
DGX Spark の Live VLM WebUI でカメラ映像をリアルタイム解析してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
DGX Spark を使ってこれまで、ローカルコード補完や Claude Code との連携など、テキストベースの活用を中心に検証してきましたが、今回は少し趣向を変えて「映像」を扱ってみます。
Playbooks にある Live VLM WebUI を使って、Webcam の映像を VLM(Vision-Language Model)で解析してみました。
Live VLM WebUI とは
Live VLM WebUI は、DGX Spark Playbooks のマルチモーダル・Vision カテゴリに含まれるツールです。カメラからの映像を VLM でリアルタイムに解析し、その結果をブラウザ上に表示してくれます。
バックエンドには Ollama、vLLM、SGLang、NVIDIA NIM など複数のエンジンを選べます。プロンプトをカスタマイズすれば、物体検出、シーン認識、OCR、安全監視など、同じカメラ映像に対してさまざまな角度から問いかけられるのが面白いところです。
通常はブラウザの WebRTC API でカメラに直接アクセスする仕組みで、RTSP ストリーム入力にも対応しています(Beta)。今回は WebRTC 経由の Webcam 入力で検証しました。
ちなみに、NVIDIA は蓄積映像の検索・要約に特化した AI Blueprint「Video Search and Summarization(VSS)」も公開しています。「今映っているもの」をリアルタイムに言語化する Live VLM WebUI と、「過去の映像から特定のシーンを探す」VSS。用途に応じて使い分けるイメージですね。
今回の構成
すべてローカルネットワーク内で完結する構成です。今回はバックエンドに Ollama を使い、gemma3:4b と llama3.2-vision:11b の 2 モデルで比較しました。
セットアップ
VLM モデルの準備
まず Ollama で VLM モデルを用意します。最初は軽量な gemma3:4b で動作確認するのがおすすめです。
ollama pull gemma3:4b
