
【アップデート】Gemini Enterprise Agent RuntimeのAgent IdentityがGAとなりました #GoogleCloudNext
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
2026年4月22日付の Google Cloud リリースノートにて、Gemini Enterprise Agent Runtime の Agent Identity が General Availability(GA) となりました。
AI エージェントをプロダクションで運用する上で「エージェントにどうやって安全に権限を与えるか」が重要になってきます。これまでは多くの場合サービスアカウントを使ってきましたが、Agent Identity はエージェント専用のアイデンティティを自動払い出しすることで、より安全な認証・認可を実現します。
今回は、Agent Identity の概要とサービスアカウントとの違いを整理した上で、ADK エージェントに Cloud Storage のデータを読み込むツールを持たせ、Gemini Enterprise Agent Runtime 上で Agent Identity を使って権限管理するまでの流れを見ていきたいと思います。
Agent Identity とは
Agent Identity は、Gemini Enterprise Agent Runtime にデプロイされたエージェントに自動的に付与される エージェント専用の暗号化アイデンティティです。SPIFFE 標準に基づいており、エージェントが MCP サーバー・クラウドリソース・エンドポイント・他のエージェントに対して安全に認証できるようにします。
従来の IAM プリンシパル(ユーザー・サービスアカウント)と同様に、IAM の allow/deny ポリシーでエージェントに対するアクセス制御を行えます。加えて、Agent Identity はエージェントのライフサイクルに紐づいており、エージェントを削除すれば ID も消滅します。
エージェントが Gemini Enterprise Agent Runtime にデプロイされると、SPIFFE URI と IAM プリンシパル識別子の 2 つの形式で ID が払い出されます。
# SPIFFE URI(エージェント間認証・mTLS 通信に使用)
spiffe://TRUST_DOMAIN/resources/SERVICE/RESOURCE_PATH
# IAM プリンシパル識別子(IAM ポリシーへの記述に使用)
principal://TRUST_DOMAIN/NAMESPACE/AGENT_NAME
# 例(IAM プリンシパル識別子)
principal://agents.global.org-123456789012.system.id.goog/resources/aiplatform/projects/9876543210/locations/us-central1/reasoningEngines/my-test-agent
TRUST_DOMAIN は Vertex AI API を有効化した際に自動でプロビジョニングされます。
- 組織が存在する場合:
agents.global.org-ORGANIZATION_ID.system.id.goog - 組織がない場合:
agents.global.project-PROJECT_NUMBER.system.id.goog
サービスアカウントとの比較
| 観点 | サービスアカウント | Agent Identity |
|---|---|---|
| ID の単位 | プロジェクト単位で作成 | エージェント単位で自動払い出し |
| ライフサイクル | 明示的に削除するまで存在 | エージェントの削除と同時に消滅 |
