
DGX Spark でロボットアームの強化学習を試してみた(Isaac Sim + Isaac Lab + SO-ARM101)
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
CES 2026 では NVIDIA の基調講演で Physical AI が大きく取り上げられ、3 月開催の GTC 2026 でも Physical AI Day が設定されるなど、ロボティクスと AI を組み合わせた領域への注目が急速に高まっています。自分もこの流れに乗らなければ!
そこで今回は「まず自分で触って理解する」をテーマに、NVIDIA Isaac Sim と Isaac Lab を基礎から学んでみることにしました。Isaac Sim のシミュレーション環境でロボットアームを動かして、報酬関数を自分で設計して、学習結果がどう変わるのかを観察してみます。
既存の学習スクリプトを実行するだけでなく、報酬設計のコードを読み解いて、パラメータを変えたり、自分で報酬関数を書いたりするところまで踏み込んでみます。強化学習の経験がほぼゼロの状態から始めた学習ログなので、同じように「Physical AI に興味はあるけど、何から手をつけていいかわからない」という方の参考になればと思います。
今回のゴール
3 段階に分けて進めます。
- DGX Spark 上に Isaac Sim + Isaac Lab の環境を構築する
- Isaac Sim の GUI でロボットアームを手動で触ってみる
- 報酬関数をカスタマイズして学習結果の変化を観察する
前提環境
| 項目 | バージョン |
|---|---|
| マシン | NVIDIA DGX Spark(GB10 Grace Blackwell) |
| OS | Ubuntu 24.04 ARM64 |
| GPU ドライバ | 580.126.09 |
| Python | 3.11(Isaac Sim 同梱) |
| Isaac Sim | 5.1.0-rc.19(ソースビルド) |
| Isaac Lab | 0.54.3 |
| isaac_so_arm101 | v1.2.0 |
SO-ARM101 と isaac_so_arm101 について
SO-ARM100/101 は The Robot Studio が開発したオープンソースのロボットアームです。6 自由度、Feetech STS3215 サーボモーターを搭載し、$220 から入手できる手頃な価格が特徴です。Hugging Face の LeRobot プロジェクトでもリファレンスハードウェアとして採用されています。今回は改良版の SO-ARM101 を使います。
isaac_so_arm101 は、この SO-ARM100/101 を Isaac Lab で使うための拡張パッケージです。URDF モデル、環境設定、学習スクリプトが一式揃っているので、環境さえ整えばすぐに強化学習を始められます。
環境構築
DGX Spark の ARM64 環境に Isaac Sim、Isaac Lab、isaac_so_arm101 をセットアップしていきます。x86_64 マシンなら pip で数分で終わる作業ですが、ARM64 ではソースビルドが必要なのと、いくつかハマりポイントがあります。ハマりポイントの詳細は記事末尾の表にまとめたので、ここではコマンド中心で進めます。
Isaac Sim のソースビルド
まず GCC 11 をインストールします。Ubuntu 24.04 のデフォルトは GCC 13 ですが、13 系だと Isaac Sim のビルドが失敗します。NVIDIA 公式 Isaac Playbook にも同じ手順が記載されています。
sudo apt update && sudo apt install -y gcc-11 g++-11
