
【Databricks】Unity AI GatewayでLLMを利用してみた
データ事業本部のueharaです。
今回は、DatabricksのUnity AI GatewayでLLMを利用してみたいと思います。
はじめに
Unity AI Gatewayは、DatabricksのLLMエンドポイント、MCPサーバー、およびコーディングエージェント向けの『AIガバナンスレイヤー』です。
Unity Catalogのガバナンスモデルがエージェント型AIに拡張され、エージェントがLLMにアクセスしたり、MCPサーバーやAPIを活用するのに対し、アクセス許可、監査、およびポリシー制御を適用できるようになります。
今回は、そのAI Gateway Endpointを作成し、Pythonスクリプトから接続を行ってみたいと思います。
なお、各種コーディングエージェントからも一部モデルを利用できたりしますが、今回はコーディングエージェントからの呼び出しは検証対象としませんのでご了承下さい。
やってみた
AI Gateway Endpointの作成
まず、AI Gatewayのエンドポイントを作成します。
Databricksトップ画面の左側タブにある、『AI/ML』から『AI Gateway』を選択します。
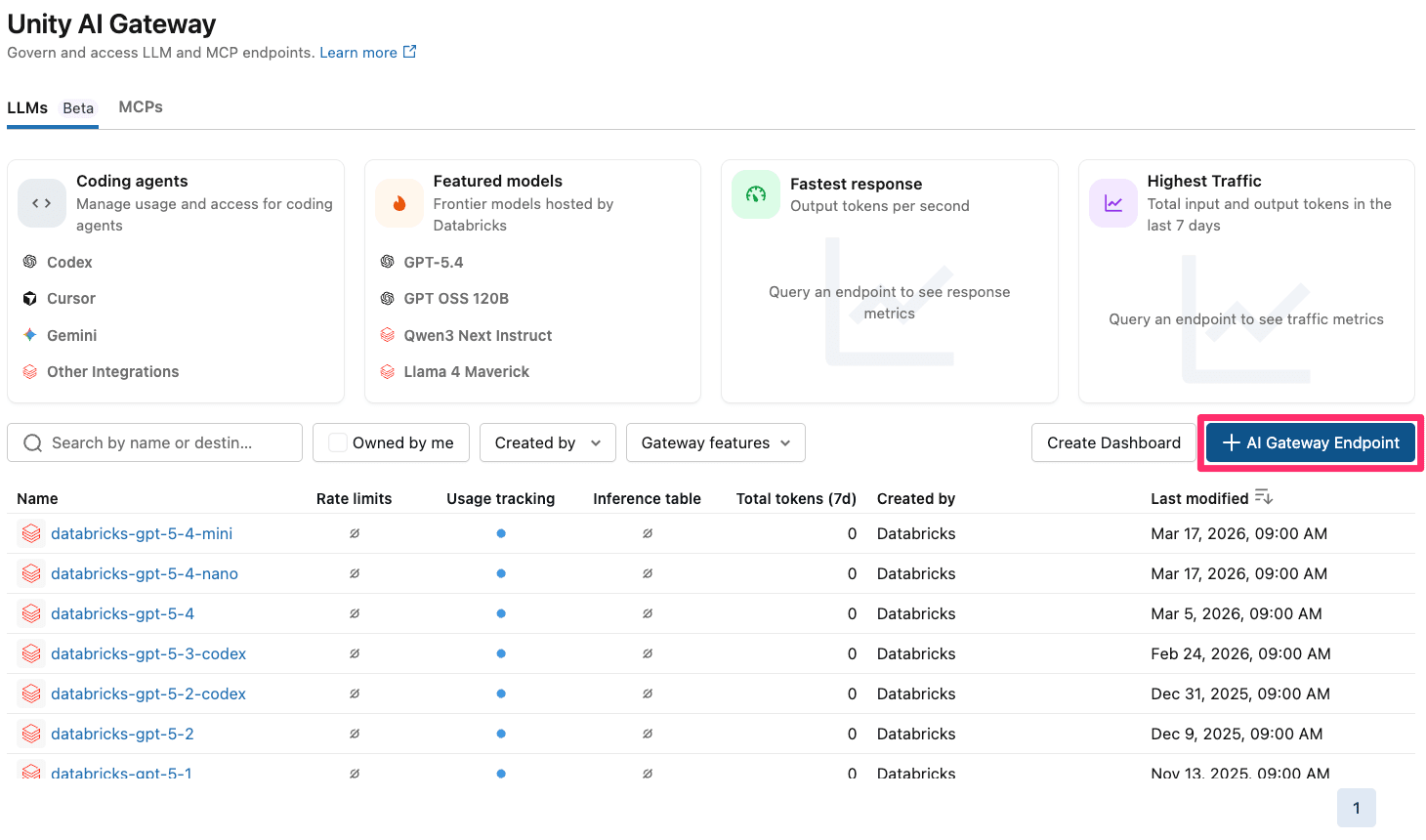
開いた画面から、『+ AI Gateway Endpoint』を押下します。
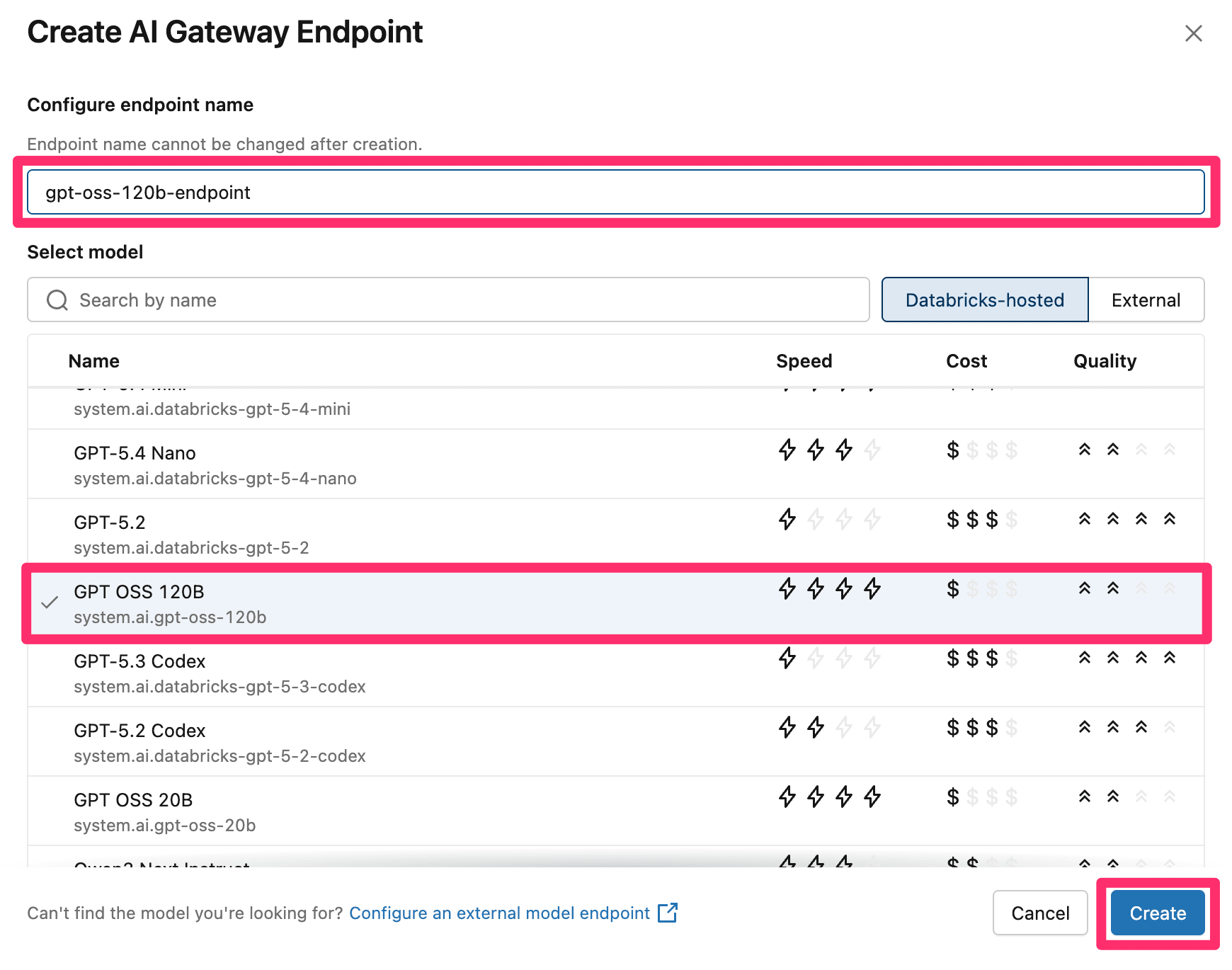
