
Amazon Q in QuickSight でトピックを作成しデータセットに Q&A してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
先日以下のブログで Amazon Q in QuickSight のハンズオンをご紹介しました。
ハンズオンだとあらかじめアセットもトピックも作成済みだったので、いまいち操作が腹落ちしなかった部分もありました。
そこで、今回は自分で用意した CSV の元データからデータセットとトピックを作成し、データセットに対して Q&A をするまで実施してみます。
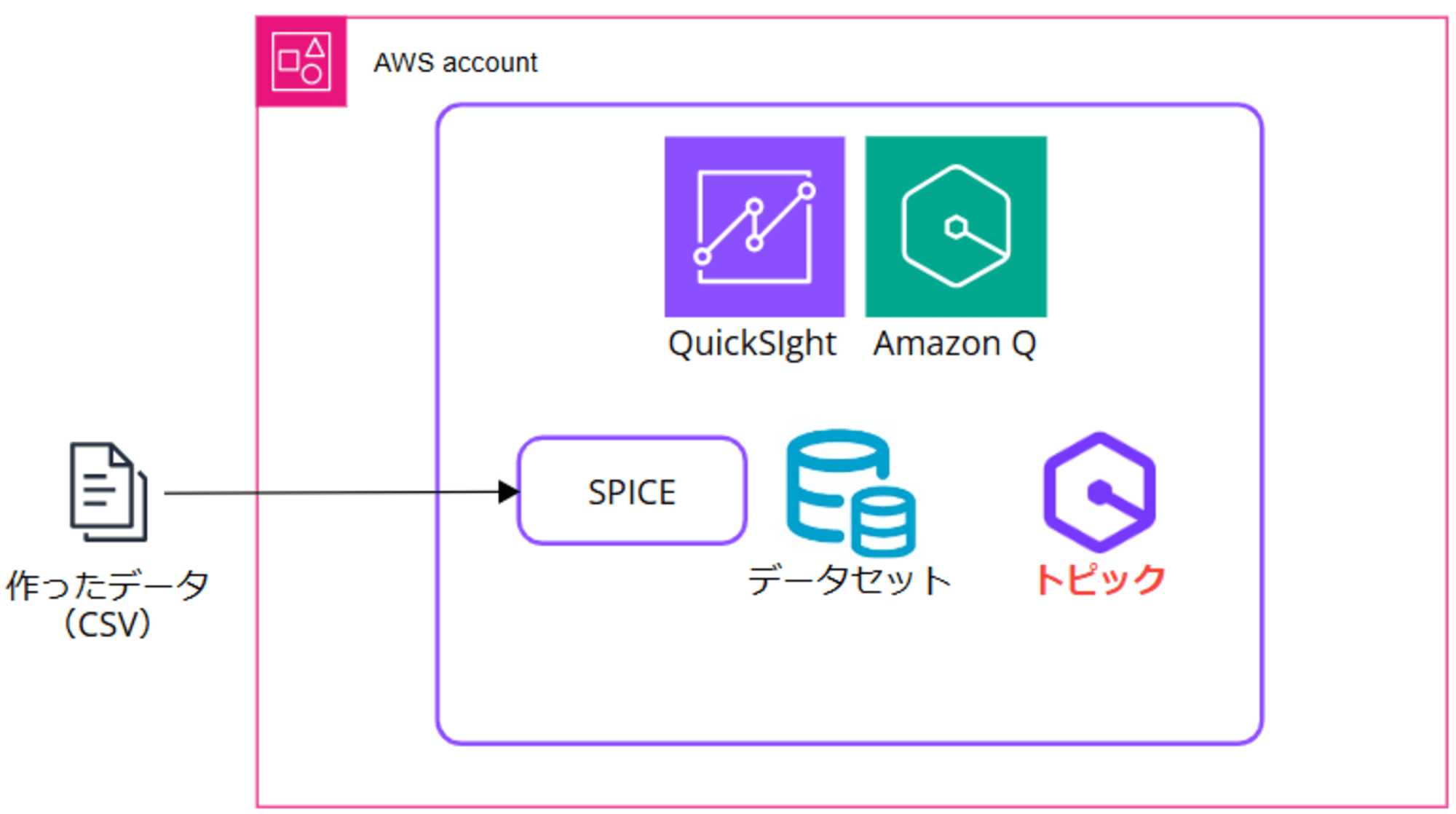
最初にイメージ
ざっくり以下のようなイメージです。
| タブ | 内容 |
|---|---|
| Sammary | 概要 |
| Data | データセットの確認と追加、トピックの更新、シノニムの設定、NAMED ENTITY の設定 |
| User Activity | 過去の Q&A 履歴の確認 |
| Suggested Questions | よく使う Q&A 質問文の登録、生成 AI が生成して提案してくれる質問文の一覧 |
作成した CSV
ある会社でお菓子を食べたり持ってきて補充するデータです。お菓子を食べたらごきげんになったり、お菓子が無くて不調になったりする会社をイメージしました。

datetime,department,section,status,chocolate,donut,osenbei
2024-10-16 17:00:00.000,コンピューティング部,EC2課,不調,19,1,20
2024-10-16 17:00:00.000,コンピューティング部,Lambda課,不調,12,1,22
2024-10-16 17:00:00.000,コンピューティング部,Lightsail課,不調,13,1,24
2024-10-16 17:00:00.000,ストレージ部,EFS課,超ごきげん,18,21,29
2024-10-16 17:00:00.000,ストレージ部,FSx課,ごきげん,18,10,24
