SAM 3.1 を DGX Spark で動かしてゼロショット物体検出を試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
物体検出といえば YOLO が定番ですが、YOLO を使うには学習データを集めてアノテーションして何十 epoch も回す必要があります。「とりあえず試したいだけなのに、準備が重い……」と感じたことがある方も多いのではないでしょうか。
今回紹介する SAM 3.1 は、Meta が公開した Segment Anything シリーズの最新版です。テキストプロンプトで「hard hat」「safety vest」のように検出したいものを指定するだけで、学習データなしに BBox(バウンディングボックス)とセグメンテーションマスクを返してくれます。2026 年 3 月にリリースされた 3.1 では、動画の複数オブジェクト追跡も最大 7 倍高速化されています。
この記事では、SAM 3.1 を DGX Spark(ARM64)で動かして、5 つの異なるシーンでゼロショット検出を試した結果を紹介します。後半では動画追跡の速度も軽く検証してみました。
SAM 3.1 とは
SAM 3(Segment Anything Model 3)は Meta が 2025 年 11 月に公開した第 3 世代のセグメンテーションモデルで、正式名称は「Segment Anything with Concepts」です(arXiv:2511.16719)。848M パラメータで、GitHub にて公開されています。
2026 年 3 月 25 日にリリースされた SAM 3.1 は、SAM 3 に Object Multiplexing を追加したアップデートです。複数オブジェクトの動画追跡が最大 7 倍高速化されており(16 オブジェクトを 1 回のフォワードパスで処理、H100 で 32 FPS)、精度や API は SAM 3 と同等のドロップイン置き換えになっています。画像検出の API やチェックポイントは SAM 3 と共通なので、今回の画像検出結果はどちらでも同じです。
ライセンスは Apache 2.0 でも MIT でもなく、Meta 独自の「SAM License」です。商用利用は基本的に可能ですが、軍事や核産業など安全保障関連の用途は明確に禁止されています。本番投入を検討する際は LICENSE 全文を確認してください。
学習データの規模も印象的で、数百万枚の画像と数万本の動画から構成される大規模な SA-Co データセットで訓練されています。LVIS ベンチマークではゼロショットで AP 47.0 を記録しています。
SAM シリーズの進化
SAM から SAM 3 までの進化をざっくりまとめると、こんな流れです。
| 世代 | リリース | 主な入力 | 出力 | 特徴 |
|---|---|---|---|---|
| SAM | 2023 年 | ポイントやボックス | マスク | 画像のみ対応 |
| SAM 2 | 2024 年 | ポイントやボックス | マスク | 動画対応(フレーム間追跡) |
| SAM 3 | 2025 年 | テキスト(概念プロンプト)や画像見本 | マスク + BBox + スコア | ゼロショット検出、動画追跡 |
SAM と SAM 2 は「この点をクリック」「この四角の中を切り出して」のように、場所を指定してセグメンテーションするモデルでした。テキストプロンプトで検出するには、Grounded-SAM-2 のように GroundingDINO で BBox を検出してから SAM 2 に渡す、という外部パイプラインが必要でした。
一方 SAM 3 では、テキストプロンプトがネイティブにサポートされています。「hard hat」のようなテキストを渡すだけで、画像内の該当オブジェクトを検出してくれます。Meta はこれを Promptable Concept Segmentation(PCS) という新しいタスクとして定義しました。画像や動画内の指定された概念に一致する全インスタンスを網羅的に検出、セグメント化するものです。GroundingDINO + SAM 2 の多段パイプラインを 1 つのモデルに統合したようなイメージですね。
