
GitHub ActionからDataplex Universal Catalogのエントリーにアスペクトタイプ・用語集を自動一括登録を実行させてみた
データ事業本部のsutoです。
この記事はクラスメソッドの Google Cloud アドベントカレンダー2025 の5日目の記事です。
Dataplex Universal Catalogを運用する際に面倒な作業となるのが、「エントリーにメタデータ(アスペクトタイプや用語集)を付与」していく作業ですよね。
今回はGitHub ActionをトリガーとしたDataplexのエントリーにアスペクトタイプ・用語集を一括登録する作業を自動化させる仕組みを作ってみました。
実行するツールについて
アスペクトタイプ・用語集を一括登録する処理を行うツールですが、前回のブログで紹介したツールに機能を追加したものになります。
このツールをDockerコンテナ化してCloud Runにデプロイして利用できるように開発しています。
開発しているツールのコードは膨大なのですべてをお見せすることはできませんが、Dataplex APIによるメタデータ付与の処理部分はこんなコードを書いています。
コード抜粋(メタデータ付与機能)
# こちらはツール内のコードの一部をご紹介するものです。
# 実際の動作には追加の実装(認証、エラーハンドリング、設定管理など)が必要です。
from typing import Dict, Any, Optional
import requests
import csv
import logging
logger = logging.getLogger(__name__)
# =============================================================================
# 1. エントリーレベルのアスペクト付与
# =============================================================================
def attach_aspect_to_entry(self,
entry_name: str,
aspect_type_id: str,
aspect_data: Dict[str, Any]) -> Dict[str, Any]:
"""
エントリーにアスペクトを付与
Args:
entry_name: エントリーの完全パス
aspect_type_id: アスペクトタイプID
aspect_data: アスペクトデータ(フィールド名と値のマッピング)
"""
# アスペクトタイプの完全パスを構築
aspect_type_path = f"projects/{self.project_id}/locations/{self.location}/aspectTypes/{aspect_type_id}"
# プロジェクト番号を取得
project_number = self._get_project_number()
# アスペクトキーの形式: {project_number}.{location}.{aspect_type_id}
aspect_key = f"{project_number}.{self.location}.{aspect_type_id}"
# エントリーを更新(PATCHリクエスト)
update_entry = {
"aspects": {
aspect_key: {
"aspectType": aspect_type_path,
"data": aspect_data
}
}
}
# updateMask=aspects と aspect_keys パラメータを使用
update_url = f"{self.base_url}/{entry_name}?updateMask=aspects&aspectKeys={aspect_key}"
response = requests.patch(update_url, headers=headers, json=update_entry)
if response.status_code in [200, 201]:
logger.info(f"Successfully attached aspect '{aspect_type_id}' to entry")
return response.json()
# ポイント:
# - アスペクトキーは `{project_number}.{location}.{aspect_type_id}` 形式
# - REST APIの `PATCH /v1/{entry_name}` エンドポイントを使用
# - `updateMask=aspects` と `aspectKeys` パラメータで特定のアスペクトのみ更新
# =============================================================================
# 2. フィールドレベルのアスペクト付与
# =============================================================================
def attach_aspect_to_field(self,
entry_name: str,
field_name: str,
aspect_type_id: str,
aspect_data: Dict[str, Any]) -> Dict[str, Any]:
"""
エントリーのフィールドにアスペクトを付与
Args:
entry_name: エントリーの完全パス
field_name: フィールド名(カラム名)
aspect_type_id: アスペクトタイプID
aspect_data: アスペクトデータ
"""
# プロジェクト番号を取得
project_number = self._get_project_number()
# フィールドレベルアスペクトのキーは "@Schema.{field_name}" サフィックス付き
# 注意: "Schema" は大文字のS
aspect_key = f"{project_number}.{self.location}.{aspect_type_id}@Schema.{field_name}"
# 新しいアスペクトのみを含む更新
update_entry = {
"aspects": {
aspect_key: {
"aspectType": aspect_type_path,
"path": f"Schema.{field_name}", # Schema.field_name 形式
"data": aspect_data
}
}
}
# エントリーを更新
update_url = f"{self.base_url}/{entry_name}?updateMask=aspects&aspectKeys={aspect_key}"
response = requests.patch(update_url, headers=headers, json=update_entry)
if response.status_code in [200, 201]:
logger.info(f"Successfully attached aspect to field '{field_name}'")
return response.json()
# ポイント:
# - フィールドレベルのアスペクトキーには `@Schema.{field_name}` サフィックスを追加
# - `path` フィールドに `Schema.{field_name}` を指定(大文字のS)
# - エントリーレベルと同じPATCH APIを使用
# =============================================================================
# 3. Glossary Term付与(エントリーレベル&フィールドレベル対応)
# =============================================================================
def attach_glossary_term(self,
entry_name: str,
glossary_id: str,
term_id: str,
term_location: str = "global",
field_name: Optional[str] = None) -> Dict[str, Any]:
"""
エントリーまたはフィールドにglossary termを付与
Args:
entry_name: エントリーの完全パス
glossary_id: Glossary ID
term_id: Term ID
term_location: Termのロケーション(デフォルト: global)
field_name: フィールド名(カラムレベルの場合)、Noneの場合はエントリーレベル
"""
# プロジェクト番号を取得
project_number = self._get_project_number()
# entryLink IDを生成(glossary_id-term_id-field_nameの形式)
entry_link_id = f"{glossary_id}-{term_id}"
if field_name:
entry_link_id = f"{entry_link_id}-{field_name}"
entry_link_id = entry_link_id.lower() # 小文字に変換
# entryLinksエンドポイント
entry_links_url = f"{self.base_url}/projects/{project_number}/locations/{entry_location}/entryGroups/{entry_group}/entryLinks?entryLinkId={entry_link_id}"
# SOURCE: データエントリー
source_entry = {
"name": entry_name,
"type": "SOURCE"
}
# フィールドレベルの場合、pathフィールドを追加
if field_name:
source_entry["path"] = f"Schema.{field_name}"
# TARGET: glossary term
term_entry_name = f"projects/{project_number}/locations/{term_location}/entryGroups/@dataplex/entries/projects/{project_number}/locations/{term_location}/glossaries/{glossary_id}/terms/{term_id}"
target_entry = {
"name": term_entry_name,
"type": "TARGET"
}
# リクエストボディ
request_body = {
"entry_link_type": "projects/dataplex-types/locations/global/entryLinkTypes/definition",
"entry_references": [source_entry, target_entry]
}
response = requests.post(entry_links_url, headers=headers, json=request_body)
if response.status_code in [200, 201]:
logger.info(f"Successfully attached glossary term '{term_id}' to entry")
return response.json()
# ポイント:
# - `POST .../entryLinks` エンドポイントを使用してentryLinkを作成
# - `field_name` が指定されている場合はフィールドレベル、Noneの場合はエントリーレベル
# - entryLinkIdは小文字、数字、ハイフンのみ使用可能
# - フィールドレベルの場合、SOURCEの`path`に`Schema.{field_name}`を指定
# =============================================================================
# 4. Entry Path自動検索機能(概要)
# =============================================================================
def _attach_from_unified_file(self, unified_file: str, entries_file: str = None) -> AttachmentResult:
"""統合フォーマットファイルからメタデータを付与"""
result = AttachmentResult()
# エントリーパスのキャッシュ(同じentry_nameの重複検索を避ける)
entry_path_cache = {}
# 統合ファイルを読み込んでパース
entries_data = self._parse_unified_format(unified_file)
# エントリーごとに処理
for entry_name, aspects in entries_data.items():
# キャッシュから取得、なければDataplexで検索
if entry_name not in entry_path_cache:
logger.info(f"Searching entry path for: {entry_name}")
entry_path = self.dataplex_client.search_entry_by_name(entry_name)
if entry_path:
entry_path_cache[entry_name] = entry_path
# メタデータ付与処理
# ... 詳細は省略 ...
return result
# ポイント:
# - `entry_name`(例: `transaction_data`)から完全なEntry Pathを自動検索
# - キャッシュ機構により同じエントリーの重複検索を回避
# - 内部で`gcloud dataplex entries search`コマンドを使用
# - 検索結果例:
# projects/PROJECT_NUMBER/locations/LOCATION/entryGroups/@bigquery/entries/...
# =============================================================================
# 5. 統合CSVフォーマットのパース(概念)
# =============================================================================
def _parse_unified_format(self, file_path: str) -> Dict[str, Dict[str, Dict[str, Any]]]:
"""
統合フォーマットをパースする
Returns:
{
entry_name: {
aspect_name: {
'level': 'entry' or 'field',
'fields': {field_name: field_value, ...},
'entry_field_name': 'column_name',
'glossary_id': 'glossary-id',
'term_id': 'term-id'
}
}
}
"""
entries_data = {}
with open(file_path, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
# CSVから必要な情報を抽出
entry_name = row.get('entry_name', '').strip()
entry_field_name = row.get('entry_field_name', '').strip()
aspect_name = row.get('aspect_name', '').strip()
# エントリーレベル or フィールドレベルを判定
level = 'field' if entry_field_name else 'entry'
# フィールド値を動的に抽出(field_name_01, field_value_01, ...)
# ... 実装の詳細は省略 ...
return entries_data
# ポイント:
# - 1つのCSVファイルでアスペクトとGlossary Termを同時管理
# - `entry_field_name`が空の場合はエントリーレベル、値がある場合はフィールドレベル
# - `field_name_XX` / `field_value_XX` の動的なペアを解析
# - 実装の詳細はツール固有のロジックとして非公開
# =============================================================================
# REST APIエンドポイント一覧
# =============================================================================
# -------------------------
# アスペクト付与
# -------------------------
# エントリーレベル:
# PATCH https://dataplex.googleapis.com/v1/{entry_name}?updateMask=aspects&aspectKeys={aspect_key}
#
# Body:
# {
# "aspects": {
# "{project_number}.{location}.{aspect_type_id}": {
# "aspectType": "projects/{project_id}/locations/{location}/aspectTypes/{aspect_type_id}",
# "data": { /* アスペクトデータ */ }
# }
# }
# }
# フィールドレベル:
# PATCH https://dataplex.googleapis.com/v1/{entry_name}?updateMask=aspects&aspectKeys={aspect_key}
#
# Body:
# {
# "aspects": {
# "{project_number}.{location}.{aspect_type_id}@Schema.{field_name}": {
# "aspectType": "projects/{project_id}/locations/{location}/aspectTypes/{aspect_type_id}",
# "path": "Schema.{field_name}",
# "data": { /* アスペクトデータ */ }
# }
# }
# }
# -------------------------
# Glossary Term付与
# -------------------------
# エントリーレベル:
# POST https://dataplex.googleapis.com/v1/projects/{project_number}/locations/{location}/entryGroups/{entry_group}/entryLinks?entryLinkId={glossary_id}-{term_id}
#
# Body:
# {
# "entry_link_type": "projects/dataplex-types/locations/global/entryLinkTypes/definition",
# "entry_references": [
# {
# "name": "{entry_name}",
# "type": "SOURCE"
# },
# {
# "name": "projects/{project_number}/locations/{term_location}/entryGroups/@dataplex/entries/projects/{project_number}/locations/{term_location}/glossaries/{glossary_id}/terms/{term_id}",
# "type": "TARGET"
# }
# ]
# }
# フィールドレベル:
# POST https://dataplex.googleapis.com/v1/projects/{project_number}/locations/{location}/entryGroups/{entry_group}/entryLinks?entryLinkId={glossary_id}-{term_id}-{field_name}
#
# Body:
# {
# "entry_link_type": "projects/dataplex-types/locations/global/entryLinkTypes/definition",
# "entry_references": [
# {
# "name": "{entry_name}",
# "type": "SOURCE",
# "path": "Schema.