2024-10-16 17:00:00.000,ストレージ部,S3課,不調,15,2,20
2024-10-16 17:00:00.000,データベース部,RDS課,普通,14,8,28
2024-10-16 17:00:00.000,データベース部,DocumentDB課,不調,19,2,29
2024-10-16 17:00:00.000,データベース部,DynamoDB課,超ごきげん,11,22,24
2024-10-16 18:00:00.000,コンピューティング部,EC2課,普通,18,8,19
2024-10-16 18:00:00.000,コンピューティング部,Lambda課,普通,11,8,21
2024-10-16 18:00:00.000,コンピューティング部,Lightsail課,普通,12,8,23
2024-10-16 18:00:00.000,ストレージ部,EFS課,超ごきげん,17,20,28
2024-10-16 18:00:00.000,ストレージ部,FSx課,超ごきげん,17,20,23
2024-10-16 18:00:00.000,ストレージ部,S3課,普通,14,9,19
2024-10-16 18:00:00.000,データベース部,RDS課,ごきげん,13,12,27
2024-10-16 18:00:00.000,データベース部,DocumentDB課,普通,18,6,28
2024-10-16 18:00:00.000,データベース部,DynamoDB課,超ごきげん,10,23,23
2024-10-16 19:00:00.000,コンピューティング部,EC2課,不調,17,1,18
2024-10-16 19:00:00.000,コンピューティング部,Lambda課,ごきげん,10,12,20
2024-10-16 19:00:00.000,コンピューティング部,Lightsail課,ごきげん,11,13,22
2024-10-16 19:00:00.000,ストレージ部,EFS課,超ごきげん,16,25,27
2024-10-16 19:00:00.000,ストレージ部,FSx課,不調,16,0,22
2024-10-16 19:00:00.000,ストレージ部,S3課,ご機嫌,13,13,18
