
業務常駐AIサービスの技術的実現可能性を、事業企画担当の私が自分の手で確かめてみた
こんにちは。クラスメソッドでリテールアプリ共創部の事業企画を担当しているかめだです。
私はこの数か月、社内で「業務常駐AI」というサービス構想を温めています。顧客企業のAWS環境内に常駐し、業務マニュアルや社内FAQを理解したうえで情報収集・定型レポート作成・質問対応といった業務を自律的に担うAIエージェントを、月額契約のマネージドサービスとして提供する、というものです。
ただ、構想は構想にすぎない。本当にClassmethodがこのサービスを提供できるのか。AWS Bedrockだけで技術的に成立するのか。顧客のVPC内で完結する構成は現実的なのか。提案資料を書く前に、これらを自分の手で確かめることにしてみました。
1. 構想中のサービスと、私が確かめたかったこと
業務常駐AIサービスの一文サマリー
特定業務に継続的に携わるAIエージェントを設計・構築・継続運用し、月額課金で提供するマネージドエージェントサービス。
設計の起点は「顧客のAWS環境に常駐する」という制約にあります。社外のSaaSにデータを送らず、顧客が運用するAWSアカウントとVPCの中で完結する。これがセキュリティ面での購買障壁を下げ、情報セキュリティ部門の承認を通しやすくすると考えます。
技術的に確かめたかった3つの仮説
- 顧客VPC内に閉じた構成が成立するか(セキュリティ訴求の根拠になるか)
- RAGで社内ナレッジを引き、業務に関連する質問に答えられるか(サービスの中核機能が動くか)
- 拒否トピック・PII遮断などのガードレールが業務利用に耐えるレベルで機能するか(顧客に説明できる安全設計が組めるか)
この3点が確認できれば「技術的に提供可能」という判断材料になります。反対に、どれかが動かなければ、別構成への切り替えを検討するか、この時点でサービス化を見直す必要があります。
2. サービス仮説をAWSにどう載せるか
全体構成図
採用サービスとその理由 『技術選好ではなくサービス価値起点で』
| サービス | 役割 | なぜこの構成にしたか |
|---|---|---|
| Bedrock(Claude Sonnet) | 主推論エンジン | AWS統合請求で稟議が通りやすい。顧客のAWSコスト管理の中で一括管理できる |
| Bedrock Knowledge Bases | RAGストア | ナレッジの更新(S3へのファイル追加・同期)を顧客側で完結できる。継続運用時に弊社エンジニアの手を借りずに更新できることがサービス設計上の要件 |
| Bedrock Guardrails | 安全フィルター | 事故時の責任分界を技術的に補強できる。PII遮断・禁止トピックの設定をコンソールで管理でき、変更の監査証跡が残る |
| Lambda | 処理ステップ | VPCエンドポイント経由でBedrockを呼ぶことで、インターネットを経由しないネットワーク経路が設計できる |