ollama pull llama3.2-vision:11b # 比較用
Live VLM WebUI のインストール
uv tool install でシステムの Python 環境を汚さずにインストールできます。
uv tool install live-vlm-webui
v0.2.1 では 43 パッケージがインストールされ、live-vlm-webui と live-vlm-webui-stop の 2 つのコマンドが使えるようになります。
起動
Ollama をバックエンドに指定して起動します。
live-vlm-webui --model gemma3:4b --api-base http://localhost:11434/v1 --port 8090
起動すると自己署名の SSL 証明書が自動生成され、DGX Spark の GPU(NVIDIA GB10)も自動検出されます。
Initialized VLM service:
Model: gemma3:4b
API: http://localhost:11434/v1 (Local)
Starting server on 0.0.0.0:8090
Auto-detected NVIDIA GPU (NVML available)
Detected NVIDIA DGX Spark (Version 7.2.3)
ブラウザで https://<DGX Spark の IP>:8090 にアクセスすれば、WebUI が開きます。
実際に動かしてみた
デスクの上を映してみる
Webcam をデスクに向けて、「この映像に何が映っているか」を VLM に聞いてみます。デスクには DGX Spark とその箱、メカニカルキーボード、Ghana チョコレート、Xiaomi モニターを並べました。
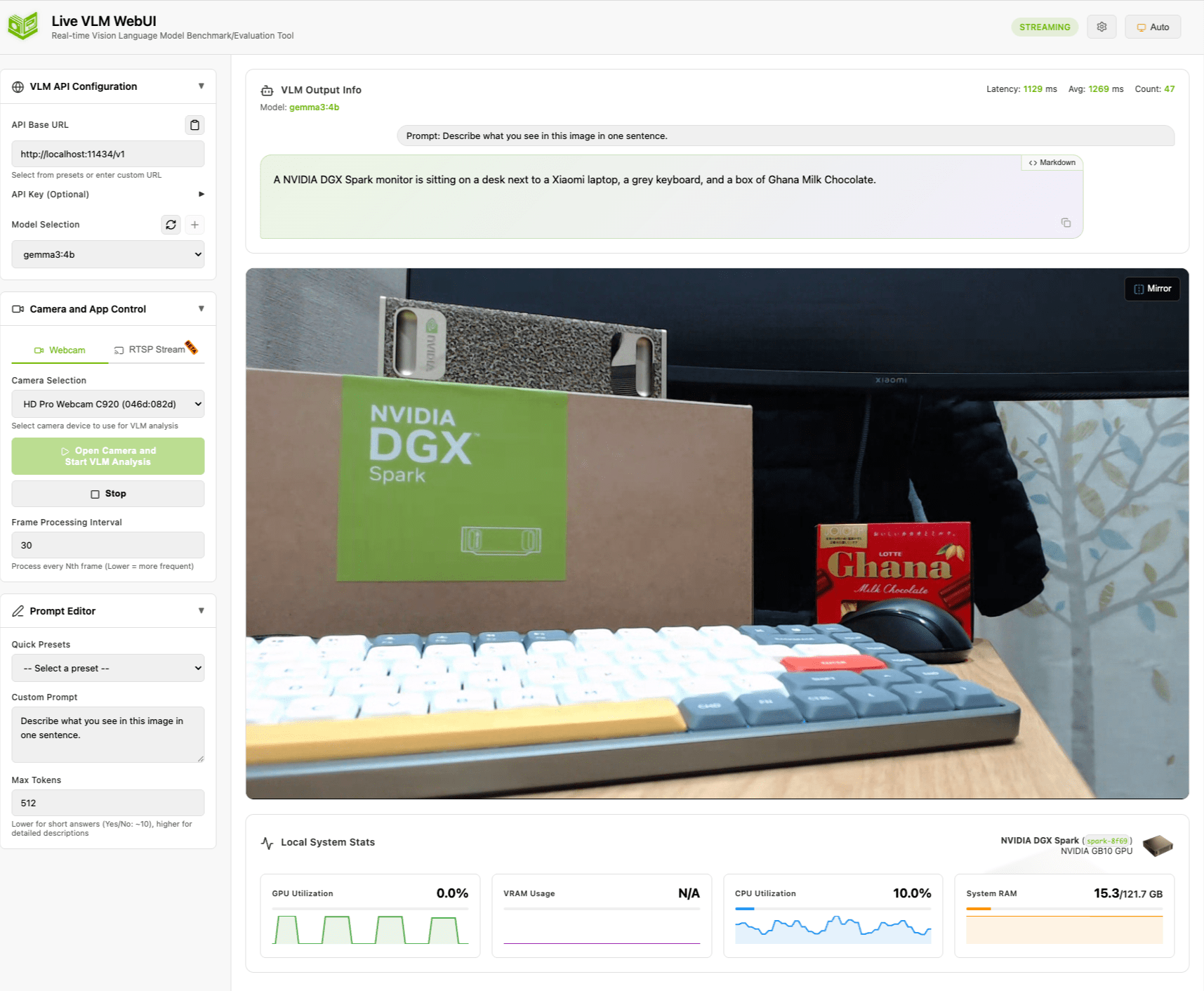
英語の 1 文プロンプト(Describe what you see in this image in one sentence.)では、こんな出力が返ってきました。
A NVIDIA DGX Spark monitor is sitting on a desk next to a Xiaomi laptop, a grey keyboard, and a box of Ghana Milk Chocolate.
