
【小ネタ】 ちょっとしたローカルでのSQL実行にDuckDBを使ったら便利だった
はじめに
こんにちは、コンサルティング部の神野です。
今回はQuickSightで実装した計算フィールドが本当に想定通りに動いているのか確認したくて、DuckDBを使って手元で検証してみたところ、便利だったのでその経験を共有したいと思います!「QuickSightの集計ロジックをSQLで再現できないかな?」という疑問から始まった小さな記事です。
環境・前提条件
今回は以下の環境で検証しています。
- Amazon QuickSight Standard Edition
- DuckDB v1.2.1
ストーリーイメージ
今回実現したいのは、以下のような成績分析です。
- 学期を跨いで科目ごとの平均点を計算する(単純な学生個人の点数ではなく、科目単位で集計した値)
- 合格基準点(60点)未満の「不合格科目」を抽出する
- 不合格科目の数を集計する
学期を跨いでこの科目は、全学生の成績が平均をクリアしているのか、難易度が適切かどうか傾向を掴む分析がしたいイメージです。
サンプルデータ
今回は以下のような学生成績データを例に考えていきます。
科目名,学期,学生数,合格者数,平均点,受講時間数
数学I,2025-前期,35,28,72.4,45
数学I,2025-後期,38,32,75.8,45
英語コミュニケーション,2025-前期,42,36,76.3,30
英語コミュニケーション,2025-後期,45,38,77.1,30
物理学基礎,2025-前期,25,15,58.6,60
物理学基礎,2025-後期,28,17,59.2,60
プログラミング入門,2025-前期,50,42,78.5,45
プログラミング入門,2025-後期,52,45,79.8,45
統計学,2025-前期,30,18,61.2,30
統計学,2025-後期,32,20,62.5,30
データベース概論,2025-前期,38,25,64.7,45
データベース概論,2025-後期,40,28,65.9,45
化学,2025-前期,22,12,55.3,60
