
Amazon S3 Tables に入門してみた
こんにちは!アノテーション AWS テクニカルサポートチームの大高です。
Amazon S3 Tables がリリースされていることは知っていましたが、未だに触ったことがなかったため、以下の公式ドキュメントを参考に触ってみたいと思います。
Amazon S3 Tables とは
Amazon S3 Tables は、以下のような特徴をもったオブジェクトストアです。
- Apache Iceberg サポートが組み込まれており、大量の表形式データを効率的に保存・管理できる
- バックグラウンドで自動的にデータを最適化することで、通常の Iceberg テーブルと比べて最大 3 倍速いクエリ性能を実現する
- 通常の S3 バケットと比べて最大 10 倍のトランザクション処理が可能となっている
詳細は以下をご参照ください。
やってみた
では、さっそくドキュメントの内容に沿って S3 Tables を試してみます。
テーブルバケットを作成し、AWS 分析サービスと統合する
S3 の管理コンソールを開いて、「テーブルバケット」メニューから「テーブルバケットを作成」をクリックします。
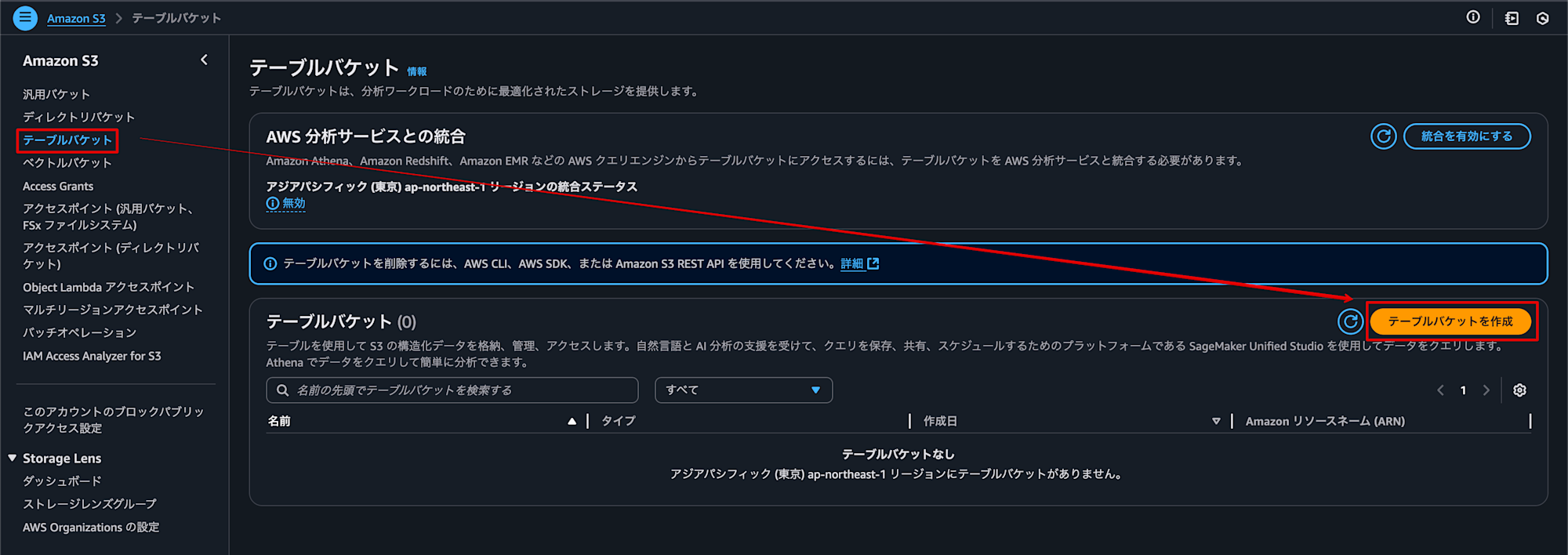
続けて、「テーブルバケット名」を入力し、他の設定はそのままでテーブルバケットを作成します。
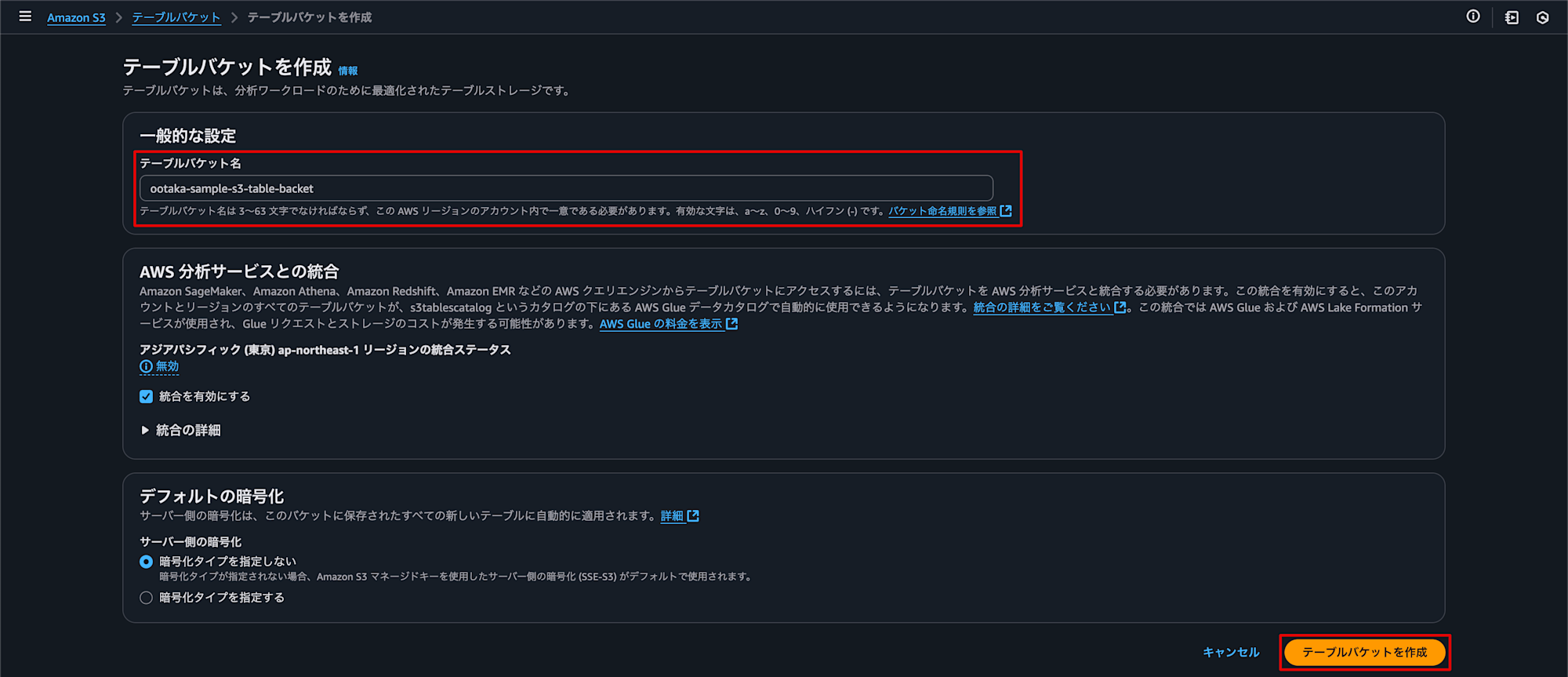
ここは簡単ですね!