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 200
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-11 200
Git LFS を入れてから、リポジトリをクローンしてビルドします。
sudo apt install -y git-lfs
git clone --depth=1 --recursive https://github.com/isaac-sim/IsaacSim.git
cd IsaacSim
git lfs install && git lfs pull
./build.sh -r # Release ビルド
DGX Spark で約 13 分でした。ディスクは最低 50GB の空きを確保しておいてください。
export ISAACSIM_PATH="${PWD}/_build/linux-aarch64/release"
Isaac Lab と isaac_so_arm101
git clone --recursive https://github.com/isaac-sim/IsaacLab.git
cd IsaacLab
# Isaac Sim へのシンボリックリンクを作成(Playbook 推奨の方法)
ln -sfn "${ISAACSIM_PATH}" "${PWD}/_isaac_sim"
# インストール(PyTorch 2.9.0+cu130 に自動アップグレードされる)
./isaaclab.sh --install
isaac_so_arm101 は --no-deps でインストールします。README にある uv sync は DGX Spark のソースビルド環境だと依存解決に失敗するためですね。
git clone https://github.com/MuammerBay/isaac_so_arm101.git
./isaaclab.sh -p -m pip install -e ~/works/robotics/isaac_so_arm101 --no-deps
実行前の環境変数設定
DGX Spark で Isaac Sim を動かすには、2 つの環境変数が必要です。
# OpenMP リンク問題の回避
export LD_PRELOAD="/lib/aarch64-linux-gnu/libgomp.so.1"
# SSH セッションなど headless で実行する場合(DISPLAY が必要)
export DISPLAY=:0
export XAUTHORITY=/run/user/1000/.mutter-Xwaylandauth.XXXXXX
LD_PRELOAD を忘れると原因不明のクラッシュに悩まされます。XAUTHORITY のファイル名はセッションごとに変わるので、ls /run/user/1000/.mutter-Xwaylandauth.* で確認してください。
Isaac Sim の GUI でロボットを触ってみる
環境が整ったので、まずは Isaac Sim の GUI を開いてロボットアームを手動で動かしてみます。
GUI の起動と SO-ARM101 の読み込み
Isaac Sim GUI を起動して、SO-ARM101 の URDF を読み込みます。
cd ~/works/robotics/IsaacSim
./_build/linux-aarch64/release/isaac-sim.sh
初回起動は拡張機能やシェーダーのキャッシュ生成で数分かかります。GUI が立ち上がったら File > Import から SO-ARM101 の URDF を読み込みます。
パスは isaac_so_arm101/src/isaac_so_arm101/robots/trs_so101/urdf/so_arm101.urdf です。Import 時に「Static Base」にチェックを入れておくと、ベースが固定されたロボットアームとして読み込まれます。
