
国税庁 FAQ × RAFT で Nemotron 9B-v2 の RAG 精度を上げてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
以前の記事で Nemotron 9B-v2-Japanese の RAG(検索拡張生成)を試した際、架空の社内規定を「参考文書」として渡して質問に答えさせるテストをしました。ベースモデルでもそれなりに文脈を拾ってくれましたが、参考文書に答えがないときにハルシネーション(もっともらしい嘘)を返す場面がありました。
では、実際のドメインデータで学習したら、この精度はどこまで上がるのか?
その疑問を検証するため、国税庁の FAQ データセットで RAG に特化したファインチューニングをやってみました。ちょうど確定申告シーズンですし、税務 FAQ なら検証としても実用としてもイメージしやすいかなと思いました。手法は RAFT(Retrieval Augmented Fine Tuning)で、学習データは 1,000 件です。
ソブリン AI の流れもあり、自社データを外部に出さずにモデルをドメイン特化させたいニーズは増えています。今回は NGC コンテナを活用することで、学習から推論評価まですべて DGX Spark 上で完結させてみました。クラウド GPU は不要で、かかったコストは CoT 生成の $2 だけです。DGX Spark をお持ちの方や、自分のドメインデータで RAG 精度を改善したい方の参考になれば幸いです。
RAFT とは
RAFT(Retrieval Augmented Fine Tuning)は、RAG パイプラインの「回答生成」部分を改善するファインチューニング手法です(arXiv:2403.10131)。
通常の RAG では、検索エンジンが取得した文書をそのまま LLM に渡して回答を生成します。LLM が文書中の正解箇所を正確に見つけられるかどうかは、モデルの汎用的な読解力に依存しています。RAFT はここに手を加えて、「関連文書の中から正解を引用して回答する」スキルを直接学習させます。
学習データの作り方は以下のとおりです。
- 質問に対する正解文書(オラクル)と、関連するが答えを含まないダミー文書(ディストラクター)を用意する
- 80% のサンプルにはオラクルを含め、20% のサンプルにはオラクルを含めない
- オラクルありの場合は、正解箇所を引用した上で推論する CoT(Chain-of-Thought)形式の回答を付与する
- オラクルなしの場合は、「回答できません」という回答を付与する
モデルは「文書の中から正解を見つける」タスクと「正解がないときに正直に言う」タスクの両方を同時に学習します。ディストラクターが混ざっている状況に慣れるので、実際の RAG パイプラインで検索精度が完璧でなくても頑健に回答できるようになるのが狙いです。
国税庁 FAQ で RAFT データセットを作る
JaGovFaqs-22k の概要
学習データには JaGovFaqs-22k(CC BY 4.0)を使わせていただきました。日本の各省庁が公開している FAQ を約 22,800 件収集したデータセットで、質問文と回答文がペアになっています。
データを探索してみると、回答文の長さは 50-2,000 文字の範囲にほとんどが収まっていて、RAG の参考文書としてちょうどいいサイズ感です。copyright フィールドに省庁名が入っているので、これを使って分野を絞り込めます。
サンプリング
22,800 件全部を使う必要はありません。RAFT 論文でも数千件規模で効果が確認されていますし、今回は後述する LoRA カバー率の制約もあるので、1,000 件に絞りました。
今回は国税庁の FAQ に集中投下しています。41 省庁に薄く分散させるのではなく、税務という単一ドメインに 1,000 件を集めることで、RAFT のディストラクター(答えを含まないダミー文書)が自然に「同じ税務トピックだが答えは違う」というハードネガティブになります。フィルタ後の国税庁 FAQ は約 2,476 件あるので、1,000 件のサンプリングには十分な余裕があります。
