
DynamoDB 障害から学ぶ AWS サービスの依存関係と設計
こんにちは!CX 事業本部製造ビジネステクノロジー部所属の hongki です。
去年の 2025 年 10 月に AWS のバージニア北部(us-east-1)リージョンで大規模な障害がありました。
約 14 時間にわたって複数のサービスに影響が出て、ゲームサーバーはもちろん、Zoom、Photoshop、Apple Music、Alexa など有名なサービスも影響を受けました。
私自身もその日、AI をはじめいくつかのサービスを使おうとしたところ、アクセスができず、手が止まったりしてました。
なぜこれほど多くのサービスが同時に止まったのか気になり、この記事を書くことになりました。
この記事では上記の AWS が公開した障害の調査報告を参考に、
今回の障害で何が起きたのかをわかりやすく解説していきたいと思います。
事象の概要
| 項目 | 内容 |
|---|---|
| 発生時刻 | 2025 年 10 月 20 日 午後 3:48 (JST) |
| 復旧完了 | 2025 年 10 月 21 日 午前 6:09 (JST) |
| 影響リージョン | us-east-1(バージニア北部) |
| 総復旧時間 | 約 14.5 時間 |
AWS サービス構造を理解する
私たちがパソコンを組み立てる時にパーツを調達するように、企業もサーバー用コンピューターが必要な時は AWS、Google Cloud、Azure などからサーバーを借りて使います。
