
【KNIME】S3 Tablesのテーブル自動作成フローにKNIMEを取り入れてみた
はじめに
データ事業本部の川中子(かわなご)です。
今回はKNIMEというツールをフローに組み込んで、Excelの定義書をインプットに
テーブル作成までを自動化してみたので、その構成をご紹介したいと思います。
KNIMEは、データ分析やワークフローを視覚的に構築できるオープンソースのプラットフォームです。
ドラッグ&ドロップで様々なコンポーネントを接続して、データ分析フローを感覚的に作成できます。
コードを書けないビジネスユーザーでも、簡単にデータ処理ができるためとても便利なツールです。
構成の概要
S3 Tablesへのテーブル作成は、AthenaやCLIなどから作成が可能で、
CLIから作成する場合には、メタデータを事前に定義したスキーマファイルの利用が可能です。
今回はそのスキーマファイル作成のパートをKNIMEのワークフローで処理して結果をS3に出力、
オブジェクトのPUTイベントをトリガに、Lambdaを実行してテーブルを作成するフローを作ってみました。
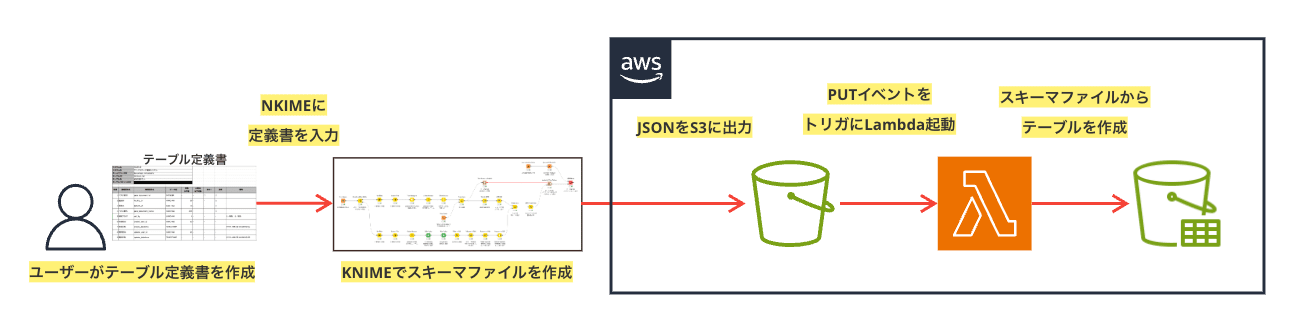
テーブル定義書は以下のような形式のものをサンプルとして作成しました。
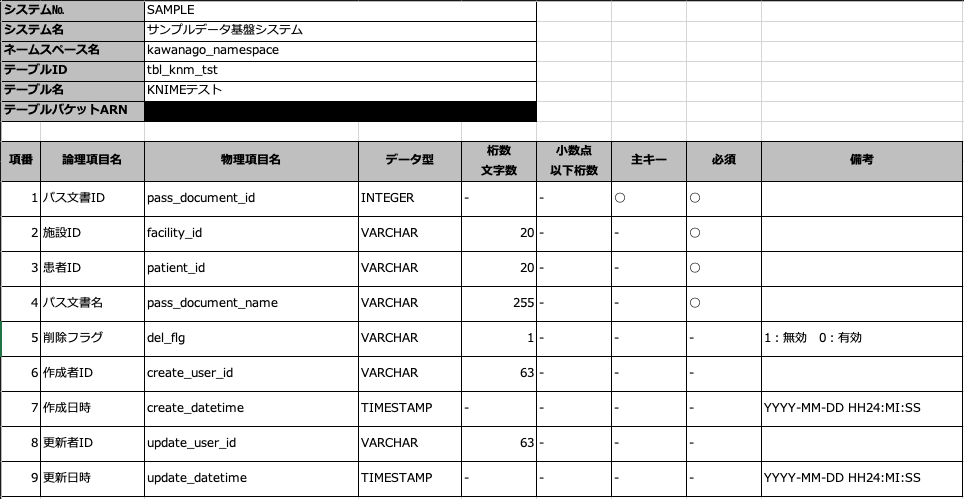
この構成なら、Excelの定義書はローカルやクラウドのストレージに残り、
テーブル作成の際に参照する具体的なスキーマ定義のファイルはS3に残るような運用になります。
KNIMEの実装
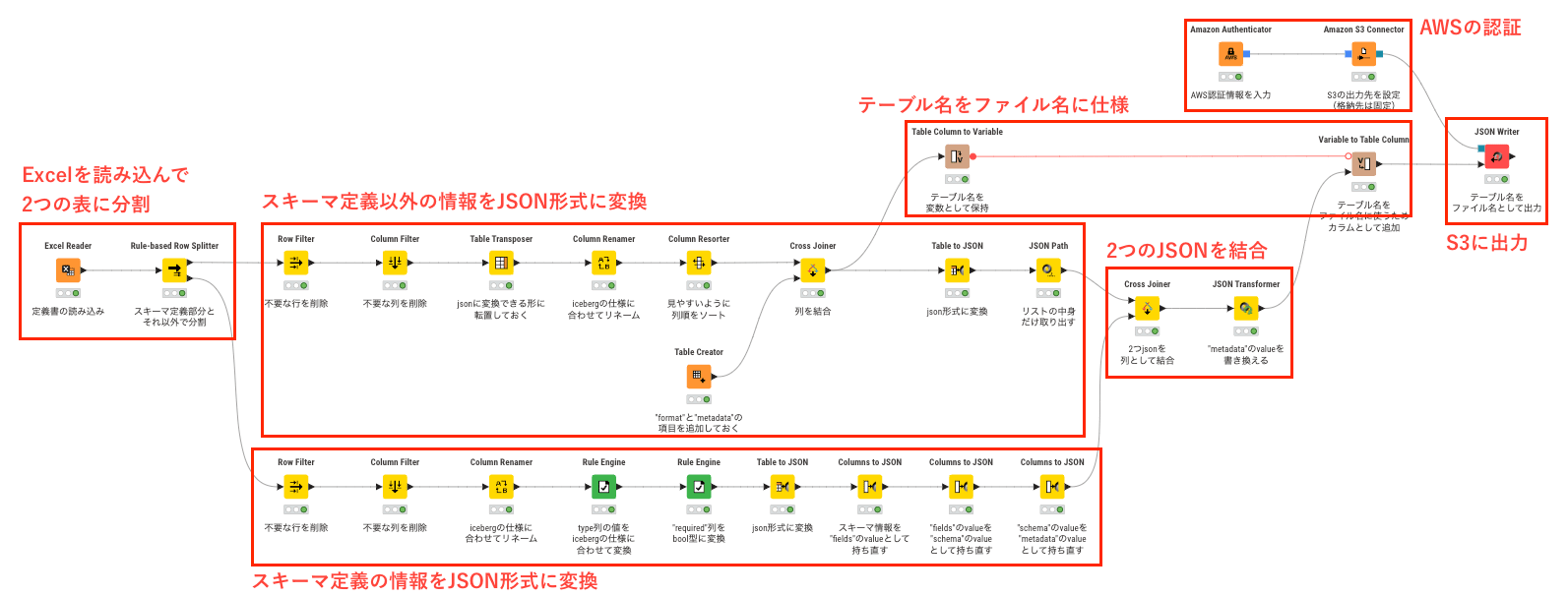
実装したKNIMEの全体像は上記のようになりました。
テーブルからJSONへの変換と整形、2つのJSONの結合でノードが多くなりました。
以下に各ステップの説明を簡単に記載していきます。
データの読み込みと分割
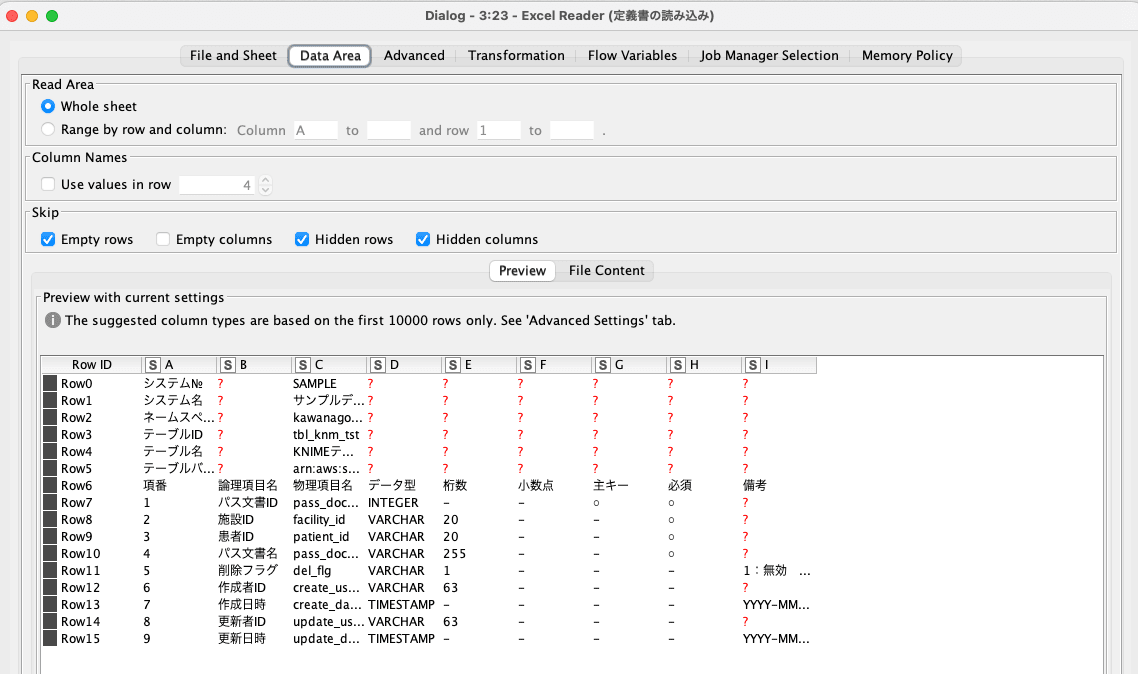
