![[アップデート] P5 インスタンスファミリーに p5.4xlarge が追加 NVIDIA H100 を 1 基から利用可能に](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-bac3d29aa65f45576f73094798087ee5/039ad6f8a7d8f18da47986d21c447f48/amazon-ec2?w=3840&fm=webp)
[アップデート] P5 インスタンスファミリーに p5.4xlarge が追加 NVIDIA H100 を 1 基から利用可能に
はじめに
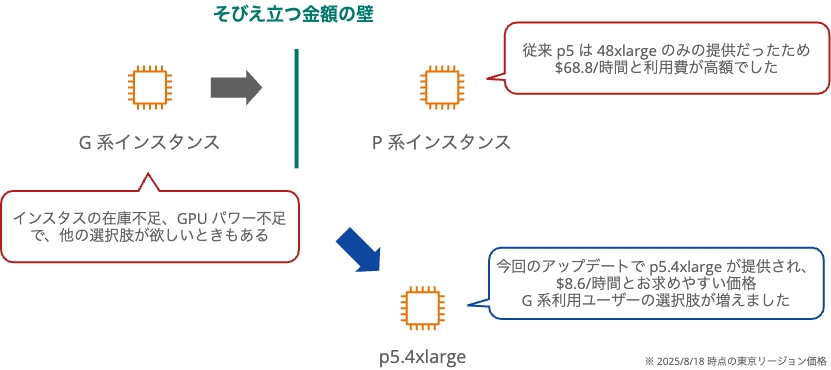
EC2 P5 インスタンスファミリーに新しいインスタンスタイプ「p5.4xlarge」が追加されました。P 系インスタンスとしては、初となるシングル GPU 構成でお求めやすい価格になっています。
GPU インスタンスの選択肢は、前世代の GPU を搭載した G5/G6 は $1 〜 23.6/時間、NVIDIA H100/H200 を搭載した P5 は最低でも $68.80/時間でした。今回登場した p5.4xlarge は H100 を搭載しながら $8.60/時間という価格設定で、GPU 選択に新たな風を吹かせてくれました。
従来の P 系インスタンス
これまで P5 インスタンスの最小構成は 8 GPU を搭載した p5.48xlarge でした。オンデマンド料金は 1 時間あたり $68.80 と非常に高額です。同じ 8 GPU 構成の g6.48xlarge と比較しても、約 3.5 倍の価格差がありました。G5 は前世代の A10G GPU で VRAM 24GB、G6 は推論最適化された L4 GPU で同じく VRAM 24GB を搭載しています。G5/G6 と P5 では GPU 性能には大きな開きがありました。
