
スマホ動画から DGX Spark の 3D デジタルツインを作ってみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
「デジタルツイン」と聞くと、製造業の大規模工場やスマートシティの話を思い浮かべる方が多いのではないでしょうか。NVIDIA Omniverse、OpenUSD、3D シミュレーション......。どれも面白そうだけど、個人が試すにはどこから手をつければいいのかわかりにくいですよね。
自分もそう思っていたのですが、「スマホで撮影した動画を 3D に変換する」ところからなら、個人でも始められるのではないかと考えて、手元の DGX Spark で試してみました。使ったのは 3D Gaussian Splatting(3DGS)という技術です。結論から言うと、30 秒のスマホ動画から DGX Spark 本体の 3D モデルをそれなりの品質で作ることができました。
3D Gaussian Splatting とデジタルツイン
デジタルツインは「現実の空間やモノをデジタルに再現し、シミュレーションや可視化に使う技術」です。工場のラインを仮想空間に再現して稼働シミュレーションを行ったり、建物の 3D モデルを使って設備配置を検討したりする用途で使われています。
その入口として今回注目したのが 3D Gaussian Splatting(3DGS)です。2023 年に発表された手法で、複数の視点から撮影した画像群をもとに、シーンを数百万個の「ガウシアン」(楕円体状の 3D 正規分布)で表現します。NeRF(Neural Radiance Fields)と同じく新規視点からの画像を生成できますが、3DGS はラスタライズベースなのでレンダリングが高速という特徴があります。
NVIDIA は Omniverse と OpenUSD を軸にデジタルツインのエコシステムを構築しています。GTC 2026 では Physical AI の文脈で Cosmos 3 世界基盤モデルや OpenUSD ベースのシミュレーション環境が発表されました。3DGS で現実空間をキャプチャし、OpenUSD 形式に変換して Omniverse のワークフローに乗せる......という流れは、個人がデジタルツインに触れる現実的なパスの一つになるのではないかと感じています。
ただし、ARM64 環境(DGX Spark)では一部のツールが非対応だったり、回避策が必要だったりと、まだ制約もあります。今回はまず「スマホ撮影 → 3D 再構築」のステップに集中し、その先の活用パスについても検討してみました。
使用環境
今回の検証で使用した環境です。
| 項目 | スペック |
|---|---|
| ハードウェア | NVIDIA DGX Spark(GB10, 統合メモリ 128GB) |
| OS | DGX OS(Ubuntu 24.04 ベース) |
| CUDA | 13.0 / Driver 580.142 |
| GPU Compute Capability | 12.1(SM121) |
| Python | 3.12 |
| PyTorch | 2.9.0+cu130 |
| Nerfstudio | 1.1.5 |
| gsplat | 1.5.3(JIT ビルド) |
| COLMAP | 3.9.1(apt, CPU 版) |
| Blender | 4.0.2(apt) |
GB10 には RT コア(レイトレーシング専用コア)が搭載されていないため、Omniverse のリアルタイムパストレーシングなどは利用できません。この記事ではラスタライズベースのレンダリングで進めています。
DGX Spark(ARM64)での環境構築
ここが今回一番ハマったポイントです。DGX Spark は ARM64(aarch64)アーキテクチャなので、x86 向けに配布されている prebuilt wheel がそのまま使えないケースが多く、いくつかの回避策が必要でした。
PyTorch と gsplat のインストール
PyTorch は CUDA 13.0 対応の cu130 wheel が ARM64 向けにも提供されています。uv でインストールしました。
uv venv --python 3.12 .venv
uv pip install torch==2.9.0 torchvision --index-url https://download.pytorch.org/whl/cu130
gsplat(3DGS のラスタライゼーションカーネル)は ARM64 向けの prebuilt wheel が提供されていないため、JIT コンパイルで対応しました。ポイントは ninja を PATH に含めることと、TORCH_CUDA_ARCH_LIST の指定です。
uv pip install gsplat packaging ninja
export PATH="$PWD/.venv/bin:$PATH"
export TORCH_CUDA_ARCH_LIST="12.0"
gsplat の初回実行時に CUDA カーネルが JIT コンパイルされ、約 34 秒でビルドが完了しました。SM121(GB10)は SM120 と binary compatible なので、TORCH_CUDA_ARCH_LIST="12.0" の指定で動作します。
Nerfstudio のインストール
Nerfstudio はそのまま uv pip install nerfstudio するといくつかの依存で引っかかります。--no-deps でインストールしてから、依存を個別に追加する形で回避しました。
uv pip install av
uv pip install nerfstudio --no-deps
uv pip install opencv-python-headless scipy plotly rich scikit-image trimesh plyfile ...
