
2019年VPC Lambdaが高速に!! AWS Lambdaの内部構造に迫るセッション 「SRV409 A Serverless Journey: AWS Lambda Under the Hood」 #reinvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
サーバーレス開発部@大阪の岩田です。 re:Invent2018が終了して約3週間、今では各セッションの動画やスライドが多数公開されており、気軽に情報収集ができるようになりました。
私もYoutubeを活用して、現地で参加できなかったセッションの動画を少しづつ視聴していたのですが、 「SRV409 A Serverless Journey: AWS Lambda Under the Hood」の内容が非常に興味深いものでした。
サーバーレス開発部が普段ゴリゴリに触っているAWS Lambda(以後は単にLambdaと表記します)の内部構造に言及しており、2019年にVPC Lambdaが高速化されるという情報も知る事ができました。 このセッションの内容を多くの人に知ってもらいたいので、Lambdaの内部構造という観点からセッションの内容をまとめてみます。 ※直訳というよりも自分なりのまとめです。また、Lambdaの内部構造に関係無い話は省略しています。
なお、筆者の英語スキルは低いです。 頑張ってまとめたたつもりですが、もし誤訳や認識違いがあれば指摘頂けると幸いです。
資料
まずセッションの資料です。英語がバリバリな方はセッション動画だけ見ておけばOKかと思います。
セッション動画
スライド
ここから個人的な見解を元にセッションの内容をまとめていきます。
Lambdaのコンポーネント
Lambdaのコンポーネントは大きく下記のように分類されます。

- Control Plane
- Developer Tools
- Lambda Console
- SAM CLI
- Control Plane APIs
- Configuration
- Resource Mgmt(Management)
- Developer Tools
- Data Plane
- Synchronous Invoke
- Front End Invoke
- Counting Service
- Worker Manager
- Worker
- Placement Service
- Asynchronous Invoke & Events
- Pollers
- State Manager
- Leasing Service
- Synchronous Invoke
Control Plane
Control Planeは開発者とLambdaのとやり取りを仲介するためのコンポーネントで、Developer ToolsとControl Plane APIsに大別されます。 Developer Toolsは開発者向けの各種ツールの事で、Lambda ConsoleやSAM CLIが該当します。
Control Plane APIsは、Lambdaの設定を行うためのConfiguration APIとリソース管理を行うためのResource Mgmt(Management) APIに分かれます。 例えばリソース管理APIではユーザーが作成したコードをパッケージングし、Lambdaサービスへのアップロードと配置を行います。
Data Plane
Data PlaneはさらにSynchronous Invoke(同期呼び出し)とAsynchronous Invoke & Events(非同期呼び出しとイベント)に分類されます。
Asynchronous Invoke & EventsはDynamoDBやKinesis、SQSといったサービスとの相互連携を行う一連のコンポーネント群です。前述のAWSサービスのイベントが処理されると、Synchronous Invoke(同期呼び出し)のエリアに引き渡されます。 ※ここの一連のコンポーネント(Pollers,State Manager,Leasing Serviceの説明は特に無かったようです)
Synchronous Invokeはこのセッションで重点的に説明されていたコンポーネント群です。
- Front End Invoke
- Counting Service
- Worker Manager
- Worker
- Placement Service
5つのコンポーネントから構成されます。
Front End Invoke
このコンポーネントは同期呼び出しと非同期呼び出し両方に対するオーケストレーションの責務を持ちます。 このコンポーネントが呼び出し元の認証を行い、妥当な呼び出しの場合だけLambda Functionの実行を許可します。 認証できた場合は、Control Plane APIを介して環境変数やメモリの割当やタイムアウトといったLambda Functionのメタデータをロードします。
次にCounting Serviceと連携して呼び出しの並列度をチェックします。 並列度が閾値を超えていない場合は対象のFunctionをWorker Managerに割り当てます。 並列度が閾値を超えている場合はWorker Managerをスケールアップさせます。 Worker Managerがスケールアップする事でWorkerもスケールアップされ、負荷分散が実現されます。
Counting Service
このコンポーネントは同時実行性に関するリージョンワイドなビューを提供し、Lambdaの同時実行数の制限を行う責務を持っています。 このコンポーネントはLambda Functionの同時実行数を常にトラッキングしており、現在の同時実行数が制限値を下回っている場合はLambda Functionの呼び出しを許可し、制限値を上回っている場合はスロットリングを発生させる可能性があります。
このコンポーネントはLambda Functionの実行毎に呼び出されるため、1.5ミリ秒未満の低レイテンシで高いスループットを実現するように設計されています。また、このコンポーネントは重要なコンポーネントなので、複数のAZに分散して配置されています。
Worker Manager
このコンポーネントはコンテナの状態(アイドル・ビジー)をトラッキングしており、使用可能なコンテナにコードの実行要求をスケジューリングし、環境変数のセットアップやLambda実行ロールの設定などを行います。
Lambda実行ロールに正しい権限が設定されており、かつコンテナが利用できない場合は、Placement Serviceを通じてWorkerのスケールアップを制御します。
Worker
このコンポーネントはLambdaのアーキテクチャーにおいて非常に重要なコンポーネントです。ユーザーのコードを実行するためのセキュアな環境=サンドボックス環境のプロビジョニングを担当しており、メモリやCPU等のリミットを設定したサンドボックス環境を作成、管理します。 Workerの責務としては以下のような処理が挙げられます。
- Lambdaのコードをダウンロードし、実行するためにサンドボックス環境にマウントする
- 複数の言語ランタイムを管理する
- 顧客のコードの初期化と実行を行う
- CloudWatchなどのAWSが管理するモニタリング用のエージェントを管理する
- サンドボックス環境内でコードの実行が完了した際にWorker Managerへの通知を行う
Placement Service
このコンポーネントはWorker上に構築されたサンドボックス環境の配置を最適化するコンポーネントです。 顧客体験やレイテンシへの影響を与えることなく、サンドボックス環境の密度が最大限になるように配置を行います。
このコンポーネントはWorkerの監視も行なっており、Workerの異常を検出すると対象のWorkerを異常(unhealthy)としてマークします。
Lambdaのコンポーネントがどのように負荷分散を実現しているか
ここからは各コンポーネントの役割を踏まえた上で、具体的なユースケースを見て行きます。 Lambdaは
- Workerがプロビジョニング済みか
- サンドボックス環境がプロビジョニング済みか
によって、いくつかの動作モードを持ちます。
シナリオ1 Workerはプロビジョニングされているが、新しいサンドボックス環境が必要な場合
このシナリオのフローはざっくり下記の通りです

