
Datadog User 一覧を作成する
1. はじめに
こんにちは。クラスメソッドオペレーションズのあのふじたです。
最近、Datadogユーザーの棚卸を行う機会があり、一覧を作成したので備忘録として記事を書こうと思います。
2. Datadogコンソールでのユーザー一覧の確認
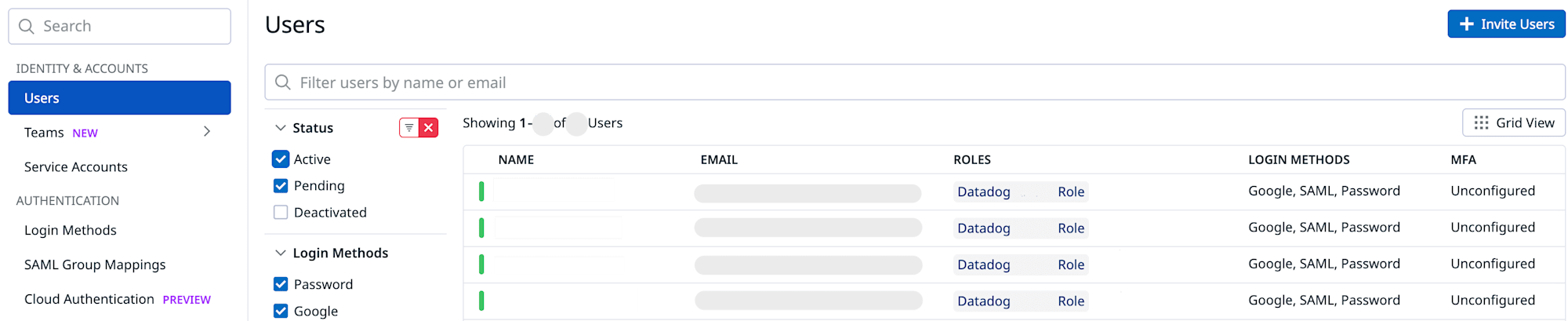
このような一覧が確認できます(organization-settings/users)。
今回の棚卸に必要そうな項目は以下でした。
- 名前
- 登録メールアドレス
- 現在のステータス
- ユーザ作成日時
- 最終ログイン日時
- 付与されているRole
残念ながらコンソールからはユーザー作成日時と最終ログイン日時をまとめてエクスポートできないようです。
API経由での取得を検討することになりました。
3. 利用するDatadog APIと公式リファレンスURL
List all users
必要な権限 user_access_read
"data": [
{
"type": "users",
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”,
"attributes": {
"uuid": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”,
"name": "",
"handle": "xxxxxx@xxxxxx.xxx”,
"created_at": "2020-01-23T12:34:56.789012+00:00",
"modified_at": "2025-01-23T12:34:56.789012+00:00",
"email": "xxxxxx@xxxxxx.xxx",
"icon": "",
"title": "",
"verified": true,
"service_account": false,
"disabled": false,
"allowed_login_methods": [
"google_oidc",
"standard"
],
"status": "Active",
"mfa_enabled": true,
"last_login_time": null
},
"relationships": {
"roles": {
"data": [
{
"type": "roles",
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”
}
]
},
"org": {
"data": {
"type": "orgs",
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”
}
}
}
},
- 名前 (name)
- ユーザ作成日時(created_at)
- 登録メールアドレス (email)
- 現在のステータス(status)
- 最終ログイン日時(last_login_time)
Role については id のみが保持されており、コンソールで確認できる Datadog XXXX Roles はこれだけでは取得できなさそうです。
List roles
必要な権限 user_access_read
{
"data": [
{
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"type": "roles",
"attributes": {
"created_at": "2020-01-23T01:23:45.678901Z",
"managed": true,
"modified_at": "2025-01-23T01:23:45.678901Z",
"name": "Datadog Admin Role",
"team_count": 0,
"user_count": XX
},
"relationships": {
"permissions": {
"data": [
{
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"type": "permissions"
},
{
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"type": "permissions"
},
{
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"type": "permissions"
},
...
