![[レポート] DynamoDBの内部アーキテクチャに迫るセッションでミリ秒のレイテンシを実現する設計思想を学んできました #AWSreInvent #DAT436](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] DynamoDBの内部アーキテクチャに迫るセッションでミリ秒のレイテンシを実現する設計思想を学んできました #AWSreInvent #DAT436
はじめに
皆様こんにちは、あかいけです。
AWS re:Invent 2025に参加しており、
「An insider's look into architecture choices for Amazon DynamoDB」というセッションを聞いてきました。
Amazon DynamoDBは、100万を超えるAWSの顧客に利用され、毎秒50万リクエストを超えるアプリケーションを支えるフルマネージドNoSQLデータベースです。
本セッションでは、DynamoDBがどのようにして一貫したシングルミリ秒のパフォーマンスを実現しているのか、その内部アーキテクチャについて解説されましたので、その内容をまとめてみました。
セッション概要
タイトル
An insider's look into architecture choices for Amazon DynamoDB (DAT436)
概要
To overcome the performance and scale limitations of relational databases, AWS built Amazon DynamoDB to deliver consistent single-digit millisecond performance at any scale for the most demanding applications on the planet. In this session, learn about the architecture choices for Amazon DynamoDB. Gain a better understanding of when to use DynamoDB and why DynamoDB is used by over one million AWS customers, and powers hundreds of applications that exceed half a million requests per second. Leave with a new perspective on how to design your own applications.