するとLLMの選択画面が表示されます。今回は『GPT OSS 120B』を選択し、適当なエンドポイント名を入力して『Create』を押下します。
エンドポイントを作成すると、以下のような画面が表示されます。
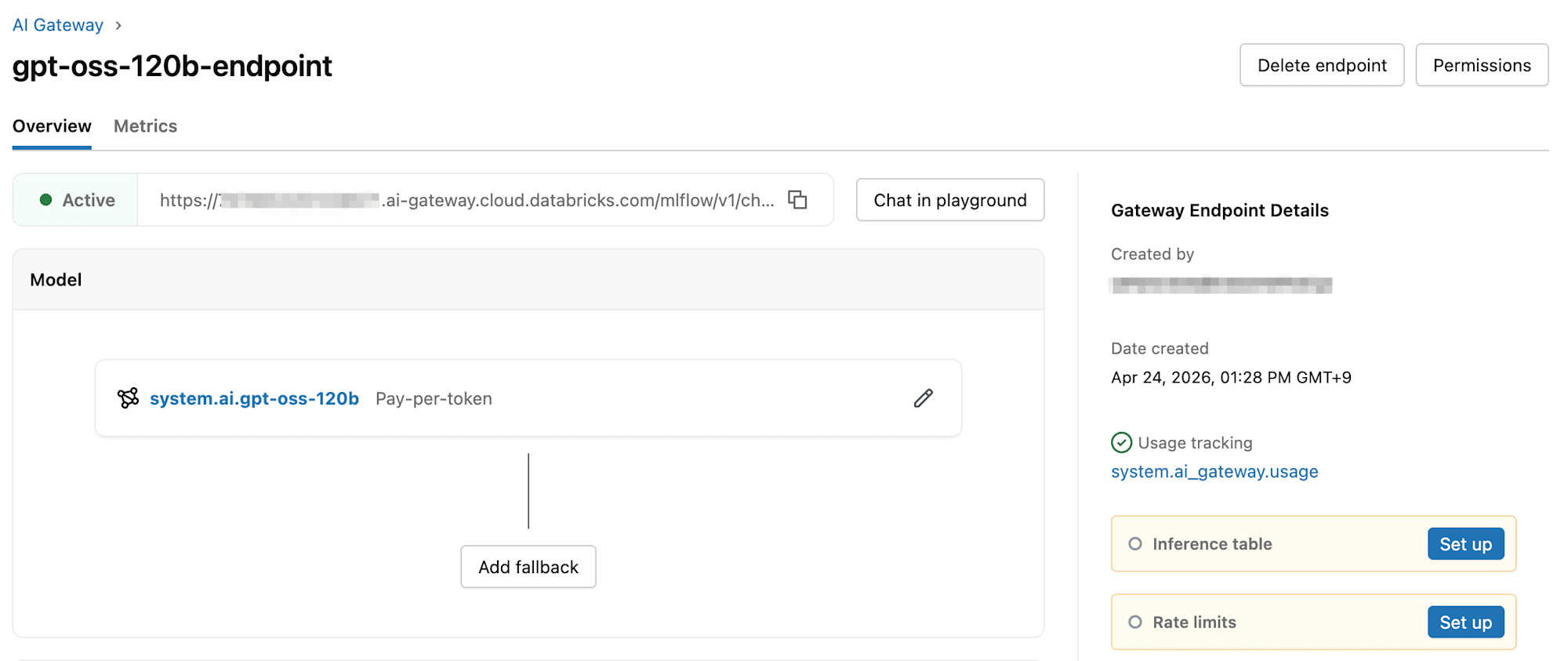
右上の「Permissions」ボタンを押下すると、権限の管理ができます。
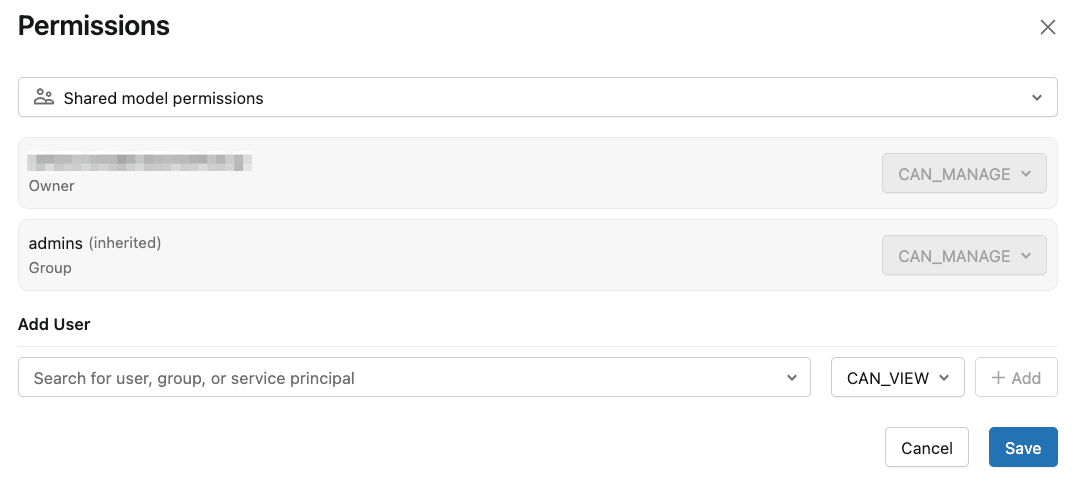
今回はOwnerユーザを利用するので、特にユーザやグループの追加はしません。
画面戻り、『Inference table』の設定を行います。
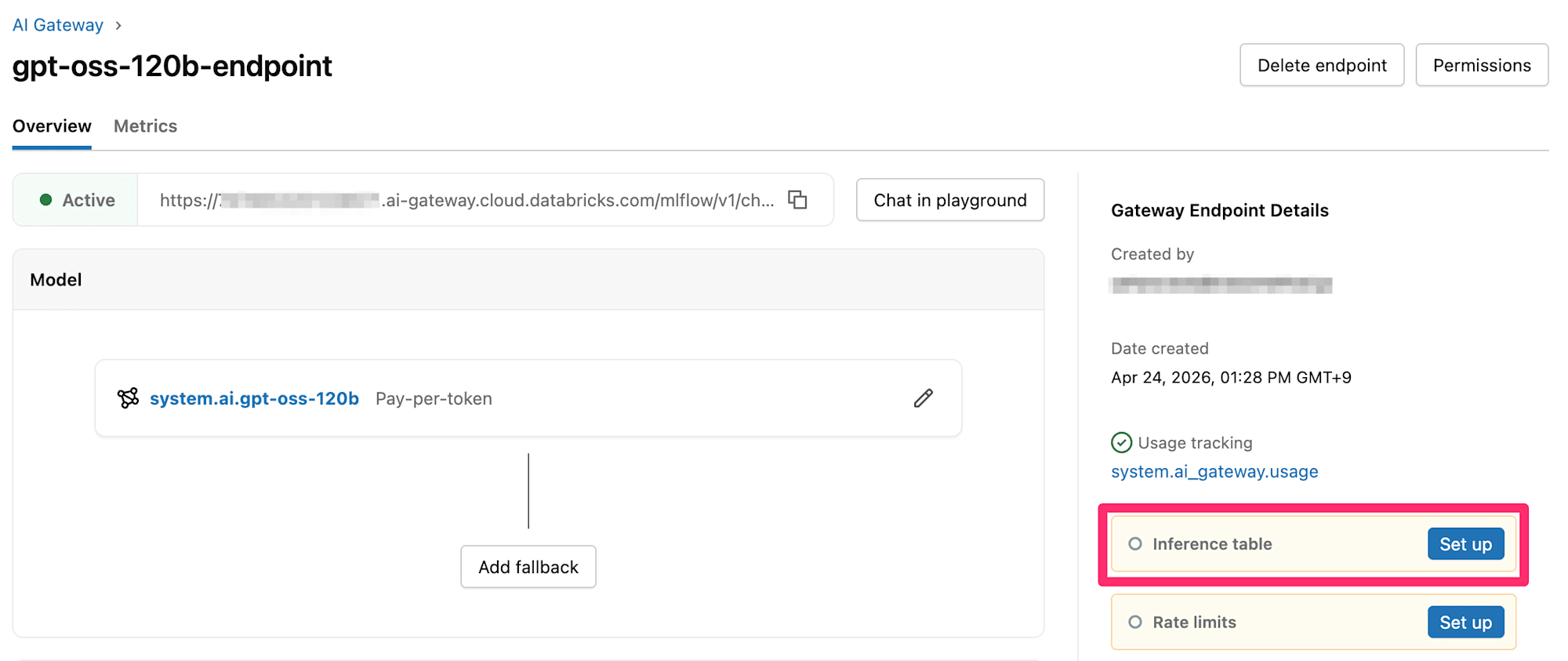
