
ワークショップを通じてAWS ParallelClusterに入門してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データ事業本部 インテグレーション部 機械学習チームの中村( @nokomoro3 )です。
今回は、以下のHPCのワークショップを通じてParallelClusterに入門してみたいと思います。
ParallelClusterの概要
AWSがサポートするオープンソースのクラスター管理ツールで、必要なコンピューティングリソース、スケジューラ、共有ファイルシステムが自動的に設定されます。
アーキテクチャとしては以下のようになっています。
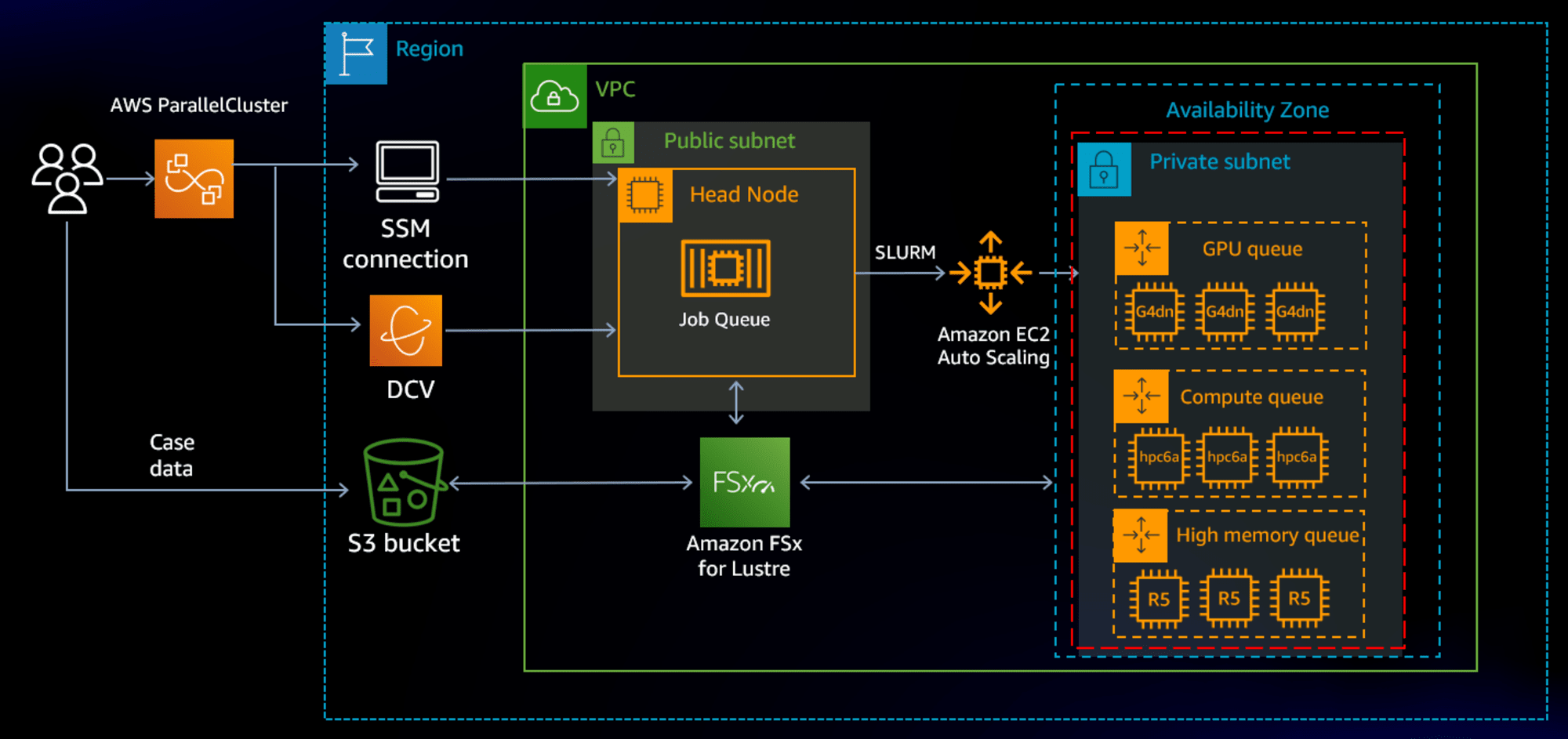
上記のように、Head NodeとなるEC2インスタンスに接続し、Head Node内でslurmというバッチスケジューラを実行することで、Compute NodeとなるEC2インスタンスをオートスケールさせてジョブを実行することができます。
実行されるワークロードは、バイオインフォマティクス系の処理であったり、近年では以下のブログで紹介されるような大規模言語モデル(LLM)の学習などにも使用することができます。
今回は、このParallelClusterのワークショップを実際にやってみたいと思います。
使用環境
使用環境は以下の通りです。
- OS: Windows 10 (WSLではありません)
- Git for Windows
なお、事前にAWS CLIはインストールしている前提とします。
aws --version
# aws-cli/2.13.15 Python/3.11.4 Windows/10 exe/AMD64 prompt/off
使用するリージョンは東京リージョンとします。
export AWS_REGION="ap-northeast-1"
途中、 pip またはそれに準じたPythonパッケージ管理ツール( uv や poetry など)が必要となりますので、そちらも事前にご準備ください。
実際のワークショップ内ではCloud9を用いていますが、本記事ではローカル環境を使用します。
また、AWSプロファイルの設定等は済んでいるものとして進めます。( AWS_PROFILE の設定など)
キーペアの作成
以下に沿った内容です。
ここでは、Head Nodeに接続するためのキーペアを作成します。
aws ec2 create-key-pair \
--key-name cm-nakamura-pcluster-key \
--query KeyMaterial \
--output text > cm-nakamura-pcluster-key.pem
作成を確認します。
aws ec2 describe-key-pairs
# {
# "KeyPairs": [
# {
# "KeyPairId": "...",
# "KeyFingerprint": "...",
# "KeyName": "cm-nakamura-pcluster-key",
# "KeyType": "rsa",
# "Tags": [],
# "CreateTime": "2024-09-14T05:27:24.581000+00:00"
# }
# ]
# }
pclusterコマンドのセットアップ
以下に沿った内容です。
ここでは、CLIでクラスタ作成などを行う pcluster というコマンドをセットアップします。
uv を使っているので以下でインストールします。( pip などでインストールもできますのでお好きなものをお使いください)
uv tool install aws-parallelcluster
インストールされたことを確認します。
pcluster version
# {
# "version": "3.10.1"
# }
クラスタ設定ファイルの作成
以下に沿った内容です。
こちらでは、クラスタの設定ファイルを作成します。
