
NVIDIA NemoClaw を DGX Spark で動かしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
先日の GTC 2026 現地レポートで、NVIDIA が発表したオープンソースの AI エージェントセキュリティスタック「NemoClaw」を紹介しました。
GTC も終わり帰国の前にさっそく DGX Spark で試してみました。今回は概念の話ではなく、インストールからエージェントとのチャットまで手を動かした記録です。
NemoClaw のおさらい
NemoClaw の詳細は前回の GTC レポート記事で解説しているので、ここでは今回の検証に必要な部分だけ簡単に振り返ります。
NemoClaw は OpenClaw(AI エージェントフレームワーク)に NVIDIA 製のセキュリティレイヤーを追加するオープンソースプラグインです。核心は OpenShell というセキュアランタイムで、sandbox(Landlock + seccomp による OS レベル隔離)、ポリシーエンジン(制約の適用と更新提案)、プライバシールーター(機密データのローカルモデル振り分け)の 3 層で構成されています。
今回のゴールは、DGX Spark 上で NemoClaw をセットアップし、Ollama 経由の Nemotron 3 Super でローカル完結のセキュアエージェント環境を動かすことです。NVIDIA が公開している DGX Spark Playbook に沿って進めていきます。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark(GB10) |
| メモリ | 128GB 統合メモリ |
| OS | Ubuntu 24.04 LTS |
| Docker | 29.1.3 |
| NVIDIA Driver | 580.126.09 |
| Node.js | v22.22.0 |
| Ollama | 0.17.2 |
| 推論モデル | Nemotron 3 Super 120B-A12B(Q4_K_M, Ollama) |
DGX Spark では既に Ollama 経由で Nemotron 3 Super が動いています。この環境に NemoClaw を追加する形で進めます。Ollama の OLLAMA_HOST=0.0.0.0 設定も済んでいるので、sandboxからの接続準備はできています。
DGX Spark の基本的なセットアップや Nemotron 3 Super の導入については、過去の記事もご参照ください。
DGX Spark にインストールする
NVIDIA が公開している DGX Spark Playbook に 14 ステップの手順がまとまっています。Docker、Node.js 22、Ollama のインストールから丁寧に書かれているので、DGX Spark を初めて触る方はそちらから始めるのが確実です。
自分の環境ではこれらが導入済みなので、NemoClaw 固有のインストールから始めます。
OpenShell CLI のインストール
NemoClaw のsandboxランタイムである OpenShell の CLI をインストールします。
curl -LsSf https://raw.githubusercontent.com/NVIDIA/OpenShell/main/install.sh | sh
openshell: resolving latest version...
openshell: downloading openshell v0.0.11 (aarch64-unknown-linux-musl)...
openshell: verifying checksum...
openshell: extracting...
openshell: installed openshell 0.0.11 to /home/morishige/.local/bin/openshell
ARM64 の DGX Spark では、インストールスクリプトが自動的に aarch64 向けバイナリをダウンロードしてくれました。
NemoClaw のインストール
NemoClaw 自体は GitHub リポジトリを clone して npm でグローバルインストールする方式です。
cd ~
git clone https://github.com/NVIDIA/NemoClaw.git
cd NemoClaw
sudo npm install -g .
