Go runtime の goroutine の動きを覗いてみた
こんにちは 人材育成室 育成メンバーチームで 研修中の はすと です。
前回書いたGo のバイナリを覗いてみた ではGoのバイナリを覗いて、Go の早さは runtime に関係しているだろうという結論に至りました。go runtimeには goroutine, GC, メモリマネージャー、チャネルなど、いくつかの構成要素があります。今回はその中にある goroutine に焦点を当てて、仕組みを覗いてみます。
goroutine とは
まず、goroutineとは、Go のruntimeにおける並行と並列処理を可能にするものです。
並行と並列はそれぞれ別の意味を持ちます。並行とは1つのCPUで処理を交互に行うことで、複数の処理があたかも同時に行われているように見えるものです。並列とは、複数のCPUを使って複数の処理をそれぞれのCPUに割り振って同時に行うことを言います。
例えば、メールの返信とコードを書くという二つのタスクがあったときに、並行は一人の自分が、メールを書いた後にコードを書いて、メールの返信が返ってきたらメールを書いて、またコードを書く作業に移るという動きをして、見た目上は同時に行っているように見えますが掛かっている時間は変わりません。
並列の場合は自分が物理的に二人存在し、メールを書く人とコードを書く人が完全に分離している状態です。そうなるとかかる時間は1/2になります。
goroutineにおける 3つの概念 GMP
なぜ CPU1個でも並行処理ができるのか?それを理解するためには goroutineを支える G・M・Pの3つの概念を知る必要があります。
| 説明 | |
|---|---|
| G | goroutine の実行単位 |
| P | GをキューイングしMをアタッチするスケジューラ |
| M | OSスレッド。PにアタッチされることでGを実行する |