内部的には DETR ベースの検出器と SAM 2 由来のトラッカーが単一のバックボーンを共有しており、画像検出と動画追跡の両方を 1 つのモデルで扱えるようになっています。
YOLO との違い
ここで気になるのが、YOLO と何が違うのかという点です。テキストプロンプトで物体検出ができるモデルは GroundingDINO や YOLO-World など他にもありますが、SAM 3 は単一モデルでテキストから BBox + マスク + 動画追跡まで完結する点が強みです。ここでは代表的な YOLO と比較してみます。
| 観点 | YOLO(v8m 等) | SAM 3 |
|---|---|---|
| 設計思想 | クローズドセット(固定クラス) | オープン語彙(ゼロショット) |
| 学習データ | 必要(アノテーション + 学習) | 不要(テキストプロンプト) |
| 検出クラスの変更 | 再学習が必要 | プロンプトを変えるだけ |
| 推論速度 | 高速(53fps @Jetson FP16) | 1-2 秒/画像 @DGX Spark |
| 出力 | BBox | BBox + ピクセル単位マスク + スコア |
| マスク境界品質 | IoU 閾値で精度が大きく変動 | 約 12 倍安定(閾値変化に強い) |
| エッジ推論 | 可(Jetson、数 MB〜) | 困難(848M パラメータ、VRAM 3.3 GiB) |
| 精度(ゼロショット vs FT) | FT 済みで F1 68-72% | ゼロショットで F1 59.8% |
リンゴカウントデータセットでの比較研究(arXiv:2512.11884)によると、ファインチューニング済み YOLO11 が F1 68-72% に対して、ゼロショット SAM3 は 59.8% と YOLO が上回ります。ただし、マスクの境界品質は SAM3 の方が約 12 倍安定しており、IoU 閾値を変えても SAM3 は 4 ポイントしか落ちないのに対し、YOLO は 48-50 ポイント落ちるという結果が出ています。
どちらが優れているという話ではなく、そもそもの設計思想が違います。YOLO は「速くて軽い専門家」、SAM 3 は「知識は広いが重い万能家」というイメージですね。YOLO は学習データがあって高速リアルタイム検出が必要な場面に強く、SAM 3 は「まず試してみる」「未知のクラスに対応したい」「ピクセル精度のマスクがほしい」といった場面に向いています。
今回の検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark |
| GPU | NVIDIA GB10(Grace Blackwell、128GB 統合メモリ) |
| OS | Ubuntu 22.04(ARM64/SBSA) |
| CUDA | 12.8 |
| コンテナ | NGC PyTorch 26.03(nvcr.io/nvidia/pytorch:26.03-py3) |
| SAM3 | facebookresearch/sam3(pip install) |
| VRAM 使用量 | 約 3.3 GiB |
DGX Spark で SAM 3.1 を動かす
Dockerfile
SAM 3.1 の API サーバーを立てる Dockerfile はこんな感じです。
FROM nvcr.io/nvidia/pytorch:26.03-py3
# SAM 3.1 の動画追跡用(画像検出のみなら不要)
RUN pip install --no-cache-dir flash-attn \
--index-url https://pypi.jetson-ai-lab.dev/sbsa/cu128
RUN pip install --no-cache-dir \
einops psutil pycocotools fastapi uvicorn[standard] \
