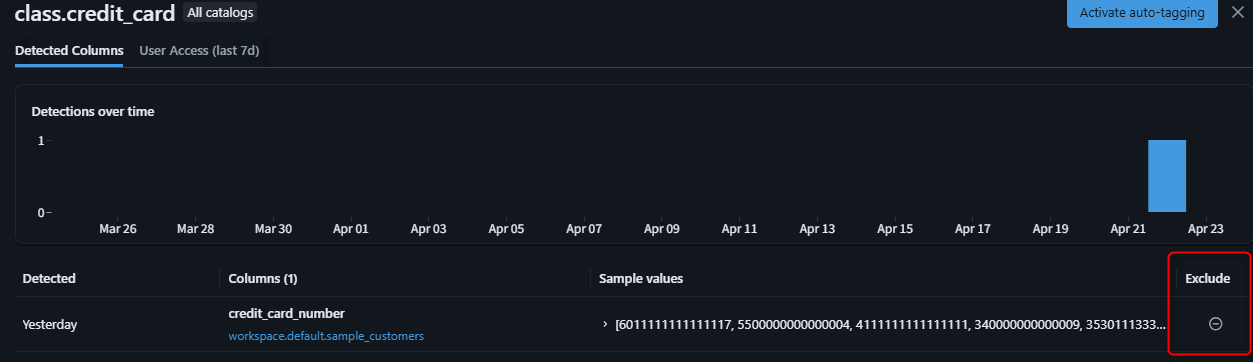
誤検出の除外
分類結果に誤検出が含まれる場合、除外設定を行うことで精度を向上できます。
除外手順
- Data Classification の結果ページで、除外したい検出結果を選択
- Exclude をクリック
- 除外されたカラムは既存の classification tag が削除され、今後の分類でも再適用されない
ポイント:
- 除外操作はモデルの精度向上にもフィードバックされるため、誤検出を見つけた場合は積極的に除外することが推奨されます。
- 除外した検出は、後から UI 上で 再度 include に戻す ことも可能です。
分類結果を活用したデータ保護
Data Classification の結果を活用して機密データを保護する方法として、カラムマスク(個別テーブルへの設定)と ABAC ポリシー(タグベースの中央管理)の2つのアプローチがあります。
| アプローチ | 特徴 |
|---|---|
| カラムマスク | テーブル・カラム単位で個別設定。シンプルだがスケールしにくい |
| ABAC ポリシー | governed tag ベースで中央管理。スケーラブルで Databricks 推奨 |
注意: ABAC で保護されたテーブルにアクセスするには Databricks Runtime 16.4 以上 または サーバーレスコンピュート が必要です。
カラムマスクによるマスキング(個別設定)
まず、マスキング用の関数を作成し、個別のカラムに適用する方法を確認します。
-- マスキング用の関数を作成
CREATE OR REPLACE FUNCTION workspace.default.mask_pii(value STRING)
RETURNS STRING
RETURN CASE
WHEN is_account_group_member('data_admin') THEN value
ELSE '***MASKED***'
END;
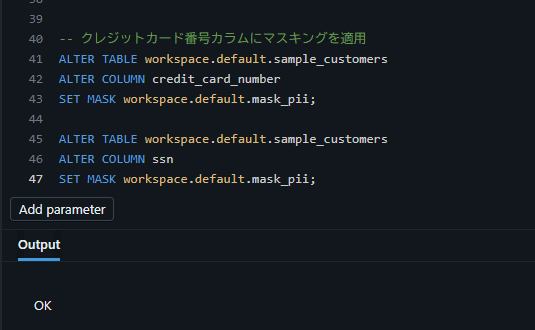
-- クレジットカード番号カラムにマスキングを適用
ALTER TABLE workspace.default.sample_customers
ALTER COLUMN credit_card_number
SET MASK workspace.default.mask_pii;
-- SSN カラムにもマスキングを適用
ALTER TABLE workspace.default.sample_customers
ALTER COLUMN ssn
SET MASK workspace.default.mask_pii;
ABAC ポリシーによるタグベースのマスキング(中央管理・推奨)
Data Classification が付与した system tag(例: class.email_address、class.credit_card など)に基づいて、CREATE POLICY / MATCH COLUMNS を使った中央集権的なアクセス制御ポリシーを作成できます。これにより、個別テーブルごとにマスクを設定する必要がなくなります。
-- マスキング用の関数を作成
CREATE OR REPLACE FUNCTION workspace.default.mask_classified_pii(value STRING)
RETURNS STRING
RETURN CASE
WHEN is_account_group_member('data_admin') THEN value
ELSE '***MASKED***'
END;
-- タグベースの ABAC ポリシーを作成(例: class.location タグが付いたカラムをマスク)
CREATE POLICY mask_classified_pii
ON SCHEMA workspace.default
COMMENT 'Mask columns classified as email addresses'
COLUMN MASK workspace.default.mask_classified_pii
TO `account users`
FOR TABLES
MATCH COLUMNS has_tag('class.location') AS c
ON COLUMN c;
ポイント: ABAC ポリシーは
MATCH COLUMNS has_tag(...)でタグ条件を指定するため、Data Classification によって自動タグ付けされた全カラムに一括でポリシーを適用できます。新しいテーブルが追加され自動分類・タグ付けされた場合も、ポリシーが自動的に適用されます。
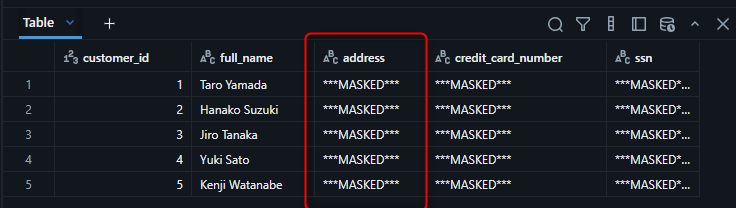
マスキング動作の確認
SELECT
customer_id,
full_name,
address,
credit_card_number,
ssn
FROM workspace.default.sample_customers;
コスト確認
Data Classification のスキャンコストは system.billing.usage テーブルから確認できます。
-- Data Classification に関連するコストを確認
SELECT
usage_date,
workspace_id,
identity_metadata.created_by,
usage_metadata.catalog_id,
usage_unit,
SUM(usage_quantity) AS usage_quantity
FROM system.billing.usage
WHERE usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
workspace_id,
identity_metadata.created_by,
usage_metadata.catalog_id,
usage_unit
ORDER BY usage_date DESC;

制限事項
- ビュー およびメトリクスビューは Data Classification の対象外
- スキャンには サーバーレスコンピュート が必須
- 初回スキャンは全テーブルが対象となるため、コストに注意が必要
まとめ
Unity Catalog の Data Classification を使用することで、テーブル内の機密データを AI ベースで自動的に検出・分類・タグ付け できることを確認しました。
特に、分類結果のタグを ABAC ポリシーと組み合わせることで、機密データの検出からアクセス制御までを一気通貫で実現 できる点は大きなメリットです。
この記事が何かの参考になれば幸いです!