- 顧客がALBにリクエストを行う
- ALBは配下のFront End Invoke(冗長構成になっている)にリクエストを流す
- Front End Invokeは呼び出し元を認証し、呼び出し対象Functionのメタデータを取得する
- Front End Invokeは取得したメタデータを使用してCounting Serviceと連携してFunctionの同時実行数をチェックする
- Front End InvokeがWorker Managerにサンドボックス環境の予約をリクエストする
- Worker ManagerはWorker上にLambdaのコードをダウンロードしてランタイムの初期化と、コードの初期処理(カスタムレイヤーで言うところのbootstrapに該当すると思われます)を実行してサンドボックス環境を構築する。サンドボックス環境が構築できたら、WorkerはWorker Managerに対してサンドボックス環境の構築が完了したことを通知する。
- Worker ManagerはFront End Invokeに対してコードの実行準備が完了したことを通知する
- Front End InvokeがWorkerにコードの実行を要求する
- Worker上でコードが実行され、コード実行に関する各種メトリクスが収集された後、Workerは自身がアイドル状態に遷移したことをWorker Managerに通知する。以後Woker Managerはサンドボックス環境が準備済みであることを認識する。
シナリオ2 Workerもサンドボックス環境もプロビジョニングされている場合

- 〜略
- Front End InvokeがWorker Managerにサンドボックス環境の予約をリクエストする
- Worker Managerは準備済みのサンドボックス環境(Warmサンドボックス)が存在することを応答する
- Front End InvokeがWorkerにコードの実行を要求する
- 〜略
基本的にはシナリオ1と同じフローで、Front End InvokeがWorker Managerにサンドボックス環境の予約をリクエストした後のフローが変わります。 Lambdaの実行パターンのほぼ全てはこのモードとのことです。
LambdaのコンポーネントがどのようにAuto Scalingを実現しているか
次はAuto Scalingのフローです。
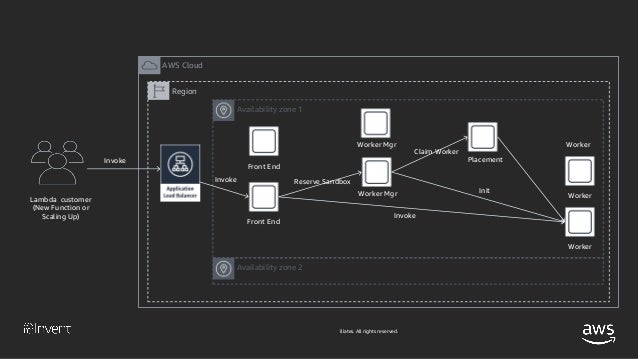
前述のシナリオ1と最初の流れは同様です。
- 〜略
- Front End InvokeがWorker Managerにサンドボックス環境の予約をリクエストする
- Worker ManagerがWorkerとサンドボックス環境を所有していない場合、Front End Invokeに対してWorkerとサンドボックス環境が無いことを応答する
- Worker ManagerはPlacement ServiceにWorkerを要求する
- Placement ServiceはWorkerをプロビジョニングするための適切な場所を探してWorkerをプロビジョニングし、Workerを配置した場所をWoker Managerに応答する
- Worker ManagerはWorker上にサンドボックス環境を作成する※以後前述のシナリオと同様の流れ
Placement Serviceについての補足
Placement ServiceはWorker Managerからの要求を達成するために十分なWorkerを確保する責務を持っており、Worker Managerに対してWorkerを6~10時間の間リースします。
Workerがリース期間の満了に近づくと、Worker Managerは全てのサンドボックス環境がアイドル状態になるように、サンドボックス環境の予約を停止します。 全てのサンドボックス環境がアイドル状態になると、Worker ManagerはPlacement ServiceにWorkerを返却します。