化学,2025-後期,25,14,56.8,60
CSV名はstudent_grades.csvとして保存し、DuckDB、QuickSightで読み込めるようにしておきます。
QuickSightでの実装
まずQuickSightで分析を行うために、以下の計算フィールドを作成しました。
計算フィールドの作成
-
平均点_科目レベル
avgOver({平均点}, [{科目名}], PRE_AGG)元データが既に平均点を含んでいるため、
ageOver関数で科目名単位での平均点を算出します。 -
不合格科目名
ifelse({平均点_科目レベル} < 60, {科目名}, NULL)- 合格の場合は NULL、不合格(平均点60点未満)の場合は科目名を返します
- NULLは
distinct_countで無視されるため、不合格科目だけをあぶり出します。
-
不合格科目数(最終指標)
distinct_count({不合格科目名})- 重複する科目名は1件にまとめてカウントすることで、不合格科目数を算出します!
ビジュアルの作成
上記の計算フィールドを使って、以下のビジュアルを作成しました。
選択した学期でのKPI数
不合格科目数を選択した学期内で算出するKPIを作成してみました。
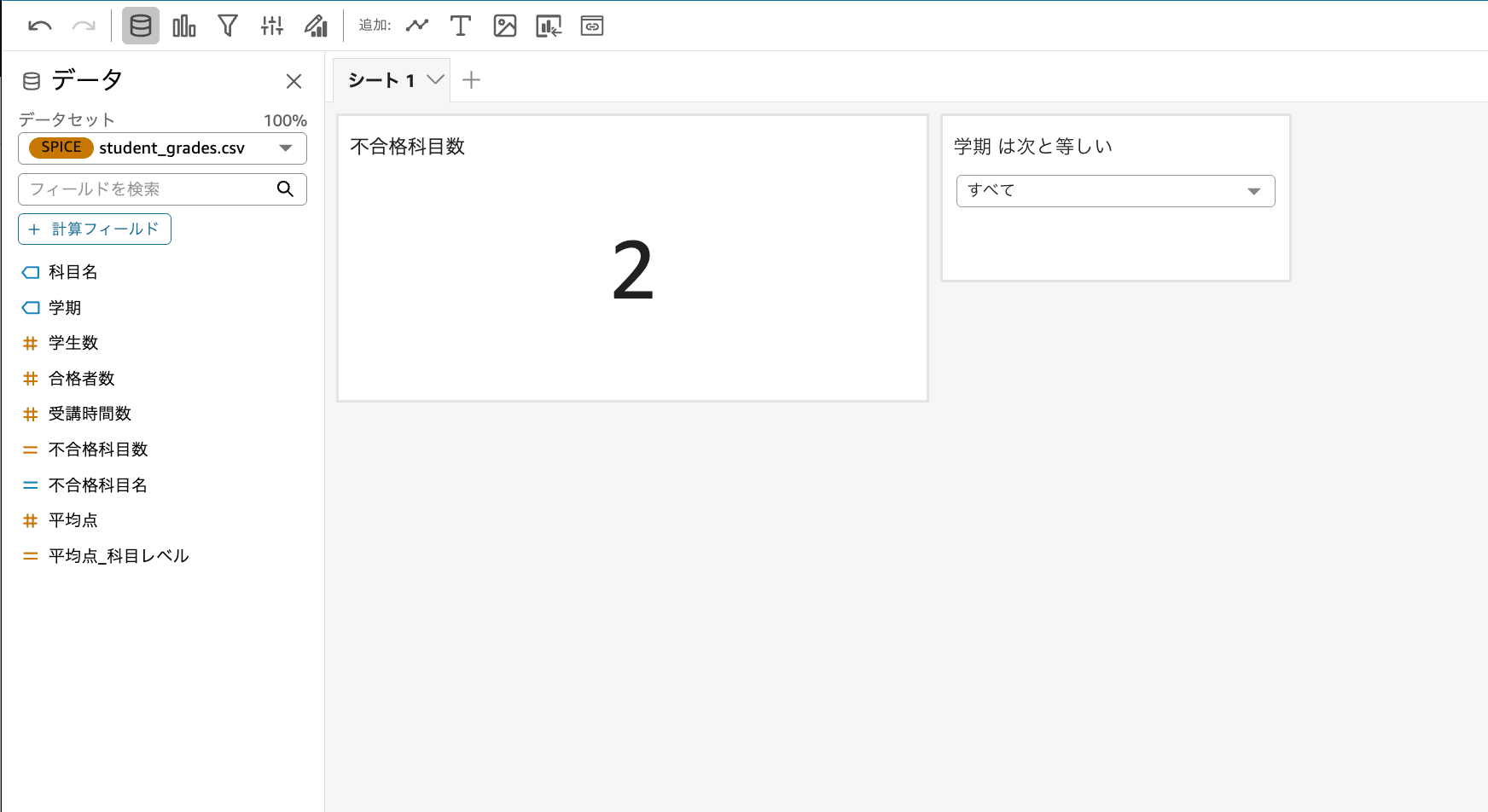
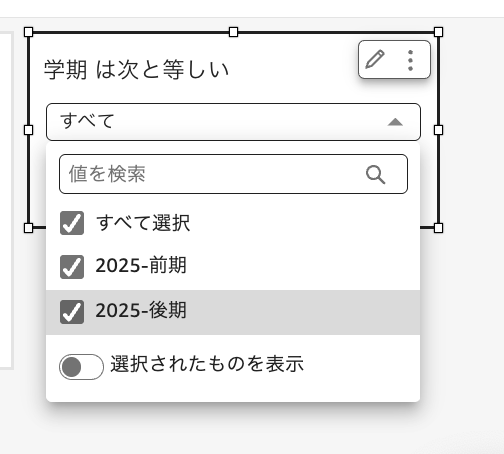
ダッシュボードは完成したものの、「この計算フィールドの実装で本当に合っているのかな?」という疑問が湧いてきました。実際にSQLを書いて計算フィールドのイメージがあっているのか、件数が一致しているのか確認したくなりました・・・(個人的にSQLが好きという理由もあります)
そこで、QuickSightの計算ロジックをSQL形式で再現して確認することで、直感的に算出ロジックが妥当か確認できるのではと思ったためです!
Pythonでコードを書いて検証もできると思いますが、直感的にSQLをローカルで実行できるDuckDBの方が魅力的だなと思い、今回試してみました!!
