物体検出モデルでシイタケの収穫時期を自動判定するまでにやったこと。〜①カスタムモデル作成編〜
はじめに
皆様こんにちは、あかいけです。
先日、DevelopersIO 2025 TOKYOにてシイタケのLTをしたのですが、
そこに至るまでの過程をブログにしてみます。
このブログを読み終わることには、好きなものを物体検出モデルで検出できるようになっているはずなので、ぜひ最後まで読んでもらえたら嬉しいです。
- 今回ブログ:カスタムモデルを作成するまで
- 次回ブログ:AWSにデプロイするまで
モチベーション
みんなシイタケ食べていますか?
私は食べてます。
和洋中、どんな料理にも合う最高の食材であるシイタケですが、
個人的にはシンプルに焼きシイタケが好きです。
そんなわけで毎日無限にシイタケを食べる方法を模索したところ、
シイタケの栽培に行きつきました。
しかし困ったことに私にシイタケはおろか、キノコの栽培経験がありません。
これではせっかく手塩にかけたシイタケたちを最高の状態で食すことができません。
あまりにも悲しすぎます…。
ということで今回は、
シイタケの収穫時期を見極めるためのカスタムモデルを作成してきます。
やりたいこと
- 成長段階を判別できるようにしたい
- 判別している状態が分かりやすく表示したい
- 画像と動画に対応したい
事前学習モデルを使おう。
ゼロイチで作るにはあまりにも時間と私の知識が足りないため、今回は事前学習モデルを活用し、その中でも有名なYOLOを使います。
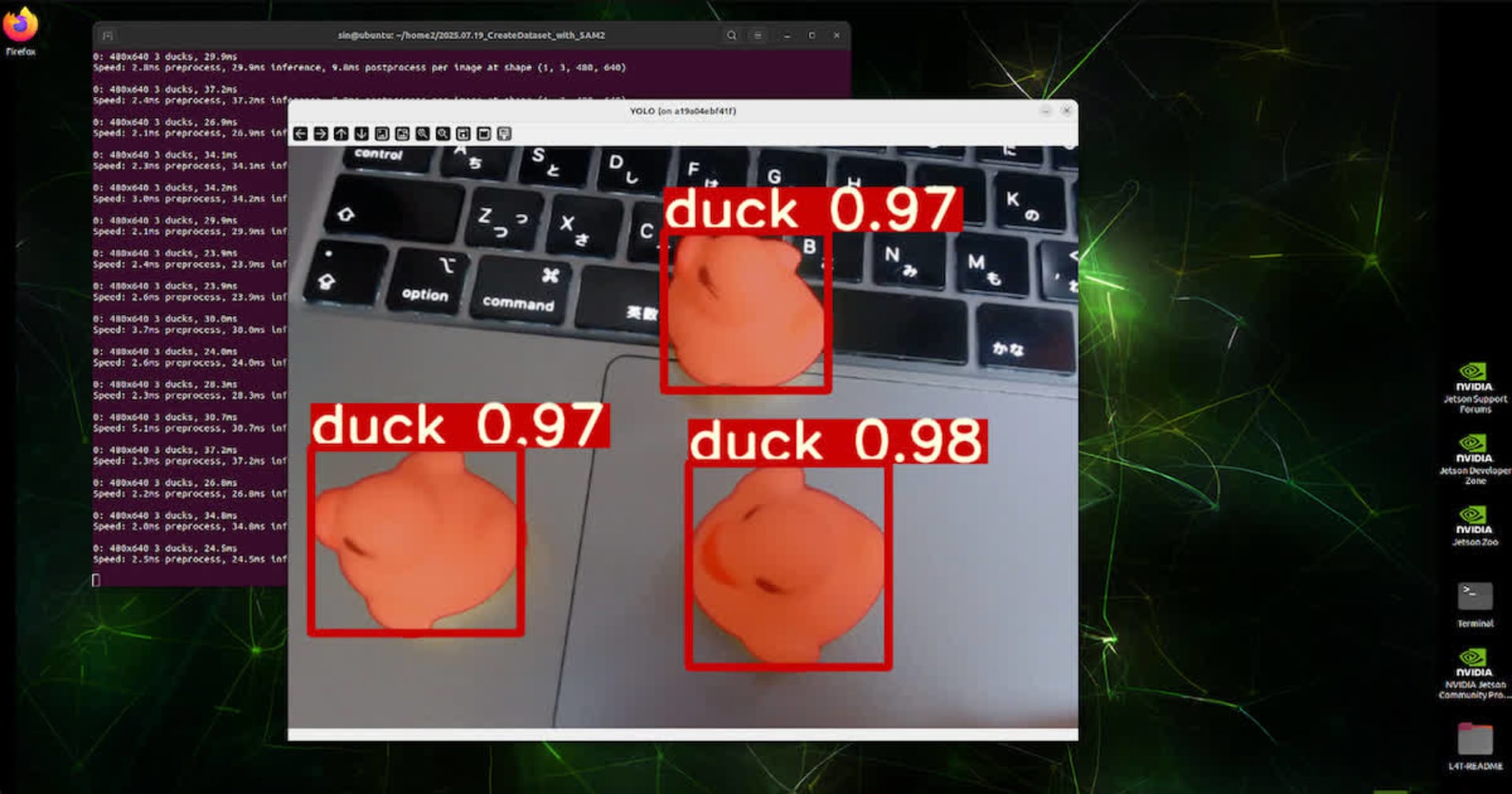
YOLOは画像や動画に対して物体検出ができ、以下のように学習済みの物体を検出すると、四角い枠(バウンディングボックス)で囲んで教えてくれます。
以下のような画像を見たことがある方も多いのではないでしょうか。
なおYOLOを使うために必要な作業は以下ブログに記載しているので、
よろしければこちらをご参照ください。
事前準備
前述したYOLOはデフォルトではシイタケに対応していないため、カスタムモデルを作成する必要があります。
そのためまずは学習時に利用するデータセットを準備する必要があるので、シイタケを育てます。
0.シイタケはどうやって育てよう?