リレーショナルデータベースのパフォーマンスとスケールの制限を克服するため、AWSはAmazon DynamoDBを構築し、世界で最も要求の厳しいアプリケーションに対して、あらゆるスケールで一貫したシングルミリ秒のパフォーマンスを提供しています。このセッションでは、Amazon DynamoDBのアーキテクチャ選択について学びます。DynamoDBをいつ使用すべきか、なぜ100万を超えるAWS顧客がDynamoDBを使用し、毎秒50万リクエストを超える数百のアプリケーションを支えているのかを深く理解できます。自身のアプリケーション設計に対する新しい視点を得ることができます。
スピーカー
- Amrit (DynamoDB Team)
- Craig (DynamoDB Team)
セッション情報
- レベル: 400 - Expert
- セッションタイプ: Breakout session
- トピック: Databases

セッション内容
DynamoDBのテネット(指針)
セッションの冒頭で、DynamoDBチームが意思決定を行う際の4つのテネット(指針)が紹介されました。
DynamoDBのすべての設計判断はこれらに基づいています。

- Security(セキュリティ): 最優先事項。決して妥協しない
- Durability(耐久性): データは必ず2つのAZに書き込まれてからコミット
- Availability(可用性): リージョナルサービスとして、AZ障害にも耐える
- Predictable Low Latency(予測可能な低レイテンシ): あらゆるスケールでシングルミリ秒のレイテンシ
スピーカーのAmritは「Security、Durability、Availabilityは交渉の余地がない。これらを犠牲にして他の機能を提供することは絶対にない」と強調していました。
これらの指標は、チーム全体で共有され、分散した意思決定を可能にしています。
大規模な組織でサービスを運用する際、中央集権的な意思決定では生産性が下がるため、指標を共有することで各メンバーが自律的に正しい判断を下せるようになっているとのことです。
DynamoDBのスケール

DynamoDBのスケールについて、具体的な数字が紹介されました。
- 毎秒50万リクエストを超えるテーブルが数百存在
- Amazon StoresビジネスはPrime Dayで毎秒1億5100万リクエストを達成(1つの顧客だけで)
- 完全に共有されたインフラストラクチャ上で、数十万のストレージノードにデータが分散
分散システムの設計原則
セッションでは、分散システムにおけるステートフルな状態管理の難しさについて詳しく解説されました。
なぜ3ノードなのか?
分散システムでレプリケーションを行う際のノード数について、段階的に説明がありました。
- 2ノード
- Primaryが障害を起こした場合は問題ない。しかしSecondaryが障害を起こした場合、Primaryへの書き込みをどう扱うか?Secondaryが復旧したときにどう同期するか?という問題がある
- 4ノード
- ネットワークパーティションが発生した場合、2対2に分断される可能性がある。両方のグループが「自分が正しい側」と判断して書き込みを受け付けると、Split Brain問題が発生する
