【登壇レポート】JAWS-UG大阪 re:Invent re:Cap LT大会 UFOが来たら強制終了で「Amazon Bedrock AgentCore EvaluationsでAIエージェントを評価してみよう!」というタイトルで登壇しました!
はじめに
こんにちは、ラ・ムーが大好きなコンサルティング部の神野です。
2026年1月26日(月)に開催されたJAWS-UG大阪 re:Invent re:Cap LT大会で「Amazon Bedrock AgentCore EvaluationsでAIエージェントを評価してみよう!」というタイトルで登壇しました!
今回のイベントは、re:Invent 2025の振り返りLT大会で、発表枠は1分、3分、5分から選べる形式でした。私は5分枠で発表させていただきました。UFO隊が出てきたら強制終了(早く終わりすぎてもダメ)というユニークなルールがあり、時間内に収められるかドキドキしながらの発表でした・・・!
実は去年のre:Invent 2025が初参加でした!スフィアでオズの魔法使いも観たこと、飛行機の中でイヤホンを落としたけど親切な外国人が拾ってくれたことが良い思い出です。
そんな中で発表されたAmazon Bedrock AgentCore Evaluationsが個人的に話したく、今回のLTで紹介させていただきました。
登壇資料
Amazon Bedrock AgentCoreとは
まず、Amazon Bedrock AgentCore Evaluationsの話をする前に、Amazon Bedrock AgentCoreについて軽く触れておきます。
Amazon Bedrock AgentCoreは、AIエージェントを簡単に作ることができるマネージドサービスです。

例えばスーパーマーケットのナレッジを持ったAIエージェントを作る場合、RuntimeでAIエージェントをホスティングして、下記のような構成で実現できます。
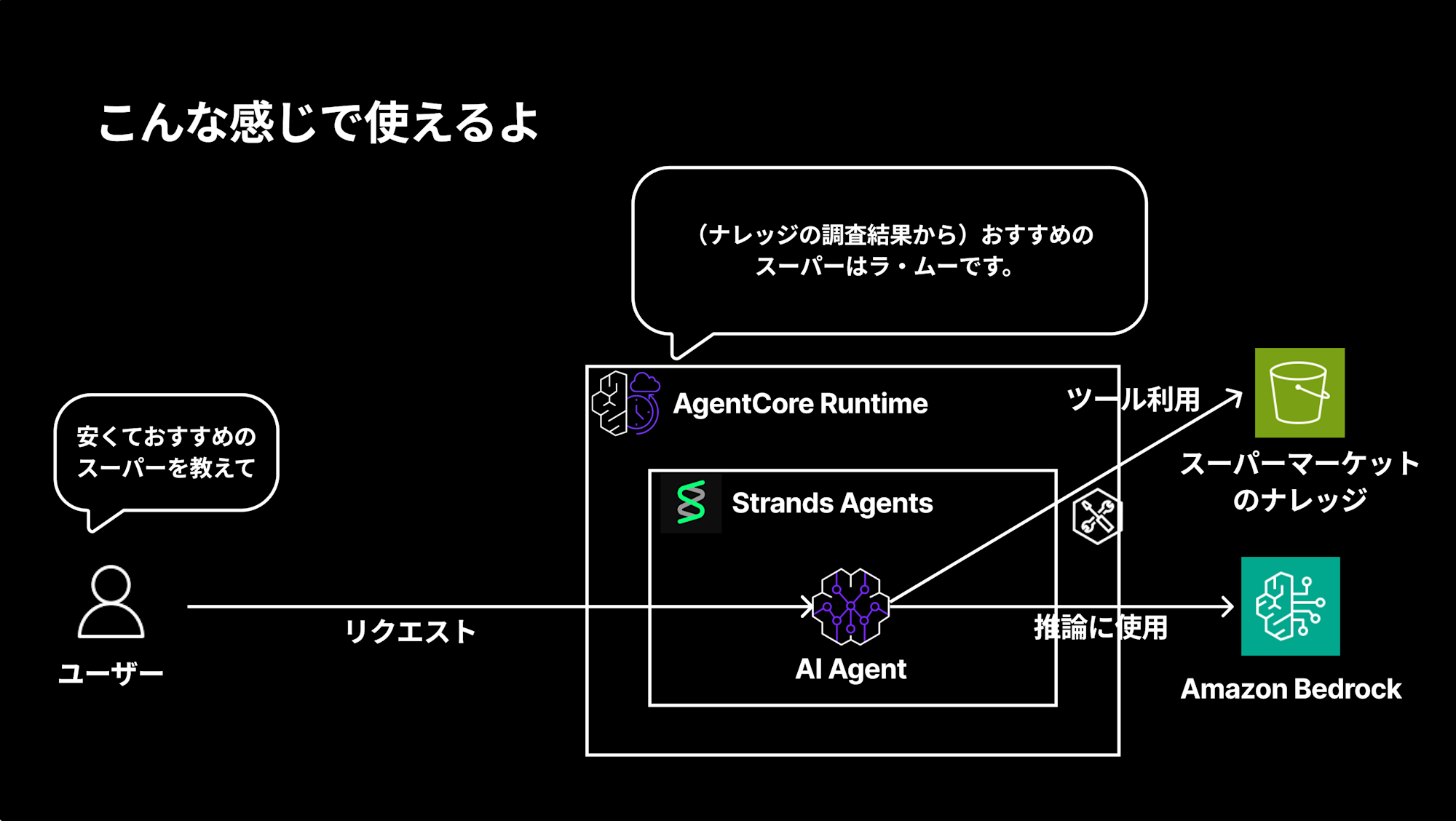
「安くておすすめのスーパーを教えて」という質問に対して、
ツールを利用してナレッジの調査結果から「おすすめのスーパーはラ・ムーです。」と回答してくれるイメージですね。
作ったAIエージェントを評価していますか?
AIエージェントを作ったはいいものの、皆さんは評価をしていますか?