| 認証方式 | サービスアカウントキー or Workload Identity | mTLS + DPoP + Certificate-bound tokens |
| 複数ワークロードへの共有 | 複数ワークロードで共有可能 | デフォルトで共有不可 |
| 偽装(impersonation) | iam.serviceAccounts.actAs で偽装可能 |
偽装不可 |
| 長期有効キー | キーファイルの発行が可能 | 長命キーの生成不可 |
| クレデンシャルの盗用リスク | キーが流出すると任意の環境で悪用可能 | 盗まれても別環境で再利用不可 |
| 最小権限の実現 | エージェントごとに手動で SA を作成・管理 | エージェント単位で自動管理 |
セキュリティの仕組み
Agent Identity のクレデンシャルは、Google が管理する Context-Aware Access(CAA)ポリシーによってデフォルトで保護されています。
CAA ポリシーは DPoP(Demonstrating Proof of Possession)認証 と mTLS を強制することでトークン盗難を防ぎます。具体的には以下の仕組みで動作します。
- エージェントが Gemini Enterprise Agent Runtime にデプロイされると、x509 証明書が自動プロビジョニングされます
- 払い出された Google Cloud アクセストークンはエージェントの x509 証明書に**暗号的に束縛(Certificate-bound tokens / RFC 8705)**されます
- 証明書を持つ正規のランタイム環境以外でトークンを使おうとすると、
401 Context-Aware Access requirements are not metエラーが返ります
これにより、クレデンシャルが盗まれても Credential Theft・Account Takeover(ATO)攻撃を防ぐことができます。
認証モデル
Agent Identity は、アクセス先に応じて 3 つの認証モデルをサポートしています。
| モデル | 用途 | 認証方式 |
|---|---|---|
| Agent's own authority | Google Cloud リソースへのアクセス | Agent Identity(Cloud ベース ID) |
| User-delegated authority | ユーザーの代わりに外部ツールを操作 | OAuth 2.0 3-legged |
| Machine-to-machine | 外部サービスへのシステム連携 | OAuth 2.0 2-legged |
今回のハンズオンは Agent's own authority のパターンです。エージェント自身の権限で Cloud Storage にアクセスします。
Auth manager
Agent Identity には Auth manager というコンポーネントも含まれており、API キーや OAuth 認証情報をエージェントに安全に提供するための保管庫として機能します。User-delegated authority や Machine-to-machine 認証で外部サービスに接続する際に利用します。
試してみた
Cloud Storage バケットに商品情報ファイルを置き、ADK エージェントにそのファイルを読み込むツールを持たせます。Agent Identity でバケットへのアクセス権を付与することで、サービスアカウントなしでエージェントが Cloud Storage のデータにアクセスできる構成を確認します。
前提条件
- Google Cloud プロジェクトが作成済みであること
- 組織(Organization)に所属するプロジェクトであること
gcloudCLI がインストール・認証済みであること- Python 3.10 以上と