{field_name}" // フィールドレベルの場合のみ
# },
# {
# "name": "projects/{project_number}/locations/{term_location}/entryGroups/@dataplex/entries/projects/{project_number}/locations/{term_location}/glossaries/{glossary_id}/terms/{term_id}",
# "type": "TARGET"
# }
# ]
# }
# =============================================================================
# 実装の重要ポイント
# =============================================================================
# 1. プロジェクト番号の取得
# - アスペクトキーには`project_id`ではなく`project_number`を使用
# - Cloud Resource Manager APIで取得: `GET https://cloudresourcemanager.googleapis.com/v1/projects/{project_id}`
# 2. アスペクトキーの形式
# - エントリーレベル: `{project_number}.{location}.{aspect_type_id}`
# - フィールドレベル: `{project_number}.{location}.{aspect_type_id}@Schema.{field_name}`
# 3. pathフィールドの形式
# - フィールドレベルのアスペクトとterm付与では`Schema.{field_name}`形式
# - "Schema"は大文字のS、ドット区切り
# 4. entryLinkIdの制約
# - 小文字、数字、ハイフンのみ使用可能
# - フィールドレベル: `{glossary_id}-{term_id}-{field_name}`
# 5. エラーハンドリング
# - Term付与失敗時もアスペクト付与は継続
# - 失敗はwarningとして扱い、全体の成功ステータスに影響させない
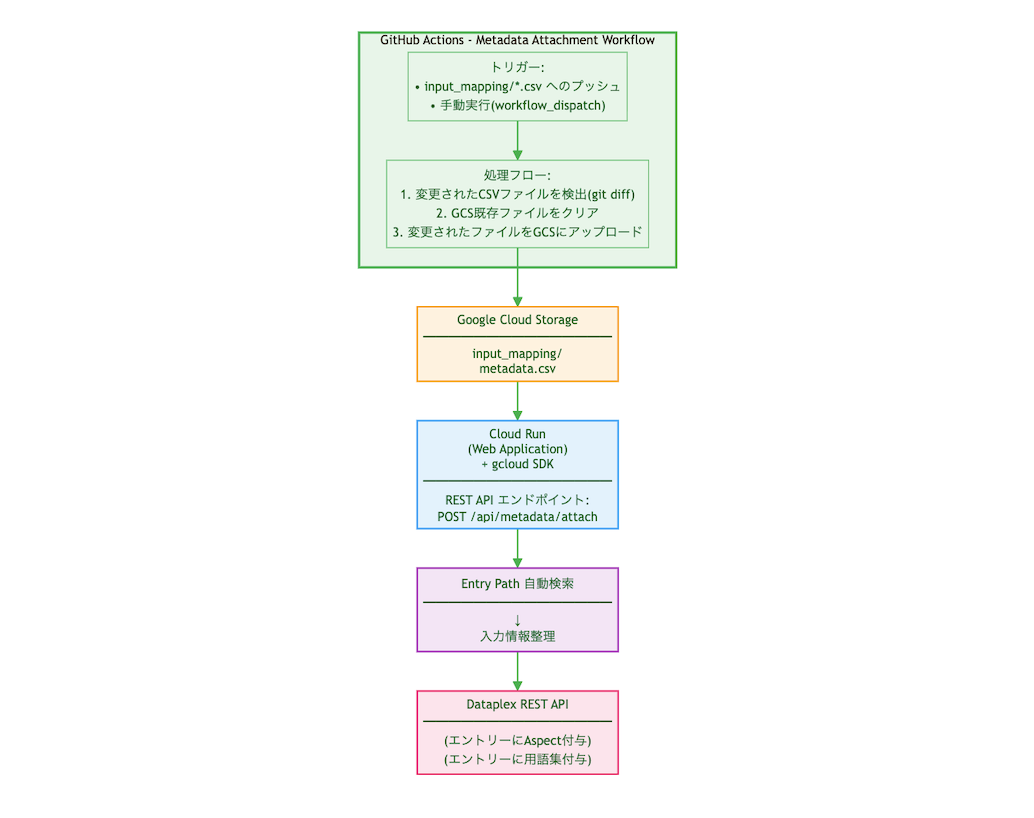
処理フローについて
仕組みとしては以下のようなフローとなります。
- githubの特定のフォルダ配下にエントリー名ごとに登録するメタデータを整理したcsvファイルをプッシュ
- プッシュしたファイルをGCSにコピー
- Cloud Runにデプロイしてあるツールの実行により、GCSからファイルを読み込み
- Dataplex APIによってメタデータ付与の処理
入力csvファイルは以下のように整理します。
- エントリーに登録するアスペクトタイプのフィールド数の分、列数を準備します。
- アスペクトタイプごとにフィールド数が異なっていても、空白にしておけば問題ありません。
- フィールドによっては値を設定しないものについても空白にしておけばOKです。
- カラム名を空白にしておけば、”テーブルレベル”にメタデータを付与する仕組みにしています。
- カラム名を入力すれば、”カラムレベル”にメタデータ付与となります。
- アスペクト名や用語集名は識別子IDのほうで記載する必要があります。

メタデータ付与処理の自動化をやってみた
処理フローで紹介した仕組みを構築する手順をご紹介します。
開発中のツールの動作テストも兼ねた内容に少し修正を加えた手順になりますが、参考になれば幸いです。
基本的にcliコマンドでリソースを作っていきます。
必要な作業環境やツール
- Google Cloud SDK (gcloud) がインストールされていること
- Docker がインストールされていること(ローカルビルドする場合)
- GitHubアカウントとリポジトリ
- 必要なGoogle CloudサービスのAPI有効化
必要なGoogle Cloud権限
以下の権限を持つGoogle Cloudユーザーが必要です。
- Project Owner または以下の個別権限:
- Cloud Run Admin
- Service Account Admin
- Artifact Registry Admin
- Storage Admin
- Dataplex Admin
- Service Usage Admin
1-1. Artifact Registryリポジトリの作成
# Dockerイメージを保存するリポジトリを作成
export REPOSITORY_NAME="dataplex-tools"
gcloud artifacts repositories create ${REPOSITORY_NAME} \
--repository-format=docker \
--location=${REGION} \
--description="Dataplex Metadata Tool container images" \
--project=${PROJECT_ID}
# Docker認証の設定
gcloud auth configure-docker ${REGION}-docker.pkg.dev --quiet
1-2. Cloud Storage バケットの作成
# GCSバケット名を設定(グローバルでユニークな名前にしてください)
export GCS_BUCKET="ツール用のバケット名(任意)"
# バケットの作成
gcloud storage buckets create gs://${GCS_BUCKET} \
--location=${REGION} \
--uniform-bucket-level-access \
--project=${PROJECT_ID}
# 必要なディレクトリ構造を作成
gsutil mkdir gs://${GCS_BUCKET}/input/
gsutil mkdir gs://${GCS_BUCKET}/input/metadata/
1-3. Cloud Run用のサービスアカウント作成
# サービスアカウント名を設定
export SERVICE_ACCOUNT_NAME="dataplex-metadata-tool-sa"