- 3ノード
- 1つのノードが障害を起こしても、残り2つで過半数を維持できる。過半数(Quorum)ベースの判断が可能
なぜ「多数の3ノードグループ」なのか?
1001ノードで過半数(501ノード)への書き込みを必要とするシステムを想像してみてください。
任意の501ノードすべてに書き込みが成功する必要があり、どれか1つでも失敗すると書き込みが失敗します。
これは可用性とコストの両面で問題があります。
そこでDynamoDBは「多数の3ノードグループ」というアプローチを採用しています。
- データをパーティションに分割
- 各パーティションは3つのノード(3つのAZに分散)でレプリケーション
- これにより、スケーラビリティと可用性を両立
アーキテクチャの概要
DynamoDBのアーキテクチャは、以下の主要コンポーネントで構成されています。
- Request Router
- リクエストのルーティング、認証・認可を担当
- Storage Nodes
- データの保存を担当
- Control Plane
- テーブル管理、パーティション管理を担当
- Metadata
- パーティションのメタデータを管理
Request Routerの役割
Request Routerの3つの質問
クライアントからのリクエストがRequest Routerに到達すると、以下の3つの質問に答える必要があります。
- あなたは誰か? - SIGv4署名の検証による認証
- そのテーブルに対する操作権限があるか? - IAMポリシーによる認可
- レート制限内か? - スループット制限のチェック
これらの処理は毎秒数億回実行されるため、数十マイクロ秒で完了する必要があります。
複数AZへの分散
Request RouterとStorage Nodesは、3つのAvailability Zone(AZ)に分散配置されています。これにより、1つのAZが障害を起こしても、サービスを継続できます。
各AZにはRequest RouterとStorage Nodesのフリートが配置され、DNSを通じてロードバランシングされます。
Storage Nodesとパーティショニング
パーティションの構造
DynamoDBのテーブルは、パーティションキーに基づいて複数のパーティションに分割されます。各パーティションは3つのAZにレプリカを持ちます。
重要なポイントとして、DynamoDBは完全に共有されたインフラストラクチャです。
あなたのデータは、他の顧客のデータと同じストレージノード上に存在します。
だからこそ、すべてのデータは常に暗号化されています(Security第一のテネット)。
ハッシュベースのパーティショニング
パーティションキーのハッシュ値に基づいて、データが各パーティションに分散されます。
テーブル作成時に必要なのは3つだけ。
-
- テーブル名
-
- プライマリキー
-
