![[新機能プレビュー] Amazon Q in QuickSight Scenarios でシナリオのデータをフィルタしたりソートしたりしてみた](https://images.ctfassets.net/ct0aopd36mqt/3aqf4zA8eWdIL3CoGscPpm/224083826f6e4dd7b971c4967b706ad8/reinvent-2024-try-jp.jpg?w=3840&fm=webp)
[新機能プレビュー] Amazon Q in QuickSight Scenarios でシナリオのデータをフィルタしたりソートしたりしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
以下ブログで現在パブリックプレビュー中の Amazon Q in QuickSight Scenarios で新規シナリオの作成をやってみました。
上記ブログでは CSV ファイルをアップロードしてシナリオを作成したのですが、シナリオから CSV ファイルの中身のデータがプレビューでき、フィルタしたりソートしたりできるので、その操作をやってみました。
シナリオにアップロードした CSV データの確認
[新機能プレビュー] Amazon Q in QuickSight Scenarios でアップロードした CSV ファイルに自然言語(英語)で質問し AI によるインサイトを得てみた | DevelopersIO で作成済みの既存のシナリオで試します。
既存のシナリオは Amazon Q in QuickSight でトピックを作成しデータセットに Q&A してみた | DevelopersIO で使った「部署ごとに保持しているお菓子の在庫」を記載した CSV ファイルをアップロードして作成しています。
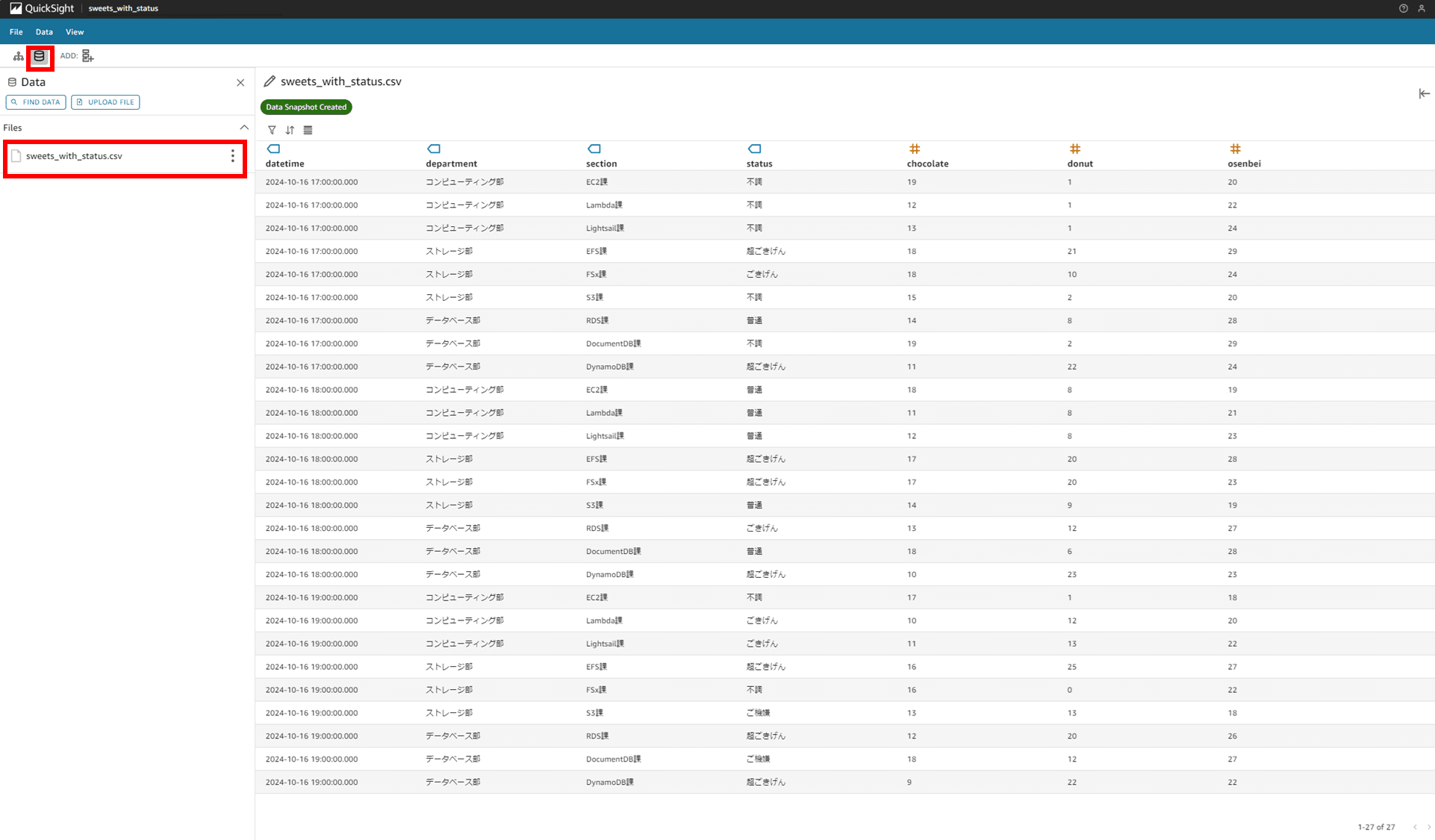
作成したシナリオを開き、画面左上のデータソースのマークからデータを確認できます。「sweets_with_status.csv」という CSV をアップロードしてシナリオを作成しているのですが、ファイルの全体はこんな感じです。
1. フィルタ
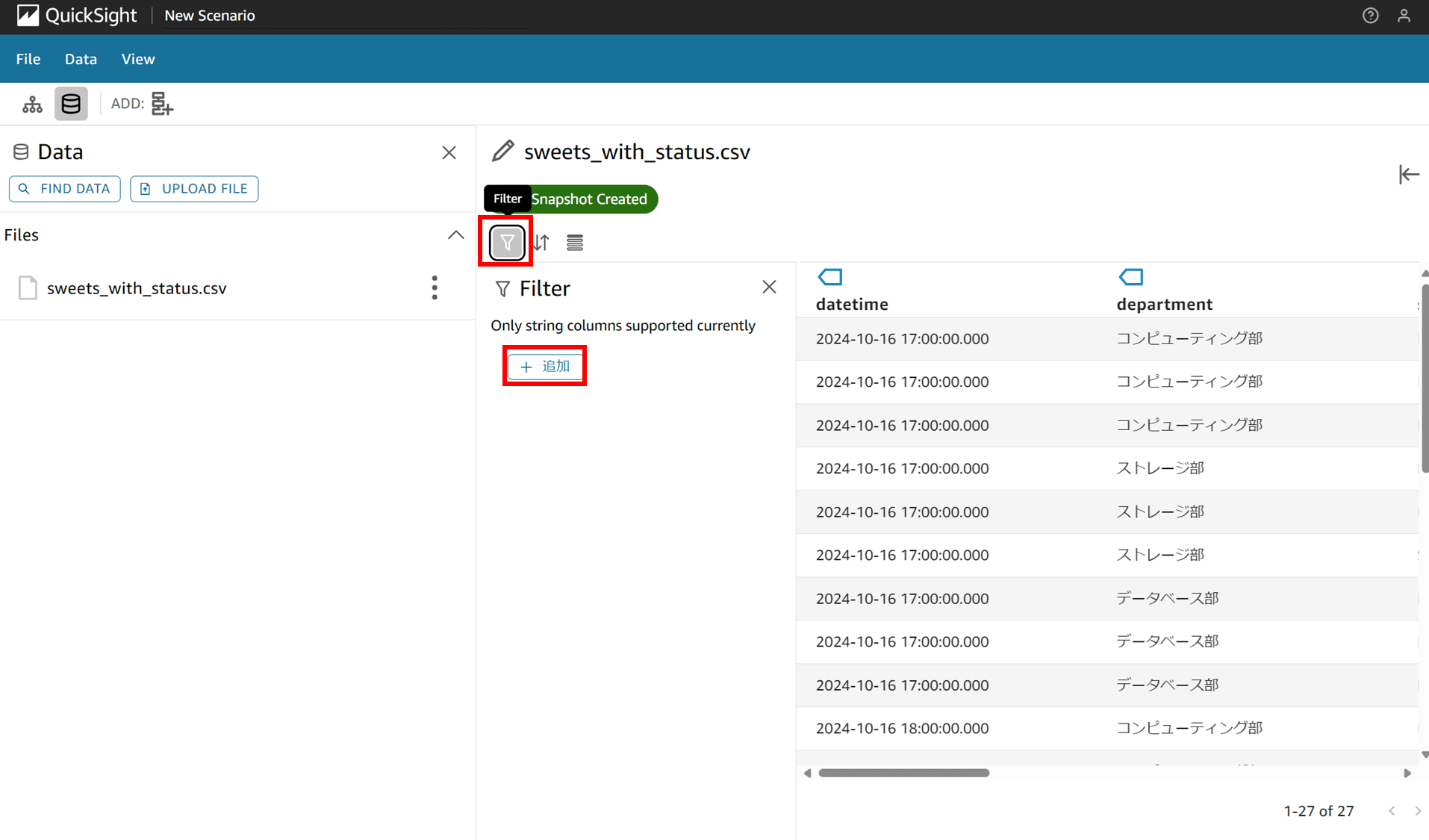
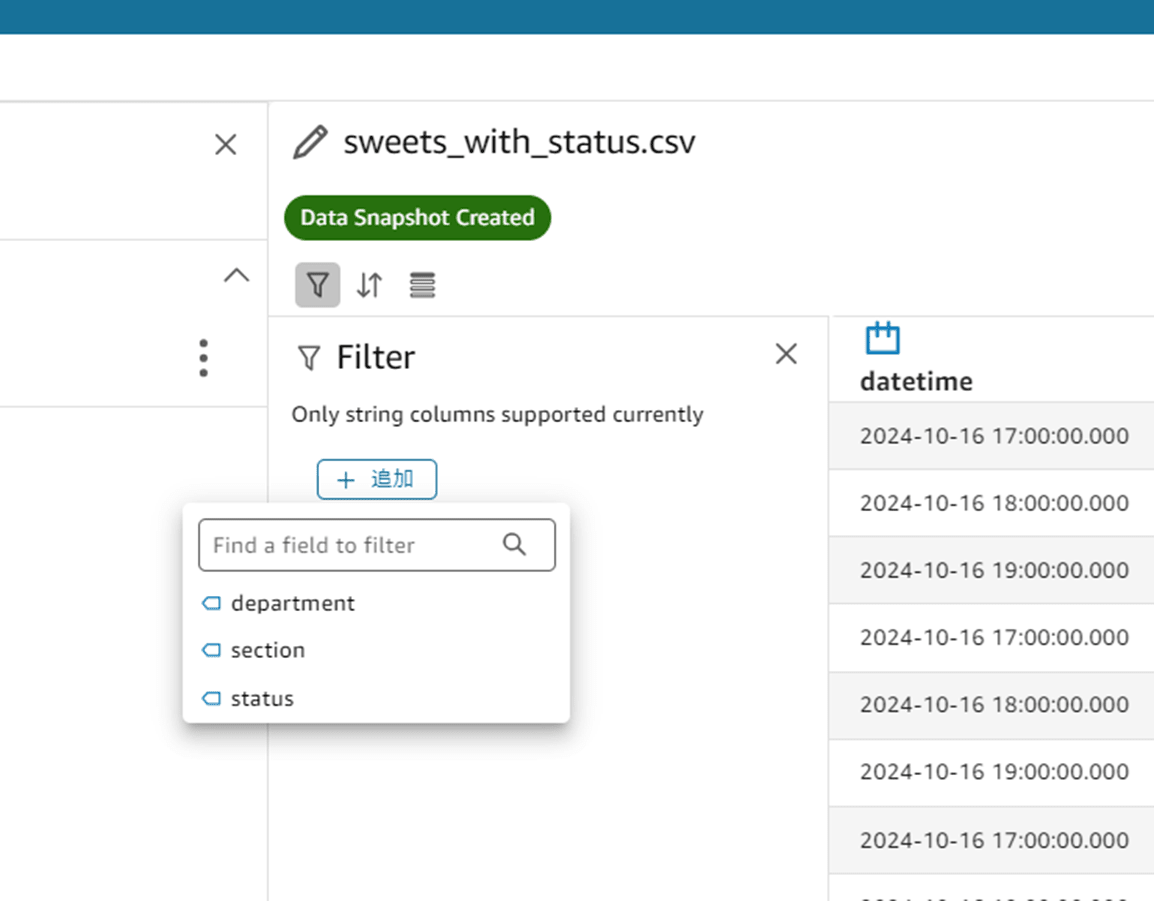
フィルタマークをクリックすると「+ 追加」ボタンからフィルタを追加できます。
Only string columns supported currently
(機械翻訳)現在サポートされているのは文字列カラムのみ
と書かれています。
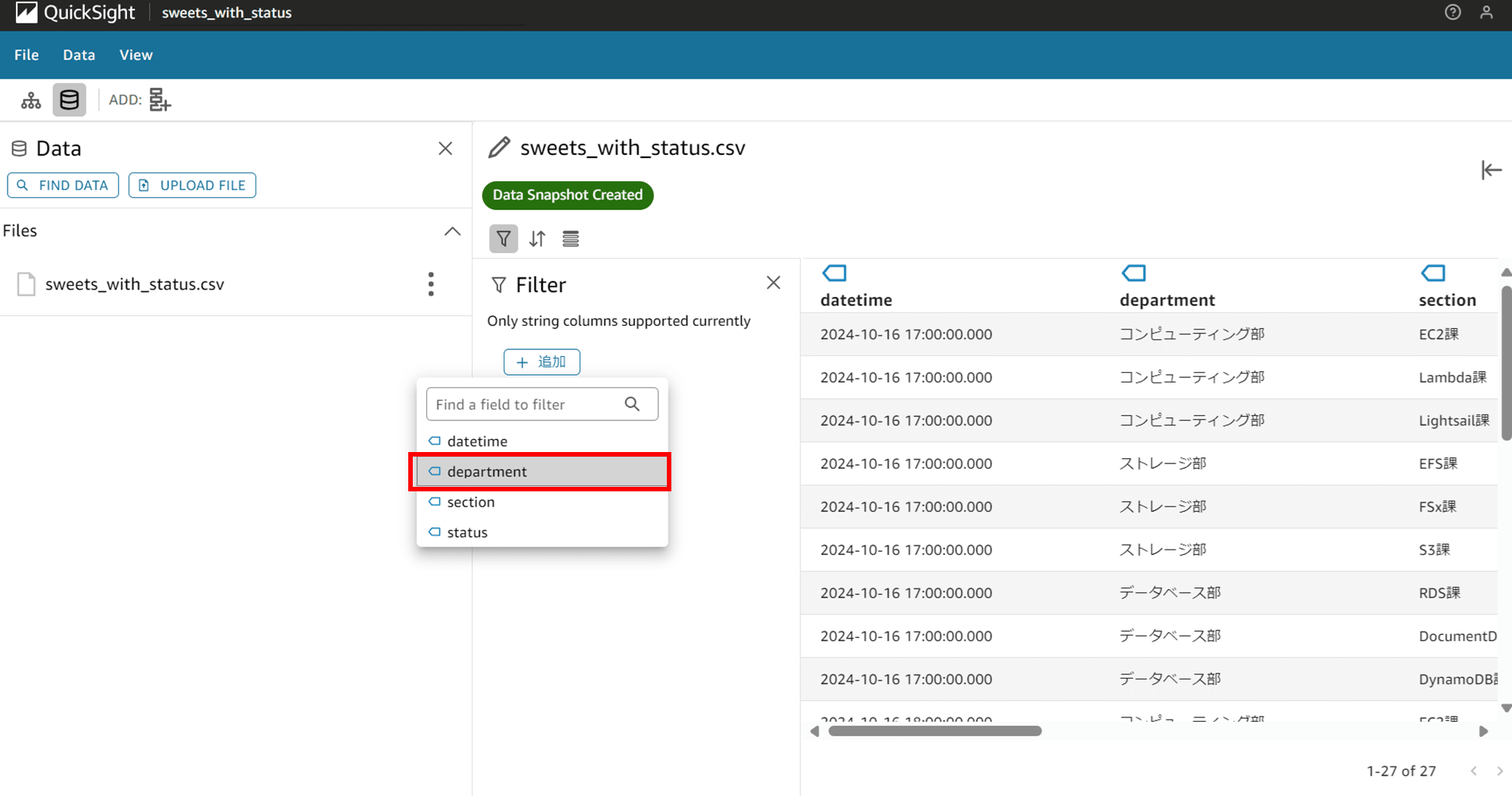
「+ 追加」をクリックすると、String(文字列)型のカラムが表示されました。確かに文字列型しかサポートしていないようですね。
今回は department(部)を選択してみます。
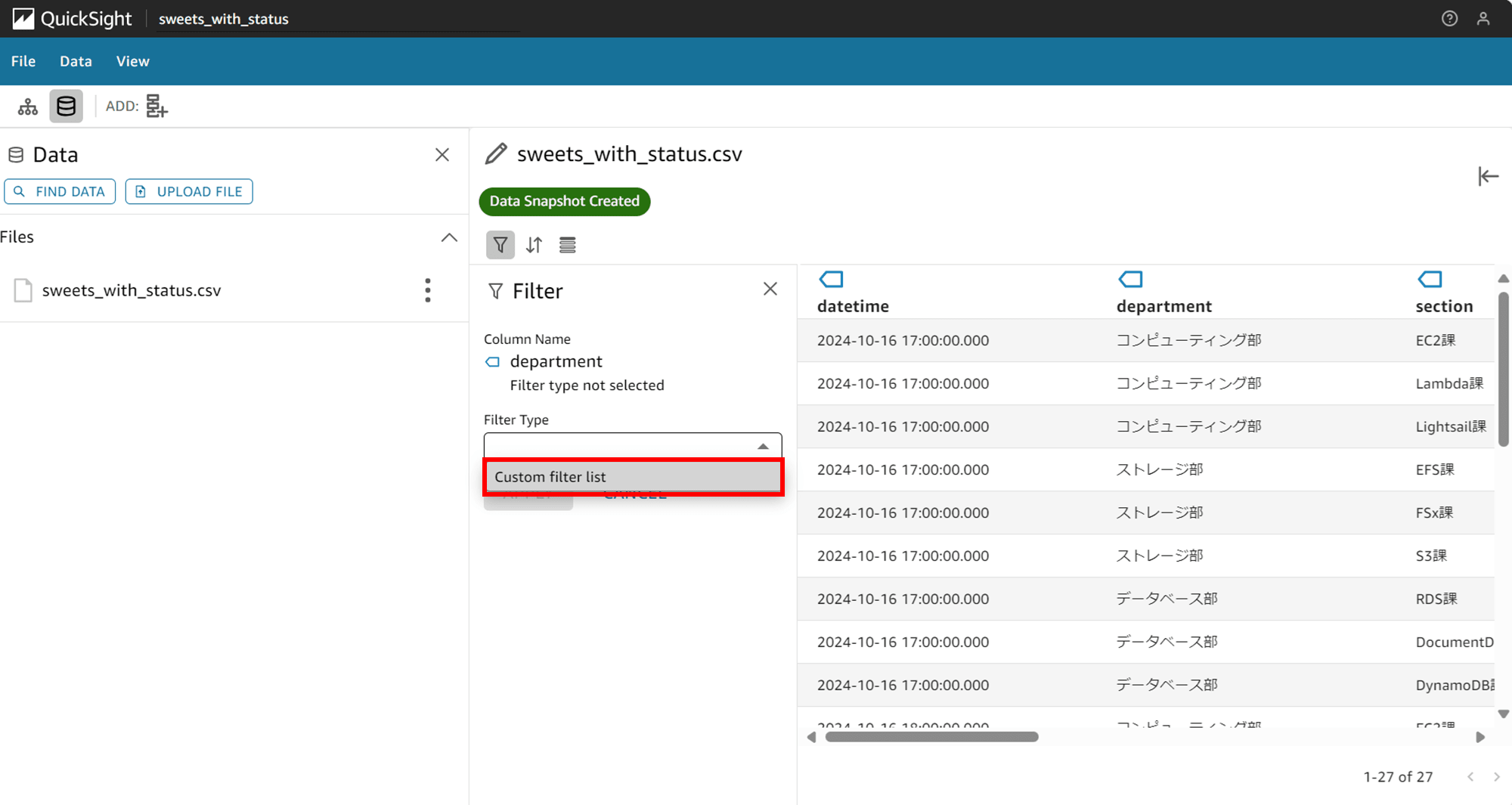