...
...
- id と attributes.name を先ほどの List all users と紐付けると ユーザー名とRole名が取得できそうです。
4. 実装ステップ
具体的には、以下のステップで進めていきます。
- API利用に必要な権限付のDatadog Application Keyの作成
- Users一覧, Roles一覧を取得
- Users一覧のid と Roles一覧のid を紐づけて必要な項目の一覧を作成
- csvファイルで保存。
- 最後に見やすいように markdown の表を表示しながら.mdファイルにも保存。
必要なパッケージのインストール(動作確認した環境のみ)
jq Install
MacOS: brew install jq
Amzn2023: yum install jq
DuckDB Install
MacOS/Amzn2023: curl https://install.duckdb.org | sh
5. 完成したScript
以下のようになりました。
今回はAPIキーとアプリケーションキーをScript内で定義しています。
実際に利用する際は環境変数から読み込むか、.envファイル等で管理し、なるべくスクリプトに直書きしない方が安全です。
またこのスクリプトを実行するには、Datadogでuser_access_read権限を持つApplication Keyが必要です。
権限不足の場合はエラーが返されます。
#!/bin/bash
DD_API_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx”
DD_APP_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx”
# ==================================================
# 設定: 外部ファイルパス
# ==================================================
SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
OUTPUT_FILE="${SCRIPT_DIR}/dd-users_$(date -Idate).csv"
# ===== ユーザー一覧取得 =====
echo "=== Fetching users ==="
PAGE=0
PAGE_SIZE=100
ALL_USERS="[]"
while true; do
RESPONSE=$(curl -s -X GET "https://api.datadoghq.com/api/v2/users?page%5Bsize%5D=${PAGE_SIZE}&page%5Bnumber%5D=${PAGE}" \
-H "Accept: application/json" \
-H "DD-API-KEY: ${DD_API_KEY}" \
-H "DD-APPLICATION-KEY: ${DD_APP_KEY}")
USERS=$(echo "$RESPONSE" | jq -r '.data')
if [ -z "$USERS" ] || [ "$USERS" = "null" ]; then
echo "No data returned at page ${PAGE}"
break
fi
COUNT=$(echo "$USERS" | jq -r 'length')
if ! [[ "$COUNT" =~ ^[0-9]+$ ]] || [ "$COUNT" -eq 0 ]; then
echo "No more users at page ${PAGE}"
break
fi
echo "Page ${PAGE}: ${COUNT} users fetched"
ALL_USERS=$(echo "$ALL_USERS" "$USERS" | jq -s '.[0] + .[1]')
if [ "$COUNT" -lt "$PAGE_SIZE" ]; then
break
fi
PAGE=$((PAGE + 1))
done
echo "Total users: $(echo "$ALL_USERS" | jq 'length')"
echo "$ALL_USERS" | jq '.' > all_users.json
echo "Saved to all_users.json"
# ===== ロール一覧取得 =====
echo ""
echo "=== Fetching roles ==="
ROLES_RESPONSE=$(curl -s -X GET "https://api.datadoghq.com/api/v2/roles" \
-H "Accept: application/json" \
-H "DD-API-KEY: ${DD_API_KEY}" \
-H "DD-APPLICATION-KEY: ${DD_APP_KEY}")
echo "$ROLES_RESPONSE" | jq '.data' > roles_data.json
echo "Roles count: $(jq 'length' roles_data.json)"
echo "Saved to roles_data.json"
# ===== DuckDB で CSV & Markdown 出力 =====
echo ""
echo "=== Generating CSV and Markdown ==="
QUERY="
WITH users_raw AS (
SELECT
attributes->>'name' AS name,
attributes->>'email' AS email,
attributes->>'status' AS status,
attributes->>'created_at' AS created_at,
attributes->>'last_login_time' AS last_login_time,
relationships->'roles'->'data' AS role_data
FROM read_json_auto('all_users.json')
),
users_unnested AS (
SELECT
u.name,
u.email,
u.status,
u.created_at,