さて、シイタケ栽培といえば山の中で原木で育てているイメージをされる方が多いのではないでしょうか?

しかし残念ながら現在私は山を所有していませんし、
LTをするまでの一ヶ月で到底用意できるものでもありません。
なので今回は菌床で育てるタイプのシイタケを用意しました。
具体的にはAmazonで購入した、もりのきのこ農園シリーズのもりのしいたけ農園です。
Twitterで調べてみるとわりと有名なようで、子供の自由研究などでも用いられているようです。

本体はこんな感じの物体で、
木のおがくずと米や麦の糠を混ぜた人工的な栄養に、シイタケ菌が植えてあるらしいです。

1.シイタケを育てる
ではシイタケを育てていきます。
シイタケを栽培したのは初めてでしたが、毎日お手入れしてあげること以外は特段難しいことはありませんでした。

水やり
水やりは毎日行います。
付属の説明書だと霧吹きと書いてありましたが、私は蛇口から水を直接ジャバジャバかけていました。
間引き
これが意外と重要で、大きいシイタケを育てるためには欠かせない作業でした。
ほっておくとだいたい50個ぐらいのシイタケが生えてくるのですが、
毎日間引いて最終的に10~20個ぐらいにしてあげると、いい感じのサイズのシイタケに成長してくれました。
2.データセット用の画像を集める
シイタケを育てながら、データセット用の画像を集めていきます。
毎日スマホで写真撮影していき、菌床を回しながら5回ぐらい、合計360度で一周写真を撮影するようにしました。

またシイタケの成長速度は思いの外早く、育て始めからだいたい5~7日前後で収穫時期を迎えました。
このあたりは温度も関係しているようなので、栽培する季節によっては前後しそうです。

カスタムモデルを作成する
ではいよいよカスタムモデルを作成していきます。
0.クラスを定義する