そのため、小規模な GPU インスタンスが必要な場合、必然的に G5 や G6 インスタンスを選択することになります。g6.2xlarge なら $1.42/時間、g6.4xlarge なら $1.92/時間で利用できます。H100 GPU の 80GB VRAM が欲しいとなった場合、急に p5.48xlarge の $68.80/時間は価格面でのハードルが高すぎました。
P 系なのにスペック控えめなインスタンスサイズが追加
大規模な機械学習や、HPC 用途向けに高額な GPU を複数搭載したインスタンスの P 系インスタンスに、同じ GPU を小規模向けのインスタンスサイズを提供開始されました。
- H100 を 1 台から利用可能
- p5.48xlarge の約 1/8 の価格で提供
- GPU 数に比例した価格設定
- G5/G6 ユーザーにとって現実的な価格帯で H100 を利用できる
スペック
ドキュメントを確認していて気になったことは、GPUDirect RDMA はサポートしていないことです。
| 項目 | 仕様 |
|---|---|
| GPU | NVIDIA H100 Tensor Core GPU × 1 |
| GPU メモリ | 80 GB HBM3 |
| vCPU | 16(8 コア × 2 スレッド) |
| メモリ | 256 GiB |
| ネットワーク帯域幅 | 100 Gbps |
| EFA サポート | あり(GPUDirect RDMA は非対応) |
他の GPU インスタンスと比較(インスタンスサイズ)
H100 を搭載している分、価格は大きく開きました。
| インスタンス | GPU | GPU メモリ | vCPU | メモリ | ネットワーク | オンデマンド料金($/時間) |
|---|---|---|---|---|---|---|
| p5.4xlarge | NVIDIA H100 × 1 | 80 GB HBM3 | 16 | 256 GiB | 100 Gigabit | $8.60 |