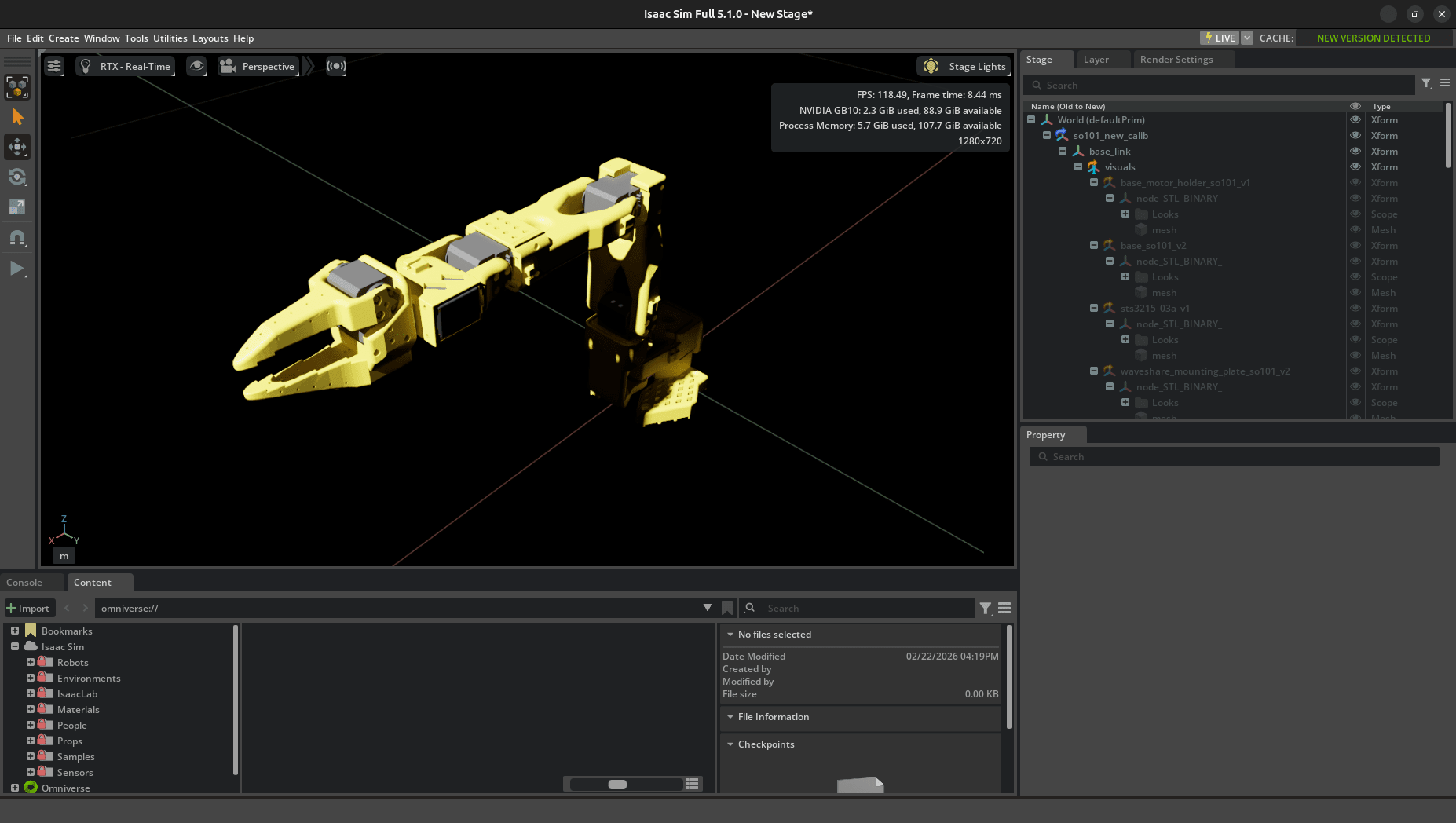
黄色いロボットアームがビューポートの中央に表示されました。右側の Stage パネルにはリンク構造がツリー表示されていて、base_link → shoulder_link → upper_arm_link → lower_arm_link → wrist_link → gripper_link という階層構造が確認できます。
Physics Inspector でジョイントを操作する
Isaac Sim には Physics Inspector というツールがあり、ロボットの各関節をスライダーで手動操作できます。Tools > Physics > Physics Inspector で開きます。
パネルが表示されたらロボットのアーティキュレーションを選択すると、各ジョイントの DOF(自由度)がスライダー付きで一覧表示されます。
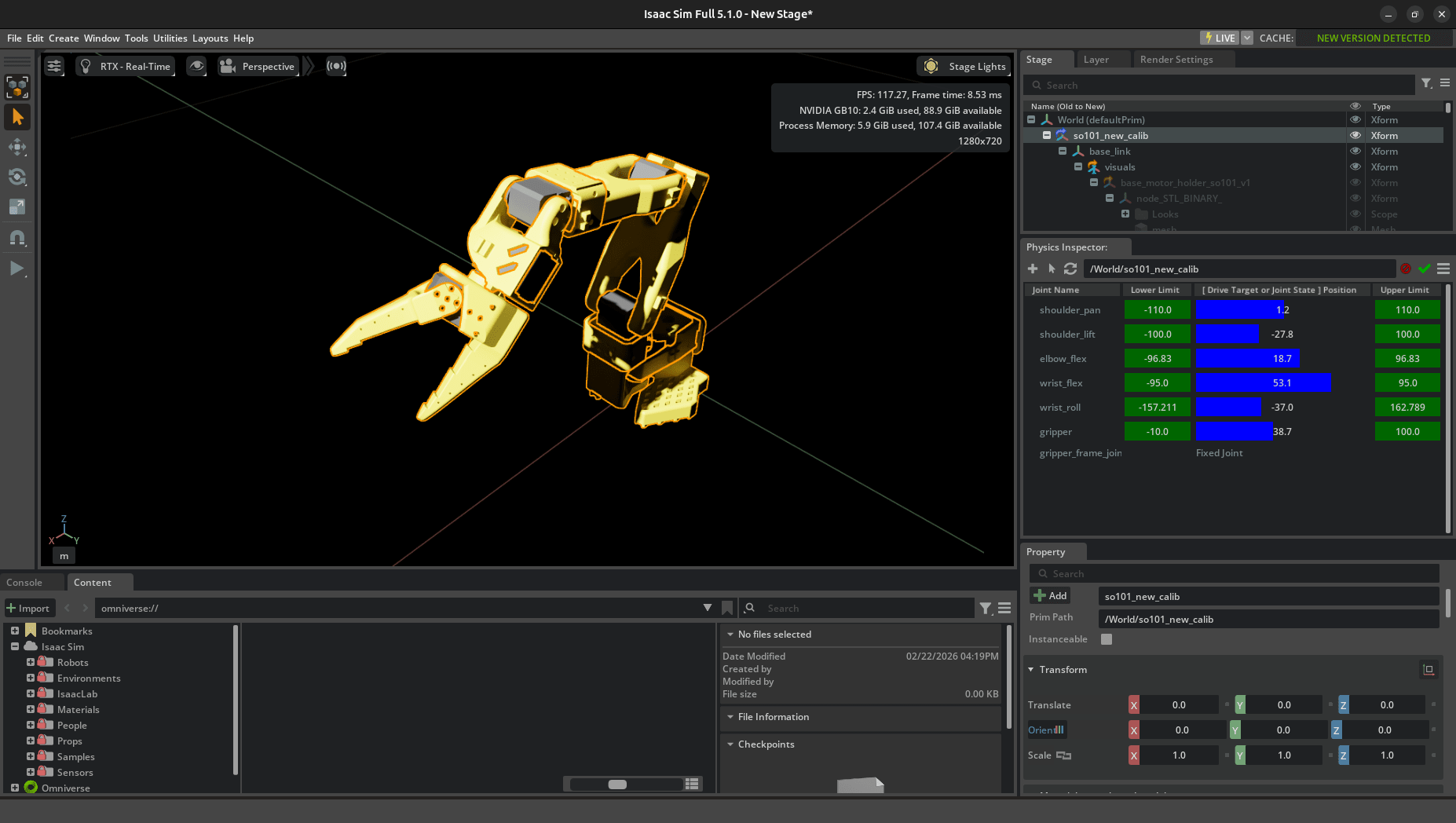
SO-ARM101 には 6 つのジョイントがあります。shoulder_pan で根元の回転、shoulder_lift と elbow_flex で腕の上下、wrist_flex と wrist_roll で手首の角度を制御します。最後の gripper はグリッパーの開閉ですね。
実際にスライダーを動かしてみると、shoulder_pan と shoulder_lift の 2 つだけでアームの大まかな位置が決まることがわかります。逆に wrist_flex と wrist_roll は先端の微妙な角度調整で、エンドエフェクタの姿勢に効いてきます。後で出てくる報酬設計で「位置追跡」と「姿勢追跡」を別々の報酬項として定義している理由が、ここで触ってみると納得できました。
スライダーのマッピングモードは「Joint Drive Target Position」がおすすめです。物理シミュレーションを通じてターゲット位置へ移動するので、実際のサーボモーターに近い挙動を観察できます。
ちなみに、こうやって手動で動かした軌跡を記録して、それを「お手本」として学習させる模倣学習(Imitation Learning)というアプローチもあります。リーダーアームで操作したデモデータからポリシーを学習させる方法で、LeRobot や GR00T がまさにこの系統ですね。今回は報酬関数ベースの強化学習に集中しますが、実機とリファレンスアームを使った模倣学習は後ほど試してみたいと思っています。
既存の Reaching タスクを動かしてみる
GUI でロボットの動きを把握できたところで、次は強化学習でロボットを動かしてみます。
ロボティクスの強化学習では、タスクの難易度を段階的に上げていくのが定番です。Reach(目標位置にアームの先端を持っていく)→ Grasp(物を掴む)→ Lift(持ち上げる)→ Place(置く)という順番ですね。Reaching タスクはその最初のステップで、「エンドエフェクタ(アームの先端)をランダムに生成された目標座標へ移動させる」だけのシンプルなタスクです。物を掴んだり持ち上げたりはしません。
シンプルとはいえ、6 つの関節を協調させて 3D 空間の任意の点に到達させる必要があるので、報酬設計の基礎を学ぶにはちょうどいい題材です。isaac_so_arm101 にはこの Reaching タスクの環境と学習スクリプトが用意されているので、それを使ってみます。
トレーニングの実行
cd ~/works/robotics/IsaacLab
./isaaclab.sh -p ~/works/robotics/isaac_so_arm101/src/isaac_so_arm101/scripts/rsl_rl/train.py \
--task Isaac-SO-ARM101-Reach-v0 \
--headless \
