【登壇レポート】 JAWS-UG熊本で「5分で紹介する生成AIエージェントとAmazon Bedrock Agents」と題してLT登壇しました! #jawsug #jawsugkmmt
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
みなさん、こんにちは!
福岡オフィスの青柳です。
2025年1月25日に熊本市内で開催された「JAWS-UG熊本」に参加・LT登壇してきました。
今回の勉強会は「JAWS-UGくまもと リブート。」と題して、約4年ぶりの熊本での開催となりました。
久しぶりの開催ということで皆さんの注目も高かったのか、地元熊本を始め、九州各地、全国から多数の参加があり、たいへん盛り上がった勉強会となりました。
登壇資料
昨今注目を集めている「生成AIエージェント」そして「Amazon Bedrock Agents」について、5分間に「ぎゅっ!」と凝縮して紹介することにチャレンジしました。
これまでの生成AIの使われ方
2022年後半にOpenAI社が「ChatGPT」を公開したことを契機として「生成AIブーム」が到来し、2023年にはAWSが「Amazon Bedrock」を公開 (4月にプレビュー、9月にGA) するなど、生成AIが広く使われるようになりました。
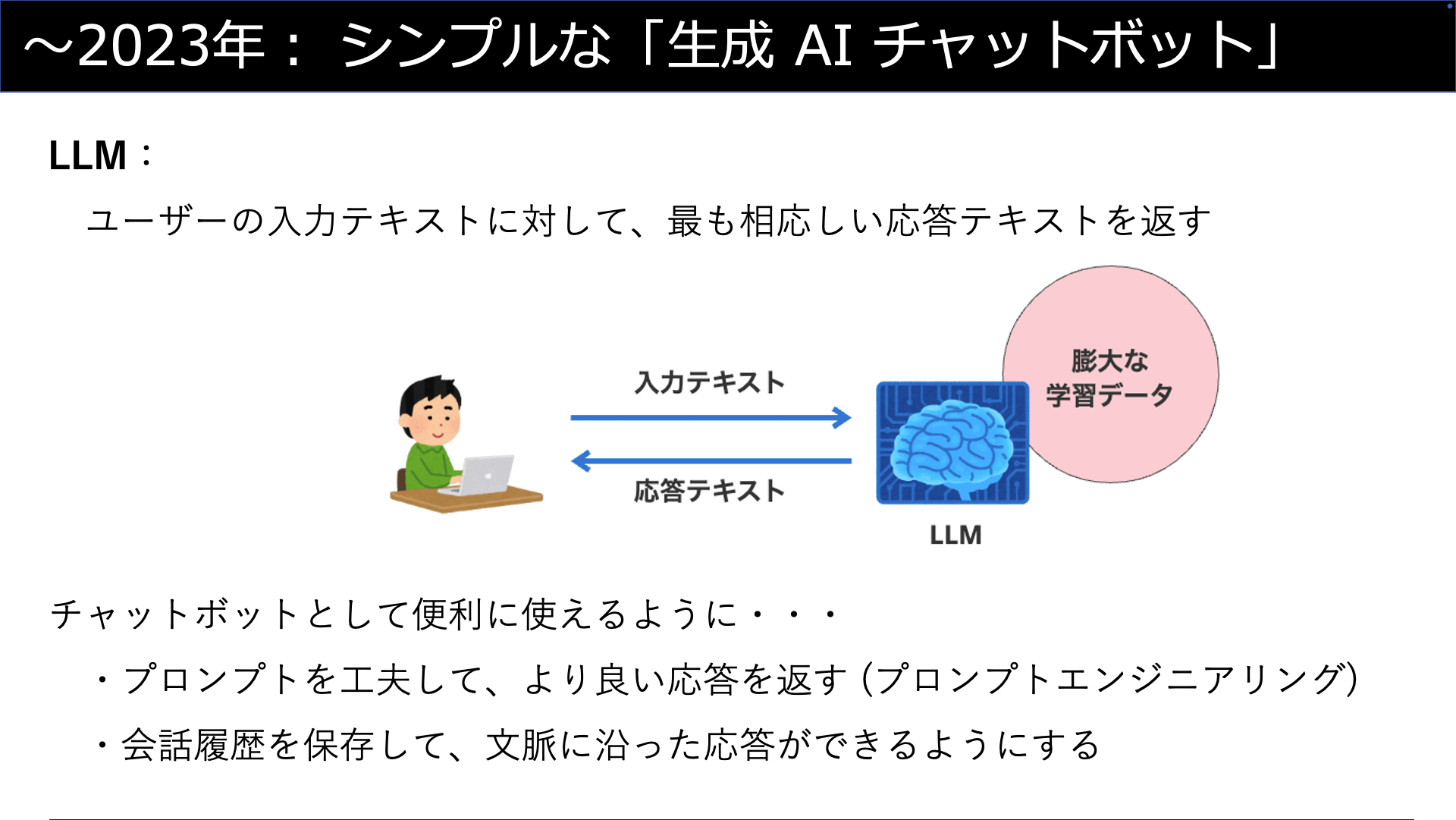
生成AIの登場当初は、生成AIとチャットでやり取りできる「生成AIチャットボット」としての利用が主でした。(今でもそうかもしれない)
生成AIの「頭脳」とも言える「LLM」(大規模言語モデル) は、それ自体は「人間が問い掛けた文章に対して、最も相応しいと考えられる応答テキストを返す」という単純な動作をします。
チャットボットとして便利に使えるように「プロンプトエンジニアリング」の手法が開発されたり、本来はステートレス (記憶を持たない) な動作をするLLMに「会話履歴」の保存・参照ができる仕組みを外部から追加する、などの改良が為されてきました。