やっていない・・・難しそう・・・でも適切に動いているか評価して作ったAIエージェントを改善したい・・・
やはり一度作っておしまいではなく、分析して継続的にアップデートをしていきたいですよね。
そんな悩みを持っている方に朗報です!
re:Invent 2025で嬉しいアップデートがありました。それがAmazon Bedrock AgentCore Evaluations(Preview)です。
Amazon Bedrock AgentCore Evaluations
Amazon Bedrock AgentCore Evaluationsは、開発・運用しているAIエージェントの評価がコンソール上からできるようになった機能です。
ダッシュボードからわかりやすく確認でき、LLMを使った評価(LLM-as-a-Judge)となります。
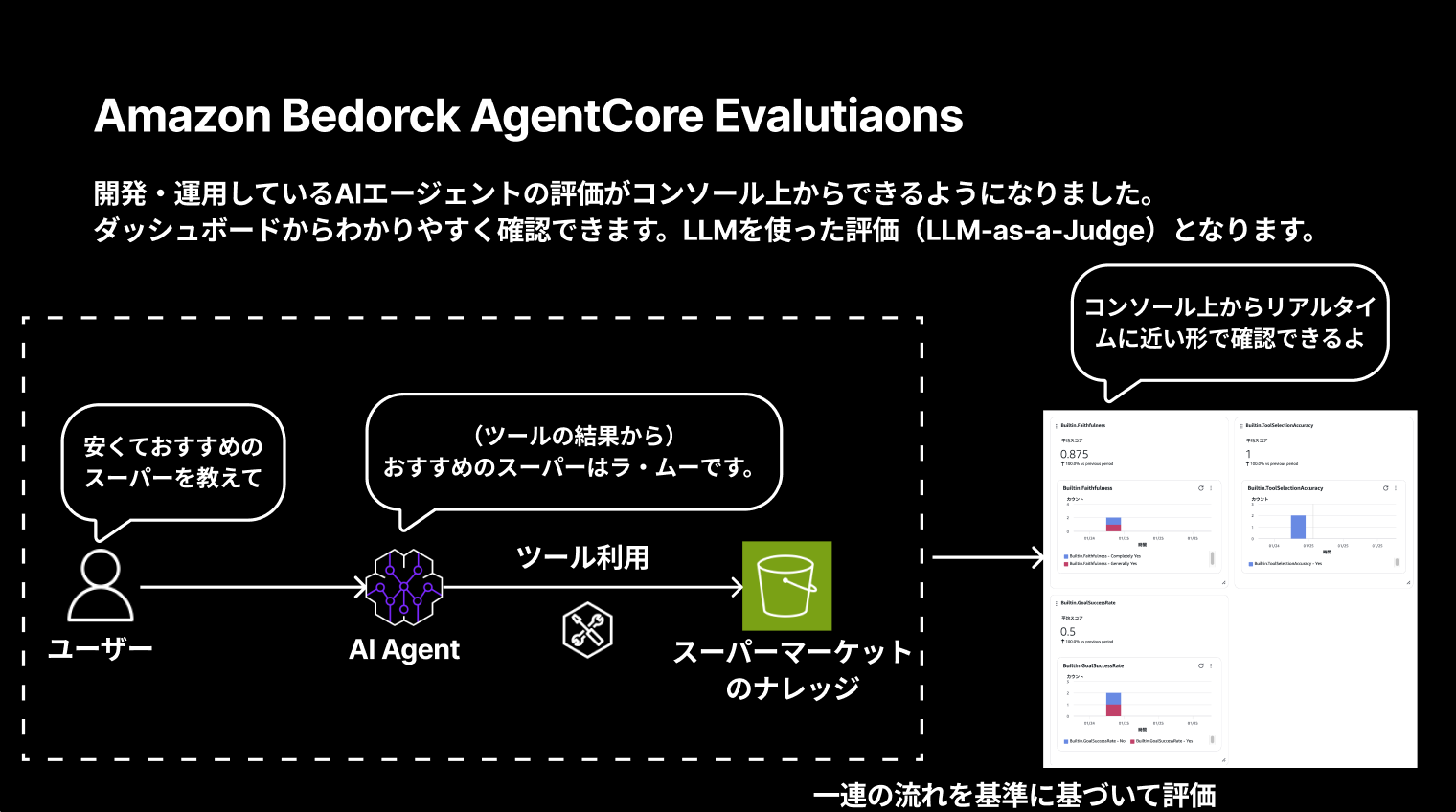
ユーザーとAIエージェントのやり取り、ツール利用の一連の流れを基準に基づいて評価し、コンソール上からリアルタイムに近い形で確認できるのは嬉しいですね!
評価方法
ログをベースに評価を行うため、稼働中のエージェントには影響がなくリアルタイムに近い形でコンソールで評価可能です。
評価方法は2種類あります。
| 評価方法 | 概要 |
|---|---|
| Online Evaluation | リアルタイムでエージェント品質を継続的にモニタリング可能、サンプリング率やフィルタ条件を指定できる。評価結果はObservabilityのダッシュボードからも確認可能 |
| On-demand evaluation | 特定のセッションIDなどを指定してオンデマンドで評価可能。Starter Toolkitで簡単に実現可能 |
どちらも運用中のエージェントには影響しないのは嬉しいポイントですね。
今回はOnline Evaluationを実際に試してみます!
On-demand evaluationは実際に試したブログがあるのでこちらも必要に応じてご参照ください!
