
GitHubのWiki更新をトリガーにGitHub ActionsでWikiのコンテンツをS3 Vectorsに登録してみた
リテールアプリ共創部@大阪の岩田です。
システム開発関連のドキュメントをどこで管理するかはプロジェクトによって様々ですが、GitHubのWikiを利用しているケースも多いのではないでしょうか?また、近年のLLMの進歩によってWikiのコンテンツをうまくベクトル検索できると、色々な調べごとが捗りそうです。
GitHubのWikiに記載されたドキュメントをうまくS3 Vectorsに放り込みつつ、Wikiの更新に追随できると便利そうだと思ったので、GitHub Actionsを使ってWikiの更新をS3 Vectorsに反映するワークフローを作ってみました。
やってみる
ということで実際にやっていきます。
S3バケットの準備
まずはバケットの作成からです。
export VECTOR_BUCKET_NAME=<作成するバケットの名前>
aws s3vectors create-vector-bucket \
--vector-bucket-name $VECTOR_BUCKET_NAME
続いてインデックスを作成します。
export INDEX_NAME=<作成するインデックスの名前>
aws s3vectors \
create-index \
--vector-bucket-name $VECTOR_BUCKET_NAME \
--index-name $INDEX_NAME \
--data-type float32 \
--dimension 1024 \
--distance-metric cosine
GitHub Actions用のIAMロール作成
GitHub Actionsからaws-actions/configure-aws-credentials@v4を使ってIAMロールを引き受けるためにIDプロバイダやIAMロールを作成します。詳細な手順についてはすでに多数のブログが存在するため割愛します。今回はS3 Vectorsへの書き込みを行うため、IAMロールにs3vectors:PutVectorsとbedrock:InvokeModelの権限を付与しておいてください。
GitHubリポジトリにvariablesを登録
ここまでで作成したAWSリソースの情報をGitHubリポジトリのvariablesに登録しておきます。
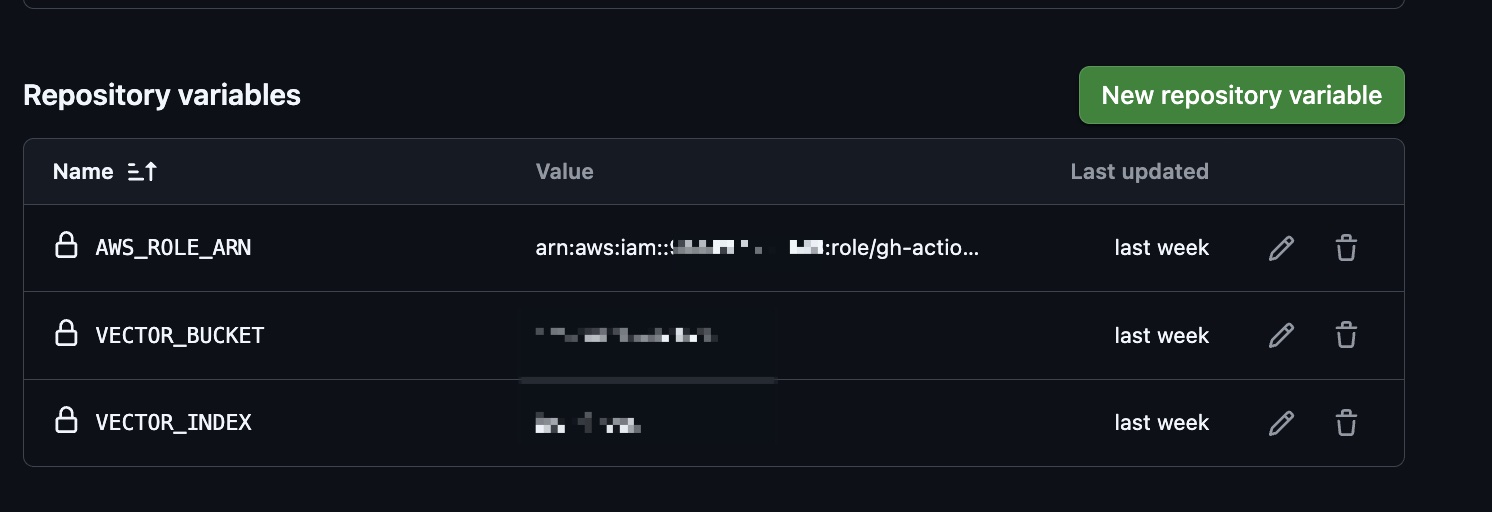
これで後ほど作成するワークフローに必要な情報がvarsから取得できるようになります。
ベクトル登録用のシェルスクリプト作成
次にWikiのコンテンツをベクトル化してs3vectorsに登録するシェルスクリプトを作成します。今回は以下のようなシェルスクリプトを作成しました。
#!/bin/bash
set -eo pipefail
PAGES="$1"
VECTOR_BUCKET="$2"
VECTOR_INDEX="$3"
# JSONの要素数を取得
ELEMENT_COUNT=$(echo "$PAGES" | jq 'length')
echo "要素数: $ELEMENT_COUNT"
# 要素数だけループ
for i in $(seq 0 $((ELEMENT_COUNT - 1))); do
PAGE_NAME=$(echo "$PAGES" | jq -r ".[$i].page_name")
echo "----------------------------------------"
echo "処理中: $PAGE_NAME"
PAGE_CONTENT=$(cat "$PAGE_NAME.md")
jq -n --arg text "$PAGE_CONTENT" '{"inputText": $text}' > file.json
aws bedrock-runtime invoke-model \
--model-id amazon.titan-embed-text-v2:0 \
--body fileb://file.json \
--content-type application/json \
--accept application/json \
output.json
jq -c '.embedding' output.json > vector_data.json
# アップロード用のベクトルJSONを作成
SOURCE_TEXT=$(jq -n --arg text "$PAGE_CONTENT" '$text')
cat > vector_upload.json << EOF
[
{
"key": "${PAGE_NAME}",
"data": {
"float32": $(cat vector_data.json)
},
"metadata": {
"source_text": $SOURCE_TEXT
}
}
]
EOF
aws s3vectors put-vectors \