Excel Readerでデータを読み取り、Rule-based Row Splitterで分割しています。
シート上部ではテーブル名やネームスペースを定義、下部ではスキーマを定義する情報を持っているので、
そのテーブルを分割してそれぞれ後続のステップでJSON形式に変換を行っています。
テーブルからJSONへの変換
スキーマ定義部分(シート下部)
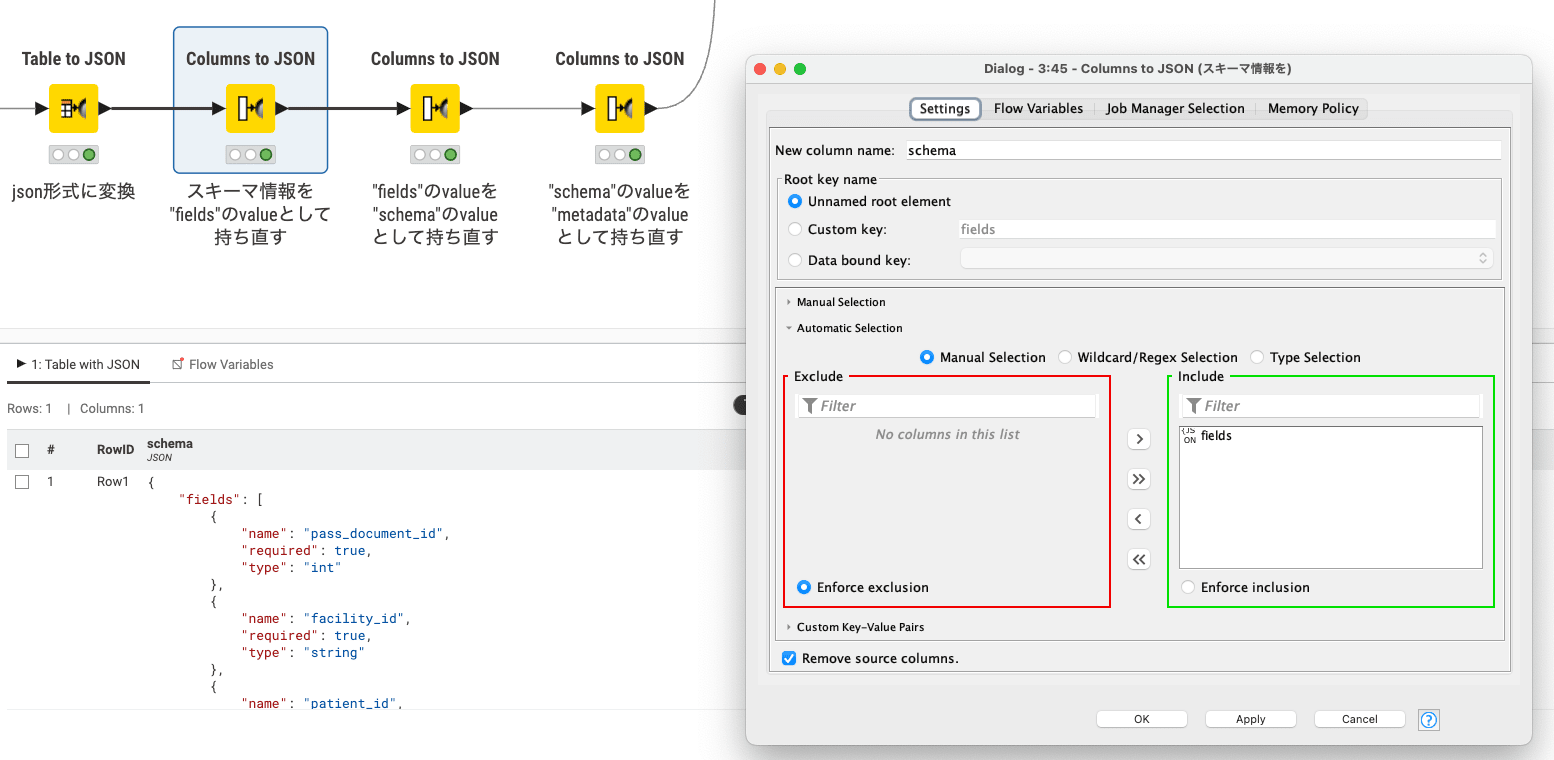
スキーマ定義部分のJSON整形のポイントとして、Columns to JSONで複数回処理を実行し、
以下のような fields > schema > icebergの入れ子構造を作成しています。
"iceberg" : {
"schema" : {
"fields" : [ {
"name" : "pass_document_id",
"required" : true,
"type" : "int"
}, {...
スキーマ定義部分以外(シート上部)
