
ElastiCache Global Datastore(Valkey)でクロスリージョンレプリケーションとフェイルオーバーを検証してみた
こんにちは、ゲームソリューション部のsoraです。
今回は、Amazon ElastiCache Global DatastoreをValkeyで構築し、東京→バージニア北部間のクロスリージョンレプリケーションとフェイルオーバーを検証した内容を書いていきます。
今回は以下の点を検証しました。
- クロスリージョンレプリケーションの動作確認
- 手動フェイルオーバーの所要時間と挙動
- フェイルオーバー後のエンドポイント切り替え方法
Global Datastoreとは
ElastiCache Global Datastoreは、異なるAWSリージョン間でElastiCacheクラスタを非同期レプリケーションする機能です。
主な特徴は以下のとおりです。
| 項目 | 内容 |
|---|---|
| 対応エンジン | Valkey 7.2以上 / Redis OSS 5.0.6以上 |
| 構成 | プライマリ 1リージョン + セカンダリ 最大2リージョン |
| レプリケーション | 自動・非同期 |
| 対応クラスタタイプ | ノードベースクラスタのみ(サーバーレス非対応) |
| 対応ノードタイプ | M5, M6g, M7g, R5, R6g, R7g等のlarge以上(t系は非対応) |
| フェイルオーバー | 手動のみ(リージョン間の自動フェイルオーバーはなし) |
検証構成
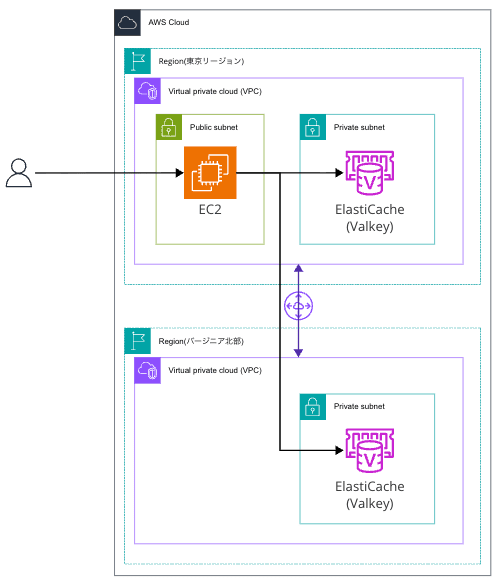
今回の検証構成は以下のとおりです。
東京リージョンのEC2からVPCピアリング経由でバージニア北部リージョンのElastiCacheにも接続します。
インフラはTerraformで構築しました。
構築結果
terraform apply完了後、マネジメントコンソールでグローバルデータストアを確認します。
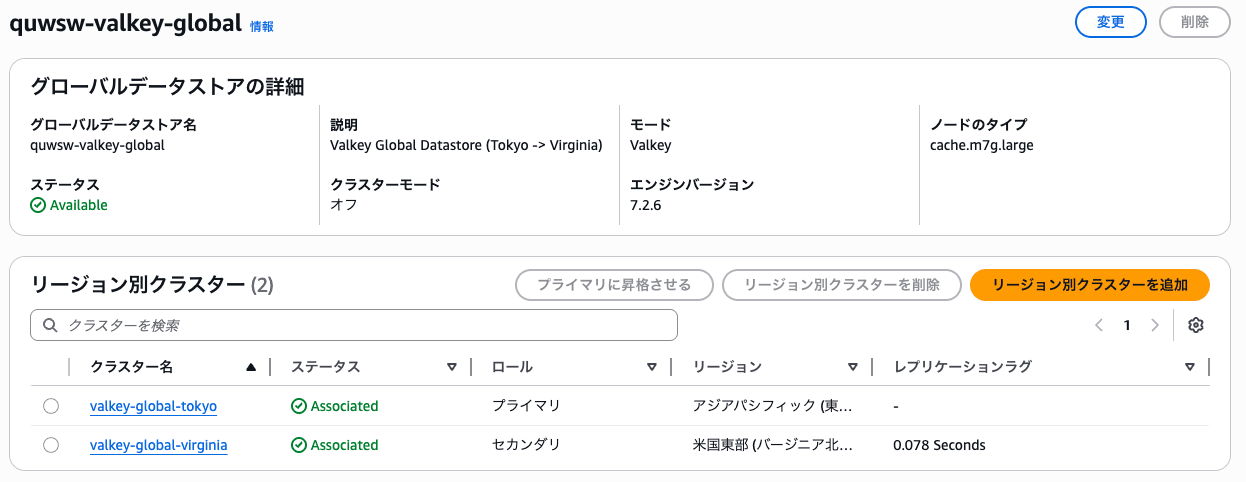
コンソールに表示されているグローバルデータストアIDには、AWSがプライマリリージョンに基づいて自動生成するプレフィックスが付与されています。
Terraformのaws_elasticache_global_replication_groupリソースでglobal_replication_group_id_suffixにvalkey-globalを指定しましたが、実際のIDはxxxxx-valkey-globalのような形式になりました。
ステータスがavailableになり、東京がプライマリ、バージニア北部がセカンダリとして登録されていれば構築完了です。
検証1: クロスリージョンレプリケーションの動作確認
まずは基本的なレプリケーションの動作を確認します。
東京のEC2から、プライマリにSETした直後にセカンダリでGETして、即座にレプリケーションされることを確認します。
# プライマリ(東京)にSET
$ valkey-cli -h <東京エンドポイント> SET test-key "hello-from-tokyo"
OK
# 即座にセカンダリ(バージニア北部)でGET ※VPCピアリング経由
$ valkey-cli -h <バージニア北部エンドポイント> GET test-key
"hello-from-tokyo"
SET直後のGETで即座に値が返ってきました。
体感でも遅延を感じないレベルでした。
参考: スクリプトでの遅延計測
ついでに、SET後にセカンダリでGETをポーリングして値が反映されるまでの時間を計測するスクリプトで20回計測してみました。