昨年2024年の生成AIにおけるトレンドは、やはり「RAG」(Retrieval-Argumented Generation; 検索拡張生成) でしょう。
最初の「RAG」に関する論文は2022年に発表されていますが、多くの方々がRAGに注目し始めたのは2023年の後半から2024年になってからではないかと思います。
(以下、RAGについて「もう知ってる!」という方も多いでしょうが、一応解説を・・・)
生成AI (LLM) は、世界中の (インターネット中の) 膨大な情報を学習させることによって、一人の人間の知識を上回る知識量で質問に回答してくれます。
しかし、根本的にLLMには「学習に使用したデータに含まれない情報については、回答できない」という制約があります。
例えば、2023年にリリースされたLLMの特定モデルは、2024年以降の新しい情報に関する知識を持ちません。
また、企業の社内データなどの非公開情報 (LLMが学習のために参照することができない情報) に関する知識も当然持ちません。
そのような「LLMが知らない情報」について質問された場合、LLMは諦めて「知らない」と回答するか、あるいは、頑張って回答しようとした挙句に「事実っぽく聞こえるが全く正しくない回答」を返してしまいます。(後者の挙動を「ハルシネーション」と言います)
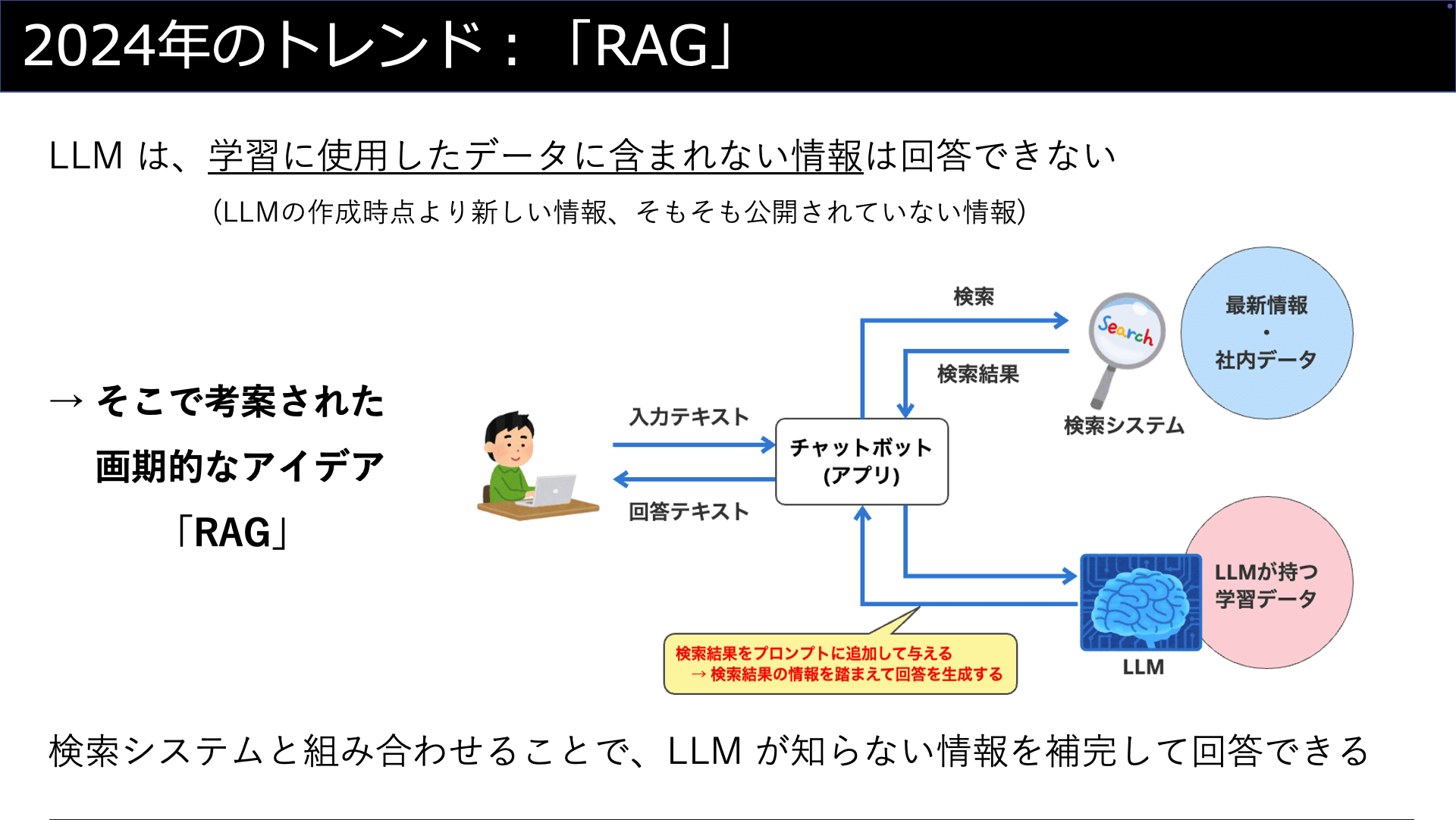
そこで考案されたアイデアが「RAG」です。
RAGは、生成AIと「検索」システムと組み合わせることにより、LLMが知らない情報を補完して回答できるようにする仕組みです。
- STEP 1: 人間が質問をする
- STEP 2: 質問を生成AIが処理する前に、まず「検索システム」で情報を探す
- STEP 3: LLMに対して、「質問内容」に加えて「参考情報」として「検索結果」をプロンプトとして与える