- 支払い方法(クレジットカード)
プライマリキーのハッシュ値を計算し、連続するハッシュ範囲がパーティションになります。アイテムを取得する際は、ハッシュを計算してどのパーティションにあるかを数十マイクロ秒で特定します。
B-treeストレージ
各パーティション内では、B-treeを使用してデータが格納されます。これにより、効率的な範囲クエリとポイントルックアップが可能です。
レプリケーションと高可用性
Multi-Paxosによるレプリケーション
DynamoDBは、Multi-Paxosコンセンサスプロトコルを使用して、3つのAZ間でデータをレプリケーションします。
各パーティションには1つのリーダーと2つのフォロワーがあり、書き込みはリーダーを通じて行われます。
書き込みの流れ
-
- クライアントがRequest Routerにリクエストを送信
-
- Request Routerがリーダーノードを特定
-
- リーダーがフォロワーにログを伝播
-
- 過半数(2/3)のノードからACKを受信後、コミット
Durabilityのテネットにより、データは必ず2つのAZに書き込まれてからクライアントにACKが返されます。
リーダー選出
リーダーノードが障害を起こした場合、Paxosプロトコルにより新しいリーダーが自動的に選出されます。
また、リーダーは各AZに均等に分散されるように配置されます。これにより、Strongly Consistent Readでもトラフィックが均等に分散されます。
AZ障害への対応
1つのAZ全体が障害を起こしても、残りの2つのAZで過半数を維持できるため、サービスを継続できます。
読み取りの整合性モデル
Eventually Consistentリード
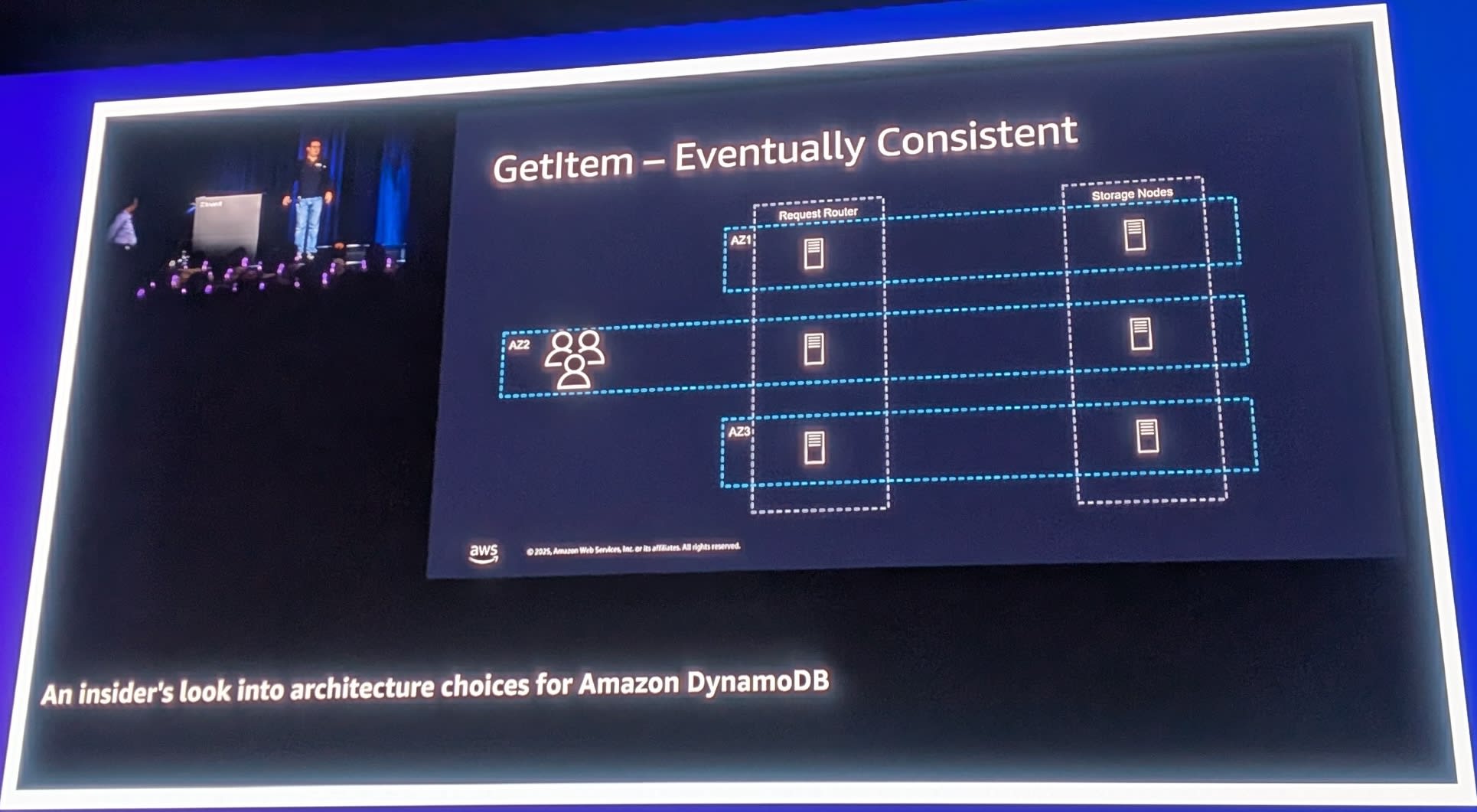
デフォルトの読み取りモードであるEventually Consistent Readでは、任意のレプリカから読み取ることができます。
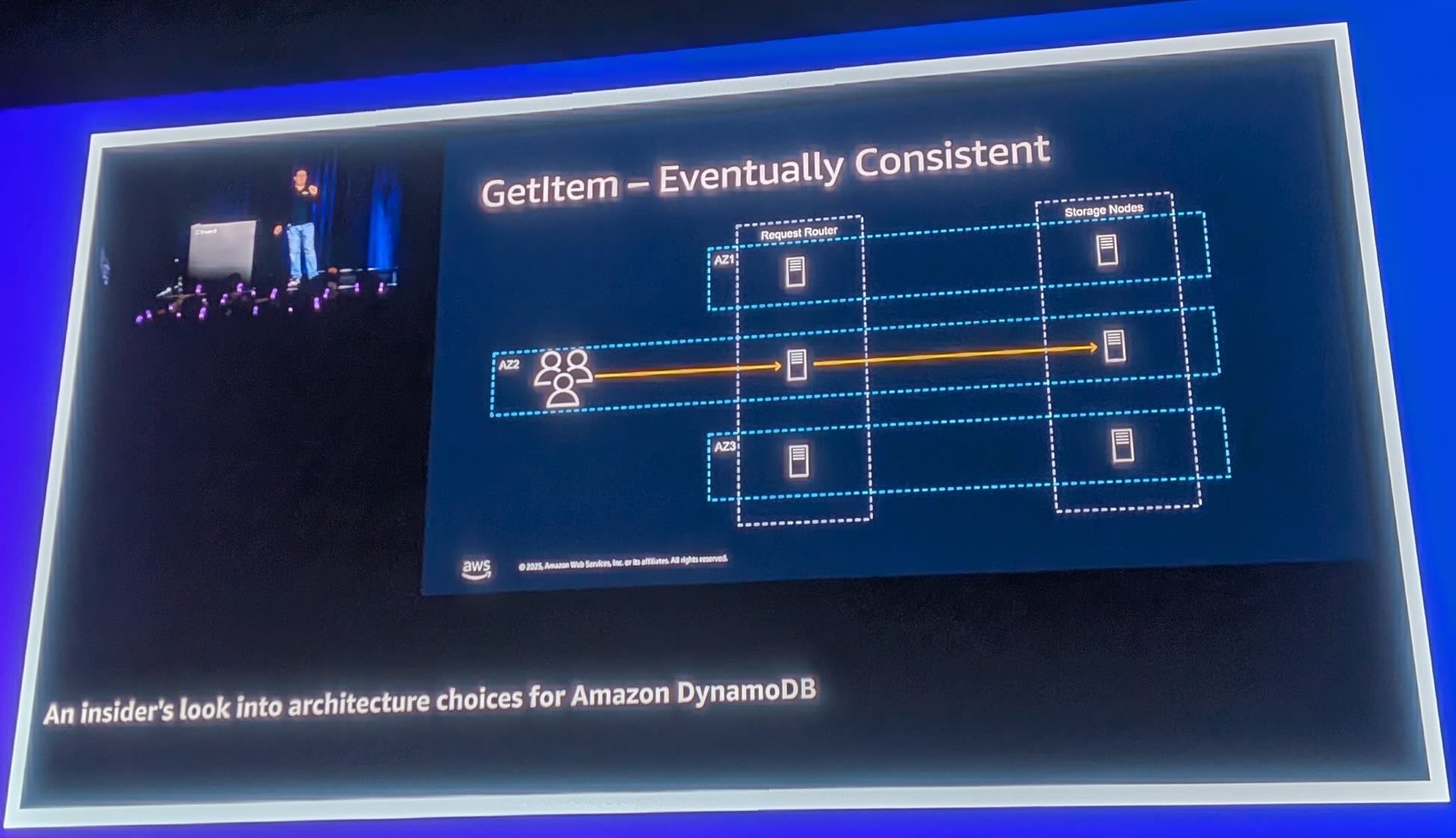
リクエストは、Request Routerからパーティションの任意のレプリカ(3つのAZのいずれか)に転送されます。これにより、読み取りの負荷を分散させ、高いスループットを実現できます。
Strongly Consistentリード
Strongly Consistent Readを使用する場合は、リーダーノードからのみ読み取りが行われます。これにより、常に最新のデータを取得できますが、レイテンシが若干増加する可能性があります。
Eventually Consistent Readの価格が安い理由
Eventually Consistent Readは、以下の理由からStrongly Consistent Readの半額で提供されています。
- Strongly Consistent Read: リーダーノード1台のみが処理可能
