
DGX Spark で映像検索 AI エージェントを動かしてみた(VSS Agent)
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
以前の記事では Live VLM WebUI を使ってカメラ映像のリアルタイム解析を試しました。「今映っているもの」を 1〜2 秒で言語化してくれる体験は面白かったのですが、実際の業務では「過去の映像から特定のシーンを探したい」というニーズの方が多いのではないでしょうか。
今回は NVIDIA の AI Blueprint「VSS(Video Search and Summarization)Agent」を DGX Spark で動かしてみました。録画した映像を食わせて、自然言語で「赤い服の人が映っているシーンはどこ?」と聞くと該当箇所を探してくれる、映像検索の AI エージェントです。
Live VLM WebUI が「目の前のカメラ映像をリアルタイムに言語化する」ツールだとすれば、VSS は「蓄積された映像を後から検索・要約する」ツール。今回は DGX Spark 上で、リアルタイム解析と蓄積映像検索の両方をローカル完結で動かしてみました。
VSS Agent とは
VSS(Video Search and Summarization)Agent は、NVIDIA Metropolis プラットフォームをベースにした映像 AI Blueprint です。映像をアップロードすると VLM で自動的にキャプションを生成し、ベクターデータベースとグラフデータベースに格納。その後、自然言語で映像の内容を検索したり、要約を生成したりできます。
できること
映像をアップロードすると、「このシーンで何が起きていますか?」のような自然言語での質問や、「赤い帽子をかぶった人が歩いているシーン」といったテキスト検索が使えるようになります。映像全体の要約生成、音声の文字起こし(多言語対応)、行動認識(特定のアクションの検出)にも対応しています。
アーキテクチャ
VSS の裏側では、複数の AI モデルとデータベースが連携しています。
VLM として Cosmos-Reason2-8B(NVIDIA の最新映像理解モデル、Qwen3-VL ベース)を採用し、LLM は OpenAI 互換 API で柔軟に差し替え可能です(デフォルトは Llama 3.1 8B)。検索には Milvus(ベクター DB)と Neo4j(グラフ DB)を組み合わせた CA-RAG(Context-Aware RAG)が使われていて、時空間的な関係性も考慮した検索ができるのが特徴です。
2 つのモード
VSS には 2 つのデプロイモードがあります。
| モード | VLM | LLM | DB | 用途 |
|---|---|---|---|---|
| Event Reviewer | Cosmos-Reason2-8B(ローカル) | 不使用 | 不使用 | CV パイプラインのアラート検証 |
| Standard VSS | Cosmos-Reason2-8B(ローカル) | Llama 3.1 8B(ローカル) | Milvus + Neo4j | フル機能の映像検索・要約 |
Event Reviewer は「CV パイプライン(物体検出等)が出したアラートを VLM で検証する」軽量モードです。Standard VSS はフル機能で、映像の検索・要約・Q&A がすべて使えます。今回は Standard VSS を中心に検証しました。
セットアップ
前提条件
| 項目 | 要件 |
|---|---|
| DGX OS | 7.2.3 以上 |
| GPU ドライバー | 580.95.05 以上 |
| NGC API Key | NVIDIA Container Registry アクセス用 |
