
Gemma 4 を DGX Spark で動かして日本語とマルチモーダルをベンチマークしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
Google から Gemma 4 がリリースされました。Apache 2.0 ライセンスで、小型の E2B(2.3B)から大型の 31B Dense まで 4 つのモデルが一度に公開されています。全モデルがマルチモーダル対応で、画像入力をネイティブに扱えます。
DGX Spark には 128GB の統合メモリがあるので、最大の 31B でも BF16(量子化なし)で動かせます。実際、NVIDIA の公式ブログでも DGX Spark で Gemma-4-31B BF16 が動作すると明言されています。量子化なしのフル精度で大型モデルを試せるのは、128GB ならではですね。
この記事では、Gemma 4 の全 4 モデルを DGX Spark に Ollama でデプロイし、日本語テキスト(JCommonsenseQA)とマルチモーダル(画像理解)の 2 軸でベンチマークした結果を紹介します。Gemma 4 から搭載された「Thinking モード」の効果と、Gemma 3 や Nemotron シリーズとの比較データも載せています。
Gemma 4 の概要
モデルファミリー
| モデル | 総パラメータ | Active パラメータ | アーキテクチャ | コンテキスト | BF16 メモリ |
|---|---|---|---|---|---|
| E2B | 5.1B | 2.3B | Dense + PLE | 128K | ~10 GB |
| E4B | 8B | 4.5B | Dense + PLE | 128K | ~16 GB |
| 26B-A4B | 26B | 3.8B | MoE | 256K | ~52 GB |
| 31B | 31B | 30.7B | Dense | 256K | ~62 GB |
「E」は Effective の略で、Per-Layer Embeddings(PLE)という技術でパラメータ効率を高めた小型モデルです。各デコーダ層に補助的な埋め込みテーブルを持たせることで、少ないパラメータでも表現力を高めています。26B-A4B は Mixture-of-Experts(MoE)で、全体は 26B ですが推論時に使われるのは 3.8B だけという効率重視の設計です。