added 1 package in 452ms
DGX Spark 向けセットアップ
NemoClaw には DGX Spark 向けの専用セットアップコマンドが用意されています。
sudo nemoclaw setup-spark
内部では Docker の cgroup 名前空間モードの設定(OpenShell が k3s をコンテナ内で動かすために必要)やユーザーの Docker グループ追加を自動で行ってくれます。初回実行時に NVIDIA API Key の入力を求められるので、build.nvidia.com で無料キーを発行して入力します。ローカルの Ollama だけで使う場合でも、CLI のゲートとして必要です。
オンボーディングウィザード
nemoclaw onboard を実行すると、7 ステップのセットアップウィザードが走ります。
cd ~/NemoClaw
nemoclaw onboard
ウィザードは 7 ステップで進みます。実際にやってみた流れを紹介します。
Step 1: Preflight
✓ Docker is running
✓ Container runtime: docker
✓ openshell CLI: openshell 0.0.11
✓ Port 8080 available (OpenShell gateway)
✓ Port 18789 available (NemoClaw dashboard)
✓ NVIDIA GPU detected: 1 GPU(s), 124610 MB VRAM
DGX Spark の Playbook には「No GPU detected と表示されることがある」と書かれていましたが、自分の環境では 124,610 MB(約 122GB)として正常に認識されました。統合メモリの報告方式は環境によって異なるようです。
なお、port 18789 は NemoClaw のダッシュボードが使うポートです。他のコンテナが使っていると Preflight でブロックされるので、事前に確認しておくとよいですね。
Step 2: Gateway
OpenShell のゲートウェイコンテナが起動します。初回はイメージのダウンロードが入るので 30-60 秒ほどかかりました。
Step 3: Sandbox
sandbox名を入力します(デフォルトは my-assistant)。NemoClaw の Dockerfile から Docker イメージをビルドし、sandboxを作成します。初回ビルドでは Node.js 22-slim ベースイメージの上に Python 3、Git、OpenClaw、NemoClaw プラグインなどがインストールされます。ARM64 の DGX Spark でもビルドは問題なく完了しました。イメージサイズは約 1.5GB で、ゲートウェイへのアップロードを含めて 5 分ほどかかりました。
Step 4: Inference
ローカルの推論エンジンを自動検出してくれます。Ollama が動いていれば候補に表示されるので、選択します。
Inference options:
1) NVIDIA Cloud API (build.nvidia.com)
2) Local Ollama (localhost:11434) — running (suggested)
Choose [1]: 2
モデルの一覧も Ollama から自動取得されます。自分の環境では 36 個のモデルが表示されました。ここで nemotron-3-super を選択します。
Step 5: Inference provider
ollama-local プロバイダーが自動作成され、推論ルートが設定されます。
Route: inference.local
Provider: ollama-local
Model: nemotron-3-super:latest
Step 6: OpenClaw
sandbox内で OpenClaw ゲートウェイが自動起動します。
Step 7: Policies
ネットワークポリシーのプリセットを選択します。pypi と npm はデフォルトで提案され、ホスト環境の環境変数(今回は SLACK_BOT_TOKEN)を検出して追加のプリセットも提案してくれました。
セットアップが完了すると、sandboxの情報が表示されます。
──────────────────────────────────────────────────
Sandbox my-assistant (Landlock + seccomp + netns)
Model nemotron-3-super:latest (Local Ollama)
NIM not running
──────────────────────────────────────────────────
Run: nemoclaw my-assistant connect
Status: nemoclaw my-assistant status
Logs: nemoclaw my-assistant logs --follow
──────────────────────────────────────────────────
全体で約 17 分でした。初回はイメージビルドがあるので時間がかかりますが、2 回目以降はキャッシュが効くのでもっと速いはずです。
推論モデルを変更したい場合
今回はオンボーディングウィザードの Step 4 で直接 nemotron-3-super を選択しました。Playbook のデフォルトは nemotron-3-nano ですが、DGX Spark の 128GB 統合メモリがあれば Super も問題なく動きます。
後からモデルを変更したい場合は、以下のコマンドで推論ルートを切り替えられます。
openshell inference set \
--provider ollama-local \
--model nemotron-3-super:latest \
--no-verify
--no-verify は、host.openshell.internal がsandbox内部からのみ名前解決されるため、ホスト側からの検証をスキップするフラグです。
プロバイダーが未作成の場合は、手動で作成します。
openshell provider create \
--name ollama-local \
--type openai \
--credential "OPENAI_API_KEY=ollama" \
--config "OPENAI_BASE_URL=http://host.openshell.internal:11434/v1"
現在の設定は openshell inference get で確認できます。
エージェントを動かしてみる
コマンドラインから実行
まずsandboxに接続して、コマンドラインからエージェントを試してみます。
nemoclaw my-assistant connect
sandbox内で:
export NVIDIA_API_KEY=local-ollama
export ANTHROPIC_API_KEY=local-ollama
openclaw agent --agent main --local -m "Say hello in Japanese" --session-id s1
こんにちは!