テスト用には国税庁から別途 200 件を確保し、さらに他省庁の FAQ 100 件を test-unseen として切り出しました。税務特化モデルが他の行政ドメインでどう振る舞うかを見るためです。
| 分割 | 件数 | ソース | 用途 |
|---|---|---|---|
| train | 1,000 + 100 | 国税庁 | RAFT 学習(うち 100 件は「回答不可」追加) |
| test | 200 | 国税庁 | EM/F1 評価 |
| test-unseen | 100 | 他省庁 | 他ドメインでの汎化評価 |
RAFT 形式への変換
サンプリングした FAQ を RAFT 形式に変換するスクリプトを書きました。処理の流れはシンプルです。
- 各質問に対し、同じ国税庁内の他の FAQ 回答をディストラクターとして 4 件選ぶ(同じ税務ドメインの文書はトピックが近いため、より難しいネガティブサンプルになる)
- 80% のサンプルには正解の FAQ 回答(オラクル)を混ぜ、20% はディストラクターだけにする
- オラクルありのサンプルでは、Claude API(Haiku)に引用付きの CoT 回答を生成させる
- 追加で 100 件の「回答不可」サンプルを混入し、計 1,100 件の学習データを作る
CoT 回答の生成コストは Claude Haiku で約 $2 でした。生成後に 50 件をランダムに抽出して手動チェックし、引用の正確性とフォーマットの一貫性を確認しています。ローカルのモデルではいまいち精度が安定せず、今回は学習データの作成にだけクラウドモデルを使用しています。(プロンプトなどの工夫で解消できた可能性はあります。)
最終的な出力は SFT(Supervised Fine-Tuning)用の JSONL 形式で、system / user / assistant の messages 構造になっています。
学習データのサンプル(1 件)
{
"messages": [
{
"role": "system",
"content": "あなたは税務に関する質問に答えるAIアシスタントです。提供された参考文書を基に正確に回答してください。..."
},
{
"role": "user",
"content": "以下の参考文書を基に質問に答えてください。\n\n参考文書1:\n...\n\n参考文書2:\n...\n\n質問: 医療費控除の対象となる医療費の範囲は?"
},
{
"role": "assistant",
"content": "参考文書3に「医療費控除の対象となる医療費は、...」と記載されています。この規定に基づくと、...したがって、対象範囲は...です。"
}
]
}
Mamba2 + LoRA の制約
全パラメータの 53% しか学習できない
Nemotron 9B-v2-Japanese は Mamba-2 と Transformer のハイブリッドアーキテクチャを採用しています。56 層のうち 27 層が Mamba-2(SSM)、4 層が Self-Attention、25 層が FFN(MLP)という構成です。
LoRA で学習しようとすると、ここで問題が発生します。Mamba-2 層の in_proj と out_proj は PEFT ライブラリの LoRA に対応していません(PEFT Issue #2274)。Mamba-2 は独自の CUDA カーネルが重みテンソルを直接参照する設計になっており、LoRA が差し込むフック(forward hook)を経由しないのが原因です。
回避策として、Attention 層と FFN 層のみに LoRA を適用しました。パラメータカバー率は 53% です。
| レイヤー種別 | 層数 | パラメータ割合 | LoRA 適用 |