uvパッケージマネージャーがインストール済みであること
ハンズオンの実行には、以下の IAM ロールが必要です。
| ロール | 用途 |
|---|---|
roles/aiplatform.user |
Gemini Enterprise Agent Runtime へのデプロイ |
roles/storage.admin |
バケットの作成・データのアップロード・エージェントへの権限付与 |
roles/iam.securityAdmin |
エージェントへの IAM ポリシー付与 |
roles/serviceusage.serviceUsageAdmin |
必要な API の有効化 |
環境変数の設定と API の有効化
まずは、ハンズオンで使用するプロジェクト名、Cloud Storage バケットの名前、リージョンなどを環境変数として設定します。
また、必要な API も有効化しておきます。
export PROJECT_ID="your-project-id"
export LOCATION="us-central1"
export STAGING_BUCKET="your-staging-bucket" # デプロイ用バケット
export DATA_BUCKET="your-data-bucket" # データ用バケット(別バケット推奨)
gcloud config set project $PROJECT_ID
gcloud services enable \
aiplatform.googleapis.com \
storage.googleapis.com
Cloud Storage にデータを準備する
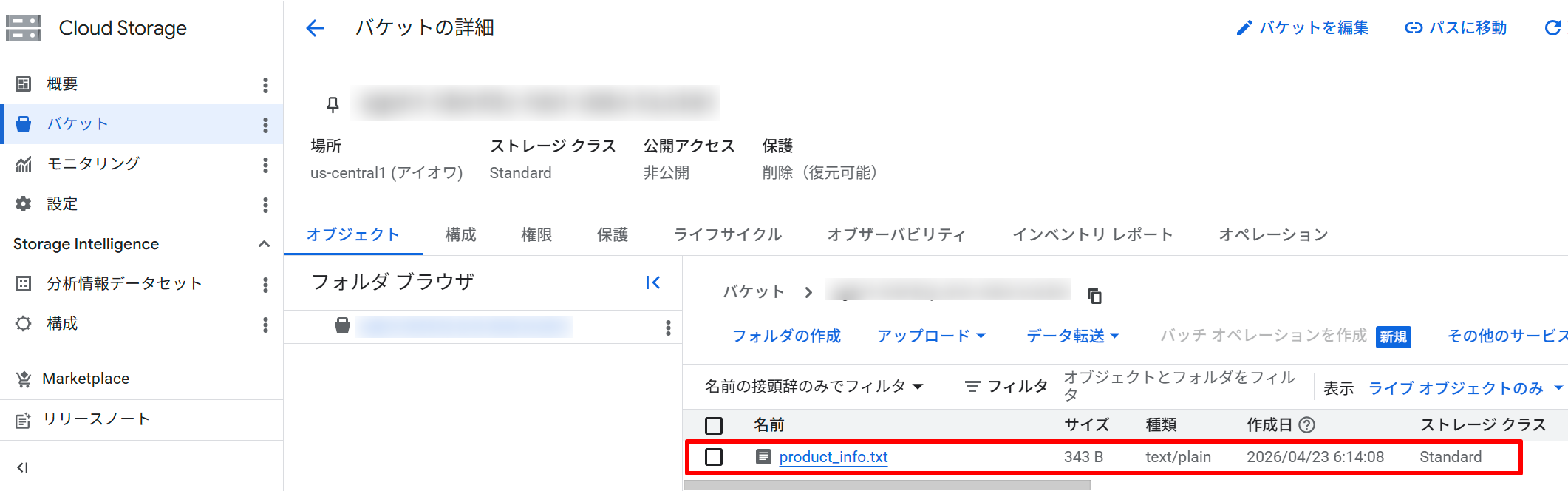
まず、エージェントが読み込む対象のバケットとファイルを作成します。
# デプロイ用バケットの作成
gcloud storage buckets create gs://$STAGING_BUCKET \
--location=$LOCATION \
--uniform-bucket-level-access
# データ用バケットの作成
gcloud storage buckets create gs://$DATA_BUCKET \
--location=$LOCATION \
--uniform-bucket-level-access
# サンプルデータファイルの作成とアップロード
cat > product_info.txt << 'EOF'
【商品名】Cloud Storage ストレージプラン
【価格】標準ストレージ: $0.020/GB/月
【概要】
Google Cloud Storage はグローバルに利用できるオブジェクトストレージです。
耐久性 99.999999999%(イレブンナイン)を誇り、
あらゆる規模のデータを安全に保管できます。
EOF
gcloud storage cp product_info.txt gs://$DATA_BUCKET/product_info.txt
バケットの作成と、ファイルのアップロードが完了しました。
Python 環境のセットアップ
ハンズオンで使用する Python 環境のセットアップを実行します。
mkdir agent-identity-demo && cd agent-identity-demo
uv init --bare --python 3.12
uv add "google-cloud-aiplatform[adk,agent_engines]" google-cloud-storage
touch agent.py deploy.py
プロジェクト構成は以下のようになります。
$ tree agent-identity-demo
agent-identity-demo
├── agent.py
├── deploy.py
├── pyproject.toml
└── uv.lock