real 0m14.423s
Nemotron 3 Super でモデルがロード済みであれば 14 秒ほどで応答が返ってきました。nvidia-smi で確認すると、Ollama が約 89,734 MiB(約 87.6GB / 128GB)を使用していました。初回はモデルロードに時間がかかるので、少し待つ必要があります。
NVIDIA_API_KEY と ANTHROPIC_API_KEY にダミー値を設定しているのは、OpenClaw が API キーの存在チェックを行うためです。実際の推論は Ollama にルーティングされるので、有効なキーである必要はありません。
ついでに、sandboxのネットワーク隔離も確認してみます。
# sandbox内で実行
curl -sI https://httpbin.org/get
HTTP/1.1 403 Forbidden
ちゃんとブロックされています。OpenShell のネットワークポリシーが効いていて、オンボーディングで許可した pypi、npm、slack 以外への外部アクセスは遮断されます。sandbox内のエージェントが意図しない外部通信を行うリスクを抑えてくれるわけですね。
OpenClaw TUI で対話する
コマンドラインで単発の質問を投げるだけでなく、対話的に使うこともできます。sandboxに接続した状態で OpenClaw の TUI を起動します。
# sandbox内で
openclaw tui
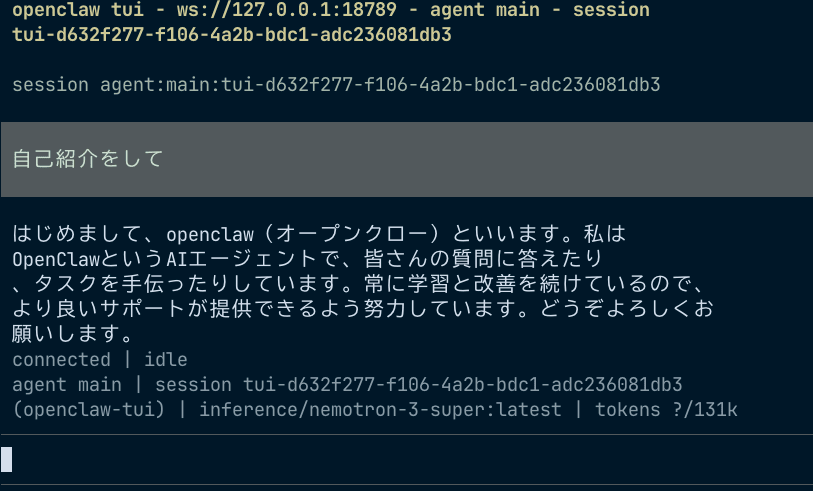
OpenShell TUI でモニタリング
別ターミナルでホスト側から OpenShell の TUI を起動すると、sandboxのアクティビティをリアルタイムで監視できます。
openshell term
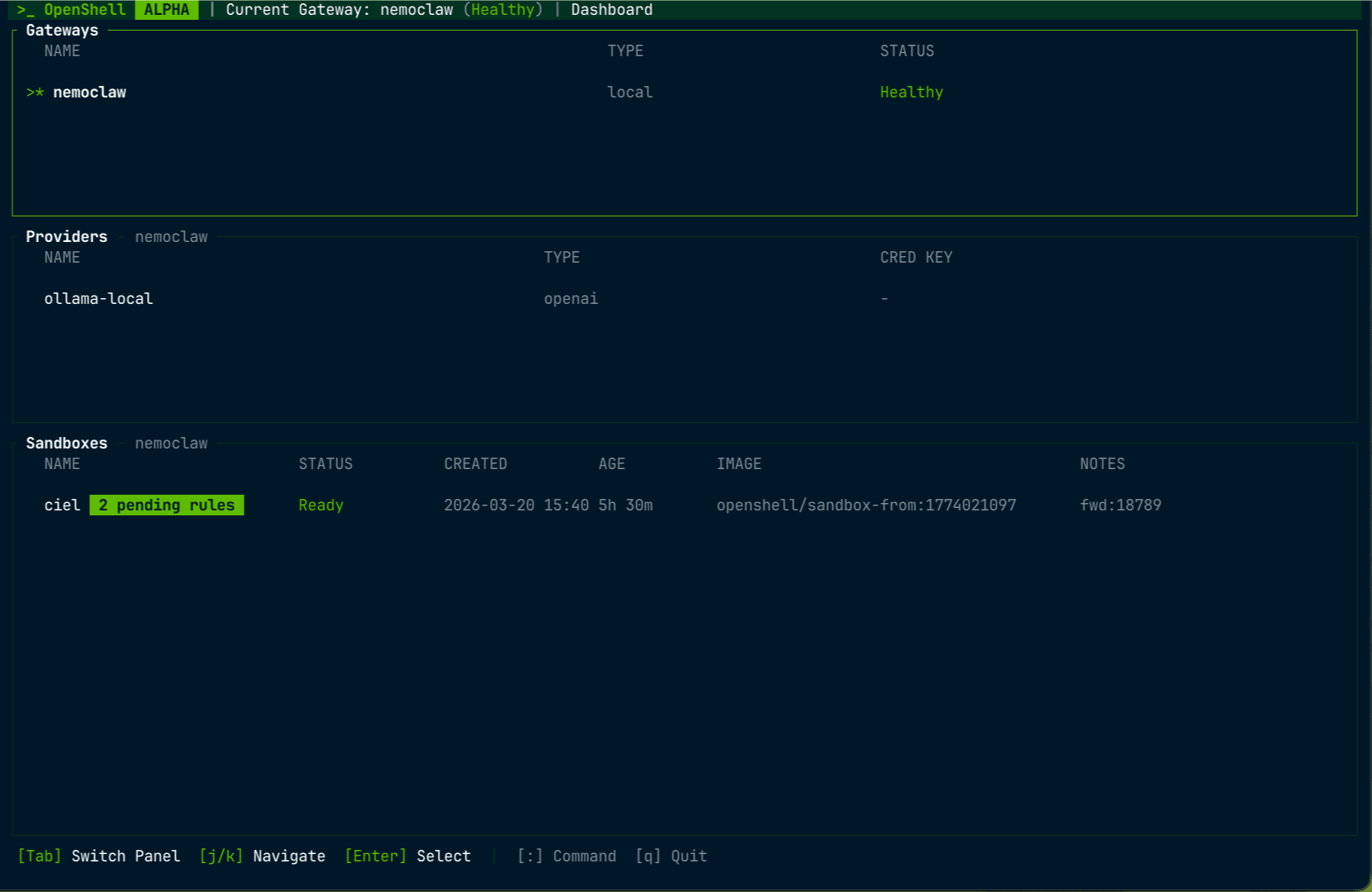
f でフォロー、s でソースフィルタ、q で終了です。
ブラウザのダッシュボードを使う
OpenClaw にはブラウザベースのチャット UI も付属しています。オンボーディングで port 18789 のフォワーディングが自動設定されているので、ダッシュボード URL を取得してブラウザで開きます。
sandbox内で:
openclaw dashboard
🦞 OpenClaw 2026.3.11 (29dc654)
Dashboard URL: http://127.0.0.1:18789/#token=29f18ce9...
