
Datadog のログアーカイブとリハイドレーションを試してみた
Datadog のログアーカイブとリハイドレーションについて
Datadog のログ関連の料金として、取り込み料金とインデックス化料金が存在します。
インデックス化しないと Log Explorer での検索ができないため、取り込んだログをすべてインデックス化しているケースも多いのでは無いでしょうか?
ただし、インデックス化料金は取り込み料金と比較して高価なため、ログ周りの料金を最適化するのであればこちらを削減したい所です。
※ 2025 年 11 月 8 日時点の、AP1 におけるオンデマンド料金は下記になります。
| 項目 | 料金 |
|---|---|
| 取り込み | 0.13 USD/GB |
| インデックス化 (3 日間保持) | 1.33 USD/100 万ログイベント |
| インデックス化 (7 日間保持) | 1.59 USD/100 万ログイベント |
| インデックス化 (15 日間保持) | 2.13 USD/100 万ログイベント |
| インデックス化 (30 日間保持) | 3.13 USD/100 万ログイベント |
インデックス化料金を削減する際、優先度の低いログは一旦アーカイブして必要に応じてリハイドレーション (再取り込み) する手法が便利です。
各操作に関する補足
取り込み(ingest): ログを Datadog に取り込むこと。取り込んだログの総量(GB)に対して課金。
インデックス化(indexing): ログを検索・分析できるようにすること。インデックス化したログのイベント数に対して課金。
アーカイブ: S3 等の外部ストレージへエクスポートすること。ストレージ側の費用が発生。
リハイドレーション: アーカイブから一時的に戻して検索可能にする操作。再取り込み+再インデックス化相当の課金が発生。
やってみる
Datadog へのログ連携
今回は CloudWatch Logs でサブスクリプションフィルターを設定して Lambda 経由で Datadog に連携します。
こちらの設定については下記ブログもご参照下さい。
アーカイブ設定
アーカイブ先の S3 を作成します。
Datadog と AWS の連携用ロールに権限を付与するので、バケットポリシーの設定は不要です。
一方で DatadogIntegrationRole に下記権限の付与が必要になります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatadogUploadAndRehydrateLogArchives",
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:GetObject"],
"Resource": ["arn:aws:s3:::<BUCKET_NAME>/*"]
},
{
"Sid": "DatadogRehydrateLogArchivesListBucket",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": ["arn:aws:s3:::<BUCKET_NAME>"]
}
]
}
Logs > Configuration > ROUTING > Archiving & Forwarding からアーカイブを作成します。
この際、host や source などの条件を使って絞り込みを行うことができます。
今回はアーカイブするログの条件を host を利用して指定します。
CloudWatch ログとサブスクリプションフィルターを利用している場合、host はロググループ名になっています。
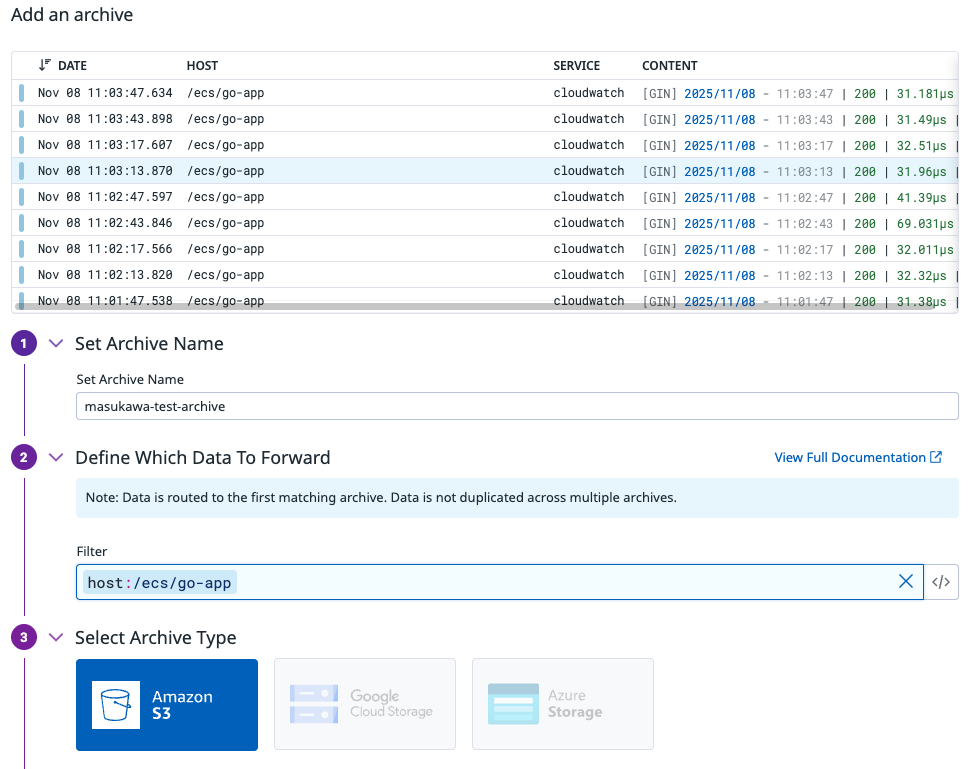