実際にやってみる
前提
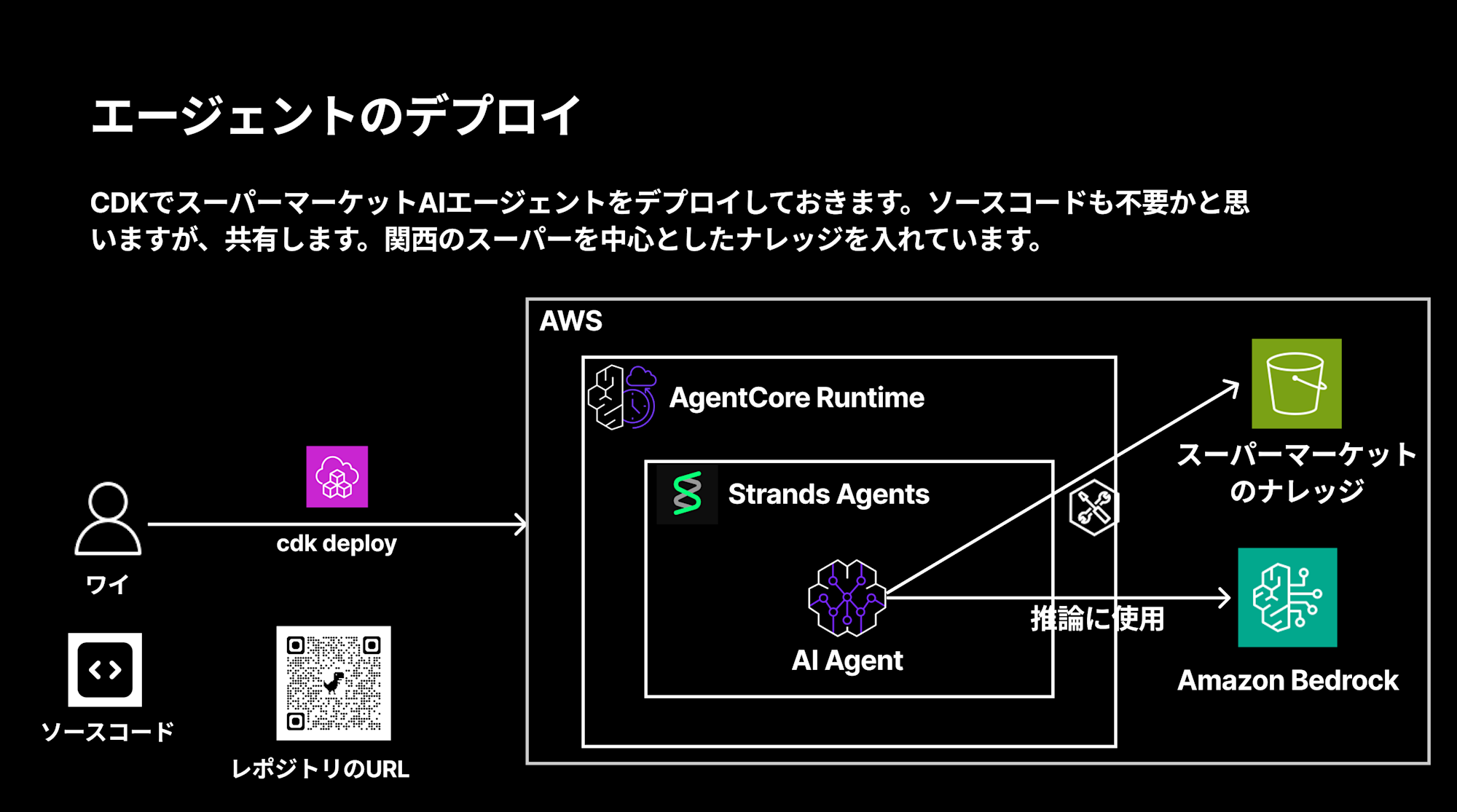
今回使用するソースコードは下記リポジトリで公開しています。
関西のスーパーマーケットを中心としたナレッジを持つAIエージェントをCDKでデプロイする構成となっています。
エージェントのデプロイ
まずはAIエージェントをデプロイしていきます。
git clone https://github.com/yuu551/supermarket-agent-cdk.git
cd supermarket-agent-cdk
必要な依存関係をインストールして、CDKでデプロイします。
pnpm install
pnpm dlx cdk deploy
デプロイが完了すると、Amazon Bedrock AgentCore上にスーパーマーケットAIエージェントが構築されます。
構成としては下記のようになります。
スーパーマーケットのナレッジドキュメントはアップロードされて、ナレッジベースも作成されているのですが同期がされていないので、手動で同期します。