Lambdaのコンポーネントがどのように障害に対応しているか
障害は常に発生し得るもので、Lambdaはホスト単位の障害やAZ単位の障害に対応できるようにデザインされています。
- Lambdaのコンポーネントは複数のAZをまたいで構成されており、前述の負荷分散・冗長構成に加えて、ホストのヘルスチェックを行なっている。ヘルスチェックに失敗したホストはLambdaの環境から除去される。
- Workerが異常(unhaelthy状態)になった場合は、Workaer Managerが異常を検出してサンドボックスのプロビジョニングを停止する。
- AZ単位で障害が発生した場合、障害が発生したAZにはトラフィックを流さないようにしてLambdaのコンポーネントは引き続き実行される。
Workerの詳細について
ここからさらにWorkerについて深掘りしていきます。
Isolation(環境の分離)
Lambdaというサービスは複数のLambda Functionを同一のハードウェア上で実行しています。 これらのLambda Functionはセキュリティと操作上の観点から環境を分離することが重要です。
Lambdaというサービスのレイヤーはこのような構成になっています。

- Lambda RuntimeのレイヤーはJava,Node.js,Pythonといった言語のランタイム
- ゲストOSはAmazonLinuxを実行している
- サンドボックス環境内のランタイムは1つのLambdaFunctionでのみ利用される
- Lambdaを複数回呼び出すと、同じサンドボックス環境内で直列に実行される。スケールアップすることはあるが、1つのサンドボックス環境が複数のLambda Functionで利用されることは無い
- ゲストOSは同一AWSアカウントの複数のLambda Functionで共有されることがあるが、同一のゲストOSを複数のAWSアカウントが共有することは無い。
- AWSアカウント間の境界は仮想化レイヤー
サンドボックスレイヤーではコンテナ型の仮想化と同じ技術を用いてサンドボックス環境間の環境分離を実現しています。

利用しているLinuxカーネルの機能は下記の通りです。
- cgroups サンドボックス環境へのリソース(メモリ、CPU、ディスクスループット)の割り当てをコントロールします
- namespaces プロセス間でリソースの分離を行う 同じホスト上で複数のサンドボックス環境が稼働していう場合でも、それぞれのサンドボックス環境から見たLambda FunctionのプロセスIDは常に1に見えます。
- seccomp カーネルのための一種のファイヤーウォールのような機能で、プロセスから発行可能なシステムコールを制限することが可能です。Lambdaから発行可能なシステムコールは必要最低限に制限されています
- iptables ネットワークの隔離機能を提供します
- chroot ファイルシステムの隔離機能を提供します
LambdaのWorkerをビルドする方法について
現在、LambdaのWorkerをビルドする方法は2種類あります
EC2インスタンス上にWorkerを構築する方法

AWSがLambdaのサービスを開始した時から利用されているモデルで、この方法は今でも利用されています。 このモデルでは複数のAWSアカウント間の環境分離はゲストOSレベルで実現しています。

Firecrackerを利用する方法
もう1つの方法はFirecrackerを用いる方法です。 Firecrackerを用いる場合は、ベアメタルのEC2インスタンス上で何十万ものEC2のマイクロVMを稼働させ、マイクロVM上にLambdaのサンドボックス環境を構築します。この方法はより柔軟、かつ迅速にサンドボックス環境を分離することが可能です。