「Filter Type」では「Custom filter list」しか選択できません。「Custom filter list」を選択します。
「Filter condition」で「Include(含む)」か「Exclude(含まない)」かを選択します。今回は Include を選択します。
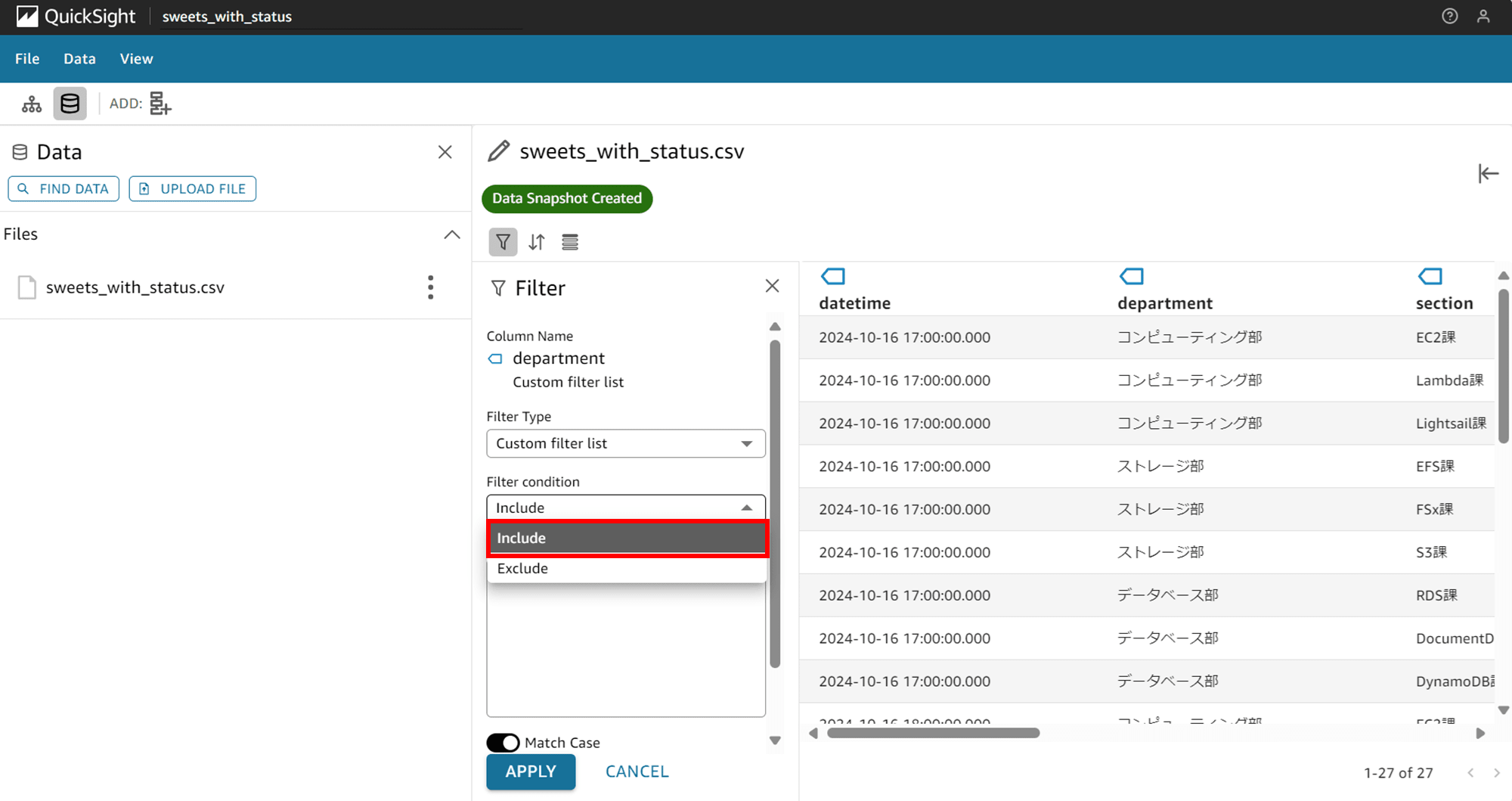
List にフィルタする文字列を入力します。今回は「コンピューティング部」だけ表示するように入力しました。
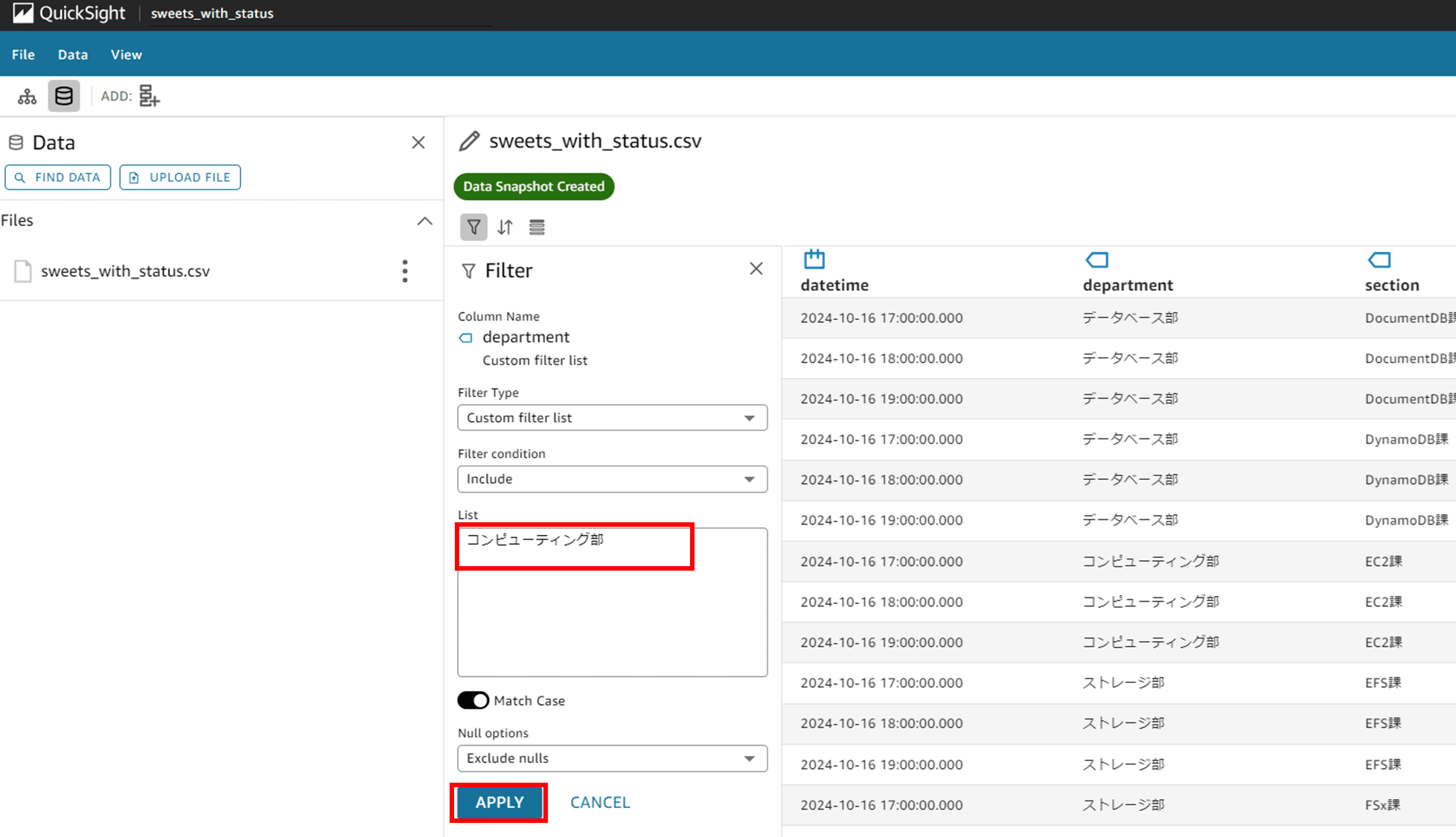
Match Case(大文字と小文字を区別する)はデフォルトで ON でした。
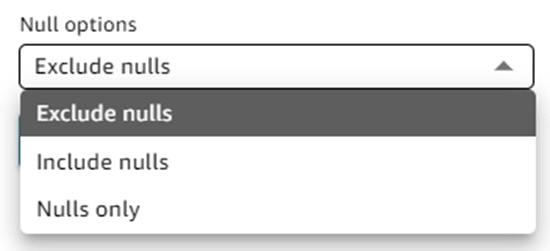
Null options では
- Exclude nulls(NULL を除外する)
- Include nulls(NULL を含む)
- Nulls only(NULL のみ)
を選択できました。今回はデフォルトの「Exclude nulls」のまま進めます。
「APPLY」をクリックして数秒待ちます。
department カラムが「コンピューティング部」の行だけ表示されるようにフィルタされました。
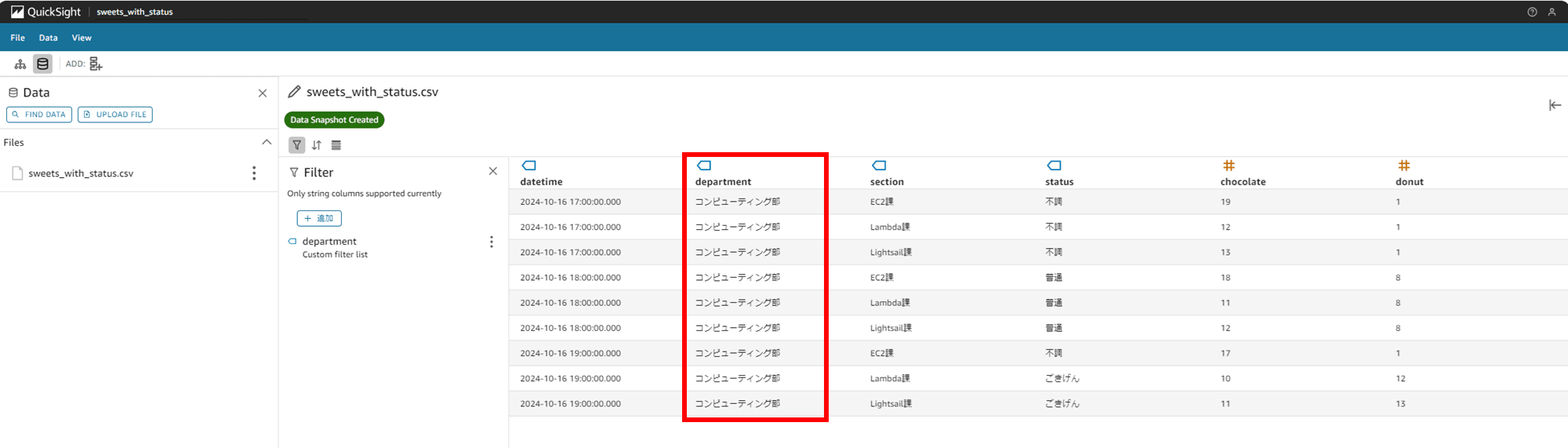
データにフィルタしましたが、既存のシナリオは変わりないです。
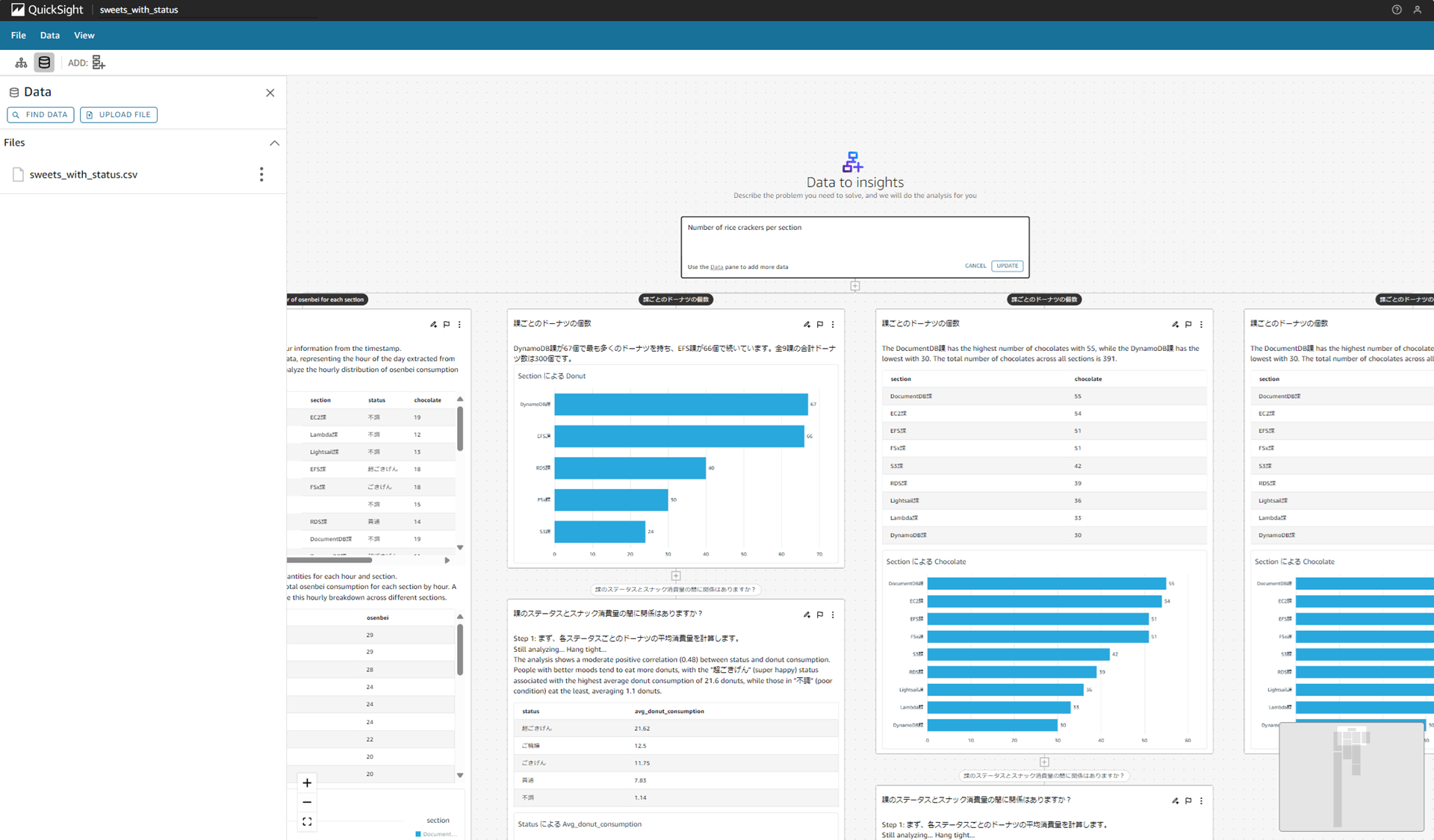
