
Gemini APIのFile Search ToolでRAG構築が楽になるらしいので試す
gemini API に直接組み込まれたフルマネージド RAG システムが紹介されていました。
紹介記事によると、
検索パイプラインを抽象化することで、開発者はアプリケーション構築に集中できるようになります。自社データでGeminiをグラウンディング(根拠付け)し、より正確で関連性が高く検証可能な回答を提供します。
RAGの複雑さを処理してくれるので、開発ワークフローがとても早くなりますよということらしい。
遅ればせながら試していこうかと思います。
特徴とか
-
非常にコスト効率が良い
ストレージと検索時のエンベディング生成が無料。
課金されるのは初回インデックス時のエンベディング生成のみ(100万トークンあたり$0.15)。
-
シンプルで統合された開発体験
ファイルストレージ、最適なチャンキング戦略、エンベディング、取得したコンテキストのプロンプトへの動的注入を自動管理。
既存のgenerateContent APIで動作するため、導入が簡単。 -
強力なベクトル検索
最新のGemini Embeddingモデルを活用。
完全一致しなくても、意味とコンテキストを理解して関連情報を検索。
-
組み込み引用機能
回答に自動的に引用が含まれ、どの文書から情報が取得されたか明示。
-
幅広いフォーマットサポート
PDF、DOCX、TXT、JSON、一般的なプログラミング言語のファイル形式など。
解決してくれることは
File Search ToolはRAGの複雑さを処理してくれる ということで、以下のことを主にやってくれそうです。
- チャンキング戦略の自動最適化
- エンベディング生成とストレージ管理
- ベクトル検索基盤の提供
- 引用機能の組み込み
- スケーリングの自動化
以前RAGシステムをn8nで作成して試していたときは確かにチャンクデータを自分でなんとかして生成してからエンベッティングノードとかベクターストアのノードなど、いろんなノードを使ってました。
これでも相当楽だと感じていたけど、もっとシンプルにできそうですね。
試してみる
ドキュメントを見ながらJavascriptのコードで試していきます。
このAPIに渡すファイルですが、データベースのテーブル情報が書かれたものにします。
これは自然言語からデータを探索したりするための仕組みを整えるために作成しているものとなります。
※ テーブル概要、説明、カラム定義、データリネージ情報、サンプルクエリなどをまとめたマークダウン形式のファイル


こんな感じの。
APIキーの取得
https://aistudio.google.com/apikey から無料で取得可能で、環境変数 GOOGLE_API_KEY に設定するか、場合によってはコードで明示的に指定します。
const { GoogleGenAI } = require('@google/genai');
// APIキーを環境変数から取得
const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY });
// または直接指定
const ai = new GoogleGenAI({ apiKey: "YOUR_API_KEY" });
ファイル検索ストアに直接アップロードする方法でやる
ドキュメントのコードサンプルを自身の環境に置き換えて実行します。
プログラムの流れは、
- モジュールのインポート
- @google/genai ライブラリから GoogleGenAI クラスをインポート
- Gemini API と連携するための基本クラス
- AI インスタンスの初期化
- 環境変数 GOOGLE_API_KEY を使用して認証
- ai オブジェクトを通じて File Search Store やコンテンツ生成にアクセス
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: { displayName: 'cm-datanexus-file-search-store' }