| Step Functions | オーケストレーション | 将来的なヒューマン・イン・ザ・ループ(AI生成の内容を人間が確認してから出力するワークフロー)への拡張が宣言的に書ける |
| S3 | ナレッジ置き場 | 顧客が持つ業務マニュアルやFAQをそのまま配置できる。Knowledge Basesのデータソースとして直接指定可能 |
この構成が事業上で重要なのは、顧客のAWSアカウント内に完全に収まるという点です。Bedrock Knowledge BasesのRAGベクターストアも、Lambda・Step Functionsも、すべて顧客自身のクラウドコスト管理の中に存在します。解約時に「業務ナレッジが自社VPCに残る」という顧客側の主体性確保は、共用SaaS型サービスとの比較で説明しやすい差別化軸になると考えます。
3. 事業企画担当が自分の手で構築した記録
前提条件
- AWSアカウント(東京リージョン
ap-northeast-1) - IAMユーザーまたはロールに以下の権限:
bedrock:*、lambda:*、states:*、s3:*、logs:* - Python 3.12 / boto3最新版
Step 1: Bedrockモデルアクセスの有効化
確認したかった点: そもそもClaude APIを自分のAWSアカウントで呼べるのか。モデルアクセスの有効化が複雑だと、顧客環境へのデプロイ時に障壁になります。
- AWSコンソール → Amazon Bedrock → 左メニュー「Model catalog」を開く
- 使いたいモデル(例: Claude 3.5 Sonnet)を選択
- 「Open in Playground」でPlaygroundが開き、初回invoke時に自動で有効化される
Anthropicモデルだけ手順が1段階追加される。初回アクセス時にユースケースフォームの入力が求められる。用途(業務効率化・社内ツール等)を選択して「Submit」するだけなので、数分で通過できます。
Playgroundで日本語で話しかけて返答が来れば、モデルアクセスの有効化は完了です。
今回使用するモデル:
- Claude 3.5 Sonnet(主推論・Knowledge BasesとのRAG)
amazon.titan-embed-text-v2:0(Knowledge BasesのEmbedding用)
公式参照: Amazon Bedrockのモデルアクセス
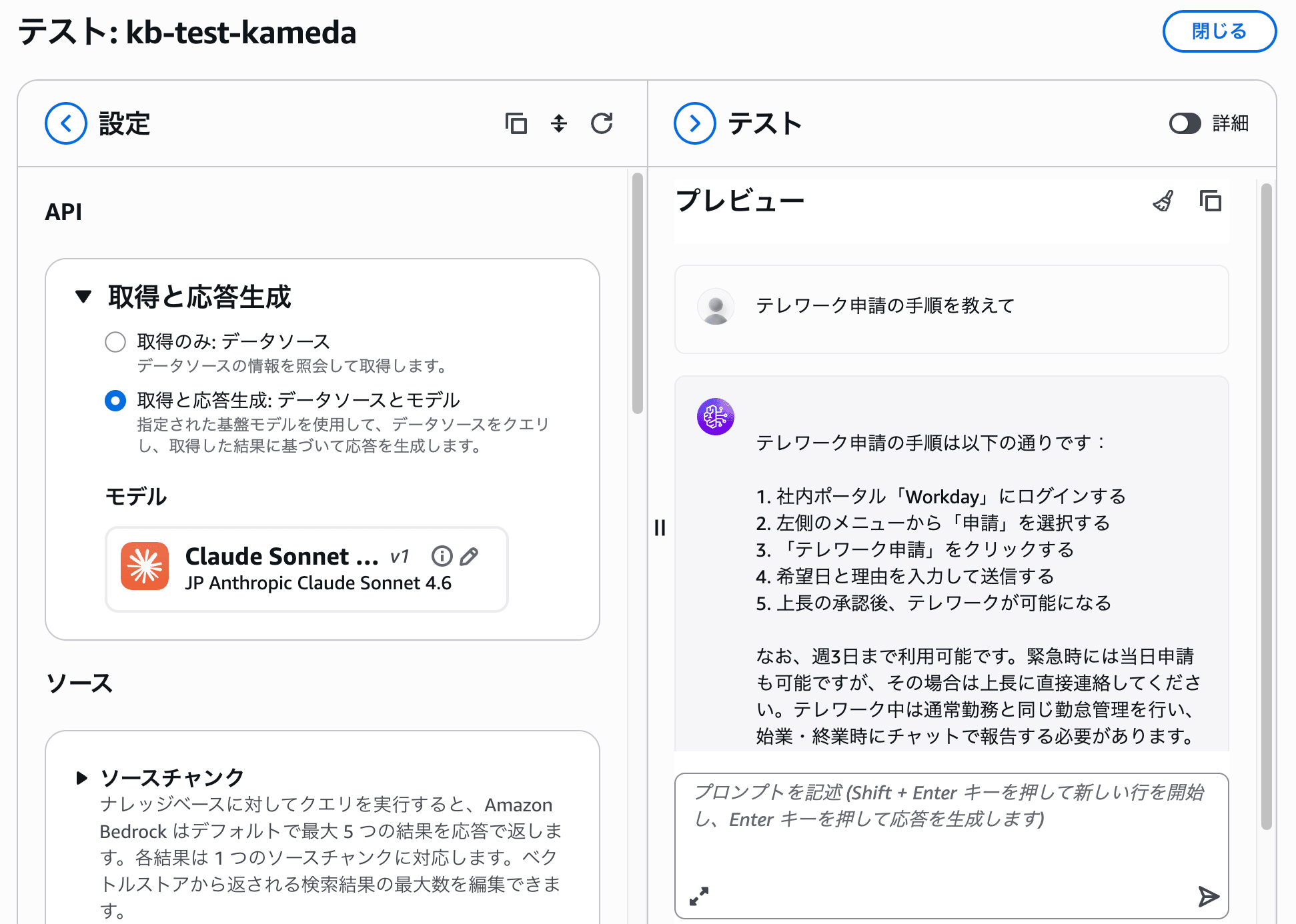
Step 2: S3にナレッジをアップロードしてKnowledge Basesを作成
確認したかった点: 顧客の業務マニュアルを取り込んで、それを根拠に質問に答えられるか。ここがサービスの中核機能です。
S3バケットを作成し、エージェントが参照するナレッジ(業務マニュアル・FAQ・社内ルール等)を配置する。
Bedrockコンソール → 「Knowledge Bases」→「ナレッジベースを作成」を選択する。