設定したフィルタの三点リーダから「Edit Filter」と「Delete Filter」が選択できます。
また、更に「+ 追加」ボタンでフィルタを追加できます。
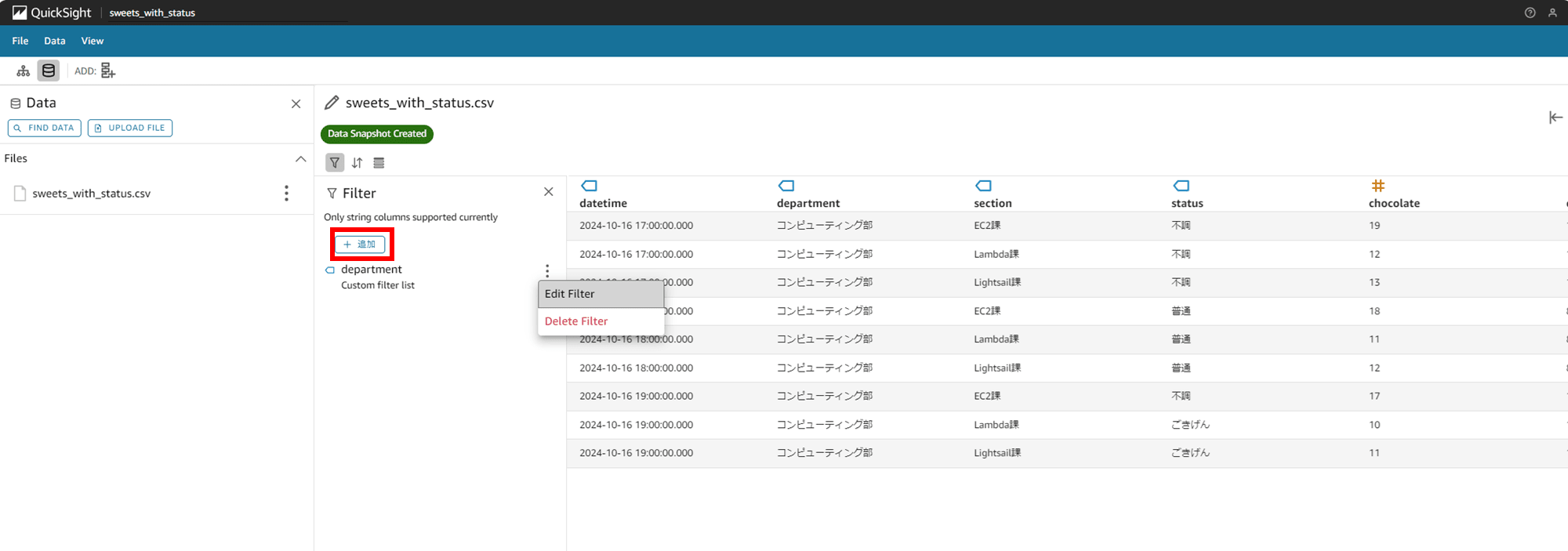
次は section カラムが「Lambda 課」のものをフィルタするように設定します。
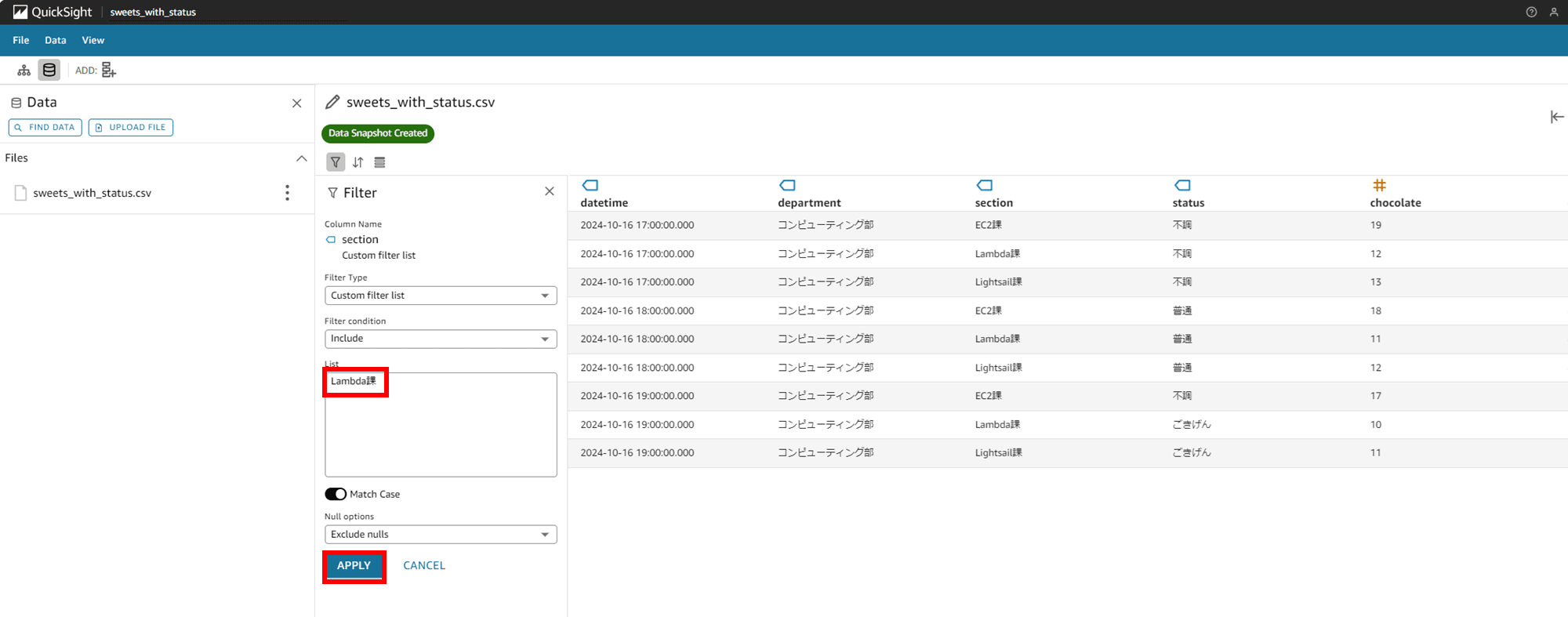
できました。department カラムが「コンピューティング部」、section カラムが「Lambda 課」のものをフィルタできています。
Match Case(大文字と小文字を区別する)を試してみます。まずは「lambda課」と先頭を小文字にした状態で Match Case を ON にします。
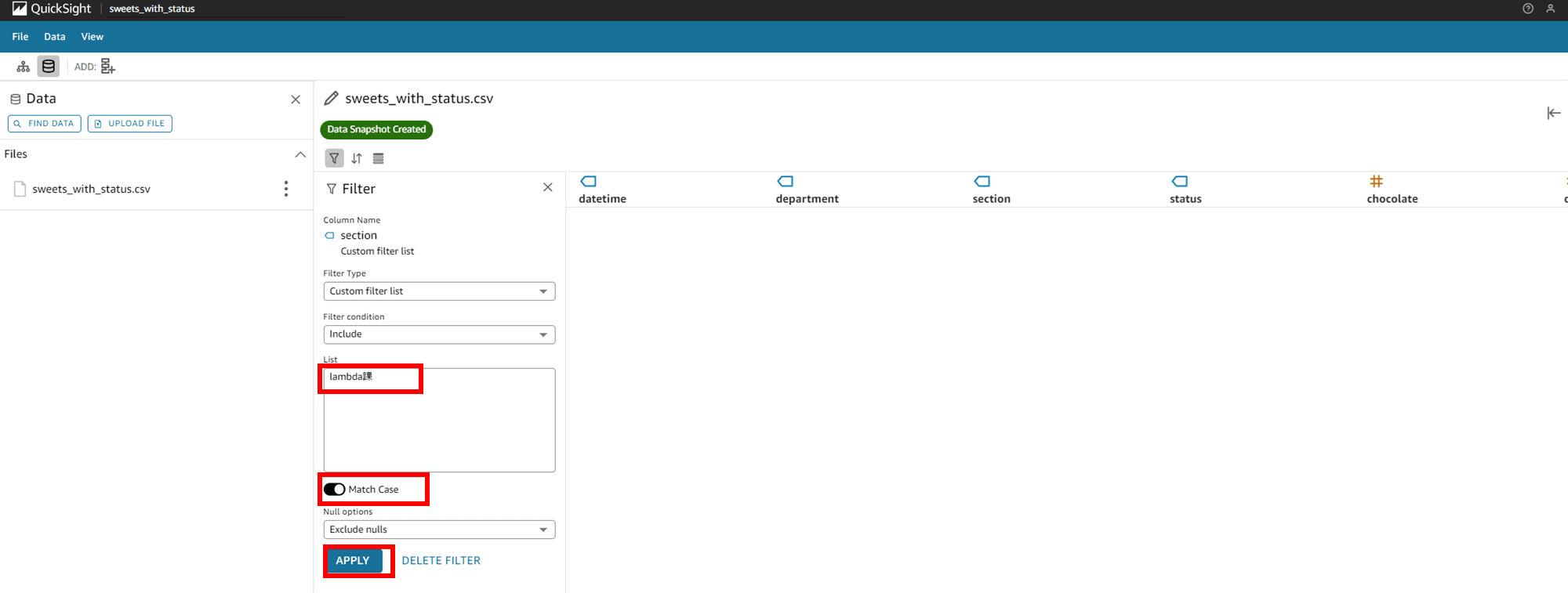
大文字小文字が区別されるため、フィルタですべての行が見えなくなりました。
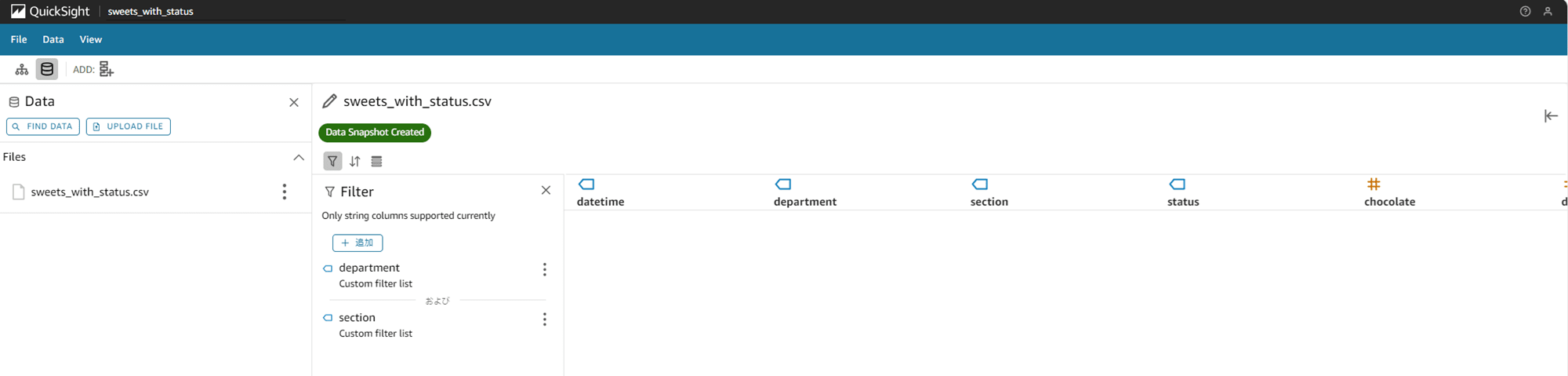
次は Match Case を OFF にします。これで、大文字と小文字が区別されなくなりました。
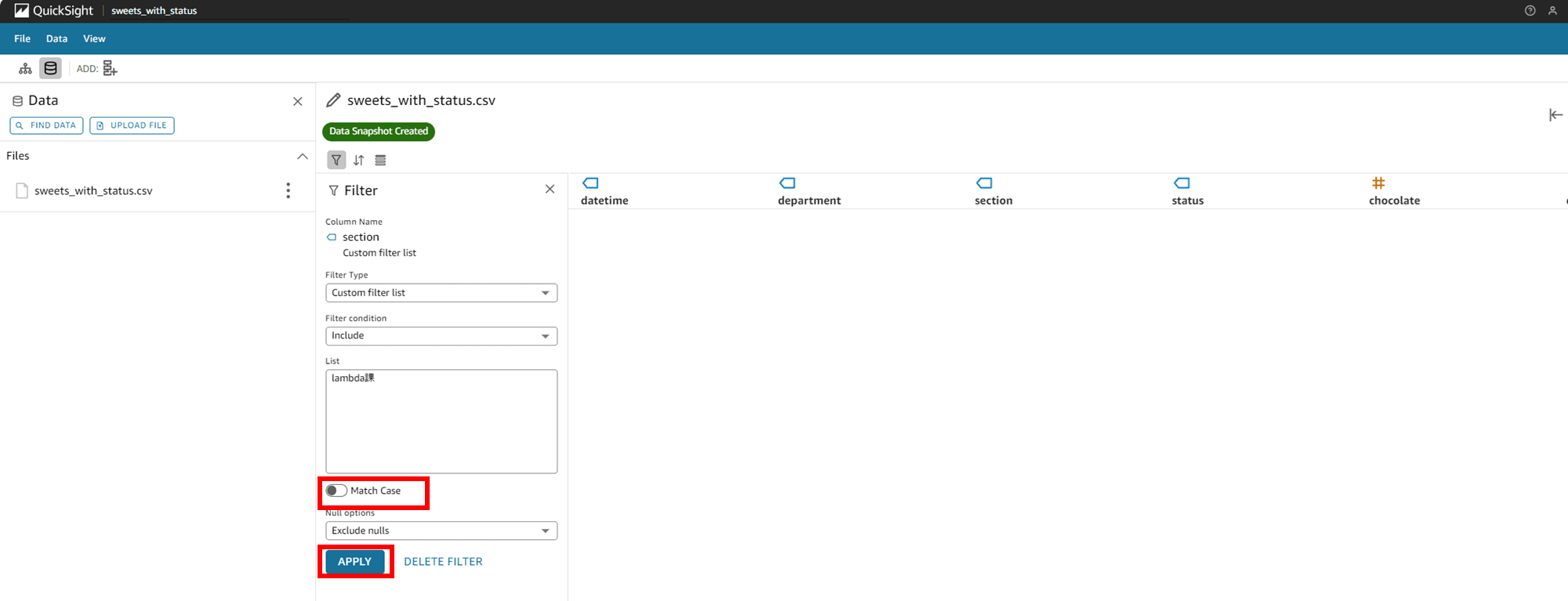
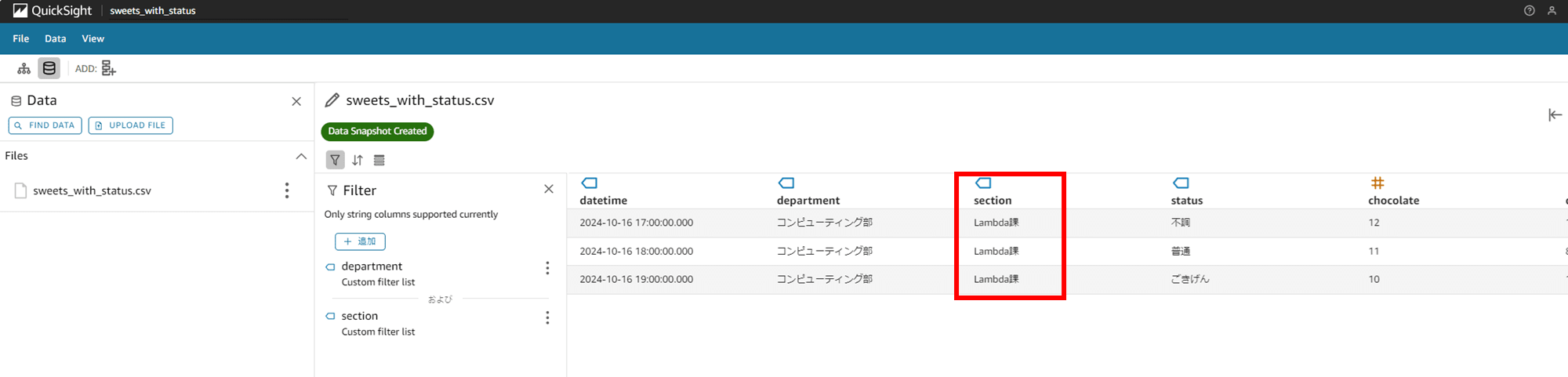
「lambda課」というフィルタでも「Lambda課」が表示されるようになりました。
2. ソート
Sort マークをクリックすると、ソート項目が出てきます。