さて、カスタムモデル作成時に利用するデータセットの作成にあたり、まずはクラスを定義する必要があります。
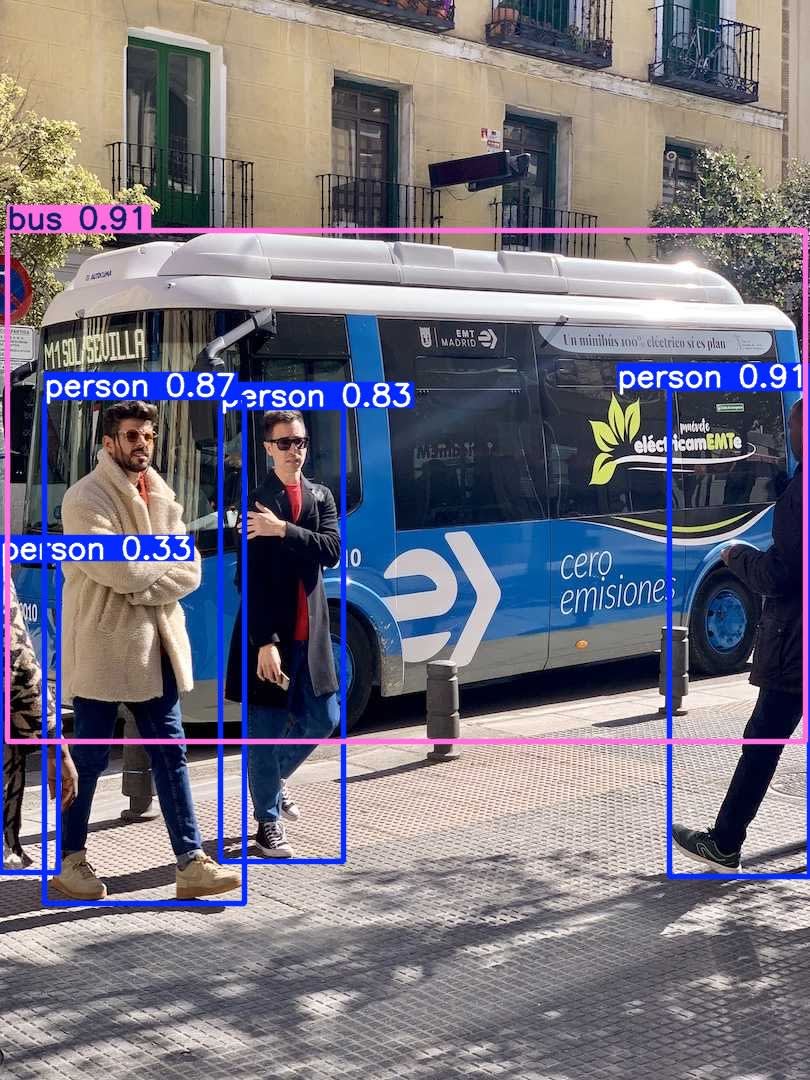
このクラスとは、本ブログ冒頭で出たようなバスと人を検出している画像のように、
「画像や動画から、どのような物体を何として検出するか」を表します。
今回はシイタケの成長に合わせて検出をしたいため、以下5つのクラスを定義しました。
0: pin # ピン期 - 傘が完全に閉じている、丸い形状
1: primordia # 原基期 - 傘閉じているが伸び始め、円柱形
2: young # 若菇期 - 傘開き始め、きのこの形だが傘は小さい
3: harvest # 収穫期 - 収穫適期、シイタケの形で傘が肉厚
4: overripe # 過熟期 - 育ちすぎ、傘が平べったくなる

なお本来ならシイタケ農家の方の知見をお借りしたいところですが、
残念ながらそんな知り合いはいないので、私の独断と偏見で定義しました。
1.アノテーションする
さて定義したクラスに応じたデータセットを作成するために、「アノテーション」という作業をする必要があります。
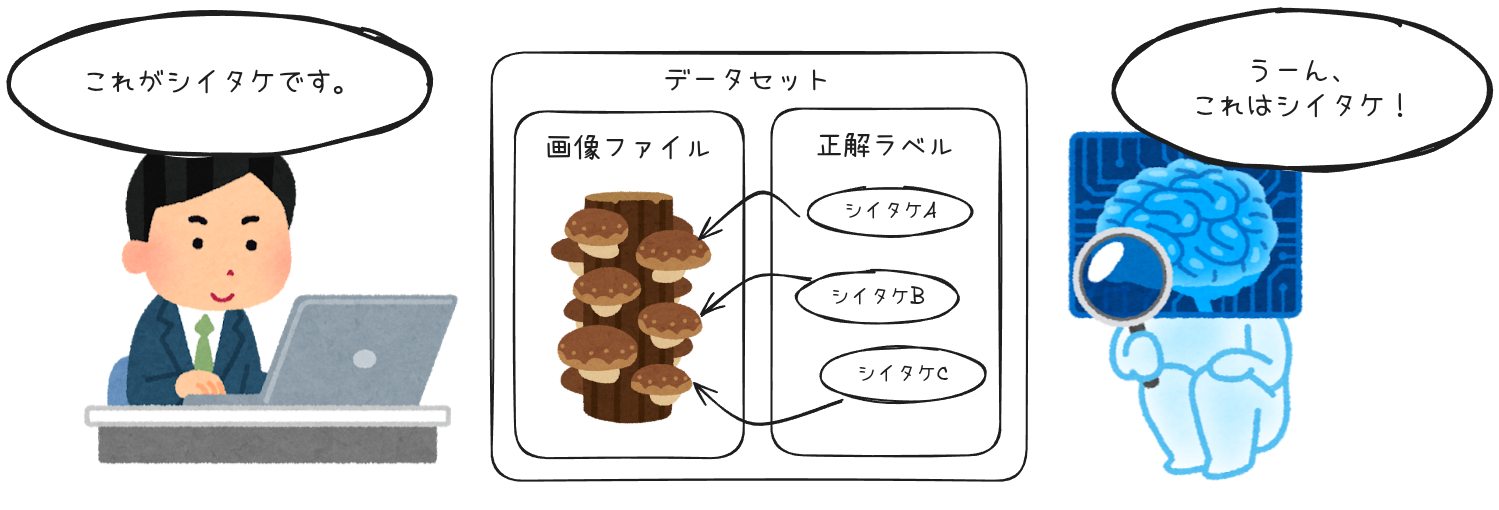
物体検出含む機械学習におけるアノテーションとは、画像ファイル内の物体に対して「これは何であるか」という正解ラベルを付ける作業です。
今回のような教師あり学習では、学習時に以下のようにAIに「正解」を教える必要があるため、この作業が必須となります。
YOLOで物体検出を行う場合、データセットの実態は 「画像ファイル + 検出対象の位置情報を記したテキストファイル」 のセットとなります。
具体的には以下のように、画像ファイルとそれに対応した同じ名前のtxtファイルとなります。

<クラスID> <ボックスの中心x> <ボックスの中心y> <ボックスの幅> <ボックスの高さ>