| g5.4xlarge | NVIDIA A10G × 1 | 24 GB GDDR6 | 16 | 64 GiB | Up to 25 Gigabit | $2.36 |
| g6.4xlarge | NVIDIA L4 × 1 | 24 GB GDDR6 | 16 | 64 GiB | Up to 25 Gigabit | $1.92 |
※ 料金は東京リージョン(ap-northeast-1)での Linux オンデマンド価格です。
他の GPU インスタンスと比較(価格)
同じ価格帯だと G6 では 24xlarge 相当でした。G6 はコスパ良いのではという気持ちにもなります。
| インスタンス | GPU | GPU メモリ | vCPU | メモリ | ネットワーク | オンデマンド料金($/時間) |
|---|---|---|---|---|---|---|
| p5.4xlarge | NVIDIA H100 × 1 | 80 GB HBM3 | 16 | 256 GiB | 100 Gigabit | $8.60 |
| g5.12xlarge | NVIDIA A10G × 4 | 24 GB GDDR6 x 4 | 48 | 192 GiB | 40 Gigabit | $8.23 |
| g6.24xlarge | NVIDIA L4 × 4 | 24 GB GDDR6 x 4 | 96 | 384 GiB | 50 Gigabit | $9.68 |
※ 料金は東京リージョン(ap-northeast-1)での Linux オンデマンド価格です。
料金体系
オンデマンド料金
上記の比較表のとおり、p5.4xlarge は $8.60/時間です。前世代の g5.4xlarge(A10G GPU)や g6.4xlarge(L4 GPU)と比較すると高額ですが、80 GB の GPU メモリと H100 アーキテクチャを考慮すると、大規模モデルの処理には利用価値があるのではないでしょうか。
スポットインスタンスも使えます
