
NVIDIA Cosmos-Reason2-8B を DGX Spark で PPE 検出向けにファインチューニングしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
NVIDIA の VLM(Vision-Language Model)をそのまま使って画像を分析することはできますが、自社のドメインに特化させたい場合はどうすればよいでしょうか。たとえば工場の安全監視で「ヘルメット未装着」を正確に検出したいとき、汎用モデルでは見落としが多いことがあります。
今回は、Cosmos-Reason2-8B を DGX Spark 上で LoRA ファインチューニングして、PPE(個人用保護具)検出に特化させてみました。300 ステップの学習で、違反検出精度が 46.7% から 90.0% に向上した過程を紹介します。
VSS(Video Search and Summarization)のような映像 AI パイプラインでは、物体検出の後段に VLM を置いて検出結果を視覚的に検証する構成があります。今回はその VLM 部分を自社データで強化する手順にフォーカスしています。
今回のゴール
DGX Spark(128GB 統合メモリ)1 台で、Cosmos-Reason2-8B に PPE 検出の知識を教え込みます。汎用 VLM を自社ドメインに特化させて、違反検出精度がどこまで上がるかを確認するのがゴールです。
やることをざっくりまとめると、こんな流れで進めました。
- SH17 PPE データセット(YOLO 形式)を VLM の学習データに変換する
- TRL + PEFT で LoRA ファインチューニングを実行する
- ベースモデルと比較して精度が上がったか確認する
PPE データセットを VLM 学習データに変換する
SH17 データセット
SH17 は建設現場の PPE 装着状態を 17 クラスでアノテーションしたデータセットです。元画像は Pexels の建設現場写真で、たとえばこのような画像が含まれています。

画像出典: Pexels(Mikael Blomkvist / Abdulrhman Alkady)
VLM はこうした画像を見て、誰がどの保護具を装着しているか・していないかを判定します。
| 項目 | 値 |
|---|---|
| Train | 6,479 枚 |
| Val | 809 枚 |
| Test | 811 枚 |
| クラス数 | 17(safety-helmet、no-helmet、safety-gloves、no-gloves など) |
| フォーマット | YOLO(class x_center y_center width height) |
YOLO アノテーションから VQA 会話ペアを作る
VLM のファインチューニングには、画像と会話のペアが必要です。YOLO のバウンディングボックス座標から、PPE の装着状況を読み取って日本語の VQA ペアに変換するスクリプトを作りました。
変換の流れはこうです。各画像のアノテーションを解析し、PPE クラス(safety-helmet / no-helmet など)のペアから装着と未装着の件数を集計します。それを <think> タグで構造化した回答に整形します。
# 変換後のデータ例
{
"messages": [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "この画像の作業者のPPE装着状態を評価してください。"}
]
},
{
"role": "assistant",
"content": [{"type": "text", "text":
"<think>\n画像には3名の作業者が確認できます。"
" 装着確認済み: 保護メガネ装着: 3件。"
" 違反検出: 安全ジャケット未装着: 4件。\n</think>\n"