レプリケーション遅延はデータ量やデータ構造、書き込み頻度などによって変わるため、少量データでの簡易的な計測である今回の数値はあくまで参考値です。
timestamp,key,set_time,replication_ms,retries
2026-03-13 07:20:22.606,lag-test-1,...,288,0
2026-03-13 07:20:23.410,lag-test-2,...,288,0
2026-03-13 07:20:24.212,lag-test-3,...,296,0
2026-03-13 07:20:25.022,lag-test-4,...,293,0
2026-03-13 07:20:25.829,lag-test-5,...,290,0
...
結果は以下のとおりです。
| 指標 | 値 |
|---|---|
| 平均遅延 | 296ms |
| 最大遅延 | 326ms |
| 最小遅延 | 284ms |
| 計測回数 | 20回 |
| リトライ発生 | 0回(全件1回目のGETで取得) |
20回すべてリトライなしで値が取得でき、平均遅延は296msでした。
この値にはSETコマンドの実行時間 + レプリケーション + GETコマンドの実行時間が含まれているため、CloudWatchメトリクスでも確認してみます。
CloudWatchメトリクスでの確認
CloudWatchのGlobalDatastoreReplicationLagメトリクスでも確認しました。
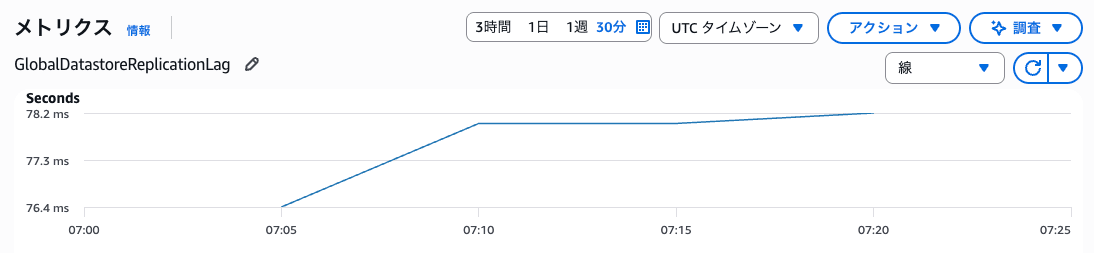
CloudWatch上では約78msで安定していました。
スクリプト計測の296msとの差は、スクリプト側がSET→GETの往復時間(東京へのSET + バージニア北部へのGET)を含んでいるのに対し、CloudWatchメトリクスは純粋なレプリケーション遅延のみを計測しているためです。
検証2: フェイルオーバー
フェイルオーバーの実行方法
Global Datastoreのリージョン間フェイルオーバーは自動では行われないため、手動操作が必要です。
AWS CLIでは以下のコマンドで実行します。
aws elasticache failover-global-replication-group \
--global-replication-group-id <Global Datastore ID> \
--primary-region us-east-1 \
--primary-replication-group-id valkey-global-virginia
マネジメントコンソールからもグローバルデータストアの画面でフェイルオーバーを実行できます。
モニタースクリプトによる観測
フェイルオーバー中の状態変化を正確に記録するため、モニタースクリプトをバックグラウンドで起動してからフェイルオーバーを実行しました。
モニタースクリプトは1秒ごとに東京・バージニア北部それぞれに対して読み取り(GET)と書き込み(SET)を試行し、結果をCSVログに記録します。
書き込みについては、valkey-cliがREADONLYエラーでも終了コード0を返すため、コマンドの出力文字列で判定しています。
モニターログの結果
timestamp,tokyo_read,tokyo_write,virginia_read,virginia_write,note
2026-03-13 07:37:32,OK,OK,OK,READONLY, ← フェイルオーバー前の通常状態
...