|---|---|---|---|
| Self-Attention | 4 | ~8% | 可 |
| FFN (MLP) | 25 | ~45% | 可 |
| Mamba-2 (SSM) | 27 | ~47% | 不可 |
パラメータの半分近くが凍結された状態で RAFT の効果が出るかどうか。正直、この時点では半信半疑でした。ただ、ネガティブな結果でも「Mamba2 凍結 + LoRA で RAG FT は効くのか」という問いに対する答えになるので、そのまま進めることにしました。
QLoRA は Mamba-2 と非互換
メモリを節約したいなら QLoRA(NF4 量子化 + LoRA)を使いたくなりますが、Nemotron-H では QLoRA も動きません。先ほどと同じ根本原因で、Mamba-2 の CUDA カーネルが重みを直接参照する設計になっています。bitsandbytes の NF4 量子化は重みのデータ型とメモリレイアウトを変換してしまうため、Mamba-2 カーネルが期待するメモリ表現と合わずにクラッシュします。
しかも LoRA を Mamba-2 層に適用しない場合でも、NF4 でモデルをロードする時点で全層の重みが量子化されるため、推論パスで同じエラーが起きます。つまり QLoRA は「LoRA を当てない層がある」問題ではなく、「そもそもモデルをロードできない」という根本的な非互換です。
幸い DGX Spark は 128GB の統合メモリを搭載しているので、BF16 のままモデルをロードしても約 18GB で済みます。今回は、QLoRA が使えないなら BF16 LoRA でいこう、という判断になりました。
NGC コンテナで SM 12.1 問題を突破
もうひとつの壁が GPU アーキテクチャです。DGX Spark の GB10 GPU(Compute Capability 12.1、以下 SM 12.1)では、pip でインストールした PyTorch だと Mamba-2 の融合カーネルが未対応で出力が壊れてしまいます。当初は「学習はクラウド、推論はエッジ」のハイブリッド構成を覚悟していましたが、NGC コンテナで解決できました。
NGC コンテナで BF16 LoRA 学習
コンテナ構成
NGC の NeMo コンテナ(nvcr.io/nvidia/nemo:25.11.01)には SM 12.1 対応の PyTorch と CUDA 13.0 が同梱されており、ARM64 にも対応しています。コンテナ内であれば融合カーネルも正しく動作するので、DGX Spark 上で学習から推論まで完結できます。追加で必要なのは trl(SFTTrainer)だけで、peft、datasets、transformers などはプリインストール済みです。
docker run --gpus all --rm --ipc=host \
--ulimit memlock=-1 --ulimit stack=67108864 \
-v /home/username/works:/workspace \
-v /home/username/.cache/huggingface:/root/.cache/huggingface \
nvcr.io/nvidia/nemo:25.11.01 \
bash -c '
pip install -q trl
python3 /workspace/.../n3-nemo-train.py \
--backend hf-peft \
--data-file /workspace/.../train.jsonl \
--output-dir /workspace/.../ngc-adapter
'
HuggingFace のキャッシュをマウントしているので、モデルの再ダウンロードは不要です。コンテナ起動から学習開始まで、trl のインストールを含めて 2 分程度でした。
BF16 LoRA 設定