- STEP 4: LLMは検索結果の情報を踏まえて回答を生成することができる
2024年は、「社内ナレッジを使ったQ&Aチャットボットを作りたい」「自社の業務やサービスに即した回答をしてくれるチャットボットが欲しい」などの要求に対して、RAGが使われる場面がかなり多く見られました。
生成AIエージェント「ブーム」到来
では、今年2025年に生成AIのトレンドとなる技術は何でしょうか・・・?

生成AIに携わる多くの方が「生成AIエージェント」だと答えるでしょう。

(お待たせしました、ここでようやく「エージェント」についての解説です)
2023年にブームとなった「シンプルな生成AIチャットボット」、2024年にブームとなった「RAG (を備えたチャットボット)」は、誤解を恐れずに言えば すごく賢い「検索サービス」「文書生成サービス」 に過ぎません。
これらの従来の生成AIの利用法は「人間の代わりに調べ物をして、整った文章にまとめてくれる」「お題やテーマを与えると、意図に沿った文章を提示してくれる」といった働きをしてくれて、仕事の生産性を大幅に向上してくれます。
ただ、人間が行う実際の仕事は、もっと複雑なタスクの組み合わせによる仕事がほとんどです。
これらの利用法は、そのような複雑なタスクの「一部分」をこなすために使われる「道具」であり、タスクの組み立てや順序などは人間が自ら考えて行う必要があります。
「生成AIエージェント」は、そのような「複雑なタスク」にまで踏み込んで人間の代わりに働いてくれるものです。
生成AIエージェントには、複雑なタスクを遂行するために、次の能力が与えられます:
- 自律的に考えて、人間と対話したり、次に行うことを決めるための能力 (オーケストレーション)
- 人間の代わりにタスクをこなすための「手」 (ツール、あるいは「ファンクション」等) (※1)
次以降のページでは、これらの「能力」について解説します。
(※1) 各社の実装によって「Tool」「Function」など呼ばれ方が異なります