| HuggingFace Token | Cosmos-Reason2-8B のアクセス用 |
| ストレージ | /tmp/ に 10GB 以上の空き |
環境構築
VSS の GitHub リポジトリをクローンし、DGX Spark 向けのシングル GPU 構成でデプロイします。
git clone https://github.com/NVIDIA-AI-Blueprints/video-search-and-summarization.git
cd video-search-and-summarization
DGX Spark(ARM64)では IS_SBSA=1 フラグの設定が必要です。
# キャッシュクリーナー実行(ARM 環境で推奨)
sudo sh deploy/scripts/sys_cache_cleaner.sh
# NGC ログイン
docker login nvcr.io
NGC API Key は NGC のセットアップページで取得できます。HuggingFace Token は Settings から。
export NGC_API_KEY="your-ngc-api-key"
export HF_TOKEN="your-hf-token"
NIM コンテナの起動
VSS では LLM、Embedding、Reranker の 3 つの NIM コンテナを使います。公式ドキュメントでは 3 つとも NIM で起動する手順が紹介されていますが、今回は LLM だけ Ollama に差し替えました。
VSS の LLM 部分は OpenAI 互換 API を叩いているだけなので、エンドポイントを差し替えれば NIM 以外の推論サーバーでも動きます。Ollama は OpenAI 互換 API(/v1/chat/completions)を標準で提供しているため、config.yaml の base_url を変えるだけで済みます。
# Ollama で Llama 3.1 8B を準備
ollama pull llama3.1:8b
Embedding と Reranker は NIM のまま起動します。この 2 つは各 3GB 程度とコンパクトで、メモリの問題は起きません。
export LOCAL_NIM_CACHE=/tmp/nim-cache
mkdir -p $LOCAL_NIM_CACHE
# Embedding NIM(26 言語対応、日本語含む)
docker run -d --name vss-embedding-nim \
-u $(id -u) --gpus '"device=0"' --shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-p 8006:8000 \
nvcr.io/nim/nvidia/llama-3.2-nv-embedqa-1b-v2:1.9.0
# Reranker NIM(26 言語対応、日本語含む)
docker run -d --name vss-reranker-nim \
-u $(id -u) --gpus '"device=0"' --shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-p 8005:8000 \
nvcr.io/nim/nvidia/llama-3.2-nv-rerankqa-1b-v2:1.7.0
NIM コンテナの初回起動にはモデルのダウンロードが入るので、それなりに時間がかかります。docker logs -f vss-embedding-nim で進行状況を確認しながら待ちます。
config.yaml で LLM エンドポイントを Ollama に向ける