ただこのアノテーションの作業を人力でやっていたら一生かかってしまうため、
アノテーション用のツールを利用します。
巷には様々なアノテーションツールがあるのですが、今回は「Label Studio」を利用します。
選んだ理由は無料で利用できること、またローカルでの実行がDockerで簡単にできるためです。
まずは以下のコマンドでローカル環境を立ち上げます。
sudo chmod -R 777 $(pwd)/mydata;
docker run -it -p 8080:8080 -v $(pwd)/mydata:/label-studio/data heartexlabs/label-studio:latest;
ブラウザでlocalhost:8080にアクセスすると以下の画面が開くため、
適当なメールアドレスとパスワードを入力します。
(ローカル実行の場合はメールアドレスの認証なども特に無いですが、忘れるとそのアカウントでログインできなくなるため気をつけてください)
ログインできたら「Create Project」をクリックします。
Project Nameなどは適当に入れます。
次にData Importでデータセットに含める画像をアップロードします。
Labeling Setupでは用途に合ったものを選択します。
今回は物体検出をしたいので、「Object Detection with Bounding Boxes」を選択します。
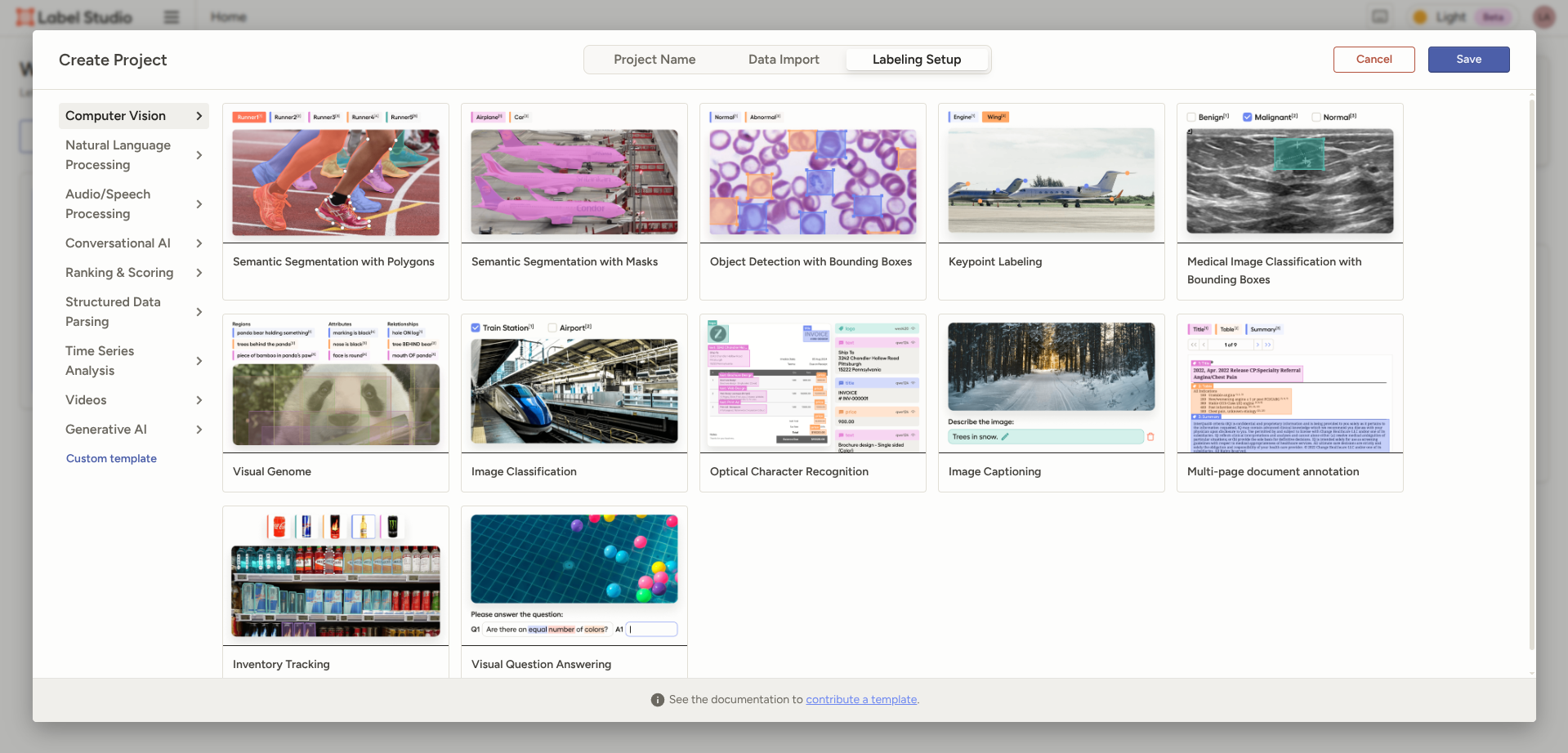
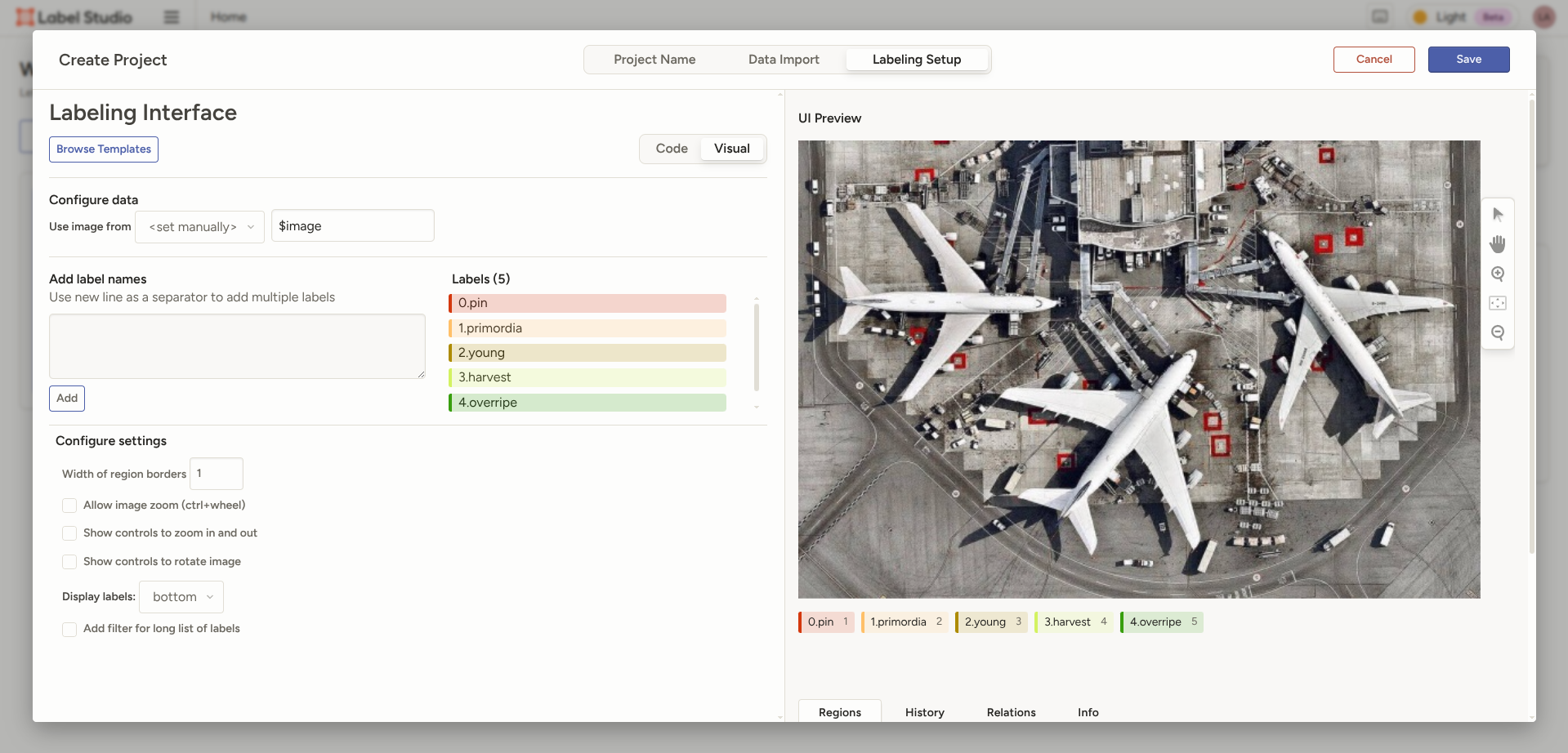
Labelsにて事前に定義したクラスを設定します。
色はわかりやすい色を適当に選びました。
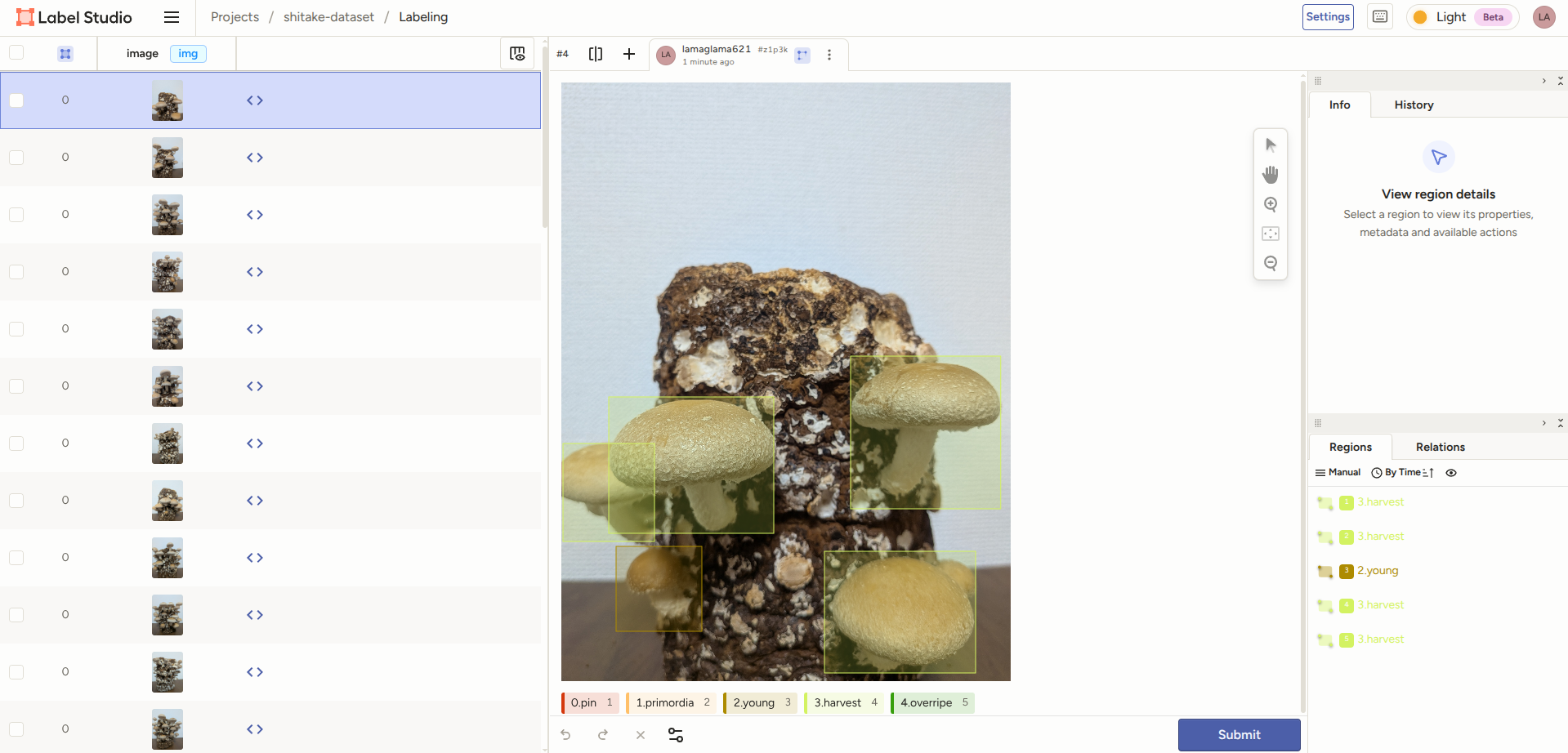