--num_envs 64 \
--max_iterations 1000
64 並列環境での RSL-RL(PPO)による学習が始まります。isaac_so_arm101 の README には SO-ARM101-Reach-v0 と書かれていますが、現行バージョンでは Isaac- プレフィックスが必要なので注意してください。
1000 イテレーション、約 9 分で学習が完了しました。DGX Spark の GB10 GPU で約 3,500 steps/s のスループットです。
| 項目 | 結果 |
|---|---|
| 所要時間 | 約 9 分 |
| スループット | 約 3,500 steps/s |
| position error | 0.0987 |
| 合計ステップ数 | 1,536,000 |
position error は序盤で急速に下がり、0.1 付近で収束しています。
学習済みポリシーの評価
./isaaclab.sh -p ~/works/robotics/isaac_so_arm101/src/isaac_so_arm101/scripts/rsl_rl/play.py \
--task Isaac-SO-ARM101-Reach-Play-v0 \
--num_envs 4 \
--video \
--video_length 200
play.py で ModuleNotFoundError: No module named 'isaaclab.utils.pretrained_checkpoint' が出る場合は、Isaac Lab 0.54.3 にこのモジュールが存在しないためです。該当箇所を try-except でラップすることで回避できます。
Play 実行時に学習済みポリシーが JIT と ONNX 形式で自動エクスポートされるので、あとで実機転送に使えます。
報酬設計を読み解く
既存のスクリプトで学習が動いたので、次はその中身を理解してみます。強化学習の挙動を決めているのは報酬関数です。isaac_so_arm101 の Reaching タスクではどんな報酬が設定されているのか、コードを読んでいきます。
Manager-Based 方式の報酬定義
isaac_so_arm101 は Isaac Lab の Manager-Based 方式を採用しています。reach_env_cfg.py の RewardsCfg クラスに、報酬項(RewTerm)を宣言的に並べる構造です。
@configclass
class RewardsCfg:
# タスク報酬
end_effector_position_tracking = RewTerm(
func=mdp.position_command_error,
weight=-0.2,
params={...},
)
end_effector_position_tracking_fine_grained = RewTerm(
func=mdp.position_command_error_tanh,
weight=0.1,
params={..., "std": 0.1},
)
end_effector_orientation_tracking = RewTerm(
func=mdp.orientation_command_error,
weight=-0.1,
params={...},
)
# ペナルティ
action_rate = RewTerm(func=mdp.action_rate_l2, weight=-0.0001)
joint_vel = RewTerm(func=mdp.joint_vel_l2, weight=-0.0001, params={...})
5 つの報酬項が定義されています。ただし SO-ARM101 の Reaching タスクでは orientation_tracking の weight が 0.0 に設定されているため、実質的に機能しているのは 4 項です。