ARM64 環境で引っかかった依存パッケージと対処
| パッケージ | 問題 | 対処 |
|---|---|---|
open3d |
ARM64 wheel なし | try: import でフォールバック(Metashape 用なので COLMAP パスでは不要) |
av (PyAV) |
古いバージョンのソースビルドが Cython エラー | 先に uv pip install av で新しい wheel を入れる |
rawpy / newrawpy |
numpy ABI 不一致 | numpy<2 にダウングレード |
pymeshlab |
ARM64 / aarch64 で除外指定 | パッチで回避(メッシュエクスポートに影響) |
usd-core |
ARM64 wheel なし | usd-exchange で代替可能(後述) |
open3d と pymeshlab については、Nerfstudio のソースコード内のインポート箇所を try/except でラップするパッチも必要でした。具体的には nerfstudio/process_data/metashape_utils.py と nerfstudio/scripts/exporter.py の import open3d を修正しています。
COLMAP
COLMAP は apt install colmap で入ります。ただし、GPU 版の SIFT 抽出は OpenGL コンテキストが必要で、ヘッドレス環境では動作しません。CPU 版(--SiftExtraction.use_gpu 0)にフォールバックしました。50〜200 枚程度のフレーム数であれば CPU 版でも数分で完了するので、実用上は問題ありませんでした。
スマホで撮影して 3D 再構築する
撮影のコツ
被写体には DGX Spark 本体を選びました。「DGX Spark で DGX Spark の 3D ツインを作る」というちょっとメタな構図です。
iPhone で水平方向に一周、やや上方から一周の 2 本の動画を撮影しました。

1080p / 30fps での撮影です。
フレーム抽出と COLMAP
2 本の動画を ffmpeg で結合し、フレームを抽出しました。
# 動画結合
ffmpeg -i side.mov -i upper.mov \
-filter_complex "[0:v][1:v]concat=n=2:v=1:a=0[outv]" \
-map "[outv]" -c:v libx264 -crf 18 combined.mp4
# フレーム抽出(8fps)
ffmpeg -i combined.mp4 -vf "fps=8" -pix_fmt rgb24 -q:v 2 images/frame_%05d.jpg
当初 3fps(87 枚)で抽出したところ、COLMAP で 43/87 枚しか登録されませんでした。8fps(232 枚)に上げたところ、隣接フレーム間のオーバーラップが増えて 115/232 枚まで登録率が向上しました。動きの速い動画ではフレーム抽出レートを高めに設定するのがよさそうです。
COLMAP のパイプラインは特徴点抽出 → マッチング → 疎な 3D 再構築の 3 ステップです。
export QT_QPA_PLATFORM=offscreen
# 1. 特徴点抽出(CPU)
colmap feature_extractor \
--database_path colmap/database.db \
--image_path images \
--ImageReader.single_camera 1 \
--ImageReader.camera_model OPENCV \
--SiftExtraction.use_gpu 0