GがブロックされるとPは現在のMをデタッチし、空いているMを新たにアタッチします。これによりブロック中でも、キューに溜まっている次のGの実行を継続できます。
図で説明するとこんな感じです。
まずは、G1,G2というタスクがPのキューに溜まった状態で、Mが複数空いている状態です。
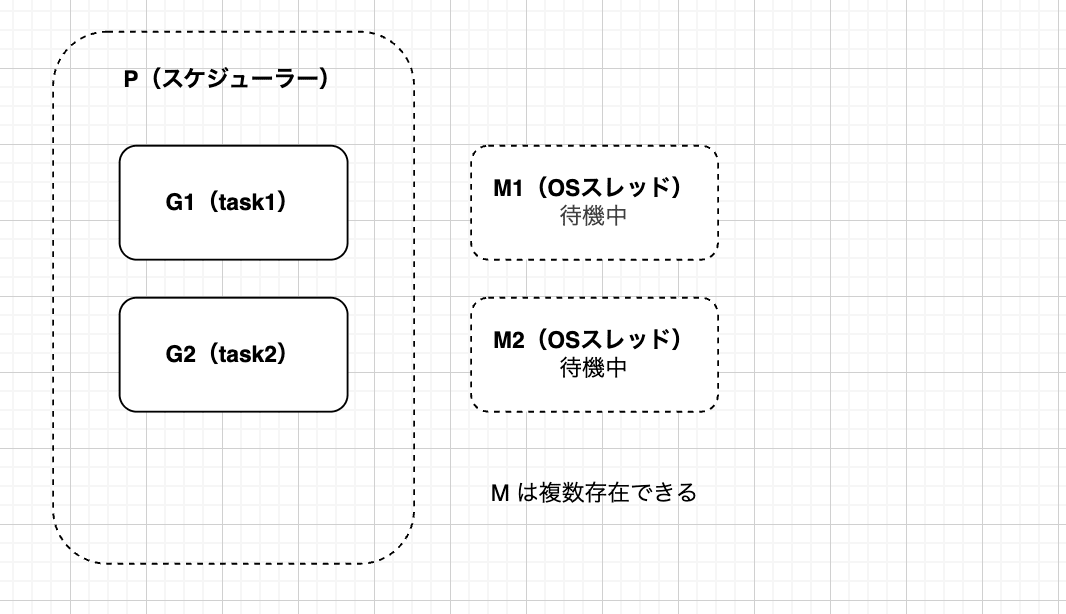
Pは空いているM1をアタッチして、G1を実行します。
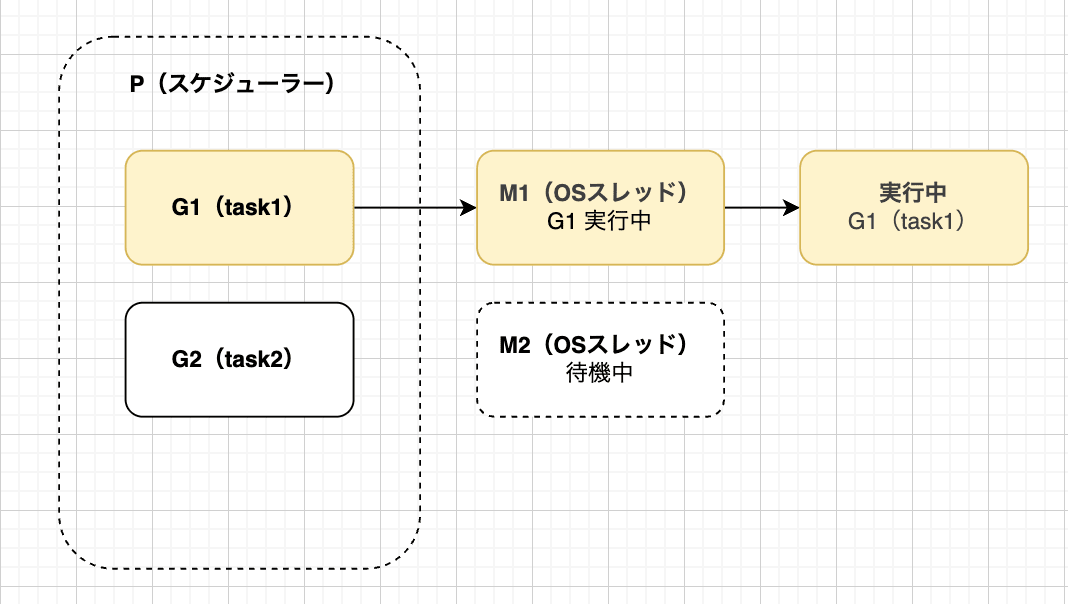
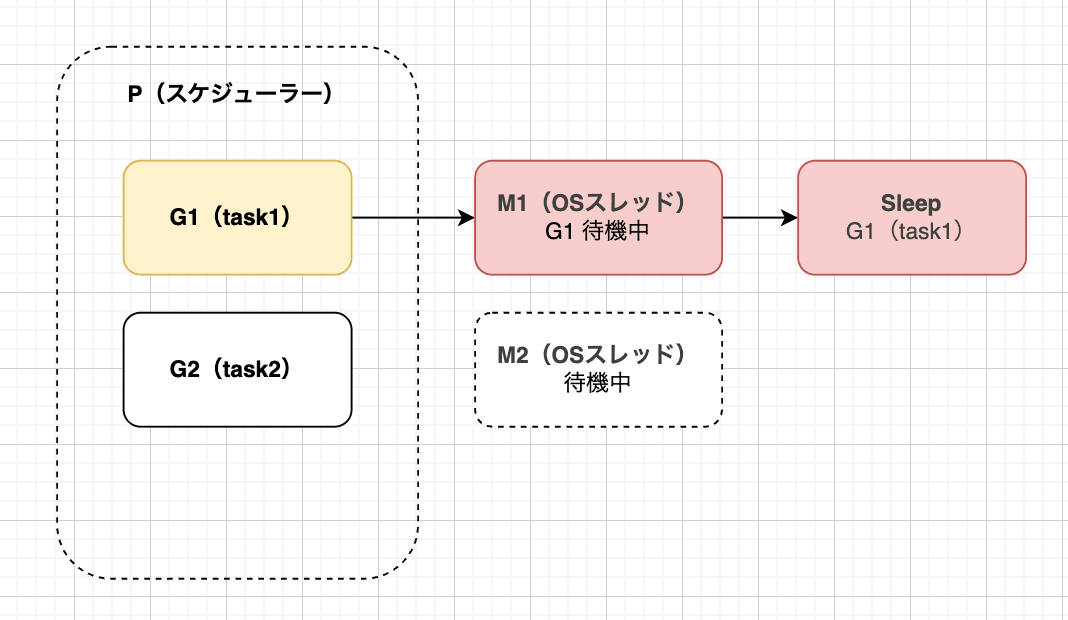
すると、G1で待機状態が発生してしまい、M1は待機状態に入ってしまいました。
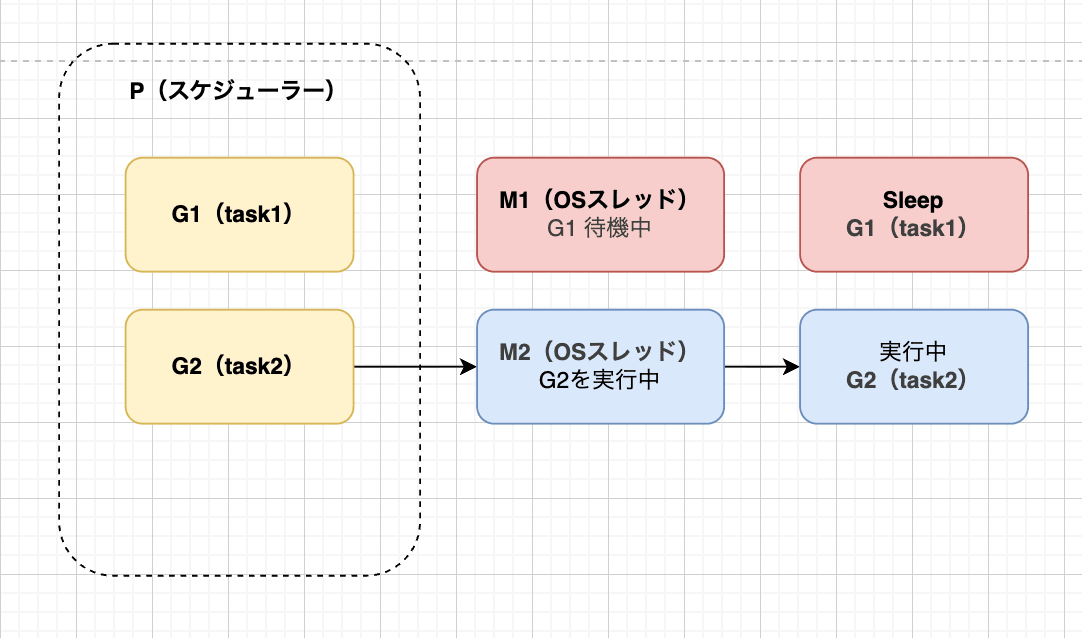
PはG2という別のタスクを実行したいため、待機状態になってしまった、M1をデタッチし、空いているM2をアタッチします。
PはアタッチしたM2でG2を実行することができました!
GMPの仕組みがわかったところで、次は実際どう機能するのかruntime.GOMAXPROCS の値を変えながら検証してみます。GOMAXPROCS は goroutine を同時に実行できるPの数を指定する設定で、デフォルトではマシンのCPUコア数が使われます。
GOMAXPROCS を変えて検証
検証はI/O処理とCPU処理の2パターンで見ていきます。I/O処理ではGMPのブロック時の動き、CPU処理ではGOMAXPROCSの違いが、それぞれ処理時間にどう影響するのかを見ていきます。
I/O処理の場合
I/O処理のサンプルコードとして、time.Sleep でI/O処理を再現しています。実際のI/O処理と同様に、CPUを使わずGをブロックする動きをするため、GMPの動きを見るのに適しています。
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