作成した S3 バケットを指定します。
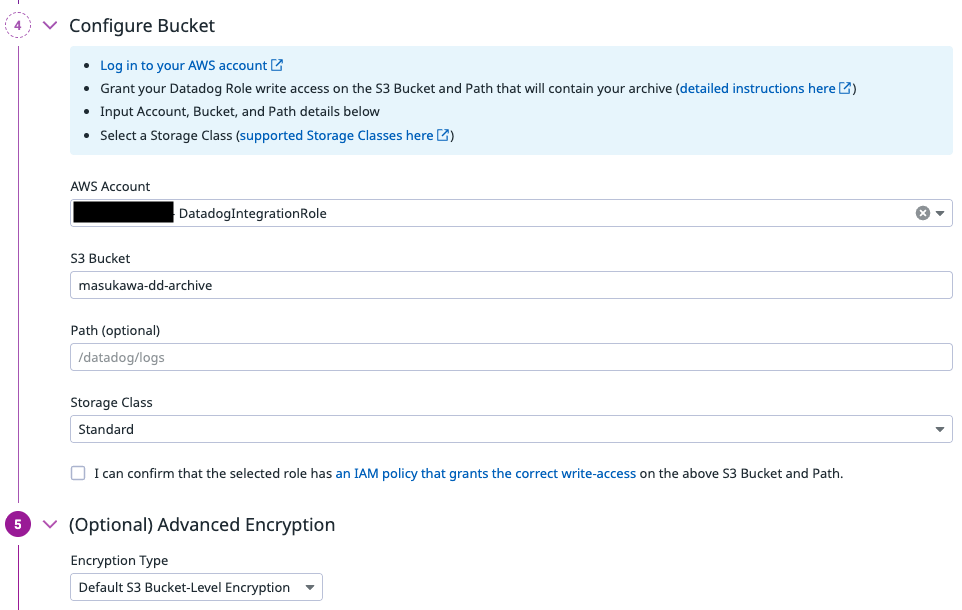
暗号化レベルは S3 バケットの設定に準じる設定とします。
「Tags in your Archive」を有効化すると最初の取り込み時に付与されていたタグをアーカイブ時に保持でき、今回はチェックを入れておきます。
「Test Configuration」をクリックすることで、権限に問題が無いかをこの段階でチェック可能です(permission_testing/ 配下にテスト用のファイルを配置して確認します)。
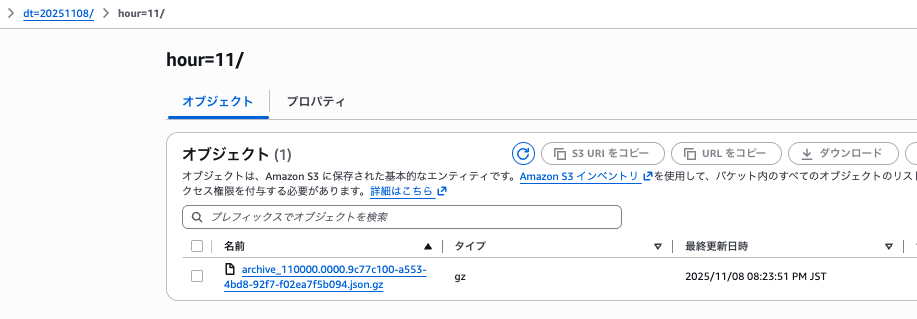
設定が完了すると、アーカイブされたログが指定したバケットにパーティションを切って GZIP 形式で配信されます。
exclusion filter の設定
これだけだとアーカイブと並行してインデックス化もされ続けてしまうので、コストを抑えるために exclusion filter を設定します。
Logs > Configuration > ROUTING > Indexes から現在利用しているインデックスを選択して Add an Exclusion Filter をクリックします。