# 2. マッチング(sequential: 動画向き)
colmap sequential_matcher \
--database_path colmap/database.db \
--SiftMatching.use_gpu 0 \
--SequentialMatching.overlap 20
# 3. 疎な 3D 再構築
colmap mapper \
--database_path colmap/database.db \
--image_path images \
--output_path colmap/sparse
ヘッドレス環境では QT_QPA_PLATFORM=offscreen の設定が必要です。GPU 版を使おうとすると OpenGL コンテキストの作成に失敗して SIGABRT で落ちます。
232 枚の処理で、特徴抽出に約 20 秒、マッチングに約 2.5 分、再構築に約 1.5 分。合計 4〜5 分程度でした。
3DGS 学習
Nerfstudio の ns-train コマンドで splatfacto を学習します。
export TORCH_CUDA_ARCH_LIST="12.0"
export QT_QPA_PLATFORM=offscreen
echo "y" | ns-train splatfacto \
--data data/dgx-spark/processed \
--output-dir outputs/ \
--max-num-iterations 30000 \
--viewer.quit-on-train-completion True \
colmap \
--colmap-path colmap/sparse/1 \
--downscale-factor 1
COLMAP が複数のサブモデルを生成した場合は、登録枚数が最も多いモデルを --colmap-path で指定します。今回は 4 つのサブモデルが生成され、115 枚が登録されたモデル 1 を使いました。
フル解像度(1920x1080)、30,000 ステップの学習で約 45 分かかりました。半分の解像度(downscale-factor 2)だと 5 分程度で完了するので、まずは低解像度で全体の流れを確認してから本番を回すのが効率的です。
| 設定 | 低解像度 | フル解像度 |
|---|---|---|
| 解像度 | 960x540 | 1920x1080 |
| ステップ数 | 15,000 | 30,000 |
| 学習時間 | 約 5 分 | 約 45 分 |
| ステップ時間 | ~21 ms/step | ~90 ms/step |
結果の確認
Nerfstudio ビューア
学習済みモデルは Nerfstudio の Web ビューアでインタラクティブに確認できます。
export TORCHDYNAMO_DISABLE=1
ns-viewer --load-config outputs/.../config.yml
ブラウザで http://localhost:7007 にアクセスすると、3DGS のレンダリング結果をマウスでぐりぐり回しながら確認できます。左パネルの Max Resolution を上げるとより精細な表示になります。
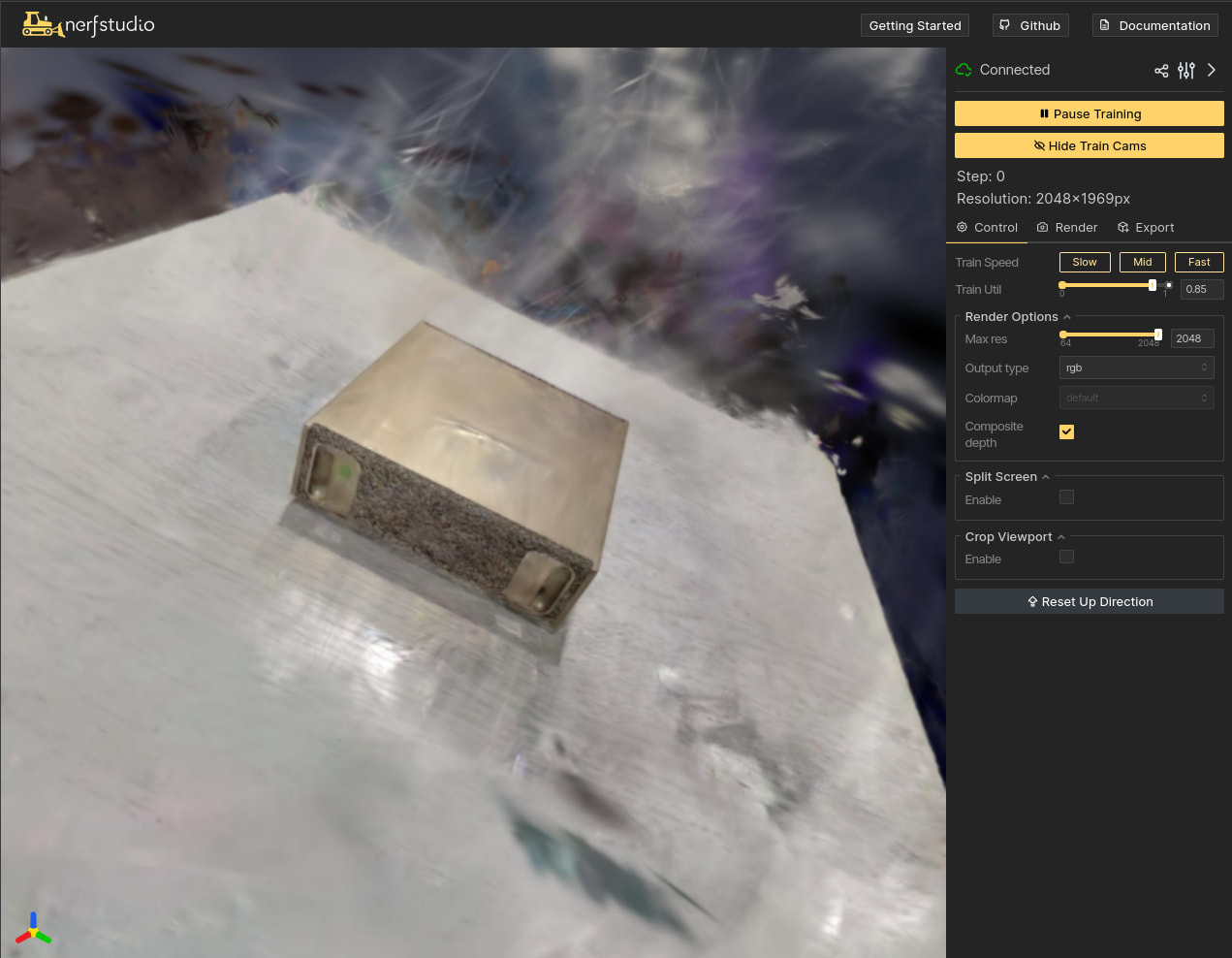
まるで指輪物語の闇の世界!?
フル解像度で学習したモデルでは、DGX Spark 前面のポート類や、NVIDIA ロゴまでうっすら確認できるレベルの品質が得られました。テーブルのテクスチャもよく再現されています。
ラフな撮影でもここまでの品質が出るので、ゆっくり丁寧に撮影すればもっと鮮明な結果が得られるはずです。
点群データの取り出し
3DGS モデルのガウシアンは PLY 形式の点群として取り出せます。チェックポイントから直接抽出するスクリプトを書きました。