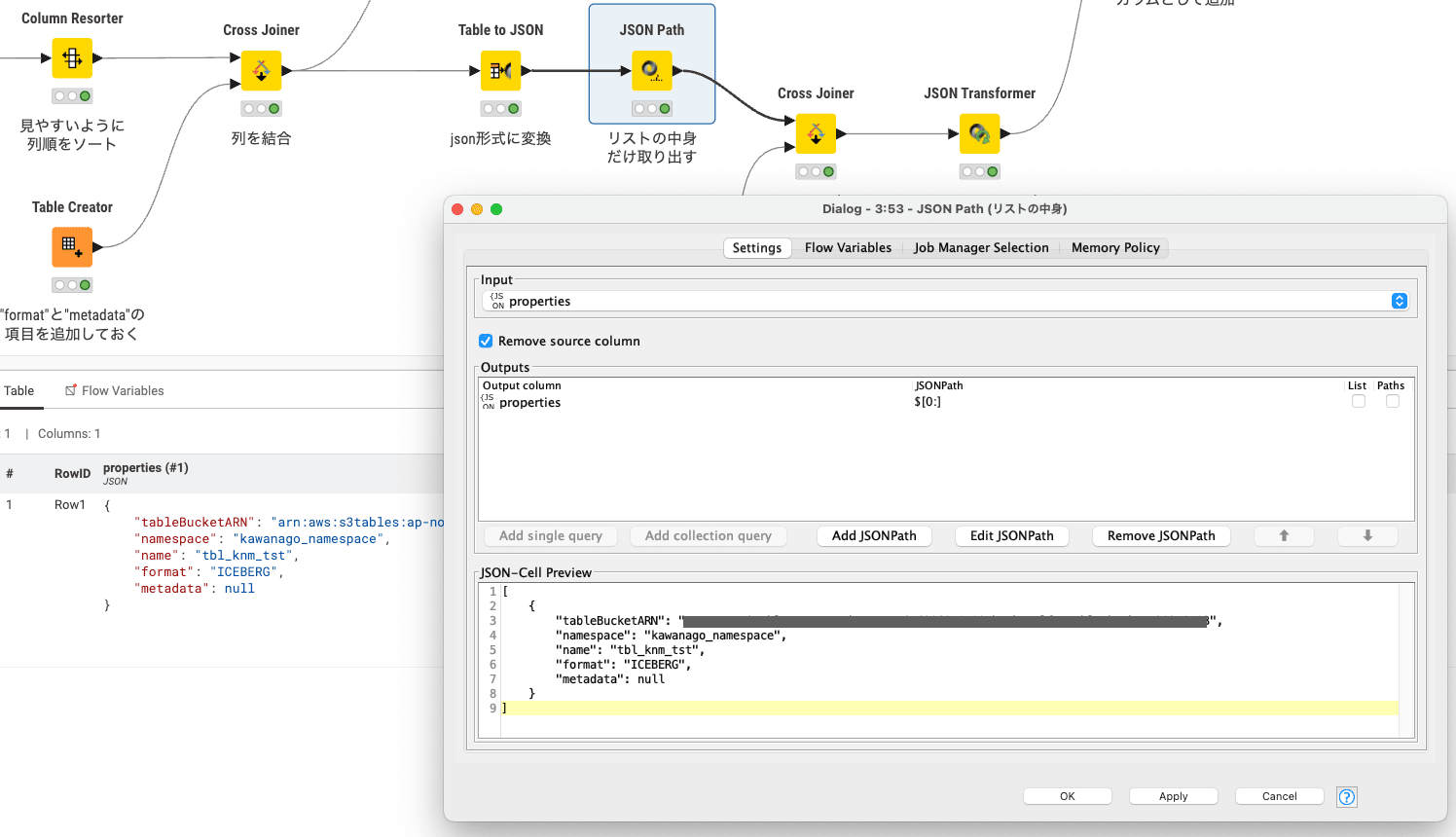
テーブル名などの定義をしているシート上部の方の変換では、formatと metadata列を追加しています。
metadata列は後にスキーマ情報で上書きするために、NULLとして設定しました。
また Table to JSONを実行するとjsonの最表面が []で囲われてしまい、
次のステップの結合時に邪魔になってしまうため、JSON Pathで中身だけを取り出しています。
JSONを結合
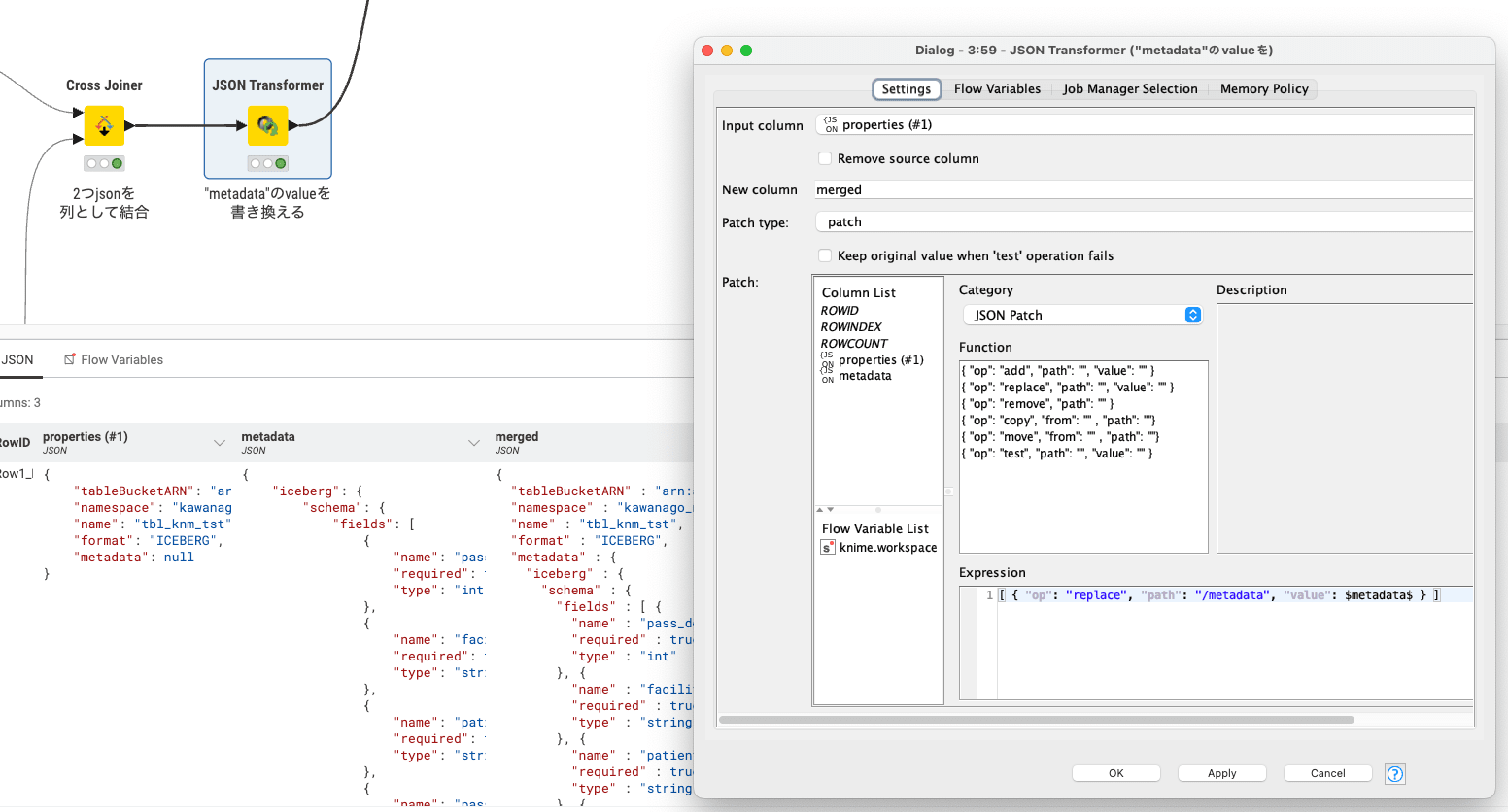
2つのJSONの結合には Cross Joinerを使用し、2つのJSONが列として並ぶ形になります。
JSON Transformerで metadata項目を上書きすることで、2つのjSONを結合しています。
AWSの認証
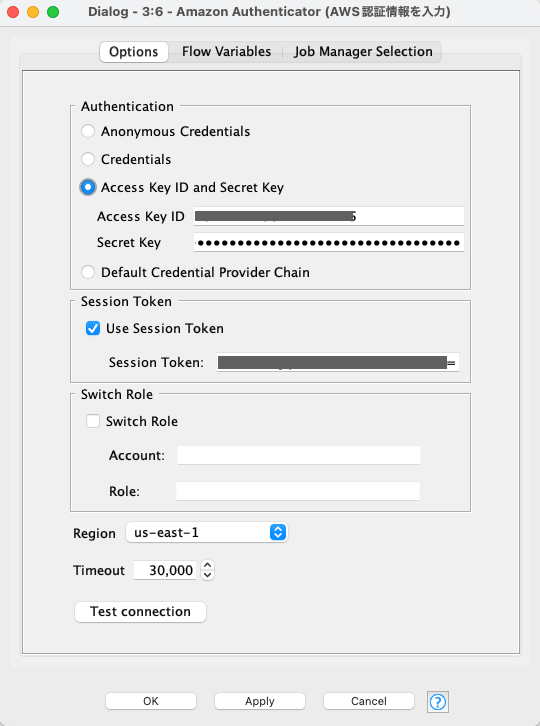