&& pip install --no-cache-dir git+https://github.com/facebookresearch/sam3.git
COPY server.py /app/server.py
WORKDIR /app
EXPOSE 8105
CMD ["python", "server.py"]
NGC PyTorch 26.03 をベースにして、SAM 3 と FastAPI をインストールしています。flash-attn は SAM 3.1 の動画追跡(Multiplex Video Predictor)で必要になるため、Jetson AI Lab の ARM64 wheel から入れています。画像検出だけなら省略可能です。
SAM 3 のリポジトリには ARM64 で decord パッケージの wheel がないという Issue が上がっていますが、decord は動画デコード用のオプション依存なので、pip install 自体は問題なく通ります。
DGX Spark 固有の dtype パッチ
ここからが本題です。SAM 3 を DGX Spark の GB10 GPU で動かすには、2 つのモンキーパッチが必要でした。
import torch.nn.functional as F
# F.linear: 入力テンソルを weight の dtype に合わせる
_orig_linear = F.linear
def _safe_linear(input, weight, bias=None):
return _orig_linear(input.to(weight.dtype), weight, bias)
F.linear = _safe_linear
# F.scaled_dot_product_attention: 出力を query の dtype に戻す
_orig_sdpa = F.scaled_dot_product_attention
def _safe_sdpa(q, k, v, *a, **kw):
return _orig_sdpa(q, k, v, *a, **kw).to(q.dtype)
F.scaled_dot_product_attention = _safe_sdpa
パッチなしで実行すると RuntimeError: expected scalar type BFloat16 but found Float のようなエラーが出ます。DGX Spark の GB10 は mixed precision の挙動が x86 環境と異なるようで、F.linear の入力と weight の dtype が食い違うケースがありました。同様に scaled_dot_product_attention の出力 dtype も query 側に合わせてやる必要があります。
この 2 つのパッチを from sam3... の import より前に適用すれば、あとは問題なく動きます。DGX Spark で新しいモデルを動かすときに、同様の dtype 不整合に遭遇するケースは他にもあったので(Cosmos-Reason2-8B のときもそうでした)、しばらくは ARM64 環境で PyTorch モデルを動かす際のお作法として覚えておくとよいのかもしれません。
API サーバー
検出 API は FastAPI で構成しました。
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
# モデルをロード(起動時に 1 回だけ)
model = build_sam3_image_model()
processor = Sam3Processor(model)
# テキストプロンプトで検出
state = processor.set_image(img)
output = processor.set_text_prompt(state=state, prompt="hard hat")
# output: {masks, scores, boxes}
set_image で画像を読み込んで、set_text_prompt でプロンプトごとに検出結果を取得します。複数のプロンプトを順番に渡して、スコア閾値でフィルタすれば完成です。