Inference table(推論テーブル)は、エンドポイントへの受信リクエストと送信レスポンスを自動的にキャプチャし、Delta Tableとしてログを記録するテーブルです。
保存先は任意ですが、Databricksマネージドなカタログでは設定ができず、「外部ストレージ」を使用するカタログを選択する必要がある点に注意して下さい。
私は手元のテスト用のスキーマに作成することにしました。
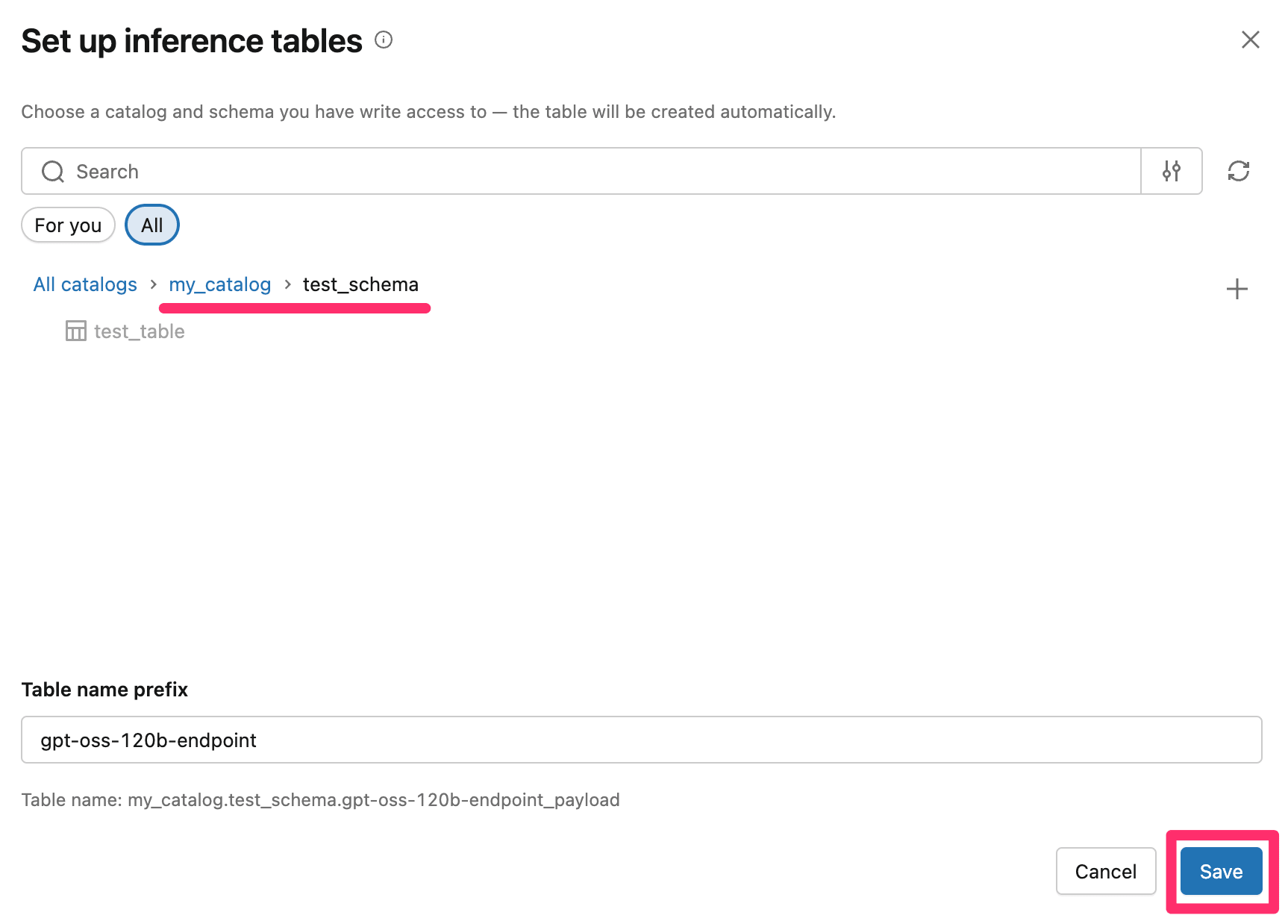
保存をすると、以下の通りInference tableが設定されます。

そのまま下の『Rate limits』を確認します。
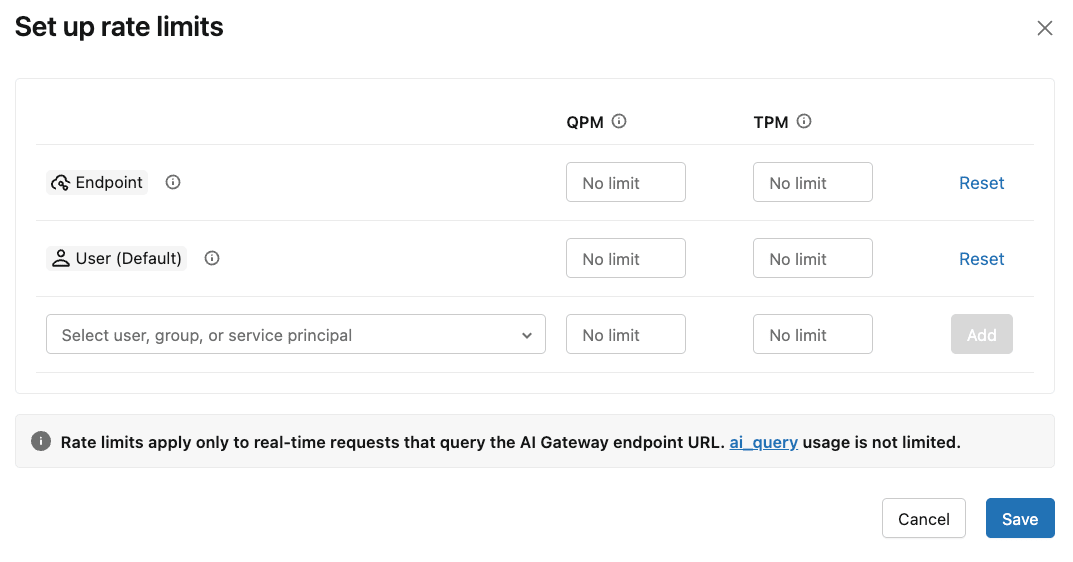