func ioTask(id int) {
fmt.Printf("task %d: start\n", id)
time.Sleep(10 * time.Second) // I/O-bound的なタスク(ただ待つ)
fmt.Printf("task %d: done\n", id)
}
func main() {
runtime.GOMAXPROCS(1) // 変更して検証(1 or 2)
var wg sync.WaitGroup
start := time.Now()
wg.Add(2)
go func() { defer wg.Done(); ioTask(1) }()
go func() { defer wg.Done(); ioTask(2) }()
wg.Wait()
fmt.Printf("elapsed: %v\n", time.Since(start))
}
| GOMAXPROCS | 実行時間 |
|---|---|
| 1 | 10.012s / 10.009s / 10.004s |
| 2 | 10.014s / 10.012s / 10.010s |
結果は、GOMAXPROCSを増やしても変わりませんでした。
これは、GMPが正しく機能している証拠と言えます。PはMが待機中になった時、空いているMで次のタスクを実行します。そのため、GOMAXPROCSの数は関係なく並行して処理を進めることができ、実行時間には差が生まれないという結果になりました。
CPU処理の場合
CPU処理のサンプルコードとして、ループ加算でCPUを占有し続ける処理を用意しました。I/O処理とは異なり待機状態が発生しないため、GOMAXPROCSの値が処理時間にどう影響するか確認できます。
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
func cpuTask(id int) {
fmt.Printf("task %d: start\n", id)