"PPEコンプライアンス違反があります。安全ジャケット未装着: 4件。"
}]
}
],
"images": [image] # PIL.Image オブジェクト
}
質問テンプレートは 5 パターン用意して、データの多様性を持たせました。画像は VLM の入力に合わせて長辺 1280px にリサイズしています。
変換結果は HuggingFace Datasets 形式で保存して、TRL の SFTTrainer にそのまま渡せるようにしました。最終的なデータ量はこのようになっています。
| Split | サンプル数 |
|---|---|
| Train | 6,437 |
| Validation | 804 |
| Test | 803 |
PPE アノテーションを含まない画像(人物のみ、顔のみなど)はスキップしているため、元の枚数より若干少なくなっています。
DGX Spark で LoRA SFT を実行する
環境構築
Cosmos-Reason2 の公式リポジトリをベースに環境を構築しました。DGX Spark は CUDA 13.0 / ARM64(aarch64)なので、cu130 の依存関係に切り替えています。
git clone https://github.com/nvidia-cosmos/cosmos-reason2
cd cosmos-reason2/examples/notebooks
# pyproject.toml の cu128_torch28 → cu130_torch29 に変更してから
uv sync
主要ライブラリのバージョンはこのようになりました。
| ライブラリ | バージョン |
|---|---|
| PyTorch | 2.9.0+cu130 |
| transformers | 4.57.3 |
| TRL | 0.26.1 |
| PEFT | 0.18.0 |
フルパラメータ SFT だとメモリが足りない
最初にフルパラメータ SFT のメモリ見積もりを計算してみたところ、モデル重み 17GB + 勾配 17GB + AdamW のオプティマイザ状態 70GB(FP32 で m と v)で合計 110-120GB になります。DGX Spark の 128GB 統合メモリに対してギリギリで、アクティベーションメモリを考えると OOM のリスクが高いと判断しました。
BF16 LoRA を選んだ理由
そこで BF16 モデルを凍結したまま LoRA アダプタだけを学習する方式にしました。
公式の trl_sft.py サンプルは QLoRA(4-bit 量子化 + LoRA)を使っていますが、量子化ライブラリの bitsandbytes が ARM64 + CUDA 13.0 で動く保証がなかったため、量子化なしの BF16 LoRA にしています。メモリに余裕があるので、量子化しなくても問題ありません。
# BitsAndBytesConfig は使わない
model = Qwen3VLForConditionalGeneration.from_pretrained(
"nvidia/Cosmos-Reason2-8B",
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="sdpa", # flash-attn は aarch64 ホイールなし
)
peft_config = LoraConfig(
r=32,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
バッチサイズを上げても速くならない
メモリに余裕があるならバッチサイズを上げて高速化……と考えたくなりますが、VLM では逆効果でした。
| 設定 | step time | ピーク GPU メモリ |
|---|---|---|