以下がそのひな形となります。
Region: ${AWS_REGION}
Image:
Os: alinux2
SharedStorage:
- MountDir: /shared
Name: default-ebs
StorageType: Ebs
HeadNode:
InstanceType: c5.xlarge
Networking:
SubnetId: ${SUBNET_ID}
ElasticIp: false
Ssh:
KeyName: ${KEY_NAME}
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: compute
CapacityType: ONDEMAND
ComputeResources:
- Name: compute
InstanceType: c5.xlarge
MinCount: 0
MaxCount: 8
DisableSimultaneousMultithreading: true
Networking:
SubnetIds:
- ${SUBNET_ID}
PlacementGroup:
Enabled: true
${AWS_REGION} , ${KEY_NAME} , ${SUBNET_ID} を適切に埋めて使用します。
${AWS_REGION} は ap-northeast-1 、 ${KEY_NAME} は先ほど作成した cm-nakamura-pcluster-key を指定します。
${SUBNET_ID} は今回、以下で取得したデフォルトのサブネットIDを使用しました。
aws ec2 describe-subnets \
--filters "Name=default-for-az,Values=true" \
--query "Subnets[].SubnetId" \
--output text
クラスタの作成
以下に沿った内容です。
先ほど作成した config.yaml を使用して、以下のコマンドでクラスタを作成します。
pcluster create-cluster --cluster-name cm-nakamura-hpc --cluster-configuration config.yaml
# {
# "cluster": {
# "clusterName": "cm-nakamura-hpc",
# "cloudformationStackStatus": "CREATE_IN_PROGRESS",
# "cloudformationStackArn": "...",
# "region": "ap-northeast-1",
# "version": "3.10.1",
# "clusterStatus": "CREATE_IN_PROGRESS",
# "scheduler": {
# "type": "slurm"
# }
# },
# "validationMessages": [
# {
# "level": "INFO",
# "type": "DeletionPolicyValidator",
# "message": "The DeletionPolicy is set to Delete. The storage 'default-ebs' will be deleted when you remove it from the configuration when performing a cluster update or deleting the cluster."
# }
# ]
# }
レスポンスに記載されているように、こちらを実行すると実際にはCloudFormationでリソースが作成されます。
クラスタの一覧やステータスはCLIでも確認することができます。
pcluster list-clusters
約10分程度待つとCloudFormationの実行が完了しました。
実行完了後は、EC2のコンソール画面でHead Nodeが立ち上がっていることも確認できました。