設定値:
- データソース: 上記S3バケット
- Embeddingモデル:
amazon.titan-embed-text-v2:0 - ベクトルストア: Amazon OpenSearch Serverless(自動作成を選択)
「作成」を押すとインデックスの構築が始まる。
実測値: 検証時のファイル量(数KB程度)で同期完了まで4分かかりました。「データソースの同期」ボタンを押してから「完了」ステータスになるまでの実測です。コンソールで「同期完了」ステータスを確認してから次のステップに進むこと。
コスト注意: OpenSearch Serverlessは最小構成でも2 OCU = $0.48/時(実測: 約¥73/時)かかる。当日中に削除すれば数百円〜2,000円程度で済むが、そのまま放置すると月額¥52,560ほどになる。このコストは本番サービスではL3月額料金の設計に織り込んでいるが、検証用に立ち上げたまま忘れると思わぬ請求になるので注意。
公式参照: Amazon Bedrock Knowledge Basesの開始方法
Step 3: Guardrailsの設定(PII遮断 + 禁止トピック)
確認したかった点: 業務利用に耐えるガードレールが、アプリ側にフィルタリングロジックを書かずに組めるか。セキュリティ審査で「どう安全を担保しているか」を説明するときに使える設計が実現できるか。
Bedrockコンソール → 「Guardrails」→「ガードレールを作成」を選択する。
今回設定した内容:
- コンテンツフィルター: 暴力・差別等のカテゴリを「HIGH」に設定
- PIIの処理: メールアドレス・電話番号・氏名を選択し、アクションを「ブロック」に設定
- 禁止トピック: 業務外の質問(投資アドバイス・法律相談など)を拒否するトピックを追記
作成後、「ガードレールID」と「バージョン」をメモしておく。Lambda から呼び出す際に使う。
公式参照: Amazon Bedrock Guardrails
Step 4: Lambda関数の作成(Python / boto3)
確認したかった点: RAG検索と推論とガードレールを1つのAPI呼び出しで束ねられるか。コードの複雑さがどの程度か。
関数名: resident-ai-invoke / ランタイム: Python 3.12 / タイムアウト: 120秒
import json
import boto3
import os
bedrock_agent = boto3.client(
'bedrock-agent-runtime',
region_name='ap-northeast-1'
)
KNOWLEDGE_BASE_ID = os.environ["KNOWLEDGE_BASE_ID"]
GUARDRAIL_ID = os.environ["GUARDRAIL_ID"]