2024-10-16 19:00:00.000,データベース部,RDS課,超ごきげん,12,20,26
2024-10-16 19:00:00.000,データベース部,DocumentDB課,ご機嫌,18,12,27
2024-10-16 19:00:00.000,データベース部,DynamoDB課,超ごきげん,9,22,22
CSV のひな形は生成 AI に生成してもらって、自分でいくつか数字やステータスを変更しました。
生成したモデルは GPT-4o です。ちなみにプロンプトはこちらです。
AWS株式会社は以下のような組織構造を持っています。
- コンピューティング部
- EC2課
- Lambda課
- Lightsail課
- ストレージ部
- EFS課
- FSx課
- S3課
- データベース部
- RDS課
- DocumentDB課
- DynamoDB課
それぞれの課は時間帯によって以下のステータスを持ちます。
- 超ごきげん
- ごきげん
- 普通
- 不調
それぞれの課に所属する人はお菓子を食べたり持ってきたりします。お菓子の種類は以下の通りです。
- チョコレート
- ドーナツ
- おせんべい
日時, 部署名, 課名, ステータス, チョコレートの個数, ドーナツの個数, おせんべいの個数 が記載された CSV ファイルを作成してください。
カラム名は `datetime`, `department`, `section`, `status`, `chocolate`, `donut`, `osenbei` としてください。
日時の形式は `YYYY-MM-DD HH:MM:SS` で date 型としてください。
データセットの作成
QuickSight コンソールで新しいデータセットを作成します。ファイルのアップロードで先ほど作成したお菓子の CSV をアップロードすると、このようにデータがプレビュー表示されます。「次へ」をクリックします。
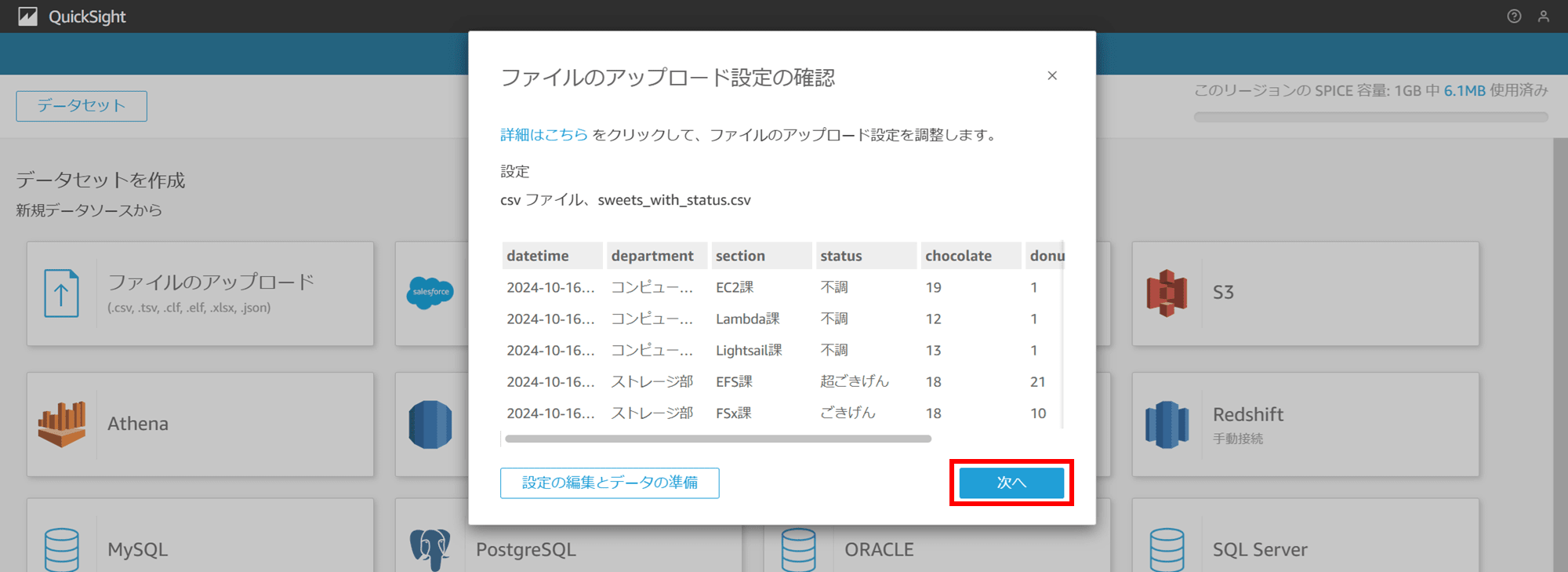
「ファイルのアップロード」では SPICE という高速インメモリ領域にデータが保存されます。「データの編集/プレビュー」をクリックします。