QLoRA の代わりに BF16(量子化なし)でモデルをロードし、LoRA アダプターを Attention 層と FFN 層の全プロジェクションに適用しています。
| 項目 | 設定 |
|---|---|
| 量子化 | なし(BF16) |
| LoRA rank | 16 |
| LoRA alpha | 32 |
| LoRA dropout | 0.05 |
| ターゲット | Attention + FFN の全 proj |
| 学習率 | 2e-4(cosine) |
| エポック | 1 |
| 実効バッチサイズ | 8(bs=1 × grad_accum=8) |
| 最大シーケンス長 | 4,096 |
| オプティマイザ | AdamW(torch) |
メモリの見積もりはこうなります。
- モデル(BF16): ~18GB
- LoRA アダプター: ~0.5GB
- オプティマイザ状態: ~1GB
- KV キャッシュ + アクティベーション: ~10GB
- 合計: ~30GB
DGX Spark の 128GB 統合メモリに対して 30GB 程度なので、余裕を持って学習できます。
学習結果
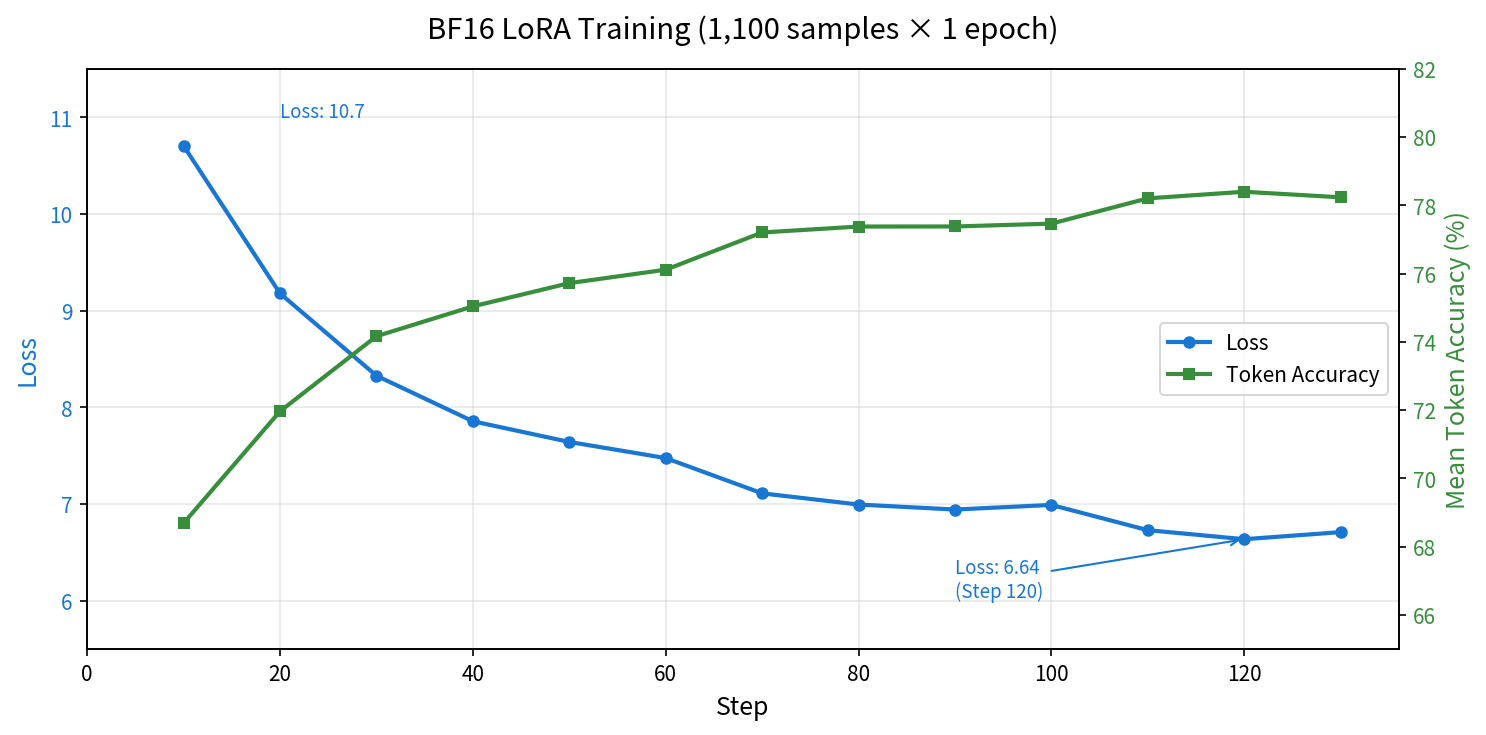
1,100 サンプル × 1 エポックで 138 ステップ、約 55 分で完了しました。Loss は 10.71 から 6.64 まで低下し、Mean Token Accuracy は 68.7% から 78.4% に上昇しています。
| ステップ | Loss | Token Accuracy |
|---|---|---|
| 10 | 10.71 | 68.7% |
| 50 | 7.64 | 75.7% |
| 100 | 6.99 | 77.5% |
| 120 | 6.64 | 78.4% |
| 138(完了) | 6.71 | 78.3% |
ステップ 120 あたりで Loss が底を打ち、そこからわずかに上昇しています。1 エポックなのでオーバーフィッティングではなく、学習率の cosine スケジュールが最終段階に入った影響でしょう。
GGUF 変換と Ollama 登録
学習済みの LoRA アダプターを GGUF 形式に変換します。llama.cpp の convert_lora_to_gguf.py を使いますが、Nemotron 9B-v2-Japanese は trust_remote_code=True が必要なカスタムモデルなので、--base オプションでローカルの HuggingFace キャッシュを直接指定するのがポイントです。--base-model-id だとインタラクティブな確認プロンプトが出てスクリプト実行がブロックされます。
# LoRA アダプターを GGUF に変換
python llama.cpp/convert_lora_to_gguf.py \
./ngc-adapter/adapter \
--outfile nemotron-9b-raft-lora-ngc.gguf \
--base ~/.cache/huggingface/hub/models--nvidia--NVIDIA-Nemotron-Nano-9B-v2-Japanese/snapshots/<hash>
変換後のアダプターは 36.1MB(132 テンソル、BF16)でした。これを Ollama に ADAPTER 方式で登録します。
# Ollama に ADAPTER 方式で登録
cat <<'EOF' > Modelfile-raft
FROM nemotron-9b-jp-nothink
ADAPTER nemotron-9b-raft-lora-ngc.gguf
EOF
ollama create nemotron-9b-jp-raft -f Modelfile-raft
