
知らないと危ないかも?BigQuery リモート関数の意外な落とし穴
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Google Cloud データエンジニアのはんざわです。
BigQuery のリモート関数は非常に便利な機能ですが、使い方によっては思わぬ落とし穴があることをご存知でしょうか?
本ブログでは、とある案件で遭遇したリモート関数の落とし穴について紹介します。
筆者はこの落とし穴により、約 10 万円の課金が発生しかねない状況に陥りました。
幸い課金は免れましたが、この経験から学んだリモート関数使用時の注意点と対策方法を紹介します。
注意事項
-
本ブログでは、リモート関数の詳細については紹介しません。
-
リモート関数を否定するつもりは全くありません。
SQL だけでは実現できないような処理もリモート関数であれば可能であり、非常に有用な機能だと思います。しかし、今回の件を通じて、使用する際には注意が必要だと感じました。
落とし穴の詳細
まずは、筆者が当時やりたかったこととその過程で発生した現象を簡単に紹介します。
その後に発生した現象を実際に再現してみます。
やりたかったことと発生した問題
当時、やりたかったことの大まかな流れは以下のとおりです。
- リクエストボディから受け取ったデータを API に渡し、そのレスポンスを返す Cloud Run Functions(旧 Cloud Functions)を作成する
- 1 の Cloud Run Functions をリモート関数に登録する
- 2 のリモート関数を使用し、BigQuery のテーブルを更新する
この過程の 3 で、当初想定していたよりも多くの Cloud Run Functions が実行され、高額な課金が発生する恐れがありました。
発生した事象の再現
それでは、実際に発生した事象を再現してみましょう。
呼び出される Cloud Run Functions のコードは以下のとおりで、BigQuery のリモート関数経由で呼び出されます。
コード自体はシンプルで、BigQuery から受け取ったデータの件数を出力し、そのまま返すだけの処理となっています。
import json
import functions_framework