sum := 0
for i := 0; i < 2_000_000_000; i++ {
sum += i
}
fmt.Printf("task %d: done (sum=%d)\n", id, sum)
}
func main() {
runtime.GOMAXPROCS(1) // ← 1と2で切り替えて計測
var wg sync.WaitGroup
start := time.Now()
wg.Add(2)
go func() { defer wg.Done(); cpuTask(1) }()
go func() { defer wg.Done(); cpuTask(2) }()
wg.Wait()
fmt.Printf("elapsed: %v\n", time.Since(start))
}
| GOMAXPROCS | 実行時間 |
|---|---|
| 1 | 910.10ms / 929.43ms / 939.35ms |
| 2 | 484.60ms / 490.86ms / 489.65ms |
CPU処理の場合は、GOMAXPROCSの数に応じて約半分になりました。
CPU処理は、I/O処理とは違い待機状態が発生しないため、GOMAXPROCS が1の場合は 2つのタスクを交互に実行します。
結果、GOMAXPROCS が1の場合は、1つのタスクにかかる時間 x 2の時間がかかるというわけです。
なぜこのような結果になったのかをそれぞれ図にしてみます。
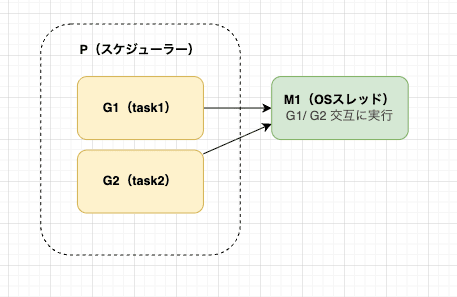
GOMAXPROCS が1の場合
GOMAXPROCS が1の場合は、Pは一つなのでキューにあるタスクを交互に実行します。
ここで、「キューなのになぜ交互?」と疑問に思ったかもしれません。これは プリエンプション という仕組みがあるためです。プリエンプション とは Goスケジューラーが「このGは長く動きすぎ」と判断して、強制的にGを切り替える仕組みです。