import torch
import numpy as np
from plyfile import PlyData, PlyElement
state = torch.load('step-000029999.ckpt', map_location='cpu', weights_only=False)
p = state['pipeline']
means = p['_model.gauss_params.means'].numpy()
features_dc = p['_model.gauss_params.features_dc'].numpy()
# SH0 → RGB 変換
C0 = 0.28209479177387814
colors = np.clip(features_dc * C0 + 0.5, 0, 1)
# PLY エクスポート
vertices = np.zeros(len(means), dtype=[
('x','f4'), ('y','f4'), ('z','f4'),
('red','u1'), ('green','u1'), ('blue','u1')
])
vertices['x'], vertices['y'], vertices['z'] = means[:,0], means[:,1], means[:,2]
vertices['red'] = (colors[:,0] * 255).astype(np.uint8)
vertices['green'] = (colors[:,1] * 255).astype(np.uint8)
vertices['blue'] = (colors[:,2] * 255).astype(np.uint8)
PlyData([PlyElement.describe(vertices, 'vertex')], text=False).write('output.ply')
211,961 個のガウシアンが PLY ファイルとして出力されます。Blender で読み込んで Geometry Nodes で球体をインスタンス配置すれば、カラー付きの点群レンダリングも可能です。Nerfstudio のビューアと比べると粗い表示ですが、3D 空間にどのようにガウシアンが分布しているかを俯瞰できるので、デバッグや記事の素材としては役立ちました。

PLY → USD 変換
当初、OpenUSD の Python バインディング usd-core が ARM64 非対応のため USD 変換は断念していたのですが、NVIDIA が公式に提供する usd-exchange パッケージが ARM64 に対応していることがわかりました。
uv pip install usd-exchange
これで pxr API が使えるようになります。PLY 点群を USD 形式に変換するスクリプトを書いてみました。
from pxr import Usd, UsdGeom, Vt
from plyfile import PlyData
ply = PlyData.read('dgx_spark_3dgs_50k.ply')
v = ply['vertex']
stage = Usd.Stage.CreateNew('dgx_spark_3dgs.usda')
UsdGeom.SetStageUpAxis(stage, UsdGeom.Tokens.y)
points = UsdGeom.Points.Define(stage, '/DGXSpark/PointCloud')
positions = [(float(v['x'][i]), float(v['y'][i]), float(v['z'][i])) for i in range(len(v))]