起動は docker run でサクッと動かせます。
docker build -t sam3-api .
docker run --gpus all -p 8105:8105 \
-e HF_TOKEN=$HF_TOKEN \
-v hf-cache:/root/.cache/huggingface \
sam3-api
SAM3 のモデルは HuggingFace のゲート付きリポジトリで公開されているため、事前に facebook/sam3 でアクセスリクエストを送り、HF_TOKEN 環境変数にトークンを設定しておく必要があります。hf-cache ボリュームをマウントしておけば、2 回目以降の起動でモデルの再ダウンロードを省略できます。
/health エンドポイントで VRAM 使用量を確認できます。
curl http://localhost:8105/health
# {"status":"ok","model":"sam3","vram_gib":3.3}
3.3 GiB というのは、DGX Spark の 128GB 統合メモリからすると非常に軽量です。他のモデル(VLM や LLM)と同居させても余裕があります。
5 つのシナリオで検出してみた
SAM 3.1 のゼロショット検出がどこまで通用するのか、まったく異なる 5 つのドメインで試してみました。同じモデル、同じ API サーバーに対して、プロンプトを変えるだけです。
シナリオ 1: 建設現場の PPE 検出
プロンプト: hard hat, safety vest, safety glasses, person

BBox による検出結果。ヘルメット 4 個、安全ベスト 1 着、人物 4 人を検出

セグメンテーションマスクによる色分け。オブジェクトの輪郭がピクセル単位で分離されている
以前の VSS シリーズ記事でも使った建設現場の画像(Pexels 出典)で試してみました。
| プロンプト | 検出数 | 最高スコア |
|---|---|---|
| hard hat | 4 | 0.929 |
| safety vest | 1 | 0.903 |
| person | 4 | 0.959 |
推論時間は 1,840ms でした。学習なしでヘルメットや安全ベストを検出できています。safety glasses は閾値 0.5 では検出されませんでしたが、画像内で眼鏡が小さく映っているため妥当な結果かなと思います。
シナリオ 2: 倉庫/物流
プロンプト: forklift, person, pallet, safety vest, box

フォークリフト、パレット、荷物、作業員がそれぞれ色分けされている
プロンプトを変えるだけで、製造業の別シーンにも対応できます。
| プロンプト | 検出数 | 最高スコア |
|---|---|---|
| forklift | 1 | 0.831 |
| person | 1 | 0.949 |
| pallet | 2 | 0.708 |
| safety vest | 1 | 0.612 |
| box | 3 | 0.808 |
推論時間 773ms。フォークリフトのような特殊な機械も、テキストプロンプトだけで検出できるのはありがたいですね。
シナリオ 3: オフィスのデスク周り
プロンプト: laptop, coffee cup, phone, keyboard

ラップトップ、コーヒーカップ、スマホ、キーボードが色分けされている
PPE とはまったく異なるドメインです。
| プロンプト | 検出数 | 最高スコア |
|---|---|---|
| laptop | 1 | 0.982 |
| coffee cup | 1 | 0.840 |
| phone | 1 | 0.961 |
| keyboard | 1 | 0.958 |
推論時間 688ms。ラップトップ(0.982)やスマホ(0.961)のスコアが非常に高く、日常的なアイテムの検出精度は安定していました。
シナリオ 4: 街並み/交通
プロンプト: person, car, traffic light, backpack