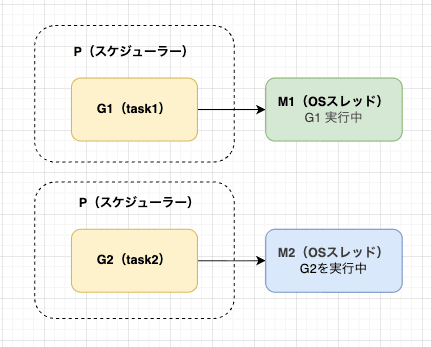
GOMAXPROCS が2の場合
GOMAXPROCS が2の場合はPが2つ存在し、それぞれがGを実行するため、実行時間は半分になったということです。
ここからは、さらに解像度を上げるためgo tool trace を使って実際のGMPの動きを可視化してみようと思います。runtime/trace パッケージを使うと、プログラム実行中の GMP のイベント(Gの生成・Pへのアタッチなどのスケジューリング情報)をファイルに記録し、go tool trace でブラウザ上にタイムライン表示ができます。
go tool trace で GMP の動きを見てみる
CPU処理のコードに、trace記録用のコードを数行追加します。
package main
import (
"fmt"
"runtime"
"sync"
"time"
"os"
"runtime/trace"
)
func cpuTask(id int) {
fmt.Printf("task %d: start\n", id)
sum := 0
for i := 0; i < 2_000_000_000; i++ {
sum += i
}
fmt.Printf("task %d: done (sum=%d)\n", id, sum)
}
func main() {
runtime.GOMAXPROCS(2) // ← 1と2で切り替えて計測
f, _ := os.Create("trace.out") // トレース結果の出力先ファイルを作成
trace.Start(f) // トレース記録開始
defer trace.Stop() // トレース記録終了
var wg sync.WaitGroup
start := time.Now()
wg.Add(2)