あとはアップロードしたシイタケに対して、ひたすらアノテーションしていきます。

操作としては、
定義したクラスに応じて、以下のように画像内のシイタケを四角い枠で囲うだけです。
アノテーションの作業が終わったら、画面右上のエクスポートからダウンロードします。
Export dataは「YOLO with Images」を選択しました。
2.学習用データセットを作成する
ダウンロードしたデータセットは、
デフォルトだと以下のフォルダ構成になっています。
dataset/
├── images/ # 画像データ
├── labels/ # アノテーションデータ
├── notes.json
└── classes.txt
ただ学習時にはtrain(トレーニングデータ)、val(バリデーションデータ)が必要となるため、
それに合わせて以下のようにディレクトリ構成を変更します。
dataset/
├── images/
│ ├── train/ # 全体の80% モデルの学習用
│ └── val/ # 全体の20% モデルの評価・調整用
├── labels/
│ ├── train/
│ └── val/
└── data.yaml # データセット設定情報
手動で分別するのは面倒なので、以下のスクリプトで作成します。
やっていることは画像(images)とアノテーションデータ(labels)のセットを、ランダムにtrainとvalに振り分けてコピーしているだけです。
#!/bin/bash
# 現在のディレクトリを確認
CURRENT_DIR=$(pwd)
echo "現在のディレクトリ: $CURRENT_DIR"
# 新しいディレクトリ構造を作成
mkdir -p dataset/images/train
mkdir -p dataset/images/val
mkdir -p dataset/labels/train
mkdir -p dataset/labels/val
# classes.txtとnotes.jsonをコピー
cp classes.txt dataset/
cp notes.json dataset/
# 画像の総数をカウント
TOTAL_IMAGES=$(ls images/*.jpg | wc -l)
echo "総画像数: $TOTAL_IMAGES"
# 80%をtrainに、20%をvalに
TRAIN_COUNT=$(echo "$TOTAL_IMAGES * 0.8" | bc | cut -d'.' -f1)
echo "Train: $TRAIN_COUNT 枚"
echo "Val: $(($TOTAL_IMAGES - $TRAIN_COUNT)) 枚"
# 画像をシャッフルして分割
cd images
ls *.jpg | shuf > /tmp/shuffled_images.txt
# Train用に移動
head -n $TRAIN_COUNT /tmp/shuffled_images.txt | while read img; do
basename="${img%.*}"
cp "$img" ../dataset/images/train/
cp "../labels/${basename}.txt" ../dataset/labels/train/
done
# Val用に移動
tail -n +$(($TRAIN_COUNT + 1)) /tmp/shuffled_images.txt | while read img; do
basename="${img%.*}"
cp "$img" ../dataset/images/val/
cp "../labels/${basename}.txt" ../dataset/labels/val/
done
cd ..