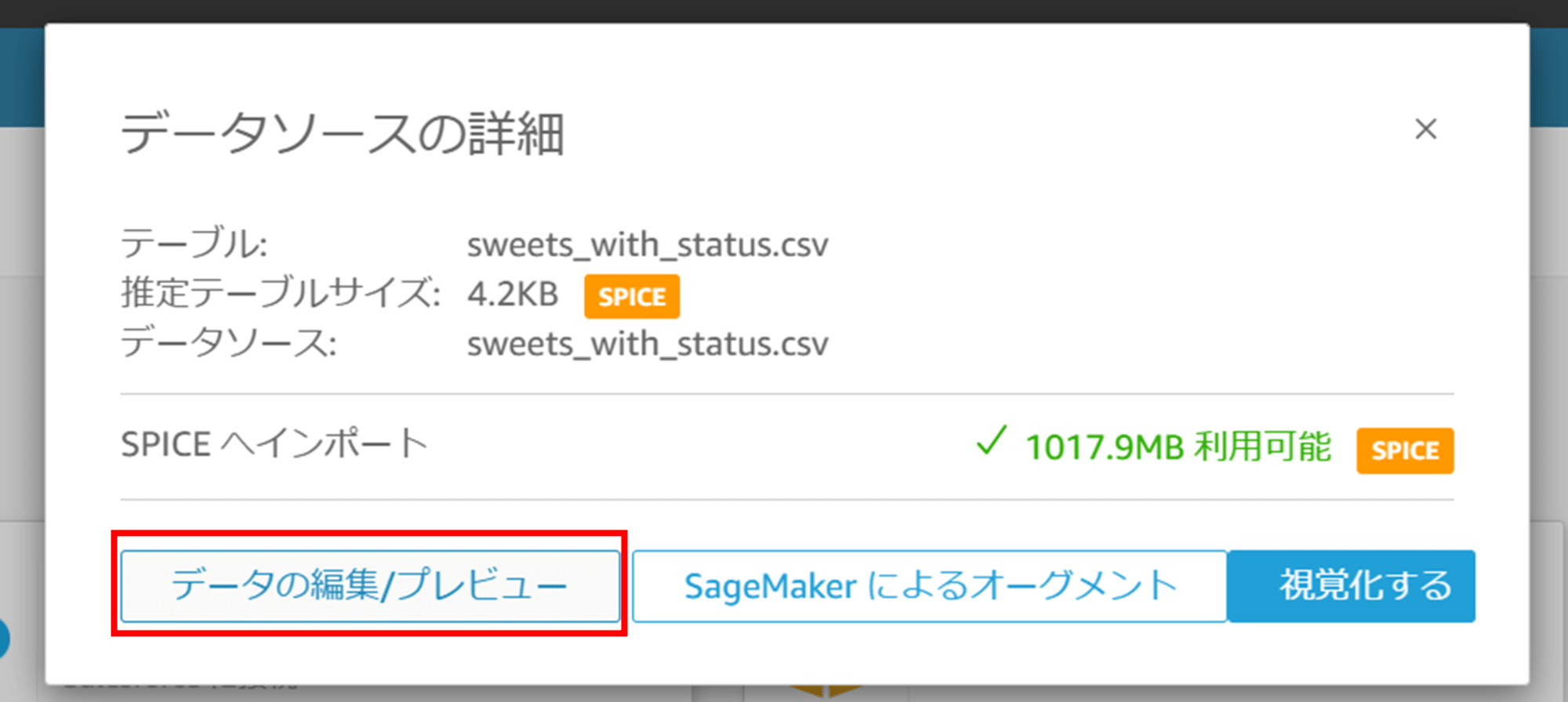
読み込んだ CSV ファイルのデータを確認できます。右上の「保存して公開」をクリックして、データセットを保存します。
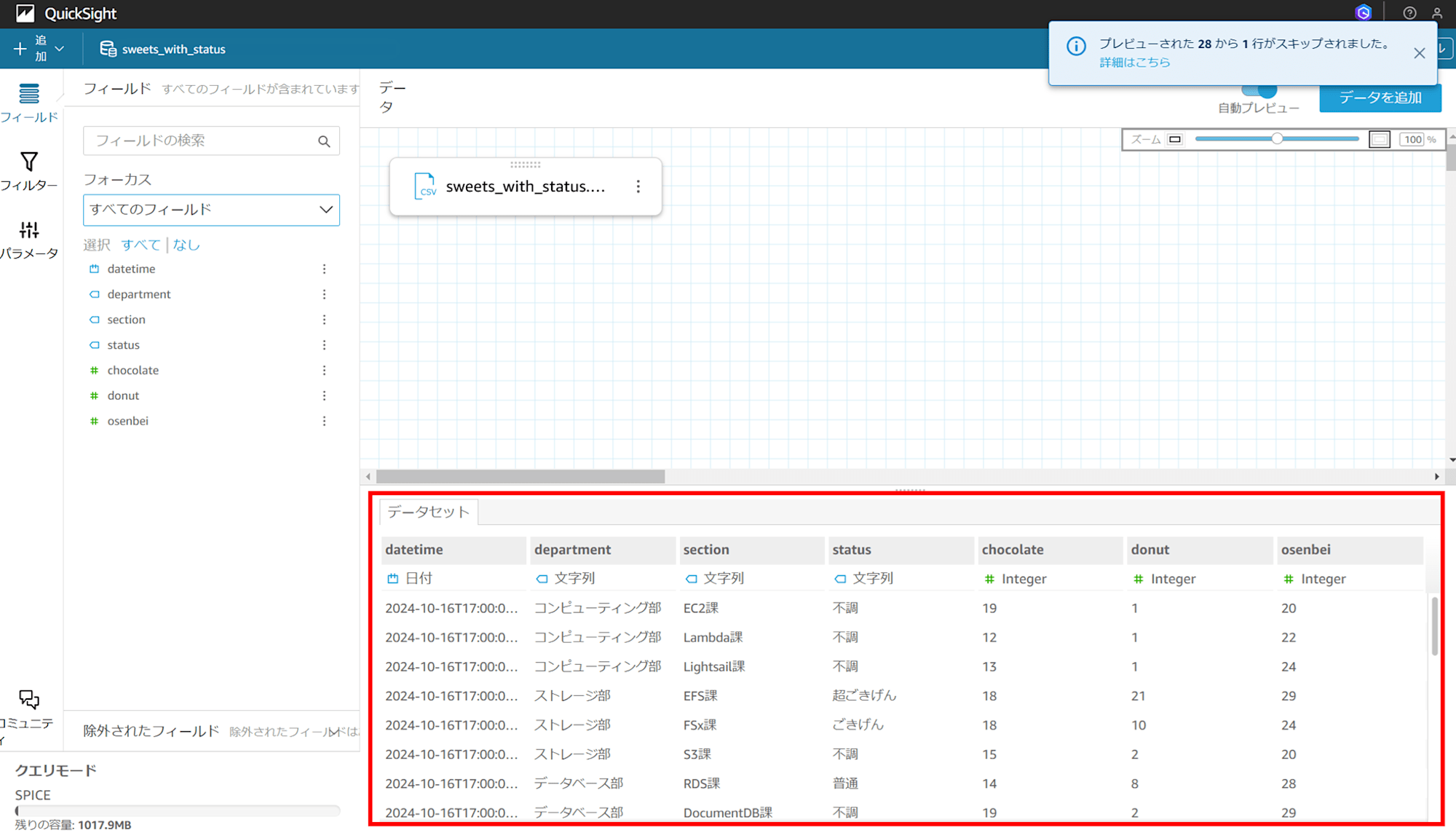
トピックの作成
では Q in QuickSight の真髄ともいうべきトピックの作成を行っていきます。
画面左メニューに「トピック」という項目があるので選択し、「NEW TOPIC」をクリックします。
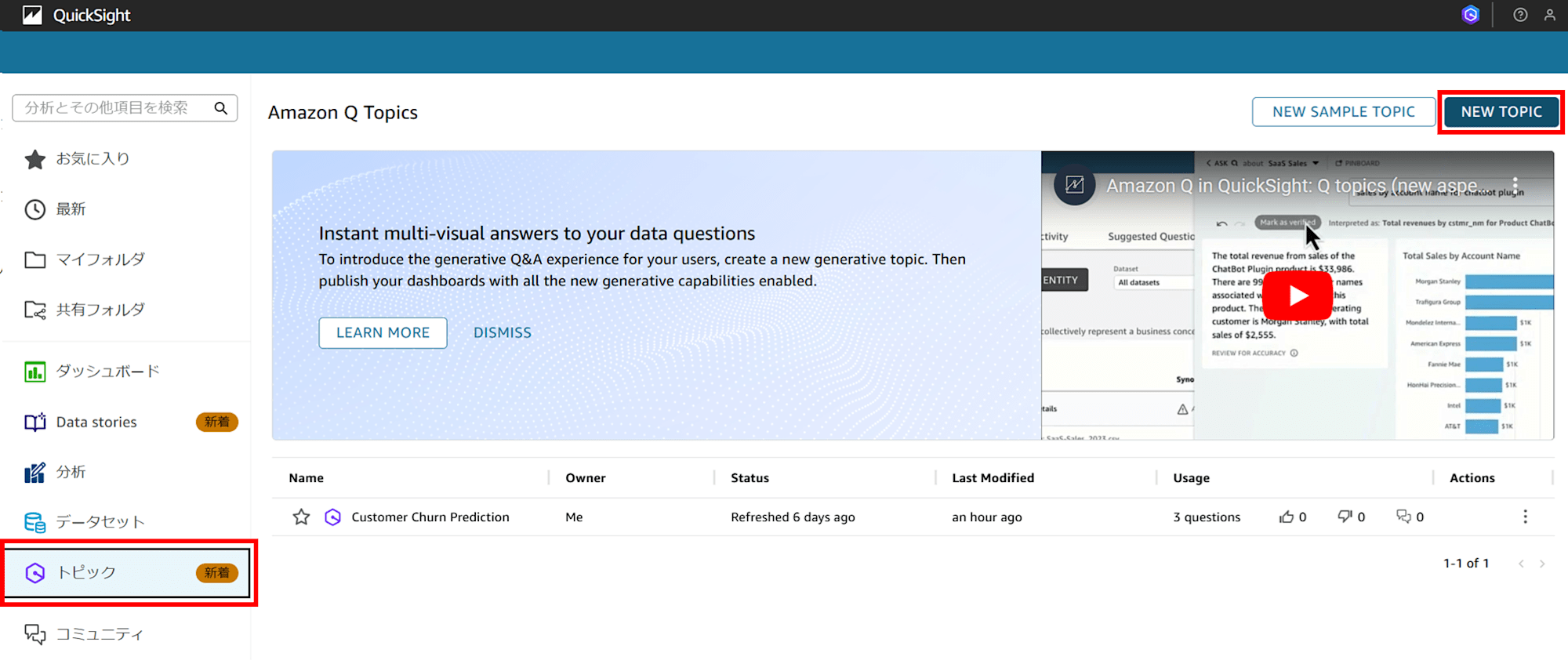
トピックの名前と説明を入力し、「Use new generative Q&A experience.」にチェックを入れ「CONTINUE」をクリックします。
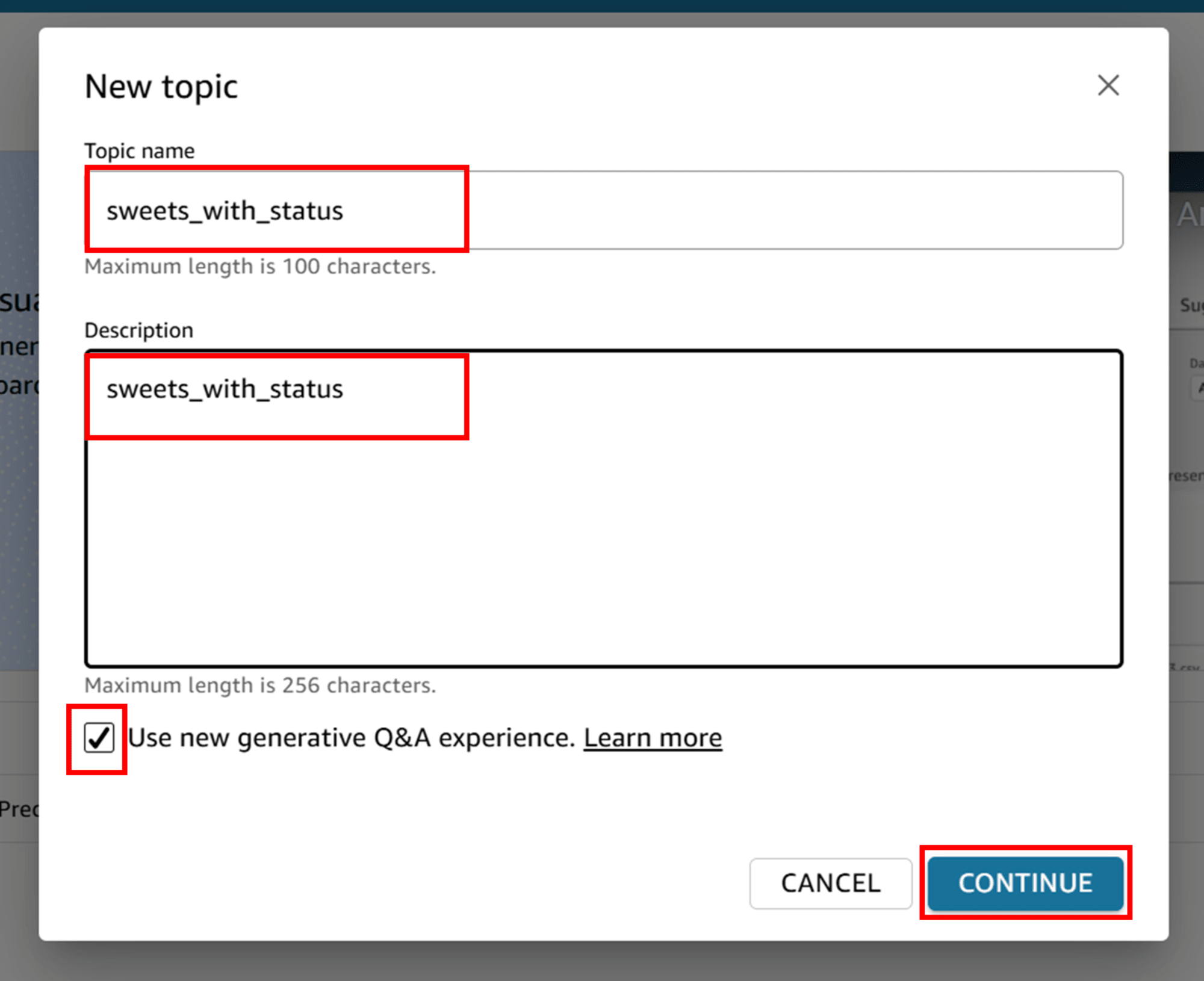
データセットの選択画面で、先ほど作成したお菓子のデータセット「sweets_with_status」を選択して「CREATE」します。
数秒待ちます。
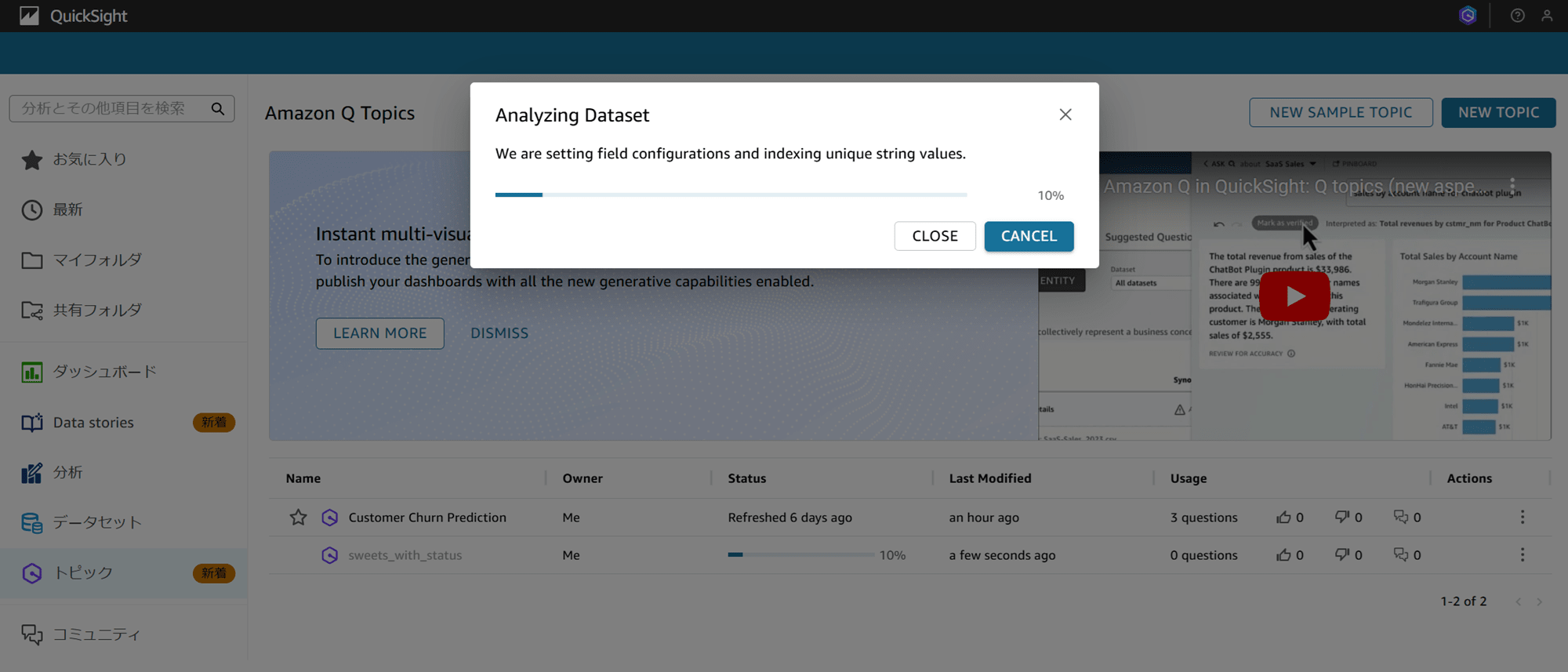
トピックができました。クリックして開くとこのような画面になっています。
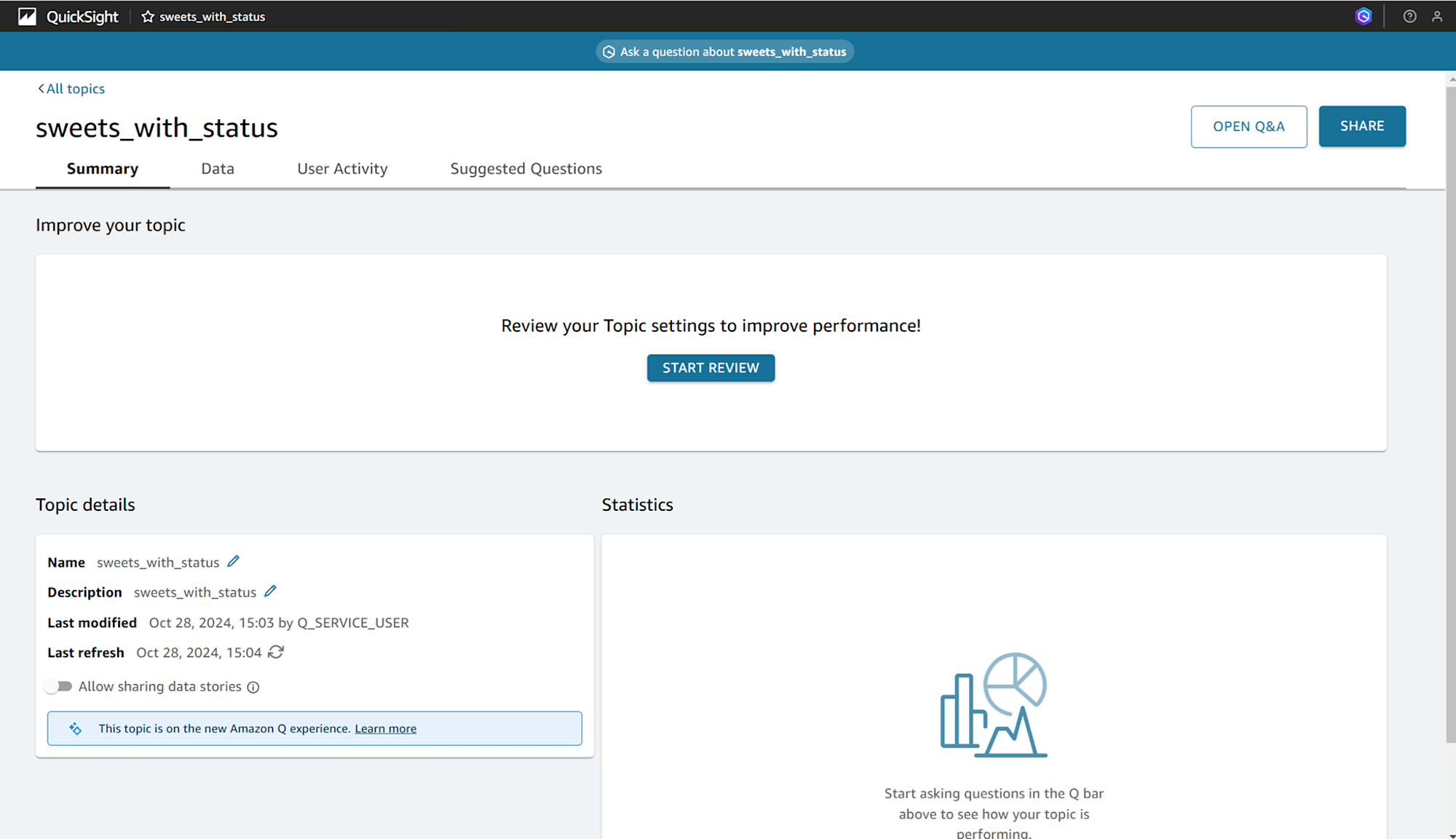
この画面はトピックワークスペースというらしいです。
DATA FIELDS でのシノニムなどの設定
「Summary」タブで「START REVIEW」をクリックすると、
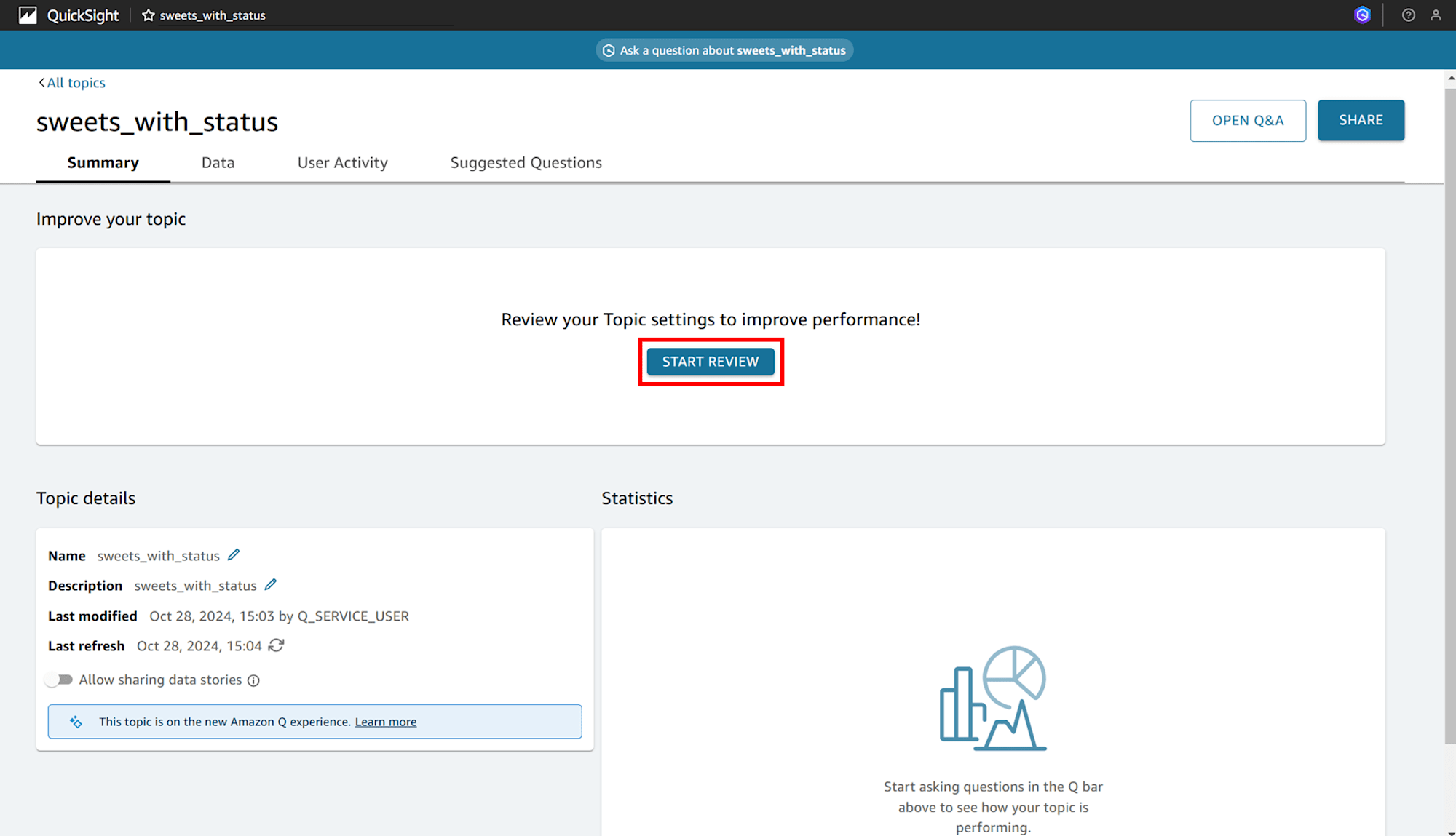
画面右にチュートリアルのポップアップのようなものが出て、「Data」タブが開かれます。
データフィールドにカラムが自動でバッと表示されています。データセットからトピック側に読み込んでくれるんですね。
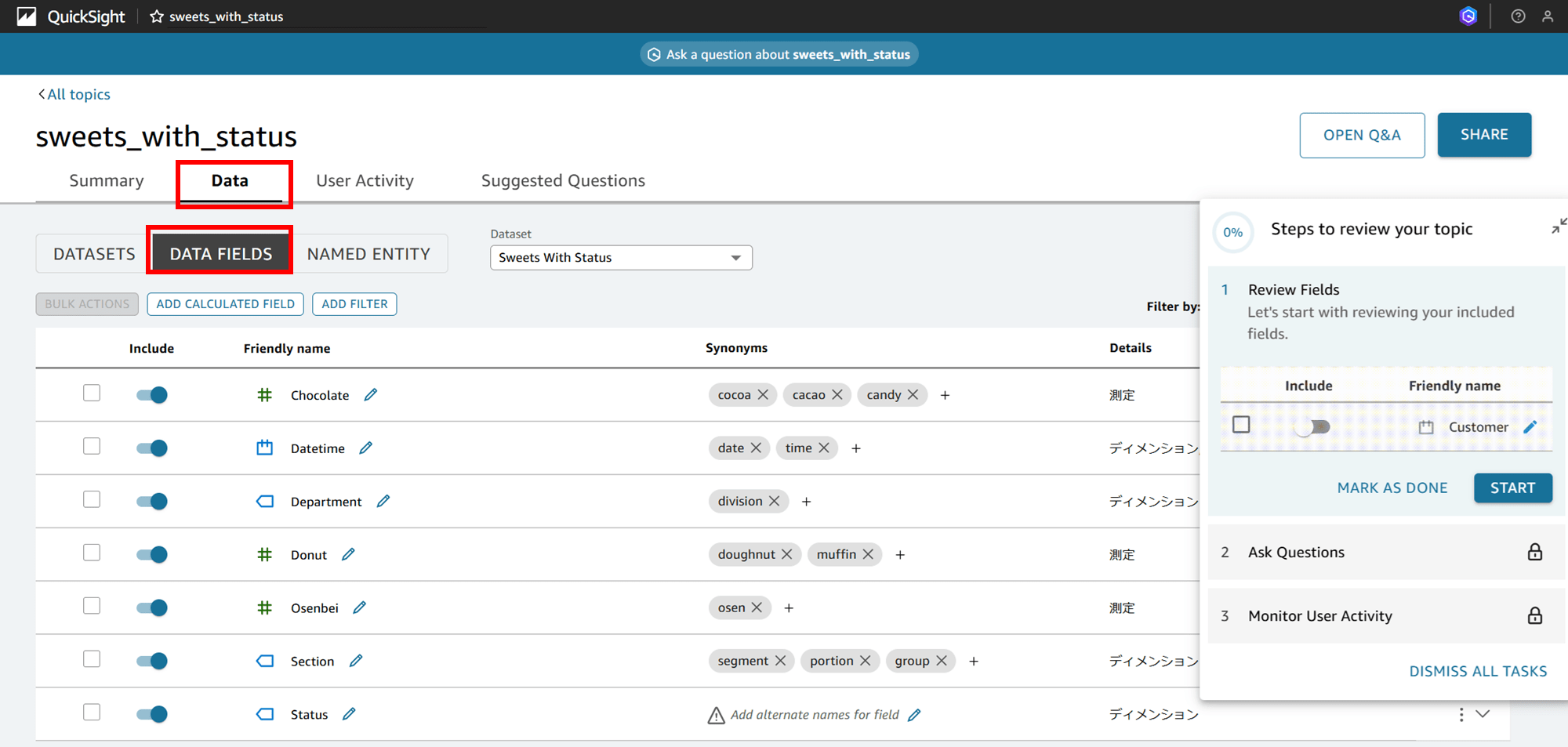
DATA FIELDS では「Include」、「Friendly name」、「Synonyms」、「Details」の設定ができます。