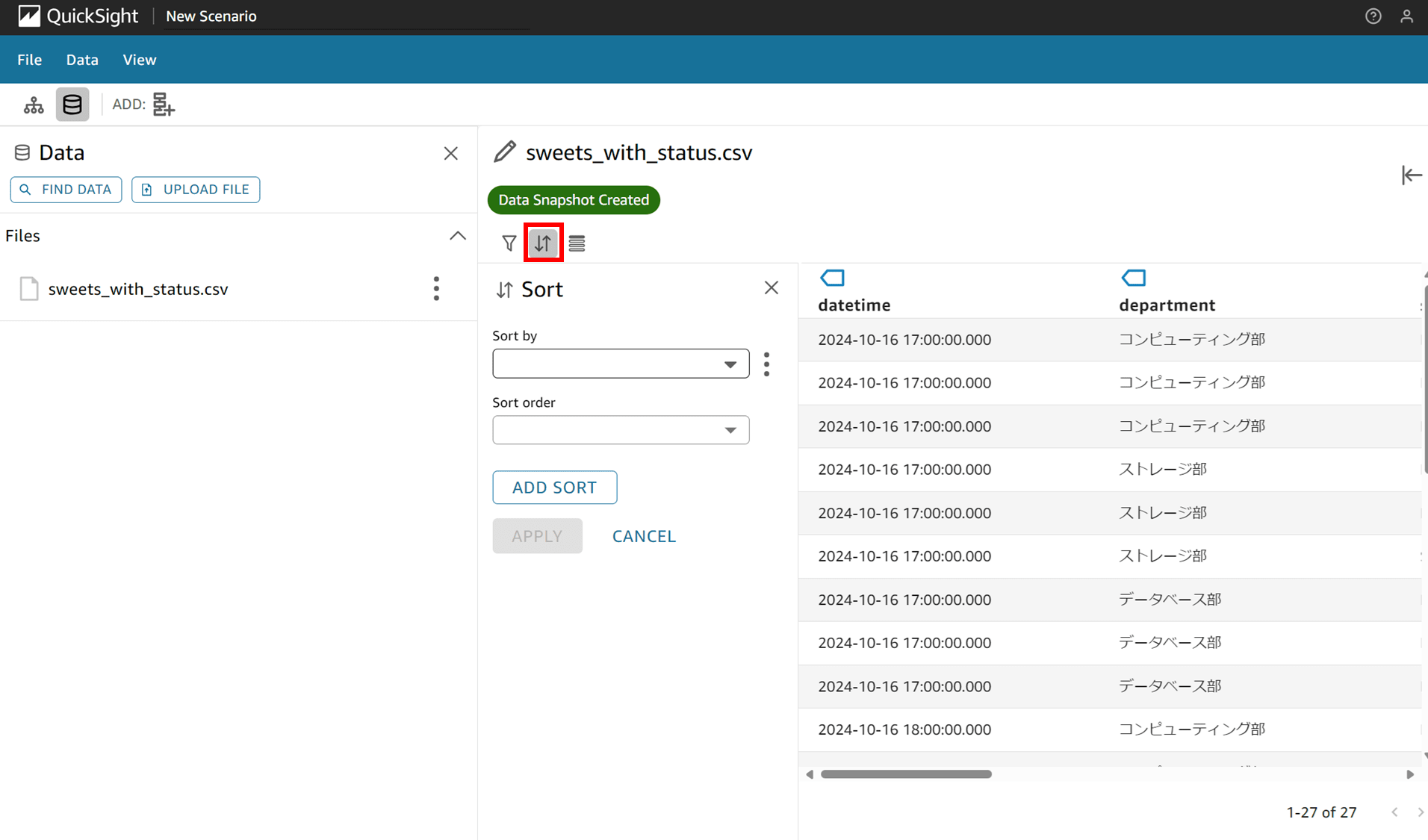
「Sort by」では並べ替えの対象となるカラムが選択できます。
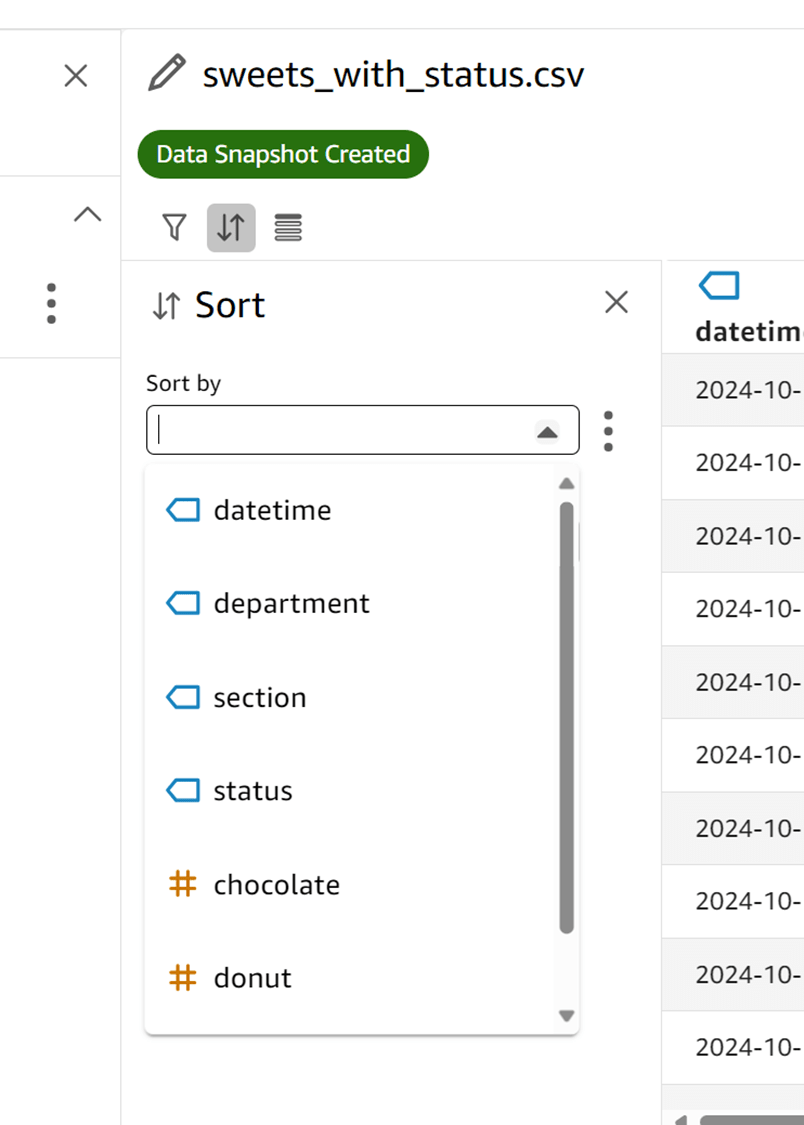
「Sort order」では Descending(降順)か Ascending(昇順)か選択できます。
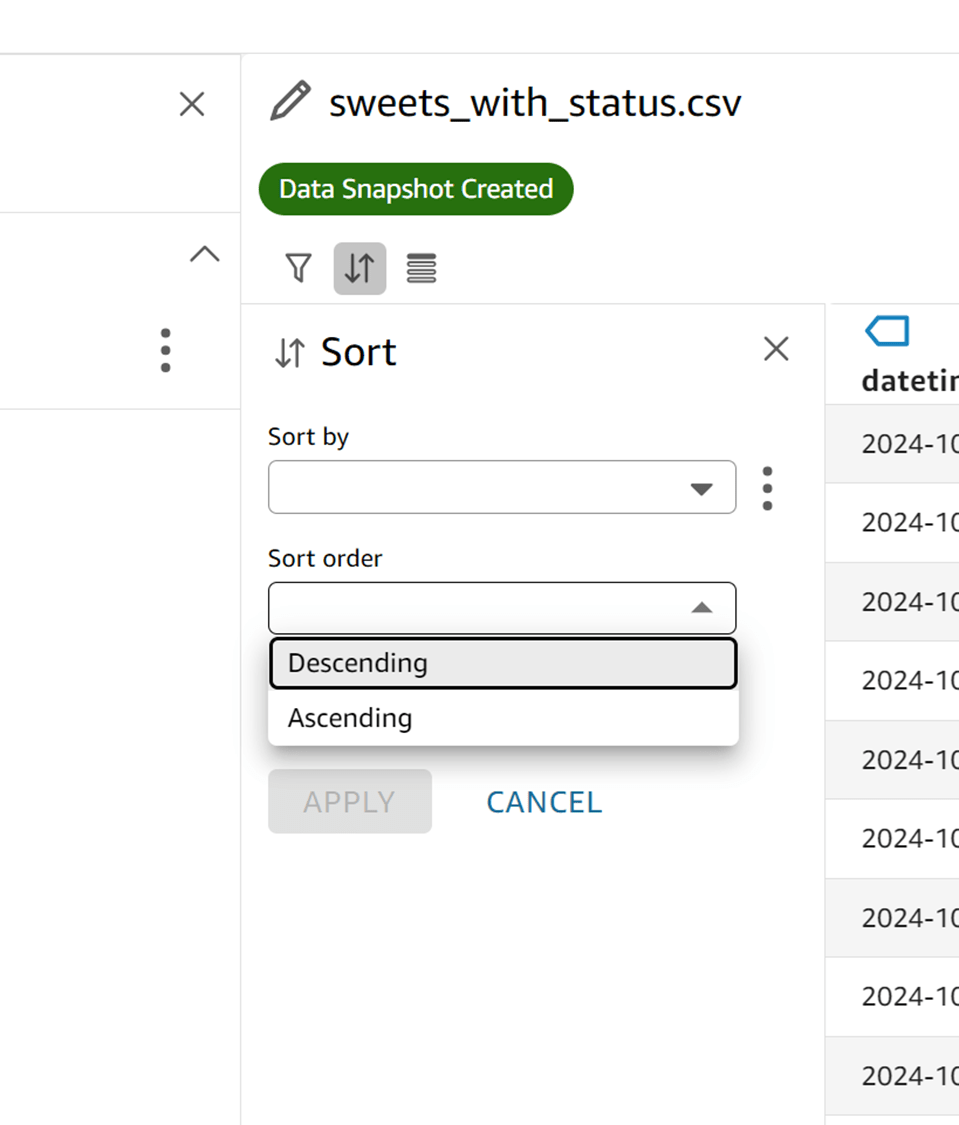
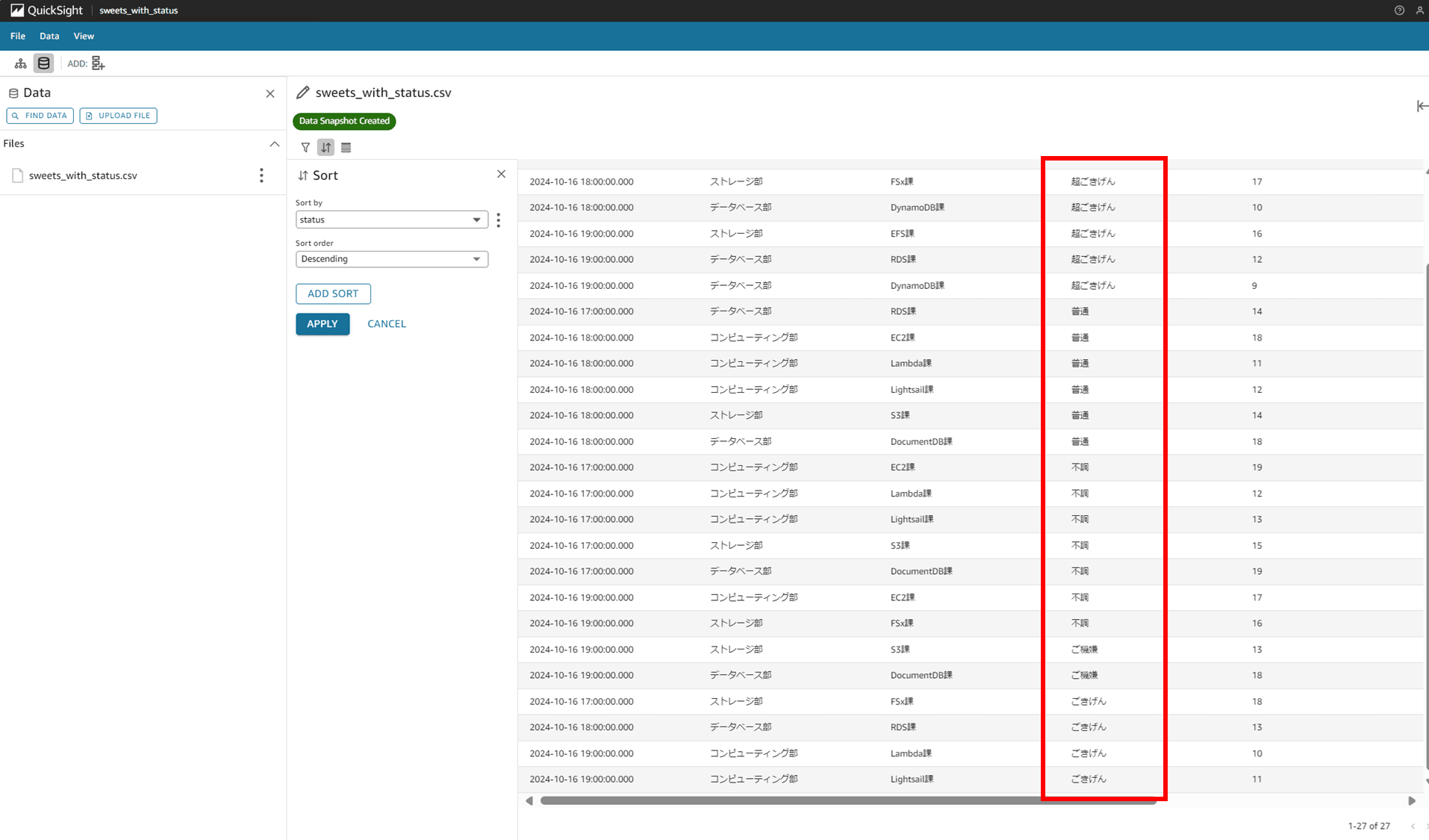
「Sort by」では status、「Sort order」では「Descending」を選択して APPLY します。
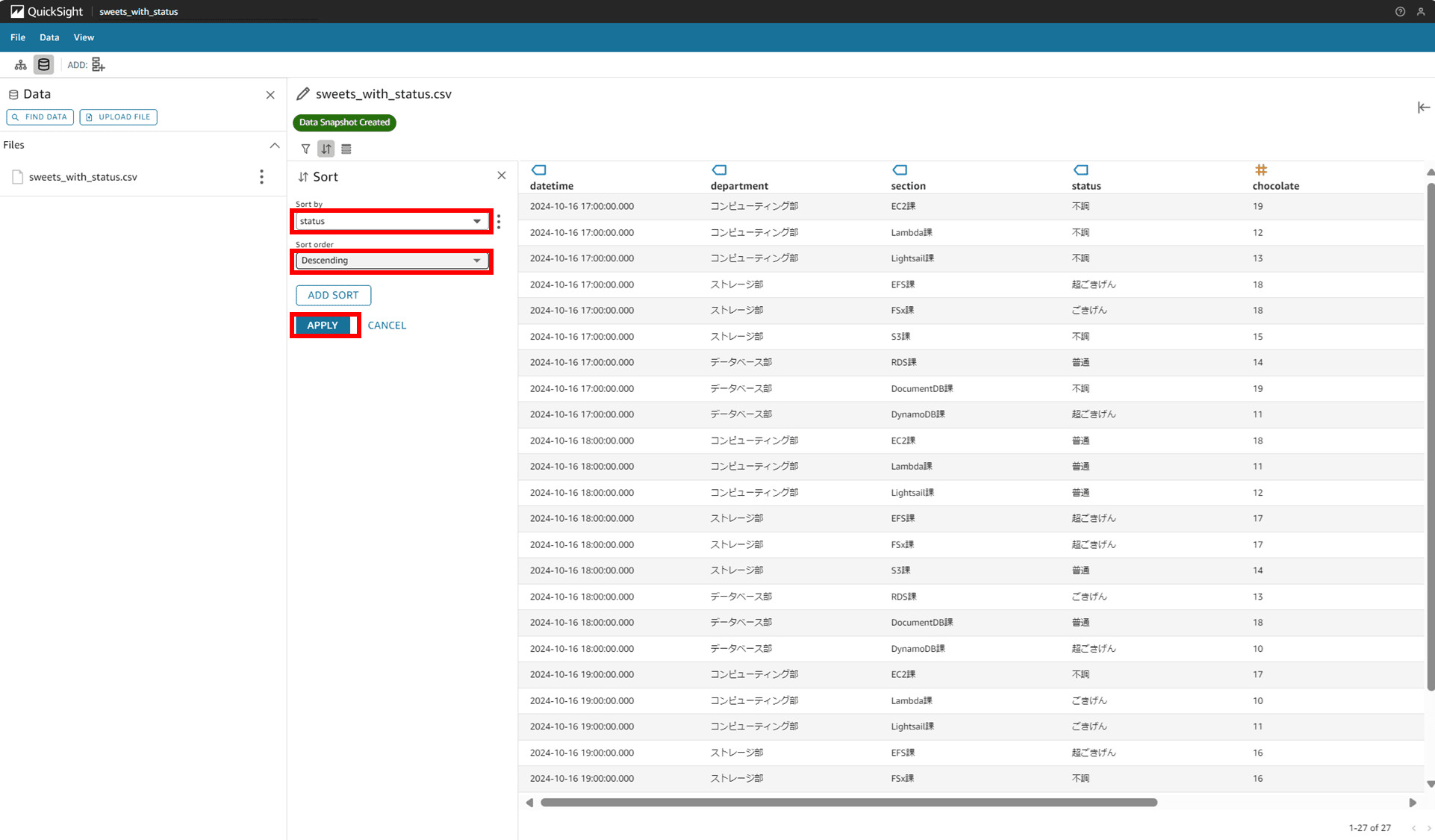
status カラムが順番に並びました。
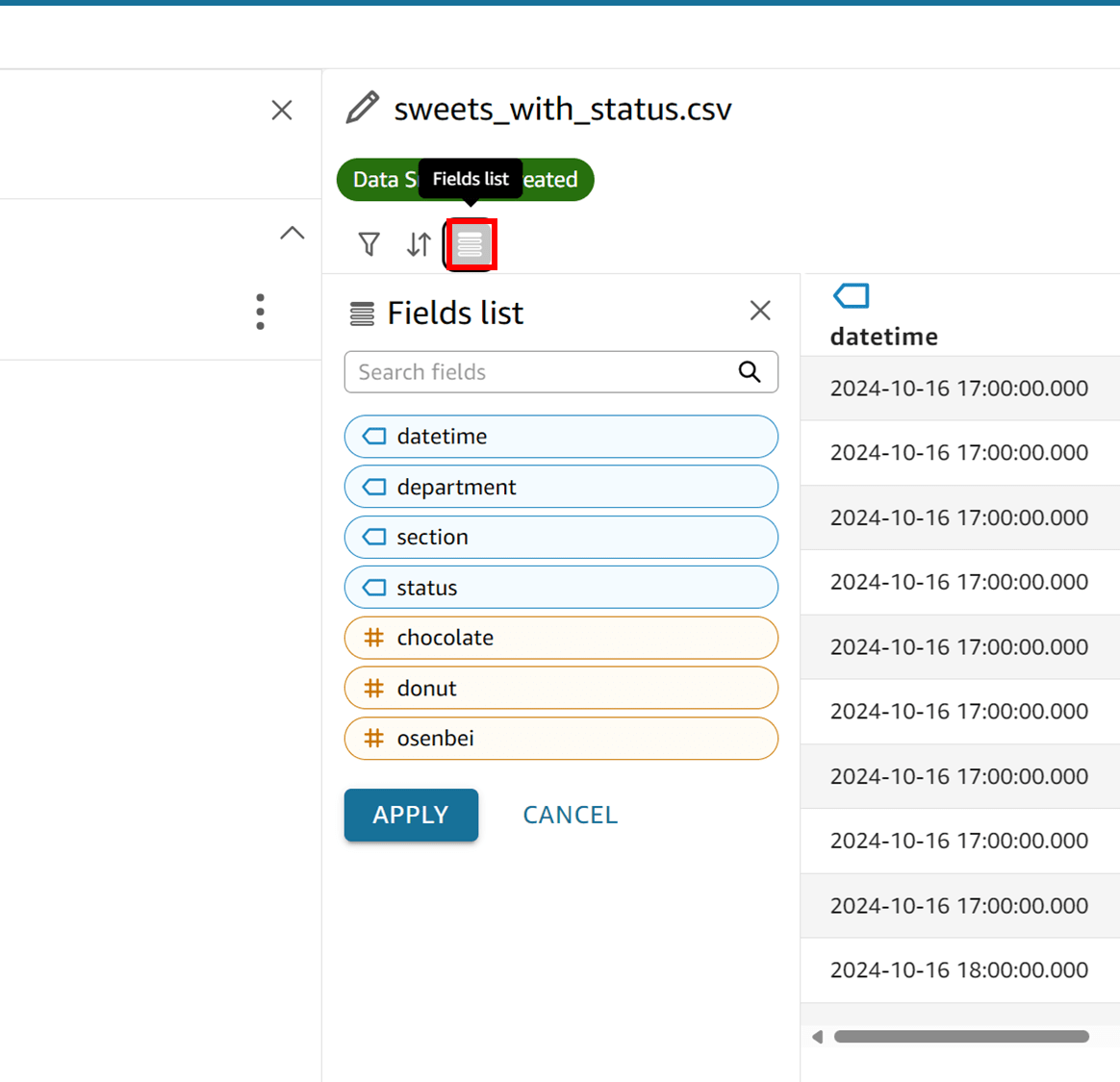
3. Fields list
最後に「Fields list」という項目があるのですが、ここで何ができるのか予想できませんね。いろいろやってみましょう。
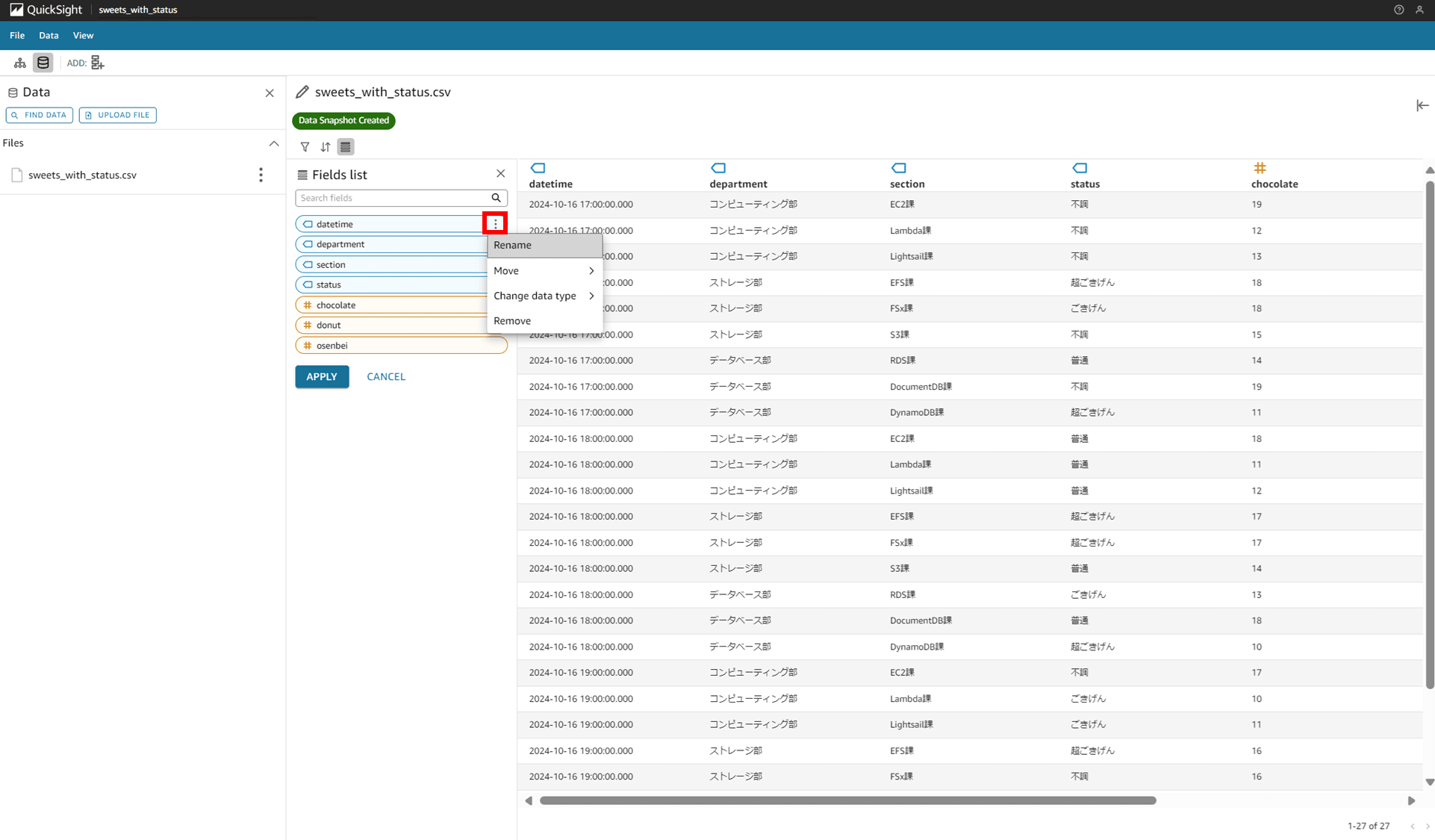
カラムの一覧が表示されているのですが、各カラムの三点リーダでは
- Rename
- Move
- Change data type
- Remove
という 4 つの項目が選択できます。
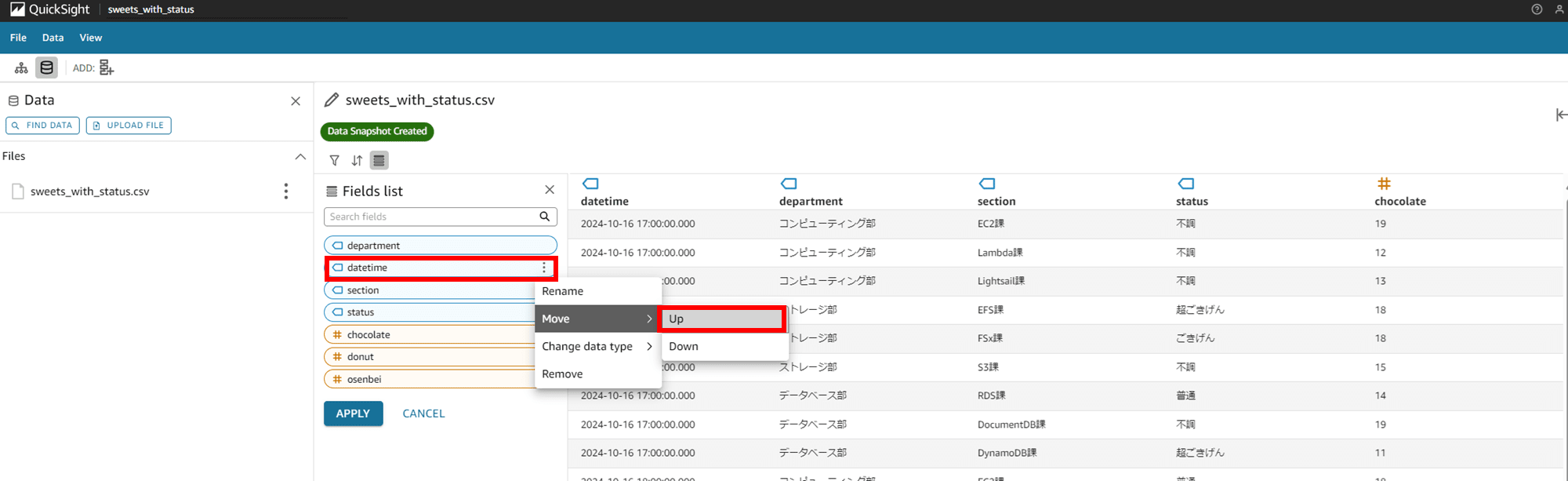