E2B と E4B はテキストと画像に加えてオーディオ入力にも対応しています(ただし Ollama では 2026 年 4 月時点でオーディオ未サポート)。
ライセンス
Gemma 4 は Apache 2.0 ライセンスで公開されています。Gemma 3 までは独自の「Gemma Terms of Use」で、商用利用に一部制限がありました。Apache 2.0 になったことで、改変や再配布を含む商用利用が制限なく可能になっています。企業での導入検討がしやすくなったのは大きな変化ですね。
Gemma 3 からの主な変化
Gemma 3 は 1B / 4B / 12B / 27B の 4 サイズで、4B 以上がマルチモーダル対応でした。Gemma 4 での大きな変化をまとめるとこんな感じです。
- 26B-A4B という MoE モデルが追加されました。Active 3.8B で 27B Dense に近い性能を狙えます
- 推論前にステップバイステップで考える Thinking モードが全モデルに搭載されました
- Shared KV Cache によって後半の N 層が前半の KV ステートを再利用し、推論時のメモリと計算コストが削減されています
Thinking モード
Ollama では "think": true を API パラメータに渡すだけで有効化できます。レスポンスでは message.thinking に推論過程が、message.content に最終回答が分離されて返ってくるので、後処理もシンプルです。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark |
| GPU | NVIDIA GB10(128 GB 統合メモリ) |
| OS | Ubuntu 22.04(ARM64/SBSA) |
| CUDA | 12.8 |
| Ollama | 0.20.0 |
セットアップ
Ollama 0.20.0 以降で Gemma 4 がサポートされています。
# Gemma 4 — BF16(E2B / E4B / 31B)+ Q4_K_M(26B MoE)
ollama pull gemma4:e2b-it-bf16 # 10 GB
ollama pull gemma4:e4b-it-bf16 # 16 GB
ollama pull gemma4:26b # 17 GB (Q4_K_M)
ollama pull gemma4:31b-it-bf16 # 62 GB