points.GetPointsAttr().Set(Vt.Vec3fArray(positions))
colors = [(v['red'][i]/255.0, v['green'][i]/255.0, v['blue'][i]/255.0) for i in range(len(v))]
points.GetDisplayColorAttr().Set(Vt.Vec3fArray(colors))
stage.GetRootLayer().Save()
50,000 点のカラー付き点群が USD ファイル(3.6 MB)として出力されました。DGX Spark 上で 3DGS → PLY → USD という変換パイプラインが完結するのはいいですね。
同様に pymeshlab も ARM64 向け wheel(2025.7.post1)が提供されており、uv pip install pymeshlab でインストールできました。PLY の読み込みや法線計算は動作しますが、Poisson Surface Reconstruction によるメッシュ化は今回の点群では安定しませんでした。3DGS のガウシアンは「レンダリング品質の最適化」で配置されるため、表面に均一に並ぶわけではなく、従来のフォトグラメトリ点群とは性質が異なります。撮影品質の向上と外れ値の削減がメッシュ化の前提になりそうです。
この先に広がる活用パス
3DGS で 3D モデルができたところで、「これをどう使うか」についても考えてみました。
今回実際に試したのは VLM による分析です。v3 のレンダリング画像を Qwen2.5-VL(7B)に渡してみたところ、ポートが見えるアングルの画像では「コンピューターやネットワークデバイス」「下部にポートやスロットが見える」と、用途まで推測した回答が返ってきました。
この 3D レンダリング画像には、おそらくコンピューターやネットワークデバイスの一部である製品が描かれています。上部は光沢のある表面で、全体的にシンプルなデザインです。下部には、いくつかのポートやスロットが見えます。
一方、上部からのアングルでは「淡いベージュ色の立方体」としか認識されませんでした。3DGS の強みは任意の視点からレンダリングできる点にあるので、さまざまなアングルの画像を VLM に渡して「死角のない分析」を行うといった活用が面白そうです。
VLM 分析以外にも、いくつかの展開が見えてきました。一つは Isaac Sim との連携です。以前の記事で SO-ARM101 ロボットアームを Isaac Sim 上で動かしましたが、そのシーンの背景を 3DGS でキャプチャした実空間に置き換えれば、「自分のデスクの上でロボットをシミュレーションする」というデジタルツインらしい使い方ができます。もう一つは Omniverse と OpenUSD エコシステムへの統合です。実はこの方向は既に動き出していて、2026 年 3 月公開の OpenUSD v26.03 では 3DGS が UsdVolParticleField3DGaussianSplat スキーマとして正式にサポートされました。NVIDIA も Omniverse NuRec として 3DGS レンダリングを Omniverse 内で扱えるライブラリを提供しています。今回 usd-exchange で PLY → USD 変換が動いたので、「スマホ撮影 → 3DGS → USD」のパイプラインは DGX Spark 上で既に実現できています。OpenUSD 側の 3DGS サポートが進んでいる今、この流れは加速しそうですね。
Isaac Sim へのインポートにはメッシュ化が必要ですが、3DGS 点群の性質上、きれいなメッシュを得るには撮影品質の改善が前提になります。今回はラフな撮影だったこともあり、メッシュ化は断念しました。pymeshlab(ARM64 対応済み)や open3d(conda-forge 版)といったツールは揃っているので、丁寧に撮影し直せば改善の余地はありそうです。