| batch=1, grad_accum=8 | 5.3 min | 31.5 GB(24%) |
| batch=4, grad_accum=2 | 6.3 min | 73.0 GB(56%) |
batch=4 にするとメモリ使用量は 2.3 倍に増えるのに、速度は逆に遅くなりました。VLM は画像ごとにトークン数が異なるため、バッチ内のパディングオーバーヘッドが大きいのが原因です。
速度を上げたい場合は、バッチサイズではなく gradient accumulation のステップ数を減らすのが正解でした。
学習の設定と実行
バッチサイズの検証結果を踏まえて、最終的にはこの設定に落ち着きました。
| パラメータ | 値 |
|---|---|
| バッチサイズ | 1 |
| Gradient accumulation | 4(有効バッチ 4) |
| 学習率 | 2e-4 |
| LoRA rank / alpha | 32 / 32 |
| 最大ステップ数 | 300 |
| Gradient checkpointing | 有効 |
| Optimizer | AdamW(標準、8-bit ではない) |
uv run python train_lora_sft.py \
--max-steps 300 \
--batch-size 1 \
--grad-accum 4 \
--lr 2e-4 \
--lora-rank 32 \
--lora-alpha 32
学習結果
| 項目 | 値 |
|---|---|
| 学習時間 | 14 時間 36 分 |
| ピーク GPU メモリ | 34.5 GB / 128 GB(27%) |
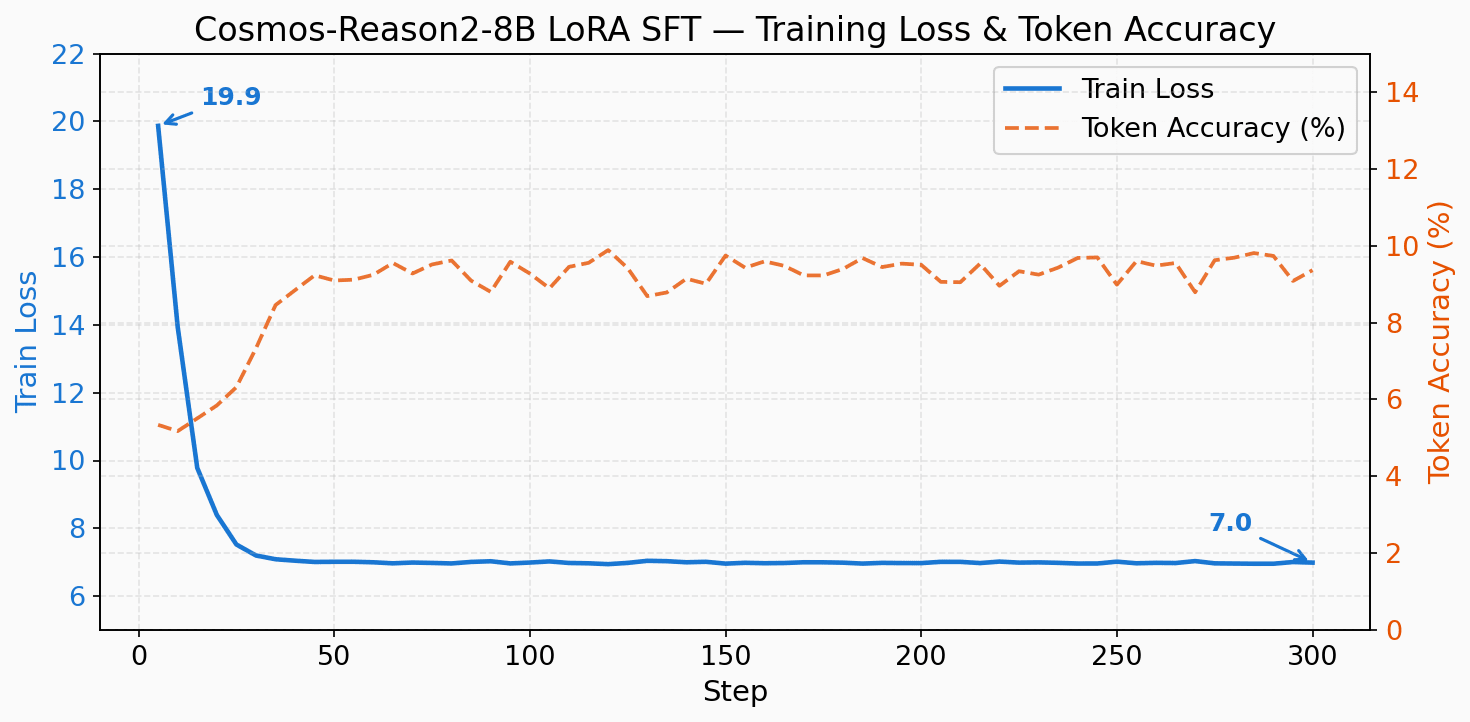
| Train Loss | 19.87 → 7.40 |
| LoRA アダプタサイズ | 333 MB |
Loss は 300 ステップで 19.87 から 7.40 まで下がりました。128GB メモリの 27% しか使っていないので、まだかなり余裕があります。
最初の 20 ステップで急激に下がり、その後はゆるやかに収束していく典型的な LoRA SFT のカーブです。
FT 前後の比較
テストセットからランダムに 30 枚を選び、同じ質問で推論を比較しました。
定量評価
| 指標 | Base | SFT(LoRA) | 改善 |
|---|---|---|---|
| PPE 違反検出精度 | 46.7% | 90.0% | +43.3% |
<think> タグ使用率 |
0% | 100% | — |
| 平均推論時間 | 47.1s | 53.2s | +6.1s |
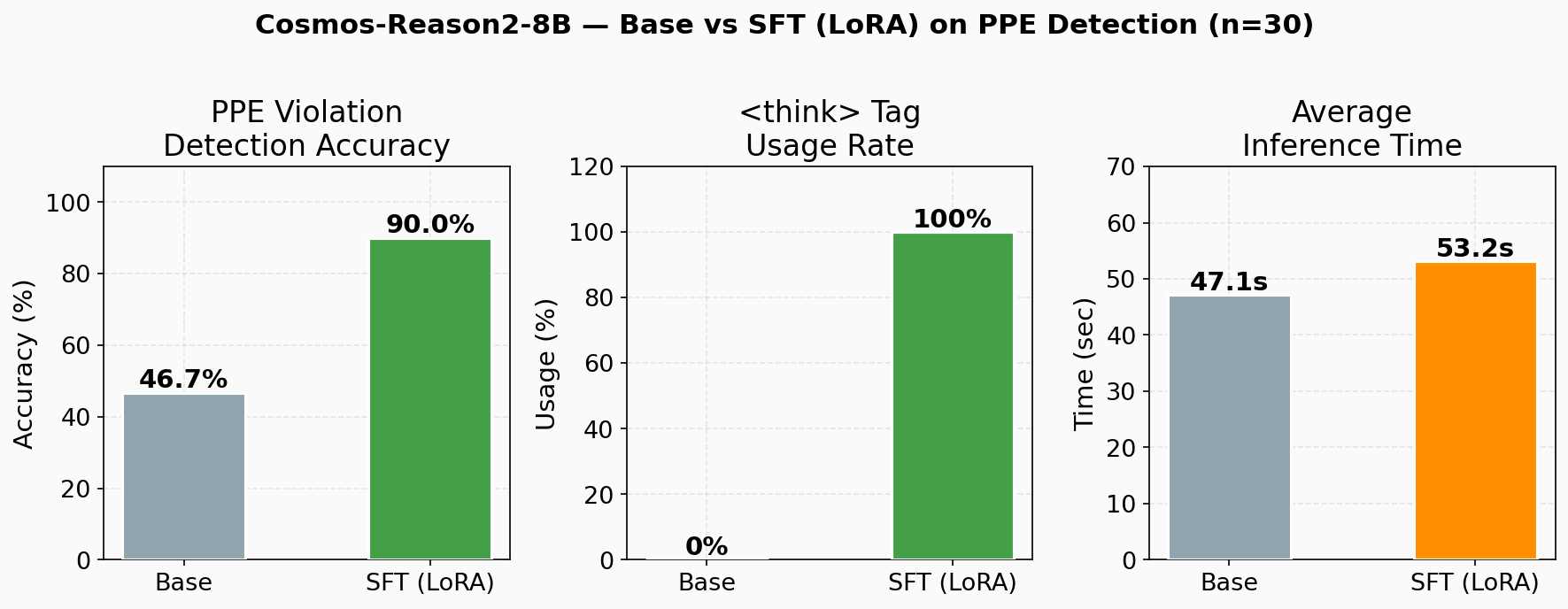
ベースモデルは PPE ドメインの知識がないため、「作業者が写っていません」「違反は見られません」のような誤判定が目立ちました。SFT 後は違反検出精度が 90% まで向上しています。
推論時間は LoRA アダプタのオーバーヘッドで +13% ほど増えていますが、実用上は気にならないレベルかなと思います。
定性的な変化
応答の形式が大きく変わりました。ベースモデルは自由文で回答していましたが、SFT 後は <think> タグで推論過程を構造化し、具体的な違反項目と件数を報告するようになっています。
ベースモデルの応答例
画像の作業者はヘルメットを装着していませんが、耳かけ型ヘッドセットを装着しています。
ヘルメットは作業中の頭部保護に不可欠な保護具であり、この画像では装着されていないため
違反と評価されます。一方で、耳かけ型ヘッドセットは音声コミュニケーションに必要な保護具
であり、適切に装着されているため違反とは評価されません。
SFT モデルの応答例
<think>
画像には3名の作業者が確認できます。 装着確認済み: 安全靴装着: 1件、保護メガネ装着: 3件。