ベースモデルには nemotron-9b-jp-nothink(thinking を無効化したバージョン)を使っています。RAG の評価で <think> タグの内容がノイズになって EM(完全一致)が 0 になる問題があったため、nothink 版をベースにしたほうが正確なメトリクスが得られると考えたためです。
Modelfile でカスタムテンプレートを書く場合、特殊トークンの扱いに注意が必要です。Nemotron 9B-v2-Japanese では <extra_id_0> ではなく <SPECIAL_10> のような単一トークンが正しい表現で、誤ったトークンを使うと精度が落ちます。FROM nemotron-9b-jp-nothink として以前の記事で設定済みの正しいテンプレートをそのまま使っています。
評価結果
定量評価(F1)
test 200 件でトークンレベル F1(予測と正解の単語重複に基づく一致率)を計測しました。Exact Match(EM)は両モデルとも 0.0 です。RAFT 学習後のモデルは「参考文書 X に〜と記載されています」という引用付き CoT 形式で回答するため、正解テキストとの完全一致は原理的に成立しません。F1 のほうが実質的な精度を反映しています。
| 構成 | F1 | 回答不可 FP | 回答不可 TN |
|---|---|---|---|
| Baseline(ベース + RAG プロンプト) | 0.5646 | 47 | 153 |
| RAFT FT(学習済み + RAG プロンプト) | 0.6536 | 3 | 197 |
| 差分 | +0.089 | -44 | +44 |
F1 が +8.9 ポイント 改善しました。ただ、それ以上にインパクトが大きいのは回答不可の誤判定(FP)の激減です。Baseline は 200 件中 47 件(23.5%)で「参考文書からは回答できません」と誤って拒否していたのに対し、RAFT FT ではわずか 3 件(1.5%)に減っています。
改善幅の大きかった上位 5 件を見ると、いずれも Baseline では F1 が 0.0(回答拒否)だったのが、RAFT FT で 0.8 前後まで回復しています。税務の専門用語が多い質問や、複合的な条件を含む質問で特に効果が出ている印象です。
一方で退行も確認されました。上位 5 件の退行では F1 が 0.3-0.4 ポイント低下しています。RAFT 学習によって回答の形式が変わった(引用 + 推論の CoT 形式になった)ことで、もともと素直に回答できていた質問の F1 が下がったケースです。
JCQ 退行チェック
ドメイン特化の学習でモデルの汎用能力が落ちていないかを確認するため、JCommonsenseQA(1,119 問)でベースラインとの比較を行いました。ベースラインは以前の記事と同じ条件(Ollama + BF16 GGUF、thinking OFF)で計測しています。N1 で確認したとおり推論エンジンによって 7.7 ポイントの差が出るため、FT 前後の比較は同一エンジンで揃えることが前提です。
| モデル | JCQ 正答率 | 差分 |
|---|---|---|
| 9B-v2-Japanese(ベース) | 92.0%(1029/1119) | - |
| 9B-v2-Japanese(RAFT FT) | 91.5%(1024/1119) | -0.5pp |
差分は -0.5 ポイントで、ほぼ誤差の範囲です。税務ドメインに特化した RAFT 学習を行っても、日本語の常識推論能力はほとんど損なわれていないことが確認できました。
定性評価
テストデータから特徴的なケースを抽出して、Baseline と RAFT FT の回答を比較しました。
改善例: Baseline が回答拒否 → RAFT FT が正答
Baseline が「提供された情報からは回答できません」と拒否していた質問に、RAFT FT は参考文書を引用して正確に回答しています。
AEO 通関業者の輸出免税(F1: 0.000 → 0.828)
質問: AEO 通関業者が関与する輸出申告について、保税地域等以外の場所における輸出貨物に係る役務の提供は、輸出免税の対象となりますか。