export SERVICE_ACCOUNT_EMAIL="${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
# サービスアカウントの作成
gcloud iam service-accounts create ${SERVICE_ACCOUNT_NAME} \
--display-name="Dataplex Metadata Tool Service Account" \
--project=${PROJECT_ID}
# 必要な権限を付与
# 1. Dataplex操作権限(アスペクトタイプ、用語集、エントリーへのメタデータ付与)
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/dataplex.editor"
# 2. GCS操作権限(入出力ファイルの読み書き)
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/storage.objectAdmin"
# 3. Cloud Resource Manager権限(プロジェクト番号取得のため)
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/browser"
2-1. ツールのデプロイの実行
プロジェクトルートで環境変数を設定します:
# deploy.shで使用する環境変数を設定
export GOOGLE_CLOUD_PROJECT="${PROJECT_ID}"
export CLOUD_RUN_REGION="${REGION}"
export CLOUD_RUN_SERVICE_NAME="dataplex-metadata-tool"
export ARTIFACT_REGISTRY_REPO="${REPOSITORY_NAME}"
以下のデプロイ用スクリプト”deploy.sh”を作成して実行しました。
deploy.sh
#!/bin/bash
# Deploy Dataplex Metadata Tool to Google Cloud Run
set -e
# カラー出力
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
# 設定変数(環境変数で上書き可能)
PROJECT_ID="${GOOGLE_CLOUD_PROJECT}"
REGION="${CLOUD_RUN_REGION}"
SERVICE_NAME="${CLOUD_RUN_SERVICE_NAME}"
REPOSITORY_NAME="${ARTIFACT_REGISTRY_REPO}"
IMAGE_NAME="${SERVICE_NAME}"
IMAGE_TAG="${IMAGE_TAG:-latest}"
# Artifact Registryのフルパス
ARTIFACT_REGISTRY_PATH="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPOSITORY_NAME}/${IMAGE_NAME}:${IMAGE_TAG}"
echo -e "${GREEN}=== Dataplex Metadata Tool - Cloud Run Deployment ===${NC}"
echo "Project ID: ${PROJECT_ID}"
echo "Region: ${REGION}"
echo "Service Name: ${SERVICE_NAME}"
echo "Image: ${ARTIFACT_REGISTRY_PATH}"
echo ""
# 1. 現在のプロジェクトIDを確認
echo -e "${YELLOW}[1/7] Checking current GCP project...${NC}"
CURRENT_PROJECT=$(gcloud config get-value project 2>/dev/null || echo "")
if [ "${CURRENT_PROJECT}" != "${PROJECT_ID}" ]; then
echo "Setting project to ${PROJECT_ID}..."
gcloud config set project ${PROJECT_ID}
fi
# 2. 必要なAPIを有効化
echo -e "${YELLOW}[2/7] Enabling required APIs...${NC}"
gcloud services enable \
cloudbuild.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
--project=${PROJECT_ID}
# 3. Artifact Registryリポジトリの作成(存在しない場合)
echo -e "${YELLOW}[3/7] Creating Artifact Registry repository...${NC}"
if ! gcloud artifacts repositories describe ${REPOSITORY_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} &>/dev/null; then
echo "Creating repository ${REPOSITORY_NAME}..."
gcloud artifacts repositories create ${REPOSITORY_NAME} \
--repository-format=docker \
--location=${REGION} \
--description="Dataplex Metadata Tool container images" \
--project=${PROJECT_ID}
else
echo "Repository ${REPOSITORY_NAME} already exists."
fi
# 4. Docker認証の設定
echo -e "${YELLOW}[4/7] Configuring Docker authentication...${NC}"
gcloud auth configure-docker ${REGION}-docker.pkg.dev --quiet
# 5. Dockerイメージのビルド
echo -e "${YELLOW}[5/7] Building Docker image...${NC}"
docker build \
--platform linux/amd64 \
-f Dockerfile.cloudrun \
-t ${ARTIFACT_REGISTRY_PATH} \
--build-arg BUILD_DATE=$(date -u +'%Y-%m-%dT%H:%M:%SZ') \
--build-arg VCS_REF=$(git rev-parse --short HEAD 2>/dev/null || echo "unknown") \
.