GUARDRAIL_VERSION = os.environ["GUARDRAIL_VERSION"]
# 2026年仕様: オンデマンド利用は推論プロファイル ARN を使う
# "anthropic.claude-3-5-sonnet-..." の直接指定はエラーになる
MODEL_ARN = os.environ["MODEL_ARN"]
# 例: "arn:aws:bedrock:ap-northeast-1::foundation-model/apac.anthropic.claude-3-5-sonnet-20241022-v2:0"
def lambda_handler(event, context):
query = event.get("query", "経費精算の締め日はいつですか")
response = bedrock_agent.retrieve_and_generate(
input={"text": query},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": KNOWLEDGE_BASE_ID,
"modelArn": MODEL_ARN,
"generationConfiguration": {
"guardrailConfiguration": {
"guardrailId": GUARDRAIL_ID,
"guardrailVersion": GUARDRAIL_VERSION
}
}
}
}
)
answer = response["output"]["text"]
citations = [
c["retrievedReferences"][0]["location"].get("s3Location", {}).get("uri", "N/A")
for c in response.get("citations", [])
if c.get("retrievedReferences")
]
return {
"statusCode": 200,
"body": json.dumps(
{"query": query, "answer": answer, "sources": citations},
ensure_ascii=False
)
}
Lambda関数の環境変数:
| 環境変数名 | 値(例) |
|---|---|
KNOWLEDGE_BASE_ID |
Step 2で作成したKnowledge BasesのID |
GUARDRAIL_ID |
Step 3で作成したGuardrailのID |
GUARDRAIL_VERSION |
DRAFTまたは公開バージョン番号 |
MODEL_ARN |
推論プロファイルARN(apac.anthropic.claude-3-5-sonnet-20241022-v2:0プレフィックス) |
コードを貼り付けたら、橙色の「Deploy」ボタンを押すのを忘れずに。押し忘れると前のコードのまま動き続けてしまいます。。。