Baseline の回答:
提供された情報からは回答できません。
RAFT FT の回答:
参考文書2に「AEO通関業者に委託した者が行う輸出申告に係る貨物については、
消費税法施行令第17条第2項第4号に規定する特例輸出貨物に該当し、保税地域等
及び特例輸出貨物の輸出のための船舶又は航空機への積込みの場所における役務の
提供並びに保税地域等相互間の運送に限り、輸出類似取引として消費税が免除されます」
と記載されています。
Baseline は参考文書に答えがあるにもかかわらず拒否しています。RAFT FT は参考文書 2 の該当箇所を正確に引用した上で回答しており、CoT 形式の学習効果が出ています。
確定申告シーズンに身近な質問 3 選
ちょうど確定申告の時期なので、FAQ の中から気になりそうな質問で比較してみました。
医療費控除: ホクロ除去は対象になる?(F1: 0.640 → 0.720)
質問: ホクロを除去するための手術の費用は、医療費控除の対象になりますか。
Baseline の回答:
提供された参考文書1から5のうち、医療費控除に関連する情報が記載されているのは
参考文書4です。
参考文書4には以下のように記載されています:
「容姿を美化し又は容貌を変えるための費用は、疾病の治療のための費用には当たら
ないので、ホクロの除去費用は、医療費控除の対象とはなりません。」
この記述によると、ホクロを除去するための手術は「容姿を美化し又は容貌を変える」
目的に該当すると判断されており、したがって疾病の治療費用には該当しないため、
医療費控除の対象とはなりません。
ただし、ホクロが皮膚がんやその他の疾患によるもので、医師によって「治療目的」
と明確に認められた場合は例外的に医療費控除の対象となる可能性がありますが、
提供された情報にはそのようなケースについての言及が(以下略)
RAFT FT の回答:
参考文書4に「容姿を美化し又は容貌を変えるための費用は、疾病の治療のための
費用には当たらない」と記載されています。ホクロの除去は容姿や容貌を改善する
目的で行われるものであり、医療費控除の対象となる「疾病の治療」に該当しない
ため、医療費控除の対象とはなりません。
したがって、ホクロを除去するための手術の費用は、医療費控除の対象になりません。
どちらも結論は正しいですが、Baseline は参考文書にない推測(「皮膚がんの場合は例外」)を付け加えてしまっています。RAFT FT は参考文書の引用に忠実で、余計な推測を加えていません。
還付申告: どんな場合にできる?(F1: 0.588 → 0.511)
質問: 所得税等の還付申告はどのような場合にできますか。
Baseline の回答:
所得税等の還付申告は、確定申告の必要がない方でも、源泉徴収された税金や
予定納税をした税金が納め過ぎになっている場合に行うことができます(参考文書5)。
RAFT FT の回答:
参考文書5に「確定申告の必要がない方でも、次のいずれかに当てはまる方などで、
源泉徴収された税金や予定納税をした税金が納め過ぎになっている場合には、還付を
受けるための申告(還付申告)により税金が還付されます」と記載されています。
どちらも正確に回答していますが、RAFT FT は引用形式で根拠を明示しています。F1 が下がったのは、引用部分のトークンが正解テキストと完全一致しないためです。
がん保険: 生命保険料控除の対象?(F1: 0.675 → 0.520)
質問: がんに罹患したことにより一定の保険金が支払われるいわゆる「がん保険」の保険料は、生命保険料控除の対象となりますか。
Baseline の回答:
参考文書3によると、「がん保険」の保険料は生命保険料控除の対象となります。
【根拠】所得税法第76条第1項、第2項、第6項、第7項、所得税法施行令第208条
の6第2号に基づき…
RAFT FT の回答:
参考文書3に「『がん保険』の保険料は生命保険料控除の対象となります。」と