go func() { defer wg.Done(); cpuTask(1) }()
go func() { defer wg.Done(); cpuTask(2) }()
wg.Wait()
fmt.Printf("elapsed: %v\n", time.Since(start))
}
続いて、先ほどのコードを実行し、生成されたtrace.out ファイルをターゲットにgo tool trace を実行します。
$ go run ./go/cpu-bound.go
$ go tool trace -http=":8080" trace.out
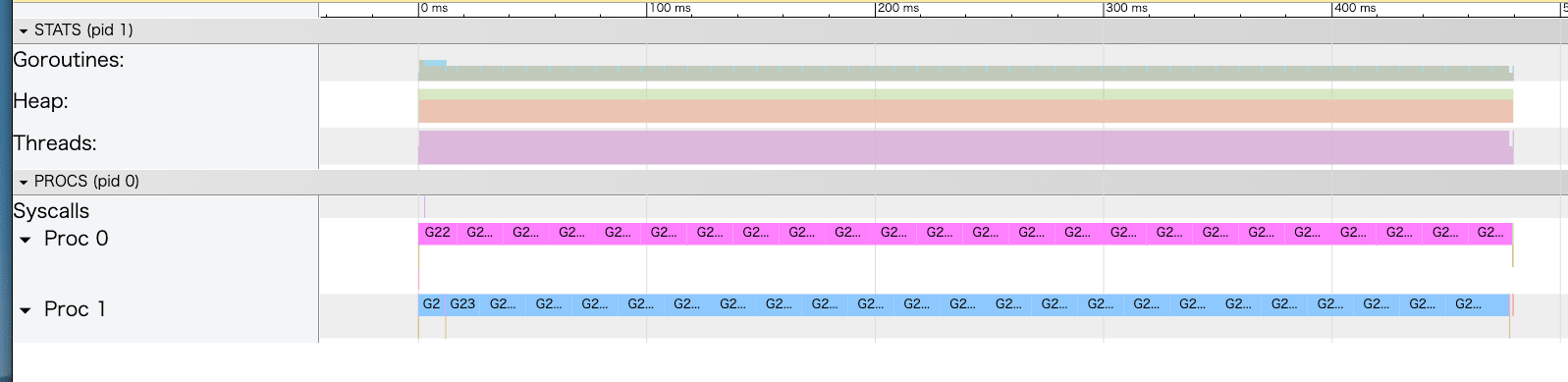
GOMAXPROCS(1)の場合
ここが非常に面白いポイントで、Pは確かに一つですが、二つのタスクが交互に走っています。
少し振り返ると並行とは「1つのCPUで処理を交互に行うこと」でした。まさに以下のトレース画面ではそれを表しています。goroutineの仕組みとしては、プリエンプション が発生していることがわかります。
STATSの項目について
トレース画面上部のSTATSでは3つの情報が確認できます。
- Goroutines: goroutineの数の推移(Running/Runnable/GCWaitingの内訳)
- Heap: 現在のヒープ使用量(Allocated)と次のGCが発動する閾値(NextGC)を表示。
- Threads: OSスレッド数の推移。ProcとMが1対1でアタッチしているため、GOMAXPROCS=2ではスレッドも2本使われていることがわかります。


GOMAXPROCS(2)の場合
こちらも非常に面白い結果が見えました。
Pが二つ存在するのは予想通りだったのですが、2つのPがそれぞれ自分のGだけを処理し続けるパターンと、PをまたいでGが入れ替わるパターンの2種類がありました。これはトレースを実際に可視化したからこそ見えたものです。