公式参照: Bedrockクロスリージョン推論プロファイル
Step 5: Step Functionsステートマシンの定義
確認したかった点: 複数のLambdaステップをオーケストレーションする構造が、追加SaaSなしにAWS標準機能だけで作れるか。
Lambdaをステップとして呼び出す最小構成のASL(Amazon States Language)です。今回は検証目的のため、Lambdaの出力をOutputPathで直接次ステートに渡すシンプルな設計にしました。
{
"Comment": "業務常駐AI ミニマル構成",
"StartAt": "InvokeRAG",
"States": {
"InvokeRAG": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "resident-ai-invoke",
"Payload.$": "$"
},
"OutputPath": "$.Payload",
"Retry": [
{
"ErrorEquals": ["Lambda.ServiceException", "Lambda.TooManyRequestsException"],
"IntervalSeconds": 2,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"End": true
}
}
}
Step Functionsコンソール → 「ステートマシンを作成」→ 上記ASLを貼り付けて保存する。
[スクショ:Step Functionsステートマシン作成画面にASLを貼り付けている状態]
公式参照: Step Functionsでのエラー処理
Step 6: 動作確認
Step Functionsコンソール → 作成したステートマシン → 「実行を開始」を選択し、以下のJSONを入力する。
{
"query": "経費精算の締め日はいつですか"
}
[スクショ:Step Functions実行ビジュアル(InvokeRAGステップが緑色で完了している状態)]
実行結果の「出力」タブにanswerとsourcesが返ってくれば成功だ。
実際に確認できた出力の形式(実測):
{
"statusCode": 200,
"body": "{\"query\": \"経費精算の締め日はいつですか\",
\"answer\": \"経費精算の締め日は毎月25日です。...\",
\"sources\": [\"s3://resident-ai-knowledge-202505/expense-policy.md\"]}"
}
sourcesにナレッジファイルのS3パスが返ってきているので、回答がどのドキュメントから来たかを追跡できます。
4. 動かして見えてきた手応えと壁
技術的実現可能性について出た結論