DuckDBでのSQL実行
DuckDBでの準備
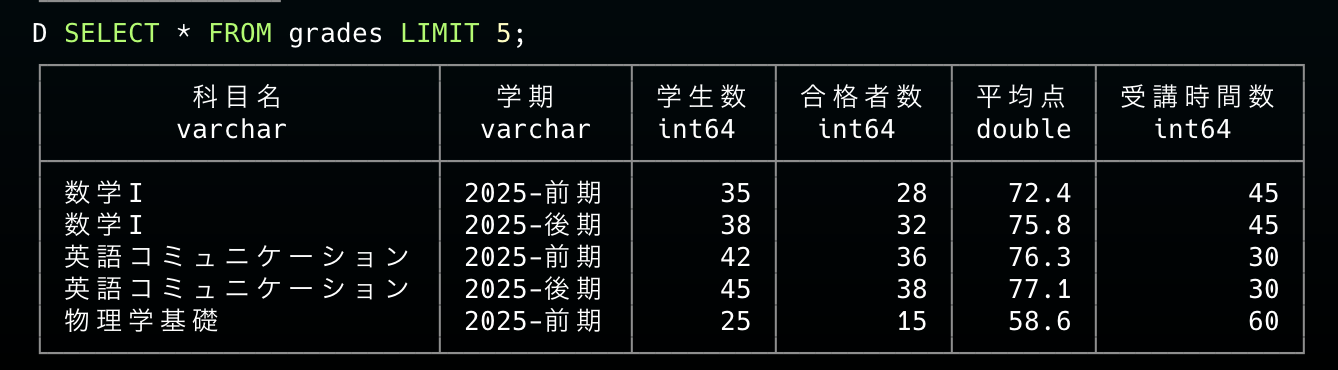
まずはCSVを読み込んでデータを確認してみます。
-- CSVファイルを読み込んでテーブルを作成
CREATE TABLE grades AS
SELECT * FROM read_csv_auto('your-path/student_grades.csv');
-- データを確認
SELECT * FROM grades LIMIT 5;
QuickSightの計算フィールドをSQLで再現
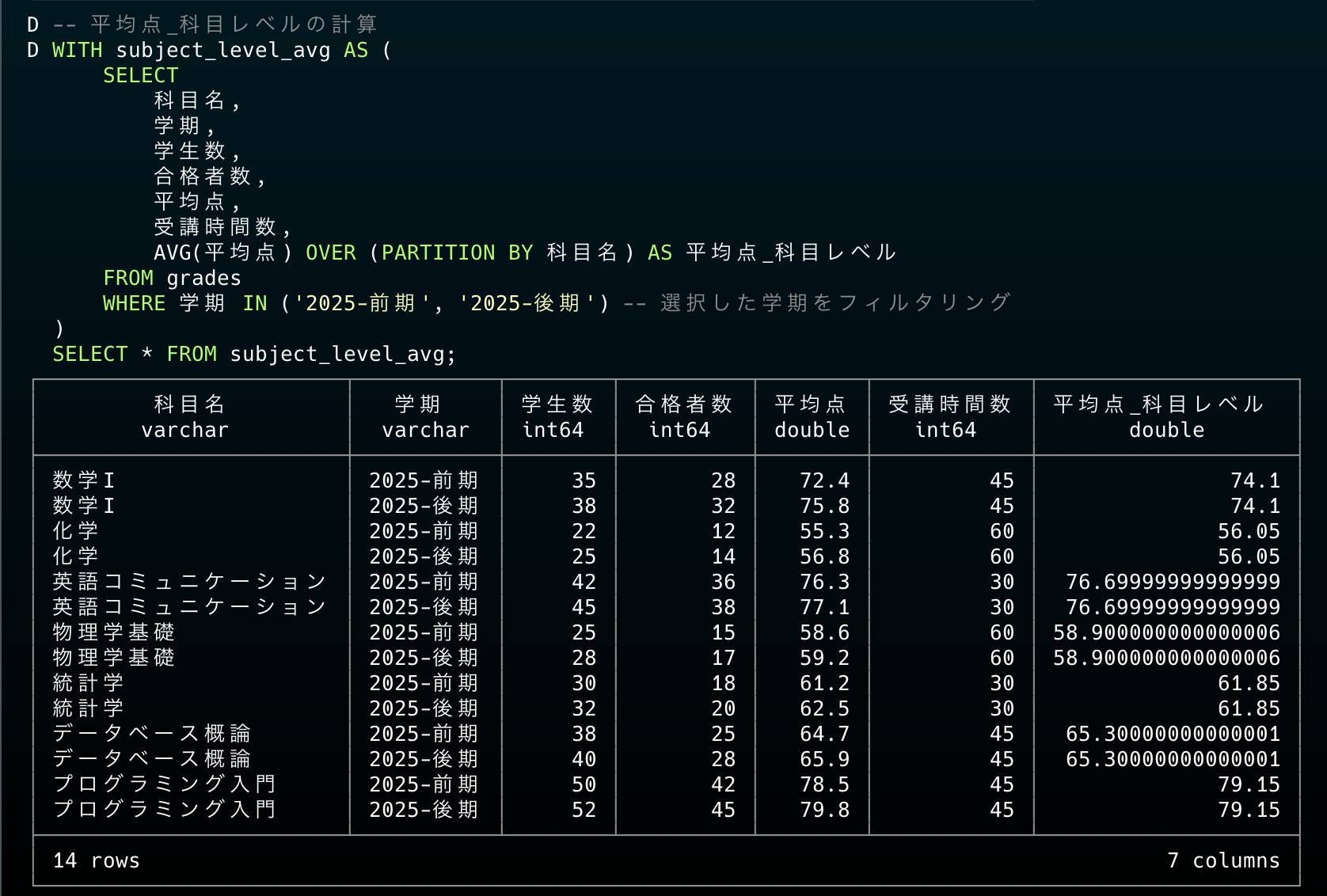
1. 平均点_科目レベルの再現
QuickSightの avgOver({平均点}, [{科目名}], PRE_AGG) を再現します。この関数は科目名ごとに平均点を計算します。
-- 平均点_科目レベルの計算
WITH subject_level_avg AS (
SELECT
科目名,
学期,
学生数,
合格者数,
平均点,
受講時間数,
AVG(平均点) OVER (PARTITION BY 科目名) AS 平均点_科目レベル
FROM grades
WHERE 学期 IN ('2025-前期', '2025-後期') -- 選択した学期をフィルタリング
)
SELECT * FROM subject_level_avg;