では、なぜこのようにばらつくのでしょうか?これはグローバルキューの存在が関わっています。プリエンプションが発生すると、GはPのローカルキューではなくグローバルキューに入ります。空になったPはグローバルキューからGを探しにいきますが、どのPが先に取得するかはタイミング次第です。そのため、同じPが同じGを再取得することもあれば、別のPが取得して入れ替わることもあります。
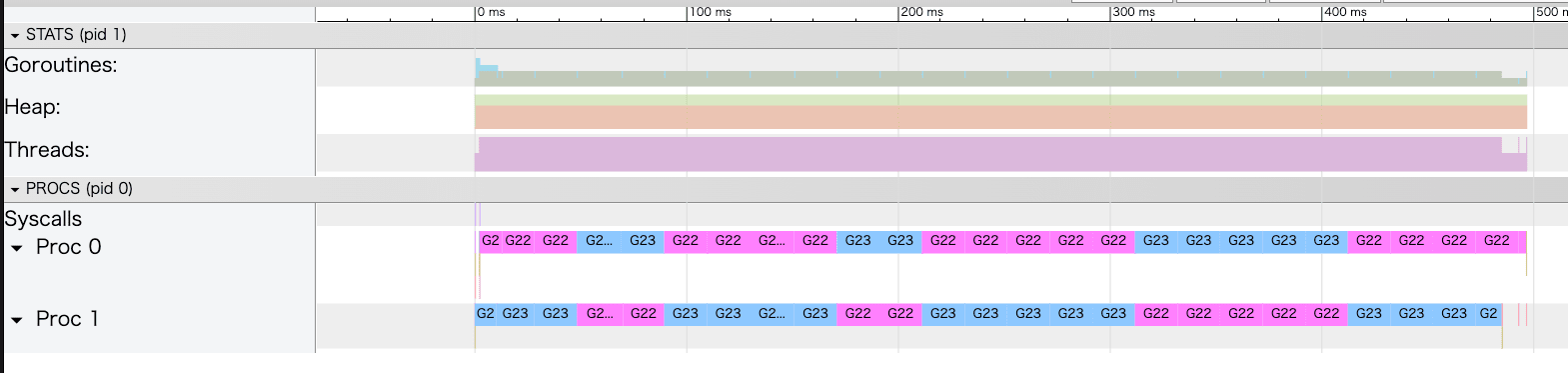
2つのパターンを図で比較してみます。
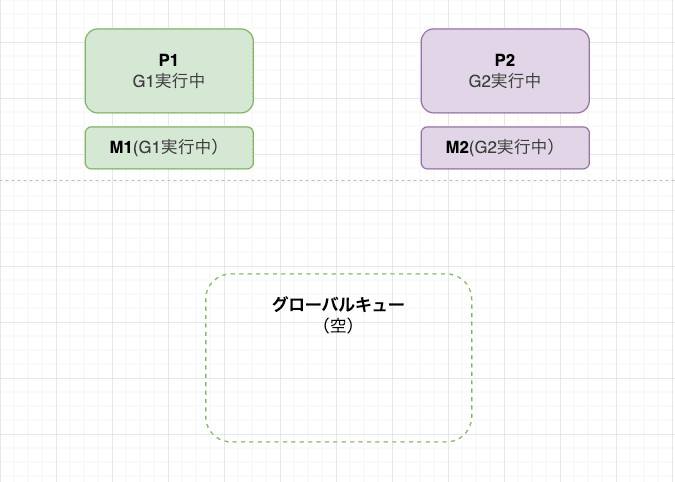
同じPが担当し続けるパターン
それぞれのPが自分のGをMにアタッチして並列実行しています。
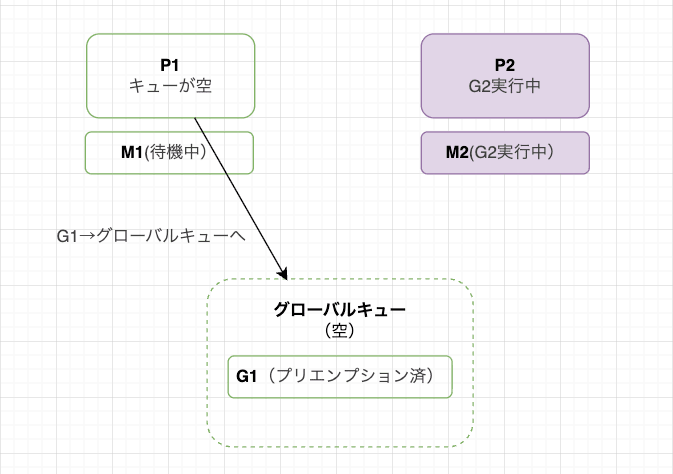
G1 にプリエンプションが発生し、G1 はPのローカルキューではなくグローバルキューに入ります。
この時、P2 は G2 を引き続き実行中なため、グローバルキューには G1のみがある状態です。
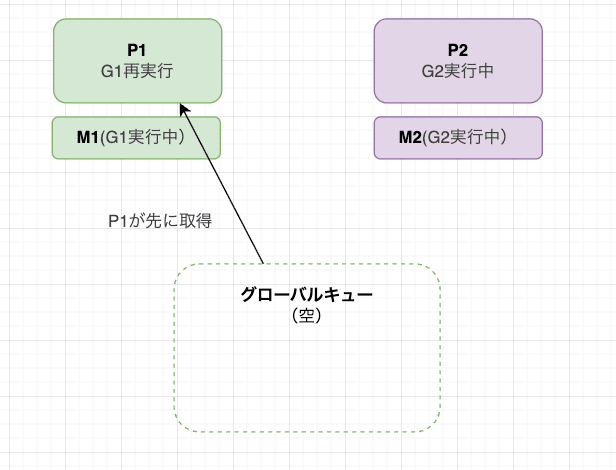
次に、P1 がグローバルキューを確認し、再度 G1 を取得して自分のキューに入れます。
そして、P1 は G1 を再び実行し、同じ P が同じ G を担当し続ける流れになります。これがトレース画面では同じ色が途切れず続いて見えます。
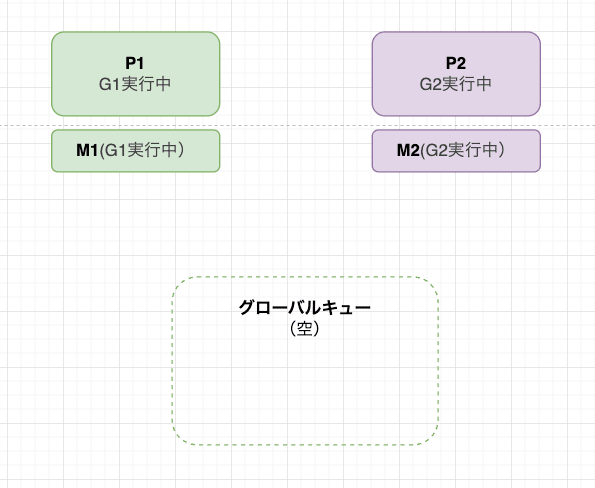
Gが入れ替わるパターン
こちらも初めは同じく、それぞれのPが自分のGをMにアタッチして並列実行しています。
ここからが異なる部分で、G1 と G2 にほぼ同時にプリエンプションが発生します。G1・G2 の両方がグローバルキューに入り、両方のキューが空になります。
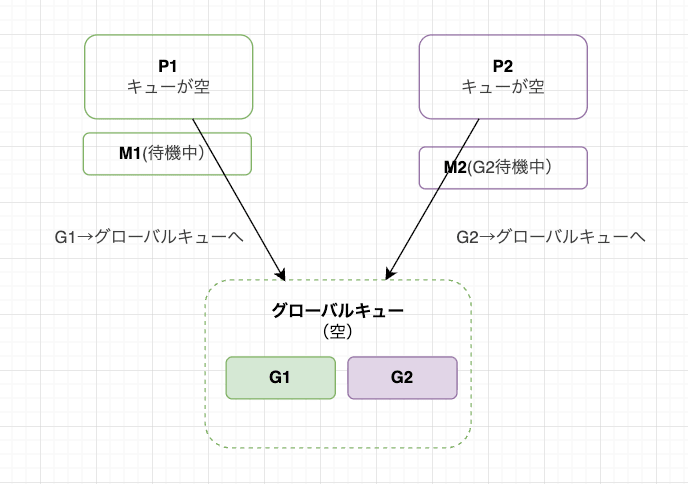
P1 と P2 が同時にグローバルキューを確認しにいきます。