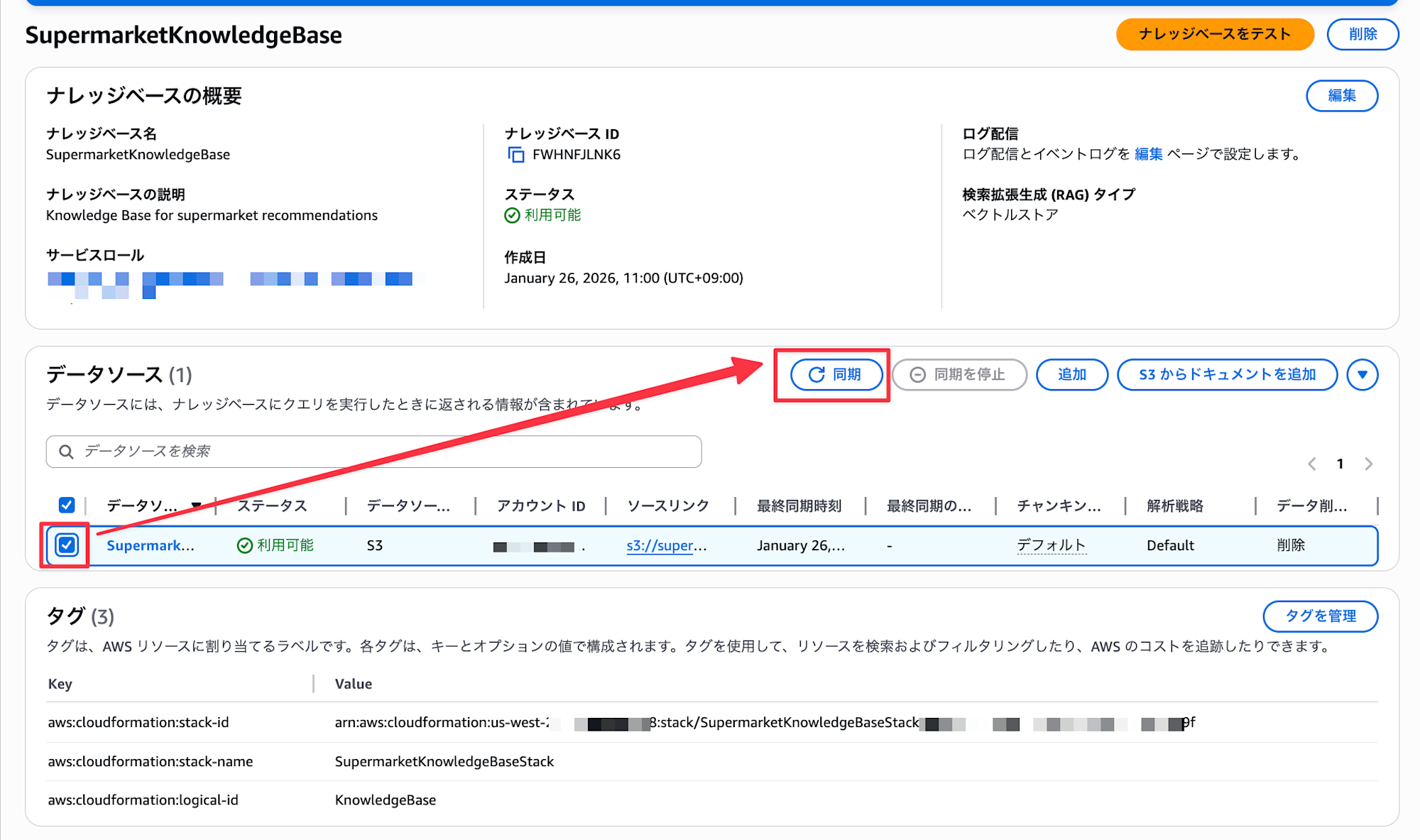
コンソール上から評価設定する
Amazon Bedrock AgentCoreのコンソールから設定を行います。今回は下記3つを評価指標として選択しました。
| 評価指標 | 概要 |
|---|---|
| Faithfulness(忠実性) | 回答の情報が提供されたコンテキスト/ソースによってサポートされているかを評価 |
| Goal success rate(目標達成率) | 会話がユーザーの目標を正常に達成したかを評価 |
| Tool selection accuracy(ツール選択の正確性) | エージェントがタスクに適切なツールを選択したかを評価 |
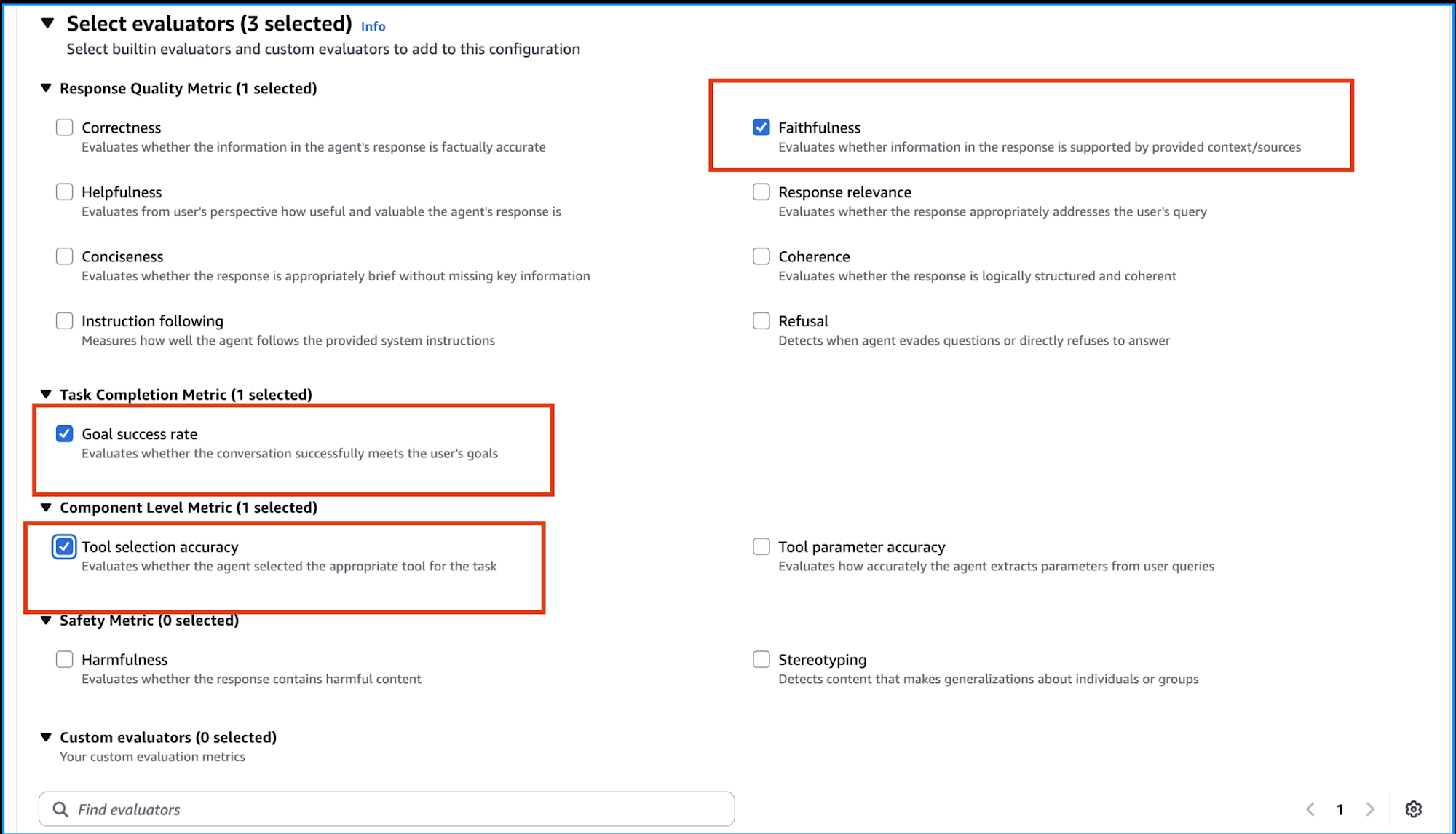
コンソールのSelect evaluatorsセクションから、上記3つにチェックを入れて設定を保存すればOKです!