--vector-bucket-name "$VECTOR_BUCKET" \
--index-name "$VECTOR_INDEX" \
--vectors file://vector_upload.json
echo "S3へのベクトル登録完了: ${PAGE_NAME}"
echo "----------------------------------------"
done
echo "========================================"
echo "全処理完了"
処理の流れの概要は以下の通りです。
- 第1引数で登録対象ページのファイル名を、第2,3引数でバケット名とインデックス名を受け取る
- 登録/更新されたWikiページの分だけ以下の処理を繰り返し
- 対象ページのコンテンツをTitanでベクトル化
- 内容次第では入力テキストトークンの最大数:8,192を超えることも想定されますが、今回は検証目的なので考慮外としています。
- ベクトル化したデータをS3に保存
- 対象ページのコンテンツをTitanでベクトル化
エラーハンドリングなどは割愛しているのでご注意ください。
このシェルスクリプトをGitHub Actionsのワークフローから呼び出してWikiのコンテンツを順次S3 Vectorsに取り込んでいきます。
GitHub Actionsのワークフローを作成
続いてGitHub Actionsのワークフローを作成します。今回作成したワークフローは以下の通りです。
name: Create Vectors
on: gollum
permissions:
id-token: write
jobs:
job:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v1
- name: Dump github.event
env:
EVENT: ${{ toJson(github.event) }}
run: echo "${EVENT}"
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ vars.AWS_ROLE_ARN }}
aws-region: ap-northeast-1
- name: Clone Wiki
run: git clone https://github.com/${{ github.repository }}.wiki.git --depth 1
- name: Save Vectors
run: |
REPO_NAME=$(echo "${{ github.repository }}" | cut -d '/' -f 2)
cd ${REPO_NAME}.wiki
PAGES=$(jq -c .pages <<< $EVENT)
bash ../save-vectors.sh "$PAGES" ${{ vars.VECTOR_BUCKET }} ${{ vars.VECTOR_INDEX }}
env:
EVENT: ${{ toJson(github.event) }}
shell: bash
ポイントをいくつか見ていきましょう。
まずonにgollumを指定することでWikiページの作成/更新をトリガーにワークフローを起動します。ページの削除ではワークフローが起動されないため、一度登録されたベクトルは削除できないことに注意しましょう。
イベントデータの中身は以下のようになっており、ページ名が変更された場合は変更前のページ名が取得できないことも注意が必要です。
{
"pages": [
{
"action": "edited",
"html_url": "https://github.com/<リポジトリ名>/wiki/Home",
"page_name": "Home",
"sha": "af35ba689cb5d93f378edf8f0b1eed9b34e4caff",
"summary": null,
"title": "Home"
}
],
"repository": {
"allow_forking": true,
...略
}
}
Clone Wikiのステップではgit clone https://github.com/${{ github.repository }}.wiki.git --depth 1で対象GitHubリポジトリに紐づくWikiのリポジトリをクローンしてWikiのコンテンツを取得します。
Wikiのリポジトリには<ページ名>.mdという形式のファイル名がフラットに並んでいるので、Save Vectorsのステップで対象マークダウンファイルの名前を抽出してバケット名、インデックス名と合わせてシェルスクリプトに渡してベクトルを登録します。
Wikiページを作成/更新してみる
ここまでで準備が整ったので、実際にWikiページをいくつか作成/更新してみます。今回は適当に昔話でも登録しておきましょう。
5つほど昔話を登録しました!