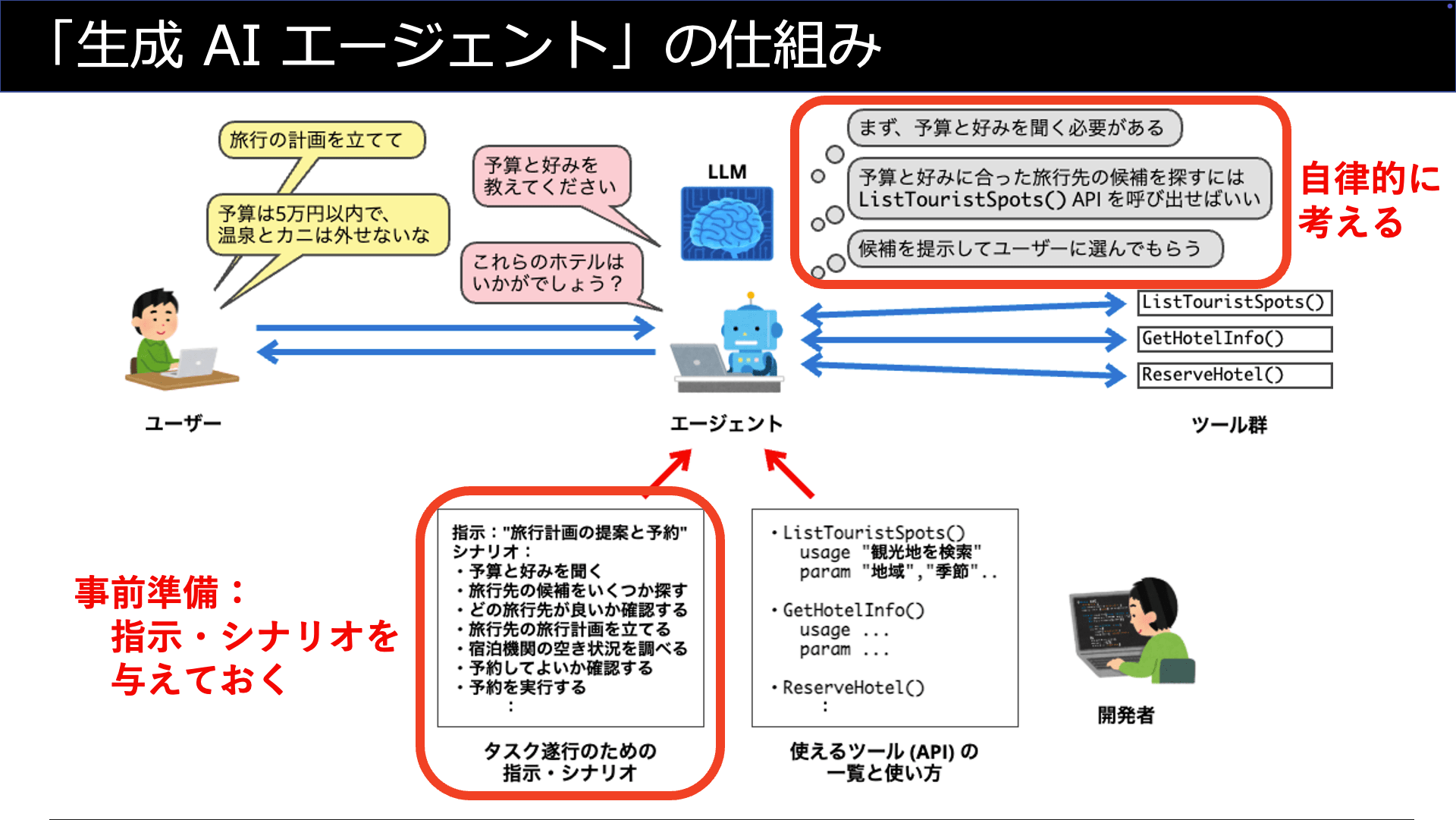
ここでは「旅行のプランを立てたりホテル予約をしてくれるエージェント」を考えてみます。
生成AIエージェントは、プランを立てるために必要な情報をユーザーから聞き出す必要がありますし、聞き出した情報に基づいてプランを立てるために調べ物をする必要があります。
なおかつ、ユーザーとの対話は自然な会話の中で行うことが期待されますし、調べ物やホテル予約の実行はユーザーが明示的に手順を与える訳ではありません。
つまり、生成AIはユーザーが明確な指示を出したり適切な順序を示さなくとも、自律的に考えてタスクをこなす必要があります。
これを実現する生成AIエージェントの能力が「オーケストレーション」です。
人間が意図した通りにオーケストレーションを行わせるために、予め「タスク遂行のための指示・シナリオ」を与えておく必要があります。
ポイントは、指示やシナリオはプログラムコードのような形ではなく、人間に指示を与える時のような文章 (テキスト) で与えるという点です。
この指示・シナリオをLLMは解釈して、自律的に考えて「次に何を行うべきか」を決定します。決定に基づいて、必要となる「ユーザーとの対話」や「(後述する) ツールの実行」を行うのです。
生成AI (LLM) は、膨大な情報に基づいて「質問に対する回答を提示する」ことは得意です。
また、人間とテキスト (場合によっては音声) でやり取りをすることができます。
つまり、生成AIは「頭脳」と「耳 (または目)」と「口」を持っている、と言うことができます。
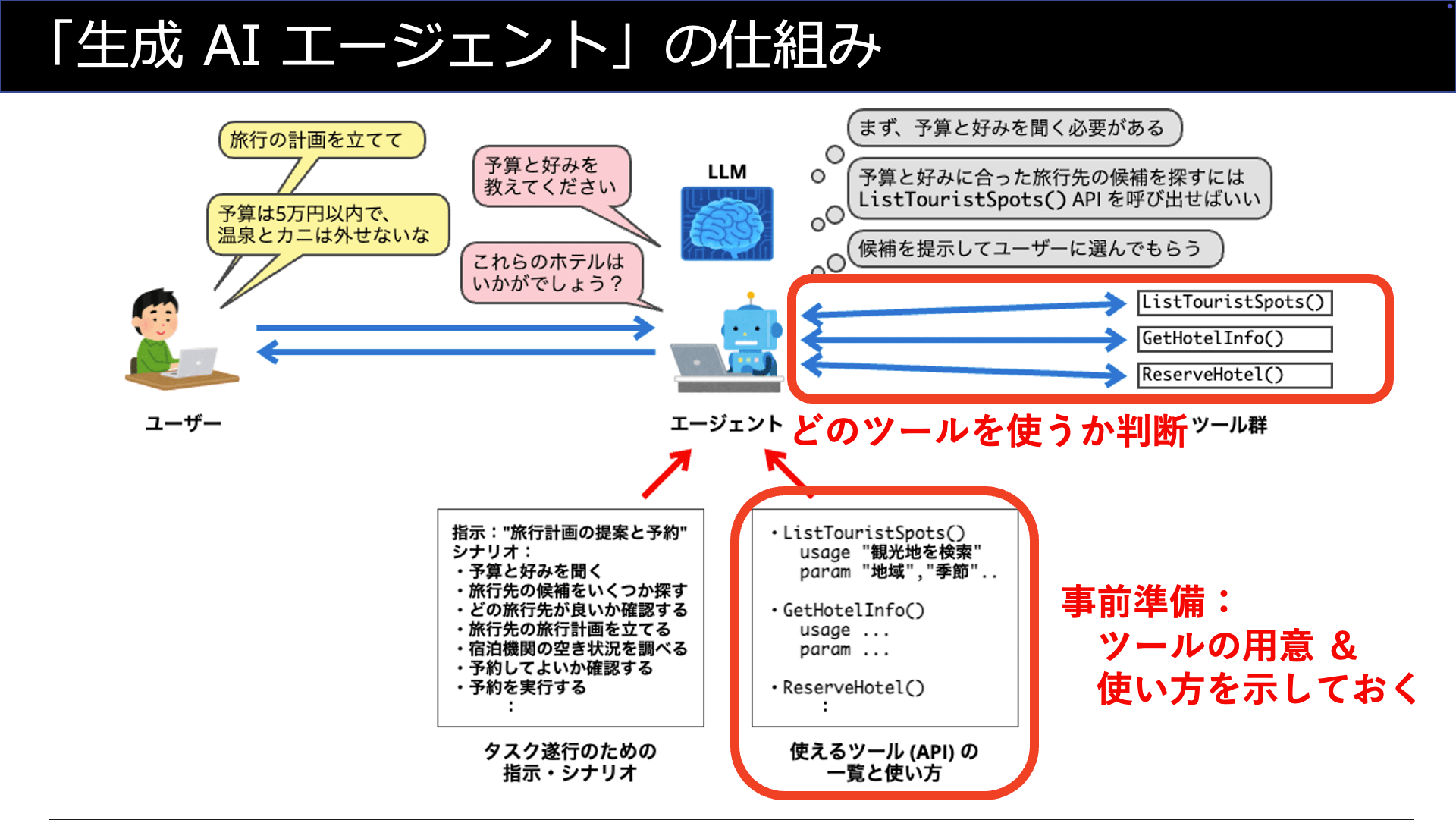
生成AIが持っていないのは、考えたこと・調べたことを実際に実行する「手」です。
生成AIエージェントにおける「ツール」とは、生成AIに「手」を与えるものだと言えます。