このモデルでは複数のAWSアカウント間の環境分離はマイクロVMレベルで実現しています。

デバイスのエミュレーションについて
Firecrackerの上では数十万のマイクロVMが稼働していると言われていますが、実際のハードウェア上には数十万のHDDやネットワークカードは存在しません。 しかし、マイクロVMの各ゲストOSはHDDやネットワークカードを認識し、それぞれのユーザー空間からはハードウェアのように見えます。 これはデバイスのエミュレーションによって実現されています。
ゲストOS向けのデバイスエミュレーションにはvirtioを利用しています。 virtioはゲストカーネル内のブロックデバイスやネットワークカードを実装するセキュアな方法です。 virtioを使うことでゲストOS<->ホストOS間のやり取りを減らしています。Firecrackerの革新はデバイスエミュレーションが非常に制限されたサンドボックス内で実行されることです。
※virtio周りの知識不足でFirecrackerの有無でvirtioの使い方がどう変わるのかがよく分からず...
Utilization
次のトピックはUtilizationについてです。 Lambdaのシステムはいかにハードウェアリソースの利用量をコントロールしているのでしょうか?
サーバーがビジー状態を保つように調整する
例えば7つのサンドボックス環境がそれぞれリソース使用率60%で稼働するのは無駄です。対して4つのサンドボックスがそれぞれリソース使用率99%で稼働するのは良い状態です。


通常のシステムでは余裕を持った閾値でWorker群をスケールさせて負荷分散を行いますが、Lambdaは少量のサンドボックス環境が全てビジー状態になるように負荷をコントロールします。これはコード実行の観点からは良いことで
- キャッシュ
- 事前計算されたリソース
- オープン済みのNW接続
- 一時ファイル
といったリソースを効率よく利用することができます。 理想的な稼働状態はCPUのサイクルは全てコードの実行に利用されており、WorkerのRAMはユーザーデータで埋め尽くされている状態です。
ワークロードの配置について
Placement Serviceはワークロード=Lambda Functionの配置を最適化するように動作します。

同じワークロードを実行するサンドボックス環境のコピー群を1つのサーバー上で動かす構成は良くない構成です。コピー同士のワークロードに相関関係があり、1つのサンドボックス環境でリソースの使用率が跳ね上がったときに、同じワークロードを実行する別サンドボックスのリソース使用率も跳ね上がることになります。 こうなるとホストの限られたハードウェアリソースを有効活用できなくなり、1つのハードウェアに詰め込めるサンドボックス環境が少なくなります。

対して1つのサーバー上に複数のワークロードが混在するのは良い状態です。ワークロードAがビジー状態でもワークロードBがアイドル状態という状況は限られたハードウェアリソースを有効活用でき、1つのハードウェアに詰め込めるサンドボックス環境が多くなります。
うまく同居できるワークロードを選択して配置することが重要で、Placement Serviceは統計情報を活用してできるだけ相関の無いワークロード同士を同じサーバーに配置するよう動作します。
例えば20面のダイスを投げた時に1~20の数値が出る確率は全て同じ確率で分布します。

対して10面のダイスを2回投げて、出た目の合計を計測すると、20が出る確率より12が出る確率の方が高くなります。 10面のダイスを2回投げて合計値に20を出すには10を2回連続で出す必要がありますが、12を出すためには10+2、9+3、8+4、7+5といった多数の組み合わせが存在するからです。

同じ理屈で相関の無い複数のワークロードを1つのサーバーに配置することで、サーバー全体の負荷が標準化されます。
VPC Lambdaの改善について
2019年に向けてVPC Lambdaを改善する準備を進めているそうです。
現在のアーキテクチャ
まずVPC Lambdaの動作についてのおさらいです。

VPC Lambdaが実行された際、ENIが作成されてWorkerにアタッチされます。 ENIを作成、アタッチすることでVPCのフル機能がサポートされる代わりに
- VPC Lambdaは起動に時間がかかる
- Workerごとにサブネット内のIPアドレスを1つ消費する
といったデメリットがあります。 現状のアーキテクチャではENIへのNAT処理はWorker内部で LocalNATするような構成となっています。
今後のアーキテクチャ
2019年中に下記のようなアーキテクチャに移行します。

今後はWorker外のRemoteNATというコンポーネントでENIとのNAT処理を行い、WorkerとRemoteNATの間はSecure Tunnelというコンポーネントで接続されるようなアーキテクチャに移行される予定です。 このアーキテクチャの移行により、
- 時間のかかる処理はLambda Functionのスケール時ではなくLambda Function作成時に実行されるので、スケールが早くなる
- VPC Lambdaのレイテンシが下がり、レイテンシが予測しやすくなる
- ENIやIPアドレスの範囲に制限を設けずにVPC Lambdaを実行できるようになる
- 1つのENIを多くのWorkerで共有して利用するためIPアドレスの消費数が減り、NWの管理が簡素化される
といった効果が期待できます。
Firecrackerの効果
前述のVPC Lambdaの改善はFirecrackerのおかげで実現可能になりました。 Firecrackerと他の仮想化ソリューションを比較すると、Firecrackerには下記のような特徴があります。
- スタートアップタイムが削減される
- メモリのオーバーヘッドが削減される
- 柔軟性が上がる
- パフォーマンスはあまり変わらない
Firecracker最高!!
まとめ
Lambdaの内部構造を知ることができる面白いセッションだと感じました。 2019年にリリースされるVPC Lambdaが待ち遠しいです!!