DGX Spark の箱を「monitor」と誤認識していますが、Xiaomi モニター、キーボード、Ghana チョコレートはきっちり言い当てています。レイテンシは約 1,100ms。1 秒ちょっとでこの精度なら、リアルタイム解析としては十分実用的です。
プロンプトを変えてみる
同じシーンでプロンプトを変えてみました。
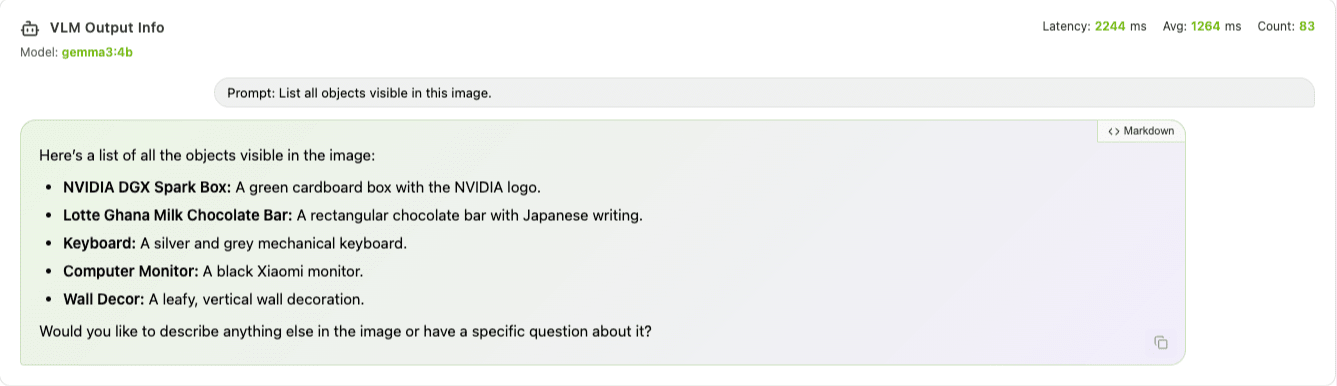
物体列挙(List all objects visible in this image.)に切り替えると、1 つ 1 つの物体を個別に説明する出力に変わります。
- NVIDIA DGX Spark Box: A green cardboard box with the NVIDIA logo.
- Lotte Ghana Milk Chocolate Bar: A rectangular chocolate bar with Japanese writing.
- Keyboard: A silver and grey mechanical keyboard.
- Computer Monitor: A black Xiaomi monitor.
- Wall Decor: A leafy, vertical wall decoration monitor.
Ghana チョコの日本語パッケージまで認識しているのは驚きました。
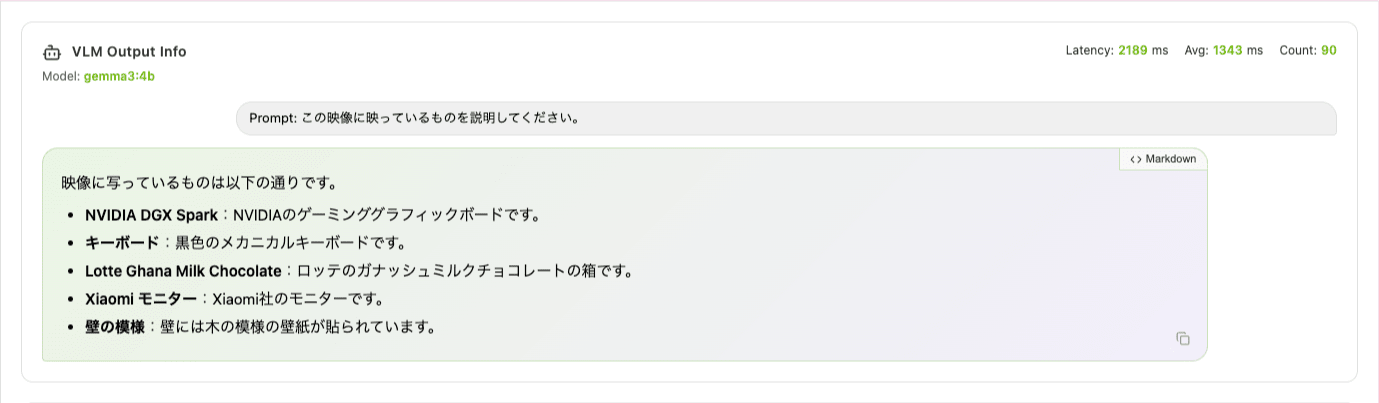
日本語プロンプト(この映像に映っているものを説明してください。)でも自然な日本語で返ってきます。
- NVIDIA DGX Spark:NVIDIA のゲーミンググラフィックボードです。
- キーボード:白色のメカニカルキーボードです。
- Lotte Ghana Chocolate:ロッテのミルクチョコレートの箱です。
- Xiaomi モニター:Xiaomi のモニターです。
- 背景には植物の模様の壁飾りが写っています。
DGX Spark を「ゲーミンググラフィックボード」と表現しているのはご愛嬌ですが、全体の認識精度は高いですね。
推論速度
gemma3:4b でのレイテンシを計測しました。30 フレームに 1 回(約 1 秒間隔)で VLM に問い合わせる設定です。
| プロンプト | レイテンシ | 体感 |
|---|---|---|
| 英語 1 文 | 約 1,100ms | ほぼリアルタイム |
| 英語リスト | 約 2,000ms | 少し待つ程度 |
| 日本語 | 約 1,100〜2,500ms | 出力量に依存 |
「数秒おきに AI が状況を言語化してくれる」という体験です。リアルタイムの映像監視というよりは、定期的な状況レポートに近い感覚ですね。
モデルを変えて比較
同じデスクのシーンで、gemma3:4b と llama3.2-vision:11b の出力を比べてみました。
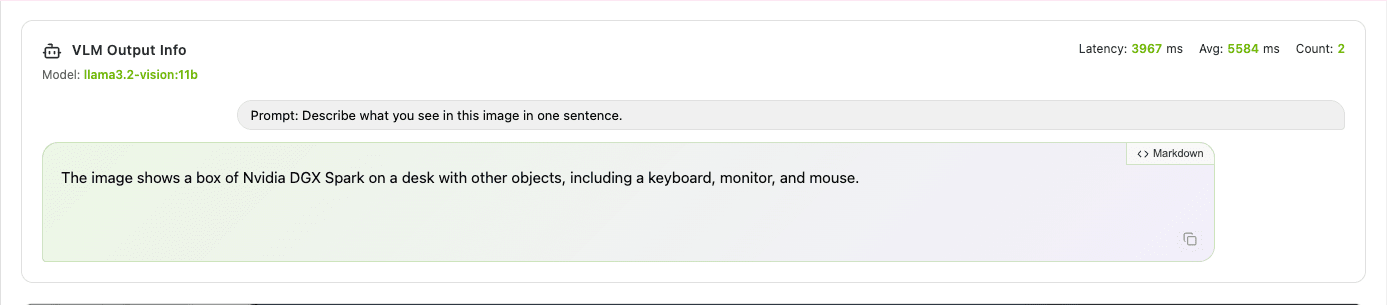
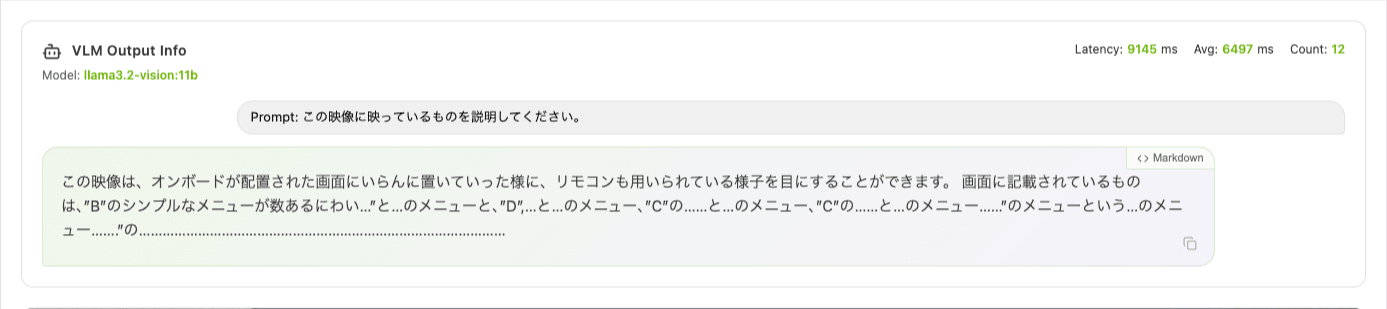