26B-A4B は Ollama で BF16 タグが提供されていなかったため Q4_K_M での計測です。他の 3 モデルは量子化なしのフル精度です。
VRAM 使用量
Ollama でモデルをロードした際の実測値(ollama ps の SIZE 列、コンテキスト長分の KV キャッシュ込み)です。
| モデル | 量子化 | VRAM |
|---|---|---|
| gemma4:e2b-it-bf16 | BF16 | 15 GB |
| gemma4:e4b-it-bf16 | BF16 | 23 GB |
| gemma4:26b | Q4_K_M | 38 GB |
| gemma4:31b-it-bf16 | BF16 | 117 GB |
31B BF16 は 117 GB で 128 GB の統合メモリをほぼ使い切ります。
テキストベンチマーク: JCommonsenseQA
ベンチマーク方法
日本語の常識推論能力を測るため、JCommonsenseQA v1.1 を使用しました。1,119 問の 5 択問題を 3-shot プロンプトで評価しています。過去記事(Nemotron シリーズ)でも同じデータセットを使っているので、歴代モデルとの横比較が可能です。
結果
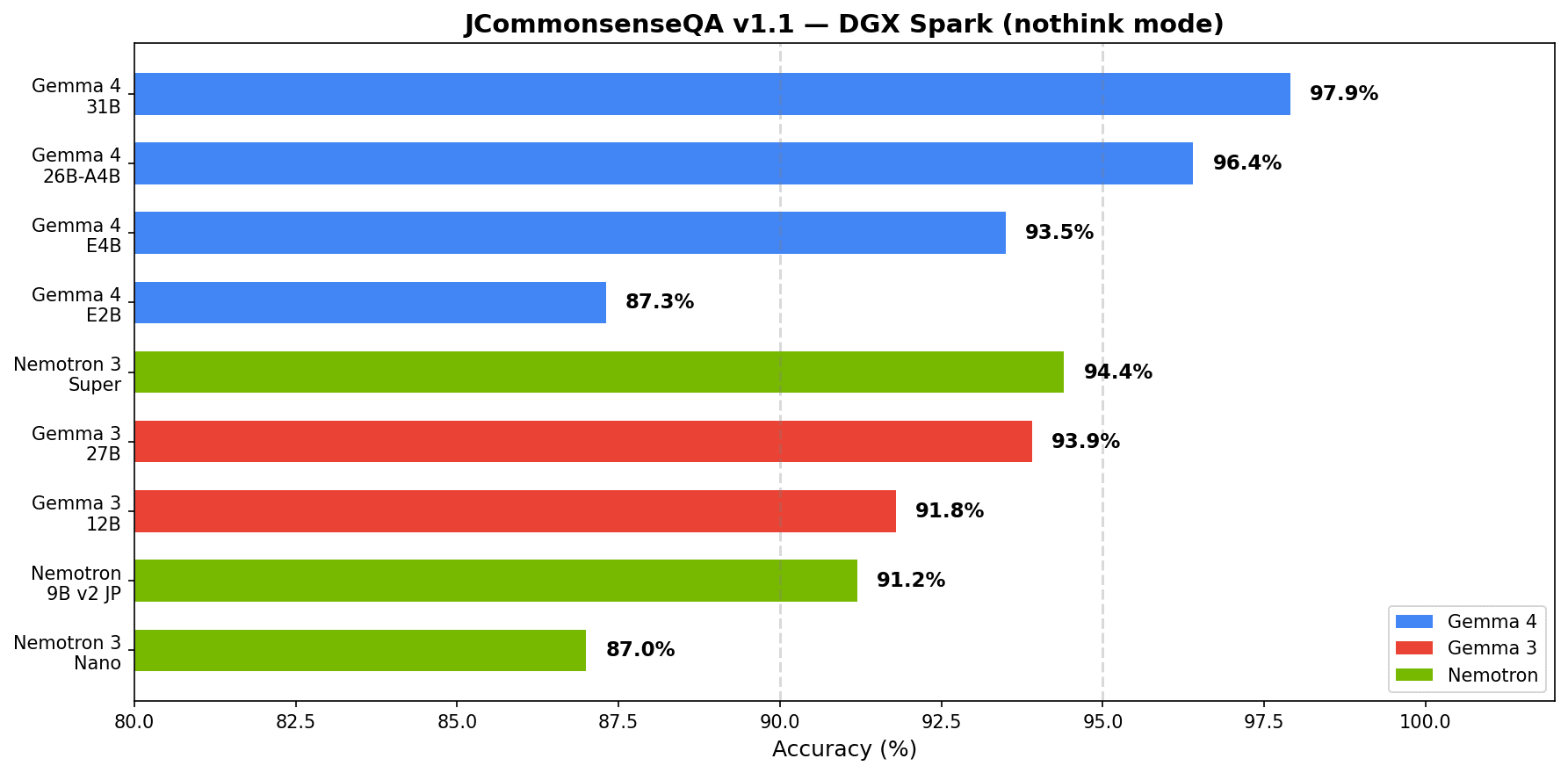
| モデル | パラメータ(Active) | 量子化 | Think | 正解率 | レイテンシ | tok/s |
|---|---|---|---|---|---|---|
| Gemma 4 31B | 31B (30.7B) | BF16 | off | 97.9% | 1.97s | 4.6 |
| Gemma 4 26B-A4B | 26B (3.8B) | Q4_K_M | off | 96.4% | 0.33s | 69.5 |
| Nemotron 3 Super | 120B (12B) | Q4_K_M | off | 94.4% | 0.92s | 35.6 |
| Gemma 3 27B | 27B | Q4_K_M | off | 93.9% | — | — |
| Gemma 4 E4B | 8B (4.5B) | BF16 | off | 93.5% | 0.28s | 46.2 |
| Gemma 3 12B | 12B | Q4_K_M | off | 91.8% | — | — |
| Nemotron Nano 9B v2 JP | 9B | BF16 | off | 91.2% | 0.98s | — |