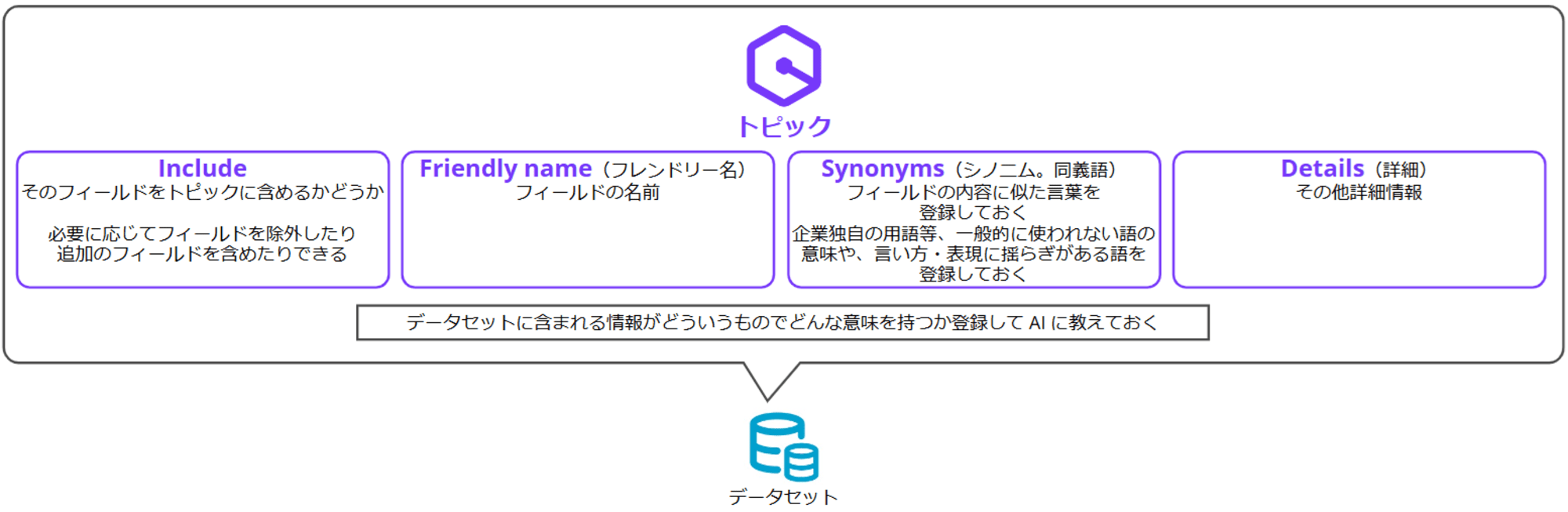
| Include | そのフィールドをトピックに含めるかどうか。必要に応じてフィールドを除外したり追加のフィールドを含めたりできる |
| Friendly name(フレンドリー名) | フィールドの名前 |
| Synonyms(シノニム。同義語) | フィールドの内容に似た言葉を登録しておく。企業独自の用語等、一般的に使われない語の意味や、言い方・表現に揺らぎがある語を登録しておく |
| Details(詳細) | その他詳細情報 |
シノニム(Synonyms)を見ると「Chocolate」に対して「cocoa」、「cacao」、「candy」などの類義語も自動で設定されています。candy はちょっと違うような気もしますが、ここまで自動で出てくれるとは驚きです。何もしなくてもある程度は設定されるみたいです。
よく見ると、「Osenbei」に対してのシノニムが「Osen」という謎の語になっていたり、Status のシノニムが入力されていなかったりするので、手で修正します。
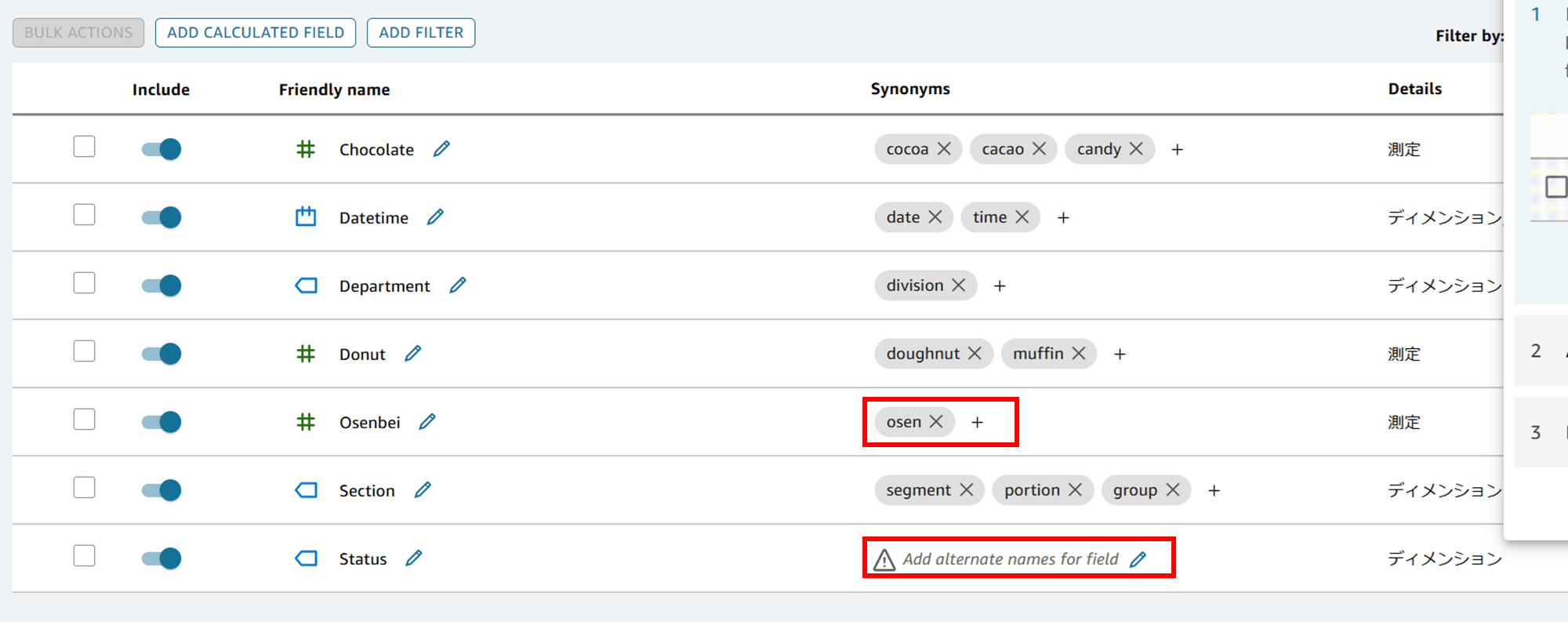
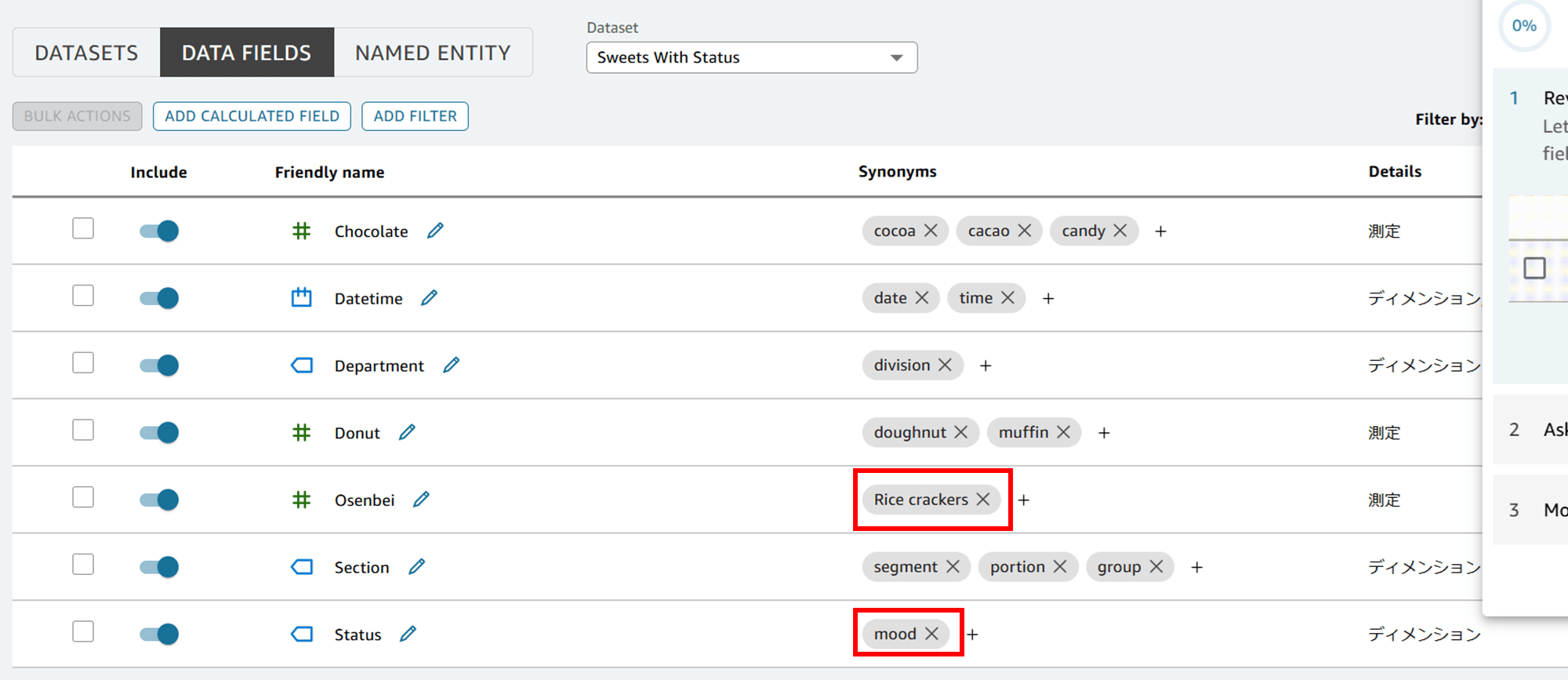
「Osenbei」には「Rice crackers」、「Status」には「mood」と追加してみました。
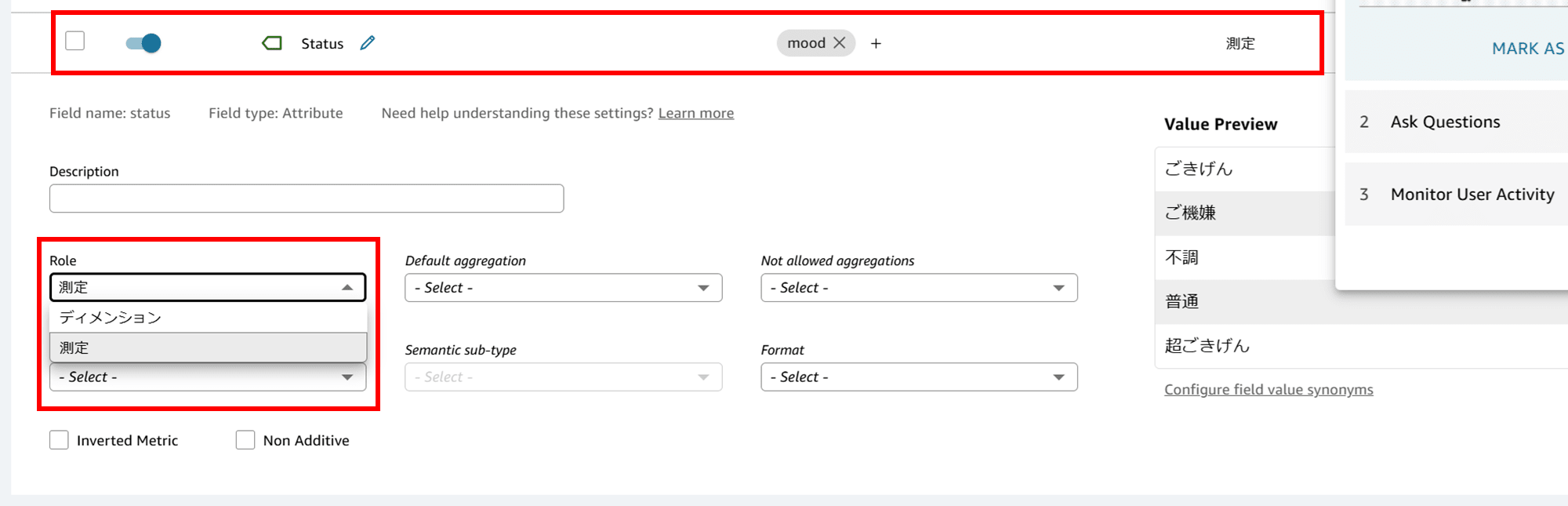
「Status」の詳細(Details)もディメンション⇒測定に修正します。
- ディメンション:データを分類・整理する属性やカテゴリ(例:部門やセクション)
- 測定:数値データで、集計・計算の対象となるもの(例:売上数量や金額)
「DATASETS」をクリックすると、データセットの情報が表示されます。「ADD DATASETS」というボタンがあるので、1 つのトピックにデータセットを追加することもできるっぽいです。
トピックの更新を定期実行、または手動実行できるようになっており、定期実行のスケジュールを設定できるようです。
データセットが更新されたときにトピックも更新できる(すべき)という感じでしょうか。
