
Lambda Managed Instances環境固有のレースコンディションについて確認してみた #AWSreInvent
リテールアプリ共創部@大阪の岩田です。
Lambda Managed Instancesでは基本的にLambdaのプログラミングモデルがそのまま利用可能ですが、通常のLambda実行環境とは異なる点があることに注意が必要です。
このブログでは/tmpディレクトリの利用を例としてLambda Managed Instances固有のレースコンディションについて検証していきます。
同時実行モデルに関する違い
コンピューティングタイプにLambda Managed Instancesを指定したLambda Functionは同時実行制御について通常のLambda Functionとは異なるモデルで動作します。
公式ドキュメントの記載は以下の通りです。
Lambda Managed Instances support multi-concurrent invocations, where one execution environment can handle multiple invocations at the same time. This differs from the Lambda (default) compute type, which provides a single concurrency model where one execution environment can run a maximum of one invoke at a time. Multi-concurrency yields better utilization of your underlying EC2 instances and is especially beneficial for IO-heavy applications like web services or batch jobs. This change in execution model means that thread safety, state management, and context isolation must be handled differently depending on the runtime.
通常のLambdaは以下のようなモデルです。
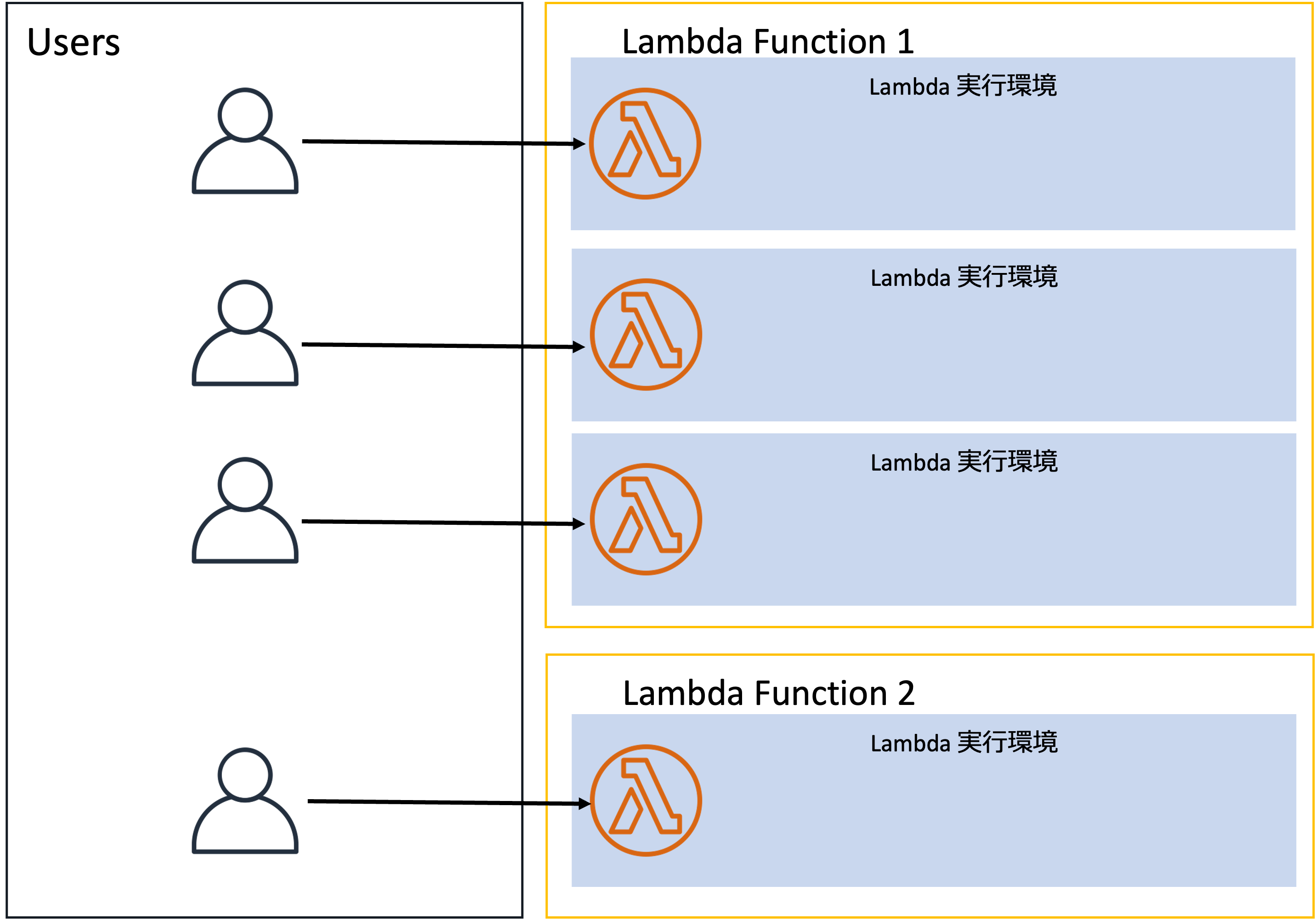
1つのLambda実行環境が同時に処理するリクエストは最大1つだけです。複数のリクエストが発生した場合は複数のLambda実行環境が起動して並列で処理を行うことになります。
それに対してLambda Managed Instancesを利用する場合は以下のようなモデルになります。
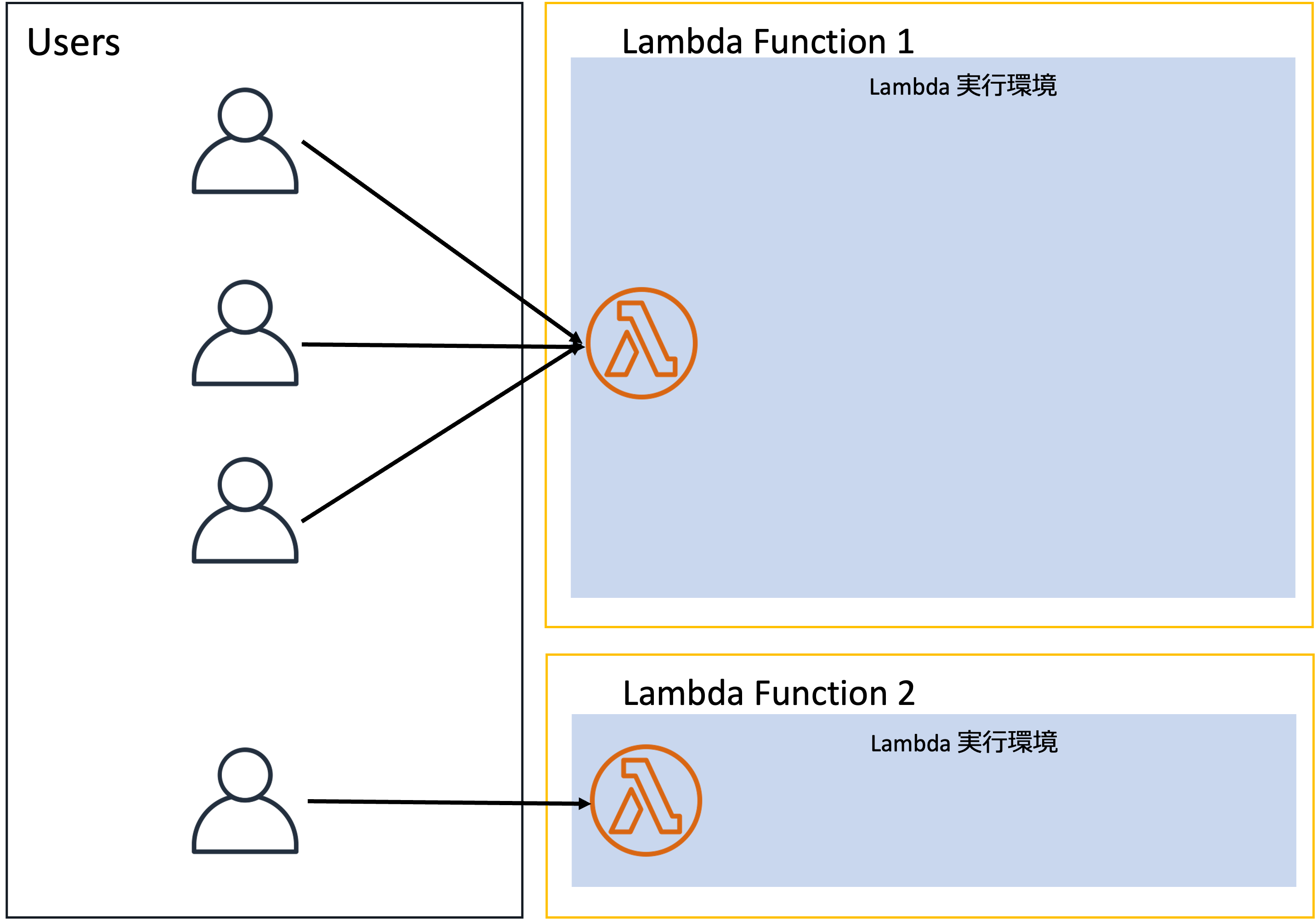
1つのLambda実行環境が同時に複数のリクエストを処理します。
これらのモデルの違いから、Lambda Managed Instancesを利用する際は通常のLambdaとは異なる注意点が存在します。
詳細については以下ドキュメントに記載されています。
ランタイムによって同時実行の実現方法がマルチプロセスだったりマルチスレッドだったりとマチマチなので、各ランタイムごとに固有の考慮事項が存在しますが、全ランタイム共通で記載されているのが/tmpディレクトリに関する考慮事項です。例えばPythonの場合は以下のように記載されています。
The /tmp directory is shared across all concurrent requests in the execution environment. Concurrent writes to the same file can cause data corruption, for example if