VSS の設定ファイル config.yaml で、LLM のエンドポイントを Ollama に向けます。変更するのは chat_llm、summarization_llm、notification_llm の 3 箇所です。
chat_llm:
type: llm
params:
model: llama3.1:8b
base_url: 'http://host.docker.internal:11434/v1' # Ollama
max_tokens: 2048
temperature: 0.2
top_p: 0.7
host.docker.internal は Docker コンテナ内からホスト側のサービスにアクセスするための DNS 名です。Ollama はホスト側のポート 11434 で待ち受けているので、VSS のコンテナからこの URL で繋がります。
VSS 本体のデプロイ
Embedding / Reranker NIM が ready を返し、Ollama で LLM が応答するのを確認したら、VSS 本体を起動します。
cd deploy/docker/local_deployment_single_gpu
# .env に NGC_API_KEY と HF_TOKEN を設定
source .env
# ARM64 フラグ(DGX Spark 必須)
export IS_SBSA=1
docker compose up -d
VSS 本体のイメージ名に -sbsa サフィックスがつくのが DGX Spark(ARM64)のポイントです。IS_SBSA=1 を設定すると、compose.yaml 内で vss-engine:2.4.1-sbsa が選択されます。
初回起動時には Cosmos-Reason2-8B(VLM)のダウンロードが走ります。HuggingFace のゲート付きモデルなので、事前に Cosmos-Reason2-8B のページ でライセンスに同意しておく必要があります。
起動が完了したら、ブラウザで http://<DGX Spark の IP>:9100 にアクセスします。
デフォルト構成で動かす(Llama 3.1 8B)
サンプル映像をアップロード
まずは VSS リポジトリに含まれているサンプル映像(倉庫の監視映像 warehouse.mp4)を使って、一連のフローを確認します。Web UI の「FILE SUMMARIZATION」タブから mp4 ファイルをアップロードすると、Cosmos-Reason2-8B(VLM)がフレームごとにキャプション(テキスト説明)を自動生成し、GraphRAG として Milvus と Neo4j に格納してくれます。
要約を生成する
アップロードが終わったら「Summarize」ボタンを押します。VLM がチャンク単位でキャプションを生成し、それを LLM(Llama 3.1 8B)が要約・集約するという流れです。倉庫映像では 113 秒で処理が完了しました。
生成された要約は 4 つのカテゴリに整理されて出てきました。
- Unsafe Behavior — はしご上での不安定な作業姿勢、安全帯の未着用
- Operational Inefficiencies — 作業員間の待ち時間
- Potential Equipment Damage — フォークリフト周辺の安全確認不足
- Unauthorized Personnel — 保護具なしでの立ち入り
デフォルトのプロンプトが倉庫監視向けに設定されているため、安全管理の観点でよくまとまっています。
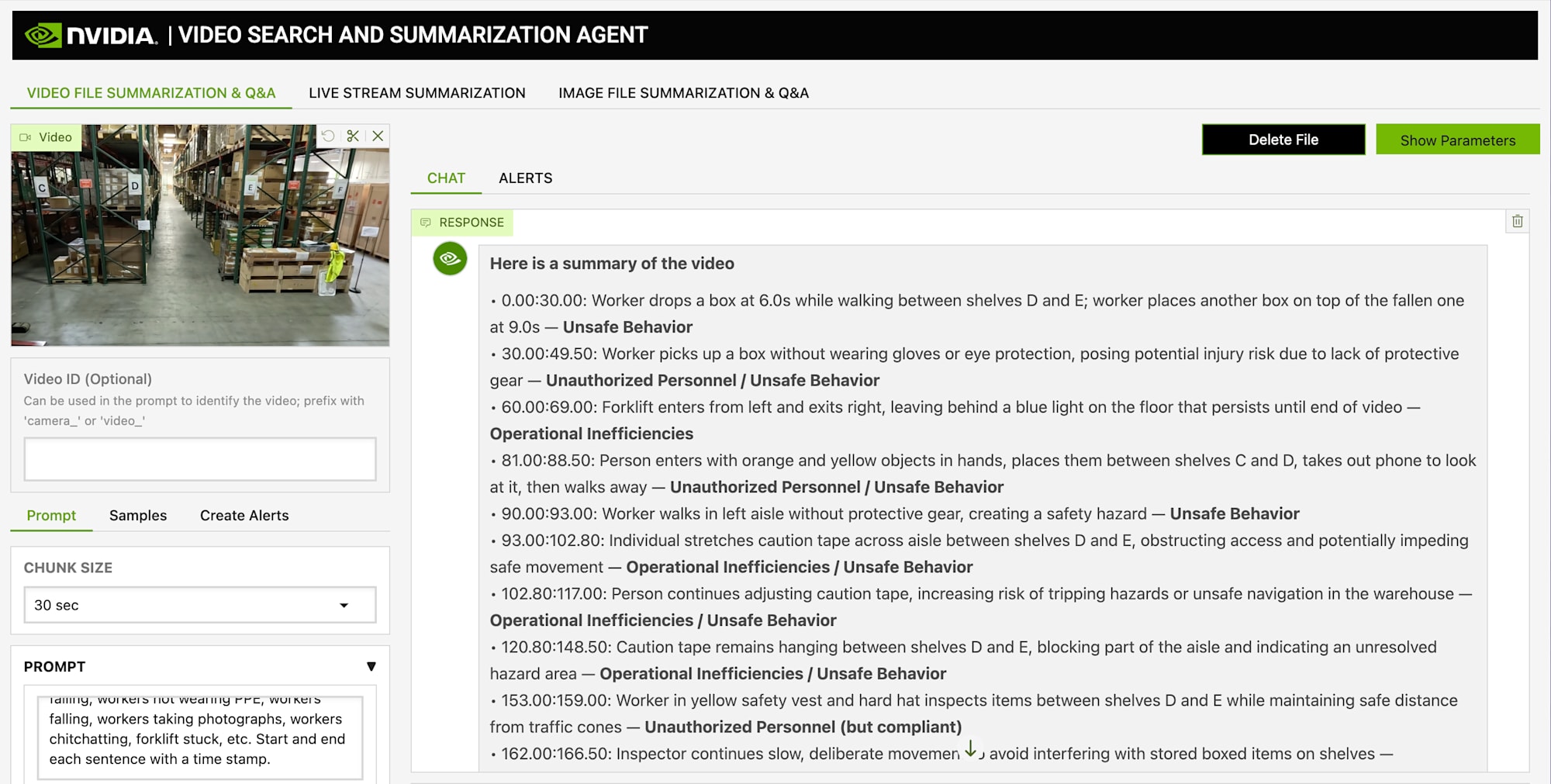
英語で質問してみる
要約だけでなく、チャット形式で映像の内容に質問することもできます。
Q: "What safety violations were detected?"