@functions_framework.http
def hello_http(request):
request_json = request.get_json()
calls = request_json["calls"]
# データ件数を出力
print(f"受け取ったデータ件数:{len(calls)}")
return json.dumps({"replies": [str(call[0]) for call in calls]})
この Cloud Run Functions を以下のクエリでリモート関数に登録します。
CREATE OR REPLACE FUNCTION test.remote_function(input STRING) RETURNS STRING
REMOTE WITH CONNECTION `asia-northeast1.bq-remote-functions`
OPTIONS (
endpoint = 'https://asia-northeast1-<PROJECT_ID>.cloudfunctions.net/bq-remote-function'
);
リモート関数の登録方法:Create a remote function
最初に以下のクエリでサンプルテーブルを作成します。
CREATE TABLE test.sample_table AS (
SELECT
_u AS alp
FROM
UNNEST(['A', 'B', 'C', 'D', 'E']) AS _u
);
まずは、シンプルに以下のクエリでリモート関数を試してみます。
SELECT
test.remote_function(alp)
FROM
test.sample_table
- 出力ログ

ログからも分かるように、1 つの Cloud Run Functions が 5 レコードを受け取っています。
次に、テーブルを更新するために UPDATE 構文を使った以下のクエリでリモート関数を試してみます。
UPDATE test.sample_table
SET
alp = test.remote_functions(alp)
WHERE
TRUE
- 出力ログ
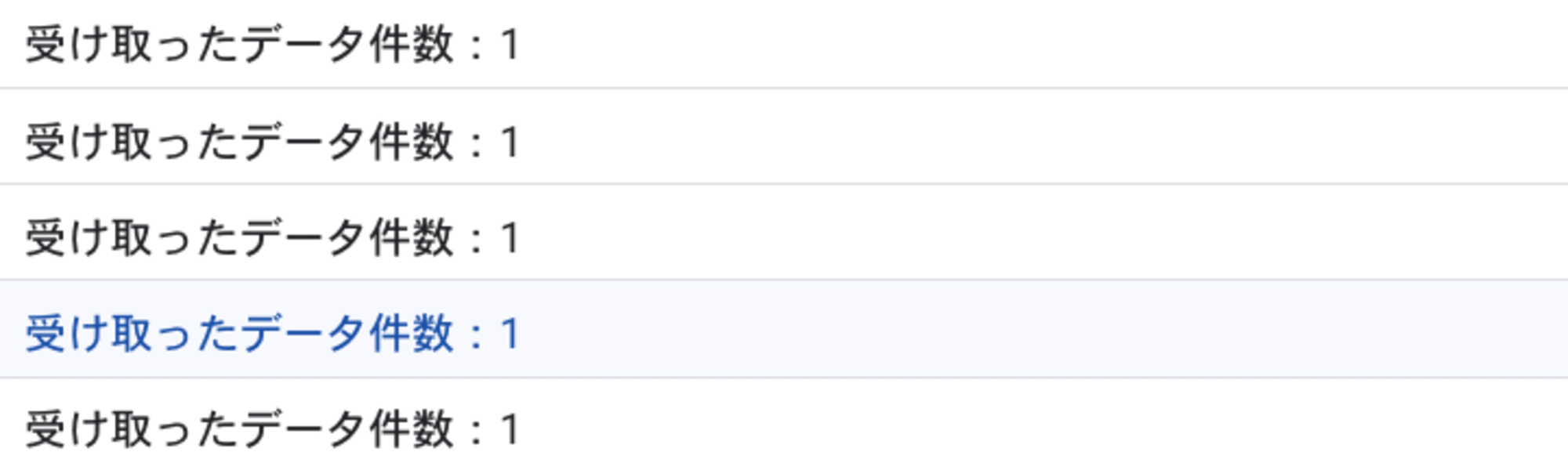