表示された URL をブラウザで開くと、OpenClaw のチャット UI が表示されます。#token=... のハッシュフラグメントを含む完全な URL をそのまま使う必要がある点に注意してください。
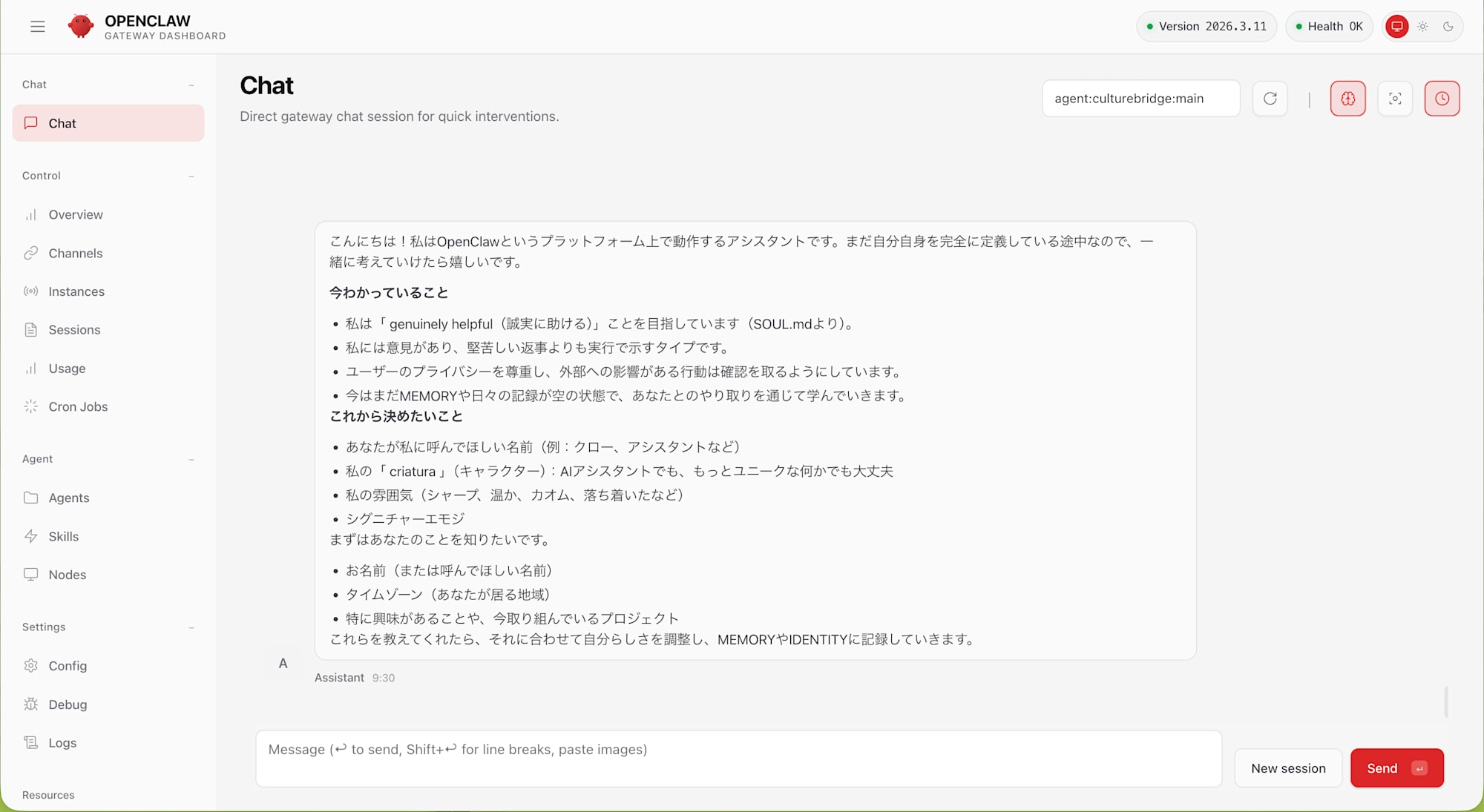
sandbox の運用 Tips
セットアップが終わればエージェントとのやり取りは快適ですが、開発やカスタマイズの段階ではいくつか知っておくと助かるポイントがあります。
ファイルの出し入れ
sandbox 内は最小限の環境で、vi や nano といったエディタも入っていません。設定ファイルの編集やスクリプトの配置は、ホスト側で作業してから openshell sandbox upload で送り込む流れになります。
# ホスト → sandbox にファイルを送る
openshell sandbox upload my-assistant ./my-file.txt /sandbox/
# sandbox → ホストにファイルを取得する
openshell sandbox download my-assistant /sandbox/output.txt ./
ディレクトリごとアップロードする場合、.gitignore のルールがデフォルトで適用されるので node_modules 等が含まれる心配はありません。無効にしたい場合は --no-git-ignore フラグを使います。
VS Code Remote-SSH で接続する
openshell sandbox ssh-config コマンドで SSH config エントリを生成できます。これを ~/.ssh/config に追記すれば、VS Code の Remote-SSH 拡張から sandbox に直接接続して、ファイル編集やターミナル操作ができるようになります。
openshell sandbox ssh-config my-assistant >> ~/.ssh/config
sandbox の管理
# sandbox の状態確認
nemoclaw my-assistant status
# ログの確認(リアルタイム追従)
nemoclaw my-assistant logs --follow
# sandbox の削除(やり直したい場合)
nemoclaw my-assistant destroy
ゲートウェイを含めて完全にクリーンな状態に戻すには:
openshell sandbox delete my-assistant
openshell gateway destroy -g nemoclaw
その後 nemoclaw onboard を再実行すれば、最初からやり直せます。
アーキテクチャの整理
DGX Spark 上の NemoClaw は以下のような入れ子構造で動作しています。
DGX Spark (Ubuntu 24.04, cgroup v2)
└── Docker (29.x, cgroupns=host)
└── OpenShell gateway container
└── k3s (embedded)
└── nemoclaw sandbox pod
└── OpenClaw agent + NemoClaw plugin
Docker の中で k3s が動き、その中にsandboxの Pod が立つという構造です。nemoclaw setup-spark が Docker の cgroup 名前空間モードを設定してくれるのは、この k3s が cgroup v1 スタイルのパスを期待するためですね。
OpenShell のセキュリティ隔離は 4 層で構成されています。
| 層 | 保護対象 | タイミング |
|---|---|---|
| ファイルシステム | 許可パス外の読み書きをブロック | sandbox作成時に固定 |
| ネットワーク | 未許可の外部接続をブロック | ランタイムでホットリロード可能 |