VLM が生成した英語キャプションと GraphRAG の検索結果をもとに、LLM が回答を返してくれます。はしご上での PPE 未着用、フォークリフト周辺の安全確認不足など、要約と整合する内容でした。
日本語で質問してみる
同じ映像に対して、日本語で質問するとどうなるか試してみました。
Q: 「この動画で確認された安全上の問題は何ですか?」
Llama 3.1 8B でも日本語で返答が返ってきます。ただし「はしごの上で不安定な姿勢で作業」「保護具の未着用」など、基本的な指摘にとどまり、英語の回答と比べると情報量が少なめでした。VLM キャプションが英語で生成されているため、日本語クエリとの間にギャップがある状態です。

Nemotron 9B で日本語検索してみる
ここからが今回の記事で一番試したかったところです。VSS のデフォルト構成は英語中心ですが、DGX Spark には Nemotron シリーズの記事 で検証済みの日本語 LLM があります。LLM を差し替えたら、日本語での映像検索はどのくらい使えるようになるのか。
config.yaml を書き換える
Ollama には Nemotron 9B-v2-Japanese がすでに動いているので、config.yaml のモデル名を変えるだけです。chat_llm、summarization_llm、notification_llm の 3 箇所を書き換えます。
chat_llm:
type: llm
params:
- model: llama3.1:8b
+ model: nemotron-9b-jp-nothink
base_url: "http://host.docker.internal:11434/v1"
config.yaml を保存したら VSS の via-server コンテナを再起動します。映像を再度アップロードし直す必要はありません(GraphRAG のデータはそのまま残ります)。
倉庫映像で比較
同じ warehouse.mp4 に対して Summarize を実行したところ、結果にはっきりした差が出ました。
| 項目 | Llama 3.1 8B | Nemotron 9B-v2-Japanese |
|---|---|---|
| 処理時間 | 113 秒 | 316 秒 |
| 検出イベント数 | 4 カテゴリ(大まかな分類) | 14 件(個別のタイムスタンプ付き) |
| 出力言語 | 英語 | 英語(キャプションが英語のため) |
| 詳細度 | カテゴリ名 + 概要 | 各イベントの具体的な描写 |
Llama 3.1 8B の出力が「Unsafe Behavior」「Operational Inefficiencies」といったカテゴリ単位の概要だったのに対し、Nemotron 9B は「0:08〜0:10: はしごの上で作業員が不安定な姿勢で作業中」のように、タイムスタンプと具体的な状況を個別に列挙してくれました。処理時間は約 3 倍かかりますが、情報の粒度にはかなりの差がありました。
日本語 Q&A の差はさらに顕著でした。
Q: 「この動画で確認された安全上の問題は何ですか?」
| 観点 | Llama 3.1 8B | Nemotron 9B |
|---|---|---|
| 回答言語 | 日本語(ぎこちない) | 日本語(自然) |
| 指摘数 | 2〜3 件 | 4 件以上 |
| 用語 | PPE(英語のまま) | 個人防護装備(日本語訳) |
| 具体性 | 「はしごでの作業」 | 「はしご上で安全帯未着用での高所作業」 |
フリー映像素材で試す
倉庫映像だけだと「たまたま相性がよかった」可能性もあるので、Pexels からダウンロードしたフリー映像素材でも試してみました。
交差点映像
交通量の多い交差点の映像(38 秒)をアップロードしたところ、最初は「異常なし」という結果に。原因はプロンプトでした。デフォルトの倉庫向けプロンプトのままだと「倉庫内の異常行動」を探すため、交通映像では何もヒットしません。
VSS の Web UI では、Summarize 実行時に 3 種類のプロンプトを編集できます。
| プロンプト | 役割 | カスタマイズ例(交通監視) |
|---|---|---|