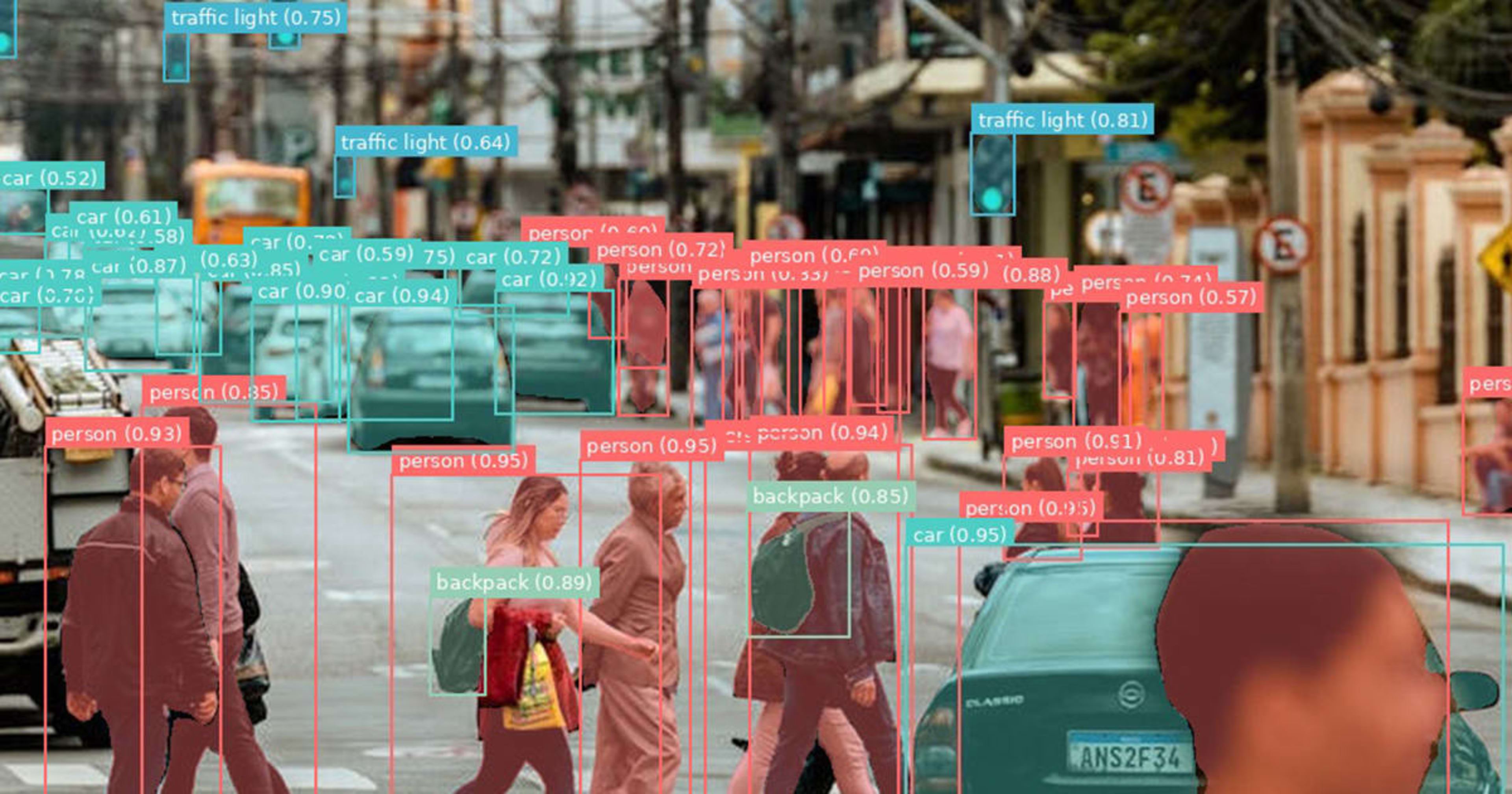
横断歩道を渡る歩行者 26 人、車 18 台、信号機 7 基が一気に検出されている
自律走行やサーベイランス的な文脈で、混雑したシーンに SAM 3.1 を適用してみました。
| プロンプト | 検出数 | 最高スコア |
|---|---|---|
| person | 26 | 0.954 |
| car | 18 | 0.955 |
| traffic light | 7 | 0.923 |
| backpack | 2 | 0.886 |
推論時間 706ms。26 人の歩行者と 18 台の車を一括検出している点が印象的です。固定クラスの YOLO だと「backpack」のような追加検出は再学習が必要ですが、SAM 3.1 ならプロンプトに追加するだけです。
シナリオ 5: スーパーの青果コーナー
プロンプト: banana, apple, melon, price tag, strawberry

バナナ 17 本、リンゴ 39 個、値札 5 枚がプロンプトごとに色分けされている
最後はリテール分野です。小さい果物が大量に並ぶシーンでどこまで検出できるか試してみました。
| プロンプト | 検出数 | 最高スコア |
|---|---|---|
| banana | 17 | 0.874 |
| apple | 39 | 0.851 |
| price tag | 5 | 0.945 |
| strawberry | 3 | 0.565 |
推論時間 702ms。リンゴ 39 個を個別に検出しているのは驚きました。値札(price tag)も 0.945 の高スコアで検出できています。strawberry のスコアが低めなのは、網越しで見えにくかったためでしょう。
5 つのシナリオすべてで、プロンプトを変えるだけで検出できました。建設現場から街並み、スーパーの青果売り場まで、モデルの再学習なしで対応できるのがゼロショット検出の強みですね。
性能を測ってみた
VRAM 使用量
| 状態 | VRAM |
|---|---|
| モデルロード後 | 3.3 GiB |
| 検出実行中(ピーク) | 約 3.9 GiB |
DGX Spark の 128GB 統合メモリに対して 3% 程度です。VLM(Cosmos-Reason2-8B で約 17 GiB)や LLM(Nemotron-Nano-9B-v2 で約 17 GiB)と並べても、余裕で同居できます。
推論速度
5 シナリオの実測結果をまとめます。
| シナリオ | プロンプト数 | 推論時間 |
|---|---|---|
| 建設現場 PPE | 4 | 1,840ms |
| 倉庫/物流 | 6 | 773ms |
| オフィス | 5 | 688ms |
| 街並み/交通 | 5 | 706ms |
| スーパー青果 | 5 | 702ms |
初回(PPE)が 1,840ms と遅いのは、set_image の画像埋め込み計算にウォームアップが含まれているためです。2 回目以降は 700ms 前後で安定しています。
YOLO の 53fps(Jetson FP16)と比べるとかなり遅いですが、リアルタイム検出ではなく「録画映像やアーカイブ画像の分析」という用途であれば、1 秒以下で返ってくるのは十分実用的です。
閾値による検出数の変化
同じ画像に対して score_threshold を 0.3 / 0.5 / 0.7 と変えて、検出数がどう変わるか比較してみました。
倉庫シーン(forklift, person, pallet, safety vest, box, hard hat)
| 閾値 | 検出プロンプト数 | 検出インスタンス数 | 変化 |
|---|---|---|---|
| 0.3 | 5 | 8 | safety vest や pallet も拾う |
| 0.5 | 5 | 8 | 0.3 と同じ(元々のスコアが高い) |
| 0.7 | 4 | 4 | safety vest が脱落、pallet と box が減少 |