問題は、このようなクエリだと 1 つの Cloud Run Functions で 1 レコードしか受け取らないことです。
つまり、UPDATE 構文の SET 句でリモート関数を使用すると、更新の対象となったデータ件数分だけ Cloud Run Functions が起動されることになります。
今回の例だと、対象のテーブルが 5 レコードだったので 5 回 Cloud Run Functions が起動されました。
しかし、仮にこれが 1 万件だったら 1 万回起動されますし、100 万件だったら 100 万回起動されてしまいます。
筆者は、500 万件のテーブルを更新する予定だったのですが、実行する一歩手前でこの仕様に気づき、500 万回起動されるのを未然に防ぐことができました。
課金額の概算
ここからは仮に Cloud Run Functions が 500 万回起動された場合、いくらになるのか算出してみます。
料金の計算には、公式が提供している以下の料金計算ツールを使用します。
案件の対応時に想定していた構成は、以下のとおりになります。
- リージョン:
asia-northeast1(東京) - 割り当てられるメモリ:
2 GiB- リモート関数である程度まとまったデータを扱う想定だったため、少し大きめのメモリが必要でした
- 割り当てられる CPU:
1- 2 GiB 以上のメモリを割り当てるためには、1 vCPU 以上の割り当てが必要です
- 呼び出し回数:
5 million(= 500 万回) - リクエストの実行時間:
5 秒(= 5000 ms)- 処理時間の大まかな平均値にしています
- 最大インスタンス数:
1000 - 同時実行数:
1
上記の構成で料金を見積もると、以下のような結果になります。
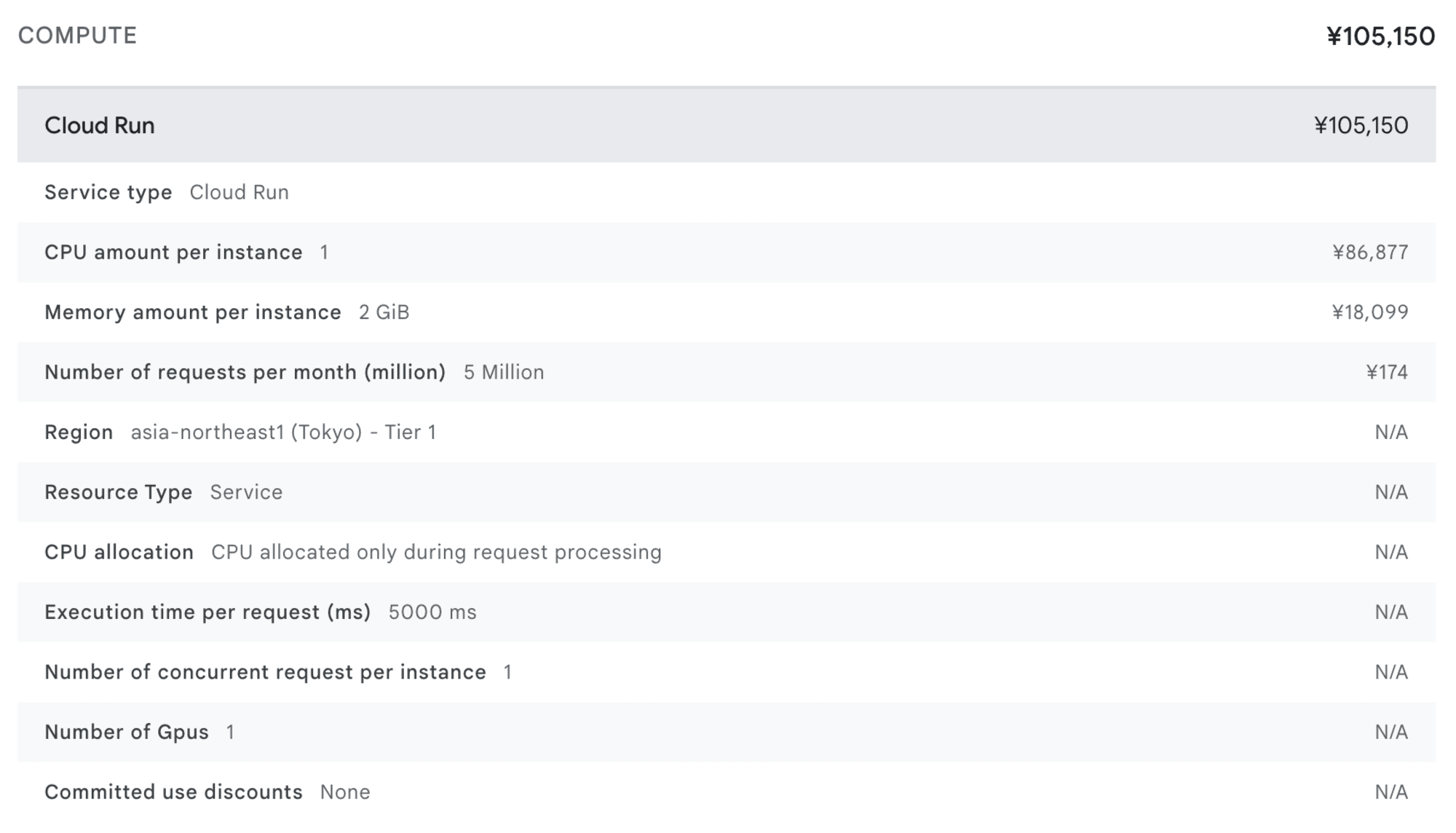
ご覧の通り、料金はなんと 500 万回あたり 10 万 5150 円 という結果になりました。
たった 500 万件のデータを更新するだけでこの料金は非常に高額ですね...
なお、この料金は Cloud Run Functions の利用料金のみを指しています。別途、BigQuery のデータスキャン料金やスロット料金などが発生します。(この料金と比べたら微々たるものだと思いますが...)