AWSの認証には Amazon Authenticatorを使用しています。
どうやらこのノードではMFAなどの情報を渡すことができないようで、
私の検証環境ではスイッチロールができないため、ターミナルでassume-roleした情報を直書きしました。
AWSの認証については他にも設定の方法があるので、別の機会に記事にしたいと思います。
結果の出力
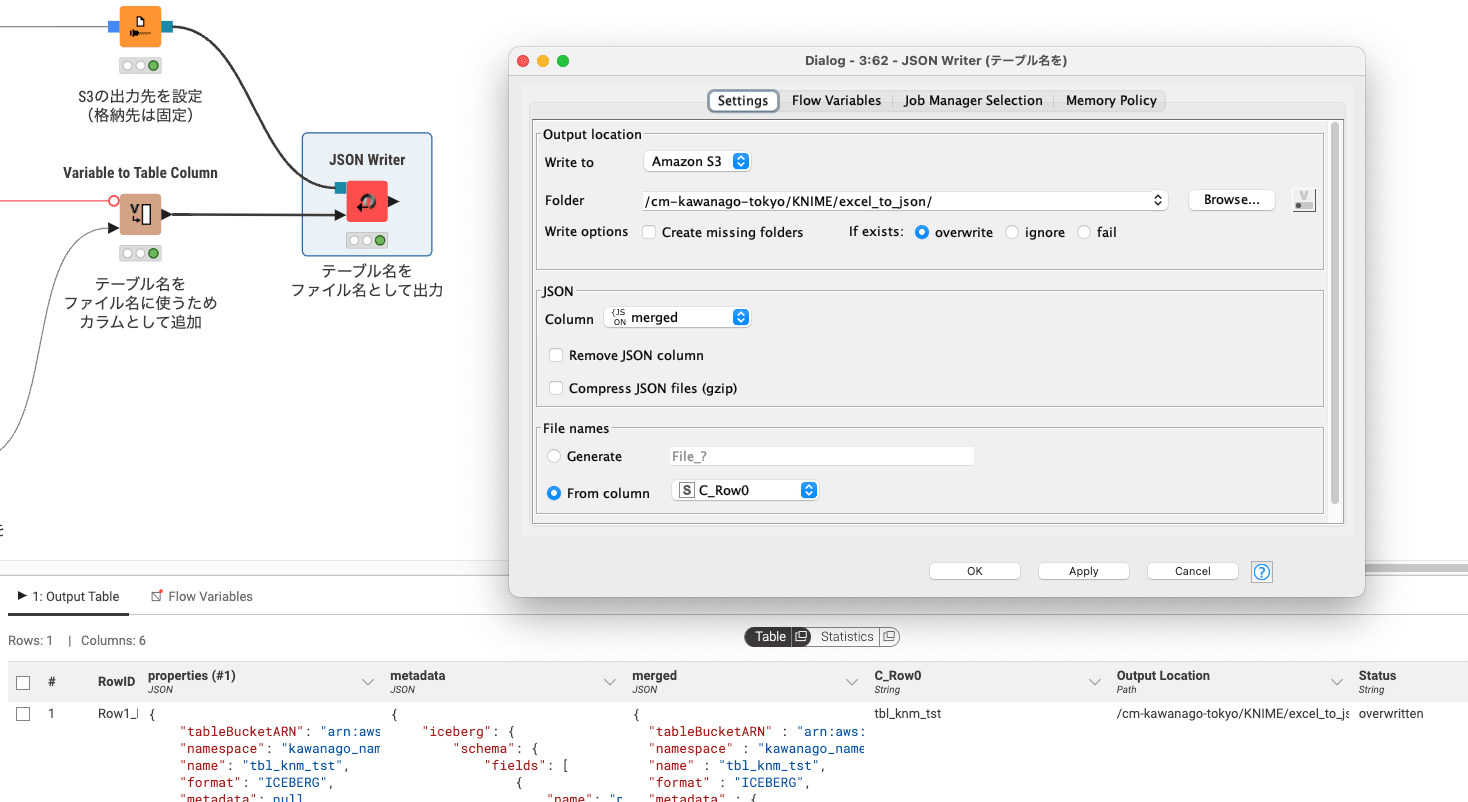
JSON Writerを用いて、結合した結果を指定のS3バケットのフォルダに出力します。
File namesではFrom columnを選択し、変数化していたテーブル名をファイル名として命名しました。
KNIME以外の準備
AWS側で必要な設定やLambdaの準備をしておきます。
S3 Tablesのテーブルバケットやネームスペースは作成されていることを前提としています。
Lambda
スキーマファイルを読み込み、S3 Tablesにテーブルを作成するLambdaを作成しました。
