
AWS Lambdaで取得したデータをAmazon S3に保存する構成をAWS SAMでデプロイしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
API経由で取得したデータをAmazon S3に保存したい
おのやんです。
みなさん、Webで公開されているAPIからデータを取得して、AWS環境に保存したと思ったことはありませんか?私はあります。
例えばSaaSサービスなどで、システムのログデータをAPIへリクエストして取得できるということはよくあります。そういった際に、監査などの要件でデータをAmazon S3(以下、S3)バケットに保存したいというニーズは一定数存在します。
ということで、今回はAWS Lambda(以下、Lambda)からAPIにリクエストを送信してデータを取得し、S3バケットに保存する処理を設定していきたいと思います。またAWSリソースのデプロイには、IaCの一種であるAWS SAM(以下、SAM)を使用します。
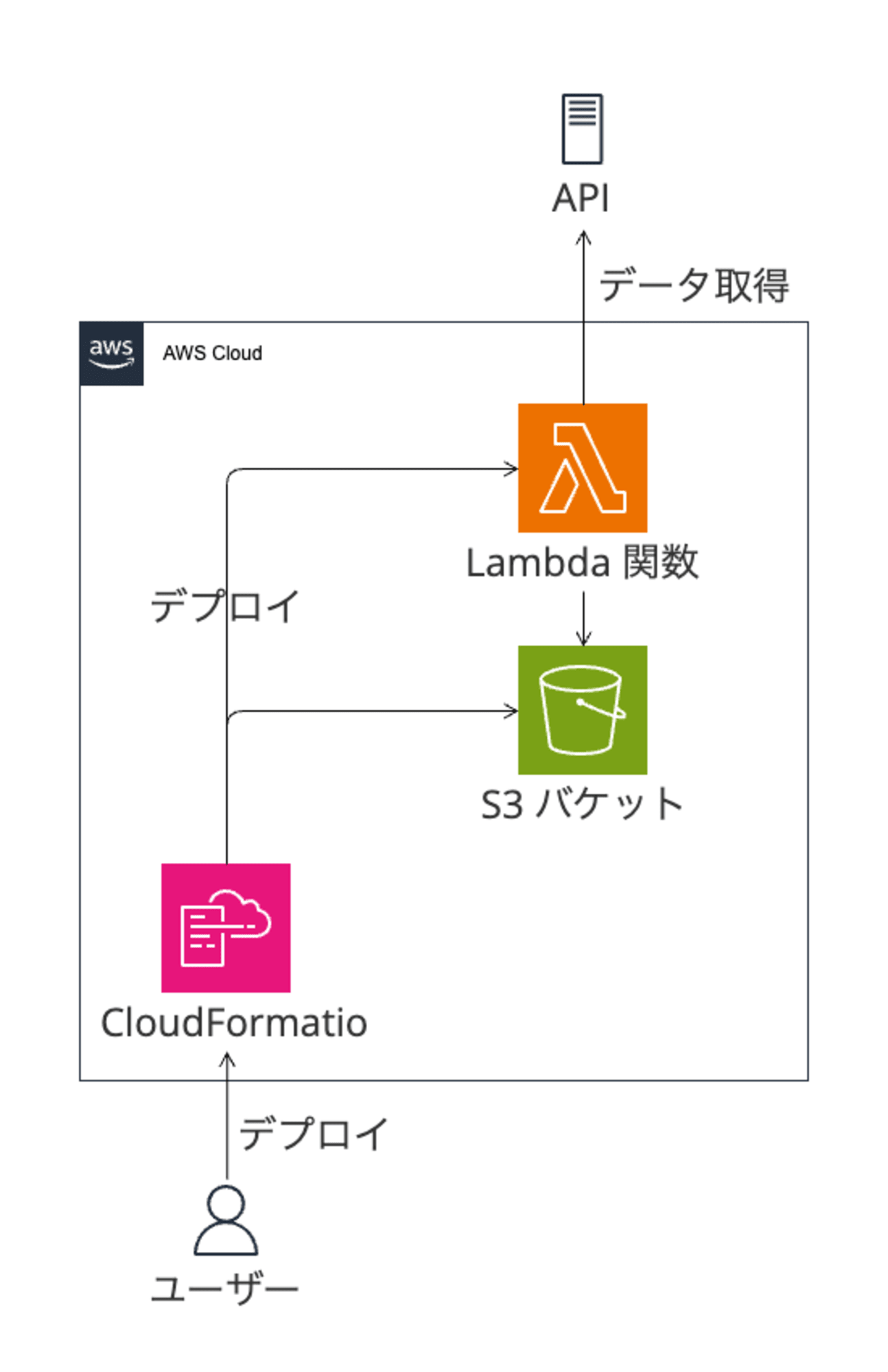
構成
今回目指す構成は以下のとおりです。構成したいシステムとして、Lambda関数とS3バケットがあります。このLambdaとS3をSAM経由でデプロイします。SAMは、実体はAWS CloudFormation(以下、CFn)ですので、デプロイ時にはCFnスタックが作成されることになります。
ディレクトリ構成
今回扱うSAMのディレクトリ構成は以下のようになります。通常のSAMはひとつのルートディレクトリ直下にsamconfig.toml、template.yamlを置きます。しかし今回のケースでは複数のシステム(複数種類のAPIなど)にリクエストを送信することが考えられたので、APIごとにLambdaコードを分けて管理できるようディレクトリを分けています。
├── aws-test-fetching-app-dev
│ ├── function
│ │ └── index.py
│ └── layer
│ └── requirements.txt
├── samconfig.toml
└── template.yaml
SAMテンプレート
今回のSAMテンプレートは以下のとおりです。今回は、Lambda関数、Lambdaレイヤー、Lambda用IAMロール、S3バケットを最小限の構成で作成しています。
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: Fetch API data
Parameters:
SystemName:
Type: String
Default: aws
EnvName:
Type: String
Default: test
#=========================================================================#
# Lambda関数用 IAMロール
#=========================================================================#
Resources:
AWSTestFetchingDataFunctionIamRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${SystemName}-${EnvName}-fetching-data-function-role"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Action: "sts:AssumeRole"
Effect: Allow
Principal:
Service: lambda.amazonaws.com
ManagedPolicyArns:
- "arn:aws:iam::aws:policy/CloudWatchLambdaInsightsExecutionRolePolicy"
Policies:
- PolicyName: !Sub "aws-test-fetching-data-policy-dev"
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action: "logs:CreateLogGroup"
Resource: !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:*"
- Effect: Allow
Action:
- "logs:CreateLogStream"
- "logs:PutLogEvents"
Resource: !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/${SystemName}-${EnvName}-fetching-data-function-log-group"
- Effect: Allow
Action: "s3:PutObject"
Resource: !Sub "arn:aws:s3:::${SystemName}-${EnvName}-fetching-data-bucket-${AWS::AccountId}"
- Effect: Allow
Action:
- "ssm:GetParameter"
- "ssm:GetParameters"
Resource: !Sub "arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:parameter/api/endpoint1/*"
#=========================================================================#
# Lambda関数用 レイヤー
#=========================================================================#
AWSTestFetchingDataFunctionModulesLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: Modules
ContentUri: aws-test-fetching-data/layer/
CompatibleRuntimes:
- python3.12
Metadata:
BuildMethod: python3.12
#=========================================================================#
# データ保管用 バケット
#=========================================================================#
AWSTestFetchingDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub ${SystemName}-${EnvName}-fetching-data-bucket-${AWS::AccountId}
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
#=========================================================================#
# データ取得用 Lambda関数
#=========================================================================#
AWSTestFetchingDataFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "${SystemName}-${EnvName}-fetching-data-function"
Description: "APIデータ取得・S3バケット保存用Lambda関数"
CodeUri: aws-test-fetching-data/function/
Handler: index.lambda_handler
Runtime: python3.12
Timeout: 900
MemorySize: 256
Role: !GetAtt AWSTestFetchingDataFunctionIamRole.Arn
Environment:
Variables:
API_SECRET: /api/endpoint1/secret
API_SERVICE_PRINCIPAL: /api/endpoint1/service-principal
BUCKET_NAME: !Sub ${SystemName}-${EnvName}-fetching-data-bucket-${AWS::AccountId}
Layers:
- !Ref AWSTestFetchingDataFunctionModulesLayer
- !Sub "arn:aws:lambda:${AWS::Region}:580247275435:layer:LambdaInsightsExtension:60"
IAMロール作成
IAMロールの部分では、最小権限の考えに則って、Lambda関数が必要な最小の権限を付与しています。特にAPIから取得したデータをLambdaからS3バケットに保存する際は、対象のS3バケットに対するs3:PutObject権限が必要になります。
また、Lambda関数のログをCloudWatch Logsに保存するときや、アクセスキーをAWS Systems Manager(以下、SSM) Parameter Storeから取得したいときも、それぞれ権限が必要になるので注意してください。
#=========================================================================#
# Lambda関数用 IAMロール
#=========================================================================#
Resources:
AWSTestFetchingDataFunctionIamRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${SystemName}-${EnvName}-fetching-data-function-role"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Action: "sts:AssumeRole"
Effect: Allow
Principal:
Service: lambda.amazonaws.com
ManagedPolicyArns:
- "arn:aws:iam::aws:policy/CloudWatchLambdaInsightsExecutionRolePolicy"
Policies:
- PolicyName: !Sub "aws-test-fetching-data-policy-dev"
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action: "logs:CreateLogGroup"
Resource: !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:*"
- Effect: Allow
Action:
- "logs:CreateLogStream"
- "logs:PutLogEvents"
Resource: !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/${SystemName}-${EnvName}-fetching-data-function-log-group"
- Effect: Allow
Action: "s3:PutObject"
Resource: !Sub "arn:aws:s3:::${SystemName}-${EnvName}-fetching-data-bucket-${AWS::AccountId}"
- Effect: Allow
Action:
- "ssm:GetParameter"
- "ssm:GetParameters"
Resource: !Sub "arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:parameter/api/endpoint1/*"
Lambda関数・Lambdaレイヤー作成
今回はディレクトリを少しいじって、APIごとにLambda関数を分離できる構成をとっています。そのため、CoreUriの部分はディレクトリパスから始めたaws-test-fetching-data/function/になります。
またLambdaからAPIにリクエストを送信する場合、処理の実装によってはライブラリをインストールするためのLambdaレイヤーが必要です。ここも、ディレクトリを分離する場合はCodeUri部分をaws-test-fetching-data/layer/にします。aws-test-fetching-data/layer/直下の保存してあるrequirements.txtに書かれているライブラリが、sam build時にダウンロードされます。