| Gemma 4 E2B | 5.1B (2.3B) | BF16 | off | 87.3% | 0.22s | 91.1 |
| Nemotron 3 Nano | 30B (3B) | Q4_K_M | off | 87.0% | 0.31s | 118.5 |
Gemma 3 のレイテンシは過去記事で lm-evaluation-harness を使用しており、Ollama API との直接比較ができないため省略しています。また、Gemma 4 の E2B / E4B / 31B は BF16、26B-A4B と比較対象モデルは Q4_K_M と量子化条件が異なる点にはご注意ください。
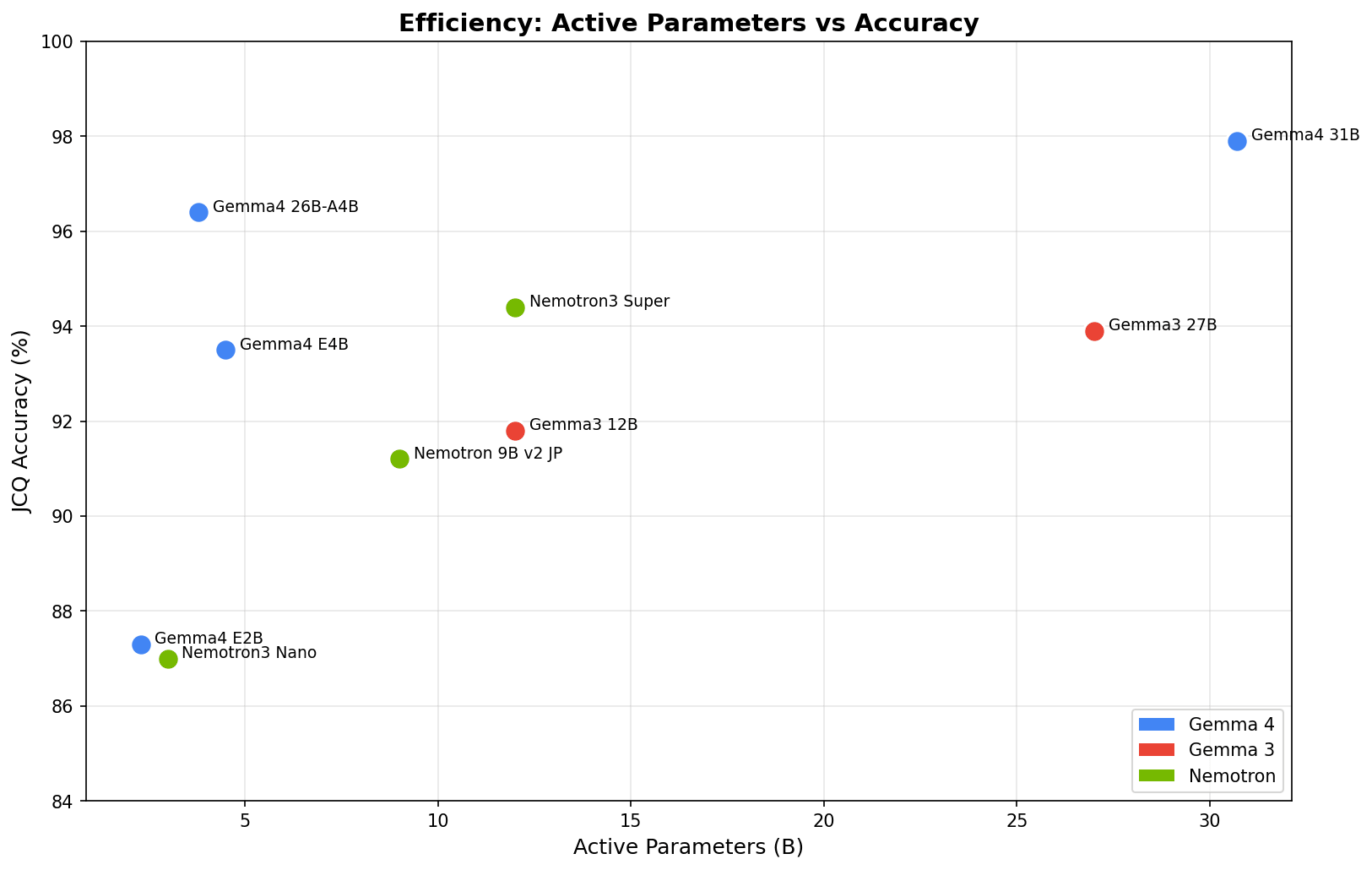
31B が 97.9% で全モデル中トップ。過去記事で Gemma 3 27B が 93.9% で DGX Spark ローカルモデルの最高スコアだったので、同系列で 4 ポイント改善したことになります。
注目は 26B MoE です。Active パラメータはわずか 3.8B なのに 96.4%。Nemotron 3 Super(120B、Active 12B)の 94.4% を上回り、レイテンシも 0.33s/q と Nemotron 3 Nano(0.31s/q)並みの速さです。
E4B も 4.5B Effective で 93.5% と、日本語特化の Nemotron Nano 9B v2 JP(91.2%)を上回っています。汎用モデルとしての日本語能力の高さがうかがえますね。
Thinking モードの効果
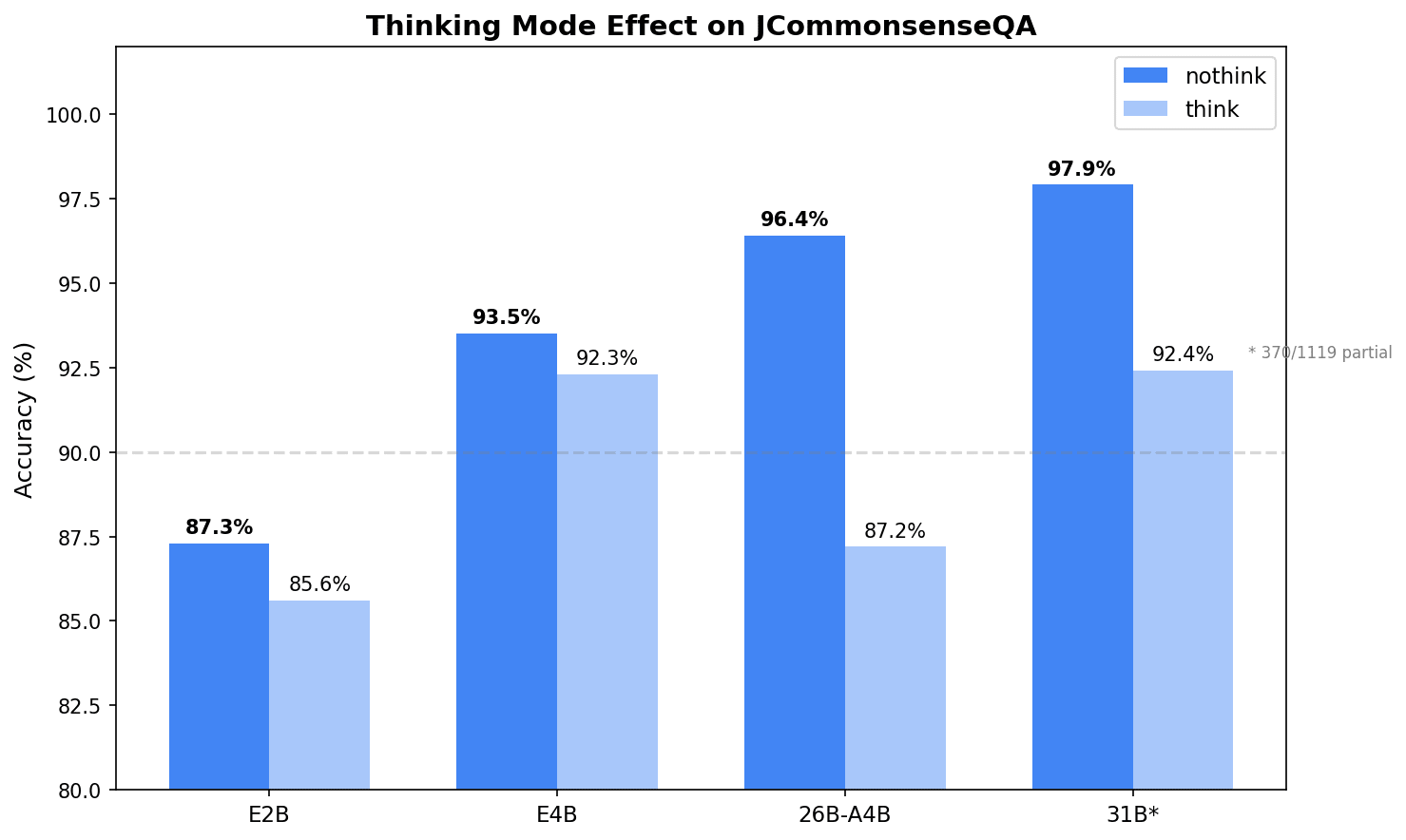
| モデル | nothink | think | 差分 | レイテンシ増 |
|---|---|---|---|---|
| E2B | 87.3% | 85.6% | -1.7% | ×31 倍 |
| E4B | 93.5% | 92.3% | -1.2% | ×7.5 倍 |
| 26B-A4B | 96.4% | 87.2% | -9.2% | ×15 倍 |
| 31B | 97.9% | 92.4%* | -5.5% | ×34 倍 |
* 370/1119 問の参考値
JCQ のような知識ベースの 5 択問題では、Thinking モードは全モデルで逆効果でした。特に 26B MoE は 9.2 ポイント低下しています。「この選択肢も正しいかもしれない」と考えすぎて迷いが生じている印象です。