エンドポイント/グループ/ユーザ単位で、『1分あたりのクエリ数(QPM)』および『1分あたりのトークン数(TPM)』の制限を適用できることが分かります。
今回は特に設定せずに進みます。
これでエンドポイントの設定は完了です。
トークンの発行
次に、トークンの発行を行います。
作成したエンドポイントのページの下に進むと、『Generate Access Token』があるのでボタンを押します。
するとAccess Tokenが表示されるので、控えておきます。
これでトークンの発行は完了です。
Pythonスクリプトの作成
以下のようなPythonスクリプト test.py を作成しました。
import os
from openai import OpenAI
BASE_URL = os.environ.get("BASE_URL")
DATABRICKS_TOKEN = os.environ.get("DATABRICKS_TOKEN")
MODEL = "gpt-oss-120b-endpoint"
client = OpenAI(api_key=DATABRICKS_TOKEN, base_url=BASE_URL)
chat_completion = client.chat.completions.create(
messages=[
{"role": "user", "content": "FizzBuzz問題を解くPythonコードを書いてください。"},
],
model=MODEL,
max_tokens=1024,
)
print(chat_completion.choices[0].message.content)
BASE_URL および DATABRICKS_TOKEN は環境変数から取得するようにし、モデルは先程作成したエンドポイント名を入力します。
LLMに投げるメッセージは今回はリテラルで定義しています。
動作確認
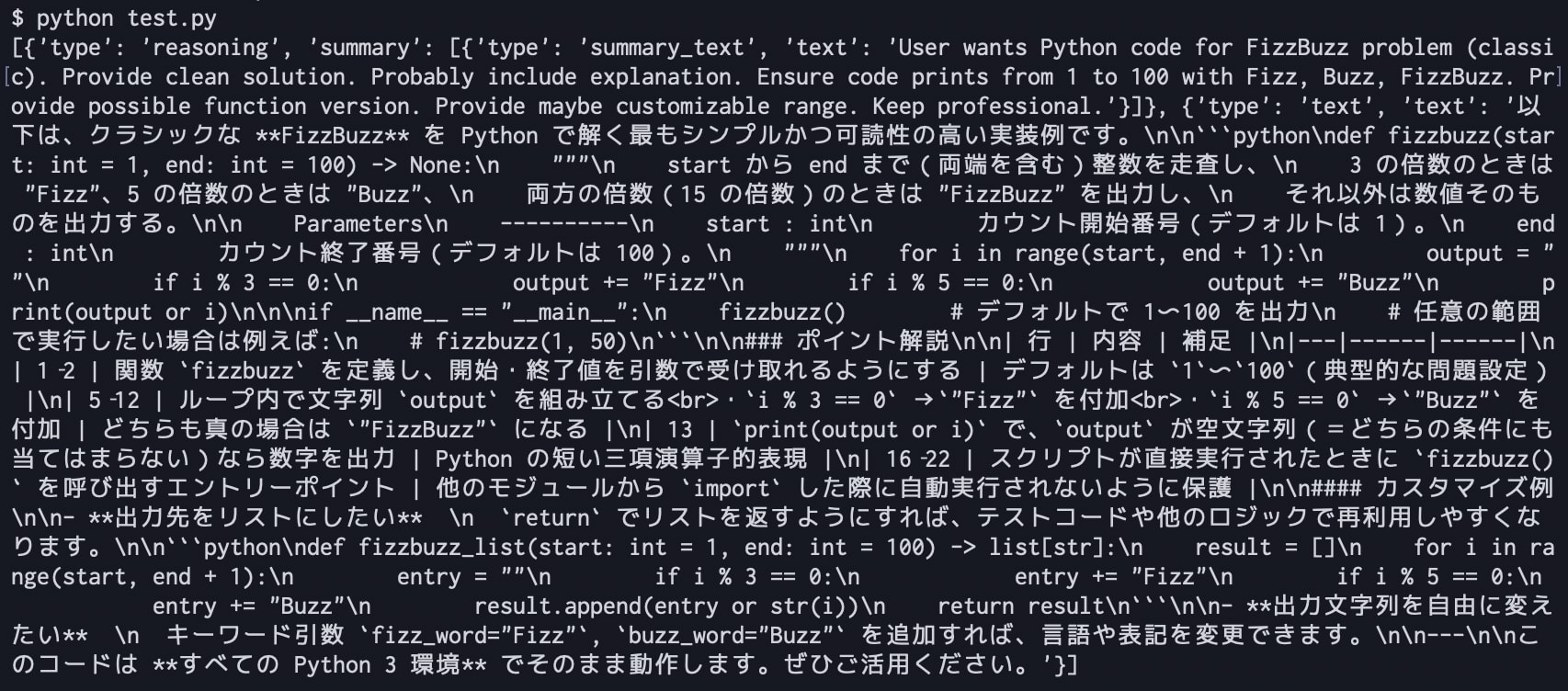
環境変数を設定し、Pythonスクリプトを実行します。
# BASE_URLの設定
$ export BASE_URL=https://<WORKSPACE-ID>.ai-gateway.cloud.databricks.com/mlflow/v1
# DATABRICKS_TOKENの設定
$ export DATABRICKS_TOKEN=<取得したトークン>
# スクリプト実行
$ python test.py