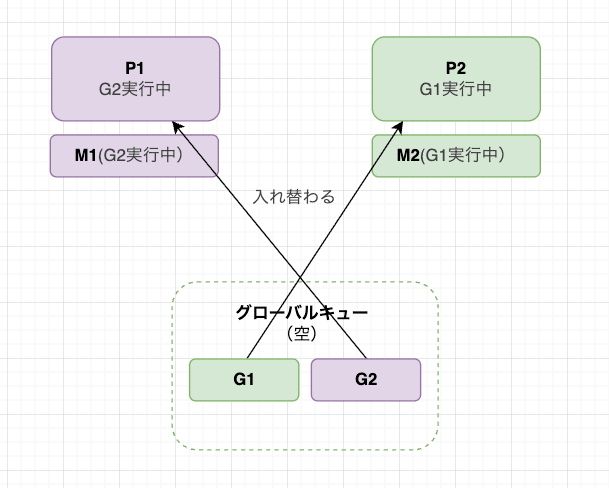
取得順はタイミング次第ですが、今回は P1 が G2 を、P2 が G1 を取得しました。
これが、P をまたいで G が入れ替わるパターン で、トレース画面では色が交差して見えます。
おまけ
Proc部分を拡大してみると違和感に気づきました。
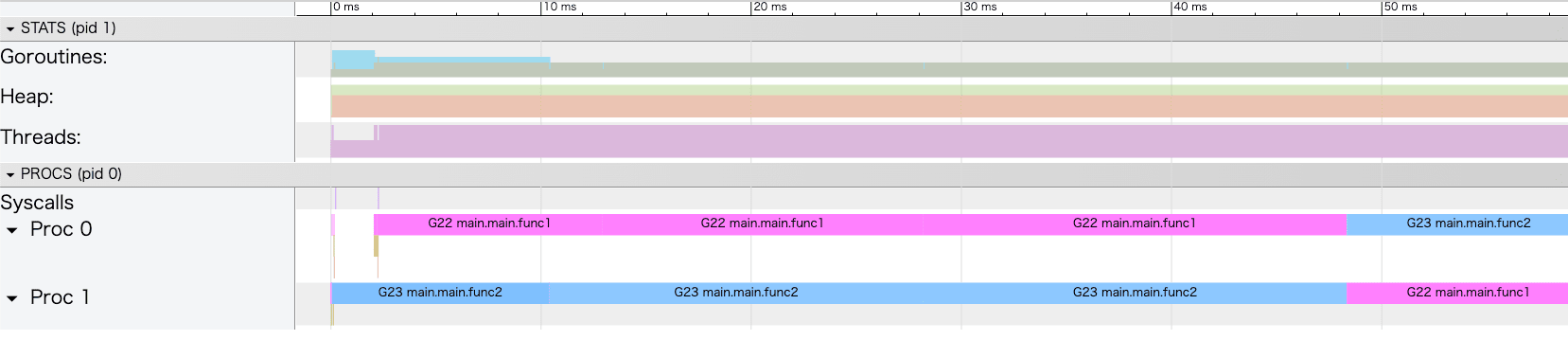
Proc0が若干遅くスタートしています。これはなぜでしょうか。
これは、コードを見返すとわかるのですが、以下のように go func() を順番に実行していました。なので、goroutineのキューへの投入にわずかな時間差が生じ、起動タイミングがずれて見えた。という仕組みでした。
go func() { defer wg.Done(); ioTask(1) }()
go func() { defer wg.Done(); ioTask(2) }()
まとめ
今回は goroutine を支える GMP モデルの仕組みを、概念の理解から実際のトレースによる可視化まで段階的に見てきました。
テキストや図で「Pがブロック中のMをデタッチして別のMをアタッチする」「プリエンプションでGが切り替わる」といった動きはなんとなく理解できますが、go tool trace で実際のタイムラインを見ることで、自分の書いたコードがどのように動いているのかが見えて、非常に面白かったです。
特に GOMAXPROCS=2 のケースでは、同じPが同じGを担当し続けるパターン と、PをまたいでGが入れ替わるパターン の2種類を見ることができました。これはグローバルキューの存在を知識として知っているだけでは気づけない、可視化したからこそ見えた発見でした。
次回は、GC やメモリマネージャーなど、goroutine 以外の runtime の仕組みを覗いてみたいと思います。
参考