エージェントの実装
agent.py に Cloud Storage からファイルを読み込むツール付きのエージェントを実装します。
from google.adk.agents import Agent
from google.cloud import storage
def read_file_from_gcs(bucket_name: str, blob_name: str) -> str:
"""Cloud Storage からファイルの内容を読み込む
Args:
bucket_name: 読み込むバケット名
blob_name: 読み込むオブジェクト名
Returns:
ファイルの内容(テキスト)
"""
# Gemini Enterprise Agent Runtime 上では ADC が自動的に Agent Identity を使用する
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
return blob.download_as_text()
agent = Agent(
model="gemini-2.5-flash",
name="gcs_reader_agent",
instruction=(
"あなたは Cloud Storage に保存されたデータを読み込んで回答するアシスタントです。"
"ユーザーから質問を受けたら、適切なファイルを read_file_from_gcs ツールで取得し、"
"その内容に基づいて回答してください。"
),
tools=[read_file_from_gcs],
)
storage.Client() はデフォルトで Application Default Credentials(ADC)を使用します。Gemini Enterprise Agent Runtime 上では、ADC が自動的に Agent Identity のクレデンシャルを取得します。コードに認証情報を埋め込む必要はありません。
Agent Identity 付きでデプロイ
import vertexai
from vertexai import types
from vertexai.agent_engines import AdkApp
from agent import agent
PROJECT_ID = "your-project-id"
LOCATION = "us-central1"
STAGING_BUCKET = "your-staging-bucket"
client = vertexai.Client(
project=PROJECT_ID,
location=LOCATION,
http_options=dict(api_version="v1beta1"), # Agent Identity には v1beta1 が必要
)
app = AdkApp(agent=agent)
remote_app = client.agent_engines.create(
agent=app,
config={
"display_name": "gcs-reader-agent",
"identity_type": types.IdentityType.AGENT_IDENTITY,
"requirements": [
"google-cloud-aiplatform[adk,agent_engines]",
"google-cloud-storage",
"cloudpickle",
"pydantic",
],
"extra_packages": ["agent.py"],
"staging_bucket": f"gs://{STAGING_BUCKET}",
},
)
print(f"Agent Engine ID: {remote_app.api_resource.name}")