その中でも DynamoDB という、データを key-value 形式で保存するサーバーレスデータベースがありますが、
多くの AWS サービスが内部的にこの DynamoDB を利用していました。
今回の事象は DynamoDB の DNS 管理システムに潜んでいたバグから始まりました。
障害に関連する DynamoDB の依存関係
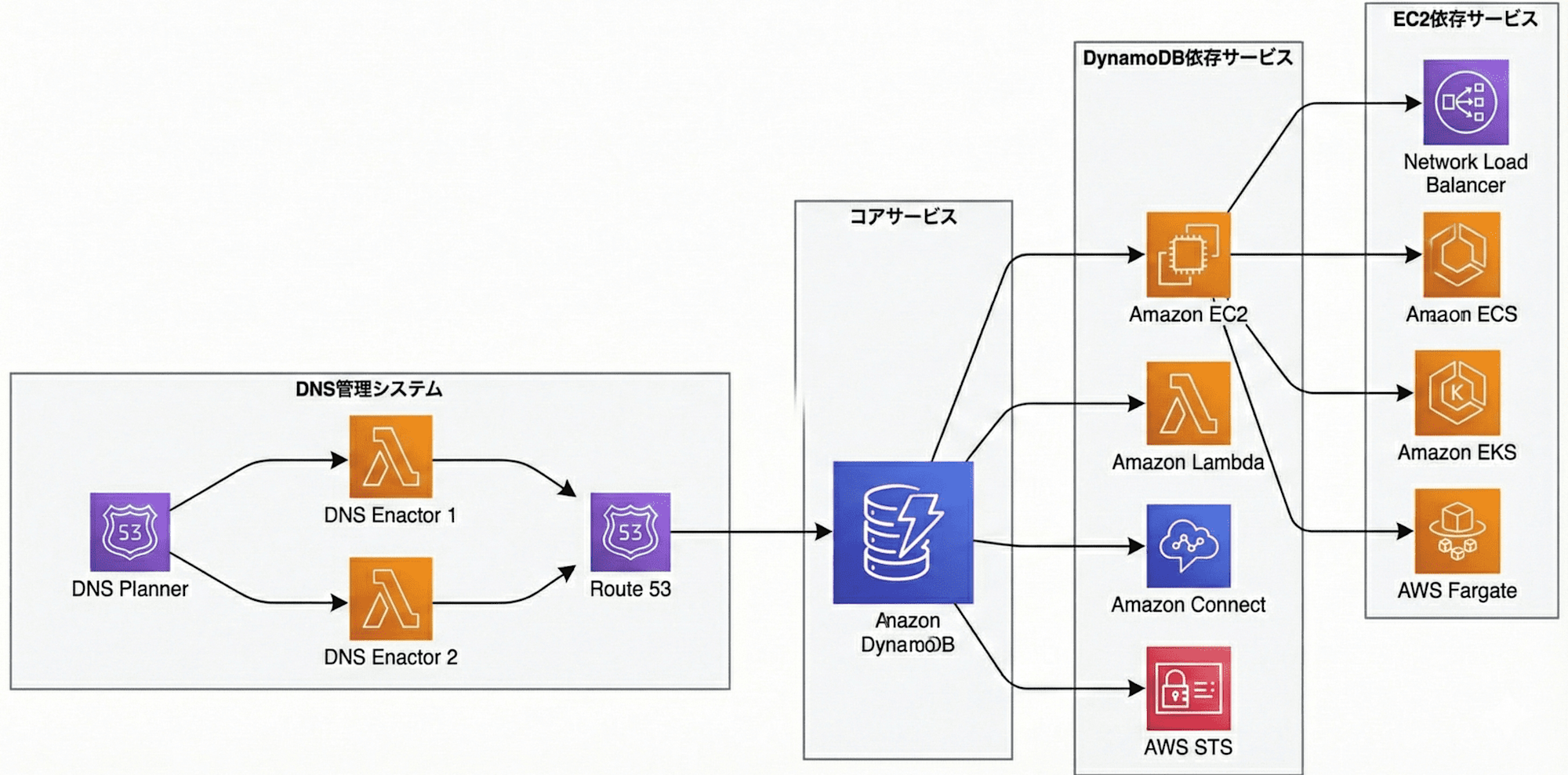
この図からわかるように、DynamoDB は多くのサービスと紐付いています。
この他にも多くのサービスと連携しており、AWS の中核を担う重要なサービスです。
それでは、今回のバグと関連があり、連鎖的に障害が発生したサービスをひとつずつ紹介したいと思います。
DNS とは?
私たちが Google にアクセスする時、本来は IP アドレスを入力する必要があります。
でも google.com のようなドメイン名を入力してもアクセスできますよね?これを可能にしているサービスが DNS です。
DynamoDB もこの DNS サービスを利用しています。
dynamodb.us-east-1.amazonaws.com のようなドメインを入力すると、自動的に DynamoDB サーバーの IP アドレスに変換してくれる役割を担っています。
DNS 自動管理システム
しかし、このDNSを自動で管理するコードに問題が発生したとのことです。