u.last_login_time,
unnest(from_json(u.role_data, '[\"json\"]')) AS role_entry
FROM users_raw u
WHERE json_array_length(u.role_data) > 0
UNION ALL
SELECT
u.name,
u.email,
u.status,
u.created_at,
u.last_login_time,
NULL AS role_entry
FROM users_raw u
WHERE json_array_length(u.role_data) = 0 OR u.role_data IS NULL
),
user_role_ids AS (
SELECT
name,
email,
status,
created_at,
last_login_time,
json_extract_string(role_entry, '\$.id') AS role_id
FROM users_unnested
),
roles AS (
SELECT
id,
attributes->>'name' AS role_name
FROM read_json_auto('roles_data.json')
)
SELECT
ur.name,
ur.email,
ur.status,
ur.created_at,
ur.last_login_time,
string_agg(r.role_name, ', ') AS roles
FROM user_role_ids ur
LEFT JOIN roles r ON ur.role_id = r.id
GROUP BY ur.name, ur.email, ur.status, ur.created_at, ur.last_login_time
ORDER BY
CASE ur.status WHEN 'Active' THEN 1 WHEN 'Pending' THEN 2 ELSE 3 END,
ur.email;
"
# CSV 出力
echo "$QUERY" | duckdb -csv > "$OUTPUT_FILE"
echo "CSV saved to ${OUTPUT_FILE}"
echo "Total rows: $(tail -n +2 "$OUTPUT_FILE" | wc -l)"
# Markdown 表を標準出力 & .md ファイルに保存
echo ""
echo "=== Result (Markdown) ==="
echo ""
echo "$QUERY" | duckdb -markdown | tee "${OUTPUT_FILE%.csv}.md"
echo ""
echo "Markdown saved to ${OUTPUT_FILE%.csv}.md"
echo "Done!"
実行イメージ
=== Fetching users ===
Page 0: 100 users fetched
Page 1: 100 users fetched
Page 2: 100 users fetched
Page 3: 1 users fetched
Total users: 301
Saved to all_users.json
=== Fetching roles ===
Roles count: 3
Saved to roles_data.json
=== Generating CSV and Markdown ===
CSV saved to /Users/user/dd-users_2026-05-15.csv
Total rows: 309
| name | email | status | created_at | last_login_time | roles |
|---------------------------------|---------------------------------------|----------|----------------------------|-------------------------|------------------------|
| dd-user_1 | user_1@xxxxx.xxxx | Active | 2020-01-23 01:23:45.678901 | 2025-05-01 01:23:45.678 | Datadog Admin Role |
| dd-user_2 | user_2@xxxxx.xxxx | Active | 2020-01-23 01:23:45.678901 | 2025-05-01 01:23:45.678 | Datadog Admin Role |
| dd-user_3 | user_3@xxxxx.xxxx | Active | 2020-01-23 01:23:45.678901 | 2024-04-23 01:23:45.678 | Datadog Standard Role |
| dd-user_4 | user_4@xxxxx.xxxx | Pending | 2020-01-23 01:23:45.678901 | NULL | Datadog Standard Role |
| dd-user_5 | user_5@xxxxx.xxxx | Disabled | 2020-01-23 01:23:45.678901 | 2020-01-23 01:23:45.678 | Datadog Standard Role |
...
...
...
Markdown saved to /Users/username/dd-users_2026-05-15.csv.md
Done!
最後に
Datadog は現状ユーザー削除ではなく無効化までしかできないので長く使っているとユーザー数がどんどん増えてしまいますよね。
時々、無効化漏れのユーザーがいないか確認することもあるかもしれません。
このブログがどなたかの役に立てば幸いです。
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AIをフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイト をぜひご覧ください。※2026年1月 アノテーション㈱から社名変更しました。