position_command_error(weight=-0.2)は、エンドエフェクタと目標位置の L2 距離をそのままペナルティにする項です。遠いほど大きなマイナス報酬になるので、ロボットを目標に「大まかに近づける」役割ですね。
position_command_error_tanh(weight=0.1, std=0.1)は面白い設計で、距離を tanh カーネルでマッピングしています。tanh は目標に近いほど報酬が急激に上がる性質があるので、「最後の微調整」を強く動機づけます。std パラメータが小さいほど、より近距離での精度にこだわるようになります。
orientation_command_error(weight=-0.1)はエンドエフェクタの姿勢追跡です。ベースの RewardsCfg では weight=-0.1 ですが、SO-ARM101 の joint_pos_env_cfg.py で orientation の weight が 0.0 に上書きされているため、実際の学習では無効化されています。Reaching タスクでは「どの角度で到達したか」より「目標位置に届いたか」が重要なので、妥当な判断ですね。
残り 2 つの action_rate_l2 と joint_vel_l2 は、動きの滑らかさを促すペナルティです。アクションの急激な変化や関節速度を抑制することで、実機でも再現しやすい動作を学習させる狙いがあります。初期 weight は -0.0001 とかなり小さいですが、これにはカリキュラム学習が絡んでいます。
カリキュラム学習による段階的なペナルティ強化
CurriculumCfg を見ると、action_rate と joint_vel の weight が学習の進行に応じて強化されるように設定されていました。
@configclass
class CurriculumCfg:
action_rate = CurrTerm(
func=mdp.modify_reward_weight,
params={"term_name": "action_rate", "weight": -0.005, "num_steps": 4500}
)
joint_vel = CurrTerm(
func=mdp.modify_reward_weight,
params={"term_name": "joint_vel", "weight": -0.001, "num_steps": 4500}
)
最初はペナルティをほぼゼロにして「まず目標に届くこと」を優先し、4500 ステップかけて徐々にペナルティを強化して「滑らかに動くこと」を要求していく仕組みです。action_rate は -0.0001 から -0.005 へ 50 倍に、joint_vel は -0.0001 から -0.001 へ 10 倍に上がります。
この「まず大雑把にできるようにしてから、徐々に品質を求める」というアプローチは、人間の学習過程にも似ていて自然な設計だなと感じました。
Isaac Lab の 2 つのアプローチ
Isaac Lab には今回使っている Manager-Based 方式のほかに、Direct Workflow と呼ばれるアプローチもあります。Direct Workflow は DirectRLEnv を継承して _get_rewards() メソッドに報酬計算を直接実装する方式で、SoftBank さんの Physical AI 実践記事 がまさにこのアプローチを使っています。
Manager-Based は「宣言的に MDP を定義する」スタイルで、報酬の追加や weight の調整がコンフィグの変更だけで済む手軽さがあります。今回は isaac_so_arm101 のコードベースをそのまま活かしたいので、Manager-Based のまま進めます。
カスタム報酬を設計してみる