llama3.2-vision:11b の英語出力は gemma3:4b より詳細で、背景のジャケットやカーテンの模様まで認識していました。ただし、日本語プロンプトに切り替えると出力が崩壊します。
| 観点 | gemma3:4b | llama3.2-vision:11b |
|---|---|---|
| 英語の精度 | 主要な物体を正確に認識 | より詳細(9 項目)、背景まで拾う |
| 日本語対応 | 自然な日本語で出力 | 文法が崩壊、実用外 |
| レイテンシ(英語 1 文) | 約 1,100ms | 約 3,000〜4,000ms |
| GPU 使用率 | 13〜14% | 約 90% |
| メモリ使用量 | 約 15 GB | 約 54 GB |
リアルタイム映像解析では、モデルサイズを大きくすればいいというわけではなさそうです。gemma3:4b は速度と日本語対応、リソース効率のバランスが良く、DGX Spark の 128GB メモリに対して GPU 使用率 13% と余裕があります。残りのリソースで別のタスクも同時に走らせられますね。
llama3.2-vision:11b は英語限定で詳細な認識が必要なケースには向いていますが、レイテンシが 3〜4 倍に伸びるため、リアルタイム性とのトレードオフが大きいです。
エッジ AI(YOLO) との違い
ここで、VLM とは別のアプローチとの違いも整理しておきます。Seeed Studio の ReCamera 2002w のように、カメラ単体で YOLO による物体検出を実行できるエッジデバイスも増えています。実際に同じデスクのシーンを ReCamera の YOLO で検出させてみました。

ReCamera の YOLOTIn Detection では、マウスは「mouse」と正しく検出できましたが、Ghana チョコレートは「book」と誤分類されています。COCO データセットの 80 クラスに「チョコレート」は含まれないため、形状が近い「book」に割り当てられたのでしょう。DGX Spark の箱やキーボードにはバウンディングボックスが出ていません。
一方、gemma3:4b の VLM は同じシーンで「NVIDIA DGX Spark Box」「Lotte Ghana Milk Chocolate Bar」「Keyboard」「Xiaomi Monitor」と自然言語で正確に描写していました。この差がまさに YOLO と VLM のアプローチの違いです。
| 観点 | エッジ YOLO(ReCamera) | DGX Spark(VLM) |
|---|---|---|
| 出力形式 | バウンディングボックス + ラベル | 自然言語の文章 |
| 語彙 | COCO 80 クラス等、固定 | 制限なし |
| 文脈理解 | 個別の物体検出のみ | シーン全体の関係性を把握 |
| カスタム質問 | 不可 | プロンプトで自由に質問 |
| 推論速度 | 数十 ms | 1〜4 秒 |
| 必要なハードウェア | カメラ単体(USB 給電) | GPU サーバー |
「どちらが優れている」という話ではなく、用途がまったく違います。「あの物体がどこにあるか」を高速に知りたければ YOLO、「この状況を言葉で説明して」と聞きたければ VLM。YOLO は目、VLM は脳に近い役割ですね。