今回はAWS側で用意されたLambdaレイヤーを参照しているため、固有のARN(arn:aws:lambda:${AWS::Region}:580247275435:layer:LambdaInsightsExtension)を指定しています。
#=========================================================================#
# Lambda関数用 レイヤー
#=========================================================================#
AWSTestFetchingDataFunctionModulesLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: Modules
ContentUri: aws-test-fetching-data/layer/
CompatibleRuntimes:
- python3.12
Metadata:
BuildMethod: python3.12
#=========================================================================#
# データ取得用 Lambda関数
#=========================================================================#
AWSTestFetchingDataFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "${SystemName}-${EnvName}-fetching-data-function"
Description: "APIデータ取得・S3バケット保存用Lambda関数"
CodeUri: aws-test-fetching-data/function/
Handler: index.lambda_handler
Runtime: python3.12
Timeout: 900
MemorySize: 256
Role: !GetAtt AWSTestFetchingDataFunctionIamRole.Arn
Environment:
Variables:
API_SECRET: /api/endpoint1/secret
API_SERVICE_PRINCIPAL: /api/endpoint1/service-principal
BUCKET_NAME: !Sub ${SystemName}-${EnvName}-fetching-data-bucket-${AWS::AccountId}
Layers:
- !Ref AWSTestFetchingDataFunctionModulesLayer
- !Sub "arn:aws:lambda:${AWS::Region}:580247275435:layer:LambdaInsightsExtension:60"
requests
S3バケット作成
S3バケットは、最小限の設定(パブリックアクセスを明確にブロック)にしています。ここは要件によってバージョニングの有効化やライフサイクルルールを設定するかと思います。
#=========================================================================#
# データ保管用 バケット
#=========================================================================#
AWSTestFetchingDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub ${SystemName}-${EnvName}-fetching-data-bucket-${AWS::AccountId}
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
Lambda関数のコード
今回、Lambda関数のコードはPythonで記述します。処理としては、APIに対してリクエストを送って、そのデータをファイルの保存してZIP圧縮してS3バケットに保存しています。
なお、今回のコードは部分的にサンプル値を使用しているため、参考にする場合は適宜書き換えてから実行するようにしてください。
import datetime
import gzip
import json
import logging
import os
import shutil
from datetime import datetime
from zoneinfo import ZoneInfo
import boto3
import requests
from requests.auth import HTTPBasicAuth
logger = logging.getLogger()
logger.setLevel(logging.getLevelName(os.getenv("LOG_LEVEL", "INFO")))
ssm = boto3.client("ssm")
s3 = boto3.client("s3")
# SSM Parameter Storeからパラメータを取得する
def get_ssm_parameter(name):
response = ssm.get_parameter(Name=name, WithDecryption=True)
return response["Parameter"]["Value"]
# APIからログを取得する
def fetch_logs(endpoint, secret, service_principal, temp_file_path):
try:
# HTTPリクエストを送信してログデータを取得する
response = requests.get(endpoint, auth=HTTPBasicAuth(secret, service_principal))
# レスポンスのHTTPステータスコードが200番台であれば、try部分を実行
# レスポンスのHTTPステータスコードが200番台意外なら、except部分を実行
response.raise_for_status()
with open(temp_file_path, "w") as f:
json.dump(response.json(), f)
except requests.RequestException as e:
logger.error(f"An error occurred while fetching logs: {str(e)}", exc_info=True)
raise