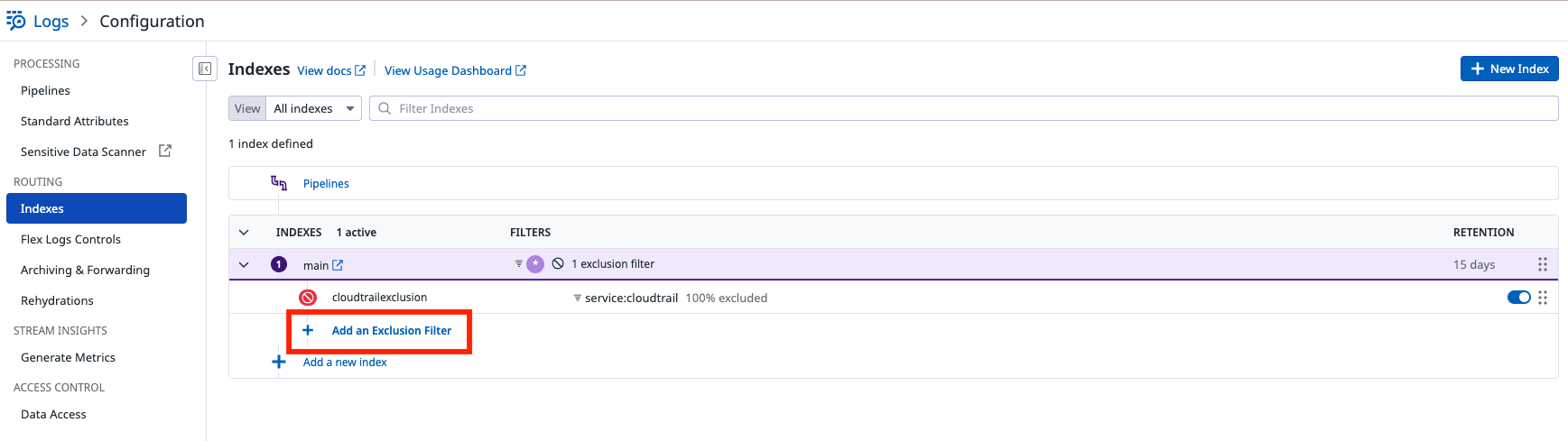
インデックスしないための条件を付与して「Add Exclusion Filter」をクリックします。
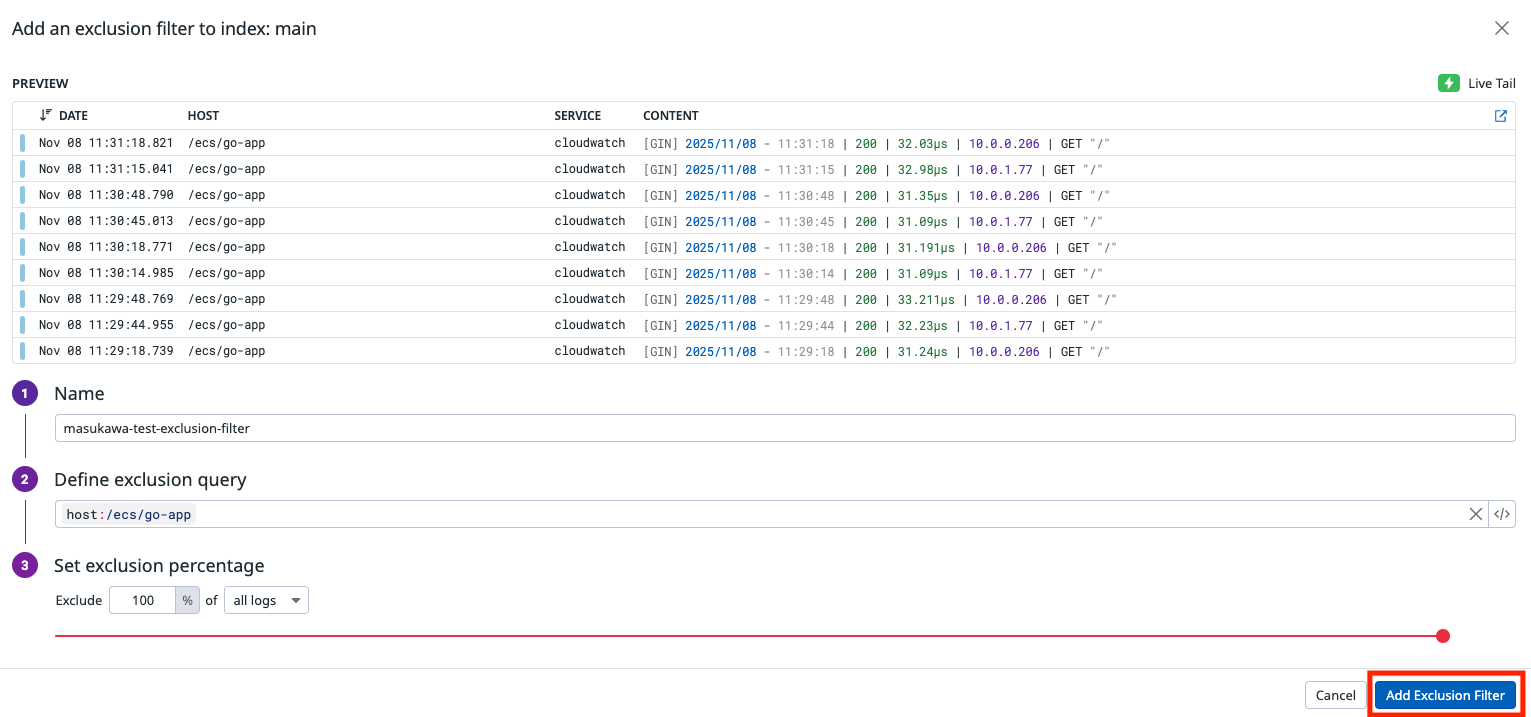
今回はアーカイブする条件と合わせて host 条件を指定しました。
設定が完了すると新規ログについて Log Explorer で検索できなくなります。
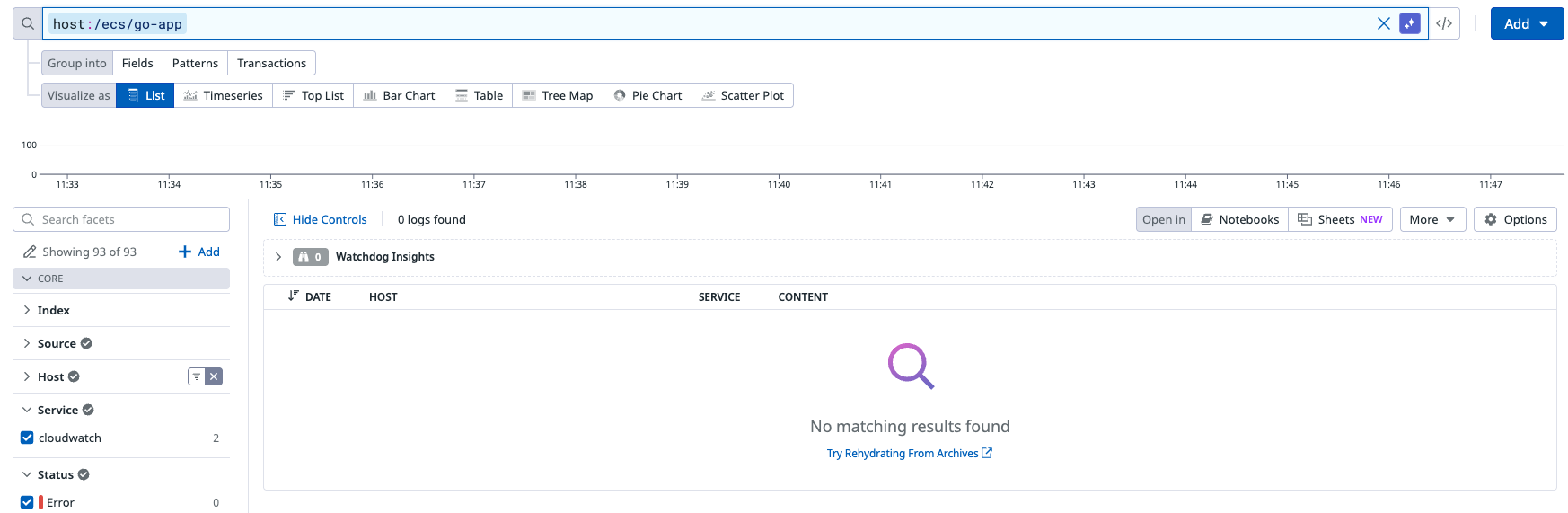
リハイドレーションの実行
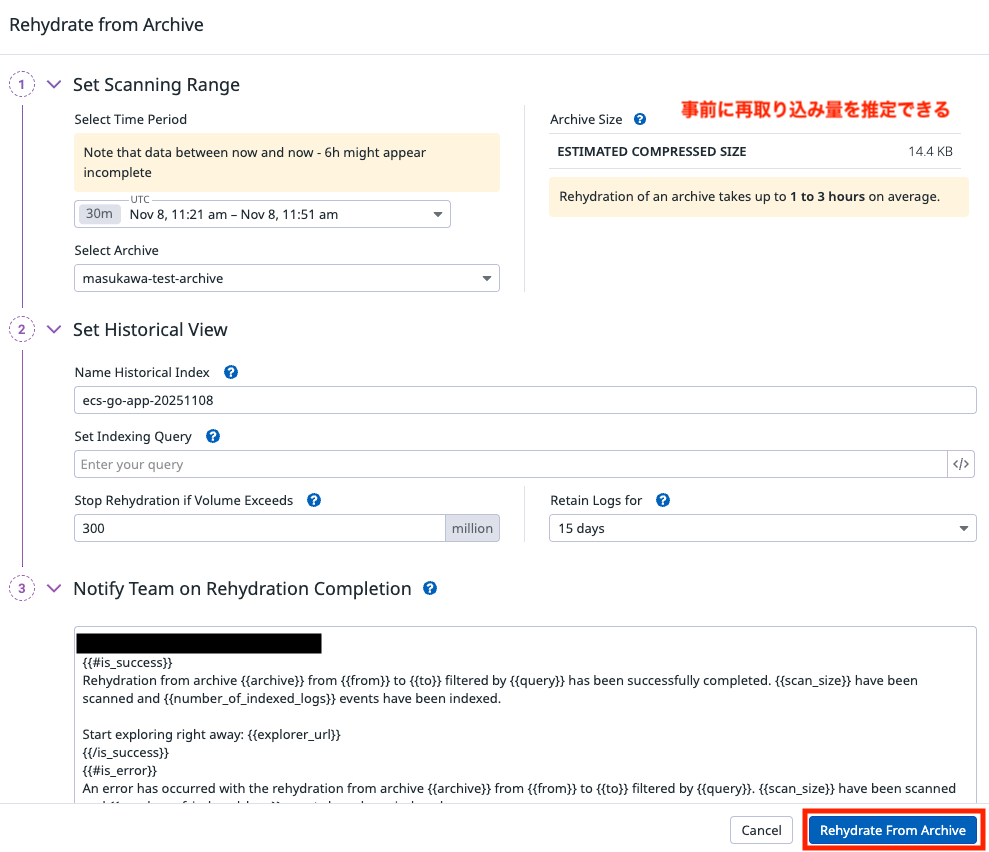
リハイドレーションは Logs > Configuration > ROUTING > Rehydrationsから実行します。
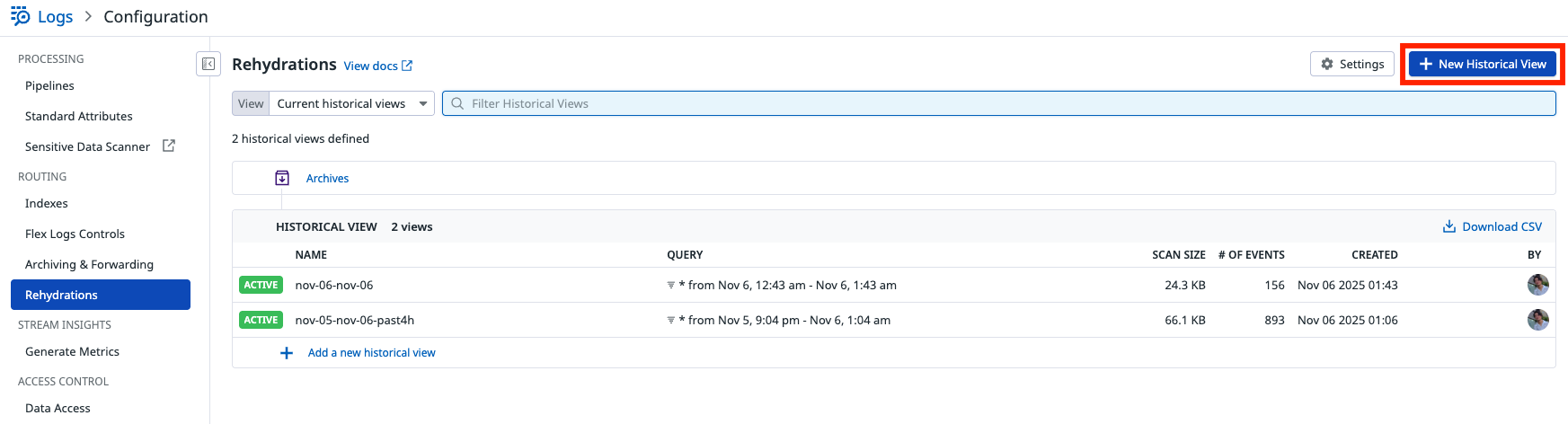
どの時間帯のログを取り込むかを最初に指定する必要があるので、 今回は直近 30 分を対象にします。
この際、「Estimate」をクリックすることで取り込み対象のログサイズを確認可能です。
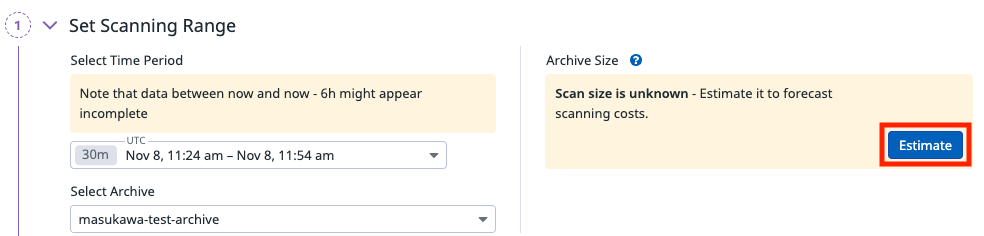