テーブル名前空間とテーブルを作成する
S3 バケットが用意できたので、今度はテーブルを作成していきます。
今回は AWS CLI を利用して作成したいと思います。
なお、実行するユーザーには AmazonS3TablesFullAccess 権限を付与してあります。
・ 名前空間を作成
$ aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:ap-northeast-1:XXXXXXXXXXXX:bucket/ootaka-sample-s3-table-backet \
--namespace sample_namespace
{
"tableBucketARN": "arn:aws:s3tables:ap-northeast-1:XXXXXXXXXXXX:bucket/ootaka-sample-s3-table-backet",
"namespace": [
"sample_namespace"
]
}
・名前空間が正常に作成されたことを確認
$ aws s3tables list-namespaces \
--table-bucket-arn arn:aws:s3tables:ap-northeast-1:XXXXXXXXXXXX:bucket/ootaka-sample-s3-table-backet
{
"namespaces": [
{
"namespace": [
"sample_namespace"
],
"createdAt": "2025-10-10T09:19:52.517915+00:00",
"createdBy": "XXXXXXXXXXXX",
"ownerAccountId": "XXXXXXXXXXXX",
"namespaceId": "11e66160-185c-41d6-95dd-1eee1ab677de",
"tableBucketId": "737e5369-d61c-4224-b76f-7319e4f2a9af"
}
]
}
・テーブルスキーマを定義した新しいテーブルを作成
mytabledefinition.json を用意して、
{
"tableBucketARN": "arn:aws:s3tables:ap-northeast-1:XXXXXXXXXXXX:bucket/ootaka-sample-s3-table-backet",
"namespace": "sample_namespace",
"name": "sample_table",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "int","required": true},
{"name": "name", "type": "string"},
{"name": "value", "type": "int"}
]
}
}
}
}
テーブルを作成します。
$ aws s3tables create-table --cli-input-json file://mytabledefinition.json
{
"tableARN": "arn:aws:s3tables:ap-northeast-1:XXXXXXXXXXXX:bucket/ootaka-sample-s3-table-backet/table/ad6ba121-7e38-4b70-8342-4ac6772367a0",
"versionToken": "3b986a21324b4199a16b"
}
ここも AWS CLI で簡単にできました。
Athena で SQL を使用してデータをクエリする
最後にクエリを実行してみます。
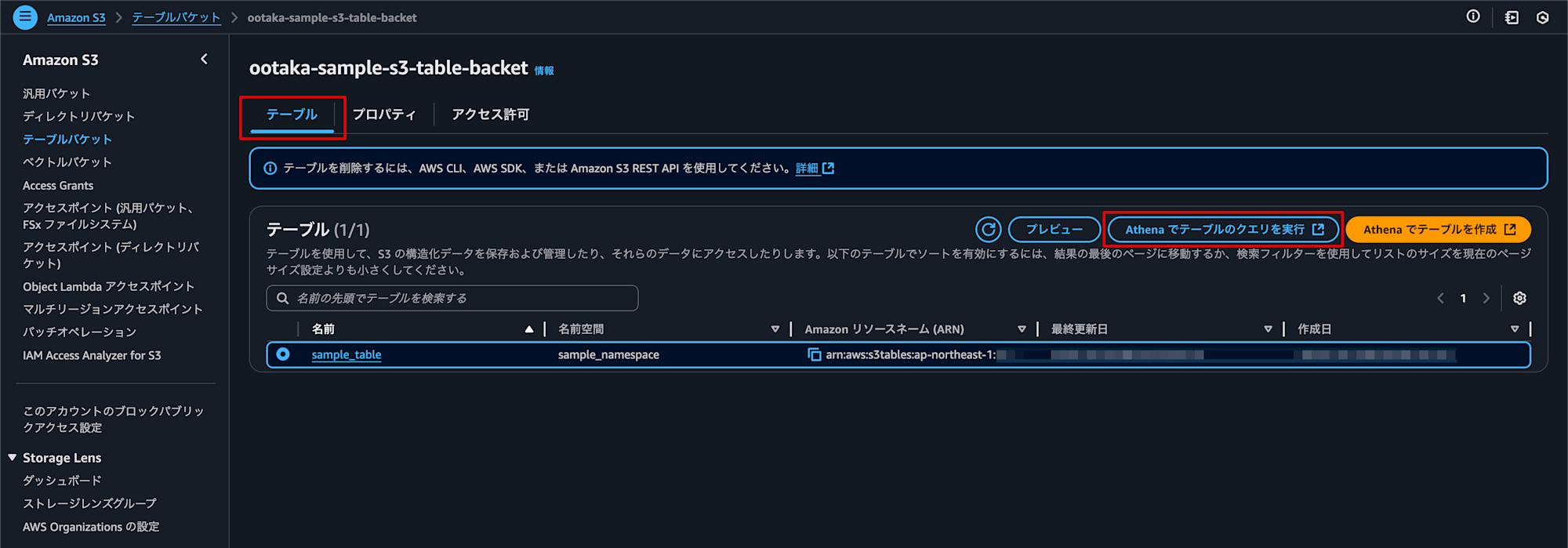