# 6. Artifact RegistryへPush
echo -e "${YELLOW}[6/7] Pushing image to Artifact Registry...${NC}"
docker push ${ARTIFACT_REGISTRY_PATH}
# 7. Cloud Runへデプロイ
echo -e "${YELLOW}[7/7] Deploying to Cloud Run...${NC}"
gcloud run deploy ${SERVICE_NAME} \
--image=${ARTIFACT_REGISTRY_PATH} \
--platform=managed \
--region=${REGION} \
--project=${PROJECT_ID} \
--allow-unauthenticated \
--memory=2Gi \
--cpu=2 \
--timeout=600 \
--max-instances=10 \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}"
# デプロイ完了
echo -e "${GREEN}=== Deployment Completed Successfully! ===${NC}"
# サービスURLの取得
SERVICE_URL=$(gcloud run services describe ${SERVICE_NAME} \
--platform=managed \
--region=${REGION} \
--project=${PROJECT_ID} \
--format='value(status.url)')
echo ""
echo -e "${GREEN}Service URL: ${SERVICE_URL}${NC}"
echo ""
echo "Test the service:"
echo " curl ${SERVICE_URL}/health"
echo ""
echo "Example API calls:"
echo " # Aspect Type Generation"
echo " curl -X POST ${SERVICE_URL}/aspect/generate \\"
echo " -H 'Content-Type: application/json' \\"
echo " -d '{\"project_id\": \"${PROJECT_ID}\", \"input_dir\": \"./input_aspect\"}'"
echo ""
echo " # Glossary Generation"
echo " curl -X POST ${SERVICE_URL}/glossary/generate \\"
echo " -H 'Content-Type: application/json' \\"
echo " -d '{\"project_id\": \"${PROJECT_ID}\", \"input_dir\": \"./input_glossary\"}'"
デプロイが成功すると、Cloud RunのサービスURLが表示されます:
Service URL: https://dataplex-metadata-tool-xxxxxxxxxx-an.a.run.app
このURLを控えておいてください。GitHub Actionsの設定で使用します。
3-1. Workload Identity Federationの設定
GitHub ActionsがGCPリソースに安全にアクセスできるようにWorkload Identity Federationを設定します。
3-1-1. Workload Identity Pool の作成
export POOL_NAME="github-actions-pool"
export POOL_DISPLAY_NAME="GitHub Actions Pool"
gcloud iam workload-identity-pools create ${POOL_NAME} \
--location="global" \
--display-name="${POOL_DISPLAY_NAME}" \
--project=${PROJECT_ID}
3-1-2. Workload Identity Provider の作成
export PROVIDER_NAME="github-actions-provider"
export GITHUB_ORG="your-github-org" # GitHubの組織名またはユーザー名
export GITHUB_REPO="your-repo-name" # リポジトリ名
gcloud iam workload-identity-pools providers create-oidc ${PROVIDER_NAME} \
--location="global" \
--workload-identity-pool=${POOL_NAME} \
--issuer-uri="https://token.actions.githubusercontent.com" \
--attribute-mapping="google.subject=assertion.sub,attribute.actor=assertion.actor,attribute.repository=assertion.repository,attribute.repository_owner=assertion.repository_owner" \
--attribute-condition="assertion.repository_owner == '${GITHUB_ORG}'" \
--project=${PROJECT_ID}
3-1-3. サービスアカウントへの権限付与
# GitHub Actions用のサービスアカウントを作成(Cloud Run用とは別)
export GITHUB_SA_NAME="github-actions-sa"
export GITHUB_SA_EMAIL="${GITHUB_SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${GITHUB_SA_NAME} \
--display-name="GitHub Actions Service Account" \
--project=${PROJECT_ID}
# 必要な権限を付与
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${GITHUB_SA_EMAIL}" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${GITHUB_SA_EMAIL}" \
--role="roles/run.invoker"
# Workload Identity Pool とサービスアカウントの紐付け
gcloud iam service-accounts add-iam-policy-binding ${GITHUB_SA_EMAIL} \
--role="roles/iam.workloadIdentityUser" \
--member="principalSet://iam.googleapis.com/projects/$(gcloud projects describe ${PROJECT_ID} --format='value(projectNumber)')/locations/global/workloadIdentityPools/${POOL_NAME}/attribute.repository/${GITHUB_ORG}/${GITHUB_REPO}" \
--project=${PROJECT_ID}
3-1-4. Workload Identity Provider の識別子を取得
# プロジェクト番号を取得
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format='value(projectNumber)')
# Workload Identity Provider の完全な識別子
export WORKLOAD_IDENTITY_PROVIDER="projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${POOL_NAME}/providers/${PROVIDER_NAME}"
echo "Workload Identity Provider:"
echo ${WORKLOAD_IDENTITY_PROVIDER}
この値をGitHub Secretsに設定します。
3-2. GitHub Secretsの設定
GitHubリポジトリの Settings > Secrets and variables > Actions で以下のSecretsを追加します:
| Secret名 | 値 | 説明 |
|---|---|---|
GCP_WORKLOAD_IDENTITY_PROVIDER |
projects/[PROJECT_NUMBER]/locations/global/workloadIdentityPools/[POOL_NAME]/providers/[PROVIDER_NAME] |
Workload Identity Providerの識別子 |
GCP_SERVICE_ACCOUNT |
github-actions-sa@[PROJECT_ID].iam.gserviceaccount.com |
GitHub Actions用サービスアカウント |
設定方法:
- GitHubリポジトリにアクセス
- Settings > Secrets and variables > Actions
- "New repository secret" をクリック
- 上記の各Secretを追加
3-3. GitHub Actionsワークフローファイルの作成
今回作成したワークフロー「metadata-attachment.yml」は以下となります。
- リポジトリの特定のフォルダ(今回は"input_mapping")に入力csvファイルをプッシュ
- csvファイルがGCSのinput/metadata/配下にコピー(直前にフォルダ内の初期化など実施している)
- コピー後、Cloud Run API呼び出し
name: Metadata Attachment
on:
push:
paths:
- 'input_mapping/*.csv'
workflow_dispatch:
env:
PROJECT_ID: your-google-cloud-project-name. # Google Cloud プロジェクト名
GCS_BUCKET: your-bucket-dataplex-metadata-tool # 1−2で作成したGCSバケット名
CLOUD_RUN_URL: https://dataplex-metadata-tool-xxxxxxxxxx-an.a.run.app # 2-1で作成したCloud RunサービスURL
GCP_REGION: asia-northeast1
jobs:
attach-metadata:
runs-on: ubuntu-latest
permissions:
contents: read
id-token: write
steps:
- name: Checkout code
uses: actions/checkout@v4
with:
fetch-depth: 2 # 直前のコミットとの差分を取得するため
- name: Authenticate to Google Cloud
id: auth
uses: google-github-actions/auth@v2
with:
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
token_format: 'id_token'
id_token_audience: ${{ env.CLOUD_RUN_URL }}
id_token_include_email: true
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
- name: Upload metadata mapping file to GCS
run: |
INPUT_DIR="input_mapping"
GCS_INPUT_PATH="gs://${GCS_BUCKET}/input/metadata/"
echo "📂 Current directory: $(pwd)"
echo "📁 Detecting changed CSV files in ${INPUT_DIR}"
# 変更されたCSVファイルを検出
CHANGED_FILES=$(git diff --name-only HEAD~1 HEAD | grep "^${INPUT_DIR}/.*\.csv$" || true)
if [ -z "${CHANGED_FILES}" ]; then
echo "⚠️ No CSV files changed in ${INPUT_DIR}"
exit 1
fi
echo "✅ Found changed CSV file(s):"
echo "${CHANGED_FILES}"
# GCS上の既存ファイルをクリア
echo "🗑️ Clearing existing metadata files in GCS..."
gsutil -m rm -f ${GCS_INPUT_PATH}* 2>/dev/null || echo "No existing files to remove"
# 変更されたファイルをGCSにアップロード
echo "📤 Uploading changed files to ${GCS_INPUT_PATH}"
for file in ${CHANGED_FILES}; do
if [ -f "${file}" ]; then
echo " - Uploading: ${file}"
gsutil cp "${file}" "${GCS_INPUT_PATH}"
else
echo " - File not found (may be deleted): ${file}"
fi
done
echo "✅ Upload complete"
gsutil ls ${GCS_INPUT_PATH}
- name: Get uploaded file path
id: metadata_file
run: |
GCS_INPUT_PATH="gs://${GCS_BUCKET}/input/metadata/"
echo "🔍 Finding uploaded metadata file..."