生成AIエージェントに与える「手」は、「APIの呼び出し」「プログラム (関数) の実行」といった形で実装されます。(※2)
事前準備として、エージェントに対して利用できる「ツール」のリストを呼び出し方法 (引数・戻り値など) と共に与えておきます。
そして重要なのは「各ツールを使うことで、どのようなことができるのか」を文章 (テキスト) の形で提示しておくという点です。
LLMはオーケストレーションの動作の一環として「タスク遂行のために次に行うべきことは、与えられたツール『◯◯』を使うことだ」と考える訳です。
(※2) 厳密に言うと、多くの生成AIエージェントの実装では、エージェントが行うのは「どのツールをどのように使うのか考える」ところまでで、実際に実行するのはアプリケーション側で実装することが多いです。なお、Amazon Bedrock Agentsでは「エージェントがLambda関数を直接呼び出すことができる」という点で例外的です。

ここで少し脇道に逸れますが、去年の後半から今年にかけて話題となった「Computer Use」や「Browser Use」についてお話ししましょう。
「生成AIがPCやWebブラウザを勝手に操作して仕事してくれる」という、あたかも次元の異なる夢のような技術として登場したこれらの機能ですが、実は広い意味で「生成AIエージェント」の一種なのです。
ここまでのページで説明した「ツール」の一種として、「PCのデスクトップを操作する能力」や「Webブラウザを操作する能力」を与えられたのが、Computer UseやBrowser Useの正体です。
このような機能が生まれた背景として、「ツール」をAPIやプログラム関数として用意するのは「汎用性に欠ける」という点があると考えます。
生成AIエージェントに行わせたいタスク毎に、必要な「ツール」の実装 (API、プログラム関数) を新たに開発するというのは大変です。
また、既存のAPIやプログラム関数を流用するにしても、そのまま使うことが難しく結局は改修・テストが必要になることがほとんどだと思います。