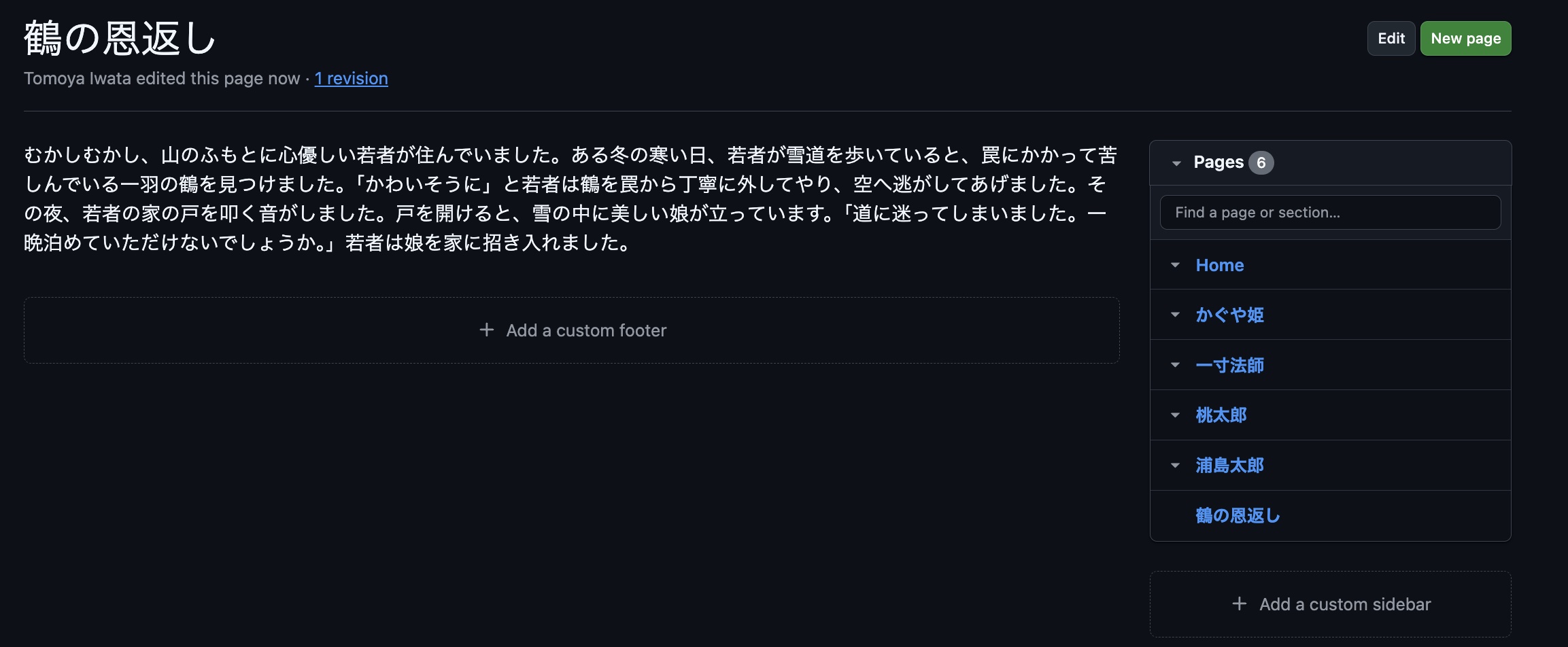
実際にS3 Vectorsの状況を確認してみます。
aws s3vectors list-vectors --vector-bucket-name $VECTOR_BUCKET_NAME --index-name $INDEX_NAME
{
"vectors": [
{
"key": "桃太郎"
},
{
"key": "鶴の恩返し"
},
{
"key": "かぐや姫"
},
{
"key": "Home"
},
{
"key": "一寸法師"
},
{
"key": "浦島太郎"
}
]
}
Wikiのページ名をキーに6つのベクトルが登録されています。
ベクトル検索を試してみる
最後にベクトル検索を試してみましょう。まず検索に利用する自然言語をベクトル化します。
aws bedrock-runtime invoke-model \
--model-id amazon.titan-embed-text-v2:0 \
--body '{"inputText":"動物がたくさん登場する昔話を教えて"}' \
--content-type application/json \
--accept application/json \
--cli-binary-format raw-in-base64-out \
/tmp/out.json
レスポンスが /tmp/out.jsonに保存されたので、ベクトルを/tmp/embedding.jsonに取り出します。
jq '{float32: .embedding}' /tmp/out.json > /tmp/embedding.json
準備が整ったのでいざ検索!
aws s3vectors query-vectors \
--vector-bucket-name $VECTOR_BUCKET_NAME \
--index-name $INDEX_NAME \
--query-vector file:///tmp/embedding.json \
--top-k 3 \
--return-distance
結果は以下の通りでした。
{
"vectors": [
{
"key": "浦島太郎",
"metadata": {},
"distance": 0.7682133913040161
},
{
"key": "鶴の恩返し",
"metadata": {},
"distance": 0.8019433617591858
},
{
"key": "一寸法師",
"metadata": {},
"distance": 0.8462569713592529
}
],
"distanceMetric": "cosine"
}
まあ良い感じに検索できてるんじゃないでしょうか?
まとめ
ドキュメントをGitHubのWikiで管理しているプロジェクトにおけるAIやLLM活用の1例として参考になれば幸いです。
今回はS3 Vectorsに直接書き込みましたが、Wikiのマークダウンファイルは通常のS3バケットにPutObjectしてBedrock Knowledge Basesの機能でS3 Vectorsに同期するようなアーキテクチャにすると色々拡張性が広がりそうですね。