Thinking モードは数学やコーディングのような段階的な推論が必要なタスク向けの設計なので、常識推論のような「知っているか知らないか」が勝負のタスクでは、直感的に答えた方がむしろ正確という結果になりました。
マルチモーダルベンチマーク
Gemma 4 は全モデルがマルチモーダル対応です。GTC 2026 で撮影した展示会場の写真を使って、日本語でのキャプション生成と構造化データ抽出、PPE(保護具)検出の 2 つの観点で検証しました。
日本語画像キャプションと構造化タグ抽出
10 枚の写真について、日本語でのシーン説明(キャプション)と構造化されたタグ情報(JSON 形式)の抽出を行いました。
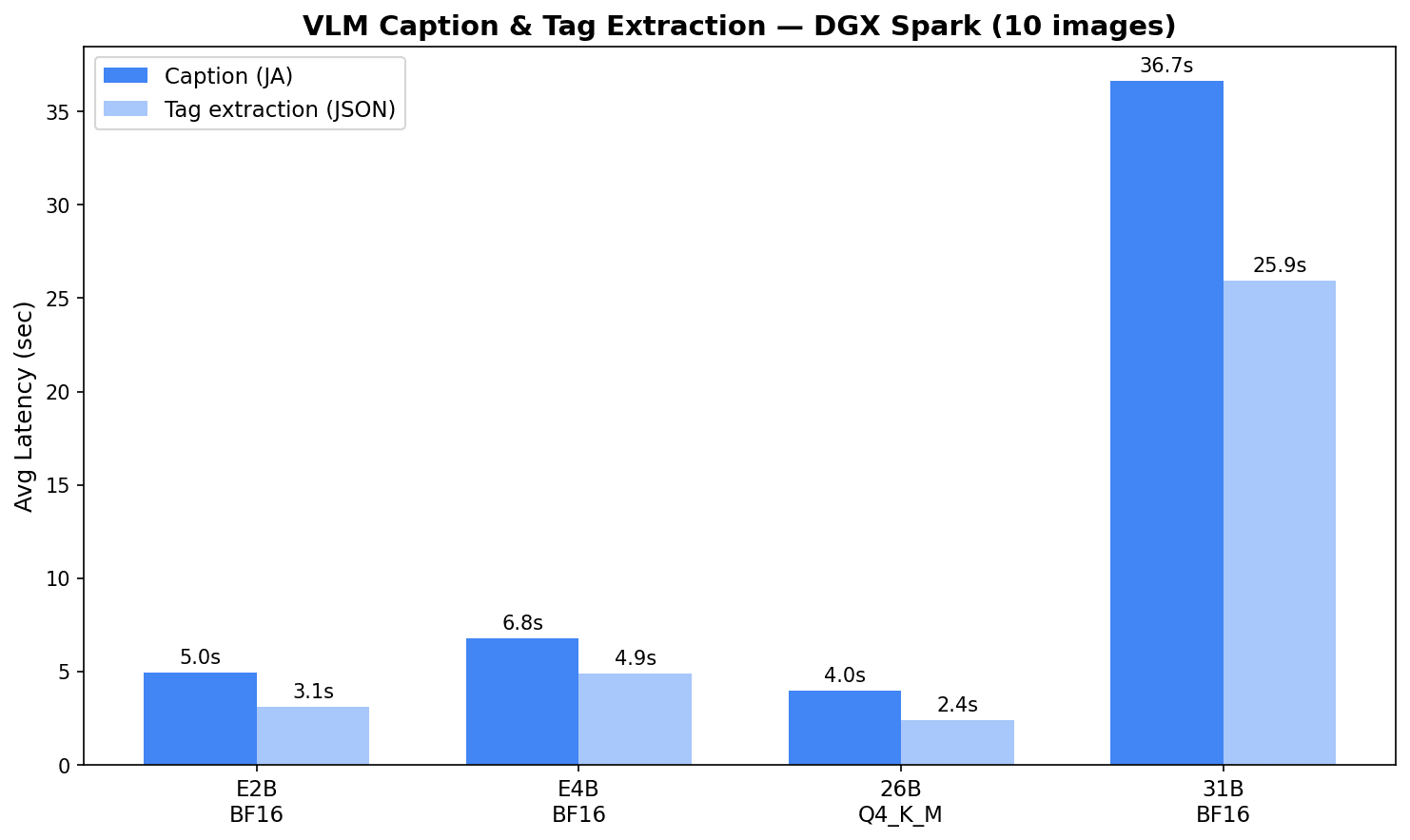
| モデル | 量子化 | キャプション平均 | タグ抽出平均 | JSON パース成功率 |
|---|---|---|---|---|
| gemma4:e2b-it-bf16 | BF16 | 5.0s | 3.1s | 100% |
| gemma4:e4b-it-bf16 | BF16 | 6.8s | 4.9s | 100% |
| gemma4:26b | Q4_K_M | 4.0s | 2.4s | 100% |
| gemma4:31b-it-bf16 | BF16 | 36.7s | 25.9s | 100% |
26B MoE が最速で、キャプション 4.0s、タグ抽出 2.4s。E2B よりも速いのは、Q4_K_M 量子化でメモリ帯域に余裕があるためと考えられます。31B BF16 は 117 GB という巨大なモデルサイズがボトルネックで、1 枚あたり 37 秒ほどかかります。
全モデルで JSON パース成功率が 100% だったのは好印象です。プロンプトで JSON フォーマットを指定すれば、構造化データの抽出にも安定して使えそうですね。
26B キャプション出力例
この画像は、屋内での展示会や技術イベントのブースの様子を捉えたものです。
中央には、黒いボディに銀色の関節を持つ人型ロボット(ヒューマノイド)が展示されており、
その背後にはスタッフと思われる二人の男性が立っています。手前のカウンターには、
来場者用と思われるお菓子が入ったバスケットが置かれています。
{
"location": "展示ホール",
"event_type": "ブースデモ",
