![[re:Invent 2019 세션 레포트] PartiQL: One query language for all of your data #reinvent](https://devio2023-media.developers.io/wp-content/uploads/2019/12/reinvent2019_report_eyecatch.jpg)
[re:Invent 2019 세션 레포트] PartiQL: One query language for all of your data #reinvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
안녕하세요! 클래스메소드 주식회사 의 김태우입니다!
오랜만에 한국어로 블로그를 작성하려니 너무 신나네요!!ㅋㅋㅋㅋ 저희 회사는 현재 80명이 넘는 인원으로 미국 라스베가스 re:Invent 에 참여하고 있습니다. 이렇게 생긴 파란색 블루자켓을 보시면 다 저희 회사분들입니다 :)

저희회사에서는 re:Invent 에 참여하고 싶은 사람은 전원 다 보내주는 대신(모든 경비 지원), 성과물로서 블로그를 최소 10편 이상 써야하는 규칙이 있습니다. ㅎㅎㅎ 네!! 저는 그 블로그를 이번에는 한국어로 전부 작성해서 한국분들에게도 현지의 생생한 정보들을 전달하려고 합니다. 오늘 제가 제일 처음으로 들었던 세션은 PartiQL(파티클 이라고 발음하더군요) 관련한 200 레벨 세션이었는데요, 평소에 궁금했던 부분들을 꽤나 자세하게 설명해주고 있어서 너무 유익했습니다.
자, 그럼 본격적인 세션 레포트로 넘어가보겠습니다!!
목차
What is PartiQL?
PartiQL 은 지난 8월 발표된 AWS 의 오픈소스 프로젝트입니다. AWS 콘솔에서는 검색해도 찾을 수 없고 별도의 공식사이트 로 관리되고 있습니다.
기본적으로 PartiQL 은 쉽게말해서
누구나 다 알고 있는 SQL 문법으로 작성한 쿼리로 모든 종류의 데이터 소스에서 데이터를 가져오자!
를 기본적인 철학으로 삼고 있습니다.
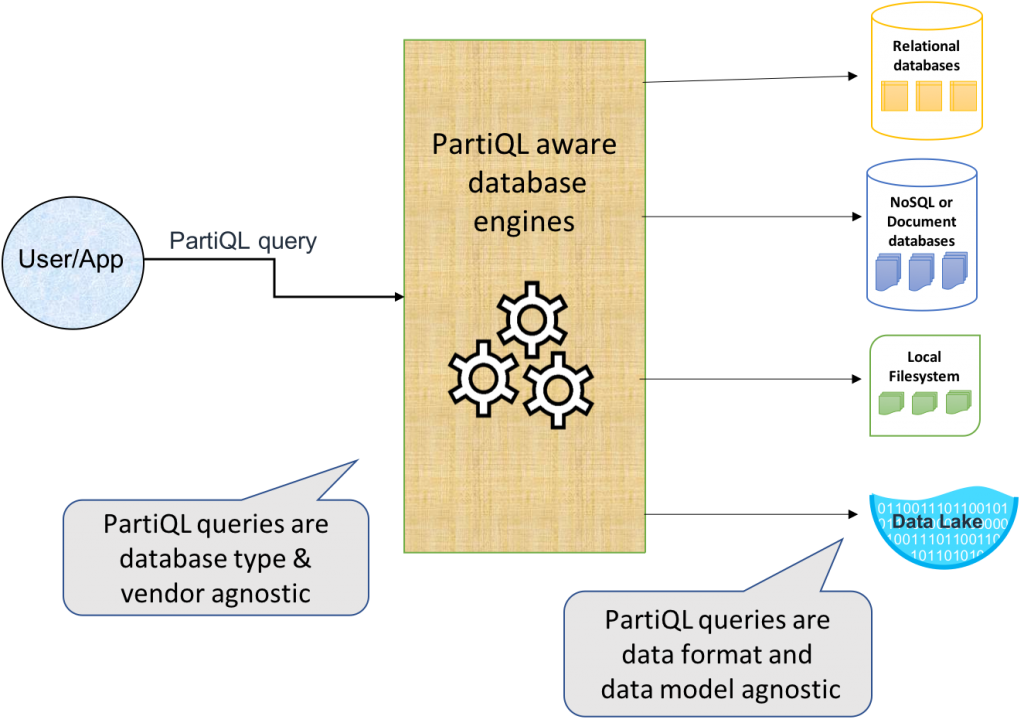
위의 그림에서 보듯이 PartiQL 의 데이터소스는 RDB 는 물론이거니와 NoSQL 이나 파일시스템, 그리고 데이터레이크까지도 지원합니다. 저도 사실 본 세션을 듣기 전에는 이름만 들어봤을뿐 구체적으로 어떤식으로 동작하는지는 잘 알아볼 기회가 없었는데요, 이번 세션을 통해 기본적인 개념은 이해하게 되어서 정말 유익했습니다.
A walkthrough of PartiQL
PartiQL data model

PartiQL 에서는 Amazon Ion 이라는 json compatible 한 strong type 과 comment 를 지원하는 데이터 형식을 사용합니다. 쿼리의 효율성을 높이기 위해 SQL bags 라는 것도 활용한다고 하는데, 이부분은 저도 정확하게 이해를 못했습니다. Strong type 이 강조되는 Amazon Ion 을 활용하는 PartiQL 이지만, PartiQL 에서는 Ion 을 SQL data type 에만 활용할 뿐, PartiQL 의 data model 로서는 dynamic typing 을 지원합니다. 이게 어느정도 수준의 dynamic typing 이냐하면, nesting 은 원하는 만큼, array 안에 heterogeneity + sparseness 도 지원하기때문에 사실상 거의 모든 스키마 타입을 다 지원한다고 보시면 될 것 같습니다.