一番上に表示されているカラム datetime の「Move」を押すと「Down」と出てきました。押してみます。
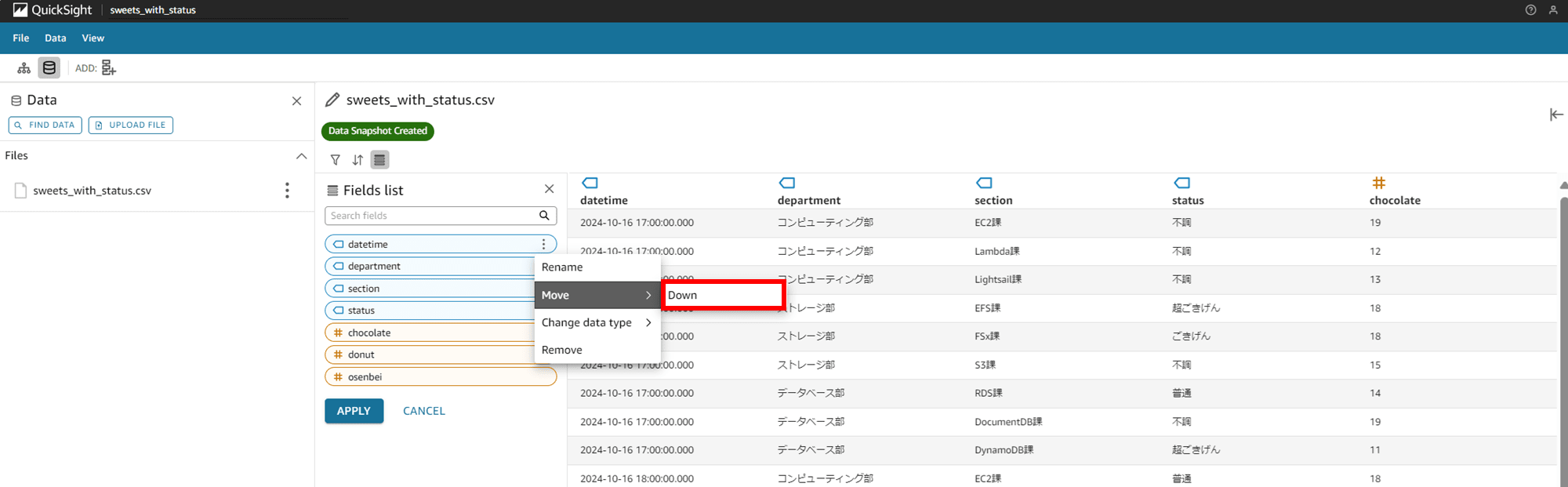
右に表示されているデータのプレビューに変わりはありませんが、Fields list のカラム一覧では datetime が二番目に下がりました。なるほど、ここの並び替えなんですね。もう一度「Move」を押すと「Up」と「Down」が出てきたので、Up を押して一番上に戻しておきます。
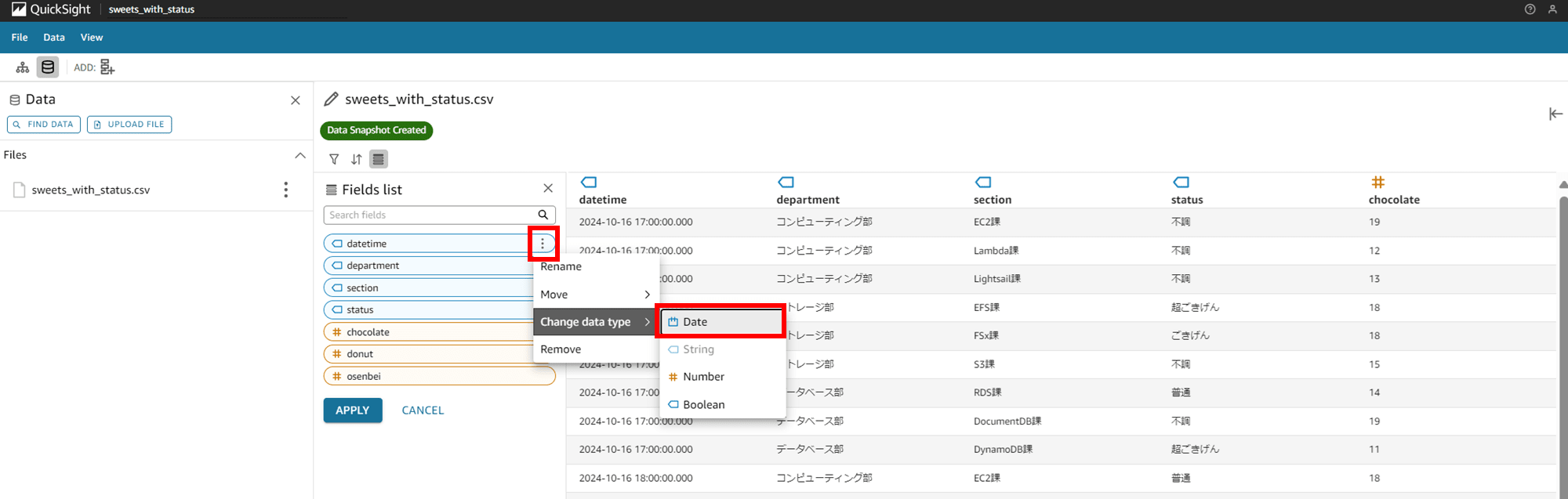
続いて「Change data type」をクリックしてみると、Date 型、Number 型、Boolean 型と方が変換できるようです。datetime が String 型になっているので、Date 型に変更してみます。
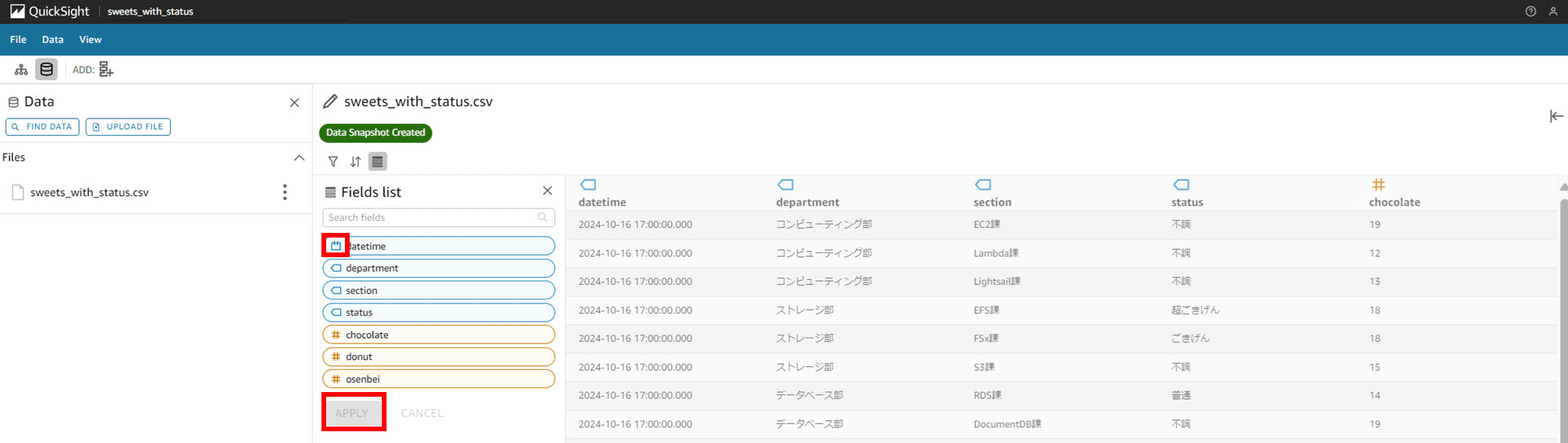
「Date」を選択するだけではまだ Fields list の datetime の左のマークがカレンダーマークになっただけで、右のデータプレビュー欄の方は String 型のマークのままです。「APPLY」を押して変更を反映します。
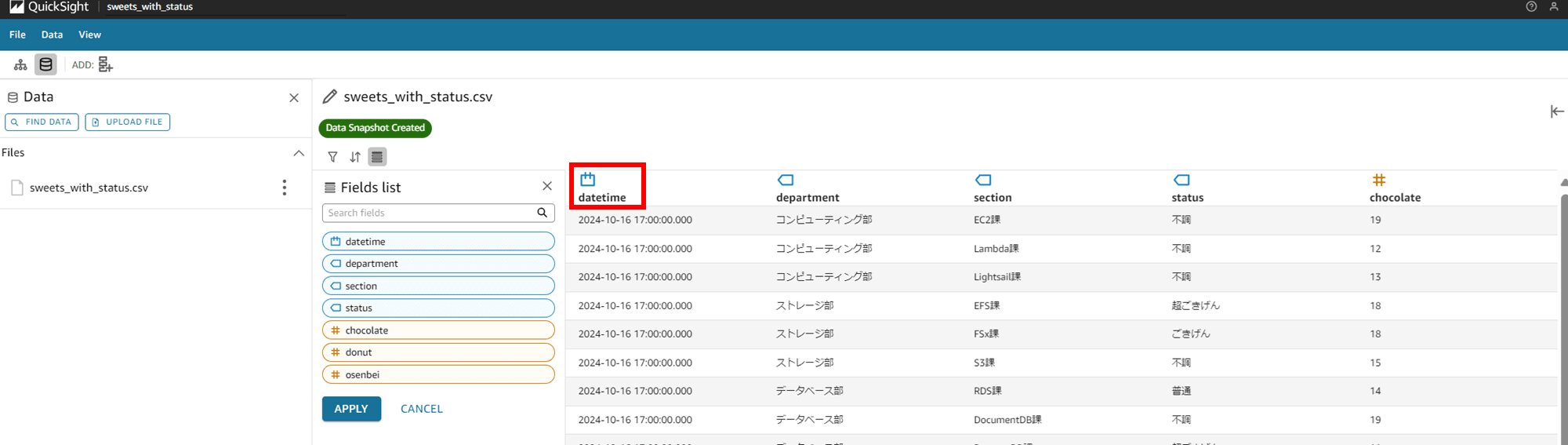
右のデータプレビュー欄の方も Date 型のカレンダーマークになりました。
ここでフィルタをもう一度見てみると、datetime はフィルタとして選択できなくなっていました。まだフィルタは String 型しかサポートしていないので、そうだな、という感じです。