| PROMPT | VLM が各フレームで何を見るか | 交通違反、信号無視、歩行者の飛び出しに注目 |
| CAPTION SUMMARIZATION PROMPT | 検出イベントの記述ルール | start_time:end_time 形式で違反内容を記述 |
| SUMMARY AGGREGATION PROMPT | イベントのカテゴリ分類 | Traffic Violations, Near-Miss Incidents 等に分類 |
「何を異常とするか」はこの 3 段階のプロンプトで定義するので、業種や監視対象に合わせてカスタマイズできます。

プロンプトを交通監視向けに書き換えたところ、信号無視や車線逸脱など 交通違反をしっかり検出 してくれるようになりました。処理時間は 178 秒です。
VLM のキャプション生成はわりと汎用的に映像を描写してくれますが、LLM の要約・集約段階ではプロンプトがドメインに合っていないと「検出ゼロ」になり得ます。プロンプト次第で同じ映像から異なるインサイトを引き出せるのが VSS の面白いところです。
バイク工場映像
製造ラインの映像(70 秒)では、プロンプトを工場向けに調整して検証しました。

| カテゴリ | 検出数 | 主な発見 |
|---|---|---|
| Production Operations | 10 件 | クレーン操作、部品の精密調整、チーム連携 |
| Safety Concerns | 1 件 | 手袋・保護メガネなしの作業員 |
| Quality Control | 1 件 | クレーン配置時に目視検査の欠如 |
| Equipment Status | 0 件 | 異常なし |
処理時間は 648 秒(70 秒の映像に対して約 10 分)。チャンク数が多い分、要約の集約に時間がかかっています。
日本語 Q&A で「品質管理の観点で気になる点はありますか?」と聞くと、Nemotron 9B は以下のように回答しました。
エンジン部品がコンベアベルトに載せられた後、目視による検査が行われていないことが確認されています。(中略)リアルタイムモニタリングのための可視センサーがコンベアベルトに設置されていない点から、自動化された品質管理システムの不足が推測されます。
目視検査の欠如やセンサー不在といった具体的な指摘を、製造業の文脈に合った用語で返してくれています。Nemotron 9B の日本語力が活きている場面ですね。
一方で、「作業員はどのような作業をしていますか?」のような汎用的な質問では英語で回答が返ってくることもありました。VLM キャプションが英語で格納されているため、検索結果の比率によって LLM の出力言語が揺れるようです。VLM 側のキャプションも日本語化すれば安定するはずですが、Cosmos-Reason2-8B の日本語キャプション品質は今後の検証課題です。
Live VLM WebUI との比較
同じ DGX Spark 上で動く映像 AI ツールとして、Live VLM WebUI と VSS を比べてみます。
| 比較軸 | Live VLM WebUI | VSS Agent |
|---|---|---|
| 用途 | リアルタイム映像の言語化 | 蓄積映像の検索・要約 |
| 処理対象 | カメラのライブ映像 | mp4 等の録画ファイル |
| レスポンス | 1〜4 秒 | バッチ処理(非リアルタイム) |
| VLM | gemma3:4b / llama3.2-vision:11b | Cosmos-Reason2-8B |
| LLM | 不要 | Llama 3.1 8B |
| データベース | 不要 | Milvus + Neo4j |
| セットアップ | uv tool install 1 行 |
Docker Compose、30〜45 分 |
| 検索機能 | なし | テキストで映像内シーン検索 |
| GPU メモリ | 2〜8GB(モデル依存) | VLM ~37GB + LLM 18GB + NIM 6GB |