プロダクション環境では、YOLO で高速にフィルタリングしてから VLM に渡すパイプラインも考えられます。たとえば工場の通路でカメラが「人が映ったフレームだけ」を選別し、DGX Spark 側でヘルメットや安全装備の着用状況を確認する、といった使い方です。クラウドに映像を送らず手元のネットワークで完結するので、プライバシーの制約がある現場でもプロトタイピングしやすい構成ですね。
おまけ
Live VLM WebUI のログには、VLM の応答がタイムスタンプ付きで記録されます。起動時に tee でファイルに保存すれば、あとから認識結果の時系列変化を追えます。
live-vlm-webui --model gemma3:4b --api-base http://localhost:11434/v1 --port 8090 2>&1 | tee vlm-log.txt
試しに、デスクの上で約 2 分間、物を出し入れしてみました。プロンプトは List all objects visible in this image. です。以下はログから抽出した認識結果の抜粋です。
18:25:41 Nvidia DGX Spark box, notebook, chocolate box (Lotte Ghana Milk Chocolate),
keyboard, computer monitor, desk, jacket. (1307ms)
18:25:59 Nvidia DGX Spark box, Keyboard, Mouse, Bottle of Kirin Lemon Tea,
Box of Japanese sweets (1253ms)
18:26:03 NVIDIA DGX Spark box, bottle of Kirin tea, keyboard, mouse, desk,
plant, plant pot, tea bag. (1538ms)
18:26:09 NVIDIA DGX Spark box, water bottle, LOTTE Ghana Milk Chocolate box,
keyboard, mouse, monitor, USB cable, reflection (1377ms)
18:26:33 Nvidia DGX Spark box, monitor, keyboard, mouse, desk, cardboard,
shadows (1181ms)
18:26:53 Nvidia DGX Spark box, computer monitor, computer keyboard,
computer mouse, two paper cups, plant, cables (1329ms)
18:27:41 Nvidia DGX Spark box, plush toy (blue whale), keyboard, mouse,
computer monitor, cable, gray speaker. (1366ms)