LATEST_FILE=$(gsutil ls -l ${GCS_INPUT_PATH}*.csv 2>/dev/null | grep -v TOTAL | sort -k2 -r | head -n1 | awk '{print $3}')
echo "metadata_file=${LATEST_FILE}" >> $GITHUB_OUTPUT
if [[ -n "${LATEST_FILE}" ]]; then
echo "✅ Metadata file: ${LATEST_FILE}"
else
echo "❌ No metadata file found in GCS"
exit 1
fi
- name: Attach metadata to Dataplex entries
id: metadata_attach
run: |
INPUT_FILE="${{ steps.metadata_file.outputs.metadata_file }}"
echo "🚀 Attaching metadata to Dataplex entries"
echo "📄 Input file: ${INPUT_FILE}"
# 認証トークン取得
TOKEN="${{ steps.auth.outputs.id_token }}"
if [[ -z "${TOKEN}" ]]; then
TOKEN=$(gcloud auth print-identity-token --audiences="${CLOUD_RUN_URL}" 2>&1 || echo "")
fi
# API呼び出し
RESPONSE=$(curl -X POST "${CLOUD_RUN_URL}/metadata/attach" \
-H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d "{
\"project_id\": \"${PROJECT_ID}\",
\"location\": \"${GCP_REGION}\",
\"metadata_file\": \"${INPUT_FILE}\",
\"dry_run\": false
}" \