記載されています。これは、がん保険も一般的な生命保険と同様に、所得税法上の
「生命保険」に該当するため、生命保険料控除の適用を受けることができることを
意味しており…
正解が「対象となります」の一文だけなので、どちらも余計な解説を加えている分 F1 は低めです。RAFT FT は CoT 形式で丁寧に解説を付けており、人が読む分にはわかりやすいのですが、メトリクス上はペナルティを受けます。
退行例: RAFT FT の要約が過度に簡略化
プロスポーツ選手の簡易課税(F1: 0.893 → 0.479)
質問: プロスポーツ選手は、簡易課税制度の適用上第何種事業に該当するのでしょうか。
Baseline の回答:
プロスポーツ選手は、第五種事業に該当するものとして取り扱われます。
【根拠】参考文書1「プロスポーツ選手は第五種事業に該当するものとして取り扱います。
【関係法令通達】 消費税法施行令第57条第5項」
RAFT FT の回答:
参考文書1に「プロスポーツ選手は第五種事業に該当するものとして取り扱います」
と記載されています。これは、簡易課税制度における取引分類において、プロスポーツ
選手が行う活動が第5種事業(他人の行う事業の補助)に該当することを意味しており...
Baseline が参考文書をほぼそのまま引用して F1 が高かったのに対し、RAFT FT は引用後に独自の解説を加えています。この解説部分に含まれるトークンが正解テキストと乖離しているため、F1 が下がりました。回答の正確性自体は問題ないのですが、F1 メトリクスとしてはペナルティを受ける形です。
考察
53% カバーの LoRA で RAFT は効いたのか
Mamba-2 層が凍結された状態で、Attention と FFN だけの学習で RAG の回答パターンを変えられるのか。それがこの記事の核心的な問いでした。
結果から言えば、パラメータの半分近くが凍結されていても RAFT の効果ははっきり出ました。以前の記事で確認した推論エンジン差(Ollama vs vLLM で JCQ 7.7pp)と比べても、今回の F1 改善幅 8.9pp は同程度のインパクトです。推論エンジンの選定で精度が変わるのと同じくらい、学習データの質でも精度を動かせるということですね。
もっとも、改善の内訳を見ると「F1 が底上げされた」というよりは「回答拒否が激減した結果、ゼロだった F1 が 0.8 前後に回復した」ケースが大きく寄与しています。RAFT の訓練データに「回答不可」サンプルを 100 件混ぜたことで、モデルが「参考文書に答えがある限り回答する」方向に誘導された結果でしょう。逆に言えば、Baseline が 200 件中 47 件で回答を拒否していたという発見自体が重要で、RAG プロンプトだけでは Nemotron 9B-v2-Japanese の過剰な慎重さを制御しきれないことがわかります。
裏を返すと、Baseline が既に正しく回答できている一般的な質問では F1 の改善幅はほとんどありません。今回の改善は「回答拒否の抑制」と「引用付き回答への矯正」に集中しており、これらは学習データの構成、とくに「回答不可」サンプルの混入比率や CoT の引用スタイルに強く依存しています。別のドメインや別の課題(たとえばハルシネーションの抑制)を狙うなら、学習データの設計から見直す必要があるでしょう。
1,000 件 RAFT の費用対効果
今回のコストを整理します。
| 費目 | コスト |
|---|---|
| CoT 生成(Claude Haiku) | ~$2 |
| BF16 LoRA 学習(DGX Spark ローカル) | $0 |
| 合計 | ~$2 |
クラウドの GPU インスタンスを使えば同等の学習に $10 前後かかるので、NGC コンテナでローカル完結できた恩恵は大きいですね。55 分の学習にかかる電気代は無視できるレベルでしょう。