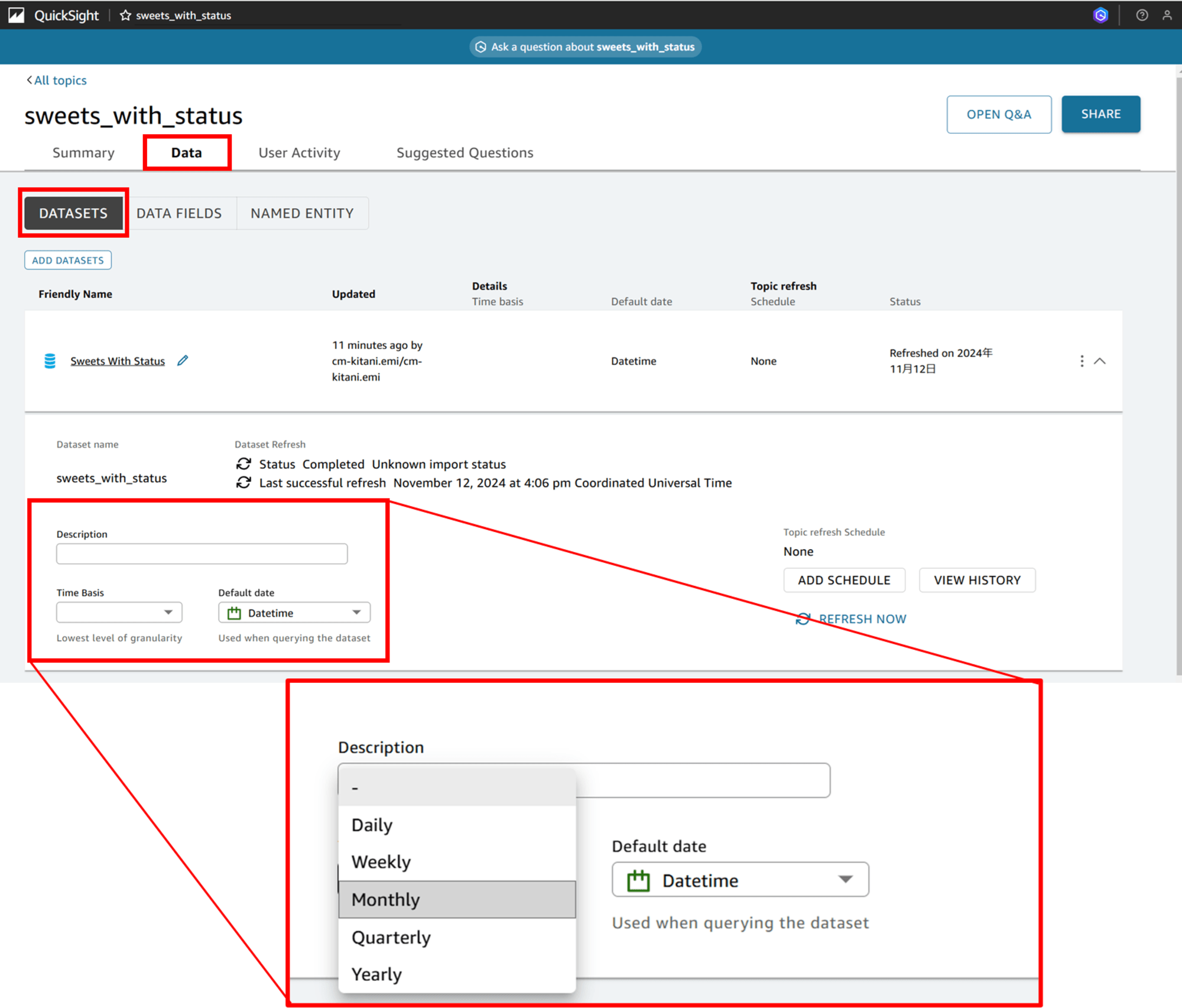
画面右に生えているチュートリアルの画面は終わるまで消せないっぽいです。Review Fields の項目で「MARK AS DONE」をクリックし進めました。
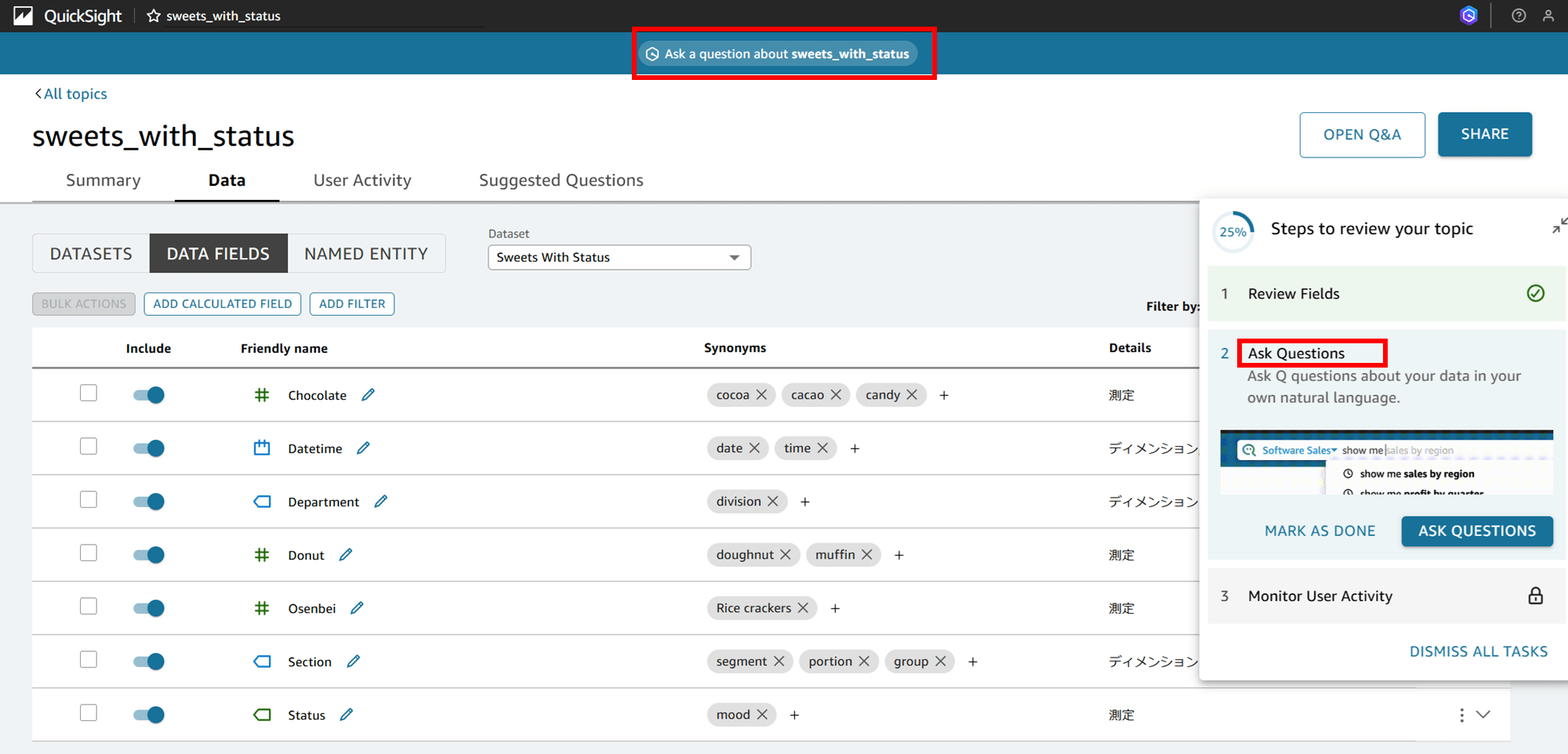
トピックからデータセットに対して自然言語で Q&A してみる
トピックに対して自然言語で Q&A をしてみます。分析やダッシュボードがなくても、データセットとトピックさえあれば生データに対して Q&A ができます。
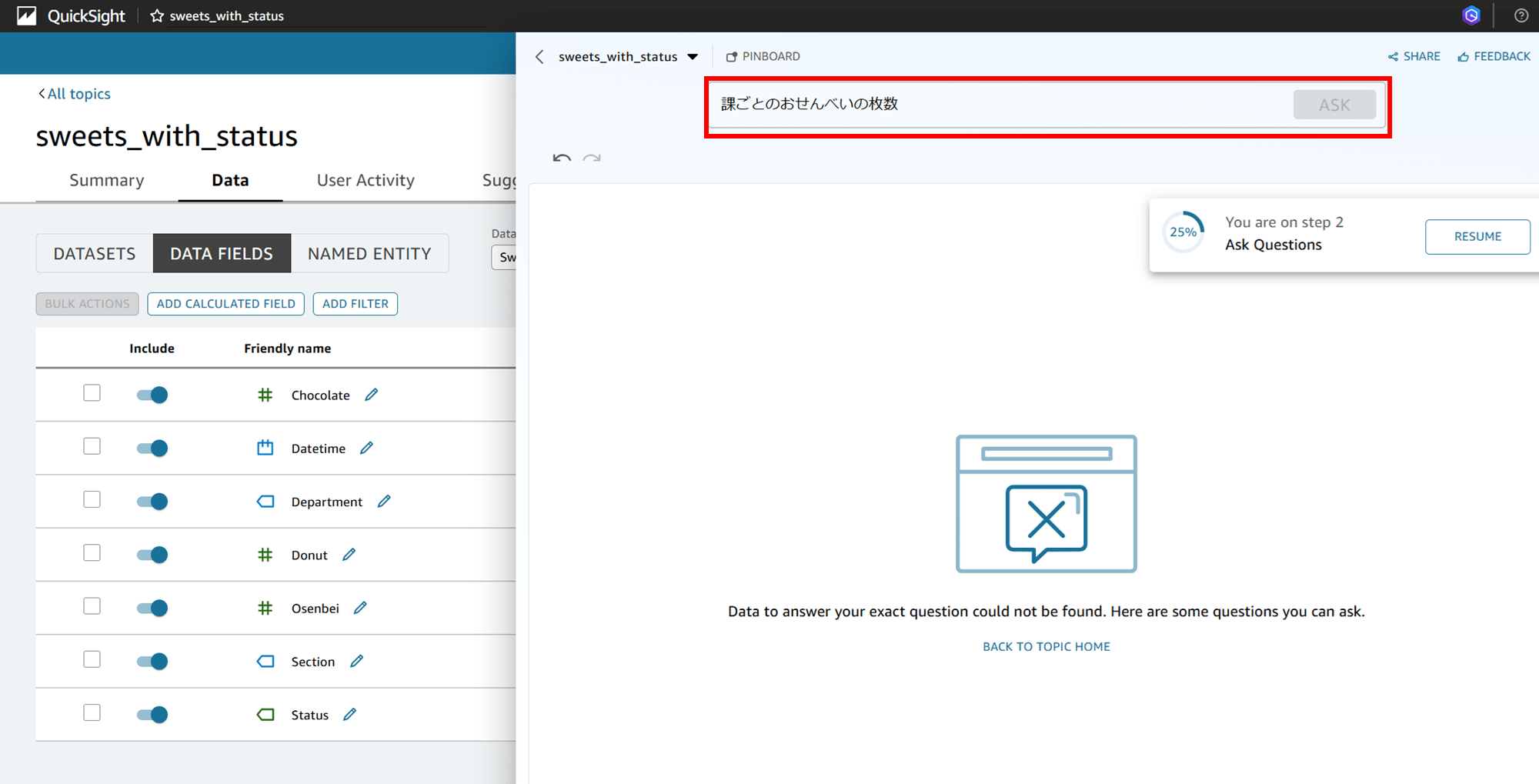
日本語で「課ごとのおせんべいの枚数」と入力してみましたが、回答できませんでした。
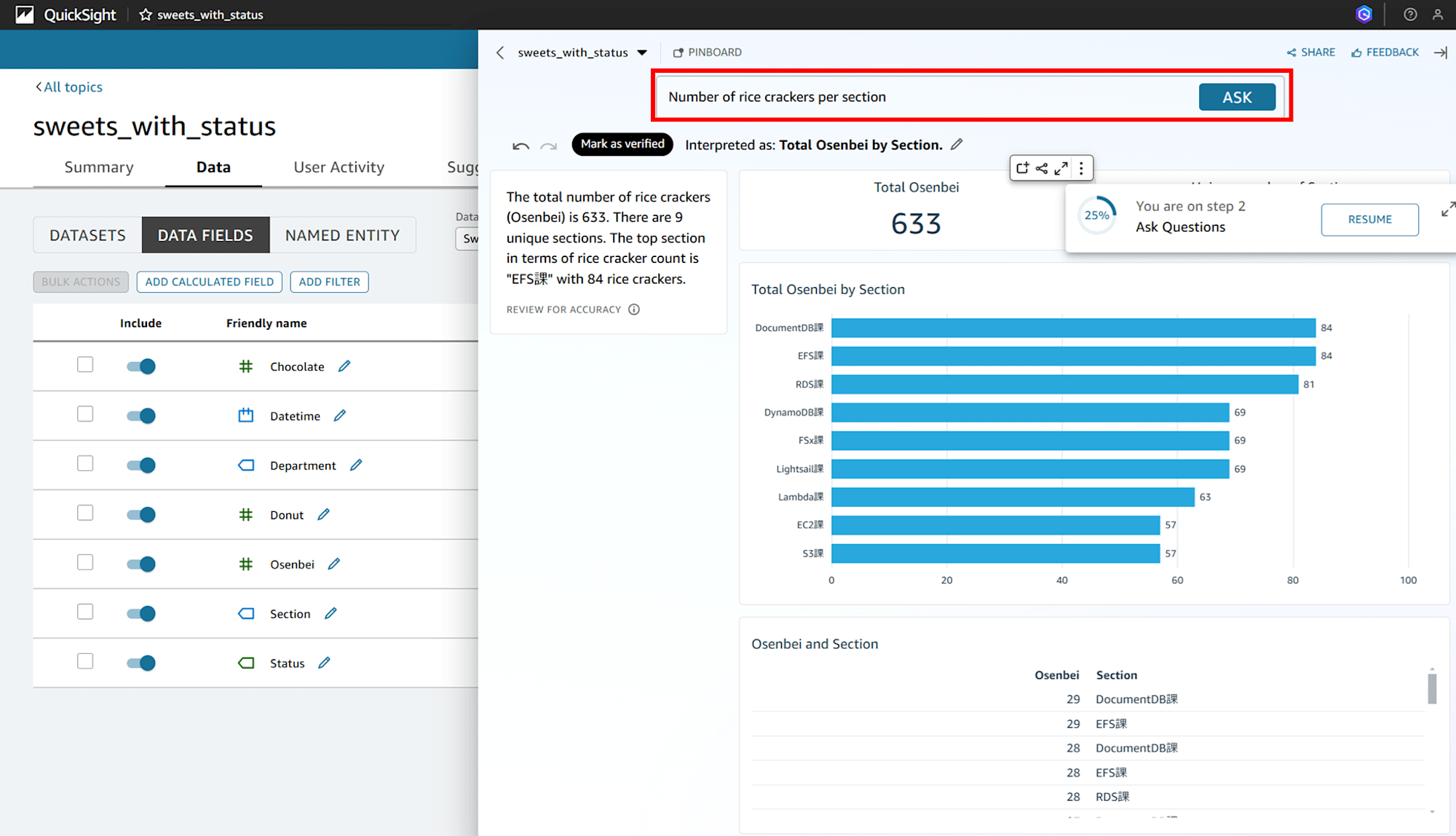
英語で「Number of rice crackers per section(課ごとのおせんべいの枚数)」と入力すると、棒グラフとともに回答が得られました。
The total number of rice crackers (Osenbei) is 633. There are 9 unique sections. The top section in terms of rice cracker count is "EFS課" with 84 rice crackers.
(機械翻訳)おせんべいの総数は633枚。 ユニークなセクションは9つある。 おせんべいの枚数でトップは「EFS課」で84枚。
「Amazon QuickSight Q でサポートされている質問のタイプ」というドキュメントがあり、「この形式で質問するといいですよ」という質問の形式が提供されています。
ユーザーアクティビティを確認する
チュートリアルには「ユーザーアクティビティ(User Activity)」記載されています。「User Activity」タブを見てみましょう。
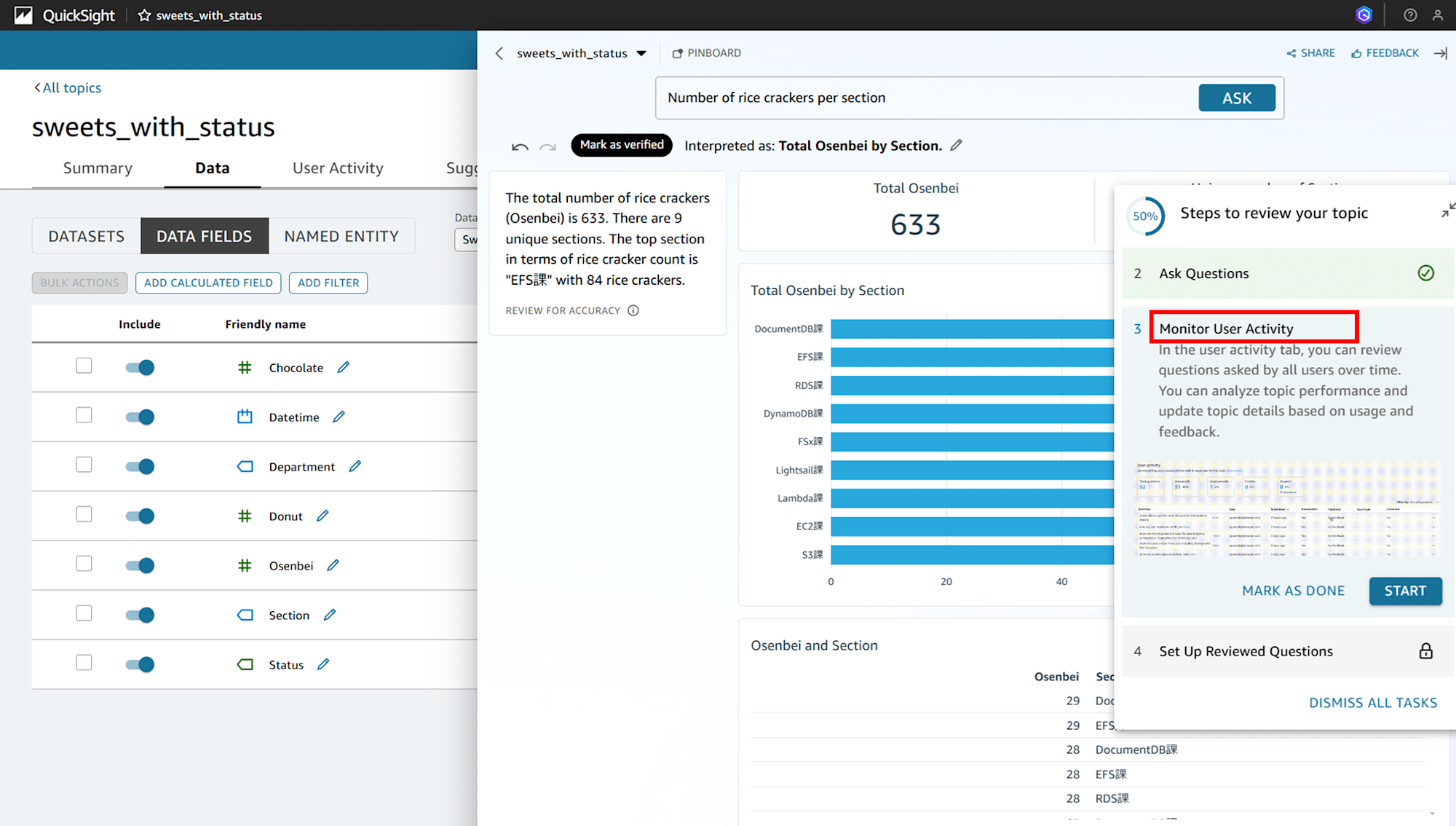
なるほど、質問の履歴が残ってます。「VIEW」をクリックすると、
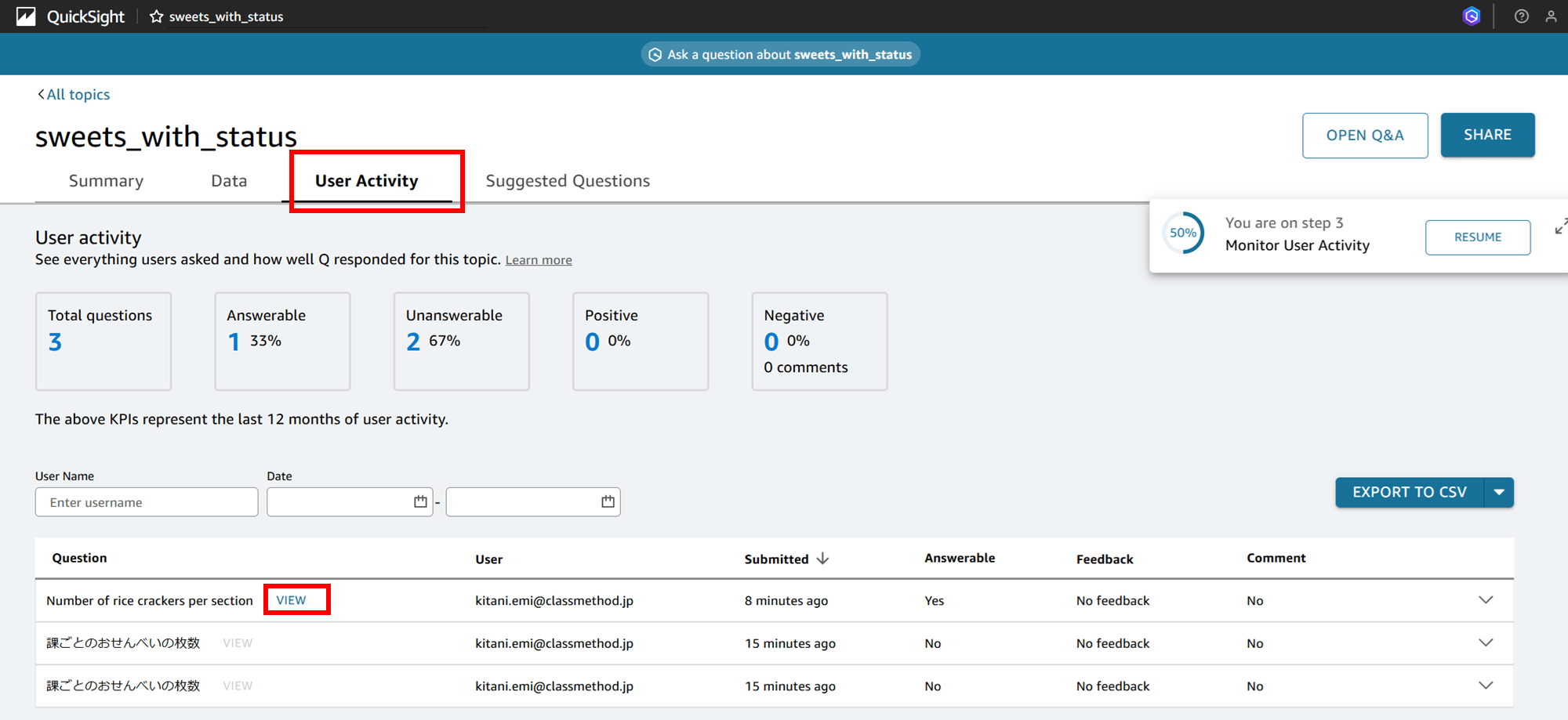