print(f"Effective Identity: {remote_app.api_resource.spec.effective_identity}")
deploy.pyを実行してエージェントをデプロイしていきます。
uv run deploy.py
デプロイが完了すると、エージェントの principal identifier が出力されます。
Agent Engine ID: projects/PROJECT_NUMBER/locations/us-central1/reasoningEngines/AGENT_ENGINE_ID
Effective Identity: agents.global.org-ORGANIZATION_ID.system.id.goog/resources/aiplatform/projects/PROJECT_NUMBER/locations/us-central1/reasoningEngines/AGENT_ENGINE_ID
コンソールでの確認
Gemini Enterprise Agent Runtime のコンソールでデプロイしたエージェントを確認することができます。
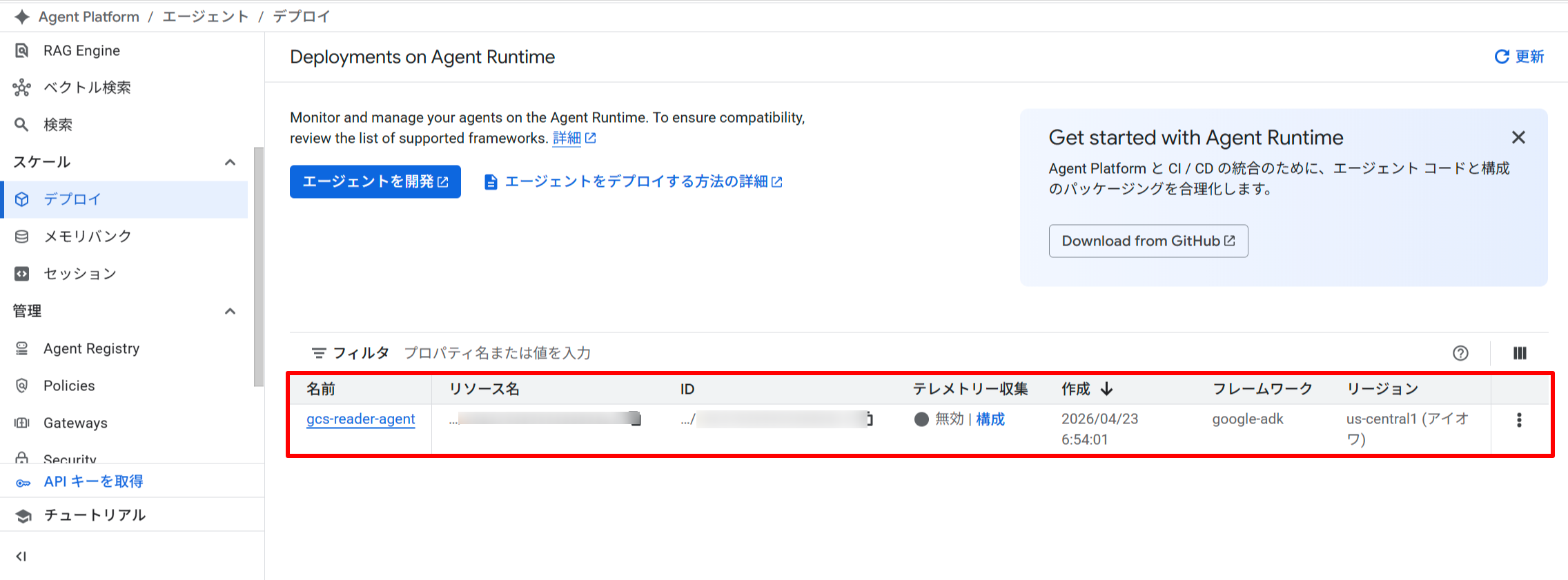
Gemini Enterprise Agent Runtime のコンソールでデプロイしたエージェントを開くと、ID 列に SPIFFE ID が表示されます。
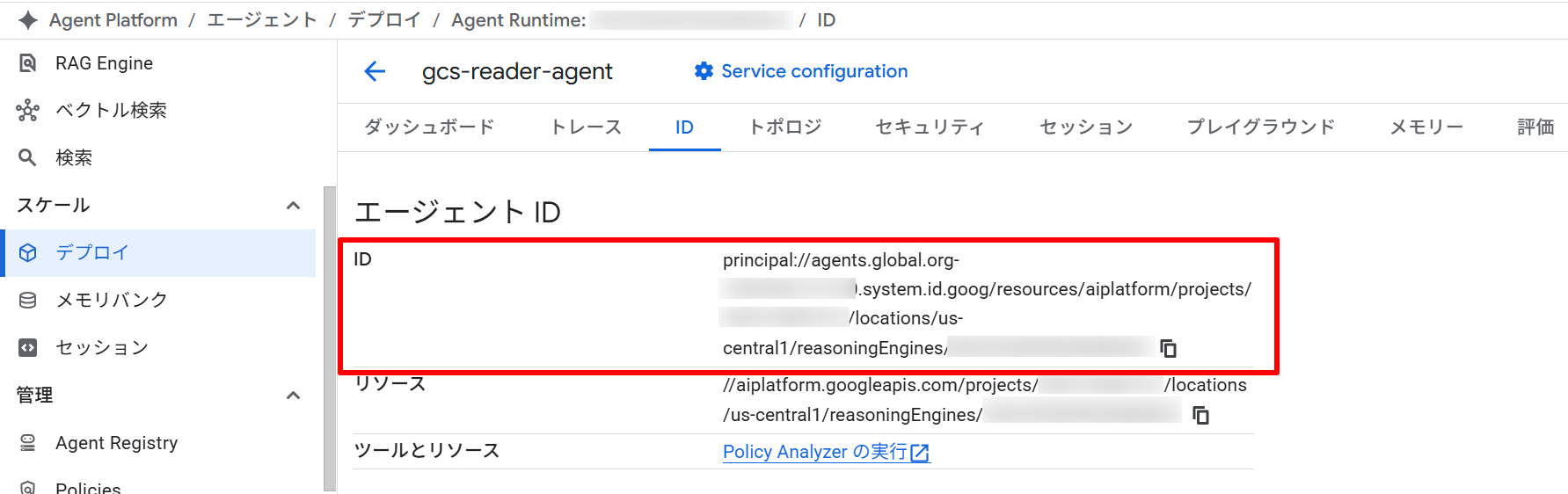
バケットへのアクセス権を Agent Identity に付与する
デプロイで得た Effective Identity の値を使ってバケットへの IAM ポリシーを設定します。
# Effective Identity の値を変数に設定
export AGENT_IDENTITY="agents.global.org-ORGANIZATION_ID.system.id.goog/resources/aiplatform/projects/PROJECT_NUMBER/locations/us-central1/reasoningEngines/AGENT_ENGINE_ID"
# データバケットへの objectViewer 権限を付与
gcloud storage buckets add-iam-policy-binding gs://$DATA_BUCKET \
--member="principal://$AGENT_IDENTITY" \
--role="roles/storage.objectViewer"
IAM が反映されると、エージェントランタイム上の ADC が Agent Identity を使って Cloud Storage への認証を自動で行います。
動作確認
import vertexai
PROJECT_ID = "your-project-id"
LOCATION = "us-central1"
AGENT_ENGINE_ID = "your-agent-engine-id" # deploy.py の出力から取得
DATA_BUCKET = "your-data-bucket"
client = vertexai.Client(
project=PROJECT_ID,
location=LOCATION,
http_options=dict(api_version="v1beta1"),
)
remote_app = client.agent_engines.get(
name=f"projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{AGENT_ENGINE_ID}"
)
session = remote_app.create_session(user_id="test-user")
response = remote_app.stream_query(