違反検出: 安全ジャケット未装着: 3件。
</think>
PPEコンプライアンス違反があります。安全ジャケット未装着: 3件。
SFT モデルは装着済みの保護具と未装着の保護具を明確に分けて報告しています。この構造化された出力は、アラート通知や監視ダッシュボードのような下流システムとの連携で扱いやすいですね。
誤検出の傾向
SFT モデルは「違反あり」の方向に寄る傾向があります。30 サンプル中 3 件が「実際は問題なし → 違反あり」の過検出でした。テストセットの 90%(30 枚中 27 枚)が違反ありのサンプルだったことが影響しています。
実運用では、これは安全監視としては悪くない方向です。「見逃し」より「誤報」の方がリスクが低いためです。ただし、コンプライアント(問題なし)のサンプルを増やしてバランスを取ることで、さらに改善できるはずです。
ハマりポイント
flash-attention が使えない
DGX Spark は ARM64(aarch64)ですが、flash-attention の公式ホイールは x86_64 のみです。cosmos-reason2 の依存定義でも platform_machine != 'aarch64' で除外されています。attn_implementation="sdpa" を指定すれば、PyTorch 標準の Scaled Dot-Product Attention にフォールバックできます。
なお、Jetson AI Lab が公開している sbsa 向けの wheel を使えば DGX Spark でも flash-attn 2.7.4 をインストールできることを別の検証で確認しています。推論では問題なく動作しましたが、SFTTrainer での長時間学習における安定性は未検証のため、今回は SDPA を採用しました。flash-attn が使えれば学習時間の短縮が期待できるので、今後試してみたいところです。
torch_dtype の非推奨警告
torch_dtype パラメータが非推奨になっていて、dtype を使うよう警告が出ます。transformers 4.57 以降の変更です。動作には影響ありませんが、新しいコードでは dtype を使うのがよいでしょう。
まとめ
DGX Spark 1 台で Cosmos-Reason2-8B の LoRA SFT を実行し、PPE 違反検出の精度を 46.7% から 90.0% に改善できました。128GB 統合メモリの 27% しか使わずに済んだので、より大きなモデルやバッチサイズでの実験にも余裕があります。
ファインチューニングのパイプライン自体はシンプルで、YOLO アノテーション → VQA 変換 → TRL SFTTrainer という流れです。VLM 特有の注意点としては、バッチサイズを上げても高速化しない(パディングオーバーヘッド)ことと、ARM64 環境での flash-attention 非対応への対処があります。
今回の LoRA アダプタは、たとえば DeepStream の物体検出(1 段目)→ VLM の視覚的検証(2 段目)という 2 段階パイプラインの 2 段目に組み込めます。汎用 VLM を自社の現場データで少しずつ育てていくワークフローとして、参考になれば幸いです。
参考リンク
- nvidia-cosmos/cosmos-reason2 — 公式リポジトリ(SFT / GRPO レシピ)
- Cosmos Cookbook: Post-training — 公式 Cookbook
- SH17 Dataset — PPE 検出データセット
- TRL SFTTrainer — TRL 公式ドキュメント
- DGX Spark Playbooks: VLM Fine-tuning — NVIDIA 公式 Playbook