another process overwrites the file. To address this, either implement file locking for shared files or use unique file names per process or per request to avoid conflicts. Remember to clean up unneeded files to avoid exhausting the available space.
ランタイムによってper process or per request の部分がper requestやper thread or per requestに微妙に変化しますが、基本的に述べられていることはリクエストを跨いで/tmpディレクトリが共有されることに注意しようということです。
やってみる
実際にリクエストを跨いで/tmpディレクトリが共有されることを確認してみましょう。
Python3.14のランタイムで以下のコードを書きました。
import json
import os
import time
def lambda_handler(event, context):
file_path = '/tmp/test.txt'
query_params = event.get('queryStringParameters') or {}
if 'read' in query_params:
content = ''
for i in range(100):
time.sleep(0.1)
if os.path.exists(file_path):
with open(file_path, 'r') as f:
content = f.read()
print(json.dumps({
"i": i,
"content": content.splitlines()
}))
return {
'statusCode': 200,
'body': json.dumps({})
}
request_id = context.aws_request_id
with open(file_path, 'a') as f:
f.write(request_id + '\n')
return {
'statusCode': 200,
'body': json.dumps({})
}
やってることは簡単で、クエリパラメータにreadが存在する場合は100msスリープして/tmp/test.txtの中身をログに出力する処理を100回繰り返します。
逆にクエリパラメータにreadが存在しない場合は/tmp/test.txtにリクエストIDを追記します。
このLambdaをAPI GWの背後に配置してcurlコマンドでクエリストリングreadを付与したリクエストを発行しました。
curl "https://<API GWのエンドポイント>?read=true"
並行してabコマンドで100リクエストを発行してみました。
ab -n 100 -c 1 "https://<API GWのエンドポイント>"
まず通常のLambda実行環境の場合の結果です。
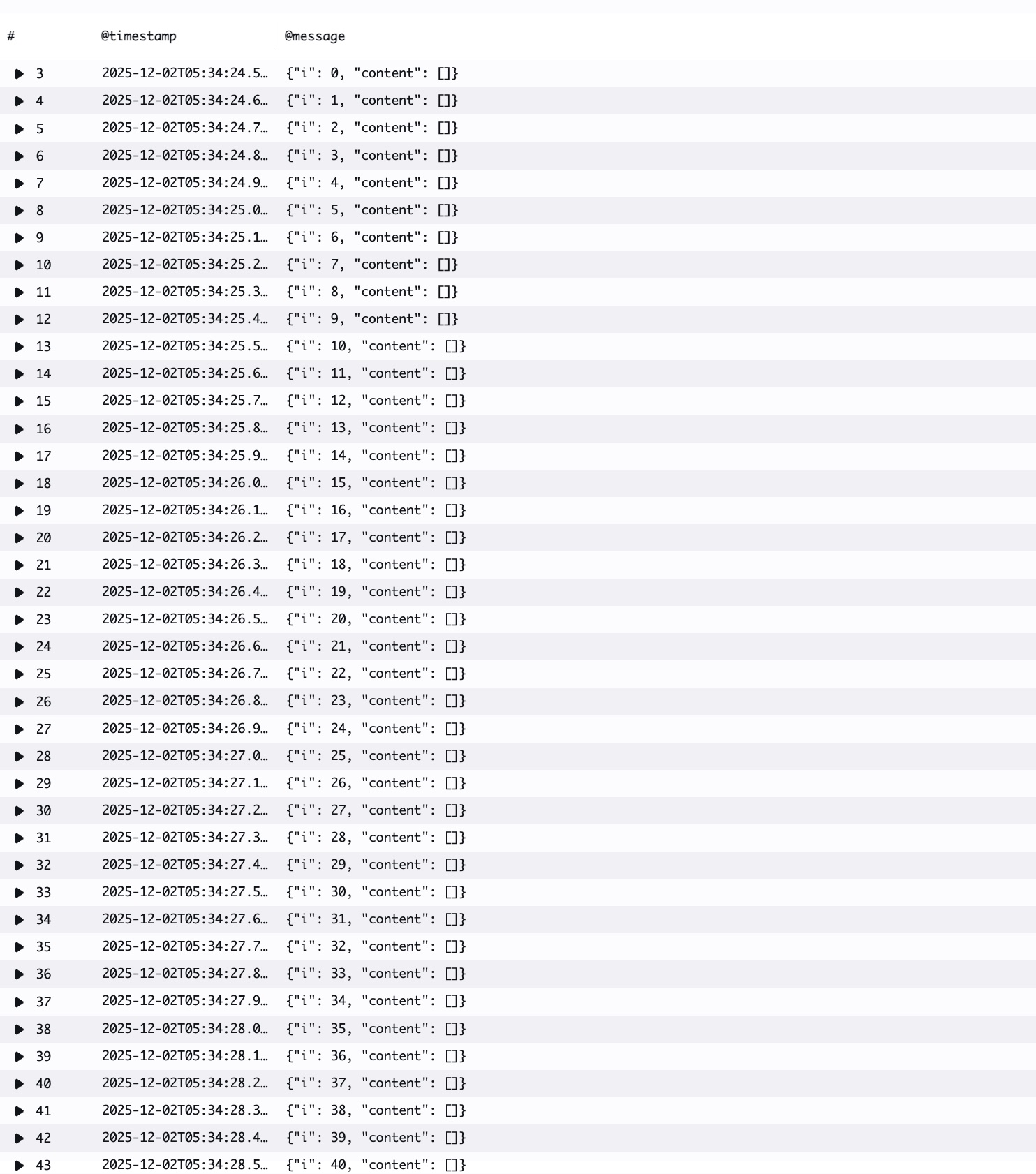
CW Logsに出力されたログを確認するとログに出力された"content"はずっと空のままです。curlコマンドからのリクエストを処理しているLambda実行環境とabコマンドからのリクエストを処理しているLambda実行環境が分離されていることが読み取れます。
続いてLambda Managed Instancesの環境でテストした際のログです。
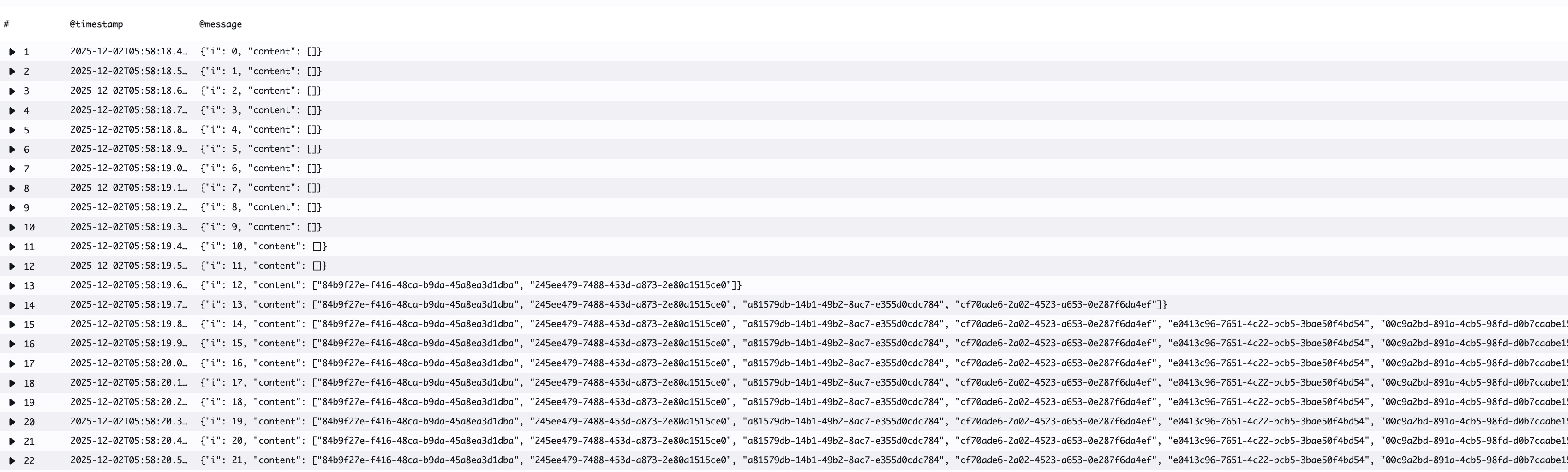
ログに出力された"content"は最初空ですが、徐々に中身が増えていっています。この結果からcurlコマンドからのリクエストを処理しているLambda実行環境がabコマンドからのリクエストも処理していることが読み取れます。
まとめ
通常のLambda実行環境では発生しないLambda Managed Instances環境固有のレースコンディションについて確認してみました。
/tmpディレクトリ配下のファイルを読み書きするようなコードがあると不具合が発生するリスクがあるので注意しておきたいですね。この他にも通常のLambda実行環境と同様の仕様とLambda Managed Instances固有の仕様があるので、利用を検討する際はしっかりドキュメントを確認するようにしましょう。
1つの実行環境が複数リクエストを同時に処理するというモデルは複数リクエストを跨いだリソース共有が可能ということでもあるので、Lambda Managed Instancesにおいてはコネクションプーリングの考え方も変わってきそうですね。Pgpool-IIのようなミドルウェアをLambda Extensionsとして各Lambda実行環境にデプロイして各リクエストを処理する個々のプロセスやスレッドはExtensionに接続するといったモデルも有効かもしれません。
参考
- Lambda Managed Instances - AWS Lambda
- Lambda Managed Instances runtimes - AWS Lambda
- Java runtime for Lambda Managed Instances - AWS Lambda
- Node.js runtime for Lambda Managed Instances - AWS Lambda
- Python runtime for Lambda Managed Instances - AWS Lambda
- .NET runtime for Lambda Managed Instances - AWS Lambda