2026-03-13 07:39:17,OK,OK,OK,OK,virginia_promoted ← バージニア北部が書き込み可能に(昇格)
...
2026-03-13 07:39:26,OK,READONLY,OK,OK,tokyo_demoted+virginia_promoted ← 東京がREADONLYに(降格)
...
2026-03-13 07:40:31,OK,READONLY,OK,OK,tokyo_demoted+virginia_promoted ← 安定状態
フェイルオーバーの所要時間
| イベント | 時刻(UTC) | フェイルオーバー開始からの経過 |
|---|---|---|
| フェイルオーバーコマンド実行 | 07:38:02 | - |
| バージニア北部が書き込み可能に(昇格) | 07:39:17 | 約75秒 |
| 東京がREADONLYに(降格) | 07:39:26 | 約84秒 |
今回の検証では約75〜84秒で切り替わりました。
データ量や環境によって変わる可能性はありますが、公式ドキュメントの「通常1分未満」に近い結果です。

フェイルオーバー後のデータ確認
フェイルオーバー前に書き込んだデータが、新プライマリ(バージニア北部)で読み取れることを確認します。
# 新プライマリ(バージニア北部)でフェイルオーバー前のデータを確認
$ valkey-cli -h <バージニア北部エンドポイント> GET failover-test
"written-before-failover-1773387207"
# 新プライマリへの書き込みテスト
$ valkey-cli -h <バージニア北部エンドポイント> SET after-failover "from-new-primary"
OK
# 新セカンダリ(東京)でレプリケーション確認
$ valkey-cli -h <東京エンドポイント> GET after-failover
"from-new-primary"
フェイルオーバー前のデータは新プライマリで問題なく読み取れました。
また、新プライマリ(バージニア北部)から新セカンダリ(東京)へのレプリケーションも正常に動作しています。
フェイルオーバー後のエンドポイント
フェイルオーバー前後でリージョナルのエンドポイントDNS名は変わりません。
# フェイルオーバー後のエンドポイント確認
$ aws elasticache describe-replication-groups \
--replication-group-id valkey-global-tokyo \
--query 'ReplicationGroups[0].NodeGroups[0].PrimaryEndpoint' \
--region ap-northeast-1
{
"Address": "valkey-global-tokyo.xxxxx.ng.0001.apne1.cache.amazonaws.com",
"Port": 6379
}
$ aws elasticache describe-replication-groups \
--replication-group-id valkey-global-virginia \
--query 'ReplicationGroups[0].NodeGroups[0].PrimaryEndpoint' \
--region us-east-1
{
"Address": "valkey-global-virginia.xxxxx.ng.0001.use1.cache.amazonaws.com",
"Port": 6379
}
エンドポイントのDNS名はフェイルオーバー前後で変わりませんが、Global Datastoreにはプライマリを自動追従するグローバルエンドポイントがないため、アプリケーション側で書き込み先を切り替える必要があります。
最後に
ElastiCache Global DatastoreをValkeyエンジンで構築し、クロスリージョンレプリケーションとフェイルオーバーの動作を確認しました。
この記事がどなたかの参考になれば幸いです。