- Eventually Consistent Read: 3つのレプリカすべてが処理可能
3つのレプリカのうち1つは障害に備えて確保しておく必要がありますが、残りの2つのノードの処理能力を活用できます。つまり、アイドル状態だったはずの容量を使えるため、安価に提供できるのです。
DNSベースのルーティングとAZ最適化

DynamoDBへのアクセスは、DNSを通じてルーティングされます。
$ dig dynamodb.us-west-2.amazonaws.com +short
35.71.119.10
このシンプルなDNSエントリの背後には、複雑な分散システムが稼働しています。
Split Horizon DNS
DynamoDBはSplit Horizon DNSを使用しています。これは、クエリの発信元によって異なるDNS応答を返す仕組みです。
- AZ-1からのクエリ → AZ-1のロードバランサーのIPを返す
- AZ-2からのクエリ → AZ-2のロードバランサーのIPを返す
これにより、クライアントと同じAZにあるRequest Routerにルーティングされ、AZ間のネットワークレイテンシを削減できます。
DynamoDBのサーバー側処理時間は非常に短いため、ネットワークレイテンシがトータルレイテンシの大きな割合を占めます。AZ内ルーティングは、レイテンシ改善に大きく貢献しています。
AZ障害時の動作
トラフィックの再分散

通常時、トラフィックは3つのAZに均等(1/3ずつ)に分散されます。

1つのAZが障害を起こした場合、残りの2つのAZがトラフィックを引き継ぎます。DynamoDBはリージョナルサービスとして、常にこの状況に対応できるだけの余剰容量を確保しています。これがDynamoDBの価格に含まれているコストです。
トラフィック偏りへの対応
特定のAZにトラフィックが偏っている場合、そのAZがダウンすると残りのAZへの負荷が倍増する可能性があります。そのため、DynamoDBは各AZへのトラフィックが1/3を超えないようにDNS管理を行っています。
Eventually Consistentリードの負荷分散

Eventually Consistent Readでは、各AZのRequest Routerがそのパーティションの3つのレプリカに対して1/3ずつリクエストを分散させます。

ローカルAZへの優先ルーティングも行われますが、Eventually Consistent Readの2倍のスループット制限を超えた場合は、ランダムルーティングに切り替わります。可用性は常にレイテンシよりも優先されます。
メタデータ管理とキャッシュ戦略
Large Fleet - Small Fleet問題
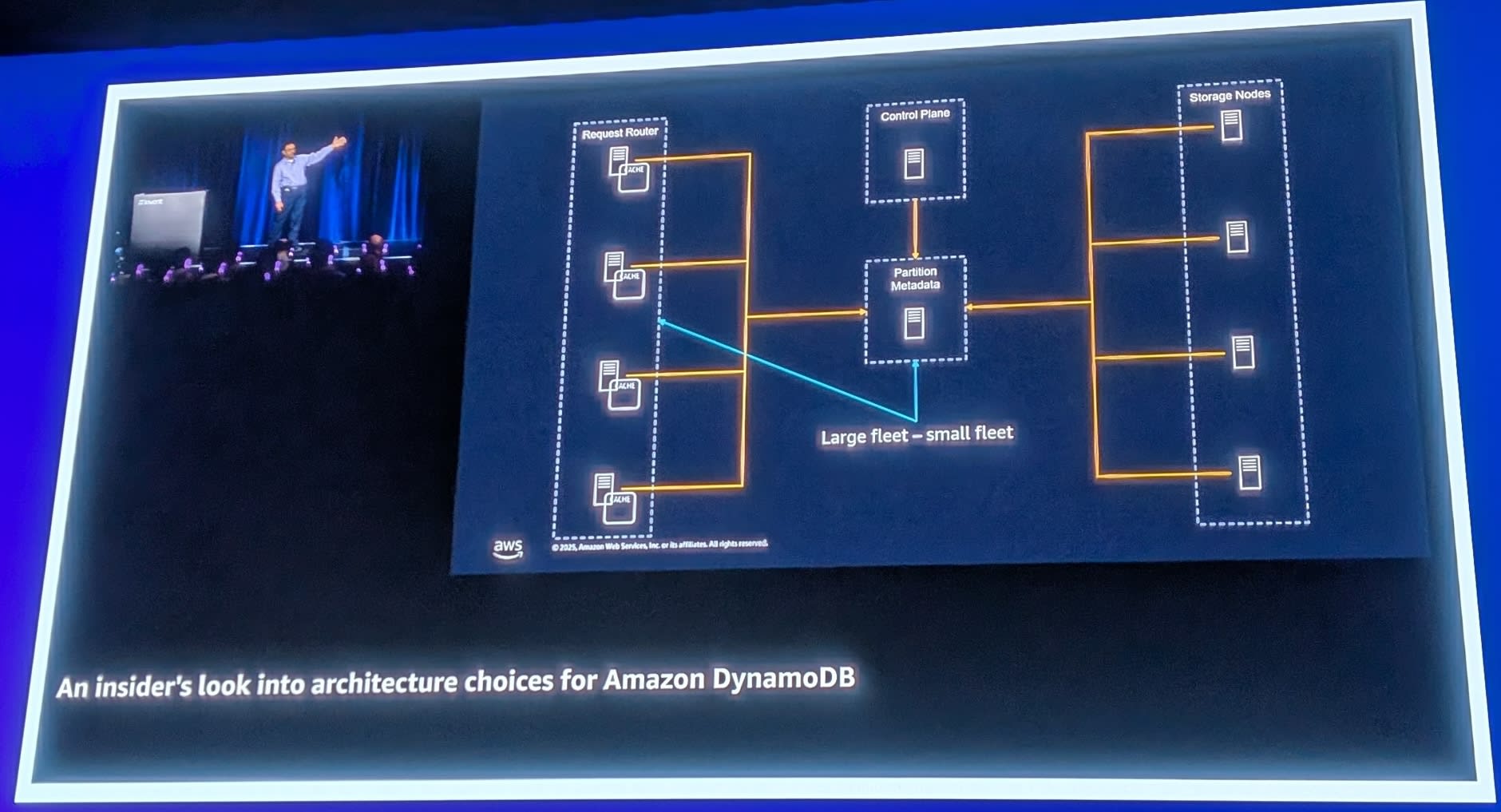
DynamoDBが直面する課題の1つが「Large Fleet - Small Fleet」問題です。
- Large Fleet: 数十万のRequest Router