| プロセス | 権限昇格や危険な syscall をブロック | sandbox作成時に固定 |
| 推論 | モデル API 呼び出しを制御されたバックエンドにルーティング | ランタイムでホットリロード可能 |
ハマりどころと対処法
DGX Spark で NemoClaw を動かす際に遭遇した問題と、Playbook に記載されている既知の問題をまとめます。
ダッシュボードのポート衝突
NemoClaw のダッシュボードは port 18789 をハードコードで使用します。自分の環境ではハッカソンで使った別のコンテナがこのポートを占有していて、Preflight で弾かれました。事前に ss -tlnp | grep 18789 で確認しておくと安心ですね。
ゲートウェイのポート衝突
port 8080 を使用しているコンテナがあると、ゲートウェイの起動に失敗します。古いゲートウェイが残っている場合は openshell gateway destroy -g nemoclaw で削除できます。
OpenShell forward が dead になる
セットアップ後しばらくすると、ダッシュボードへのポートフォワードが dead になることがありました。openshell forward list で確認して、dead になっていたら再起動します。
openshell forward stop 18789 my-assistant
openshell forward start --background 18789 my-assistant
Ollama にsandboxから到達できない
Ollama がデフォルトの localhost のみでリッスンしている場合、sandboxからアクセスできません。OLLAMA_HOST=0.0.0.0 の設定が必要です。
sudo mkdir -p /etc/systemd/system/ollama.service.d
printf '[Service]\nEnvironment="OLLAMA_HOST=0.0.0.0"\n' | sudo tee /etc/systemd/system/ollama.service.d/override.conf
sudo systemctl daemon-reload && sudo systemctl restart ollama
リモートアクセス時の origin エラー
SSH トンネル経由でダッシュボードにアクセスすると origin not allowed エラーが出ました。これは nemoclaw-start.sh が CHAT_UI_URL のデフォルト値 http://127.0.0.1:18789 のみを allowedOrigins に設定するためです。ブラウザからは http://localhost:18789 でアクセスしますが、127.0.0.1 と localhost は別オリジンとして扱われます。
対処は、sandbox内で CHAT_UI_URL を指定してゲートウェイを再起動するだけです。
# sandbox内で
export NVIDIA_API_KEY=local-ollama
export ANTHROPIC_API_KEY=local-ollama
export CHAT_UI_URL=http://localhost:18789
nemoclaw-start
パフォーマンス所感
Nemotron 3 Super と Nano の 2 モデルで、Ollama API 直接呼び出し、OpenClaw CLI、Web ダッシュボードの 3 パターンを計測してみました。
| モデル | Ollama API 直接 | OpenClaw CLI | Web チャット |
|---|---|---|---|
| Nano(30B / 3B active) | 0.6 秒 | 15 秒 | 約 1 分 |
| Super(120B / 12B active) | 5 秒 | 14 秒 | 約 5 分 |