AIエージェントに質問してみる
設定が完了したら、実際にAIエージェントに質問してみます。
コンソール上からエージェントサンドボックスからテスト可能です。
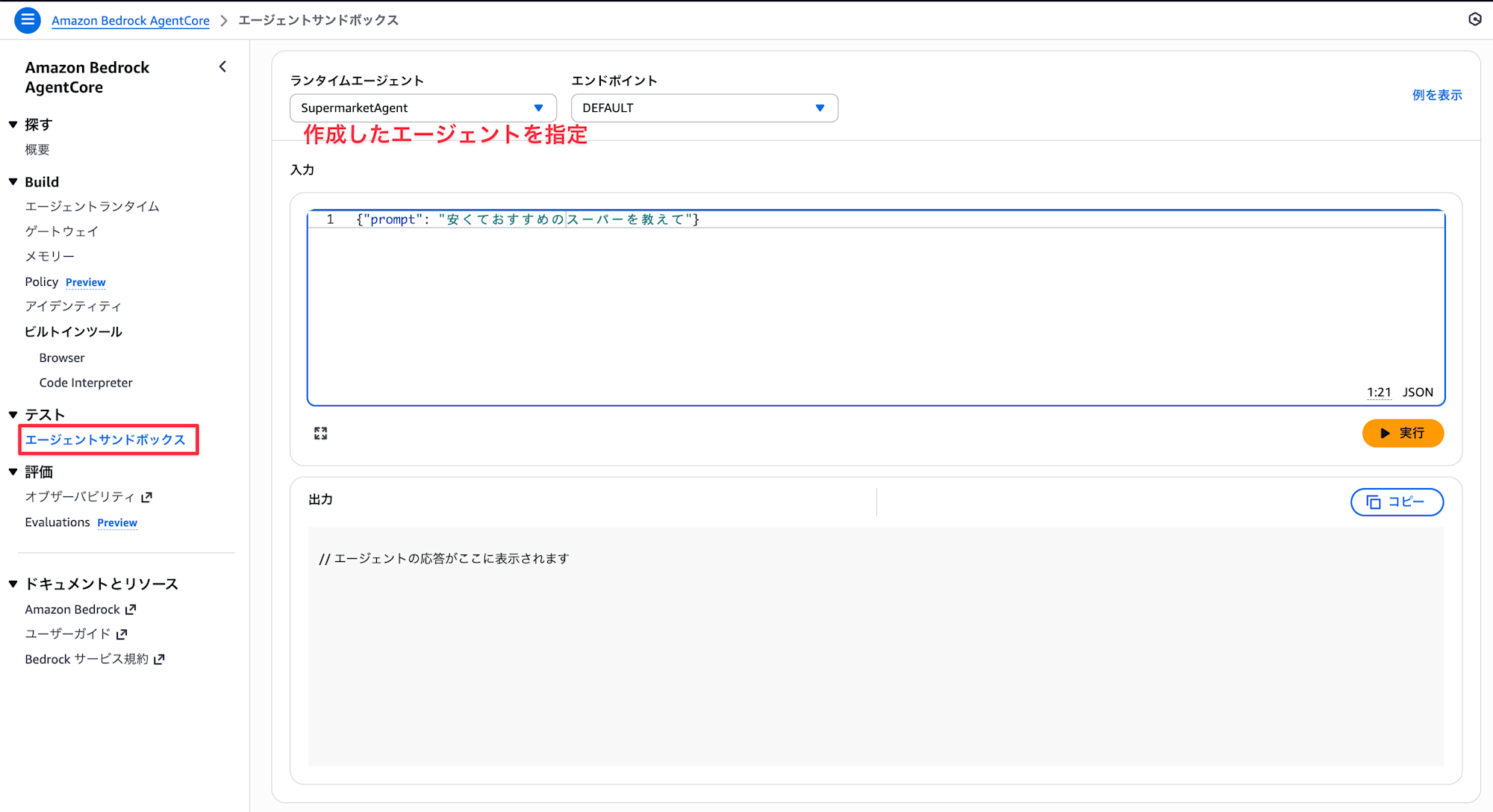
正解できそうな質問と不正解になりそうな質問を投げてみました。
質問1:安くておすすめのスーパーを教えて
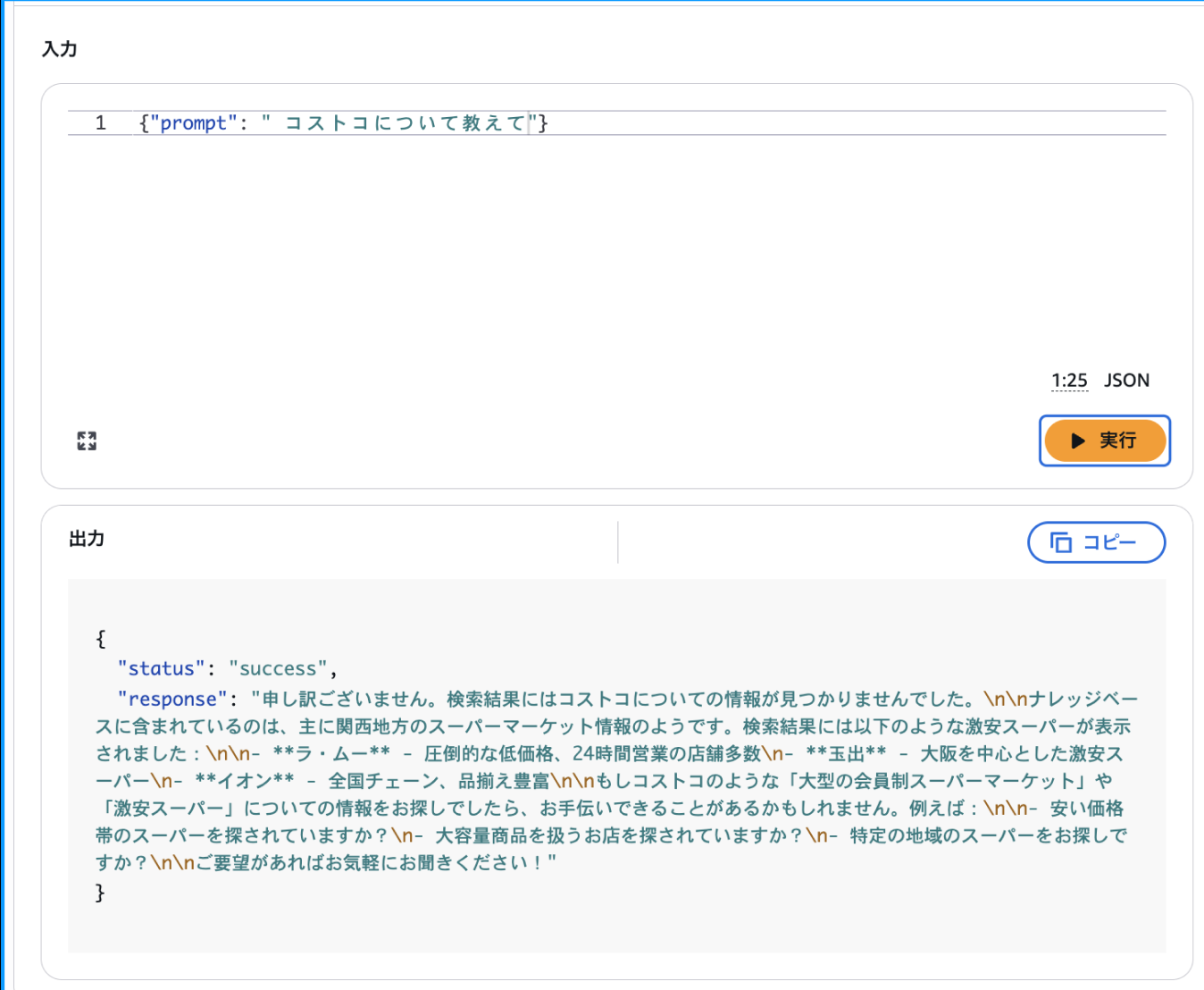
質問2:コストコについて教えて
質問1はナレッジに情報があるので回答できますが、質問2のコストコについてはナレッジに情報が入っていないので回答できないはずですね。
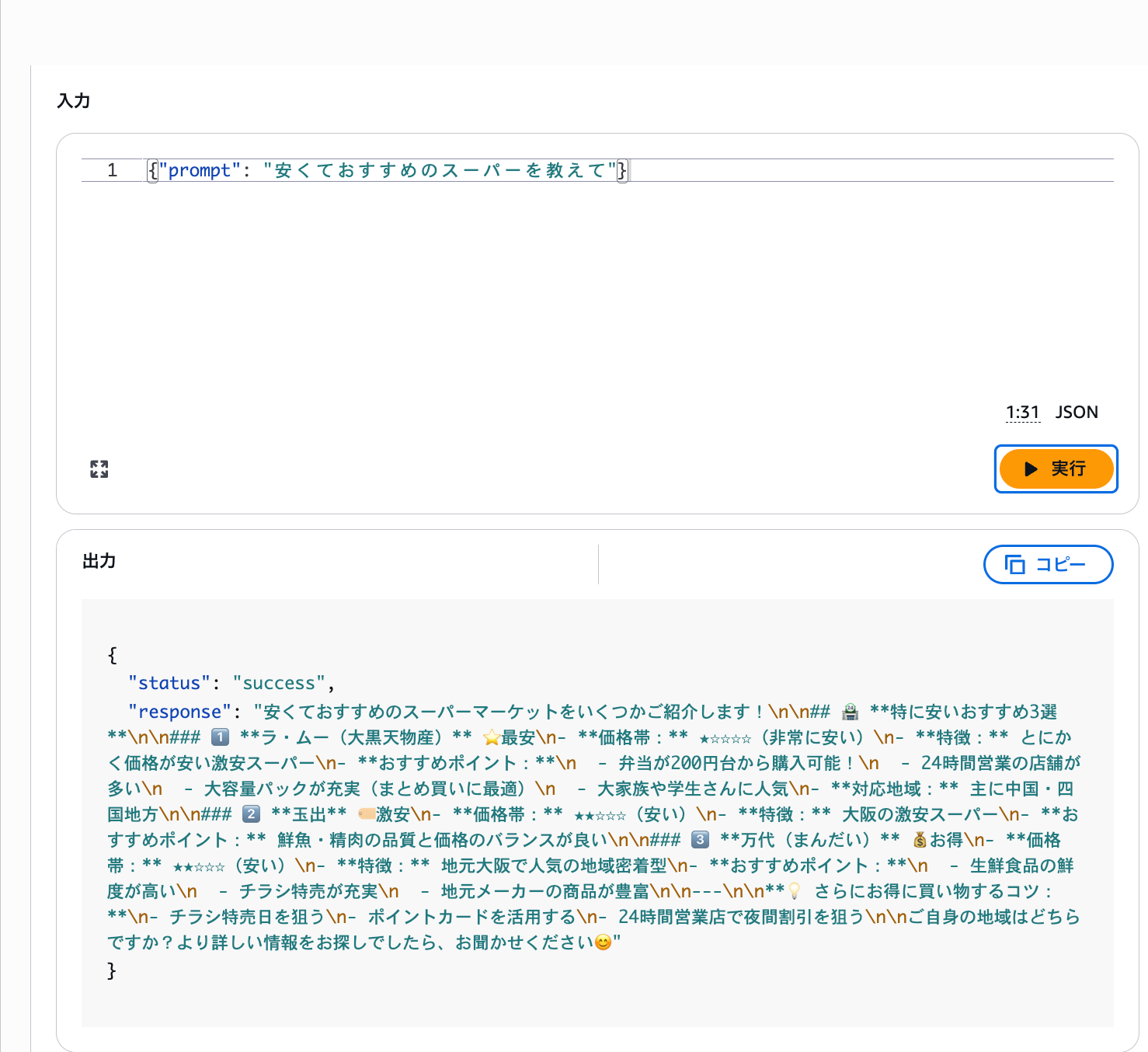
しっかりとナレッジに基づくおすすめのスーパーを教えてくれていますね。
質問2の実際の回答を見てみると、コストコの質問は「申し訳ございません。検索結果にはコストコについての情報が見つかりませんでした。」といった形で回答できていませんでした。想定通りですね。
評価結果を見てみる
いくつかの質問に対する評価サマリーはGen AI Observabilityダッシュボードから確認できます。ダッシュボードを見ると、各評価指標の平均スコアが表示されています。
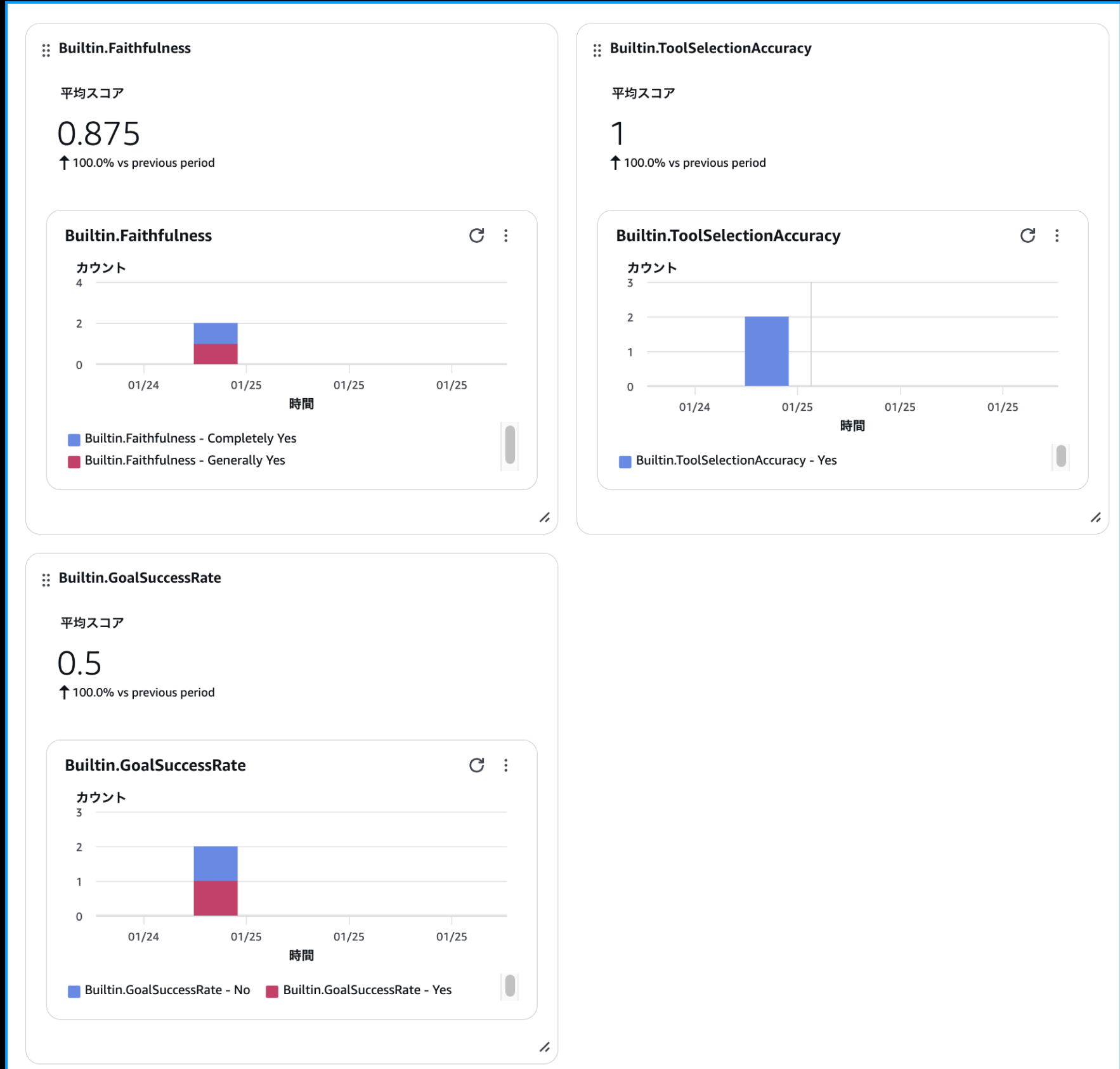
どれぐらい基準を満たしているかパッとわかるのは嬉しいですね!
評価結果を深掘りしてみる
もう少しブレイクダウンして、コストコについての質問がどんな風に評価されているのか具体的に見てみます。CloudWatch Logsに評価結果のログが格納されているので、GoalSuccessRateを例に見てみます。
設定画面にリンクがあるのでそこからロググループを確認できます。
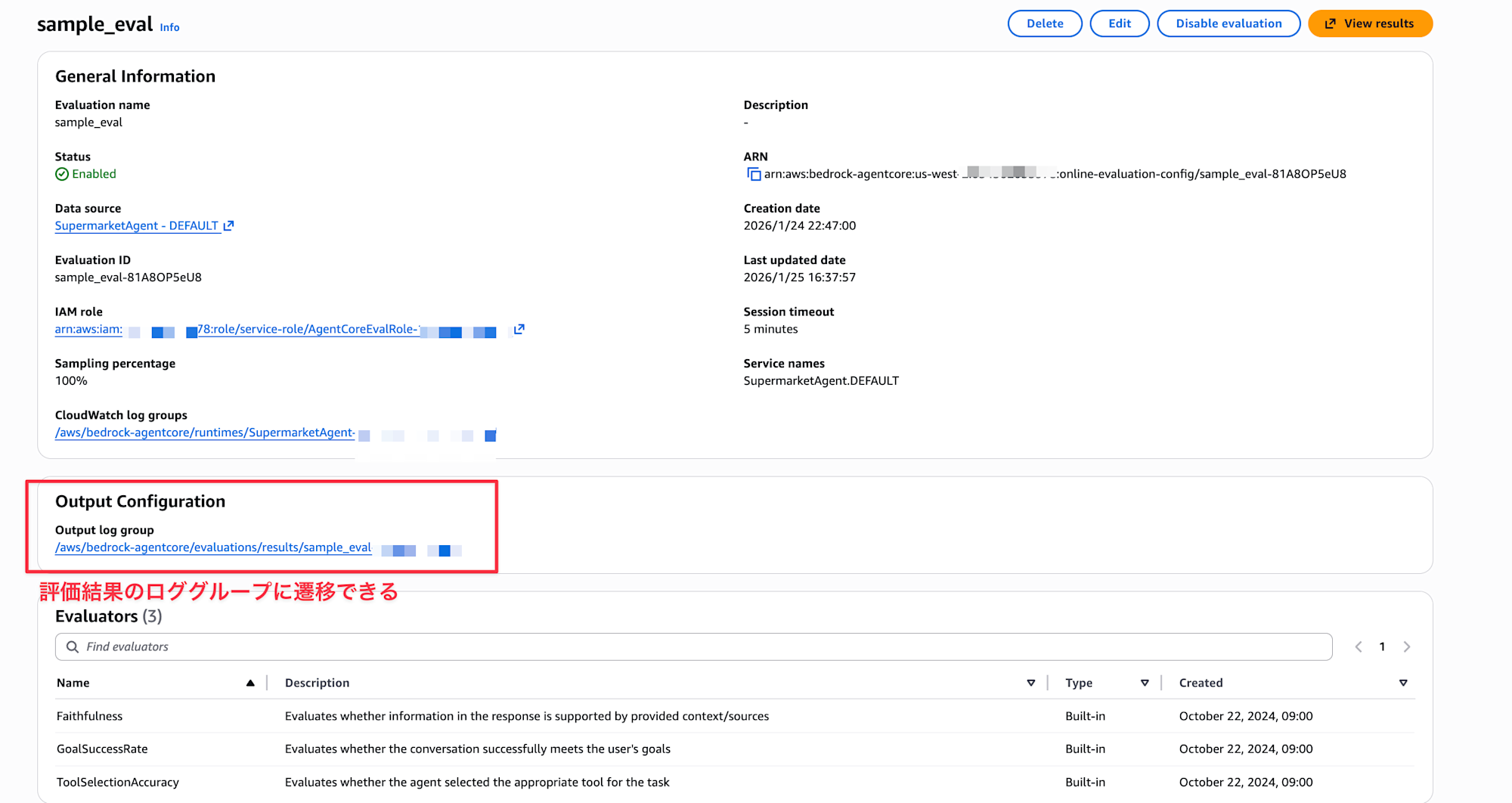