- Small Fleet: メタデータを管理するPartition Metadata
すべてのRequest Routerがメタデータを直接参照すると、Partition Metadataがボトルネックになります。
2階層キャッシュ
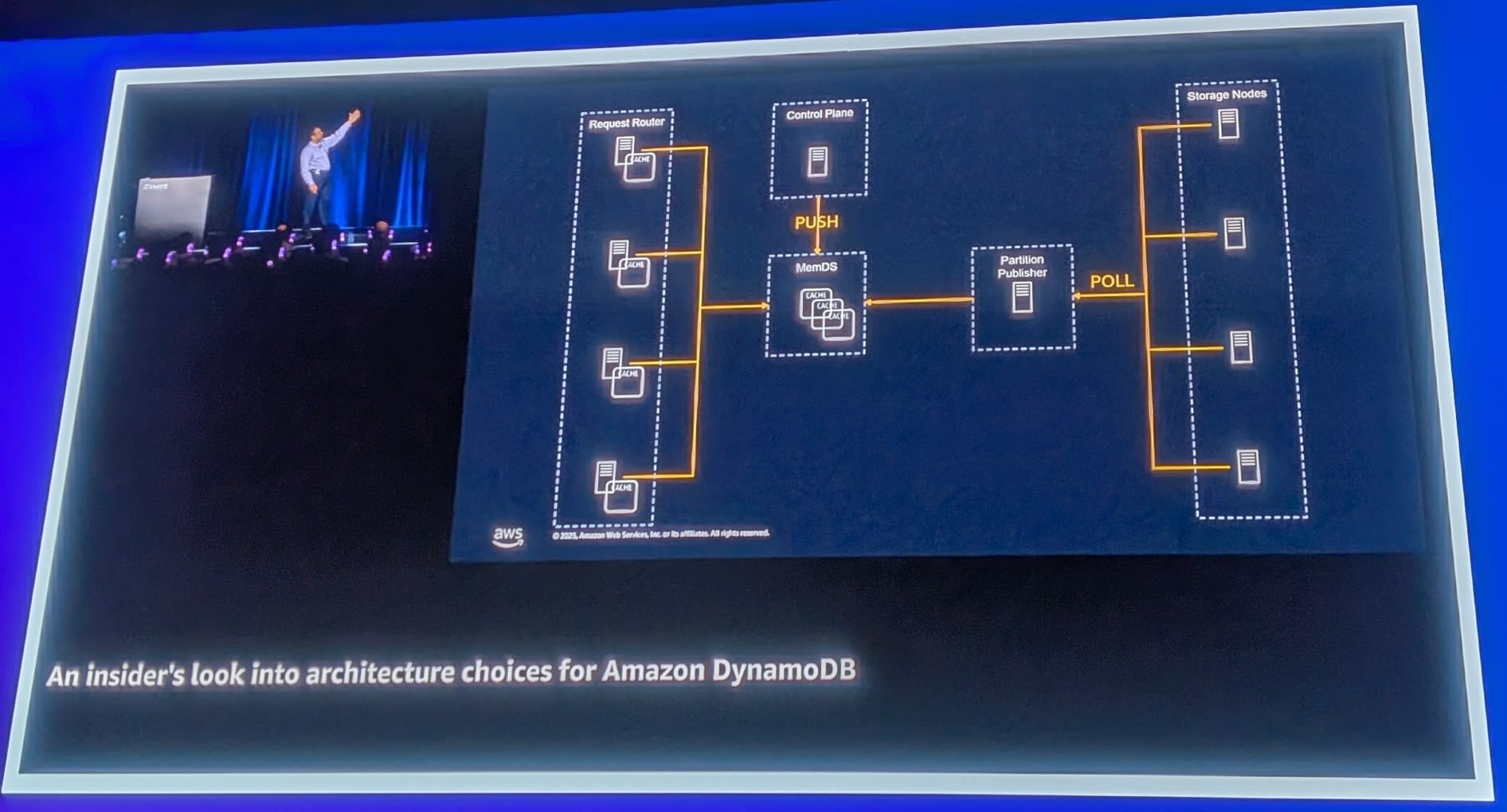
この問題を解決するため、DynamoDBは2階層のキャッシュを採用しています。
- Request Routerのローカルキャッシュ: 各Request Routerがメタデータをキャッシュ
- MemDS: 中間層のキャッシュサービス
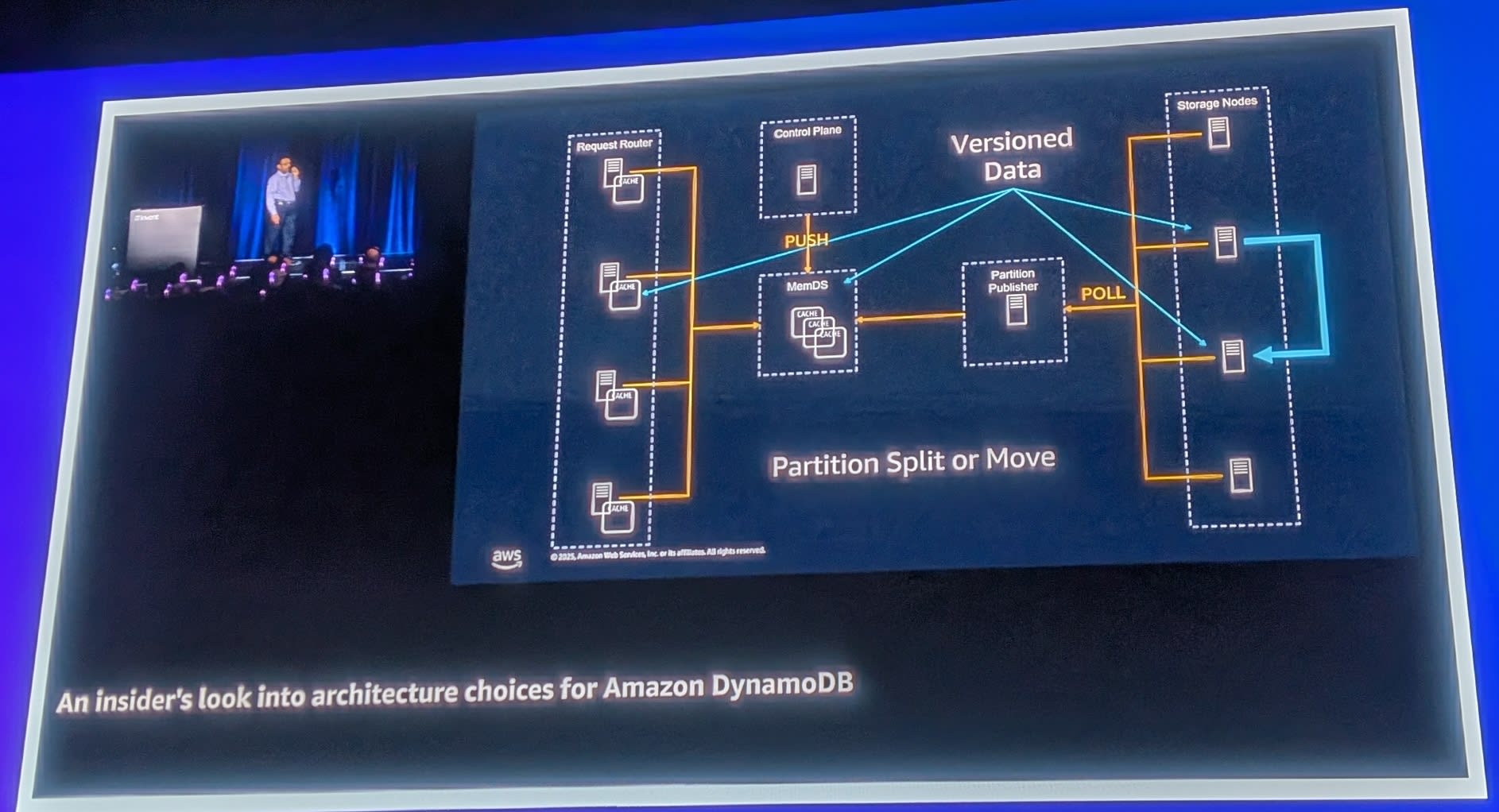
バージョン管理による整合性確保
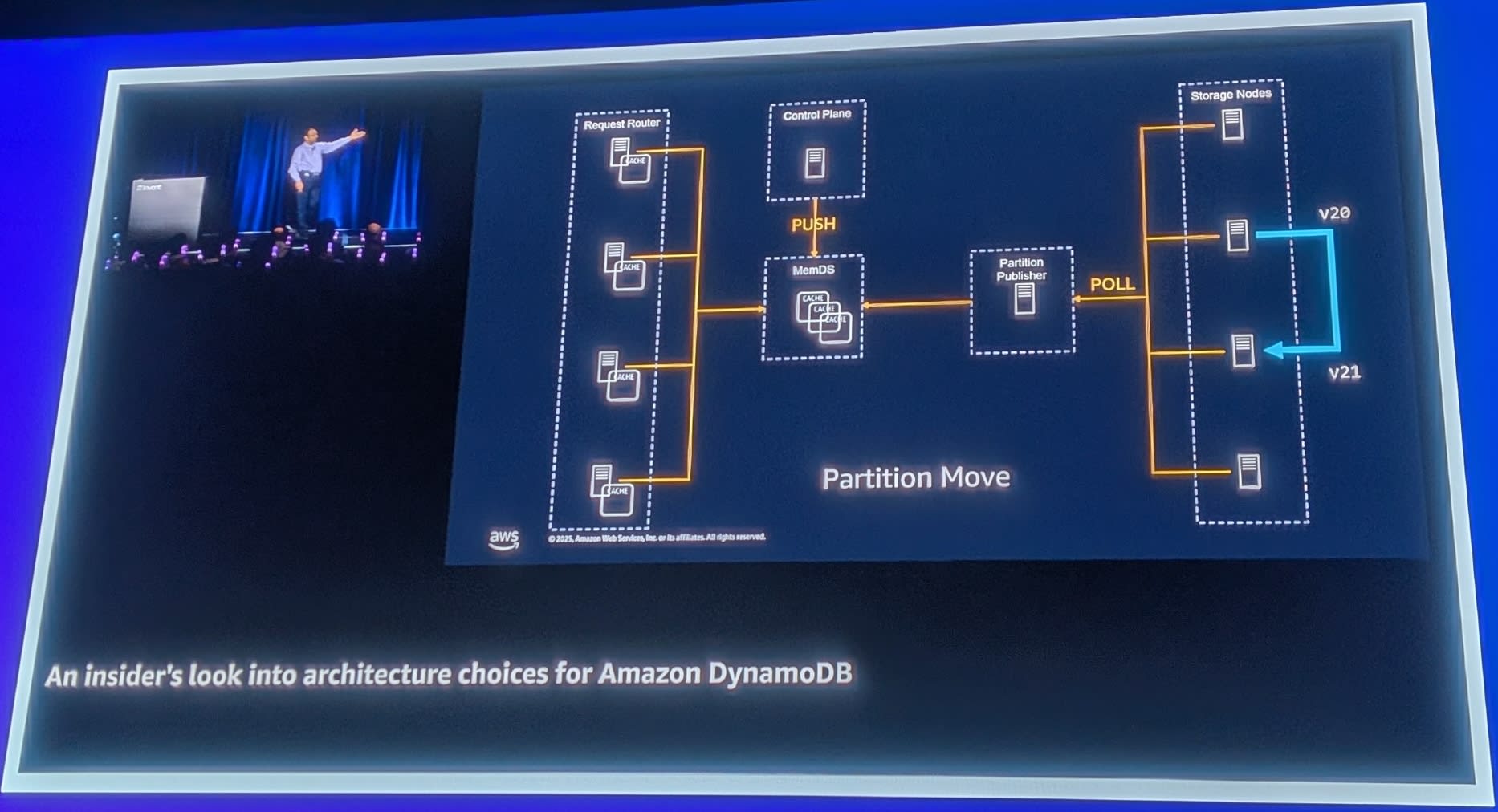
キャッシュは結果整合性(Eventually Consistent)ですが、バージョン番号を使用して整合性を確保しています。
- パーティションが移動するとバージョンが上がる(v20 → v21)
- キャッシュがv20を持っている状態でリクエストが来る
- v20のStorage Nodeにアクセス
- Storage Nodeが「v21に移動したよ」と応答
- リクエストを正しいノードにリダイレクト
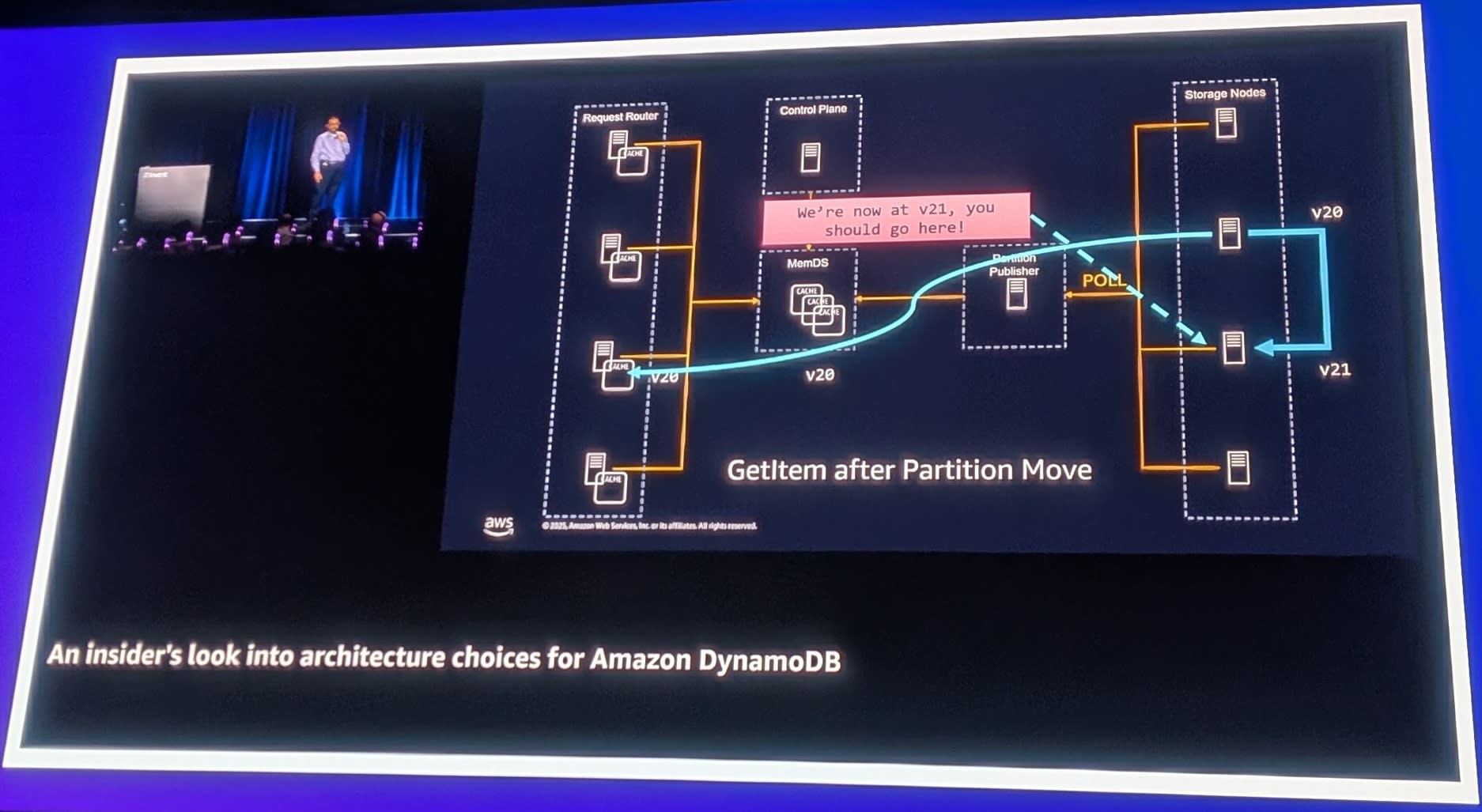
Authority(権威) はStorage Nodesにあります。Storage Nodesは自分がどのパーティションを持っているかを正確に知っています。キャッシュが古くても、最終的には正しい場所にルーティングされます。
Hedging(ヘッジング)
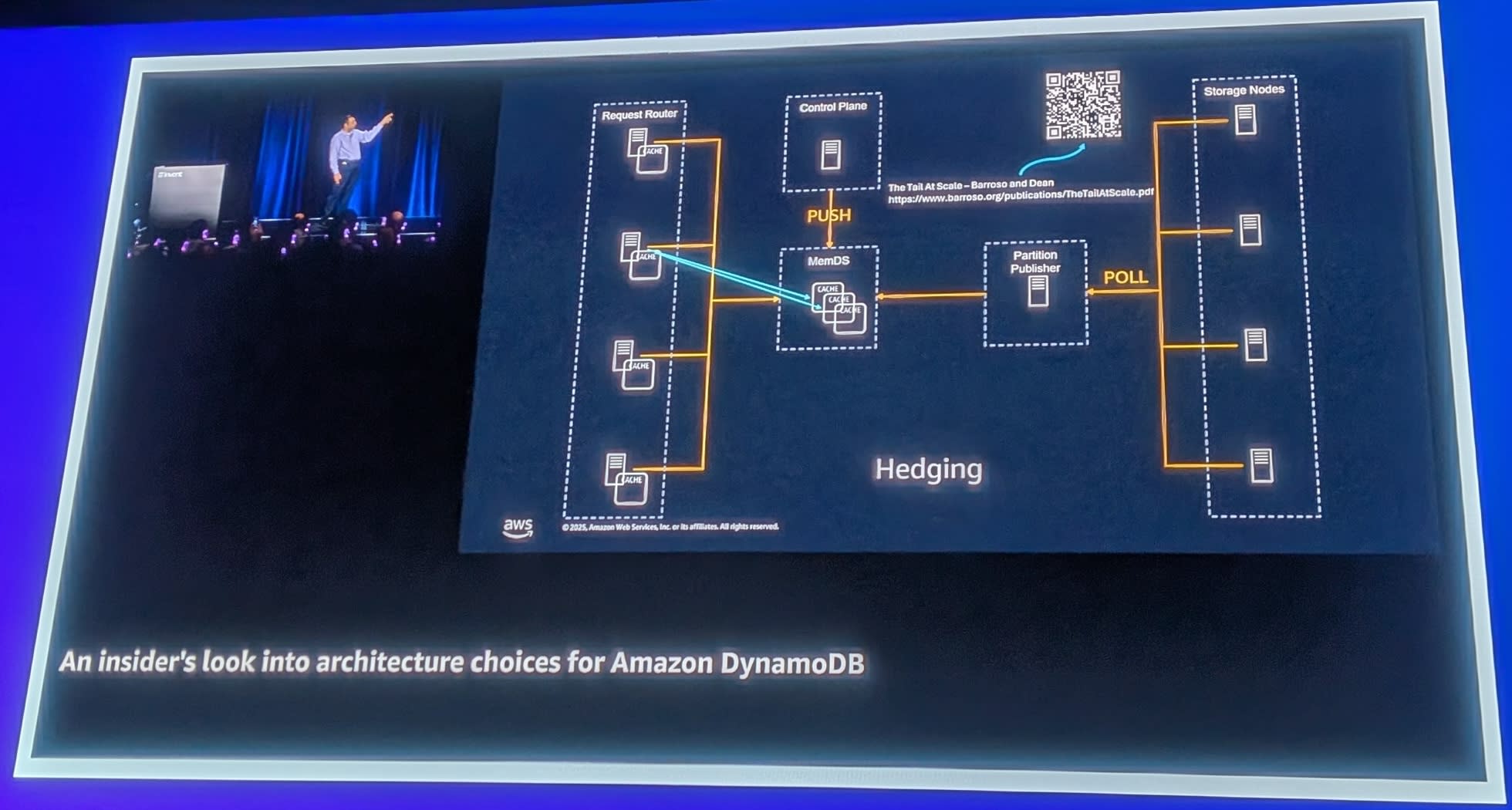
予測可能な低レイテンシを実現するため、DynamoDBはHedgingという技術を使用しています。
キャッシュミス時、1つではなく2つのMemDSサーバーに同時にリクエストを送信します。レイテンシが正規分布に従う場合、2つのリクエストを送ると統計的に1つは中央値より速く返ってきます。最初に返ってきた応答を使用することで、テールレイテンシを削減できます。
Constant Work(コンスタントワーク)
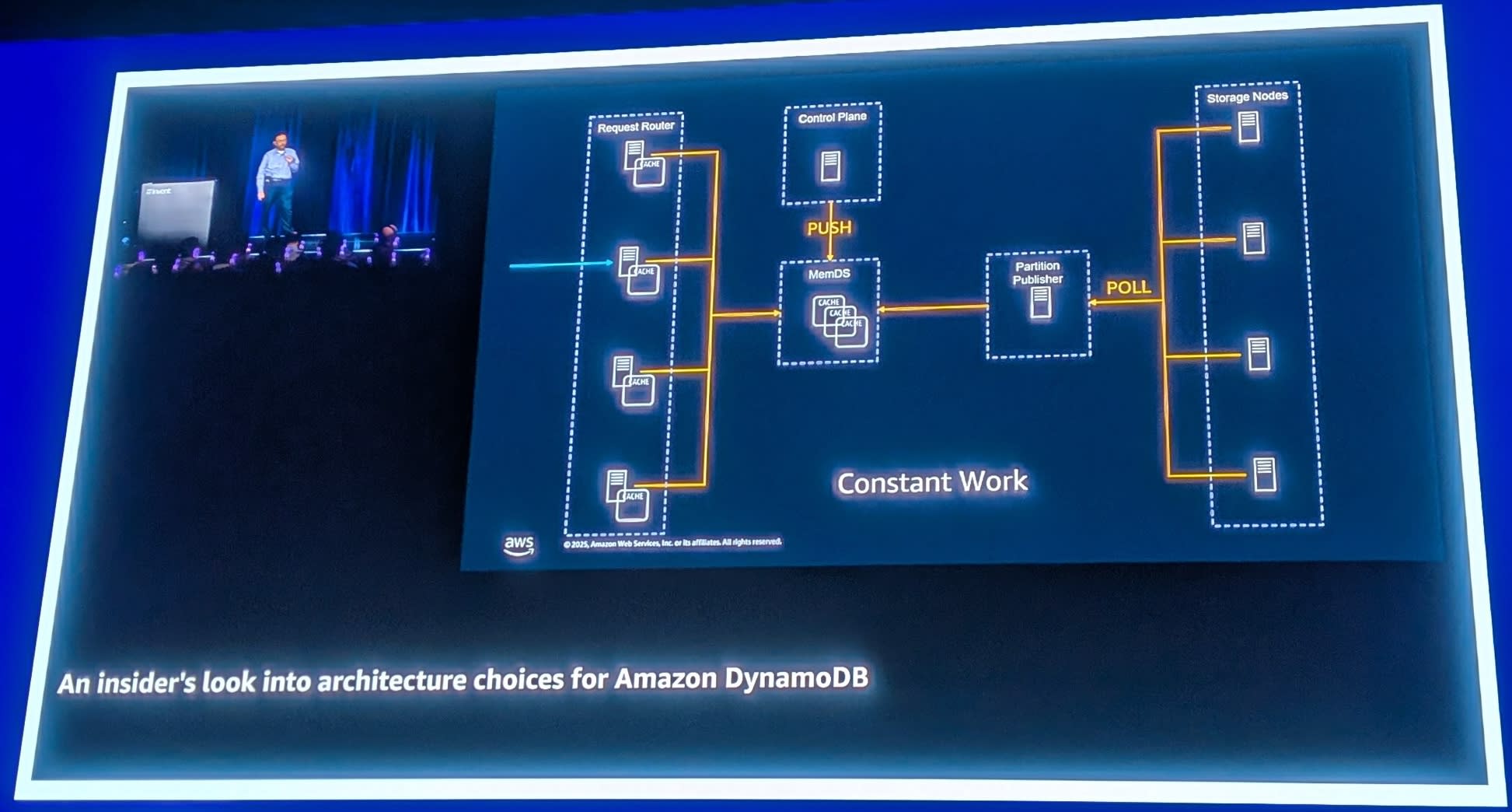
さらに、DynamoDBはConstant Workパターンを採用しています。
キャッシュヒット時でも、バックグラウンドで2つのMemDSサーバーにリクエストを送信します。
なぜか?すべてのキャッシュが同時にコールドになった場合を想像してください。突然、MemDSへのトラフィックが爆発的に増加します。
Constant Workにより、MemDSは常に一定量のトラフィックを受け取っています。キャッシュがコールドになっても、MemDSから見たトラフィック量は変わりません。これにより、Large Fleet - Small Fleet問題による障害を防止しています。