Ollama API を直接叩けばどちらのモデルも十分実用的な速度です。一方で OpenClaw エージェント経由だと、CLI で 14-15 秒、Web チャットで 1-5 分かかります。これはモデルの推論時間というより、エージェントの起動、プラグインのロード、プランニングの複数回推論コールなど、エージェントフレームワークとしてのオーバーヘッドが支配的です。
Nemotron 3 Super は reasoning_effort パラメータに対応しています。Ollama API の think パラメータで制御でき、think: false にすると推論トークンの生成がスキップされて 10 秒 → 5 秒に高速化しました。ただし、OpenClaw エージェント経由で reasoning を無効化すると、モデルの判断力が落ちてエージェントのプランニングループが増え、逆に 14 秒 → 2 分 47 秒と大幅に遅くなりました。エージェント利用時は reasoning ON のままにしておくのが正解のようです。
メモリ使用量は nvidia-smi で確認すると、Super が約 89,734 MiB(約 87.6 GB)、Nano が約 27 GB でした。DGX Spark の 128 GB 統合メモリなら Super も問題なく動きますが、他のサービスと同居させるなら Nano の方が余裕がありますね。
「とにかく動くことを確認したい」なら Super でも問題ありませんが、日常的にエージェントとして使い込むなら Nano の方がストレスが少ないかなという印象です。
まとめ
DGX Spark 上で NemoClaw Early Preview のインストールからエージェント実行まで一通り試してみました。
動いたことを振り返ると、ARM64 の DGX Spark で OpenShell のsandboxが問題なく構築でき、Ollama 経由のローカル推論でエージェントが動作し、ネットワーク隔離も正常に機能していました。ダッシュボードの Web UI からチャットもできますし、コマンドラインからの実行にも対応しています。「ローカルで完結するセキュアなエージェント環境」という NemoClaw のコンセプトが DGX Spark 上で実現できることは確認できました。
一方で、Early Preview ならではの荒削りな部分もいくつかありました。リモートアクセス時の origin エラー、ポートフォワードが dead になる問題、NVIDIA API Key がローカル利用でも要求される点など、ドキュメントだけでは分からないハマりどころがそれなりにあります。リポジトリ内の spark-install.md や DGX Spark Playbook を併せて参照すると、だいぶスムーズに進められるかなと思います。
パフォーマンスに関しては、120B の Super モデルでも「動く」ことは DGX Spark の 128 GB 統合メモリの恩恵ですが、エージェントとしての体験を重視するなら Nano の方が現実的です。ただ、ここはエージェントフレームワーク側の最適化が進めば改善される余地がありそうです。
NemoClaw はまだ Early Preview の段階ですが、OpenShell のセキュリティモデル(プロセス外ポリシー強制)は GA になったときにかなり強力な基盤になりそうな予感がしています。エージェント AI がエンタープライズで本格的に使われる時代に向けて、こういった「安全に試せるsandbox」が手元のハードウェアで動くのは心強いですね。
参考リンク
公式ドキュメント
- NVIDIA NemoClaw 製品ページ
- NemoClaw Developer Guide
- NemoClaw Architecture Reference
- GitHub - NVIDIA/NemoClaw
- DGX Spark Playbooks - NemoClaw
- OpenShell テクニカルブログ