-w "\n%{http_code}" \
-s)
HTTP_CODE=$(echo "$RESPONSE" | tail -n1)
BODY=$(echo "$RESPONSE" | sed '$d')
echo "📊 HTTP Status: ${HTTP_CODE}"
echo "${BODY}" | jq '.' || echo "${BODY}"
echo "${BODY}" > metadata_response.json
if [[ "${HTTP_CODE}" -eq 200 ]]; then
SUCCESS=$(echo "${BODY}" | jq -r '.success')
if [[ "${SUCCESS}" == "true" ]]; then
echo "✅ Metadata attachment completed"
echo "success=true" >> $GITHUB_OUTPUT
else
echo "❌ Metadata attachment failed"
echo "success=false" >> $GITHUB_OUTPUT
fi
else
echo "❌ API call failed"
echo "success=false" >> $GITHUB_OUTPUT
fi
- name: Upload API response as artifact
if: always()
uses: actions/upload-artifact@v4
with:
name: metadata-attachment-response
path: metadata_response.json
retention-days: 30
- name: Summary
if: always()
run: |
echo "## 🎉 Metadata Attachment Summary" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "- **Project:** ${PROJECT_ID}" >> $GITHUB_STEP_SUMMARY
echo "- **Input File:** ${{ steps.metadata_file.outputs.metadata_file }}" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
if [[ "${{ steps.metadata_attach.outputs.success }}" == "true" ]]; then
echo "- **Status:** ✅ Successfully attached metadata" >> $GITHUB_STEP_SUMMARY
else
echo "- **Status:** ❌ Attachment failed" >> $GITHUB_STEP_SUMMARY
fi
echo "" >> $GITHUB_STEP_SUMMARY
以下のワークフローファイルがリポジトリに存在することを確認します。
.github/workflows/metadata-attachment.yml
各ワークフローファイルの env セクションを環境に合わせて更新します:
env:
PROJECT_ID: your-project-id # 実際のプロジェクトID
GCS_BUCKET: your-bucket-name # 作成したGCSバケット名
CLOUD_RUN_URL: https://your-service-url # Cloud RunのサービスURL
GCP_REGION: asia-northeast1 # リージョン
4-1. 動作確認
実際に動作確認をした際の様子を以下に記載します。
Gitリポジトリに入力ファイルアップロード
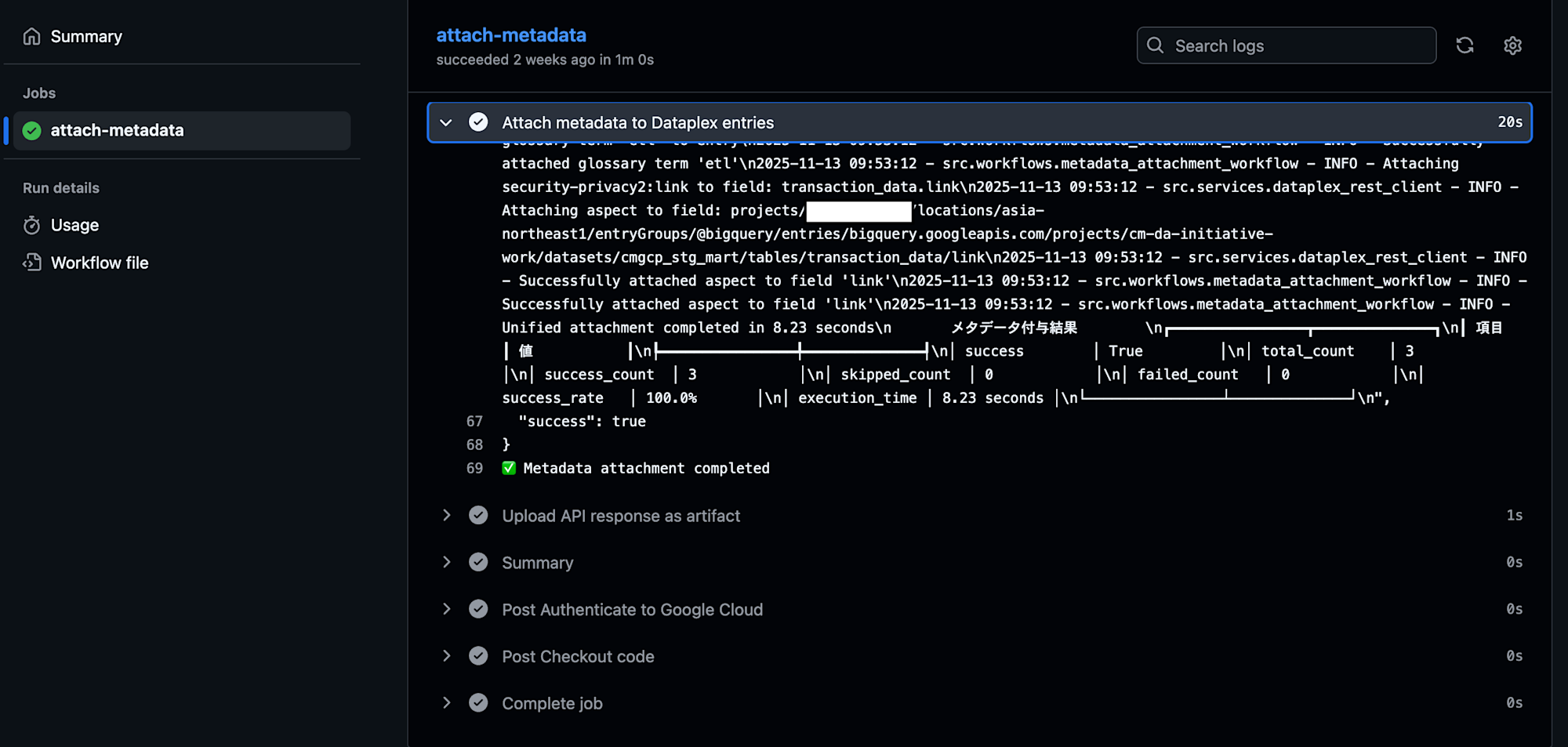
GitHub Actionワークフローのログ
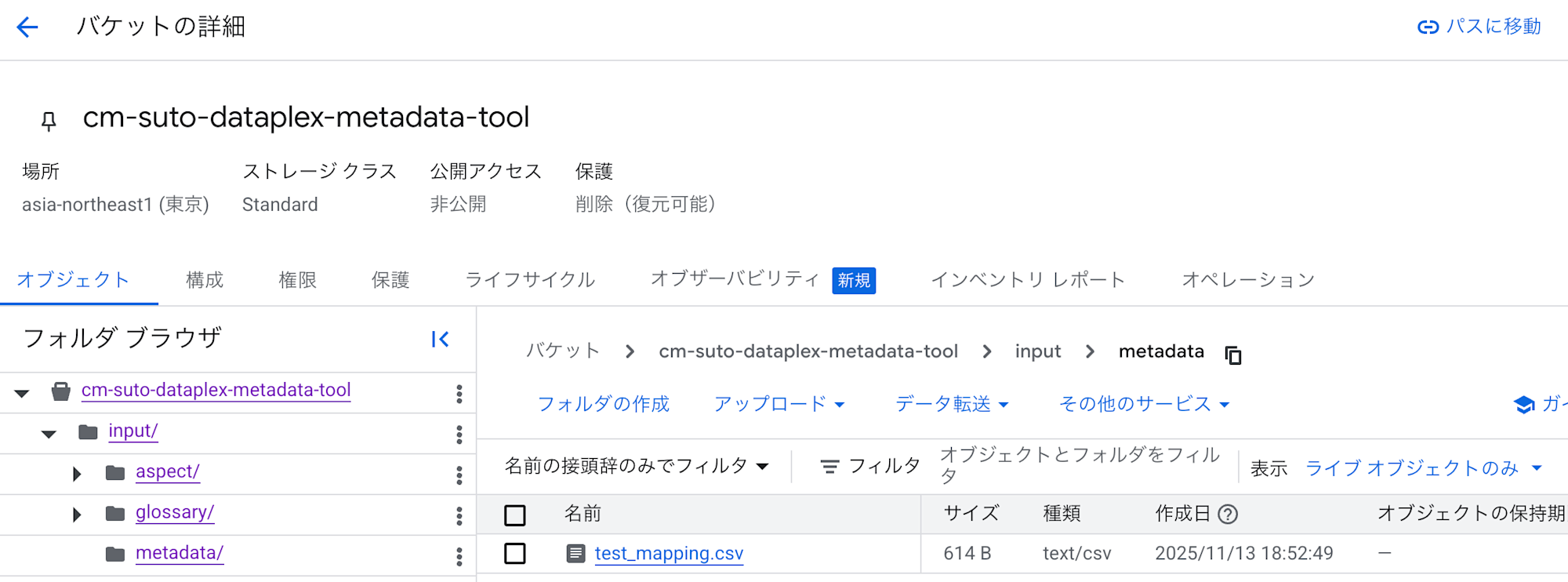
GCSバケットにファイルがコピーされています
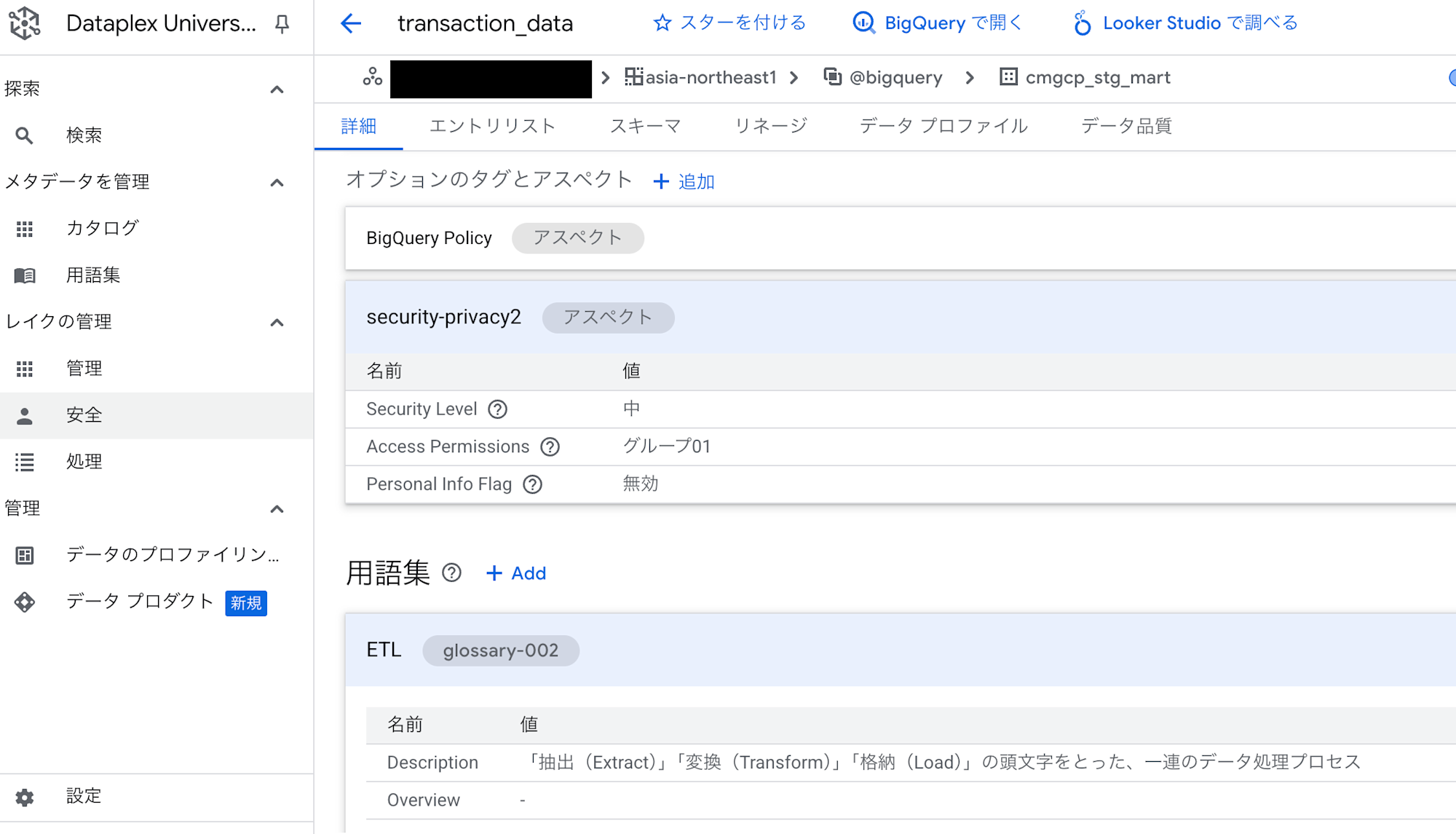
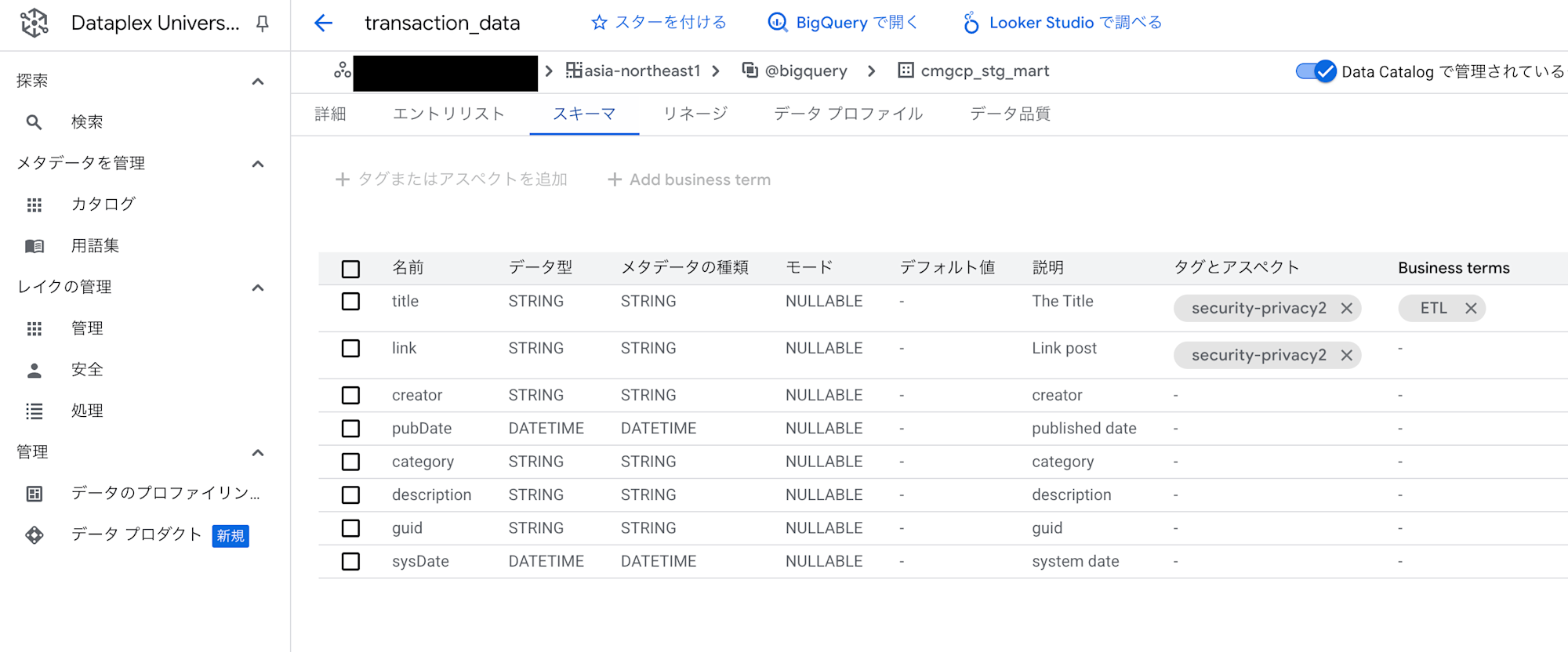
Dataplexカタログの対象エントリーに、問題なくメタデータ付与できました
以上となります。