ARM64 環境の制約まとめ
DGX Spark での検証を通じて見えてきた ARM64 環境の制約をまとめます。
| カテゴリ | 制約 | 影響 | 回避策 |
|---|---|---|---|
| 3DGS 学習 | gsplat の prebuilt wheel なし | JIT コンパイルで対応(初回 34 秒) | TORCH_CUDA_ARCH_LIST="12.0" |
| USD | usd-core が ARM64 非対応 |
usd-exchange で解決(pip install で導入可) |
|
| メッシュ処理 | pymeshlab は ARM64 対応済み |
Poisson メッシュ化はパラメータ調整要 | pip install pymeshlab で導入可 |
| 3D 処理 | open3d pip 版が ARM64 非対応 |
一部の点群処理が制限される | conda-forge 版(CPU のみ)or ソースビルド |
| Blender | apt 版は USD 非対応、公式 ARM64 Linux ビルドなし | PLY/OBJ のみ | Geometry Nodes で点群表示は可能 |
| COLMAP | GPU 版が OpenGL 依存 | ヘッドレスで GPU SIFT 使えない | CPU 版で代替(実用上十分) |
| レンダリング | GB10 に RT コアなし | パストレーシング不可 | ラスタライズベースで対応 |
検証を始めた当初は ARM64 の壁が分厚く感じられましたが、調べていくうちに usd-exchange や pymeshlab の ARM64 対応が進んでいることがわかりました。3DGS の学習 → PLY エクスポート → USD 変換までは DGX Spark 単体で完結できる状態です。残る課題はメッシュ化のパラメータチューニングと open3d の GPU 版対応あたりで、NVIDIA が DGX Spark 向けの Playbook やツールチェーンを拡充していく中で、さらに改善されていくことを期待しています。
まとめ
14 秒のスマホ動画 2 本から、DGX Spark の 3D デジタルツインを作成する一連の流れを試しました。
環境構築で ARM64 特有のハマりポイントがいくつかありましたが、gsplat の JIT コンパイルが SM121 で動作することを確認でき、Nerfstudio の splatfacto で 3DGS 学習 → レンダリング → 点群エクスポート → USD 変換まで、DGX Spark 上で完結させることができました。当初は ARM64 の制約で USD 変換は諦めていたのですが、NVIDIA の usd-exchange パッケージのおかげで実現できたのは嬉しい誤算でした。
フル解像度で 30,000 ステップの学習に約 45 分、レンダリングは 142fps。NVIDIA ロゴまでうっすら確認できる品質の 3D モデルが得られたのは、個人レベルのデジタルツイン入門としては十分な結果ではないかと思っています。今回はかなりラフな撮影でしたが、ゆっくり丁寧に撮影したり、スマホ用のジンバルを使ったりすれば、もっと鮮明な 3D モデルが作れるはずです。
過度な期待は禁物ですが、「スマホ 1 台と DGX Spark があれば、3D 再構築から USD 変換まで一通り試せる」という体験は、デジタルツインへの最初の一歩としてなかなか面白いものでした。Isaac Sim でのロボットシミュレーションや Omniverse での共同編集など、この先の展開も楽しみです。