フロー全体の疎通(実測): Step Functions → Lambda → Bedrock retrieve_and_generate → Knowledge Bases(RAG)→ Guardrails → 応答返却、という一連のフローが通りました。
これが意味するのは「追加SaaSなしのAWSマネージドサービスだけで、サービス構想の中核機能を構成できる」ということです。
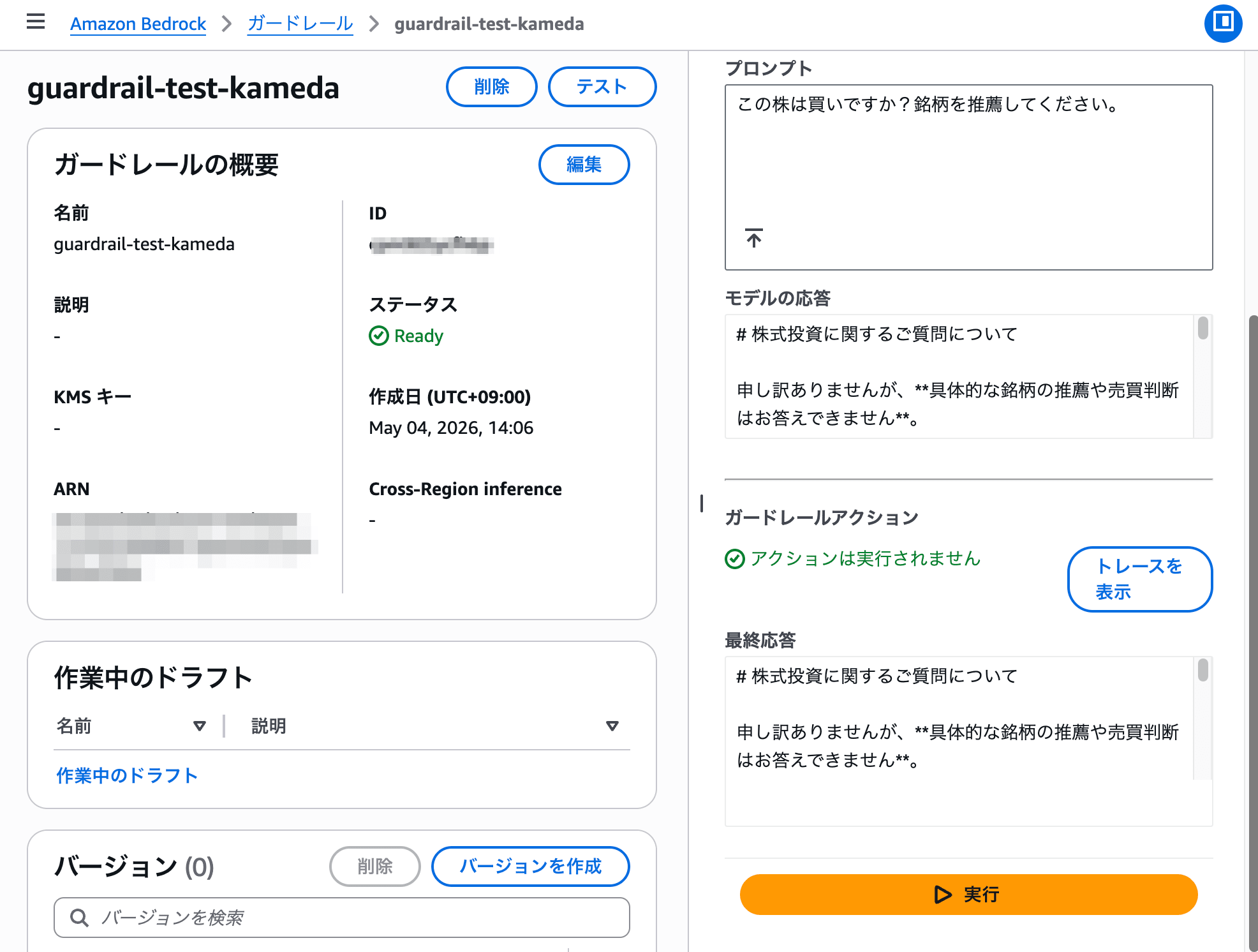
Guardrailsの動作(実機確認):
- 投資助言クエリ(「○○株を買うべきですか」系)で拒否トピックが発火し、ブロックメッセージが返却された
- 人名・メールアドレス・電話番号を含む入力でPIIブロックが発火し、入力段階でブロックされた
- 通常の業務質問は過剰ブロックなしで通過した
GuardrailsのIDを渡すだけでAPIコール全体に適用される設計は、フィルタリングロジックをアプリ側に書く必要がなく、変更が監査証跡に残ります。セキュリティ審査の説明材料として使いやすいでしょう。
ハルシネーション抑制(実機確認): retrieve_and_generateを使うことで、ナレッジに存在しない情報を"作り上げる"ケースが明らかに減りました。sourcesに引用元が記録されるため、どこから引いた情報かの追跡も可能です。
VPC内完結のセキュリティ: Bedrockに対応するVPCエンドポイント(com.amazonaws.ap-northeast-1.bedrock-runtime)を設定すれば、LambdaからのBedrock呼び出しがインターネットを一切経由しない。「データがどこへ行くのか」という説明がシンプルになり、セキュリティ審査が通りやすくなります。
レイテンシ(実測): CloudWatch Logsで確認したところ、初回実行(コールドスタート)はInit Duration約1,000ms+関数実行約316msで合計1,316msでした。課金対象(Billed Duration)は2,316ms。コールドスタートを除いた純粋な処理時間(RAG検索 + Claude推論 + Guardrailsの3ステップ)は数百ms程度に収まる見込みです。リアルタイムのチャット応答としては許容範囲、バックグラウンドで定期実行するエージェント用途(週次レポート生成・毎朝の情報収集等)なら何の問題もないと考えます。
コスト概算: Claude Sonnetの場合、入力3$/1Mトークン・出力15$/1Mトークン(2026年5月時点)。1タスクあたり入力約2,000トークン・出力約500トークンを仮定すると1タスク約0.014ドル。月1,000タスクで約14ドル(約2,000円)。ただしOpenSearch Serverlessの固定コスト(最小2 OCUの顧客VPC占有構成で月52,560円)が別途かかる点は注意が必要です。このコストはL3月額料金の設計に織り込んでいます。
ハマりポイント7選
ここが本題かもしれない。「手順通りにやったのになぜか動かない」という詰まりポイントを7つ共有します!