PartiQL query language
여기서부터가 좀 더 직관적으로 와닿는 내용들이 많았는데요, RDB 는 그냥 기존의 SQL 을 지원하는 방식과 똑같기때문에 JSON 데이터 위주로 설명을 했던 것 같습니다.

사진의 오른편에 보시면 알 수 있듯이, 정말로 모두가 알고 있는 SQL 언어로 작성되어서 왼편의 JSON 데이터에 쿼리를 날릴 수가 있습니다. LIMIT 이나 ORDER BY 등도 당연히 지원되는 것 같네요! 결과로서 우측 하단부의 sensors 라는 테이블의 readings 오브젝트 중에 v 값이 1보다 작은 애들을 내림차순으로 정렬했을때 위에서 2번째까지 가져온 내용을 표시하고 있습니다. (한국어 말이 어렵네요;;; 이래서 SQL 쿼리를 영어로 작성하나봅니다^^;)

이제부터는 FROM, WHERE 등의 semantic 에 대한 설명인데요, 우측 사진에서 보시다시피 FROM 구문이 실행되면, Amazon Ion + SQL Bags 형식의 PartiQL 데이터 모델로 변환되어서 WHERE 구문으로 넘겨집니다.

이번에는 WHERE 구문의 semantic 입니다. FROM 구문에서 결과로 넘겨받은 데이터에서 조건에 맞게 필터링되었네요. 내부적으로 동작하는 방식도 굉장히 직관적이고 좋은것 같습니다!

이번에는 LEFT JOIN 입니다. sensors 테이블과 dynamic 하게 생성한 sensors.readings 테이블을 LEFT 조인한 결과를 보여주고 있습니다. 역시 잘 동작하는군요!

SELECT 문의 r.event.v 처럼 nested 하게도 접근이 가능하네요!

서브쿼리도 작성할 수 있습니다! 이쯤되면 정말 대단하지 않나요?ㅋㅋ 저는 세션중에 OMG this is insane! 만 중얼중얼 연발했습니다..ㅋㅋㅋ 다행히 헤드셋을 착용하는 세션이라 제 중얼거림이 아무에게도 방해되지는 않았던 것 같아요ㅋㅋ

네, range query 도 당연히 가능합니다.

이게 좀 신기했는데요, SELECT VALUE 라는 처음보는 문법으로 object(tuple) 이 아닌 array 에 쿼리를 날릴수도 있다는 점을 알게되었습니다. 역시 JSON 데이터에 쿼리를 날리려면 역시 Array 에 쿼리를 날리는 경우도 고려해야할텐데, 이러한 점도 당연히 서포트해주고 있었습니다.

RDB 와는 달리 schema-less 의 data lake 의 경우에는 SQL 방식의 쿼리를 작성하면 현실적으로 전제로 했던 데이터 모델과 맞지 않아서 에러가 발생하는 경우도 많을텐데요, 이러한 경우까지 고려하여 permissive mode 와 strict mode 를 둘 다 지원한다고 합니다. permissive mode 로 설정하면 에러가 발생하는 케이스에서도 쿼리가 잘 동작한다고 하네요.

그 외에도 위와 같은 기능도 지원한다고 합니다.
Unifying query language for diverse services
Amazon Redshift 도 내부적으로 PartiQL 을 적용하고 있다고 하는데요, 이를 통해 RDB 에도 쿼리를 날릴 수 있지만 S3 에도 쿼리를 날릴 수가 있습니다. (Amazon Redshift Spectrum)
이러한 경우에 해당하는 슬라이드입니다.

Using and contributing to PartiQL in open source
PartiQL 은 오픈소스 프로젝트이기 때문에 누구나 참여할 수 있고, 참여를 적극 권장하고 있습니다.
또한 레퍼런스도 제공해주었습니다.
마치며
AWS re:Invent 2019 첫 세션이었는데, 정말 유익한 정보들로 가득해서 너무 즐거웠습니다. 참고로, Amazon Athena 의 경우에는 원래 S3 만을 지원하다가 최근에 Lambda 로 데이터소스를 얼마든지 커스터마이즈할 수 있게 되었죠!! Lambda 로 작성하는 공수가 얼마 들지 않는다면 PartiQL 보다는 Athena 를 쓰는 것이 솔직히 더 좋지 않을까 싶긴 하지만, 너무 최근에 발표된 내용이라 저도 검증은 아직 못해봤습니다. 대신에 PartiQL 의 경우에는 인스톨해서 사용하면 되기때문에 자주 사용하는 경우에는 AMI 등을 만들어두고 그떄그때 인스턴스 올려서 사용해도 좋을것 같습니다. 어떤 방식이 더 좋을지는 솔직히 지금 제 수준에서는 잘 가늠이 안되네요^^;; 이글을 보신분들 중에서 둘 다 적용해보신분들이 계시다면 댓글로 공유해주시면 감사하겠습니다!ㅎㅎ
그럼 다음편도 기대해주세요~~~!