まず、DynamoDB のような大規模サービスはサーバーを複数の場所に分散させて運用しているため、DNS Plan という内部システムを通じてトラフィックを分散させていました。
DNS Plan は人が管理するものではなく、 DNS Planner という自動化されたシステムがサーバーの状態をモニタリングし、サーバーが非効率的に動作している場合に新しい DNS Plan を作成して、トラフィックを分散させる仕組みです。
DNS Enactor というもう一つのシステムが、この DNS Plan を実際に Route53 に反映する役割を担っています。
このシステムは3つの Availability Zone にまたがって分散されており、Transaction 方式で安全に動作するように設計されています。
| システム | 役割 |
|---|---|
| DNS Planner | サーバーの状態を監視し、新しい DNS Plan を自動生成 |
| DNS Enactor | DNS Plan を実際に Route53 に適用(3つの AZ に分散運用され、Transaction 方式で安全に動作するよう設計) |
問題発生の流れ - Race Condition を理解する
今回の事象の原因は Race Condition(競合状態) というソフトウェアバグでした。
簡単に言うと、2 つの処理が同時に動いてしまい、お互いの作業を邪魔してしまう問題です。
この DNS Enactor システムに問題が発生しました。
DNS Planner から作成された Old Plan を1番目の DNS Enactor が処理していたのですが、この処理が通常より時間がかかってしまいました。
そのため、処理している最中に次の New Plan が2番目の DNS Enactor に渡され、この2番目の DNS Enactor が先に New Plan を処理してしまいました。
その後、1番目の DNS Enactor が Old Plan の処理を終えたのですが、この Old Plan は New Plan より古い Plan だったため、Old Plan が New Plan を上書きしてしまいました。
さらに、古い Plan が存在する場合にそれを削除するプロセスも存在しており、この削除プロセスが現在稼働中の Old Plan を削除してしまいました。
稼働中の Plan 削除により、リージョンエンドポイントのすべての IP アドレスが即座に削除され、以降の DNS 更新も適用できない状態になりました。
その結果、特定ドメインに対する DNS 解決が失敗するようになり、DynamoDB にアクセスできなくなりました。
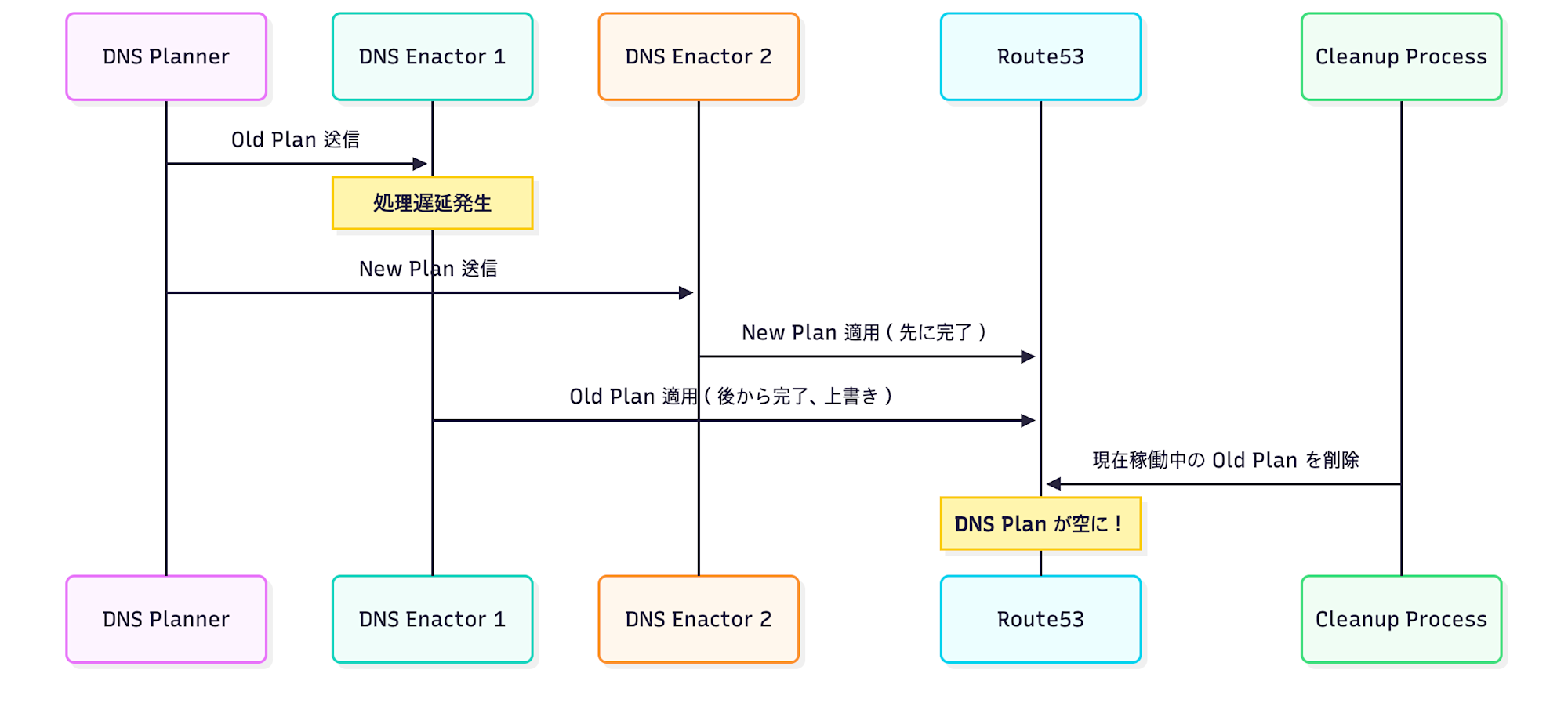
▲ タイミングのずれにより、稼働中の Plan が「古い」と判断され削除されてしまう流れ
DynamoDB 復旧時間: 約 3 時間(午後 3:48 ~ 午後 6:40 JST)
EC2(サーバーレンタルサービス)
EC2 はサーバー用コンピューターをレンタルするサービスです。