過去の質問の結果が再度見られます。
右上の「FEEDBACK」で positive もしくは negative の評価をして SUBMIT すると、
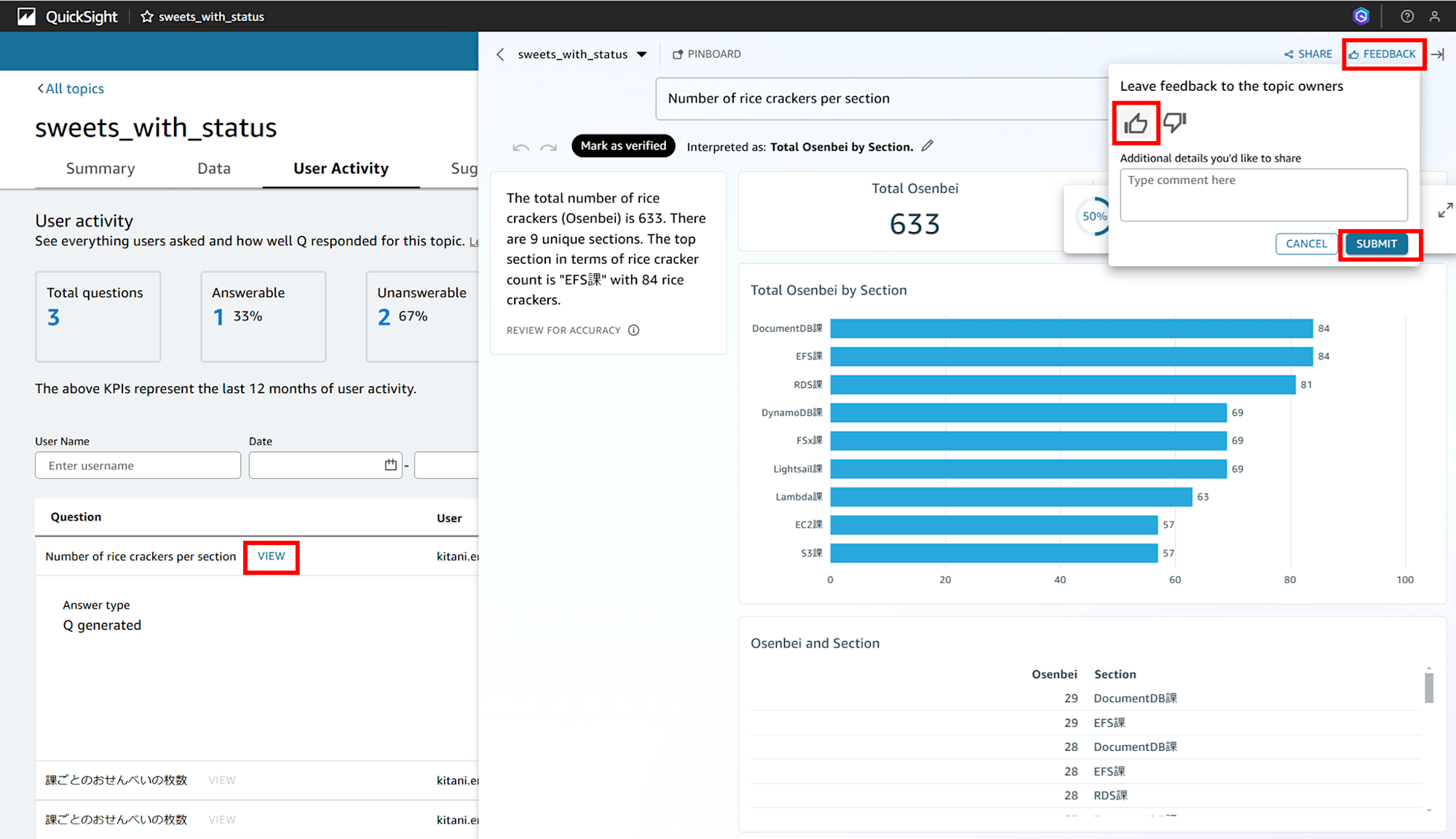
フィードバックが送信されて、
「Feedback」項目に positive もしくは negative が表示されます。
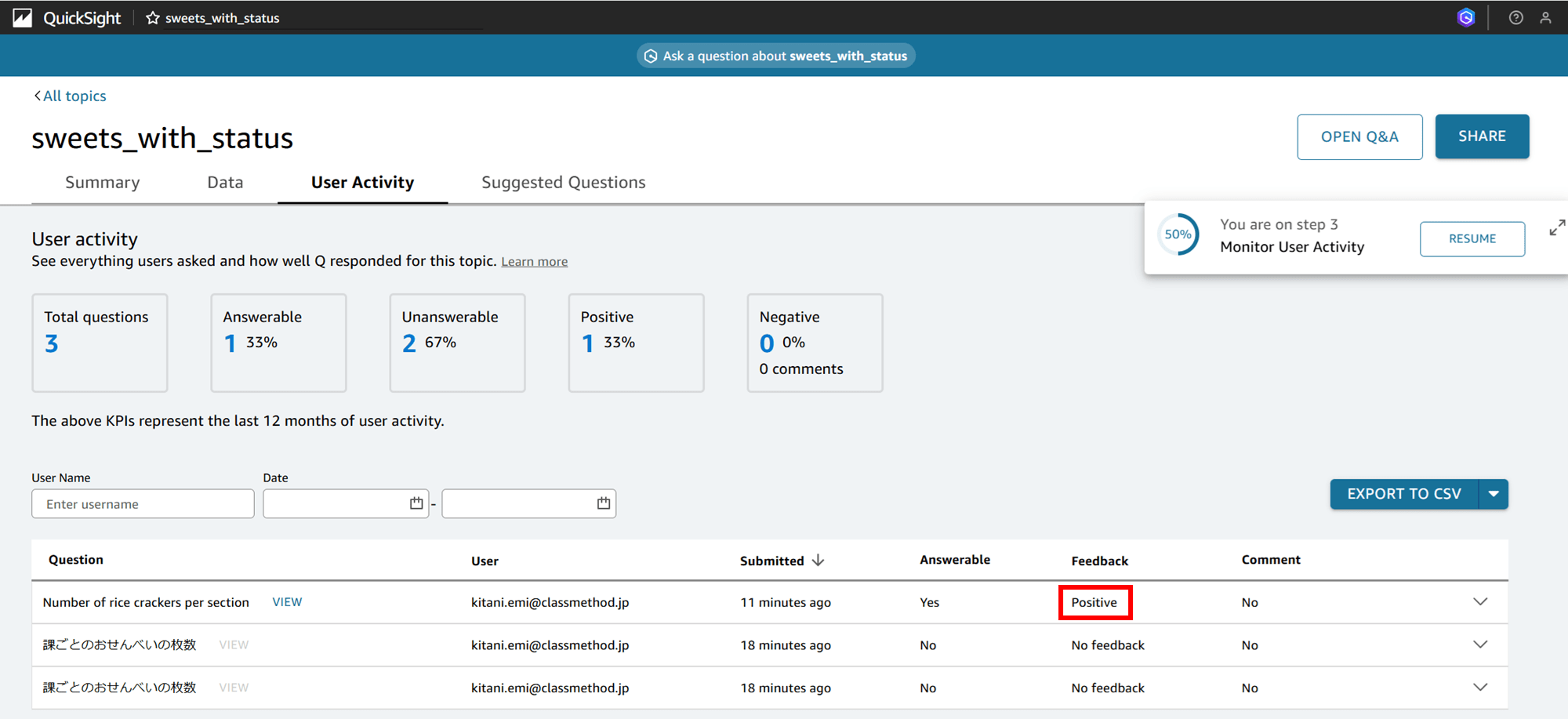
Suggested Questions を確認する
ユーザーアクティビティの履歴画面で「Mark as verified」をクリックすると「Verified」と緑色になり、
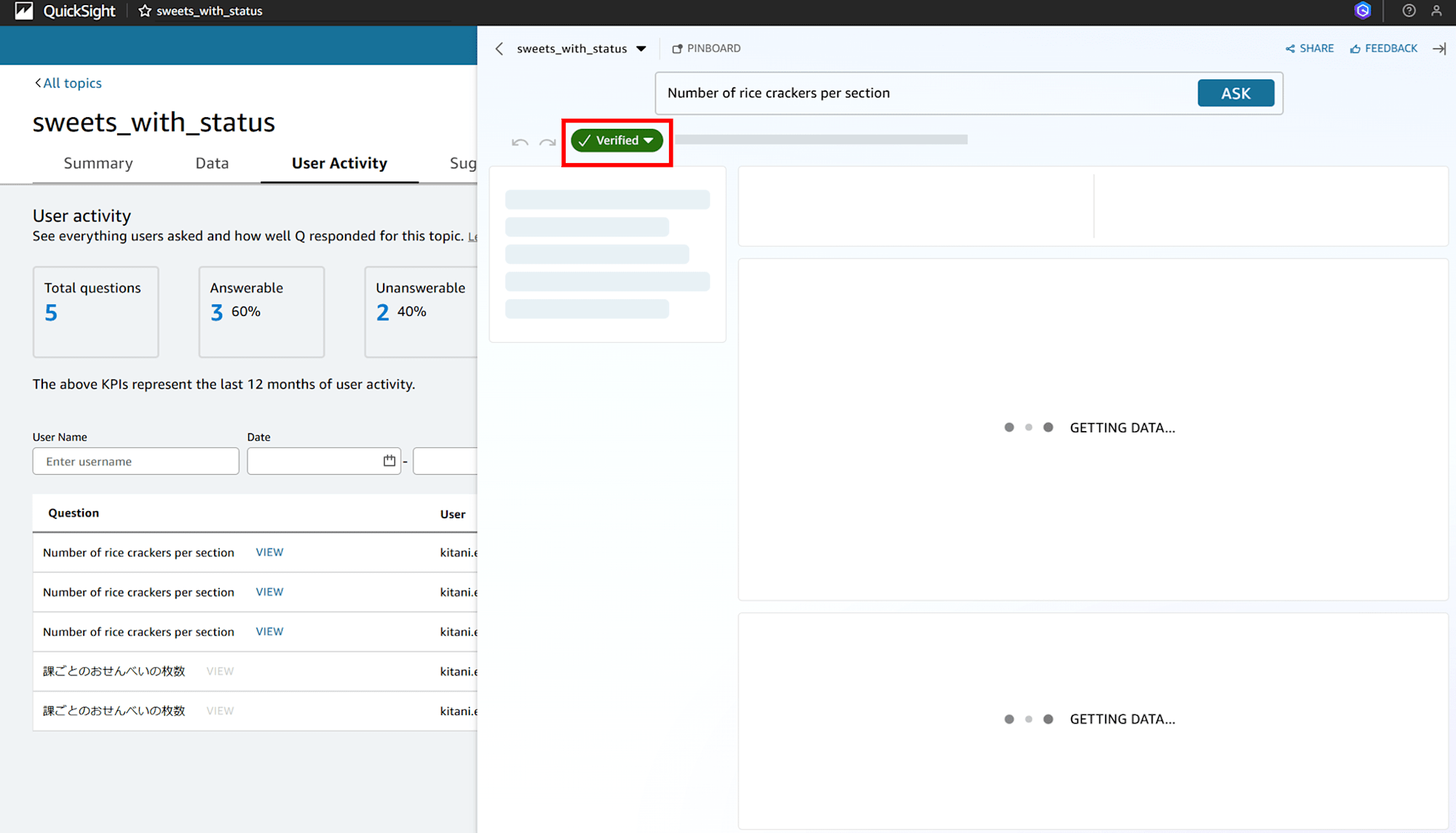
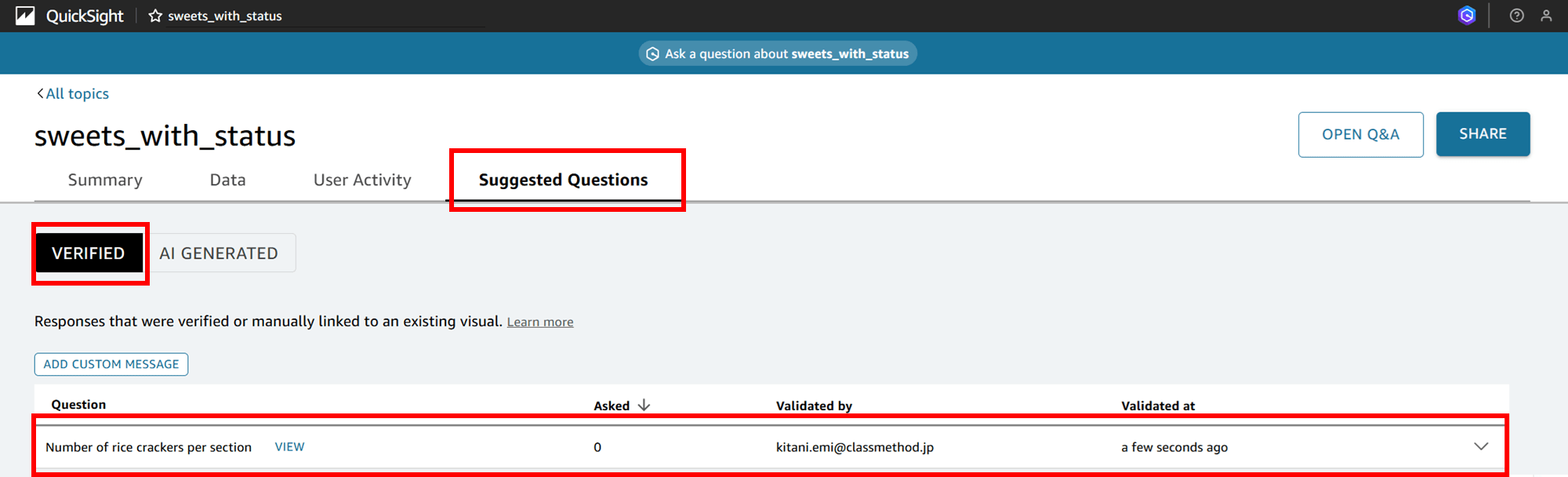
「Suggested Questions(提案された質問)」タブの「VERIFIED」から確認できるようになります。
Q in QuickSight を使うユーザー共通でよく使う質問、かつ回答精度が良いものはこうしてここから確認できるというわけですね。
「AI GENERATED」を見ると、Q が生成した質問文が掲載されています。
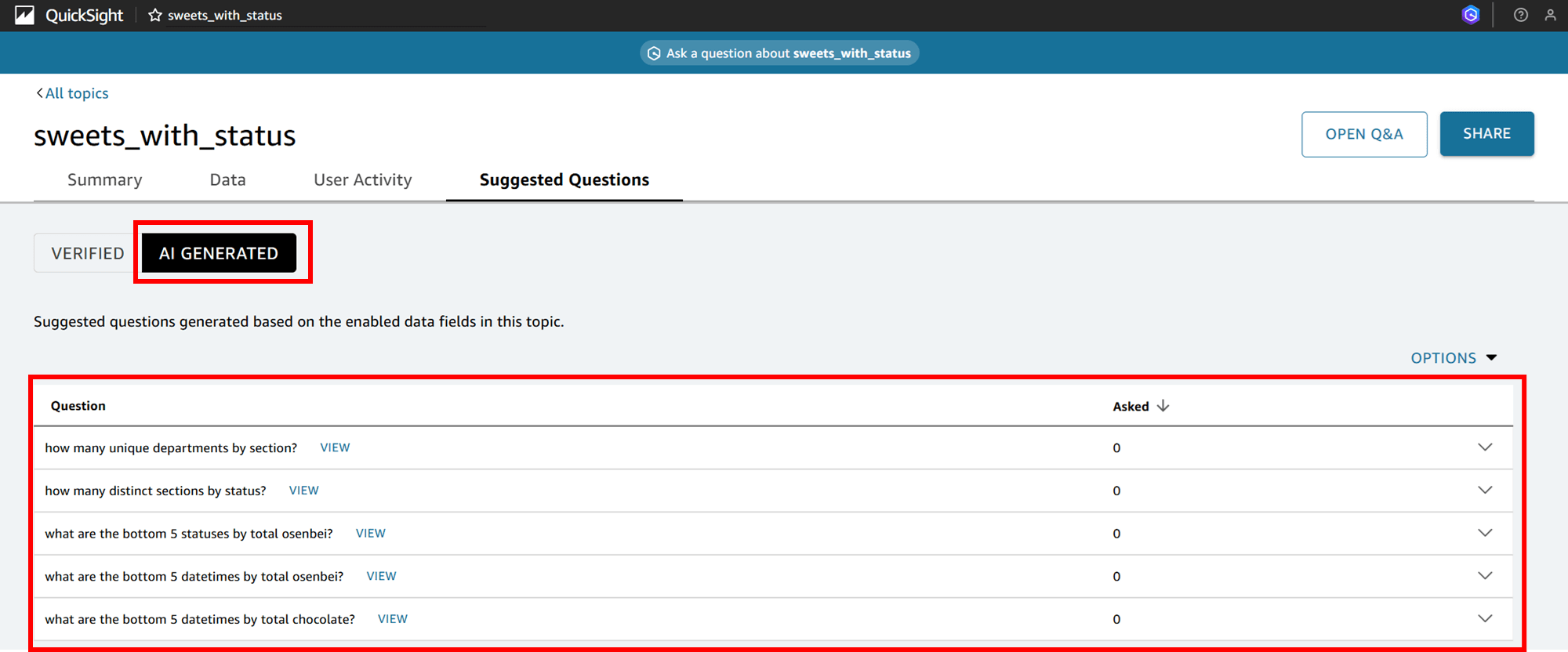
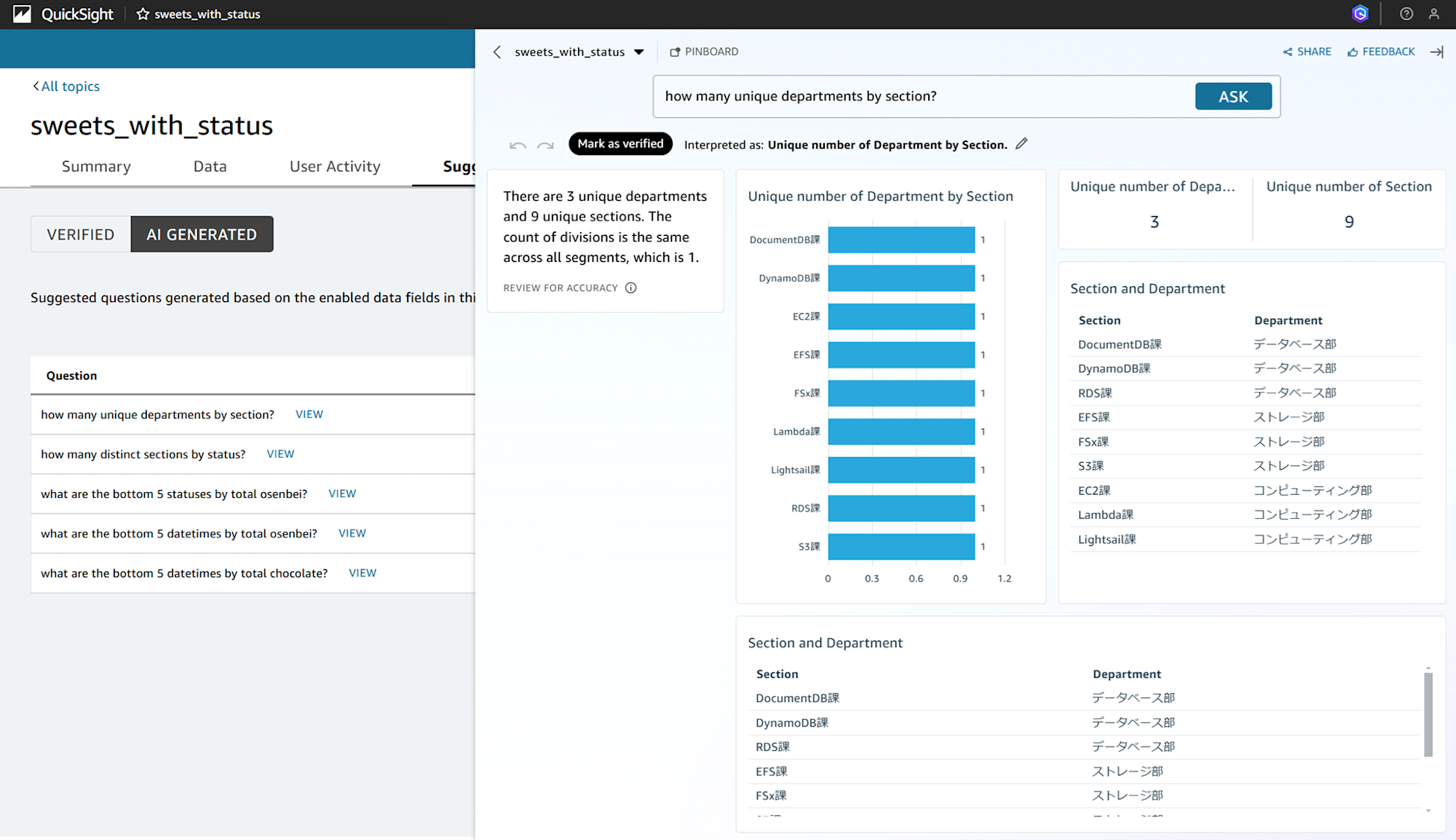
「AI GENERATED」で表示されている質問分の一番上の「how many unique departments by section?(セクション別のユニークな部門数は?)」で「VIEW」をクリックしますとこのようなグラフと回答が表示されます。
There are 3 unique departments and 9 unique sections.The count of divisions is the same across all segments, which in 1.
(機械翻訳)3つのユニークな部門と9つのユニークなセクションがある。部門の数はすべてのセグメントで同じで、1である。
