
Knowledge Bases for Amazon BedrockがサポートしたAdvanced RAGに関する機能をまとめてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、つくぼし(tsukuboshi0755)です!
アップデートにより、Knowledge Bases for Amazon BedrockがAdvanced RAGに関する機能をサポートしました。
上記ページでは一口にAdvanced RAGと表現されていますが、実際に紐解いてみるとこのアップデートの中で様々な機能が追加されている事が分かりました。
今回はこちらのアップデートについて、具体的に何ができるようになったか解説していきます!
今回のアップデート内容
今回のアップデートを紐解くと、以下の合計5つの機能が新たにサポートされた事が分かります。
- 高度な解析オプション
- 追加されたチャンキング戦略
- Lambda関数を使用したカスタムチャンキング
- CSVファイルのメタデータのカスタマイズ
- クエリの分解
以下の公式ブログでも解説があります。
各々のアップデートについて、以下で詳しく説明していきます。
高度な解析オプション
ナレッジベース作成時に高度な解析オプションを有効化する事で、PDFなどのサポートされているファイルタイプから表やグラフ等の非テキスト情報を解析する事が可能になります。
このオプションを有効化すると、非テキスト情報を解析するための基盤モデルを以下から選択できます。
- Claude 3 Sonnet
- Claude 3 Haiku
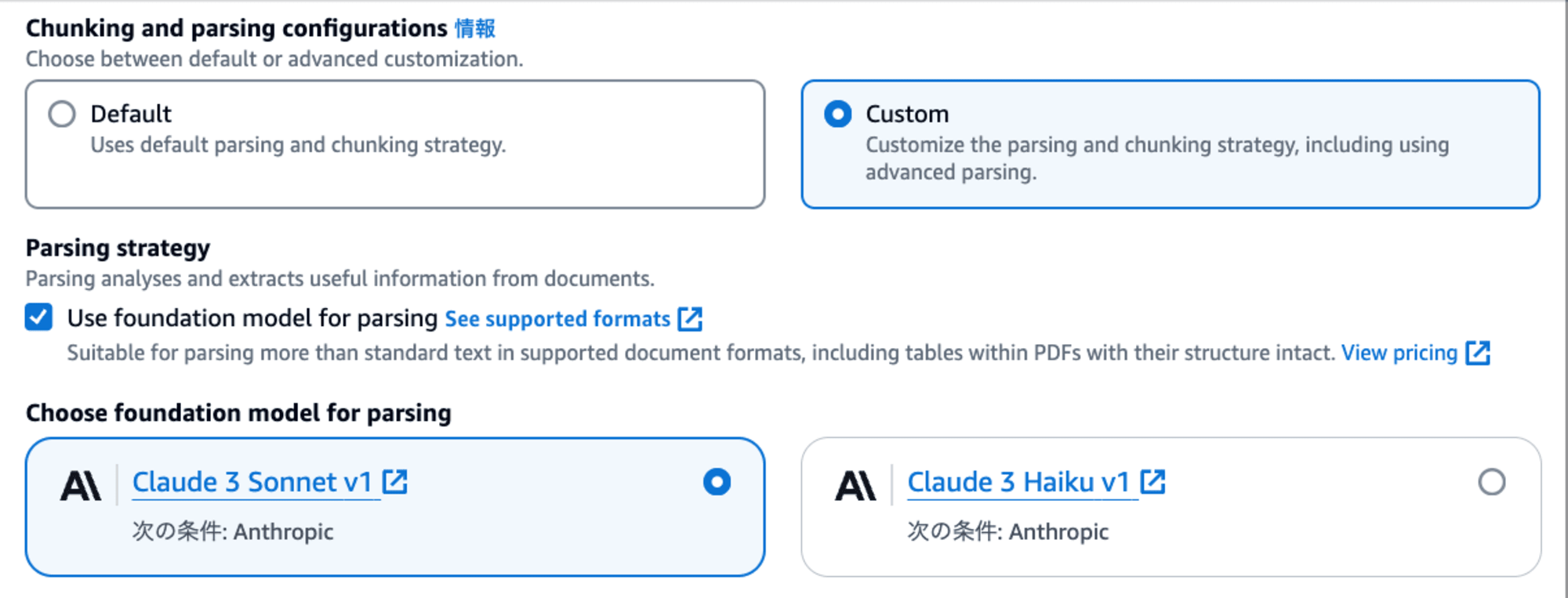
さらに非テキスト情報を解析するための既定プロンプトが与えられているのですが、これを独自の内容に上書きする事もできます。
これにより、さまざまなユースケースでプロンプトを調整し、独自の解析が可能になります。