報酬設計の構造が理解できたので、いよいよ自分でカスタマイズしてみます。2 段階で進めました。
Step A: パラメータを調整する
まずは関数を変えずに weight と std だけを調整してみます。SoArm101ReachEnvCfg を継承して、__post_init__ でパラメータを上書きするだけですね。
@configclass
class SoArm101ReachCustomACfg(SoArm101ReachEnvCfg):
def __post_init__(self):
super().__post_init__()
# 距離ペナルティを強化 (-0.2 -> -0.5)
self.rewards.end_effector_position_tracking.weight = -0.5
# tanh カーネルの感度を上げる (std 0.1 -> 0.05)
self.rewards.end_effector_position_tracking_fine_grained.params["std"] = 0.05
# 序盤からある程度の滑らかさを要求 (-0.0001 -> -0.001)
self.rewards.action_rate.weight = -0.001
距離ペナルティの強化(-0.2→-0.5)、tanh 感度の引き上げ(std 0.1→0.05)、序盤からの動作平滑化(action_rate -0.0001→-0.001)の 3 点を変更しています。コード中のコメントに各値の変更内容を記載しました。
Step B: 報酬関数を追加する
次に、新しい報酬関数を自分で書いてみます。isaac_so_arm101 の mdp/rewards.py にある object_ee_distance の tanh カーネルパターンを参考にしました。
追加したのは「関節リミット回避報酬」です。各関節が可動域の端に近づくほど報酬が下がり、中央付近にいると高い報酬を返します。実機のロボットでは関節リミット付近での動作は故障リスクがあるので、シミュレーションの段階からリミットを避ける癖をつけさせる意図があります。
def joint_pos_limit_avoidance(
env: ManagerBasedRLEnv,
std: float,
asset_cfg: SceneEntityCfg = SceneEntityCfg("robot"),
) -> torch.Tensor:
"""関節が可動域リミットから離れているほど高い報酬を返す。"""
asset = env.scene[asset_cfg.name]
joint_pos = asset.data.joint_pos
soft_limits = asset.data.soft_joint_pos_limits
# 各関節の最寄りリミットまでの距離
dist_to_lower = joint_pos - soft_limits[..., 0]
dist_to_upper = soft_limits[..., 1] - joint_pos
dist_to_nearest = torch.minimum(dist_to_lower, dist_to_upper)
# tanh カーネル: リミットから遠い→~1.0、リミット付近→~0.0
return torch.mean(torch.tanh(dist_to_nearest / std), dim=-1)
object_ee_distance の tanh カーネルを参考にしていますが、あちらは 1 - tanh(d/σ)(近いほど高報酬)なのに対し、こちらは tanh(d/σ)(リミットから遠いほど高報酬)と、逆方向の設計にしています。std=0.2 で、リミットから 0.2rad(約 11 度)以内に入ると報酬が急激に下がる設定ですね。
この関数を RewardsCfg のサブクラスで新しい報酬項として登録し、Step A の調整も併せて適用します。