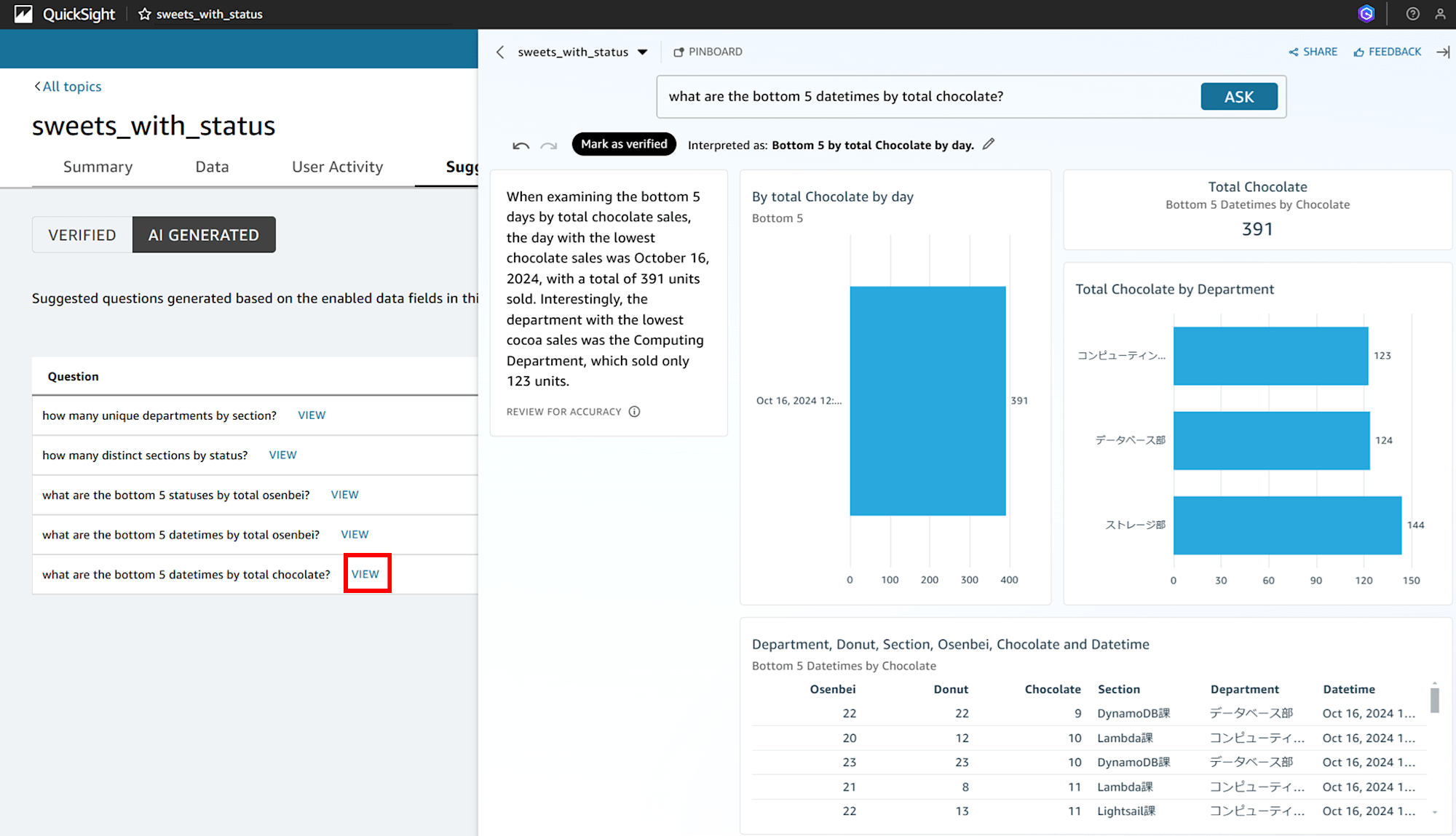
「AI GENERATED」で表示されている質問分の一番下の「what are the bottom 5 datetimes by total chocolate?(チョコレートの総数で下位5位までの日付は?)」で「VIEW」をクリックしますとこのようなグラフと回答が表示されます。
When examining the bottom 5 days by total chocolate sales, the day with the lowest chocolate sales was October 16, 2024, with a total of 391 units sold.
Interestingly, the department with the lowest cocoa sales was the Computing Department, whitch sold only 123 units.
(機械翻訳)チョコレートの総売上高で下位5日間を調べると、最もチョコレートが売れなかった日は2024年10月16日で、総売上高は391個であった。興味深いことに、チョコレートの売り上げが最も少なかった部門は、123個しか売れなかったコンピュータ部門であった。
売上のデータではないので、データの意味や意義なども Data タブのシノニムとか NAMED ENTITY とかで登録しておくとよいのかもしれません。
おわりに
データセットとトピックを作成して Q in QuickSight の Q&A を試しました。分析やダッシュボードがなくても生データに Q&A できることがわかりました。
ざっくり以下のようなイメージです。
| タブ | 内容 |
|---|---|
| Sammary | 概要 |
| Data | データセットの確認と追加、トピックの更新、シノニムの設定、NAMED ENTITY の設定 |
| User Activity | 過去の Q&A 履歴の確認 |
| Suggested Questions | よく使う Q&A 質問文の登録、生成 AI が生成して提案してくれる質問文の一覧 |