使い方としては「Live VLM WebUI でリアルタイム監視しつつ、録画を VSS に蓄積して後から検索」という組み合わせが自然です。Live VLM WebUI は「今何が起きているか」を即座に知りたいとき、VSS は「過去の映像から特定の場面を探したい」ときに使います。ただし DGX Spark の 128GB 統合メモリで両方を同時に動かすのはかなりタイトなので、用途に応じて切り替えるのが現実的です。
ユースケースを考える
DGX Spark の手元で映像 AI エージェントがローカル完結で動くとなると、プライバシーやネットワーク要件が厳しい現場でも映像解析が使えそうです。
今回のバイク工場映像の検証では、「保護メガネ未着用」「目視検査の欠如」「リアルタイム監視システムの不在」といった指摘が実際に得られました。工場のカメラ映像を VSS に蓄積し、「作業手順の逸脱」「安全装備の未着用」などを日本語で検索するという使い方は、十分に実用的な印象です。映像を外部に出せない現場でも、DGX Spark をラインサイドに置けばローカルで完結します。
製造ライン以外にも、会議録画の検索(音声文字起こしとの組み合わせ)や店舗の防犯カメラ解析など、「蓄積映像を自然言語で検索したい」場面には幅広く使えそうです。
おまけ: カメラなしでライブストリーム機能を試す
ここまではファイルアップロードによる映像検索を試してきましたが、VSS にはもう一つ「LIVE STREAM SUMMARIZATION」という機能があります。RTSP ストリームを接続すると、映像をリアルタイムにチャンク分割してキャプション生成・要約を行ってくれる機能です。
監視カメラの RTSP ストリームがなくても大丈夫です。録画済みの映像を擬似的に RTSP 配信すれば、DGX Spark 上だけで試せます。ここでは MediaMTX(軽量 RTSP サーバー)と FFmpeg を使って、先ほどと同じ warehouse.mp4 をループ配信してみました。
セットアップ
MediaMTX を Docker で起動し、FFmpeg でファイルを RTSP として配信します。
# MediaMTX(RTSP サーバー)を起動
docker run --rm -d --name mediamtx --network host bluenviron/mediamtx:latest
# warehouse.mp4 をリアルタイム速度でループ配信
ffmpeg -re -stream_loop -1 \
-i ~/videos/vss-test/warehouse.mp4 \
-c copy \
-f rtsp rtsp://localhost:8554/warehouse
-re はリアルタイム速度で読み込むフラグです。これがないと全速力で送信してしまい、ライブストリームとして成立しません。-c copy でトランスコードなしの H.264 パススルーにしているので、CPU 負荷はほぼゼロです。
VSS の API にストリームを登録します。
curl -X POST http://localhost:8100/live-stream \
-H "Content-Type: application/json" \
-d '{
"liveStreamUrl": "rtsp://host.docker.internal:8554/warehouse",
"description": "Warehouse Safety Monitoring RTSP Loop",
"camera_id": "camera_1"
}'
host.docker.internal は VSS のコンテナからホスト側の MediaMTX に到達するための DNS 名です。
ライブストリームの処理
ストリーム登録後に /summarize API を呼び出すと、VLM(Cosmos-Reason2-8B)が 10 秒チャンクでキャプションを生成し始めます。30 秒分のチャンクが溜まるとサマリーが集約される仕組みです。
実際のログを見ると、こんな感じでチャンクごとにキャプションが生成されていました。
Chunk 6: "Between the timestamps 68.8 and 70.8, an individual wearing safety gear exits through the restricted zone marked by caution tape without authorization."