ただし、$2 というのはあくまで API コスト(CoT 生成)と計算資源の話です。実際には学習データの準備にそれなりの手間がかかっています。ソースデータのフィルタリング、ディストラクターの選定ロジック、CoT プロンプトの調整、生成結果の品質チェックといった工程は自動化できる部分もありますが、ドメイン知識に基づく判断が必要な場面も少なくありません。RAFT の費用対効果を考えるときは、データ準備の工数も含めて見積もるのが現実的です。
なお、今回は CoT 生成にクラウドの AI API(Claude Haiku)を使いましたが、データを外部に出せないケースもあるでしょう。その場合は 70B クラスのオープンモデルを DGX Spark 上で動かして CoT を生成する方法が考えられます。128GB の統合メモリなら Q4 量子化の 70B モデル(約 40GB)は余裕で載るので、学習データ生成から学習、推論評価までローカルで閉じたパイプラインを組むことも可能です。CoT の品質がそのまま学習データの質に直結するため、生成結果の検証は入念に行う必要がありますが、ソブリン AI やデータガバナンスの観点では検討に値する選択肢です。
制約と今後
今回の検証にはいくつかの制約があります。
まず、Mamba-2 層が凍結されている以上、モデルの SSM ベースの長距離記憶能力には手を加えられていません。LoRA カバー率 53% は、Attention 層のクエリ-キー-バリュー計算と FFN 層の表現変換だけを調整しています。Mamba-2 の in_proj/out_proj に LoRA を適用するには、HF PEFT のアップデートを待つか、NeMo の学習パイプラインに切り替える必要があります。NGC NeMo コンテナには Megatron-Bridge v0.2.0 が含まれており、HuggingFace 形式と Megatron 形式のモデル変換が可能です。Megatron 形式に変換した上で NeMo の SFT レシピを使えば、Mamba-2 層を含む 100% LoRA カバーが実現できる可能性がありますが、これは別の記事で検証したいと思います。
もう一つ、データ量 1,000 件というのは意図的な制約ですが、5,000 件や 10,000 件に増やしたときに 53% カバーの LoRA がどこまでスケールするかは未検証です。前回の 4B モデルでは 10,000 件で汎用性が劣化した教訓があるので、9B モデルでも同じ傾向が出るかは気になるところです。
まとめ
Nemotron 9B-v2-Japanese を国税庁 FAQ(JaGovFaqs-22k)で RAFT ファインチューニングし、RAG の精度を検証しました。
| 項目 | 値 |
|---|---|
| 学習データ | 国税庁 FAQ 1,100 件(RAFT 形式) |
| 学習環境 | DGX Spark + NGC NeMo 25.11.01 |
| 推論環境 | DGX Spark(Ollama / GGUF) |
| LoRA 方式 | BF16 LoRA(QLoRA は Mamba-2 非互換) |
| LoRA カバー率 | 53%(Mamba-2 層凍結) |
| 学習時間 | 55 分 |
| コスト | ~$2(CoT 生成のみ) |
| F1 改善 | +0.089(0.565 → 0.654) |
| 回答拒否 FP | 47 件 → 3 件(-93.6%) |
NGC コンテナのおかげで DGX Spark 上で学習から評価まで完結できたのは、個人的に大きな収穫でした。ソブリン AI やデータ主権の観点でも、自社環境だけでドメイン特化のファインチューニングを回せるのは実用上の安心感があります。学習データを用意することは容易ではありませんが、独自ドメインのデータで RAG 精度を改善したい方にとって、RAFT は試してみる価値があるのではないでしょうか。
データ準備スクリプト、学習スクリプト、評価スクリプトは以下のリポジトリで公開しています。