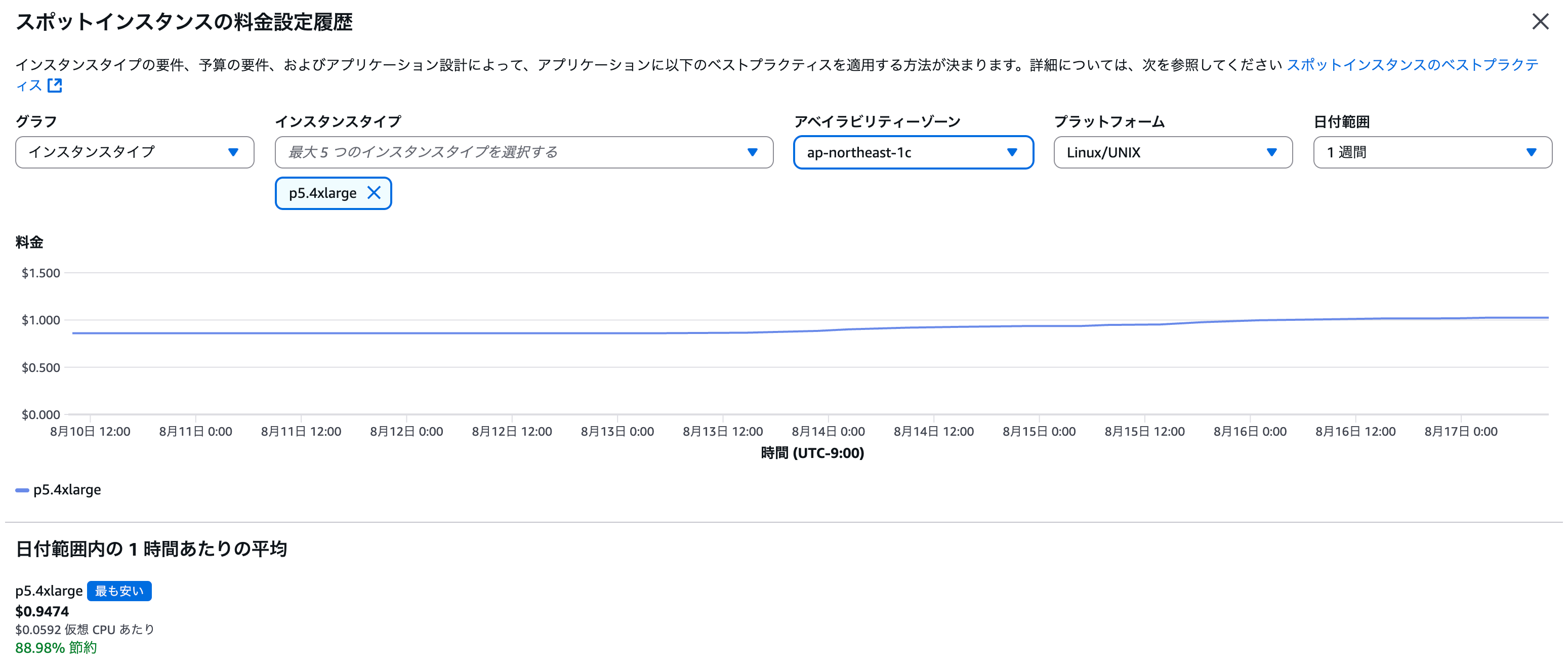
スポットインスタンスを利用すると、最大 90% の割引が可能です。中断リスクを許容できる処理であれば検討の価値があります。ただし、G5/G6 は昨今の GPU 需要によりスポット起動は困難な状況です。
p5.4xlarge は東京リージョンではあまり知られていないせいか、スポット割引が最大に近い割引率です。
今ならスポット起動できるのか試してみた
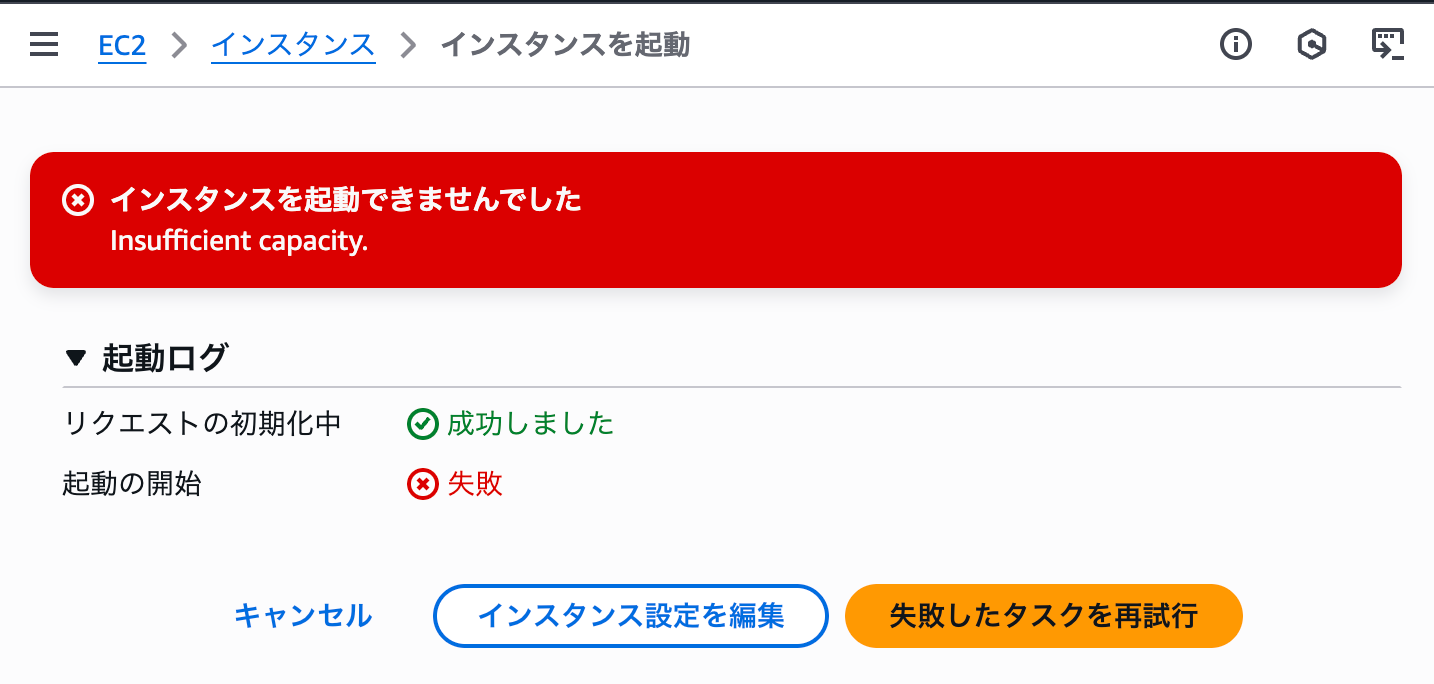
p5.4xlarge は全リージョンで利用可能ではありませんが、東京リージョンでは利用可能です。リリースされた直後であればスポットインスタンスで起動できるのか確認してみましたが、このご時世スポットで GPU インスタンスは厳しいようです。在庫がありませんでした。
クォータの確認
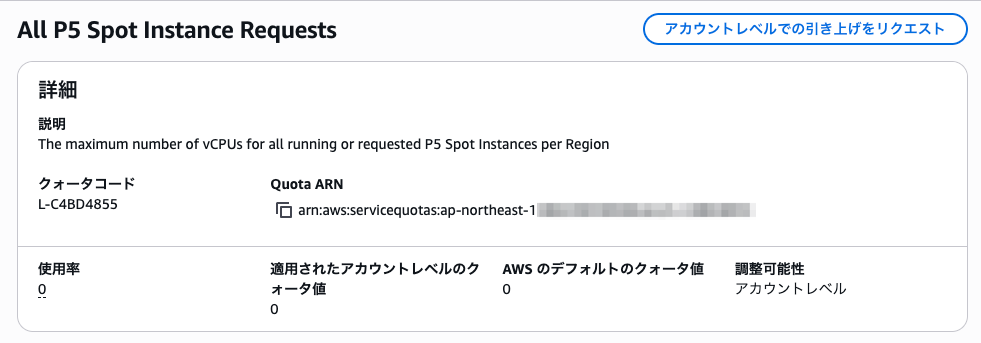
P 系インスタンスは Service Quotas の制限があります。初回利用時はクォータ引き上げリクエストが必要な場合があります。
インスタンス起動時に Max spot instance count exceeded のメッセージが表示された場合は、クォータの引き上げが必要です。

私のアカウントは東京リージョンで P5 のスポットを使ったことなかったので一切使えない状態でした。オンデマンド利用の場合も同様にサービスクォータをご確認ください。
Capacity Blocks for ML 対応
Capacity Blocks を利用すると、GPU インスタンスを事前予約できます。
まとめ
p5.4xlarge の登場により、H100 GPU の利用ハードルが大きく下がりました。機械学習や推論用のインスタンスとして新しい選択肢です。ぜひお試しください。
おわりに
個人的に気になった既存の GPU インスタンスとの価格差を調べたついでにまとめました。