ログは下記のように記録されていました。

評価結果のログを日本語に訳すと下記のようになります。
ユーザーは日本語でコストコ(Costco)について質問しました。
AIアシスタントは適切に「retrieve」ツールを使用し、ナレッジベースからコストコに関する情報を検索しました。
検索の結果、スコア0.4以上のドキュメントが5件ヒットしましたが、その中にコストコに関する具体的な情報を含むものはありませんでした。代わりに、関西地方の様々なスーパーマーケット(ラ・ムー、玉出、阪急オアシス、ライフ、イオン、コーナン)に関する情報が表示されました。
AIアシスタントはツールの出力を正しく解釈し、ナレッジベース内にコストコに関する直接的な情報が見つからなかったことを、ユーザーに誠実に伝えました。
ユーザーの目的はコストコについて知ることでしたが、ツールの出力で確認された通りナレッジベースにその情報が含まれていないため、アシスタントはその要求を直接満たすことはできません。
アシスタントは、透明性を保ちつつ代替案を提示することで、この制限に対してプロフェッショナルに対応しました。
この質問にはGoalSuccessRateで0点がついています。
コストコについて教えるっていう目標は達成できなかったですもんね。この場合はシンプルにコストコのナレッジを追加したいですね。
一方、Faithfulness(忠実性)は1点がついています。

ユーザーは「コストコ」について質問しました。アシスタントは「コストコ」というキーワードで検索を実行しましたが、その結果返ってきたのは、関西地方の様々なスーパーマーケット(ラ・ムー、ライフ、イオン、玉出、コーナンなど)に関する5件の情報であり、コストコに関する情報は一切含まれていませんでした。
アシスタントの回答は、以下の点においてこの状況を正確に反映しています。
検索結果にコストコに関する直接的な情報が含まれていなかったことを認めている。