追加されたチャンキング戦略
チャンキング戦略とは、RAGにおいてデータをどのように分割し検索対象とするかの戦略を指します。
チャンキング戦略の詳細については、以下の記事が詳しいので、別途ご参照ください。
元々ナレッジベース作成時に、以下3つの中からチャンキング戦略を選択する事が可能でした。
- デフォルトチャンキング:各ファイルを300の最大トークン数を持つチャンクに分割
- 固定サイズのチャンキング:各ファイルを20 ~ 8192の間で指定した最大トークン数を持つチャンクに分割
- チャンキングなし:各ファイルをそのままチャンクとする
上記のチャンキング戦略は、主に最大トークン数のみに依存しているものが多い印象です。
今回のアップデートにより、新たに追加された2つチャンキング戦略が追加されました。
これらは最大トークン数以外の要素を考慮したチャンキング戦略となっており、より高度な分割が可能になっています。
各々の戦略について、以下で説明します。
階層的チャンキング
一般的にRAGにおけるチャンクサイズは、検索時(Retrivalフェーズ)では小さい方が精度が上がりやすい一方で、回答生成時(Generationフェーズ)は大きい方が精度が上がりやすいという性質を持ちます。
こちらのチャンキング戦略では、各ファイルをまず親チャンクに分割した後さらに子チャンクとして分割し、親子をネスト構造として整理します。
その上で、サイズの小さな子チャンクを検索で使用し、サイズの大きな親チャンクを回答生成で使用する事で、検索と回答生成の精度を同時に上げるという良いとこ取りができるようになります。

階層的チャンキングでは、以下のパラメータを設定可能です。
| パラメータ名 | 説明 |
|---|---|
| 最大親トークンサイズ | 親のチャンクに含める必要があるトークンの最大数 |
| 最大子トークンサイズ | 子のチャンクに含める必要があるトークンの最大数 |
| オーバーラップトークン | 各チャンクの最後の要素と次のチャンクの最初の要素で共有されるトークンの数 |
上記のパラメータを適宜調整する事で、適切な階層的チャンキングを実現できるようになっています。
セマンティックチャンキング
こちらのチャンキング戦略では、テキストの意味や文脈を埋め込みモデルで分析し、各ファイルを意味的類似性に基づくチャンクに分割する手法です。

セマンティックチャンキングでは、以下のパラメータを設定可能です。
| パラメータ名 | 説明 |
|---|---|
| 最大トークン数 | 単一のチャンクに含める必要があるトークンの最大数 |
| バッファサイズ | 意味的類似度を評価する際い埋め込みの作成に追加される周囲の文の数を定義する。例えば、この値が1の場合、3つの文 (現在の文、前の文、次の文) が結合されて埋め込まれる。 |
| ブレークポイントしきい値 | 意味的類似性に基づいてテキストをチャンクに分割する場所を決定する基準となるパーセンテージ |
上記のパラメータを適宜調整する事で、自身が想定する意味的類似性に基づいたチャンキングを実現できるようになっています。
(なおここで取り上げられている意味的類似性が具体的にどのような値で計算されるかまでは、公式ドキュメントからは読み取る事ができませんでした。もしご存知の方がいらっしゃれば教えていただけると幸いです。)
Lambda関数によるカスタムチャンキング
現状のチャンキング戦略以外に、今回追加されたLambda関数によるカスタムチャンキングを使用する事で、独自のチャンキング戦略を実現できます。