S3 管理コンソールに戻り、「テーブル」タブを開くと先程作成されたテーブルが表示されていました。
テーブルを選択し、「Athena でテーブルのクエリを実行」をクリックします。
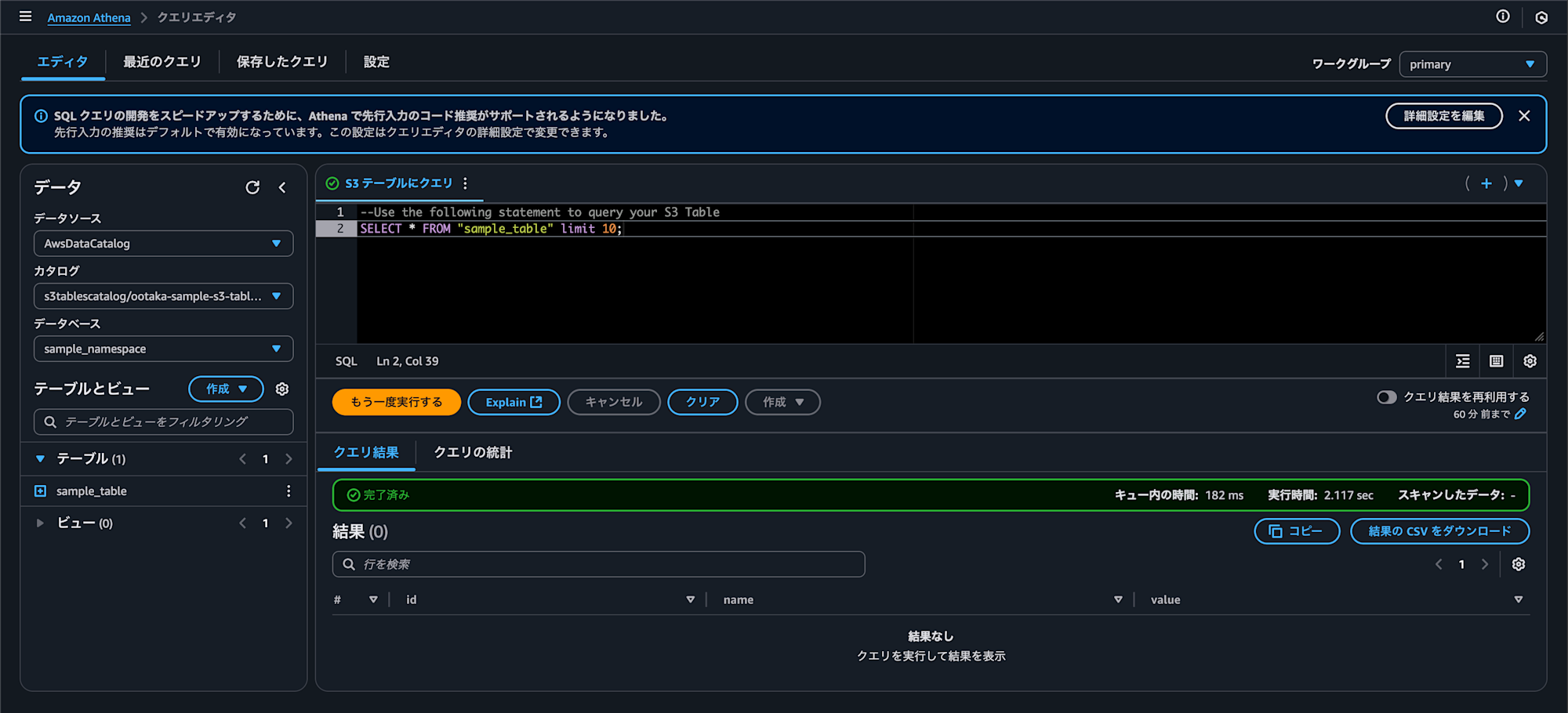
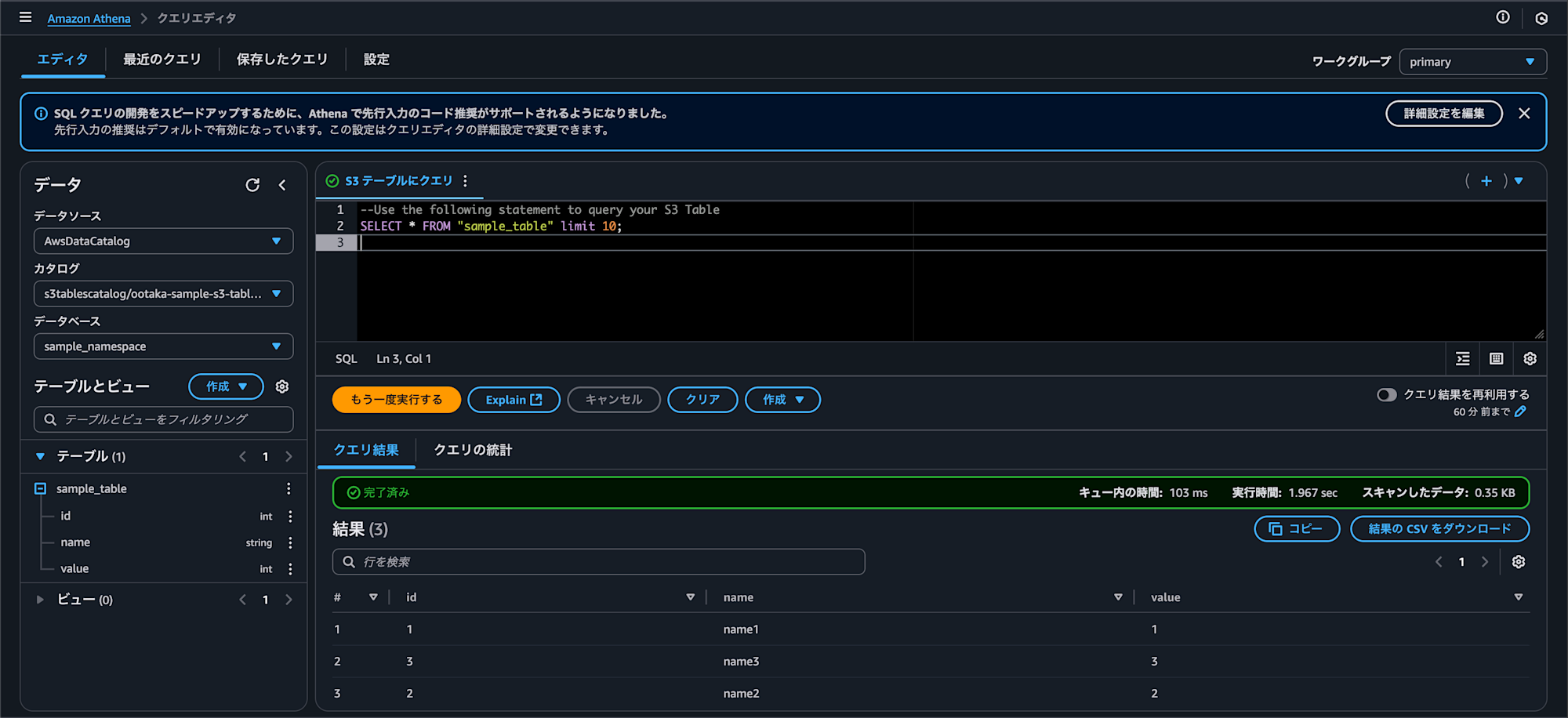
クリックすると Athena のコンソールが開き、以下のようにクエリが自動生成されていましたので、そのまま実行します。
この段階では当たり前ですが 0 件ですね。
SELECT * FROM "sample_table" limit 10;
試しに3件レコードを INSERT してみます。
INSERT INTO "sample_table" (id, name, value) VALUES (1, 'name1', 1);
INSERT INTO "sample_table" (id, name, value) VALUES (2, 'name2', 2);
INSERT INTO "sample_table" (id, name, value) VALUES (3, 'name3', 3);
その後 SELECT すると、ちゃんと想定どおり 3 件レコードが入っていました。
まとめ
以上、Amazon S3 Tables に入門してみました。
なんとなく S3 Tables はとっつきにくいイメージがあったのですが、実際に触った範囲では特に詰まることもなく簡単に作成ができました。
また、Athena でのクエリも特に意識することなく実行できたため、非常に扱いやすいと感じました。
ここから更に発展させていくと、Lake Formation が絡んできて、少し難しくなってくるのではないかと思っていますが、このあたりも機会があれば試してみたいと思います。
どなたかのお役に立てば幸いです。それでは!
参考