DynamoDB にアクセスできなくなると、新しいコンピューターをレンタルできなくなりました。
理由としては、EC2 は内部的に DynamoDB を利用してコンピューターのメタデータ(レンタル可能なリストなど)を管理しているためです。
DynamoDB の問題が解決した後も、溜まっていたリクエストが一斉に押し寄せて、コンピューターレンタル担当サービスである DWFM(Droplet Workflow Manager) にリクエストが殺到し、処理しきれなくなったのです。
AWS 側の対応としてワークロードをスロットリングし、DWFM ホストを選択的に再起動することで対応しました。
しかし、 DWFM が復旧されると、今度はレンタルしたコンピューターのインターネットが切断される問題が発生しました。
EC2 のネットワーク設定を管理する Network Manager が、溜まっていた設定変更のバックログを一斉に処理しようとしたため、大幅な遅延が発生したためです。
EC2 復旧時間: 約 14 時間(10 月 20 日 午後 3:48 ~ 10 月 21 日 午前 5:50 JST)
NLB(Network Load Balancer)
NLB はサーバーに入ってくるトラフィックを複数の EC2 サーバーに分散させるサービスです。
このサービスは定期的に EC2 サーバーの状態を確認(Health Check)していますが、EC2 サーバーの状態が継続的に不安定になると、NLB Node も不安定になり、接続エラーが発生しました。