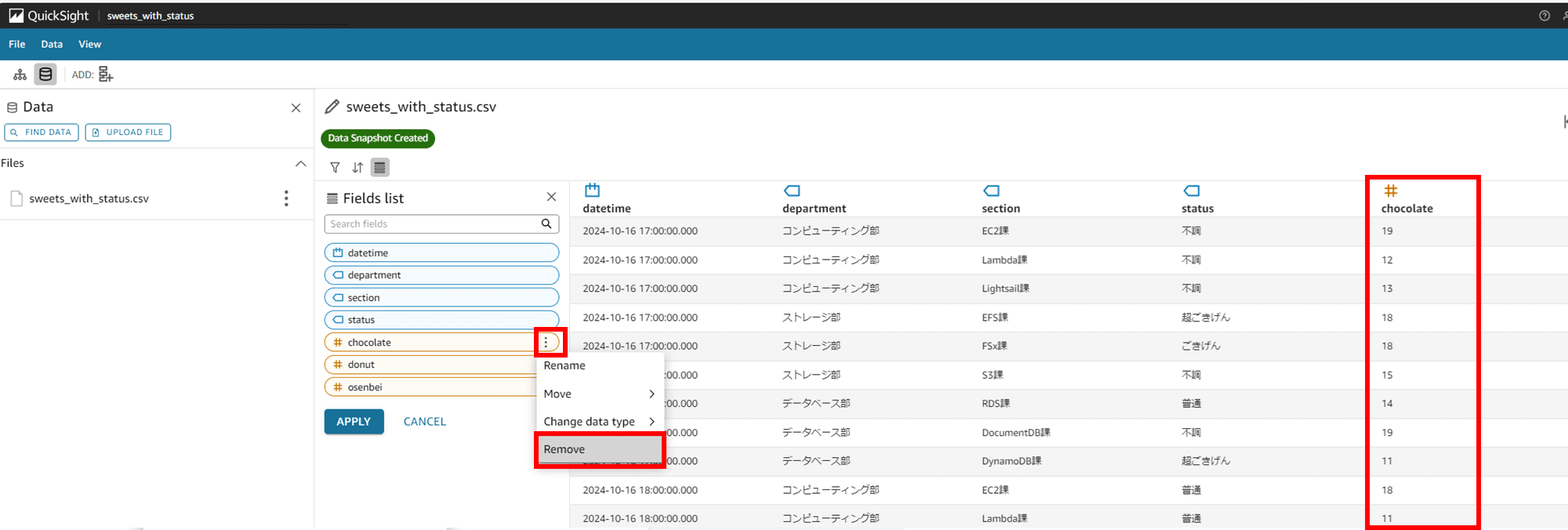
Fields list に戻ります。次は chocolate カラムを Remove してみます。
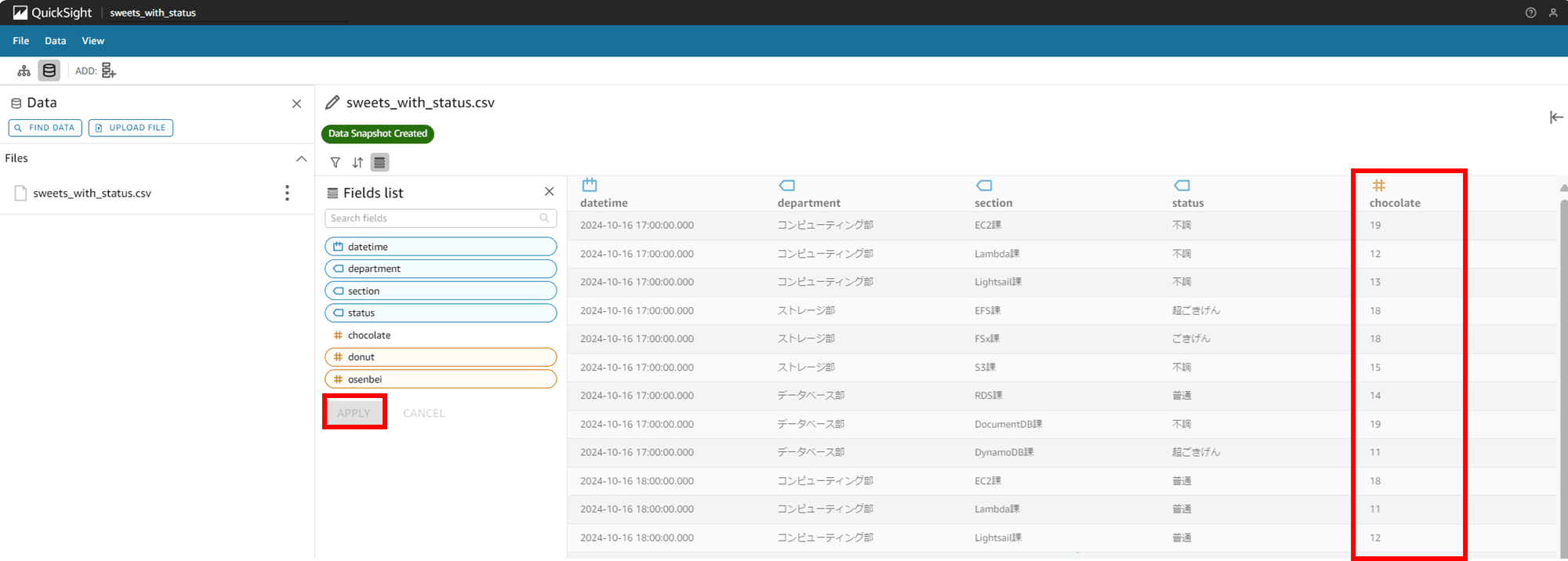
「APPLY」で変更を反映します。
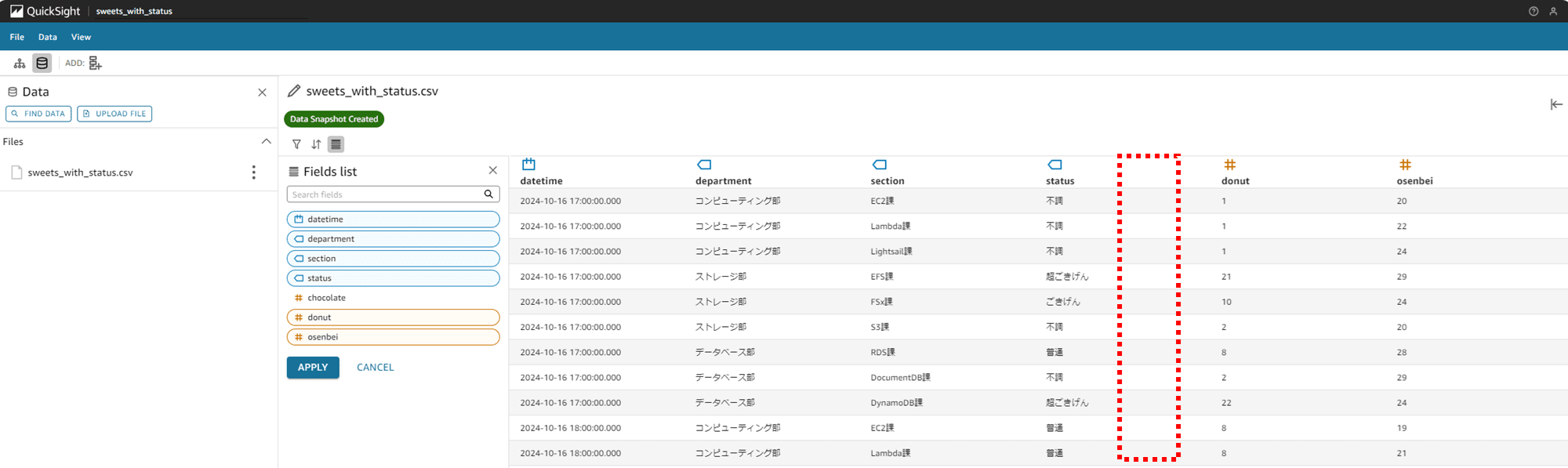
chocolate カラムが右のデータプレビュー表示から消えました。
シナリオのスレッドを見てみましたが、データプレビューから chocolate が消えても既存のシナリオに影響はありません。普通に chocolate に関しての分析が表示されています。
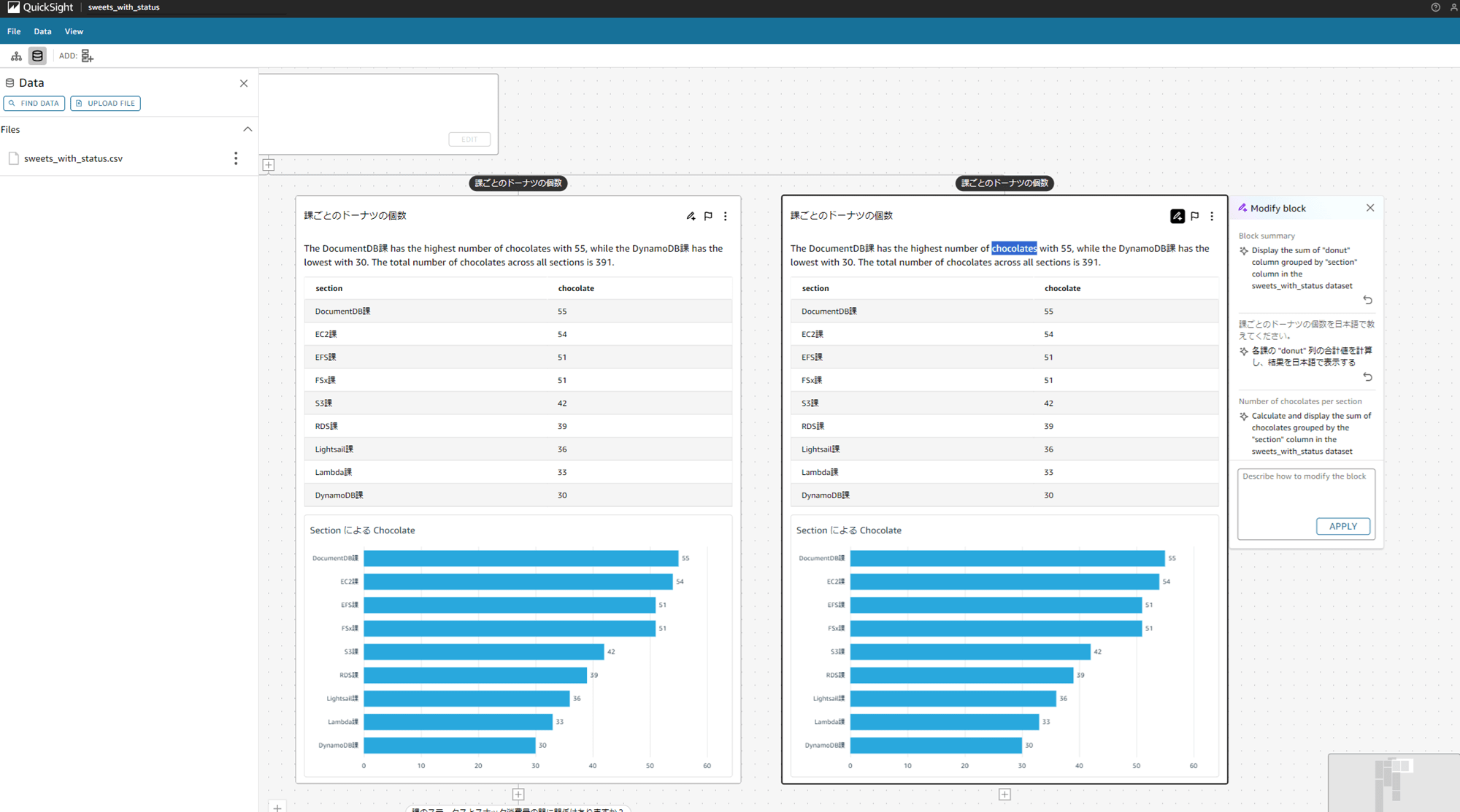
Fields list で「Remove」すると、今度は「Add」という項目が表示されるようになります。ここから戻せるってわけですね。
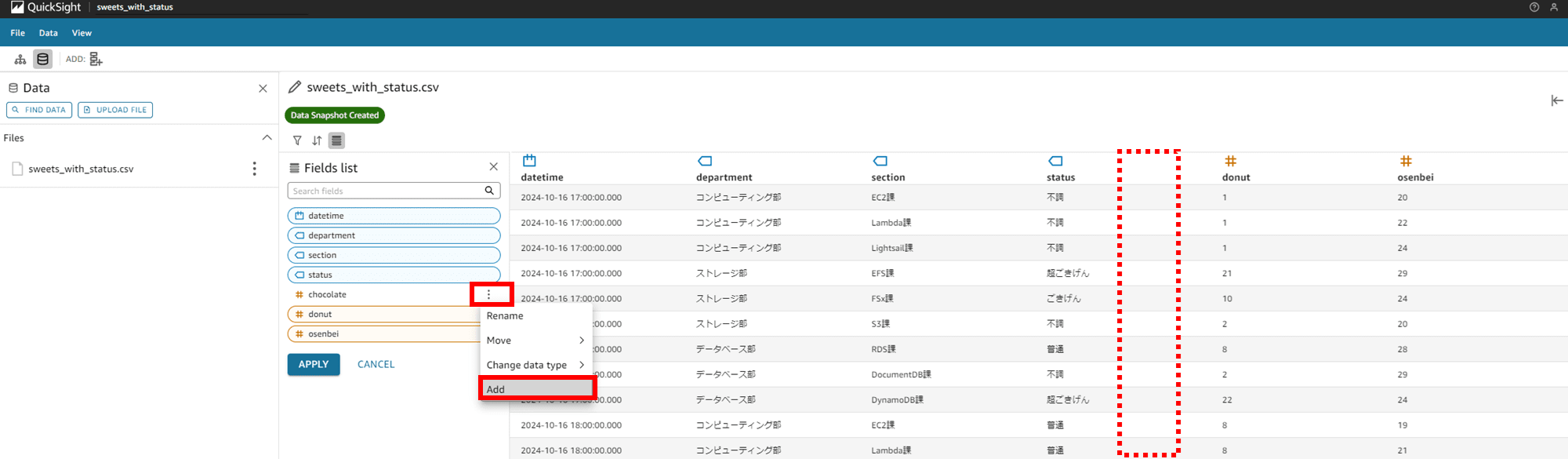
「APPLY」で変更を反映します。
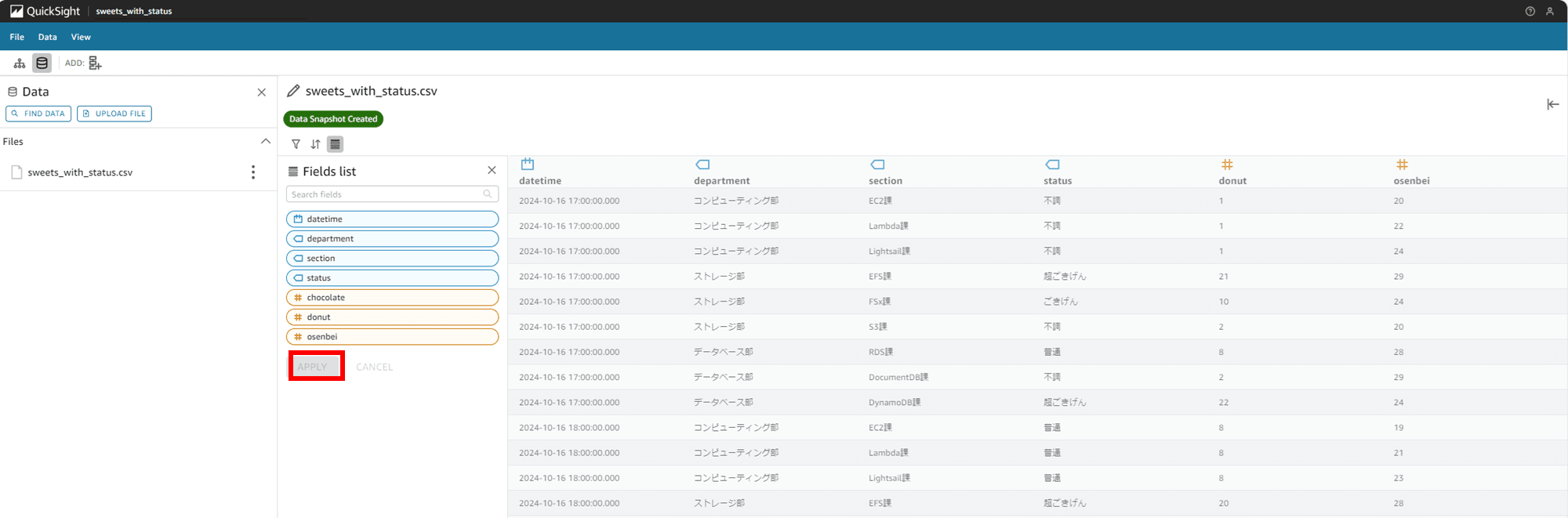
戻りました。
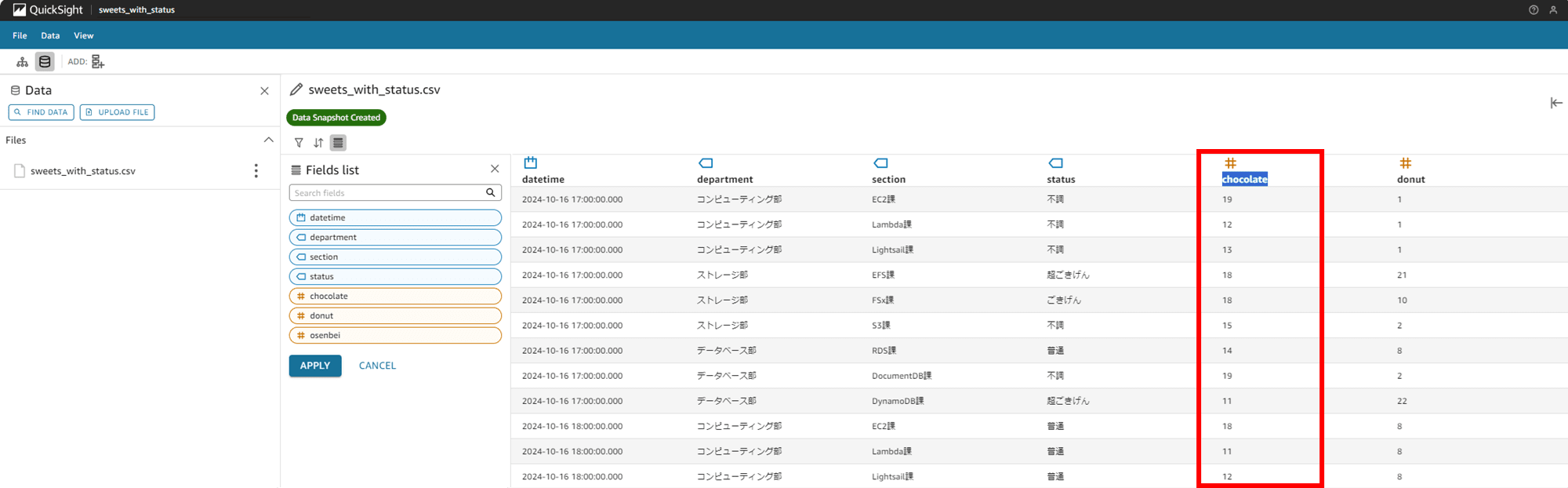
最後に「Rename」します。osenbei カラムを rice crackers 変えてみましょう。
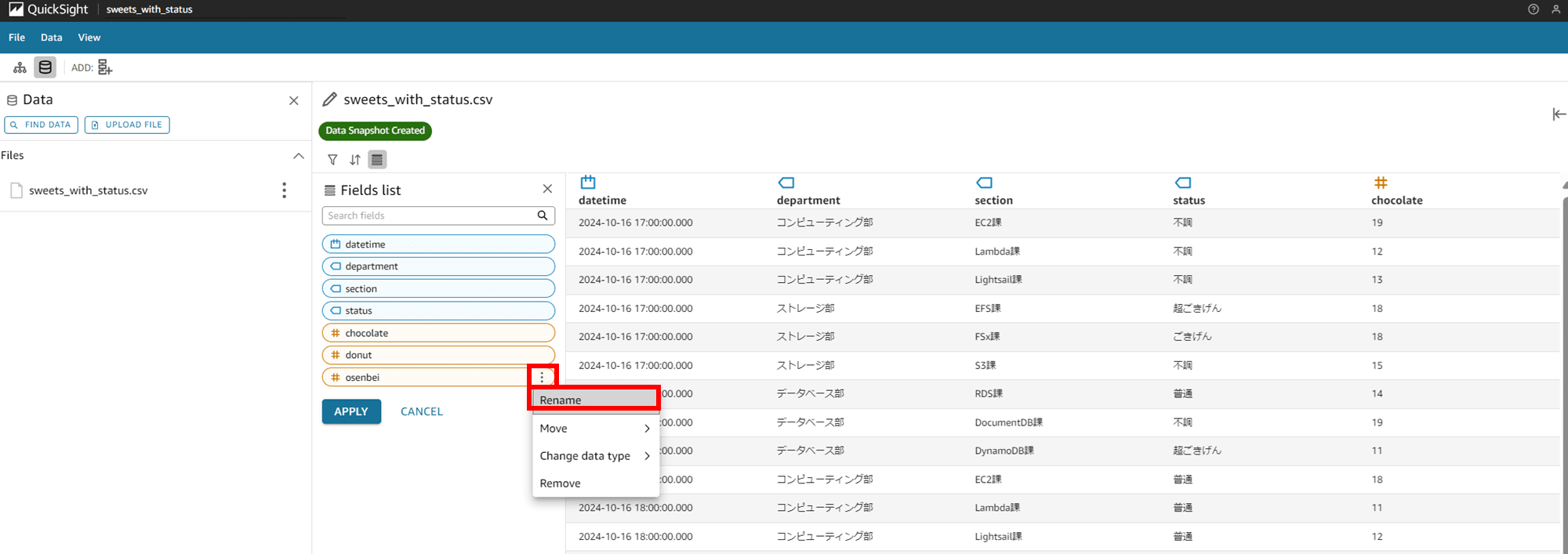