echo "Train: $(ls dataset/images/train/*.jpg | wc -l) 枚"
echo "Val: $(ls dataset/images/val/*.jpg | wc -l) 枚"
またデータセットの設定ファイルは以下の内容となります。
# しいたけ成長段階検知データセット
path: /home/username/project/database # データセットの絶対パス
train: images/train
val: images/val
# クラス数
nc: 5
# クラス名
names:
0: pin # ピン期 - 傘が完全に閉じている、丸い形状
1: primordia # 原基期 - 傘閉じているが伸び始め、円柱形
2: young # 若菇期 - 傘開き始め、きのこの形だが傘は小さい
3: harvest # 収穫期 - 収穫適期、しいたけの形で傘が肉厚
4: overripe # 過熟期 - 育ちすぎ、傘が平べったくなる
3.カスタムモデルを作成する
準備にだいぶ時間がかかりましたが、ようやくこれでカスタムモデルを作成できます。
作成はコマンドラインでも実行できますが、今回は色々チューニングしたいので、以下のスクリプトを使います。
from ultralytics import YOLO
import multiprocessing
import sys
from pathlib import Path
if __name__ == '__main__':
# コマンドライン引数のチェック
if len(sys.argv) != 2:
print("使用法: python train_shitake.py <データセットのパス>")
print("例: python3 train_shitake.py /home/username/project/dataset")
sys.exit(1)
# モデルディレクトリのパスを取得
model_dir = Path(sys.argv[1])
data_yaml = model_dir / 'dataset' / 'data.yaml'
print(f"モデルディレクトリ: {model_dir}")
print(f"データファイル: {data_yaml}")
# モデルをロード
model = YOLO('yolo12n.pt')
model_name = model_dir.name
results = model.train(
data=str(data_yaml),
# 基本設定
epochs=100, # エポック数
imgsz=640, # 入力画像サイズ
batch=8, # バッチサイズ
# デバイス設定
device='cpu', # 使用デバイス
workers=12, # ワーカー数
# プロジェクト設定
name=f'{model_name}_train',
project=str(model_dir / 'dataset' / 'runs' / 'detect'),
exist_ok=True, # 上書き許可
save=True, # モデル保存
patience=30, # 早期停止の待機エポック数
# データ拡張
hsv_h=0.015, # 色相の変化幅
hsv_s=0.7, # 彩度の変化幅
hsv_v=0.4, # 明度の変化幅
degrees=10, # 回転角度
translate=0.1, # 平行移動
scale=0.5, # スケール変換
fliplr=0.5, # 左右反転の確率
flipud=0.0, # 上下反転の確率
mosaic=1.0, # モザイク拡張の確率