DynamoDBの制限とその理由
パーティション制限

DynamoDBには以下のパーティションレベル制限があります。
- 1,000 WCU(Write Capacity Units)
- 3,000 RCU(Read Capacity Units)
これらの制限は予測可能な低レイテンシを保証するために存在します。物理ハードウェアには限界があり、共有インフラストラクチャ上で他の顧客に影響を与えないためです。
IOPS Dilution問題(過去の話)
昔のDynamoDBでは、テーブルをパーティション分割すると、プロビジョンドスループットも分割されていました(IOPS Dilution)。現在はこの問題は解消されており、パーティションが分割されても各パーティションは同じ制限値を持ちます。
パーティション数は無意味な指標
「テーブルのパーティション数」を知りたがる顧客がいますが、これは以下の理由から意味のない指標です。
- 各パーティションのキー範囲は均等ではない
- 実際に知りたいのは「最初にスロットリングされるパーティションはどれか」
そこで導入されたのがWarm Throughput機能です。
Warm Throughput
Warm Throughputは、テーブルがスロットリングなしで処理できるスループットを確認する機能です。大規模なセール(Cyber Mondayなど)の前に、テーブルの準備状況を確認できます。
トランザクション制限

DynamoDBのトランザクションには以下の特徴があります。
- Read-onlyとWrite-onlyの2種類
- One-shot: すべてのアイテムを一度に指定(BEGIN-ENDではない)
- Serializable isolationを提供
- 標準的な2フェーズコミットを使用(読み取りは最適化)

- トランザクションアイテム数の制限
- ローンチ時: 25アイテム
- 現在: 100アイテム
なぜ制限があるのか?
- トランザクション内のアイテム数が増えると、競合の確率が上がる
- 競合が増えると、可用性が下がり、レイテンシが上がる
- 予測可能な低レイテンシを維持するための制限
One-shotトランザクションのメリット:「トランザクションを開始してコーヒーを飲みに行く」ような状況が発生しない。
その他の制限
| 制限項目 | 値 | 理由 |
|---|---|---|
| アイテムサイズ | 400 KB | 共有インフラストラクチャでの公平性、予測可能なレイテンシ |
| GSI数 | 20(ローンチ時は5) | レプリケーションラグの予測可能性 |
顧客向けベストプラクティス
セッションの最後に、顧客が予測可能な低レイテンシを得るためのベストプラクティスが紹介されました。
コネクションプールの適切なサイズ設定
DynamoDBは以下をキャッシュしています。
- 認証情報(Identity credentials)