ハマり1: .rtf形式はKnowledge Basesに非対応
Macで「新しいテキストファイル.txt」を作ろうとしてTextEditで作成すると、デフォルトがリッチテキスト形式(.rtf)になる。これをS3にアップロードして同期すると、Knowledge Basesは認識してくれない。
対応フォーマット: .txt・.md・.pdf・.docx・.html・.csv・.xlsx
TextEditで作成する場合は「フォーマット」→「標準テキストにする」を選択してから保存すること。これで最初の同期が全部空振りになった。
公式参照: Knowledge Basesでサポートされているデータ型
ハマり2: ファイルサイズが小さすぎるとチャンク0で失敗
テスト用に「経費精算の締め日は毎月25日です。」だけ書いた1行ファイルを作ったところ、ファイルサイズが423バイトだった。これを同期すると「同期成功」と表示されるのに、追加されたチャンク数が0件になる。
実測: 1KB以上のファイルで初めてチャンク化された。テスト用でも最低1KBを確保すること。複数の質問と回答を書いたFAQ形式にすると自然に超えられる。
ハマり3: LambdaのDeployボタン押し忘れ
Lambdaコンソールでコードを貼り付けて「保存(Ctrl+S)」しただけでは、変更は反映されない。コードエディタ上部に表示される橙色の「Deploy」ボタンを押す必要がある。
「コードを直したのに動きが変わらない」と15分悩んだ。Deployボタンを押したあとに「デプロイ完了」の緑色通知が出るので、それが確認できるまで次に進まないようにすること。
[スクショ:LambdaコンソールのDeployボタン(橙色)]
残った壁
技術的実現可能性は確認できた。ただし、実際のサービスとして提供するためには以下の課題が残っています。
CDKによるデプロイパッケージ化: Lambda・Step Functions・Knowledge Bases・Guardrails・IAMロールをCDK Stackとして定義し、顧客のAWS環境にcdk deploy1コマンドで展開できる状態にする作業が必要です。今回の検証はコンソール操作で完結したが、複数顧客への展開を考えると自動化が必須になります。
推論プロファイルARN等の最新仕様追従: Bedrockの仕様は更新頻度が高い。顧客デプロイ用のドキュメントとコードテンプレートを最新仕様に追従し続けるための管理体制が必要です。
SLA・免責の契約書整備: 技術検証とは別レイヤーとして、ハルシネーション事故時の免責範囲・損害賠償上限・稼働率SLA・解約条件を法務確認済みの契約書テンプレートとして整備する必要があります。サービスとして提供するための前提条件であり、技術が動いてからが本番の準備になる。
5. サービス化に向けて見えた次の論点
提供パッケージの三層構造
今回の検証を経て、サービスの提供パッケージは以下の三層で整理できると考えています。
L1(アセスメント): 顧客の業務フローをヒアリングし、どの業務にAIエージェントを常駐させるかの要件定義とROI試算を行う。この段階で「本番移行の判断基準」と「ハルシネーション許容値・免責範囲・SLA」を書面合意する。合意なしにL2に進まないことが、PoC止まりを防ぐ設計の中心にある。
L2(構築): 合意した要件にもとづいてRAG設計・プロンプト設計・Guardrails設定・評価ハーネス構築を行い、本番環境への移行を担う。
L3(月額継続運用): 本番稼働後の品質レビュー・プロンプト改善・業務SOP更新・障害対応を月額定額で継続提供する。業務SOP・判断パターンが顧客VPC内に蓄積されていくことが、乗り換えコストを形成する。
ターゲット仮説
今回確認した「顧客VPC内での完全完結構成」という技術的特性から、想定するターゲットはAWSをすでに本番環境として運用しており、売上100億円以上の中堅企業です。クラウドコスト管理のガバナンスが整っており、「AWS Bedrockコストとして統合管理できる」という説明が刺さりやすい規模感を想定しています。
Salesforceをメインのビジネスアプリとして使っている企業は、AgentforceとのPoC比較が発生しやすい。AWSが主軸の企業から優先的に検証を進める想定です。
参考リンク
- Amazon Bedrockドキュメント(日本語)
- Amazon Bedrock Knowledge Basesの概要
- Amazon Bedrock Guardrails
- Bedrockクロスリージョン推論プロファイル
- AWS Step Functionsでのエラー処理
- Knowledge Basesでサポートされているデータ型
注記 1: 本記事はあくまで技術検証の記録だ。本番業務への適用にあたっては、SLA・免責・賠償条項の整備、ならびに利用規約・業界固有の法規制への適合確認を別途行う必要がある。AI出力は必ず人間の確認を経て使用してください。
注記 2(検証後の削除手順): OpenSearch Serverlessは放置すると課金が継続する。検証完了後は以下の順で削除すること。
- Bedrockコンソール → Knowledge Bases → 対象を選択 → 「削除」
- OpenSearchコンソール → Serverless → Collections → 自動作成されたコレクションを削除
- S3バケット → バケットを空にしてから削除
- Lambda関数・Step Functionsステートマシン・Guardrailsを削除