lambda_function.pyは以下の通りです。
import json
import boto3
import logging
# ロガーの設定
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# AWS クライアントの初期化
s3_client = boto3.client('s3')
s3tables_client = boto3.client('s3tables')
def lambda_handler(event, context):
try:
# EventBridgeからS3オブジェクトの情報を取得
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = event["Records"][0]["s3"]["object"]["key"]
# スキーマファイルの読み込み
response = s3_client.get_object(Bucket=bucket, Key=key)
schema_info = json.loads(response['Body'].read().decode('utf-8'))
# テーブルの作成
s3tables_client.create_table(**schema_info)
return {
'statusCode': 200,
'body': json.dumps(f'Successfully created table')
}
except Exception as e:
logger.error(f"Error with creating table: {e}")
raise
S3バケットのイベント通知設定
上で作成したLambdaを起動できるように、スキーマファイル出力先のバケットに、
Lambdaへのイベント通知設定をしておきます。
Amazon EventBridge に通知を送信するをONにしておくのを忘れずに。

実行
作成したテーブル定義書をExcel Readerで指定し、末端のJSON Writerを実行します。
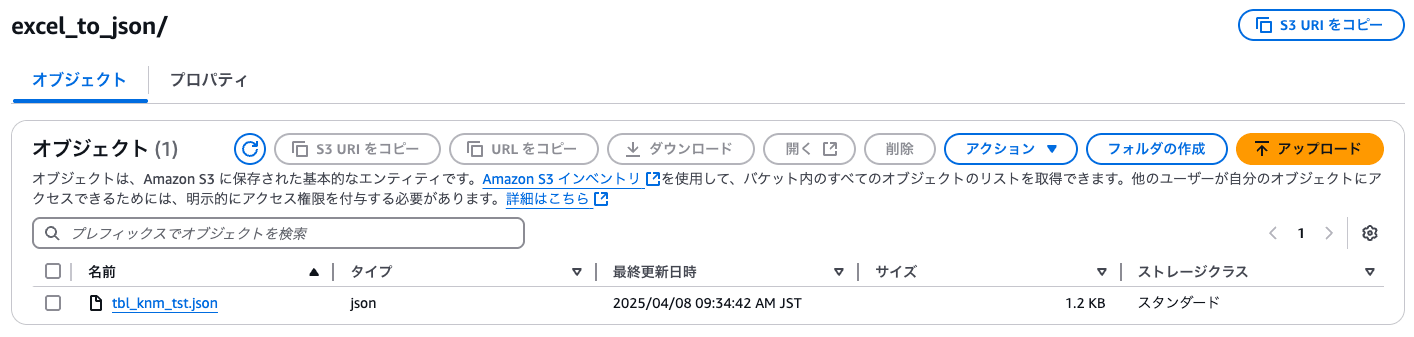
実行はすぐに完了し、S3の指定したフォルダにスキーマファイルが出力されました。
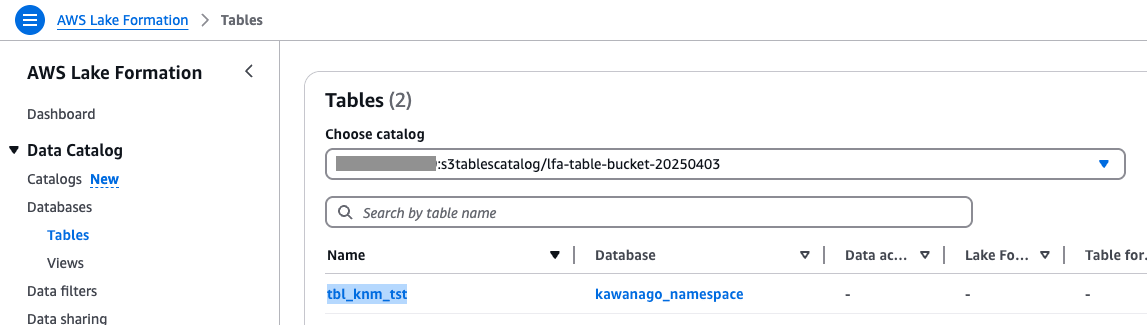
Lake Formationを確認するとtbl_knm_tstが新しく作成されていました。
さいごに
今回はKNIMEをフローに組み込んでS3 Tablesへのテーブル作成自動化をやってみました。
テーブル作成にLambdaを使うなら、そもそも全てLambdaで処理することも可能なのですが、
Lambdaを使わずCLIからの実行でも便利なので、運用ルール次第だと思います。
今後KNIMEを使う機会があれば、少しずつ使い方についての記事も書いてみたいと思います。
最後まで閲覧頂きありがとうございました。