- テーブルメタデータ
新しい接続ごとに新しいRequest Routerに接続される可能性があり、キャッシュのメリットを受けられません。
- 推奨事項
- 長寿命のコネクションを使用
- トラフィック量に応じてコネクションプールサイズを調整
- 低トラフィック時は小さなコネクションプール
- 高トラフィック時は大きなコネクションプール
リクエストのヘッジング
アプリケーション側でもHedgingを活用できます。
- 読み取り: Eventually Consistent Readで2つのリクエストを送信、最初の応答を使用
- 書き込み: 冪等性を確保した上で2つのリクエストを送信
タイムアウトを長くするのではなく、Hedgingで予測可能なレイテンシを実現しましょう。
まとめ「なぜDynamoDBなのか?」
本セッションで解説されたアーキテクチャの選択により、DynamoDBは以下を実現しています。
| 特徴 | 実現方法 |
|---|---|
| Security | 常時暗号化、SIGv4認証 |
| Durability | 2 AZへの書き込み確認後にコミット |
| Availability | 3 AZへのレプリケーション、Multi-Paxosコンセンサス |
| Predictable Low Latency | キャッシュ、Hedging、Constant Work、制限による保護 |
すべての設計判断は、4つのテネットに基づいています。
顧客から「なぜこうなっているのか?」と聞かれたら、答えはおそらくこの4つのどれかに当てはまるとのことでした。
さいごに
以上、「An insider's look into architecture choices for Amazon DynamoDB」のセッションレポートでした。
普段何気なく利用しているDynamoDBですが、その裏側で分散システムの設計における難しさと、それをどのように解決してきたを知るいい機会になりました。
個人的には特に以下のポイントが印象的でした。
- テネット駆動の意思決定
- Security、Durability、Availability、Predictable Low Latencyという明確な優先順位
- Constant Work
- キャッシュヒット時でもバックエンドに一定負荷をかけ続けることで、障害を防ぐ
- Large Fleet - Small Fleet問題への対処
- 大規模システムならではの課題と解決策
- トランザクションがOne-shotである理由
- 予測可能性のためのトレードオフ
またこれらのDynamoDBのアーキテクチャ選択は、自身のアプリケーション設計においても参考になると思います。
「テネットを明確にし、チーム全体で共有することで、分散した意思決定を可能にする」というアプローチは、サービス開発だけでなく組織運営にも応用できそうですね。
この記事が誰かのお役に立てば幸いです。