Chunk 11: "Between 114.8s and 120.9s, a person is carrying two boxes but drops one while walking through the aisle, posing a safety hazard due to potential injury from falling objects."
30 秒ごとのサマリーでは、これらのチャンクが集約されて「Worker is not wearing any safety equipment and is handling materials without proper protective gear」のようなカテゴリ別の報告になります。ファイルアップロード版と同じ映像なのに、ライブストリームでは NTP タイムスタンプが付くのが特徴的ですね。
ファイルアップロードとの違い
同じ warehouse.mp4 を 2 つの方式で処理してみると、処理モデルの違いがはっきり見えます。
| 比較項目 | ファイルアップロード | ライブストリーム |
|---|---|---|
| 処理方式 | 一括インジェスト | 10 秒チャンク逐次処理 |
| タイムスタンプ | 映像内タイムコード | NTP |
| 要約タイミング | 処理完了後 | 30 秒ごとにインクリメンタル |
| Q&A レスポンス | 7〜19 秒 | 500 秒以上(VLM がチャンク処理優先) |
| Q&A の時制 | 過去形(何が起きたか) | 現在形(今何が起きているか) |
| ユースケース | 録画の事後分析 | リアルタイム監視 |
Q&A のレスポンス時間に大きな差が出たのは、ライブストリームでは VLM が常にチャンク処理を回しているためです。VLM のリソースを Q&A と共有する構成なので、ストリーミング中は Q&A がキューの後ろに回されます。ファイルアップロードではインジェスト完了後に VLM のリソースが空くため、Q&A は 10〜20 秒程度で返ってきていました。
実用面では、ライブストリームは「要約 + アラートの自動生成」がメインの使い方になりそうです。リアルタイムの Q&A は、GPU を追加して VLM を専用化するか、チャンク処理の間隔を広げるといった工夫が必要になるでしょう。
まとめ
VSS Agent を DGX Spark にデプロイし、録画映像の検索・要約から日本語 LLM への差し替え、ライブストリーム機能まで一通り試してみました。DGX Spark の 128GB 統合メモリは余裕があるとは言えず、LLM を NIM から Ollama に切り替えてメモリを約 40GB 節約しています。VSS が OpenAI 互換 API を標準にしている設計のおかげで、この切り替えは config.yaml の base_url を変えるだけで済みました。
LLM を Nemotron 9B-v2-Japanese に差し替えるだけで、要約の粒度と日本語 Q&A の品質が目に見えて改善したのは収穫でした。一方で、プロンプトのドメイン適合も検出精度を大きく左右します。デフォルトの倉庫向けプロンプトのまま交差点映像を処理すると「異常なし」になりますが、交通監視向けに書き換えるだけで違反を検出できました。VLM キャプションが英語のままなので質問の種類によって回答言語が揺れる点は、VLM 側の日本語化と合わせて今後の課題です。
前回の Live VLM WebUI が「今映っているもの」をリアルタイムに言語化するツールだったのに対し、VSS は「過去の映像をテキストで検索する」ピースを埋めてくれました。両方が同じ DGX Spark 上でローカル完結するのは、映像を外部に出せない現場で特に価値がありそうです。
今回の検証環境
| 項目 | スペック |
|---|---|
| DGX Spark | 128GB LPDDR5x、GB10(Grace Blackwell) |
| DGX OS | 7.2.3 |
| GPU ドライバー | 580.126.09 |
| CUDA | 13.0 |
| VSS Agent | 2.4.1 |
| VLM | Cosmos-Reason2-8B |
| LLM(デフォルト) | Llama 3.1 8B(Ollama) |
| LLM(日本語) | Nemotron 9B-v2-Japanese(Ollama) |
| Embedding | Llama 3.2 NV-EmbedQA 1B v2 |
| Reranker | Llama 3.2 NV-RerankQA 1B v2 |
| データベース | Milvus v2.6.5 + Neo4j 5.26 |