# ログファイルを圧縮してS3にアップロードする
def upload_to_s3(temp_file_path, temp_file_gz_path, bucket_name, request_time):
s3_object_path = request_time.strftime("%Y/%m/%d")
s3_object_id = request_time.strftime("%Y%m%d%H%M%S")
s3_key = f"{s3_object_path}/ppsiem_rowlog_{s3_object_id}.log.gz"
try:
# ファイルの内容をコピーして、圧縮ファイルを作成する
with open(temp_file_path, "rb") as gzip_in:
with gzip.open(temp_file_gz_path, "wb") as gzip_out:
shutil.copyfileobj(gzip_in, gzip_out)
# 圧縮ファイルをS3にアップロードする
with open(temp_file_gz_path, "rb") as f_in:
s3.upload_fileobj(f_in, bucket_name, s3_key)
logger.info(f"Successfully uploaded log to S3: {s3_key}")
except Exception as e:
logger.error(f"Failed to upload log to S3: {str(e)}", exc_info=True)
raise
def lambda_handler(event, context):
try:
# 環境変数を取得する
endpoint_parameter = os.environ.get("API_ENDPOINT")
secret_parameter = os.environ.get("API_SECRET")
service_principal_parameter = os.environ.get("API_SERVICE_PRINCIPAL")
s3_bucket_name = os.environ.get("BUCKET_NAME")
# AWS SSM Parameter Store からパラメータを取得する
endpoint = get_ssm_parameter(endpoint_parameter)
secret = get_ssm_parameter(secret_parameter)
service_principal = get_ssm_parameter(service_principal_parameter)
# 現在時刻(日本時間)を取得する
request_time = datetime.now(ZoneInfo("Asia/Tokyo"))
# 一時ファイルを作成する
temp_log_file_path = "/tmp/temp.log"
temp_log_file_gz_path = f"{temp_log_file_path}.gz"
# APIからログを取得する
fetch_logs(
endpoint,
secret,
service_principal,
temp_log_file_path,
)
# ログが書き込まれた一時ファイルを、S3にアップロードする
upload_to_s3(
temp_log_file_path, temp_log_file_gz_path, s3_bucket_name, request_time
)
# 一時ファイルを削除する
os.remove(temp_log_file_path)
os.remove(temp_log_file_gz_path)
return {"statusCode": 200, "body": "Log fetching completed successfully"}
except Exception as e:
logger.error(f"An error occurred in lambda_handler: {str(e)}", exc_info=True)
return {"statusCode": 500, "body": "An error occurred during execution"}
S3アップロード部分
このコードの中でも、S3アップロード部分は少し複雑かと思っています。具体的には、一時ファイルから圧縮後の一時ファイルへデータの内容をコピーして圧縮し、この圧縮後のファイルをS3に保存している形になります。
# ログファイルを圧縮してS3にアップロードする
def upload_to_s3(temp_file_path, temp_file_gz_path, bucket_name, request_time):
s3_object_path = request_time.strftime("%Y/%m/%d")
s3_object_id = request_time.strftime("%Y%m%d%H%M%S")
s3_key = f"{s3_object_path}/ppsiem_rowlog_{s3_object_id}.log.gz"
try:
# ファイルの内容をコピーして、圧縮ファイルを作成する
with open(temp_file_path, "rb") as gzip_in:
with gzip.open(temp_file_gz_path, "wb") as gzip_out:
# 一時ファイルから圧縮後の一時ファイルへデータ内容をコピー
shutil.copyfileobj(gzip_in, gzip_out)
# 圧縮ファイルをS3にアップロードする
with open(temp_file_gz_path, "rb") as f_in:
s3.upload_fileobj(f_in, bucket_name, s3_key)
logger.info(f"Successfully uploaded log to S3: {s3_key}")
except Exception as e:
logger.error(f"Failed to upload log to S3: {str(e)}", exc_info=True)
raise
Lambda => S3のデータ保存処理は意外とシンプル
以上、半分私が忘れないために書いたような内容でしたが、全体を通してそこまで複雑な処理は出てこない印象でした。
ちなみに、Lambdaの処理がうまく実行されない場合は、LambdaのIAMロールが適切でなかったり、ライブラリの更新をLambdaレイヤーに反映し忘れてたりするのが原因であることが多いです。デプロイや実行に詰まるようであれば、こういった部分をチェックしてみてください。
こちらの内容が参考になれば幸いです。では!