AWS 側は自動フェイルオーバーを一時的に無効化し、手動で対応することで状況を安定させました。
NLB 復旧時間: 午後 9:30 ~ 午前 6:09 JST(10 月 20 日 ~ 21 日)
Lambda
Lambda はサーバーレスコンピューティングサービスで、サーバーを直接管理せずにコードを実行できるようにしてくれます。
Lambda はコードをアップロードすると、コードに関する情報を DynamoDB に保存しますが、DynamoDB にアクセスできなくなったため、Lambda コードの実行が遅延または失敗するようになりました。
このため Lambda 関連の backlog が溜まり、SQS(メッセージキューシステム)のキューポーリングサブシステムにも障害が発生しました。
その他の影響を受けたサービス
上記のサービス以外にも、以下のサービスが影響を受けました。
- Amazon Connect: クラウド型コンタクトセンターサービス(通話処理、チャット、ケース管理に影響)
- STS(Security Token Service): 認証トークンの発行に遅延
- Amazon Redshift: クラスター操作やクエリ実行時に API エラー
- ECS / EKS / Fargate: コンテナの起動やクラスターのスケーリングに影響
- AWS Management Console: STS の遅延により、コンソールへのログインが不安定に
影響を受けたサービスの全体像
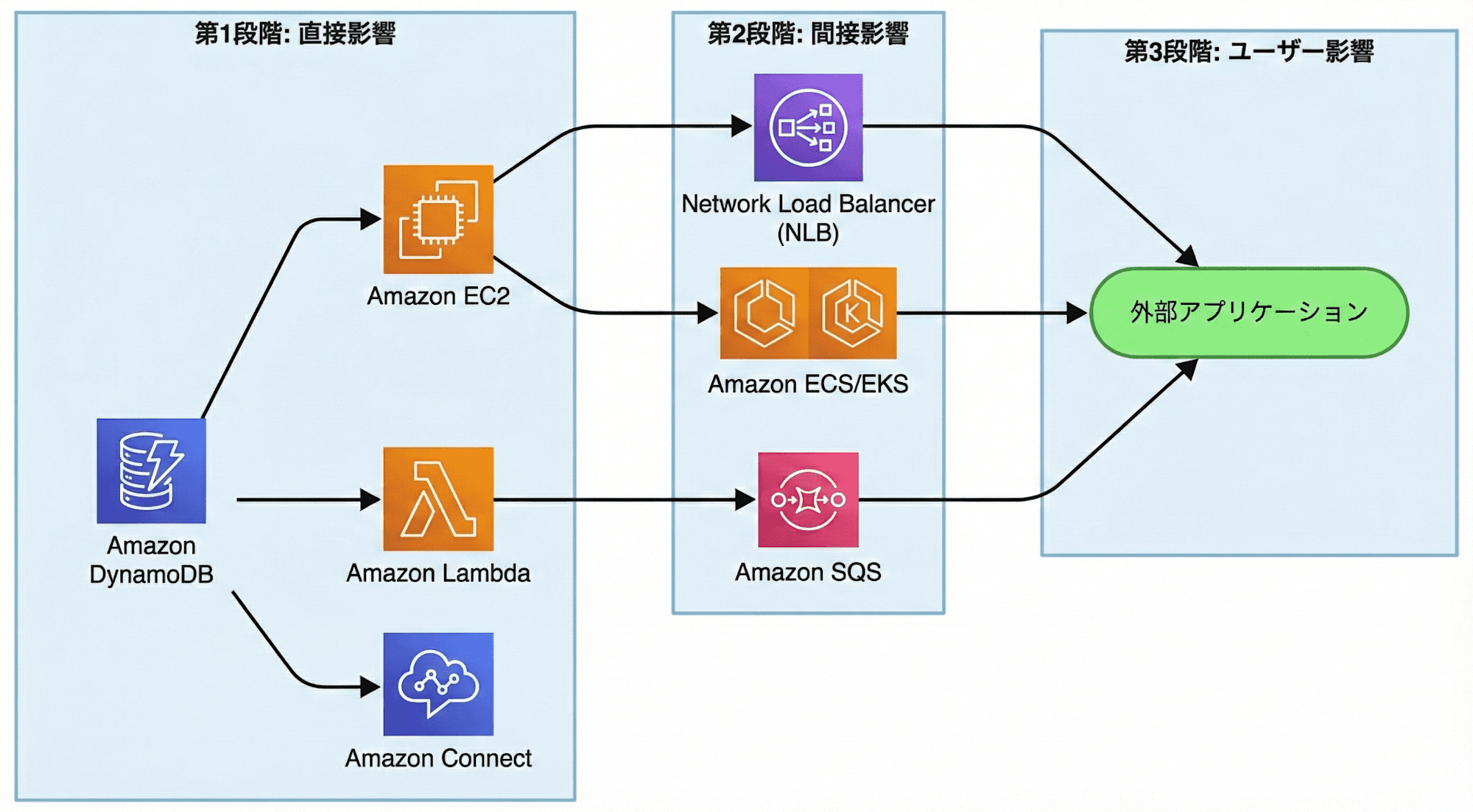