こちらはKnowledge Basesにて以下のリソースを指定する事で、自身がカスタマイズしたチャンキング処理を実装できます。
- Lambda関数:カスタムチャンキング処理を実施
- S3バケット:Lambda関数に入力される加工前ファイル、及びLambda関数から出力される加工後ファイルを保存
この機能を用いる事で、LangChainやLLamaIndexといったOSSフレームワーク等で提供されていたり、あるいは自身が実装したチャンキングのメソッドを呼び出す事が可能です。
例えばチャンキング戦略で「チャンキングなし」を指定した場合、Lambdaで定義した特定のカスタムチャンキング処理のみを実行する事ができます。
一方チャンキング戦略で「デフォルトチャンキング」及び「固定サイズのチャンキング」等を指定した場合、事前に特定のトークン数でチャンキングされたファイルに対して、さらに特定のカスタムチャンキング処理をかませるというような事も可能です。
これによりデータ内容に応じて、より柔軟なチャンキング処理を実現できるようになっています。
CSVファイルのメタデータのカスタマイズ
メタデータを使用する事で、コンテンツのフィルタリングを行う事ができます。
メタデータフィルタリングの詳細については、以下の記事が詳しいので、別途ご参照ください。
今回のアップデートにより、csvファイルのみとなりますが、特定の列のみをコンテンツフィールドまたはメタデータフィールドとして指定できるようになりました。
これにより、必要なデータのみをコンテンツフィールド及びメタデータフィールドで指定し、不要なデータは除外する事で、特に大規模なCSVデータセットにおいて効率的にデータを管理する事ができます。
なおこの機能を使用するには、ソースファイルとは別に、以下のような内容で同じ名前の<filename>.csv.metadata.jsonファイルを用意する必要があります。
{
"metadataAttributes": {
"target": "company-wide",
"year": 2024,
"for_managers": true
},
"documentStructureConfiguration": {
"type": "RECORD_BASED_STRUCTURE_METADATA",
"recordBasedStructureMetadata": {
"contentFields": [
{
"fieldName": "String"
}
],
"metadataFieldsSpecification": {
"fieldsToInclude": [
{
"fieldName": "String"
}
],
"fieldsToExclude": [
{
"fieldName": "String"
}
]
}
}
}
}
上記のメタデータファイルを作成する際は、以下の点にご注意ください。
- コンテンツフィールドは現在1つのみ指定可能
- メタデータ包含/除外フィールドが指定されていない場合、コンテンツ列を除くすべての列はメタデータ列として扱われる
- メタデータ包含フィールドのみが指定されている場合は、指定された列のみがメタデータとして扱われる
- メタデータ除外フィールドのみが指定されている場合は、除外列を除くすべての列がメタデータとして扱わる
- CSCファイル内に空白行が見つかった場合は、スキップして無視する
クエリの分解
LLMに送る質問メッセージを入力クエリと呼びます、
ナレッジベースのテストやRetrieveAndGenerateAPIでメッセージを送る際に、クエリ分解オプションを有効化する事で、複雑な入力クエリを複数のサブクエリに分解できるようになりました。

例えば以下のクエリをKnowledge Bases for Amazon Bedrockに送付するとします。
クラスメソッド社の日比谷本社オフィスはどこにありますか?Classmethod Odysseyはその会社と評判と社会的イメージにどのような影響を及ぼしましたか?
この機能を有効化した上でクエリを送付すると、上記のクエリが以下のサブクエリに分解された上で、Knowledge Bases for Amazon Bedrockに対して複数のクエリが実行されます。
クラスメソッド社の日比谷本社オフィスはどこにありますか?
クラスメソッド社に関するClassmethod Odysseyとは何ですか?
Classmethod Odysseyは、クラスメソッド社の会社と評判と社会的イメージにどのような影響を及ぼしましたか?
この機能により、複雑なクエリが送付された場合でも、より正確な検索結果を得やすくなりました。
最後に
今回はナレッジベースがサポートしたAdvanced RAGに関する機能をまとめてみました。
想像していたよりも様々な機能が絡んだアップデートだったので、本記事では敢えてどのような事ができるようになったかに焦点を当てて解説してみました。
今回のアップデートだけでナレッジベースを完全なAdvanced RAGとして使用するのはまだ難しい印象ですが、個々の機能は有用なものばかりですのでぜひご活用して頂くと良いと思います。
以上、つくぼし(tsukuboshi0755)でした!