レスポンスをそのまま出力しているため少し結果が見辛いですが、以下の通り回答が返ってくることが確認できました。
Databricks上でエンドポイントのページから、以下のようにメトリクスを確認することができます。
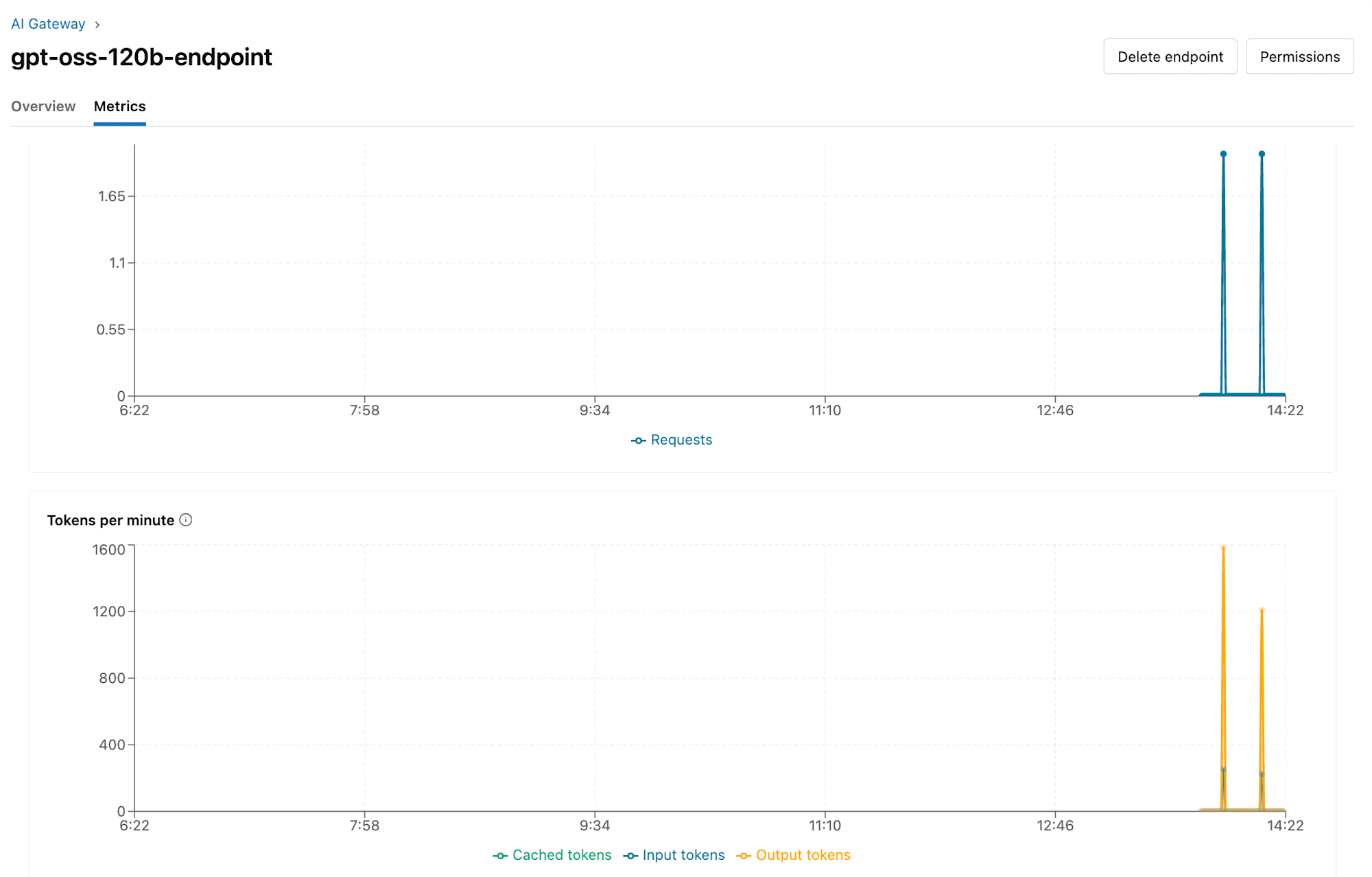
また設定した推論テーブルから、リクエストとレスポンスの結果等も確認することができました。

最後に
今回は、DatabricksのUnity AI GatewayでLLMを利用してみました。
Unity AI Gatewayを利用することで、LLMを「組織の管理対象」とすることができ、使用量監視、レート制限、推論ログ、権限制御を実施できます。
参考になりましたら幸いです。