カラム名を編集し、「APPLY」で変更を反映します。
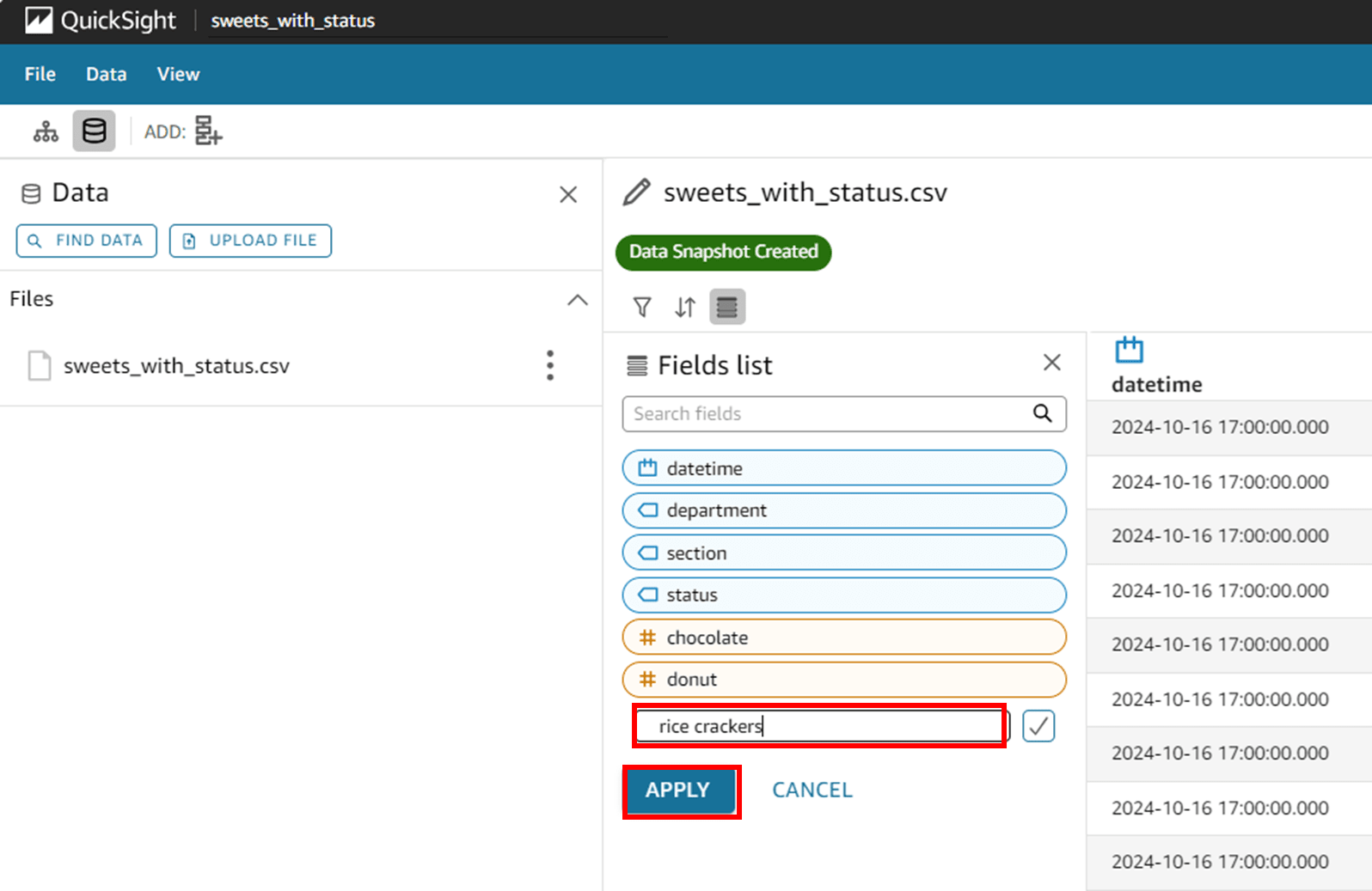
カラム名が rice crackers に変わりました。
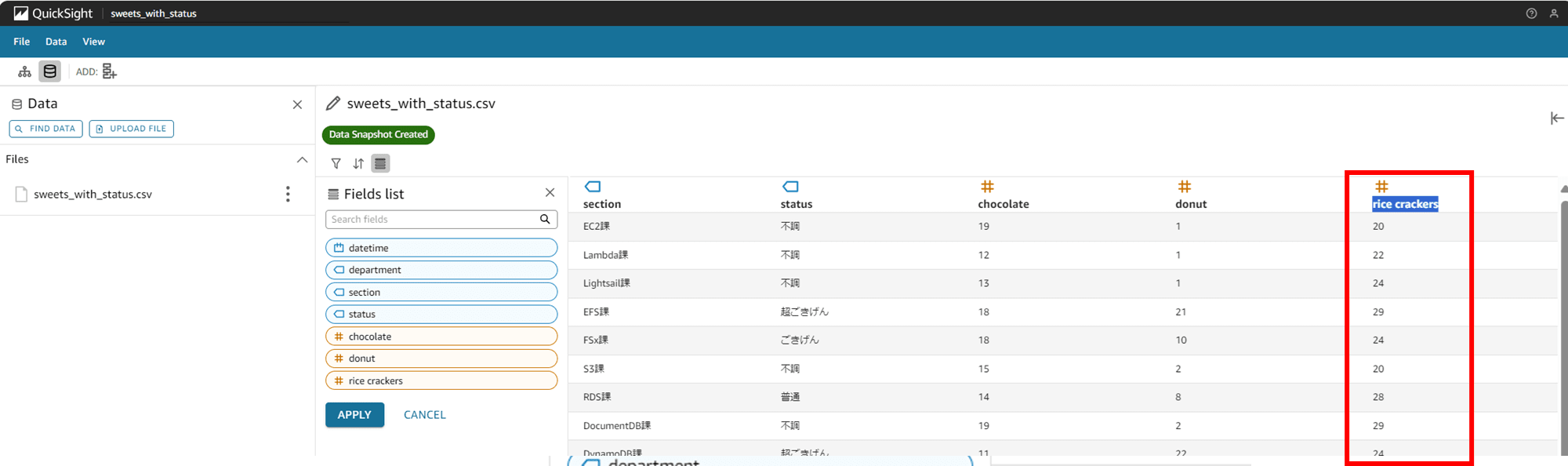
先ほどと同様、既存のシナリオには影響ありません。
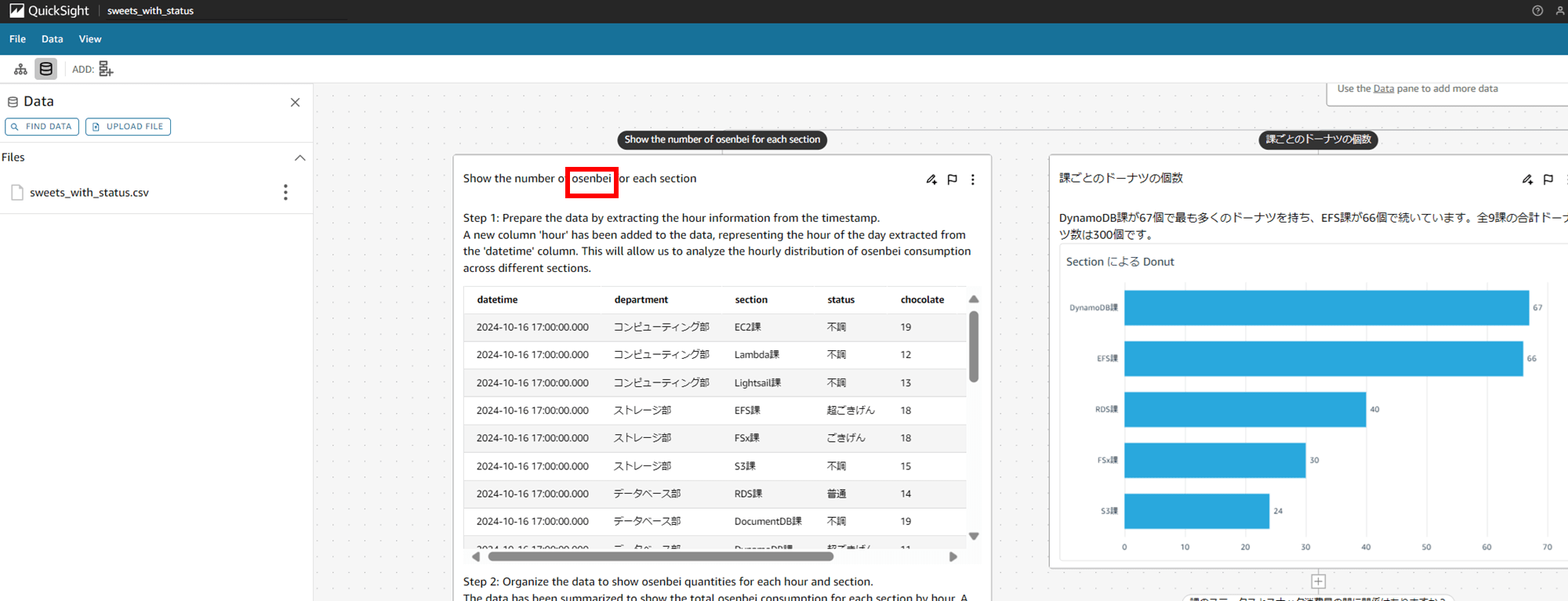
新たに rice crackers という表現を使ってシナリオにスレッドを追加してみましょう。
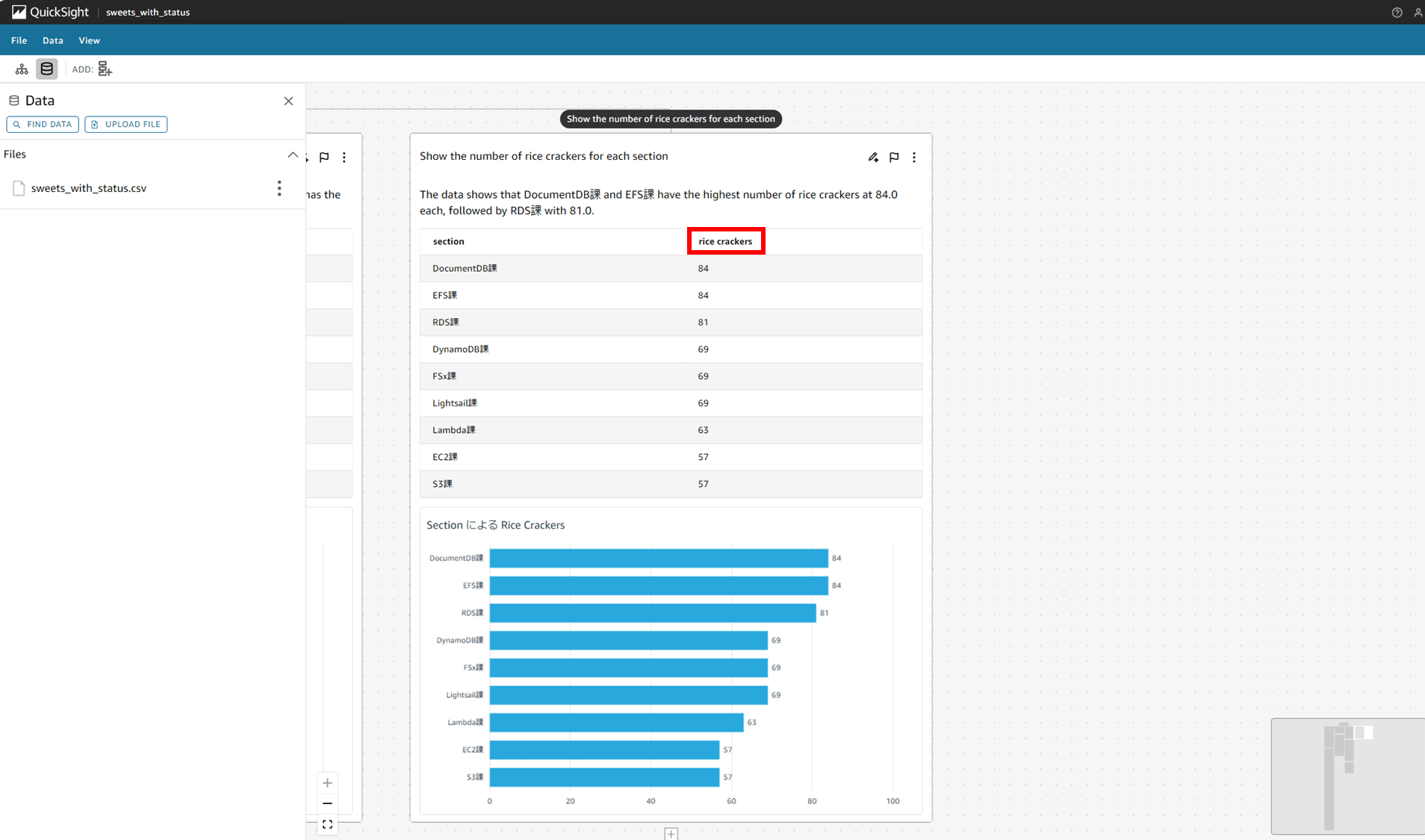
「Show the number of rice crackers for each section(課ごとのおせんべいの枚数を表示する」と入力して SUBMIT します。
1 分程度で推論が終わり、rice crackers フィールドの数値を計算して分析できました。これくらいならカラム名を変えなくても Q のモデルの方で解釈して分析してくれそうですが、こんな風にカラム名を変えて分析することもできそうですね。
おわりに
データのフィルタやソートをしても既存のシナリオには影響ありません。新しくリネームしたデータフィールドの情報を使って推論することもできました。
今回は CSV ファイルを直接アップロードしていましたが、ダッシュボードからシナリオを作成するパターンではどんな表示になるのか気になるので、今度はそちらもやってみます。