18:27:56 Box, Keyboard, Mouse, Phone, Computer monitor, Wall, Tree (1166ms)
18:28:05 NVIDIA DGX Spark box, bottle of tea, computer monitor,
computer keyboard, computer mouse, desk, water, background blur. (1351ms)
飲み物を置けば「Bottle of Kirin Lemon Tea」、ぬいぐるみを置けば「plush toy (blue whale)」、スマホを出せば「Phone」と、物の出し入れに対して 1〜2 秒で認識が更新されていきます。ぬいぐるみの種類が「blue whale」「plush shark」「plush dolphin」とフレームごとに揺れるのは、4B パラメータモデルの限界が見えて面白いところです。
一方で、DGX Spark の箱やキーボードなど常にフレームに映っている物体は安定して認識され続けています。レイテンシも 1,100〜1,500ms の範囲に収まっており、約 2 分間で 58 フレーム分の解析がログに残りました。
このログを集計すれば、「特定の物体がどのフレームで認識されたか」「認識の安定性はどうか」といった定量的な分析もできます。簡易的な映像モニタリングのプロトタイプとしては、十分に使えそうな手応えでした。
まとめ
Live VLM WebUI を DGX Spark にインストールして、カメラ映像のリアルタイム VLM 解析を試してみました。
セットアップは手軽です。uv tool install 1 行でインストールが完了し、Ollama と組み合わせてすぐに動かせます。gemma3:4b であれば約 1 秒間隔で映像を解析でき、日本語プロンプトにもきちんと対応しています。GPU 使用率 13% 程度に収まるので、DGX Spark の 128GB メモリを他のワークロードと共有しながら使えるのは大きいです。
一方で、llama3.2-vision:11b は英語では詳細な認識ができるものの、日本語の出力が崩壊する点と、レイテンシが 3〜4 倍になる点はリアルタイム用途では厳しいと感じました。個人的には「大きいモデル=常に良い」とは限らないのが、今回一番面白い発見でした。
映像を扱う VLM の進化は早いので、モデルが世代交代すればこのあたりの制約も変わってくるはずです。IP カメラの RTSP ストリームと組み合わせたり、エッジ側の YOLO と連携させたり、アイデア次第で色々なことに挑戦できそうです。
今回の検証環境
| 項目 | スペック |
|---|---|
| DGX Spark | 128GB LPDDR5x、GB10(Grace Blackwell) |
| Live VLM WebUI | v0.2.1 |
| VLM モデル | gemma3:4b / llama3.2-vision:11b |
| バックエンド | Ollama |
| カメラ | HD Pro Webcam C920(1080p) |
| 比較デバイス | Seeed Studio ReCamera 2002w(YOLO) |