街並みシーン(person, car, traffic light, backpack, crosswalk)
| 閾値 | 検出プロンプト数 | 検出インスタンス数 | 変化 |
|---|---|---|---|
| 0.3 | 5 | 56 | crosswalk 含む全プロンプト検出 |
| 0.5 | 5 | 56 | 0.3 と同じ |
| 0.7 | 4 | 35 | crosswalk 脱落、person 26→15、car 18→12 |
閾値 0.5 がバランスのよい設定でした。0.7 にすると低スコアのプロンプト(crosswalk 0.68、safety vest 0.61)が脱落し始めます。0.3 まで下げても今回の画像では誤検出が大きく増えることはありませんでしたが、密度の高い画像では誤検出が増える可能性があるので、ユースケースに応じて調整するのがよさそうです。
YOLO と SAM 3.1 をどう使い分けるか
実際のパイプラインでは、YOLO と SAM 3.1 は排他的ではなく組み合わせて使えます。たとえばエッジの YOLO でリアルタイムに人物を検出し、サーバー側の SAM 3.1 で保護具の有無をゼロショットで補強する、といった構成です。この組み合わせについては、今後の記事で実際にパイプラインを組んで検証する予定です。
おまけ: SAM 3.1 の動画追跡も試してみた
SAM 3.1 の目玉機能である Object Multiplexing による動画追跡もせっかくなので試してみました。歩行者が 80 人以上映る繁華街の動画(Pexels 出典、30 フレーム)を使って、画像モード(フレームごとに独立検出)と動画モード(Multiplex Video Predictor)の速度を比較しています。
DGX Spark で動かすには、Dockerfile で入れた flash-attn に加えて、モジュール名のシムと SDPA フォールバックが必要でした(詳細は GitHub リポジトリのスクリプトを参照してください)。
速度比較
| モード | 処理方式 | FPS | 合計時間(30 フレーム) |
|---|---|---|---|
| 画像モード | フレームごとに独立検出 | 1.22 | 24.5s |
| 動画モード(SAM 3.1 Multiplex) | 共有メモリで一括処理 | 1.52 | 19.7s |
DGX Spark では 1.2 倍の速度向上 に留まりました。Meta が公表している H100 での 7 倍速には届いていませんが、これは flash-attn が DGX Spark の SM121 をネイティブサポートしていないため、SDPA へのフォールバックが発生しているのが主因です。Object Multiplexing のアルゴリズム自体は正常に動いているので、今後の対応状況次第でさらなる高速化が期待できそうです。
まとめ
SAM 3.1 を DGX Spark で動かして、テキストプロンプトだけで物体検出ができることを確認しました。
やってみた感想としては、YOLO のように学習データを準備しなくても「とりあえず検出してみる」ができるのは地味にありがたいですね。PPE からオフィス用品、食材まで、プロンプトを変えるだけで対応できる柔軟さは、探索的な分析やプロトタイピングに向いていると感じました。
一方で、推論速度は YOLO の 53fps に対して 700ms/画像と 30 倍以上遅いですし、ゼロショットゆえに専用学習済みモデルほどの精度は出ません。リアルタイム検出が必要な場面では、やはり YOLO に軍配が上がります。
実際のプロダクション環境では、SAM 3.1 で大量のラベリングデータを生成して、そのデータで軽量な YOLO モデルを蒸留してデプロイする、という使い方がコスパのよいパターンとして注目されています。DGX Spark の 128GB 統合メモリなら SAM 3.1 によるラベリングも余裕を持って回せるので、この手の「重いモデルで知識を蒸留して軽いモデルに移す」ワークフローとの相性はよさそうです。
SAM 3.1 のコンテナイメージと検出スクリプトは GitHub リポジトリで公開しています。