実際に見つかった情報(ラ・ムー、玉出、阪急オアシス、ライフ、イオンといった関西のスーパーマーケット情報)を正しく特定している。
現在の知識ベースでは、コストコの情報が利用できないことを明示している。
コストコに関する具体的な質問があれば、改めてサポートする旨を提案している。
アシスタントの回答は、これまでの会話の経緯に完全に忠実です。
コストコについて情報を捏造することはなく、検索ツールの出力を正しく伝え、利用可能なデータの限界を適切に認めています。アシスタントの回答と会話履歴の間に矛盾はありません。
あくまで忠実性って観点で見てクリアしているよって感じですね。
評価結果から得られる知見
点数だけではなく、AIが何をもって判断したかを確認するのも大事ですね・・・!!
人間の評価基準とはギャップがある可能性もあります。必要に応じて目視でのチェックも組み合わせて判断しましょう!分析してボトルネックを特定してAIエージェントの動きをより良くしていきましょう!
補足:Strands Agents Eval機能
Strands AgentsでもEval機能が実装されているので、
AgentCore Evaluationsよりも凝った評価をしたいケースで試してみるのもおすすめします!
下記みたいに実装します。
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import OutputEvaluator
# テストケース定義
test_cases = [
Case(name="knowledge-1", input="フランスの首都は?", expected_output="パリ"),
Case(name="math-1", input="5 × 12 × 1.08 は?", expected_output="64.8"),
Case(
name="knowledge-2",