Head Nodeへのログイン
以下に沿った内容です。
立ち上がったクラスタのHead Nodeにアクセスしていきます。
Head Nodeへは以下でアクセスすることができます。
pcluster ssh --cluster-name cm-nakamura-hpc -i cm-nakamura-pcluster-key.pem
# Last login: Sat Sep 14 03:16:55 2024
# , #_
# ~\_ ####_ Amazon Linux 2
# ~~ \_#####\
# ~~ \###| AL2 End of Life is 2025-06-30.
# ~~ \#/ ___
# ~~ V~' '->
# ~~~ / A newer version of Amazon Linux is available!
# ~~._. _/
# _/ _/ Amazon Linux 2023, GA and supported until 2028-03-15.
# _/m/' https://aws.amazon.com/linux/amazon-linux-2023/
#
# 43 package(s) needed for security, out of 56 available
# Run "sudo yum update" to apply all updates.
これ以降はHead Node内での作業となります。
VSCodeのRemote SSH機能などでアクセスしたい場合は、以下をローカルマシンの ~/.ssh/config に記載して接続ください。
Host cm-nakamura-hpc
HostName {Head NodeのIPアドレス}
User ec2-user
IdentityFile {cm-nakamura-pcluster-key.pemファイルへのパス}
ジョブの実行
以下に沿った内容です。
Head Node内では、slurmというバッチスケジューラのコマンドが既に実行できるような状態となっています。
以降で出てくる sbatch , squeue , sinfo などはslurmのコマンドとなります。
slurmのコマンドについての詳細は以下を参照ください。
ワークショップでは、MPIを使用した並列処理のサンプルプログラムをコンパイルして実行しています。
以下で mpi_hello_world.c を作成します。
cat > mpi_hello_world.c << EOF
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#include <unistd.h>
int main(int argc, char **argv){
int step, node, hostlen;
char hostname[256];
hostlen = 255;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &node);
MPI_Get_processor_name(hostname, &hostlen);
for (step = 1; step < 5; step++) {
printf("Hello World from Step %d on Node %d, (%s)\n", step, node, hostname);
sleep(2);
}
MPI_Finalize();
}
EOF
次にモジュールをロードし、コンパイルして実行ファイルを作成します。
module load intelmpi
mpicc mpi_hello_world.c -o mpi_hello_world
次にサブミットする実行スクリプトを準備します。
cat > submission_script.sbatch << EOF
#!/bin/bash
#SBATCH --job-name=hello-world-job
#SBATCH --ntasks=4
#SBATCH --output=%x_%j.out
mpirun ./mpi_hello_world
EOF
以下でジョブをサブミットされ、処理が開始されます。
sbatch submission_script.sbatch
# Submitted batch job 1
squeueコマンドを使用してキューの状態を見ることができ、サブミットしたジョブを確認することができます。
squeue
# JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
# 1 compute hello-wo ec2-user CF 0:10 2 compute-dy-compute-[1-2]
sinfoコマンドを使用して、クラスタで利用可能なノードと状態を確認することができます。
sinfo
# PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
# compute* up infinite 2 alloc# compute-dy-compute-[1-2]
# compute* up infinite 6 idle~ compute-dy-compute-[3-8]
ここでのステータスは以下の種類があるようです。
| State | Description |
|---|---|
| idle~ | インスタンスは実行されていないが、ジョブが投入されると起動できる。 |
| alloc | インスタンスは割り当てられている。 |
| idle% | インスタンスは実行中で、ScaledownIdletime が経過するとシャットダウンする (デフォルトは 10 分) |
| mix | インスタンスは部分的に割り当てられている。 |
ワークショップの記載も参照ください。
実際、EC2のコンソール画面でも2つのインスタンスが起動されている状態となっていました。

ジョブはすぐに完了するので、結果を以下で確認することができます。
cat hello-world-job_1.out
# MPI startup(): PMI server not found. Please set I_MPI_PMI_LIBRARY variable if it is not a singleton case.
# MPI startup(): PMI server not found. Please set I_MPI_PMI_LIBRARY variable if it is not a singleton case.
# Hello World from Step 1 on Node 0, (compute-dy-compute-2)
# Hello World from Step 1 on Node 0, (compute-dy-compute-2)
# Hello World from Step 1 on Node 0, (compute-dy-compute-1)
# Hello World from Step 1 on Node 0, (compute-dy-compute-1)
# Hello World from Step 2 on Node 0, (compute-dy-compute-2)
# Hello World from Step 2 on Node 0, (compute-dy-compute-2)
# Hello World from Step 2 on Node 0, (compute-dy-compute-1)
# Hello World from Step 2 on Node 0, (compute-dy-compute-1)
# Hello World from Step 3 on Node 0, (compute-dy-compute-2)
# Hello World from Step 3 on Node 0, (compute-dy-compute-2)
# Hello World from Step 3 on Node 0, (compute-dy-compute-1)
# Hello World from Step 3 on Node 0, (compute-dy-compute-1)
# Hello World from Step 4 on Node 0, (compute-dy-compute-2)
# Hello World from Step 4 on Node 0, (compute-dy-compute-2)
# Hello World from Step 4 on Node 0, (compute-dy-compute-1)
# Hello World from Step 4 on Node 0, (compute-dy-compute-1)
ジョブ完了後もインスタンスはしばらく稼働していますが、しばらくまつとシャットダウンしていました。
クラスタの削除
最後にクラスタを削除しておきました。以下を実行するとCloudFormationのスタックごと削除されます。
pcluster delete-cluster --cluster-name cm-nakamura-hpc
# {
# "cluster": {
# "clusterName": "cm-nakamura-hpc",
# "cloudformationStackStatus": "DELETE_IN_PROGRESS",
# "cloudformationStackArn": "...",
# "region": "ap-northeast-1",
# "version": "3.10.1",
# "clusterStatus": "DELETE_IN_PROGRESS",
# "scheduler": {
# "type": "slurm"
# }
# }
# }
まとめ
いかがでしたでしょうか。本記事がAWS ParallelClusterをお使いになる方の参考になれば幸いです。







