
ELBのアクセスログをAWS LambdaでElasticsearchに取り込む
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
藤本です。
AWS LambdaがPythonに対応してから色々なことを試しています。
概要
ELBのアクセスログはS3に出力することが可能です。5分なり、1時間なりで定期的にS3にログファイルが作成されます。S3に集約することは簡単でもS3に出力されたファイルはAPIによるアクセスが必要、ログファイルが細かく分割されていることもあり、可読性の面においては優れていません。
そこでAWSではログを管理できるサービスとしてCloudWatch LogsやAmazon Elasticsearch Serviceを用意しています。Amazon Elasticsearch Serviceに関してはAWSのGithubでS3 -> AWS Lambda -> Elasticsearchの流れとなるソースコードが公開されています。ありがたい!これにより簡単にログデータを取り込むことが可能です。
一方、Elasticsearchはスキーマ定義が可能です。ELBのアクセスログにはアクセス元やアクセス先の情報、ELBやインスタンスの各処理時間、処理を渡したインスタンス、HTTPレスポンスのステータスコードなど様々な情報が一行に書かれています。それらを管理しないことは大変もったいないです。スキーマ定義することでこれらの情報をKibanaで簡単に可視化することができます。例えば、あるインスタンスのレスポンスだレスポンスが遅い、あるアクセス先のページだけレスポンスが遅い、あるページへのステータスコードが404だ。そういった情報を知ることができます。
ということで、今回はELBのアクセスログをスキーマ定義し、Amazon Elasticsearch Serviceに格納するLambda Functionを作成します。
ELBのアクセスログをfluent-plugin-elb-logを使ってkibanaで表示するのfluentdをAWS Lambdaに置き換えたものとなります。
と同時にハマったところを最後に紹介します。
設定は以下のような流れとなります。
- 事前準備
- ELBのログ出力設定
- Amazon Elasticsearch Serverce作成
- Amazon Elasticsearch Service設定
- Index Template作成
- AWS Lambda Funcion作成
- Lambda Function作成
- コードアップロード
- Event sources作成
- 動作確認
- ログ取り込み
- Kibanaによる可視化
環境
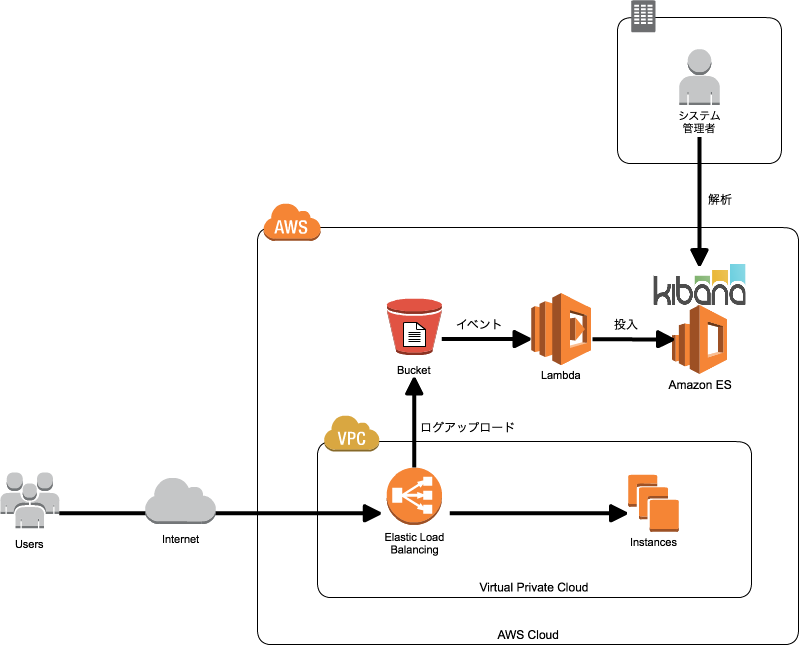
やってみた
事前準備
1. ELBのログ出力設定
ELBのログ出力設定はELBがアクセスログを出力できるようになりました!を参照。
2. Amazon Elasticsearch Service作成
Amazon Elasticsearch Serviceのドメイン作成は[新機能]Amazon Elasticsearch Serviceがリリースされました!を参照。 .oO(佐々木さんのブログをたくさん紹介してる)
Amazon Elasticsearch Service設定
1. Index Template作成
ELBのアクセスログ用にIndex Templateを作成します。今回、ELBのログ出力のフォーマットを参考にMappingのTemplateを作成します。ELBのフォーマットはアクセスログのエントリを参照ください。
# curl -XPUT 'http://search-****************.ap-northeast-1.es.amazonaws.com/_template/template1' -d '{
"template": "awslogs-*",
"mappings": {
"ELB_NAME": {
"properties": {
"timestamp": { "type": "date" },
"elb": { "type": "string" },
"client_ip": { "type": "ip" },
"client_port": { "type": "integer" },
"backend_ip": { "type": "ip" },
"backend_port": { "type": "integer" },
"request_processing_time": { "type": "float" },
"backend_processing_time": { "type": "float" },
"response_processing_time": { "type": "float" },
"elb_status_code": { "type": "integer" },