お、科目レベルで期間を跨いだ平均点が算出されましたね。
2. 不合格科目名の再現
QuickSightの ifelse({平均点_科目レベル} < 60, {科目名}, NULL) を再現します。
-- 不合格科目名の計算
WITH subject_level_avg AS (
SELECT
科目名,
学期,
学生数,
合格者数,
平均点,
受講時間数,
AVG(平均点) OVER (PARTITION BY 科目名) AS 平均点_科目レベル
FROM grades
WHERE 学期 IN ('2025-前期', '2025-後期') -- 選択した学期をフィルタリング
),
failing_subjects AS (
SELECT
科目名,
学期,
学生数,
合格者数,
平均点,
受講時間数,
平均点_科目レベル,
CASE
WHEN 平均点_科目レベル < 60 THEN 科目名
ELSE NULL
END AS 不合格科目名
FROM subject_level_avg
)
SELECT * FROM failing_subjects;
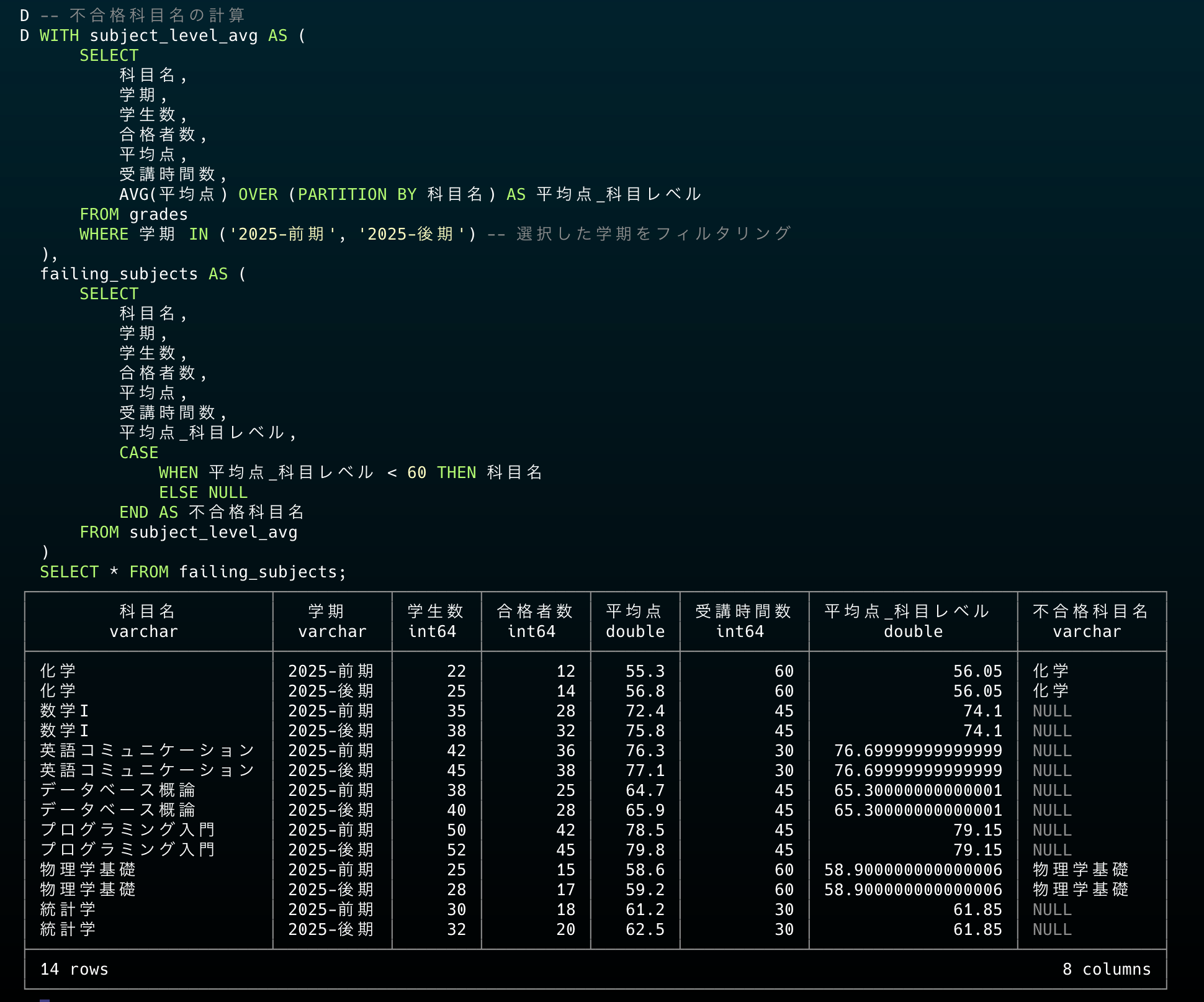
判定も無事できました!不合格科目は化学と物理学基礎ですね。ただこのままだと重複していますね。
3. 不合格科目数の再現
QuickSightの distinct_count({不合格科目名}) を再現します。
WITH subject_level_avg AS (
SELECT
科目名,
学期,
学生数,
合格者数,
平均点,
受講時間数,
AVG(平均点) OVER (PARTITION BY 科目名) AS 平均点_科目レベル
FROM grades
WHERE 学期 IN ('2025-前期', '2025-後期') -- 選択した学期をフィルタリング
),
failing_subjects AS (
SELECT
科目名,
学期,
学生数,
合格者数,
平均点,
受講時間数,
平均点_科目レベル,
CASE
WHEN 平均点_科目レベル < 60 THEN 科目名
ELSE NULL
END AS 不合格科目名
FROM subject_level_avg
)
SELECT
COUNT(DISTINCT 不合格科目名) AS 不合格科目数
FROM failing_subjects;

おおお、無事重複を除いた不合格科目数が算出できましたね!QuickSight上にある値とも一致しているので、計算ロジックは間違っていなさそうで安心しました。
おわりに
DuckDBはローカル上のCSVファイルを直接読み込めるため、データベース環境を用意する手間もなく、気軽に検証できて便利でした!!
これからも積極的にローカルでデータを扱う際は試していきたいです!!
最後までご覧いただきありがとうございましたー!