});
- File Search Store の作成
- Gemini にアップロードしたファイルを検索・参照するための「ストレージ」を作成
- displayName: UI で表示される識別名
- 戻り値: ストレージの情報(fileSearchStore.name でストレージIDを取得)
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: '/Users/mori.ryosuke/workspaces/data-analytics/google-bigquery/cm-datanexus/metadata/docs/cm
_aws_marketplace_dataset/ProductFeed_V1_view.md',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'cm_aws_marketplace_dataset/ProductFeed_V1_view.md',
}
});
- ファイルのアップロード
- Markdown ファイルをストレージにアップロード
- パラメータ:
- file: アップロードするファイルのパス
- fileSearchStoreName: ストレージID
- displayName: 引用時に表示されるファイル名
- 戻り値: 非同期操作オブジェクト(operation.done で完了判定)
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
- アップロード完了待機
- ポーリング処理(5秒ごとに進捗確認)
- 流れ:
a. operation.done === false の間ループ
b. 5秒待機
c. 現在の操作ステータスを取得
d. 完了まで繰り返す
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: "販売しているプロダクトについて教えてください",
config: {
tools: [
{
fileSearch: {
fileSearchStoreNames: [fileSearchStore.name]
}
}
]
}
});
- Gemini にクエリを実行
- パラメータ:
- model: 使用モデル(gemini-2.5-flash = 高速版)
- contents: ユーザーのクエリ(質問内容)
- tools: 外部ツール設定
- fileSearch: ストレージ内ファイルを検索
- fileSearchStoreNames: 対象ストレージID
流れ:
-
ユーザーが「販売しているプロダクトについて教えてください」と質問
-
Gemini がアップロードされたファイルを検索
-
ファイル内容に基づいて回答生成
-
実行結果の表示と実行
- response.text: Gemini の回答テキスト
- run(): 非同期関数を実行(ただし、エラーハンドリングなし)
This method is only supported by the Gemini Developer API. エラーが出た場合
私のローカル環境だと、FileSearchStores.create を実行した際にこのエラーになりました。
ライブラリ内部でVertexAIだと判定されていた模様。。。
if (this.apiClient.isVertexAI()) {
throw new Error('This method is only supported by the Gemini Developer API.');
}
これを解決するにはGemini Developer API モードで明示的に初期化しました。
const ai = new GoogleGenAI({
apiKey: process.env.GOOGLE_API_KEY,
vertexai: false // Vertex AI モードを無効化