input="神野雄大は誰?",
expected_output="知らないです",
),
]
# タスク関数
def get_response(case: Case) -> str:
agent = Agent(system_prompt="正確な情報を提供するアシスタント")
return str(agent(case.input))
# LLM Judge評価器
evaluator = OutputEvaluator(rubric="正確性と完全性を1.0-0.0で評価")
# テスト実行
experiment = Experiment(cases=test_cases, evaluators=[evaluator])
reports = experiment.run_evaluations(get_response)
reports[0].run_display()
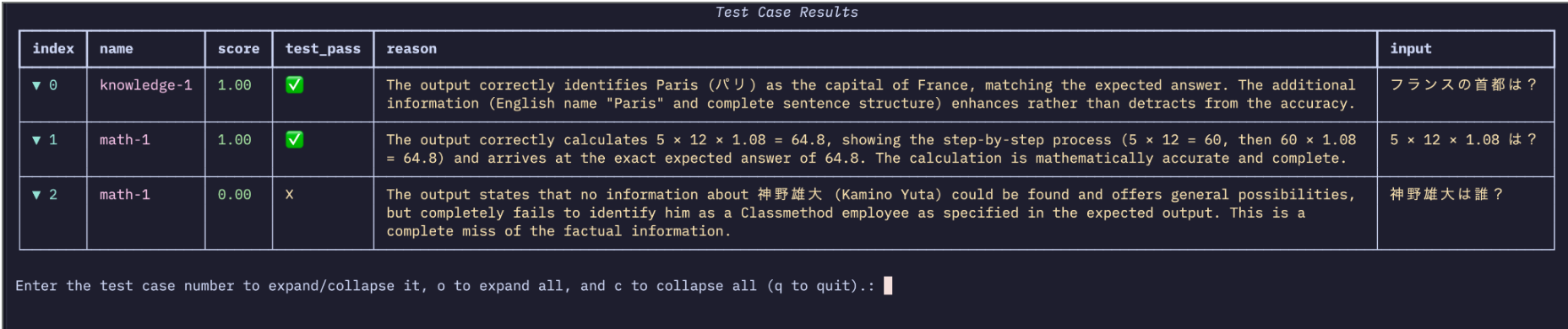
実行するとテストコードみたいに評価結果が表示されてわかりやすいです。
おわりに
AIエージェントは作って終わりではなく、フィードバックや評価を重ねて改善を積み重ねてより理想の挙動に近づけていく上でかなり嬉しいアップデートですよね!
Evaluationsを活用して、作ったAIエージェントをどんどん改善していきましょう!
今回のJAWS-UG大阪 re:Invent re:Cap LT大会、7秒残しで終わってギリギリ少し早く終わりUFO隊に連れ去れられて、終わりましたw
後2秒・・・悔しい・・・
運営の皆さん、聞いていただいた皆さん、ありがとうございました!
もしこの発表がきっかけでAgentCoreについてもっと知りたくなった場合は下記記事も読んでいただけると、とっても嬉しいです!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!