"subjects": ["人型ロボット", "来場者", "展示カウンター", "バスケット"],
"technologies": ["ヒューマノイドロボット"],
"people_count": 2,
"atmosphere": "デモ展示中"
}
PPE(保護具)検出
製造業向けの VLM 活用として、安全保護具(ヘルメット、安全ベスト等)の画像からの検出も試しました。5 枚のシーン画像に対して、JSON 形式で装着状況と遵守度を判定させています。
| モデル | 量子化 | 平均レイテンシ | JSON パース成功率 |
|---|---|---|---|
| gemma4:e2b-it-bf16 | BF16 | 3.5s | 100% |
| gemma4:e4b-it-bf16 | BF16 | 6.8s | 100% |
| gemma4:26b | Q4_K_M | 2.9s | 100% |
| gemma4:31b-it-bf16 | BF16 | 29.2s | 100% |
26B PPE 検出出力例(倉庫フォークリフト画像)
{
"workers_count": 1,
"ppe_items": [
{
"worker_id": 1,
"hard_hat": false,
"safety_vest": true,
"safety_glasses": false,
"gloves": false,
"safety_shoes": false,
"other": []
}
],
"compliance_score": "低",
"observations": "作業員は高視認性安全ベストを着用していますが、ヘルメットや安全靴、手袋などの他の重要な個人用保護具の着用が確認できません。フォークリフト作業においては、頭部保護や足元の安全確保が重要です。"
}
ゼロショットでここまで詳細な判定を返してくれるのは便利ですね。ファインチューニング済みの Cosmos-Reason2-8B(過去記事で SFT 後 90% の正解率を達成)のような専用モデルには及ばないとは思いますが、「まず試す」段階のプロトタイピングには十分な精度です。
DGX Spark 固有の注意点
- Ollama 0.20.0 以降が必須です。Gemma 4 は 2026 年 4 月 2 日リリースの 0.20.0 で初めてサポートされました
- 26B-A4B は Ollama に BF16 タグがありません。Q4_K_M のみです。BF16 で試したい場合は vLLM 等の別ランタイムが必要になります