mixup=0.0, # Mixup拡張の確率
copy_paste=0.0, # Copy-Paste拡張の確率
# パフォーマンス最適化
amp=False, # 自動混合精度
cache='ram', # データキャッシュ方法
rect=True, # 矩形トレーニング
cos_lr=True, # コサイン学習率スケジューラ
# 学習率設定
lr0=0.01, # 初期学習率
lrf=0.01, # 最終学習率
momentum=0.937, # モメンタム
weight_decay=0.0005, # 重み減衰
warmup_epochs=3.0, # ウォームアップエポック数
# 検証・保存設定
val=True, # 検証の実行
plots=True, # プロット生成
save_period=20, # モデル保存間隔
# その他
close_mosaic=10, # モザイク終了エポック
verbose=True, # 詳細表示
seed=42, # 乱数シード
deterministic=False, # 決定論的動作
single_cls=False, # 単一クラスモード
overlap_mask=True, # マスク重複許可
optimizer='SGD', # 最適化手法
fraction=1.0, # 使用データの割合
)
スクリプト実行から大体1時間ぐらいで完了して、結果は以下のとおりでした。
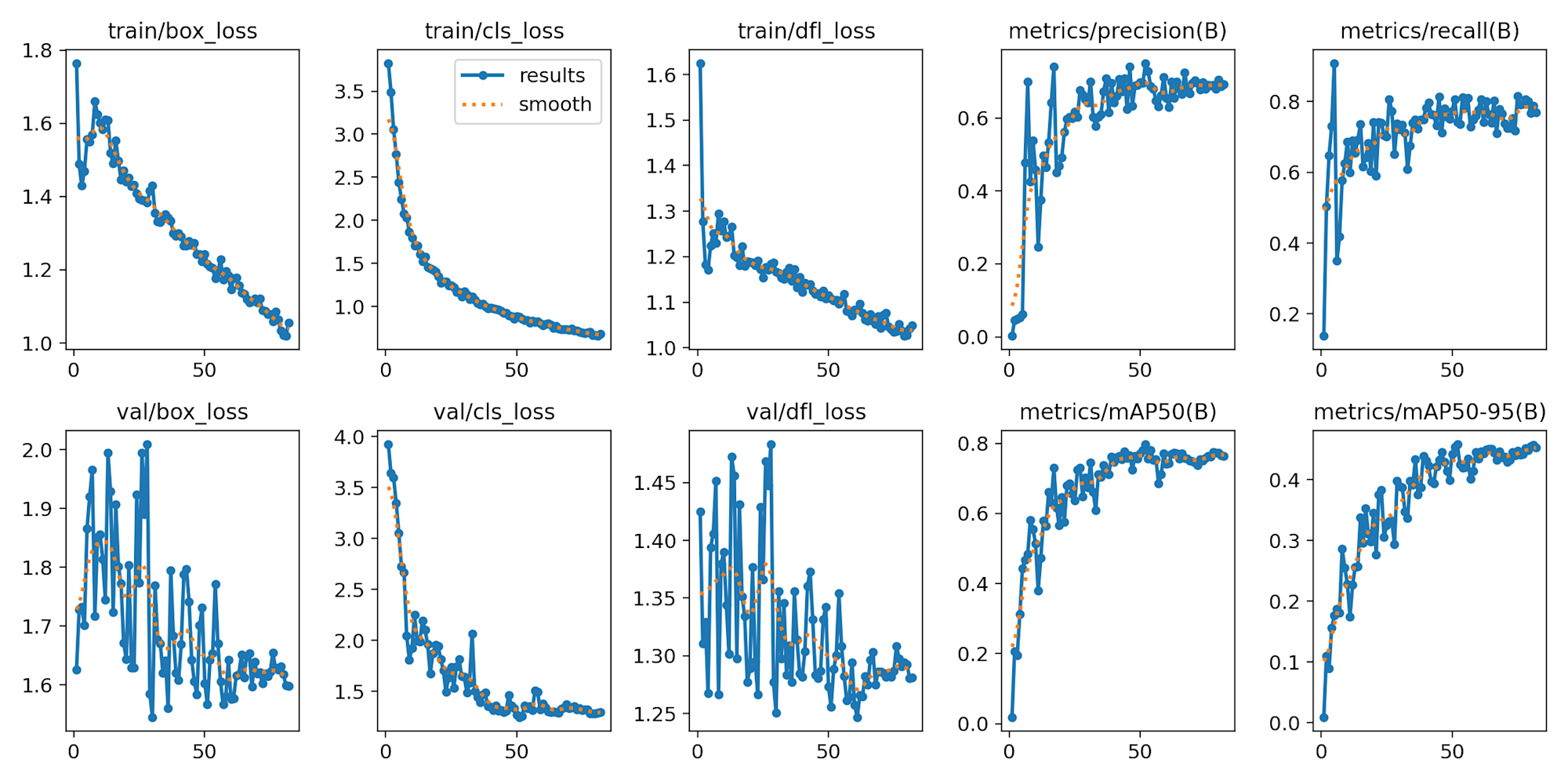
上記の各値の説明は以下ブログでしているので、気になる方はこちらをご参照ください。
シイタケを検出してみる。
では実際に作成したカスタムモデルでシイタケを検出してみます。
検出には以下のスクリプトを使用します。
from ultralytics import YOLO
import sys
if len(sys.argv) < 3:
print("usega: python predict.py <model> <image>")
print("example: python predict.py best.pt image.jpg")
sys.exit(1)
model_path = sys.argv[1]
image_path = sys.argv[2]
conf = float(sys.argv[3]) if len(sys.argv) > 3 else 0.5
# 推論実行
model = YOLO(model_path)
results = model.predict(
source=image_path,
save=True,
conf=conf,
save_txt=True,
save_conf=True,
)
結果は以下のとおりです。
こちらは学習用のデータセットに含まれていない画像ですが、いい感じに検出できていそうです。
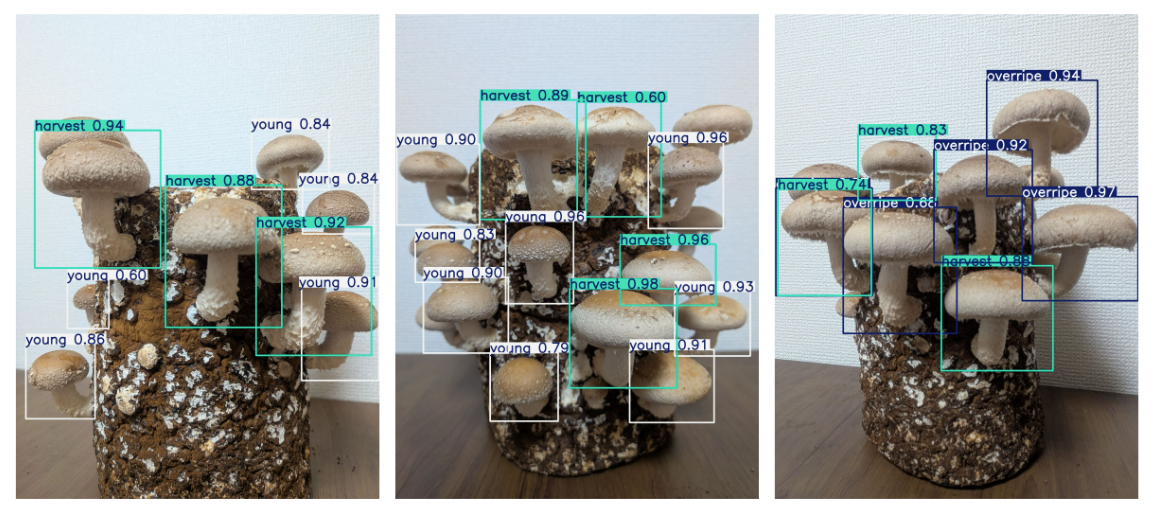
ただ若干 harvest と overripe の判定が怪しい感じなので、
このあたりはデータセットの量を増やして、さらなるファインチューニングを重ねて改善していく必要がありそうです。
さいごに
以上、「物体検出モデルでシイタケの収穫時期を自動判定するまでにやったこと。〜①カスタムモデル作成編〜」でした。
振り返ってみると意外時間がかかっており、中でもデータセット作成時のアノテーションの作業が一番大変だった記憶があります。
しかし今思えば、徹夜でひたすらシイタケの向き合ったあの時間も良い思い出になった気がします。
次回のブログでは今回作ったカスタムモデルを利用して、
シイタケを検出した動画を確認できるシステムをAWS上にデプロイする方法を解説します。