});
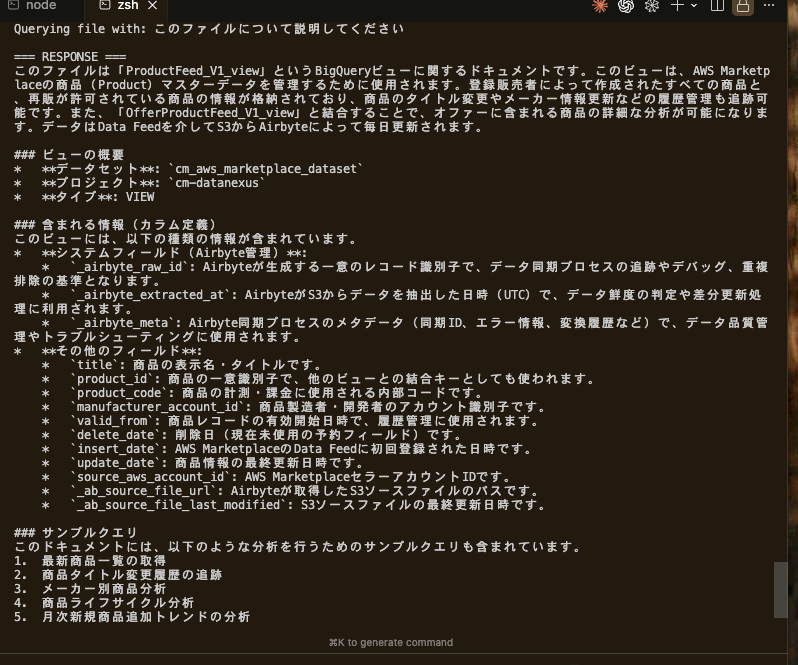
実行結果(ファイル検索ストアに直接アップロード)
こちらからの質問(このファイルについて説明してください)に対する回答をきっちり作ってくれていますね。
File Searchの基本的な仕組み
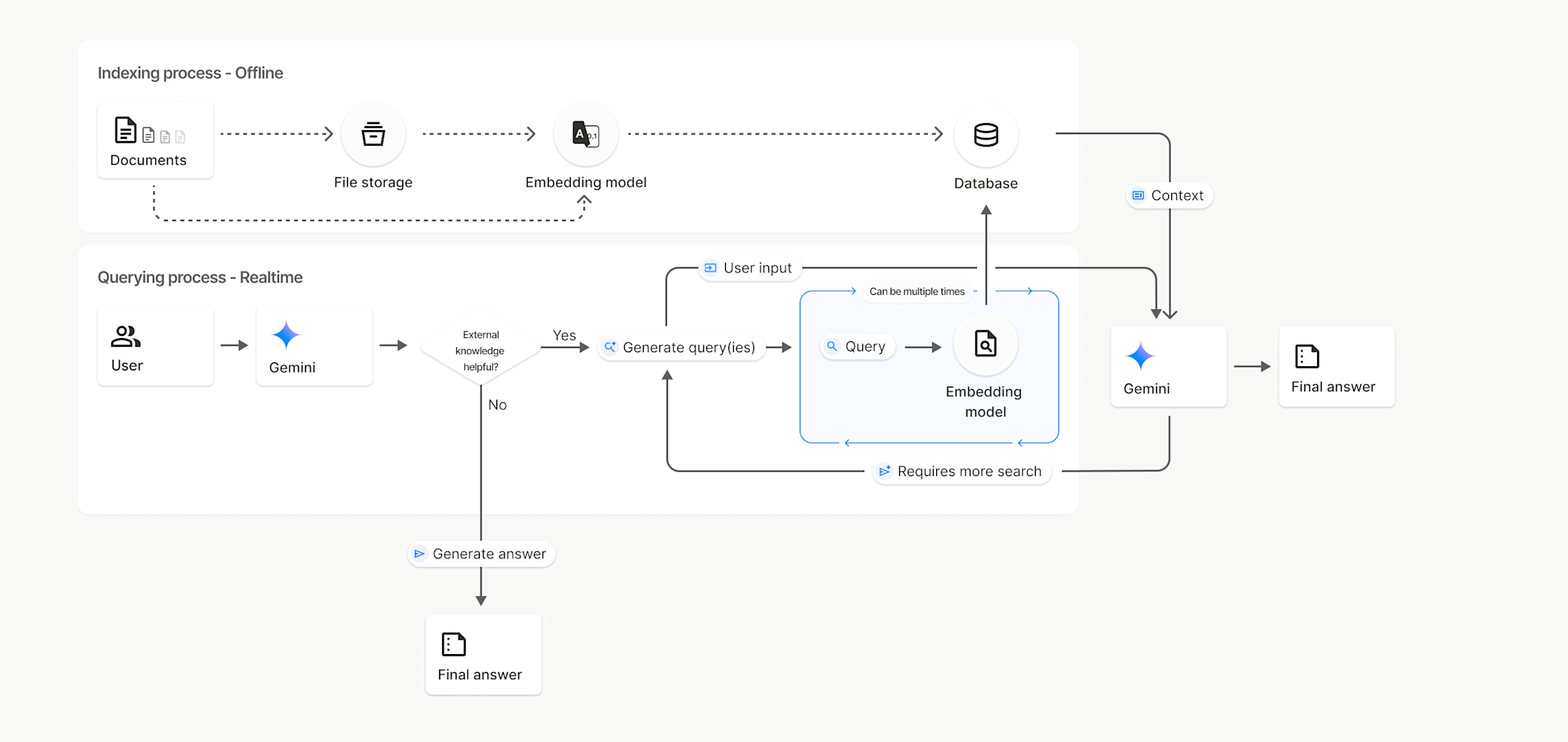
APIドキュメントにも詳しく書かれていますが、
どんな仕組みで実行されたかというと、
検索は従来のキーワードベース検索とは異なり、セマンティック検索を使用しています。これはクエリの意味とコンテキストを理解する手法です。ユーザの意図やクエリの意味を理解して、関連性の高い情報を提供するための技術。
処理の流れを簡潔にしてみると、
1. ファイルアップロード
↓
2. チャンク化(自動分割)
↓
3. エンベディング生成(gemini-embedding-001)
↓
4. ファイル検索ストアに保存
↓
5. ユーザークエリ → エンベディング変換
↓
6. ベクトル類似度検索
↓
7. 関連チャンクを取得してLLMに注入
↓
8. 回答生成(引用付き)
3つの主要コンポーネント
- ファイル検索ストア(FileSearchStore)
ドキュメントエンベディングの永続コンテナで、プロジェクトあたり最大10個作成可能です。
手動で削除するまで無期限に保存されており、ストレージ容量は階層により異なります。
- 無料: 1 GB
- Tier 1: 10 GB
- Tier 2: 100 GB
- Tier 3: 1 TB
- チャンキング設定
デフォルトで自動最適化されますが、カスタマイズも可能:
chunking_config = {
'white_space_config': {
'max_tokens_per_chunk': 200, # チャンクあたりの最大トークン数
'max_overlap_tokens': 20 # 重複トークン数
}
}
- カスタムメタデータ
ファイルにメタデータを付与してフィルタリング可能:
custom_metadata = [
{"key": "dataset_name", "string_value": "amazon_marketplace_data"},
]
# 検索時にフィルタ
metadata_filter = 'dataset_name="amazon_marketplace_data"'
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: "マーケットプレイスのデータから最新のオファーを調べて",
config: {
tools: [
{
fileSearch: {
fileSearchStoreNames: [fileSearchStore.name],
metadataFilter: metadata_filter,
}
}
]
}
});
実務での活用ポイント
- ドキュメントの整理
- 異なるプロジェクトやカテゴリごとにストアを分ける
- メタデータでさらに細かくフィルタリング
- 最適なチャンキング戦略
この辺りは実際に試して精度測る必要はありそうですね。
- 技術文書: 小さめのチャンク(200-300トークン)
- 物語・レポート: 大きめのチャンク(500-800トークン)
- コスト最適化
- 一度インデックス化すれば、検索は何度でも無料
- 頻繁に更新されないデータに最適
ただし、取得したドキュメントトークンは、通常のコンテキストトークンとして課金されます(LLMの利用)
現在試しているメタデータ管理やデータの自然言語検索に、この仕組みがかなり使えそうな感じです。
ファイルのインポートは、既存のファイルをアップロードしてファイルストアにインポートすることもできますので、
Googleドライブや、もしかするとGithubで管理しているドキュメントにも対応できるかも。
n8nを使ったハイブリット環境なんかもやってみたい。