- NVIDIA の DGX Spark Playbook では vLLM での Gemma 4 デプロイ手順も案内されています
- Blackwell 向けの NVFP4 量子化チェックポイントが準備中とのことです。31B が NVFP4 で動けばメモリと速度の両方で改善が期待できますね
モデル選定ガイド
| ユースケース | おすすめ | 理由 |
|---|---|---|
| エッジやモバイル | E2B | 2.3B Active、BF16 で 15 GB。Jetson Orin Nano でも動く |
| バランス重視 | 26B-A4B | Active 3.8B で 96.4%。速度と精度の両立が際立つ |
| 最高精度 | 31B | 97.9% だが 117 GB とレイテンシが重い。余裕がある環境で |
| 軽量な VLM 画像理解 | 26B-A4B | キャプション 4.0s/枚、JSON 100% で最速かつ高品質 |
| 日本語チャットやテキスト生成 | E4B | 93.5% で 0.28s。16 GB なので同居しやすい |
まとめ
Gemma 4 の全 4 モデルを DGX Spark で動かして、日本語テキストとマルチモーダルの両面からベンチマークしました。
JCommonsenseQA では、31B が 97.9% で DGX Spark ローカルモデルの最高スコアを更新しました。しかし個人的に一番印象的だったのは 26B MoE(Active 3.8B)の 96.4% です。Nemotron 3 Super(120B、Active 12B)の 94.4% を Active パラメータ約 3 分の 1 で超えてきたのは驚きでした。レイテンシも 0.33s/q で、もはや「小さいモデル」と同じ速度帯です。
マルチモーダルでも 26B MoE は最速(キャプション 4.0s/枚)で、JSON 構造化出力も全モデル 100% パース成功。PPE 検出のようなゼロショットタスクでも実用的な精度が出ており、プロトタイピングには十分使えそうです。
一方、Thinking モードは JCQ のような常識推論タスクでは全モデルで逆効果でした。数学やコーディング以外では無効にして使ったほうが良さそうです。
NVFP4 量子化チェックポイントが公開されれば、31B のレイテンシ改善も期待できます。26B MoE の BF16 版が Ollama に来ればさらに面白い結果になるかもしれません。