@configclass
class CustomBRewardsCfg(RewardsCfg):
"""既存報酬に関節リミット回避を追加。"""
joint_limit_avoidance: RewTerm = RewTerm(
func=joint_pos_limit_avoidance,
weight=0.05,
params={"std": 0.2, "asset_cfg": SceneEntityCfg("robot")},
)
@configclass
class SoArm101ReachCustomBCfg(SoArm101ReachEnvCfg):
rewards: CustomBRewardsCfg = CustomBRewardsCfg()
def __post_init__(self):
super().__post_init__()
# Step A と同じ調整も適用
self.rewards.end_effector_position_tracking.weight = -0.5
self.rewards.end_effector_position_tracking_fine_grained.params["std"] = 0.05
self.rewards.action_rate.weight = -0.001
既存のコードを壊さないように、SoArm101ReachEnvCfg を継承した新しい Cfg クラスとして実装しています。RewardsCfg のサブクラスで報酬項を追加し、環境 Cfg でそれを差し替える構成ですね。Gymnasium にカスタム環境として登録すれば、ベースラインと同じ train.py でそのまま学習を回せます。
ベースラインとカスタム報酬の比較
同一条件(64 envs、1000 iter)で 3 パターンの学習を実行して、結果を比較しました。
| 項目 | ベースライン | Custom A(パラメータ調整) | Custom B(関数追加) |
|---|---|---|---|
| position error | 0.0987 | 0.1279 | 0.0802 |
| 平均報酬 | 0.23 | -0.72 | 0.03 |
| スループット | 3,514 steps/s | 3,446 steps/s | 3,043 steps/s |
| 所要時間 | 約 9 分 | 約 9 分 | 約 9 分 |
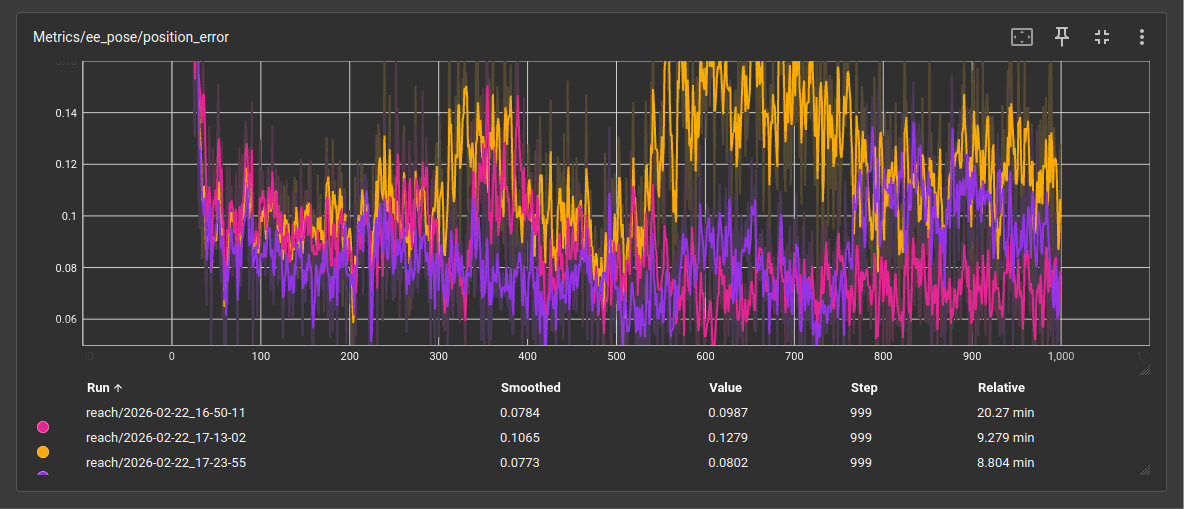
一番意外だったのは、Custom A(オレンジ) の結果です。ペナルティを強化すれば精度が上がるだろうと予想していたのですが、position error は 0.0987 → 0.1279 と逆に悪化しました。距離ペナルティの weight を -0.2 から -0.5 に上げたことで、エージェントが「罰を避ける」方向に偏り、目標への接近自体が鈍った印象です。fine_grained 報酬もベースラインの 0.0229 から 0.0023 へ激減していて、tanh カーネルの std を 0.05 に絞ったことでボーナスを獲得できる範囲が狭くなりすぎた可能性がありますね。
一方の Custom B(紫) は、Custom A と同じパラメータ調整を適用しつつ、関節リミット回避報酬を追加しただけで position error が 0.0802 とベースラインを上回りました。関節リミット回避が一種の正則化として機能して、アームを可動域の中央付近に誘導することで、結果的に目標到達の効率も良くなったようです。実際にログを見ると joint_limit_avoidance が 0.0461 と安定して報酬を獲得しており、学習の安定化に貢献しているのがわかります。