"backend_status_code": { "type": "integer" },
"received_bytes": { "type": "long" },
"sent_bytes": { "type": "long" },
"request_method": { "type": "string" },
"request_url": { "type": "string" },
"request_version": { "type": "string" },
"user_agent": { "type": "string" }
}
}
}
}'
{"acknowledged" : true}
AWS Lambda Funcion作成
1. Lambda Function作成
PythonのLambda Functionを作成します。アクセスログ件数が多いと時間がかかります。実行時間をデフォルトの3秒から伸ばしてください。今回は3分としています。ちなみに今回のソースでは13,000件の行数で13〜15秒ぐらいの処理時間となりました。RoleはS3にアクセスするためS3の読み取り権限が必要となります。Memoryはログファイルのサイズが大きい場合は合わせて増やしましょう。(S3から取得したオブジェクトをReadする時に一括じゃなく読み取る方法あるのかな。botocoreだとreadで一括で取ってくるんだよなぁ。)
2. コードアップロード
ソースコードはGistにアップロードしました。Python Elasticsearch Clientを利用していますので(触ってみたかっただけ)、Lambda Functionにアップロードする際はライブラリを同梱してください。またPython Clientを利用しているがため、IAM認証を実装していません。IAM認証を取り入れる場合はAmazon Elasticsearch ServiceのIAM Roleによるアクセス制御を参照ください。
現在は2つのパラメータを設定可能です。コメントアウトで括られた変数に設定してください。
- ES_HOST
- 接続先となるElasticsearchのホスト名、IPアドレス
- INDEX_PREFIX
- ログを格納するINDEX名のプレフィックス
- INDEX名は「INDEX_PREFIX-YYYYMMDD」の形式となります
3. Event sources作成
Lambda Functionに対してEvent sourcesを作成します。今回はS3に対してELBのアクセスログが作成される度にLambda Functionが実行されるようにしたいため、Event source typeをS3のObject Createdに設定します。Bucketは1. ELBのログ出力設定で作成したS3バケットを指定してください。必要に応じてPrefixを指定してください。
動作確認
1. ログ取り込み
ELBのログが出力するのを待ちましょう。実行の有無はLambda FunctionのMonitoringやCloudWatch Logsから確認できます。

2. Kibanaによる可視化
取り込んだデータから可視化しましょう。今回は某ブログのアクセスログを取り込みました。 例えば、左のグラフは時間毎の1秒刻みの処理時間の件数、右のグラフは時間毎の最も長い処理時間を表しています。

ハマったところ
簡単にハマったところをご紹介します。今回、投入したログファイルが13,000件ほどあったことで最初の実装では3分でタイムアウトしていしまいました。
- Bulk APIを使いましょう 最初の実装では一件一件、ドキュメントをPOSTしていたところ、このWebリクエストに時間がかかりました。当たり前といえば、当たり前ですが、、、Elasticsearchにはまとめてデータをインポート可能なBulk APIがあります。json形式で命令、投入データを一行づつ順に書いていくことでまとめての処理が可能となります。
-
型変換はElasticsearchのMappingに任せましょう Elasticsearchは投入されたデータを認識して、型を自動マッピングする機能があります。当初、投入するデータを一つ一つを正規表現で判断して型変換を実装していましたが、この処理に時間がかかっていることが分かりました。この処理時間を避けるために事前にTypeのMappingを定義しておくことでLambda Function側の実装をなくしました。
まとめ
いかがでしたでしょうか? ELBのアクセスログをElasticsearchに集約する方法は割とちまたにあふれています。 今回はELBのアクセスログを対象としましたが、ELBに限らずCloudFrontやRDSなどの様々なログ情報を全てElasticsearchに集約し、ボトルネックがどこなのか可視化された情報から発見できれば嬉しいですね。ということで色々な集約スクリプト作成がんばります。