また、Cloud Run Functions の料金は、割り当てるリソースや実行時間によって大きく変動します。
今回の構成における見積もりは約 10 万円でしたが、構成次第で安くなる可能性もあれば、逆に高くなってしまう可能性もあります。
回避方法
回避方法として、UPDATE 構文の SET 句でのリモート関数の使用を避けることを推奨します。
代わりに、事前にサブクエリや一時テーブルでリモート関数による処理を済ませるようにします。
具体的には、以下のようなクエリになります。
UPDATE test.sample_table AS t
SET
alp = alp_processed
FROM
(
SELECT
alp,
test.remote_functions(alp) AS alp_processed
FROM
test.sample_table
) AS s
WHERE
t.alp = s.alp
- 出力ログ
こうすることで、Cloud Run Functions の起動を最小限に抑えられ、リソースを効率的に活用できます。
さらに、以下の対策を実施することで、同様の問題の早期発見や影響の軽減が可能です。
-
BigQuery
- クエリの実行時間を監視する
- 必要に応じて、クエリのタイムアウト時間を短く設定する
- 可能であれば、入力をリモート関数に渡す前に絞り込む
-
Cloud Run Functions
- コードレベルで、各処理が受け取るデータ件数を出力するようにする
- 過剰なリソースを割り当てないようにする
- 可能であれば、最大インスタンス数をデフォルトの値にする
おまけ
ここまでの説明で、特定の状況下でリモート関数を使用すると、予想外に大量の Cloud Run Functions が呼び出される落とし穴があることを紹介しました。
しかし、「本当に 500 万回も実行されるの?」と疑問に思われた方も多いのではないでしょうか。
そこで、実際に 500 万回呼び出せるか検証してみました。
ただし、料金の高騰を避けるため、Cloud Run Functions に割り当てるリソースを最小限に抑えた上で確認しました。
先ほど作成したリモート関数を以下のクエリで呼び出してみます。
UPDATE samples.github_timeline
SET
repository_description = test.remote_functions(repository_description)
WHERE
TRUE
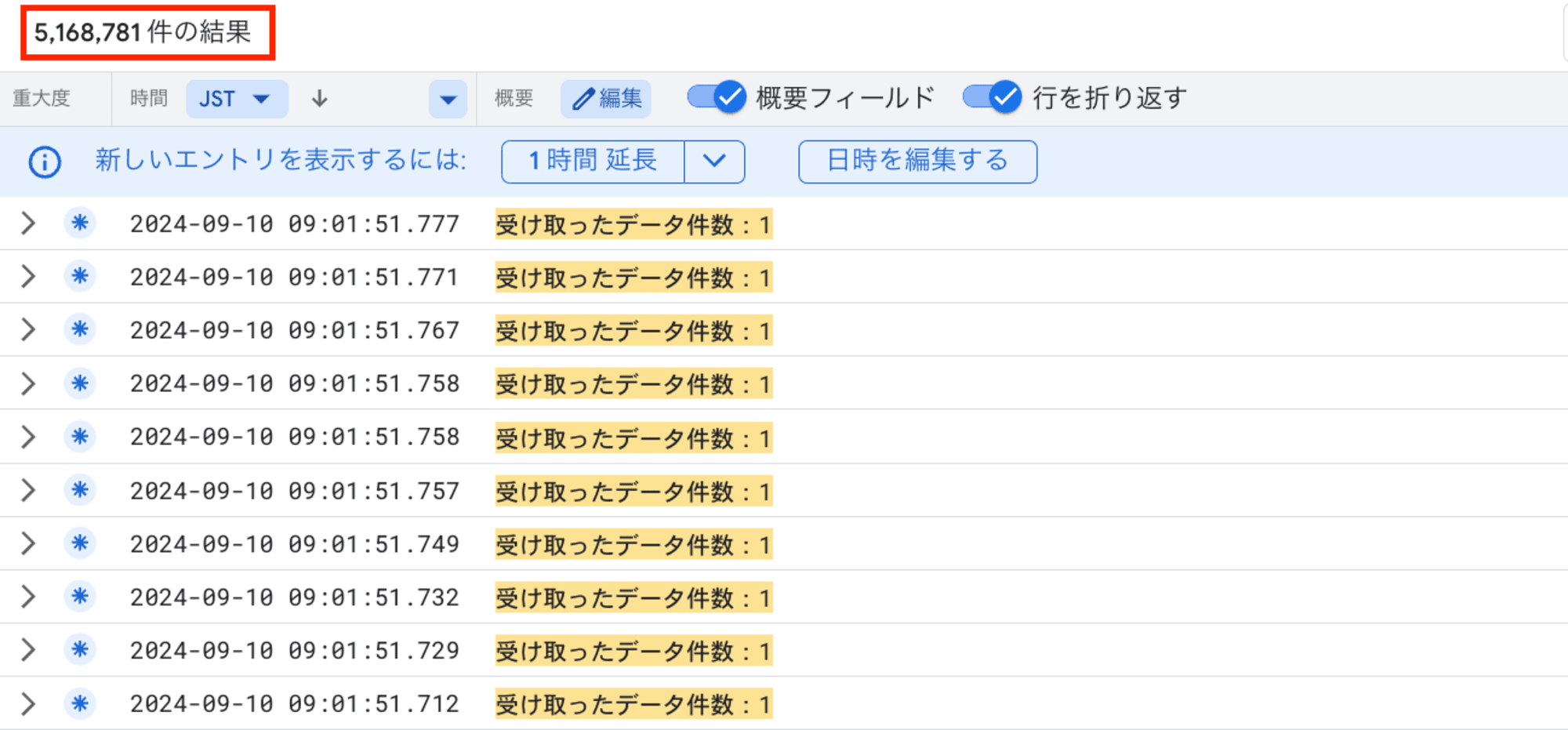
検証の結果、以下のキャプチャのとおり、Cloud Run Functions が 500 万回以上呼び出されたことが確認できました。