今回は 14.4KB と出ました。
この値を元に再取り込みにかかる料金を試算できます。
普通にログを取り込む際と同じですが、取り込み料金と合わせてインデックス化料金も発生するので注意が必要です。
こちらの料金が気になる場合は 「Set Indexing Query」でインデックス化対象を絞り込むと良いでしょう。
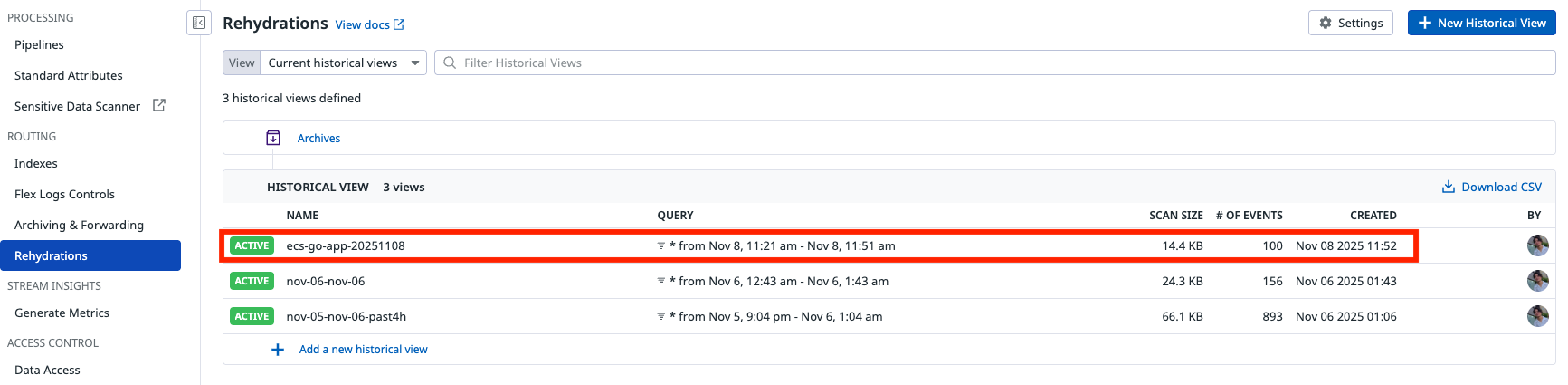
しばらくしてステータスが「ACTIVE」になると完了です。
今回はログの量が少なかったので数分で完了しました。
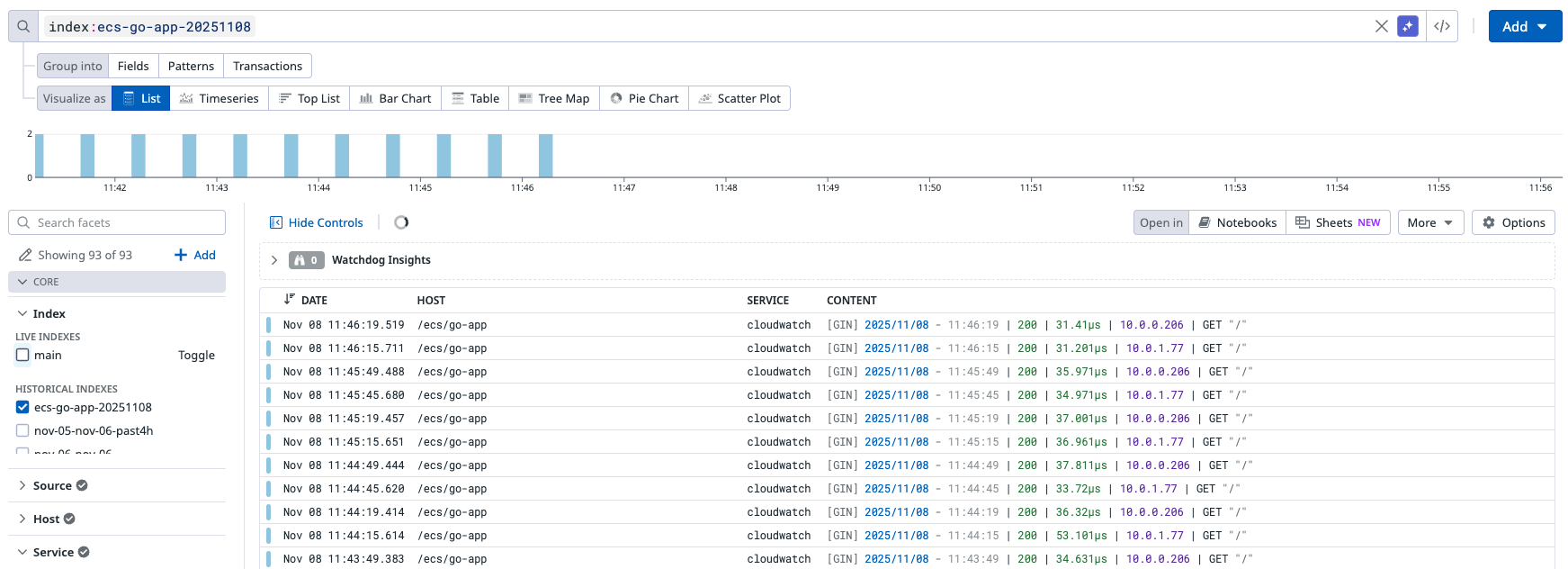
Log Explorer に戻って HISTORICAL INDEXES からリハイドレーション名を選択すると、無事再取り込みしたログを確認できました!
(補足) 「Tags in your Archive」 設定について
アーカイブする際に Datadog のタグを合わせて保存するかどうかを制御します。
タグも含めてアーカイブしておけば、リハイドレーション時に以前付与されていたタグも含めて復元可能です。
アーカイブ時にタグも含めて保存することでかかるストレージ料金が気になる場合は無効化すると良いです。
今回はこちらの機能をオフにすることで下記タグが利用できなくなりました。
- datadog.api_key_uuid
- datadog.submission_auth
- forwarder_memorysize
- forwarder_version
- forwarder_name
逆に下記は再取り込み時にも自動で付与されました。
- datadog.index
- source (=cloudwatch)
- service (=cloudwatch)
S3 のストレージ料金がよほど気になる場合でなければデフォルト設定の有効化で良い気と思いますが、今回のケースでは別にフォワーダーや API キーの情報が無くなっても困らない気がしますね。
アーカイブ前に付与されているタグや自動で付与されるタグの種類を元に有効化するかを検討すると良いでしょう。
まとめ
Datadog のログ周りの料金は、取り込みとインデックス化で別れていたり、一部ログはインデックス化しないでアーカイブすることも可能なことなど、若干複雑に感じる部分もあります。
ただ、この柔軟性を上手く活用できるとコストを抑えて Datadog を利用できます。
コストが気になる方やログを長期で保存したい方は是非試してみて下さい!