この結果から感じたのは、報酬設計では「既存のペナルティを強化する」より「別の視点の報酬を補助的に追加する」方が効果的な場合があるということです。Custom A は「もっと頑張れ」と追い立てるアプローチで、Custom B は「無理のない姿勢で動こう」と誘導するアプローチ。後者の方が学習が安定したのは、人間の学習にも通じるところがあって面白いですね。
DGX Spark aarch64 固有のハマりポイントまとめ
今回の環境構築で遭遇した DGX Spark 固有の問題を整理しておきます。
| 問題 | 原因 | 対処 |
|---|---|---|
| Isaac Sim のバイナリがない | 公式は x86_64 のみ | ソースビルド(約 13 分) |
| ビルドが失敗する | GCC 13 との非互換 | GCC 11 をインストール |
uv sync が失敗する |
ソースビルド環境の依存パッケージが PyPI にない | pip install --no-deps で回避 |
| クラッシュする(OpenMP) | libgomp のリンク問題 |
LD_PRELOAD を設定 |
| SSH 経由でハングする | XOpenDisplay が headless でも呼ばれる |
DISPLAY / XAUTHORITY を設定、またはデスクトップ環境で実行 |
| タスク名が見つからない | Isaac- プレフィックスが必要 |
README とは異なるタスク名を使用 |
| play.py でインポートエラー | Isaac Lab 0.54.3 に未実装のモジュール | try-except で回避 |
「環境構築で半日溶けた」をリアルに体験しました。この表が誰かの時間を節約できれば幸いです。
まとめ
Isaac Sim の GUI でロボットアームを触るところから始めて、既存の学習スクリプトを動かし、報酬設計のコードを読み解き、カスタム報酬で学習結果がどう変わるかを観察しました。
自分にとって一番学びが大きかったのは、報酬設計のコードリーディングですね。「tanh カーネルで近距離の精度にボーナスを与える」「カリキュラムで段階的にペナルティを強化する」といった設計パターンは、チュートリアルを読むだけでは実感が湧きにくいものでした。実際にパラメータを変えて学習結果の違いを見ることで、報酬関数が学習にどう影響するのかが体感的に理解できたかなと思っています。
DGX Spark の ARM64 環境は環境構築にそれなりの苦労がありますが、一度整えてしまえば 64 並列で約 3,500 steps/s のスループットが出ます。1000 イテレーションが約 9 分で終わるので、報酬設計を変えて→学習して→結果を見て、というサイクルを手軽に回せるのは快適でした。
次は 実際のアームの組み立て、GR00T N1.5 を使ったファインチューニングや、シミュレーションから実機へのギャップ(Sim2Real)について学んでみたいと思っています。
続編はこちら
参考リンク
- Isaac Sim GitHub
- Isaac Lab GitHub
- isaac_so_arm101 GitHub
- SO-ARM100 GitHub
- DGX Spark Isaac Playbook(GitHub)
- Install and Use Isaac Sim and Isaac Lab | DGX Spark(公式ガイド)
- Seeed Studio: Training SoArm101 Policy with IsaacLab
- Healthcare Robot Demo(CES 2026)
- SoftBank: IsaacLab で Physical AI 実践
- Isaac Lab: Creating a Manager-Based RL Environment
- Isaac Lab: Custom Reward Functions
- Isaac Sim: Basic Robot Tutorial
- 本記事のカスタム報酬スクリプト(GitHub)