この回数は、受け取ったデータ件数:1 というログメッセージの出現回数をカウントすることで計測しました。
上記の結果は、Cloud Logging のログエクスプローラーで以下のクエリを実行して得られたものです。
(resource.type = "cloud_function"
resource.labels.function_name = "bq-remote-function"
resource.labels.region = "asia-northeast1")
OR
(resource.type = "cloud_run_revision"
resource.labels.service_name = "bq-remote-function"
resource.labels.location = "asia-northeast1")
severity>=DEFAULT
SEARCH("受け取ったデータ件数:1")
また、実行したクエリの結果は以下のとおりです。

実行時間が 6 時間を超えたため、タイムアウトしていました。
並列数や実行時間にも依りますが、せいぜい 6 時間で 500 万回が起動するのが限界かと推測されます。
このことから、前述した「クエリの実行時間を監視する」という対策の重要性がよくわかると思います。
リモート関数を使用したクエリの実行時間が予想以上に長い場合は、大量の関数が呼び出されている可能性があるため、早めに調査した方が良いと考えられます。
最後に
本ブログでは、BigQuery のリモート関数の意外な落とし穴について紹介しました。
最も伝えたかったことは、UPDATE 構文の SET 句でのリモート関数の使用は避けるべき ということです。
筆者もそうでしたが、BigQuery の高額課金といえば、大規模なテーブルをフルスキャンしてしまった事故を連想する人が多いと思います。
ある程度 BigQuery を使い慣れている人であれば、API の上限を設定したり、料金プランを変更したりすることで、このような事故を回避することは容易です。
しかし、今回紹介した事象を未然に制御することは不可能で、利用者が注意するしか方法がありません。
リスク軽減のため、本ブログで紹介した対策、特に以下の3つの対策を実施することが重要だと思います。
- Cloud Run Functions
- コードレベルで、各処理が受け取るデータ件数を出力するようにする
- 過剰なリソースを割り当てないようにする
- 可能であれば、最大インスタンス数をデフォルトの値にする
BigQuery のリモート関数は強力な機能ですが、その使用には少し注意が必要だと感じました。
リモート関数を使用する際は、本記事で紹介した落とし穴に十分注意を払いましょう。