user_id="test-user",
session_id=session["id"],
message=f"バケット {DATA_BUCKET} の product_info.txt の内容を読んで、価格を教えてください。",
)
for chunk in response:
for part in chunk.get("content", {}).get("parts", []):
if "text" in part:
print(part["text"], end="", flush=True)
以下のような応答が確認できました。
無事Agent RuntimeからCloud Storageにアクセスすることができました。
この商品の価格は、標準ストレージで月額 $0.020/GB です。
バケットへのアクセス権を付与しなかった場合
試しに IAM を付与せずにアクセスすると、ツールの実行がランタイム内で 403 エラーとなり、以下のようなエラーがイベントストリームに含まれて返ってきます。Agent Identity はデプロイ直後はいかなる Google Cloud リソースへのアクセス権も持たない状態で払い出されます。
google.resumable_media.common.InvalidResponse: ('Request failed with status code', 403,
'Expected one of', <HTTPStatus.OK: 200>, <HTTPStatus.PARTIAL_CONTENT: 206>)
注意点と制限事項
- Legacy Bucket ロールは付与不可:
storage.legacyBucketReader/storage.legacyBucketWriter/storage.legacyBucketOwnerは Agent Identity に付与できません。roles/storage.objectViewerなどの非レガシーロールを使用してください - v1beta1 API が必要: Agent Identity の作成には
api_version="v1beta1"を指定する必要があります - CAA のオプトアウトは非推奨: エージェント間でトークンを共有する特殊なケースでは CAA ポリシーを無効化できますが、セキュリティリスクが高まるため推奨されません
- 後方互換性:
identity_typeを指定しない場合はこれまで通りサービスアカウントが使用されます。既存のデプロイには影響ありません
まとめ
今回は、2026年4月22日に GA となった Gemini Enterprise Agent Runtime の Agent Identity を使って、ADK エージェントが Cloud Storage のデータにアクセスする構成を試しました。
Agent Identity を使うことで、以下のメリットが得られます。
- コードに認証情報を埋め込まずに済む: ADC が Agent Identity を自動で使用するため、
storage.Client()のように普通に書くだけでよい - エージェント単位の最小権限設計: 特定のバケットにのみ
objectViewerを付与するといった細かい制御が、エージェント ID 単位でシンプルに実現できる - エージェントのライフサイクルと連動した ID 管理: エージェントを削除すれば Agent Identity も消滅するため、権限の残留を防ぐことができる
AI エージェントが自律的に Google Cloud リソースへアクセスする構成は今後ますます増えていくと考えられます。Agent Identity を活用することで、最小権限の原則に沿った安全なエージェント運用が可能になりました。ぜひ試してみてください。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!