まとめ
今回の事象は、クラウドアーキテクチャ設計において重要な教訓を与えてくれます。
DynamoDB という一つのサービスの障害が、EC2、Lambda、NLB など多くのサービスに連鎖的に広がりました。
このようなリスクを軽減するためには、以下のような設計が推奨されます。
- マルチリージョン構成: 重要なサービスほど複数のリージョンに分散させ、一つのリージョンに障害が発生しても他のリージョンでサービスを継続できるようにする
- 障害分離(Fault Isolation): コアサービスに問題が発生しても、他のサービスが独立して動作できるように設計し、障害の影響範囲を最小限に抑える
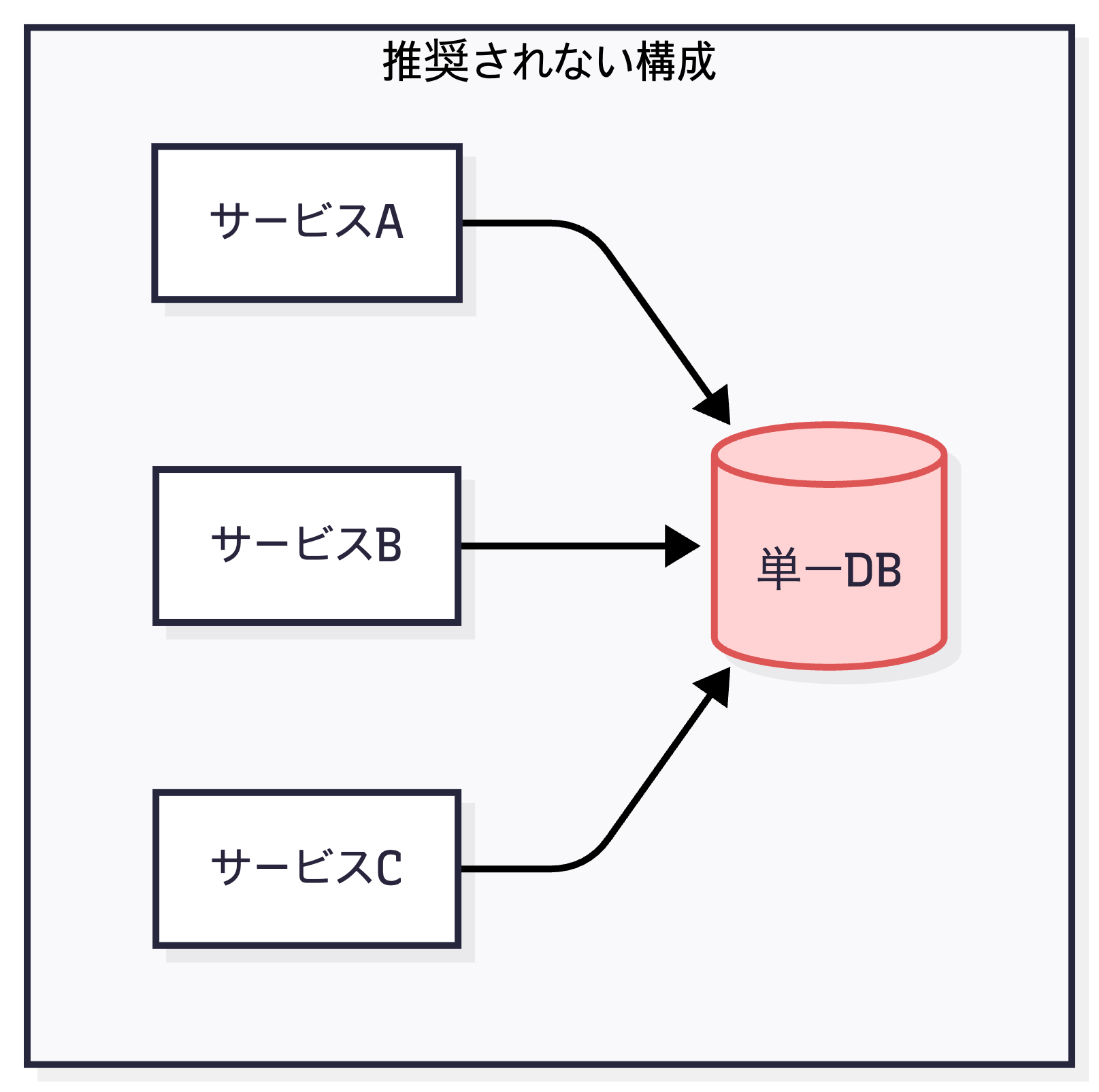
▲ 単一DBに全サービスが依存する構成(非推奨)
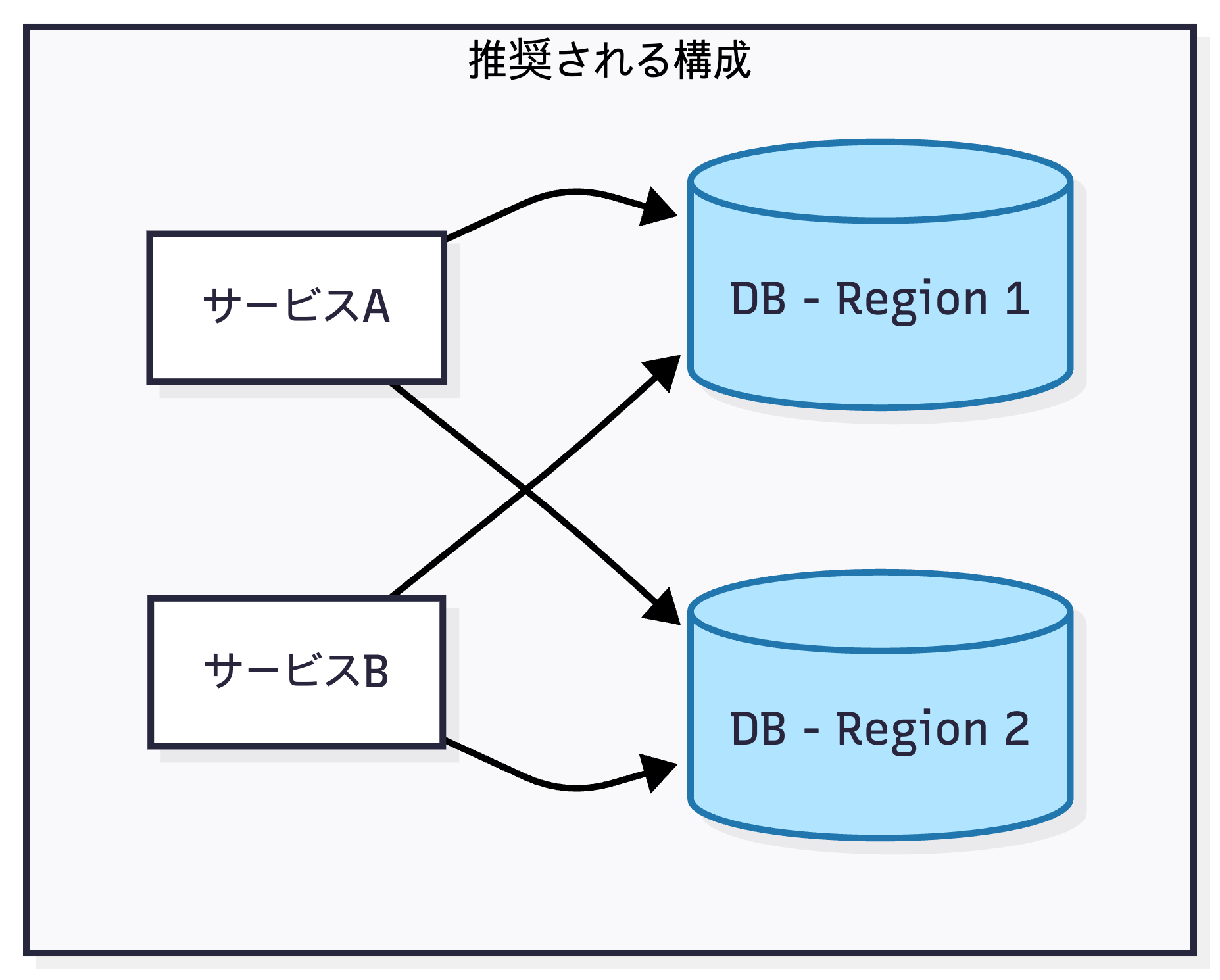
▲ 複数リージョンに分散し、クロスリージョンで接続する構成(推奨)
今回の事象は確かに多くのサービスに影響を与えましたが、同時にクラウドサービスがどのように構成されているのか、そしてより安定したシステムを設計するにはどうすれば良いのかを学ぶ良い機会でもありました。
AWS もこの事象を通じてシステムをさらに強化しましたし、私たちもこのような事例を通じてより良いアーキテクチャを設計できるようになると思います。
クラウドサービスを利用する際は、リージョン単位での障害も考慮した設計を心がけたいですね。