Computer UseやBrowser Useであれば、人間がPCやWebブラウザを使って行なっているタスクを、そのまま生成AIエージェントに行わせることができます。
とは言え、誤操作・誤認識があるために、まだまだ正確・確実にタスクを行わせるのは難しいようです。今後の発展に期待したい分野ですね。
Amazon Bedrock Agents
「生成AIエージェント」についての解説 (概要) が一通り終わったところで、いよいよ「Amazon Bedrock Agents」について解説したいと思います!

・・・と思ったのですが、やはり「5分間」で全部を解説するのは無理でした。
ということで、Amazon Bedrock Agentsについては、私が以前執筆した「AWS入門ブログリレー2024」の記事を参照ください。
このブログを執筆してからまだ1年も経たないのですが、Bedrock Agentsは新たな機能が追加されるなどアップデートが多数行われています。
いずれは、情報をアップデートしたブログ記事を公開したいと思っていますので、(期待しないで) お待ちください。
おわりに
今回の勉強会では、私のLTの他にも、さまざまなバリエーション (テックな内容からエモい話まで) のセッションがありました。
セッションの登壇資料の一部は「イベント公式ページ」で公開されています。
また、当日の雰囲気は、X (旧Twitter) のハッシュタグ「#jawsugkmmt」をご覧になれば伝わるのではないかと思います。
JAWS-UG熊本では、今後も継続して勉強会・イベントを開催していく予定ということでしたので、楽しみに期待したいと思います。
最後に、JAWS-UGでは熊本を始め九州各県 (主に北の方) で勉強会・イベントを開催しています。
今回のレポートで興味を持った方は、ぜひ、お近くのJAWS-UG支部のイベントをチェックしてみてください。









