![[レポート] 実際のAWSアーキテクチャにおける3つの失敗事例と教訓を学んできました #AWSreInvent #DEV341](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] 実際のAWSアーキテクチャにおける3つの失敗事例と教訓を学んできました #AWSreInvent #DEV341
はじめに
皆様こんにちは、あかいけです。
AWS re:Invent 2025に参加しており、
「Architecture lessons: Three failures and how to prevent them」というセッションを聞いてきました。
アーキテクチャ設計において、失敗から学ぶことほど価値のある教訓はないのではないでしょうか。
このセッションでは、実際のAWSアーキテクチャにおける3つの失敗事例を取り上げ、何が問題だったのか、ビジネスへの影響、そしてどのように修正したのかを解説してくれました。
「他人の失敗から学ぶ」という非常に実践的なセッションだったので、その内容をまとめてみました。
セッション概要
タイトル
Architecture lessons: Three failures and how to prevent them (DEV341)
概要
Some of the best lessons come from failures - but it's better to learn from someone else's. In this session we will dissect three real-world AWS architecture failures, exploring what went wrong, the business impact, and how they were fixed. You'll learn the patterns and anti-patterns behind each case, and walk away with actionable insights to avoid similar pitfalls in your own mission-critical workloads.
最高の教訓は失敗から得られますが、他人の失敗から学ぶ方が良いでしょう。このセッションでは、3つの実際のAWSアーキテクチャの失敗事例を分析し、何が問題だったのか、ビジネスへの影響、そしてどのように修正されたのかを探ります。各ケースの背後にあるパターンとアンチパターンを学び、ミッションクリティカルなワークロードで同様の落とし穴を避けるための実用的な洞察を得ることができます。
スピーカー
- Bruno Marangoni (Latam Senior Solutions Architect, DXC Technology)
セッション情報
- レベル: 300 - Advanced
- セッションタイプ: Lightning talk
- トピック: Architecture

セッション内容
アジェンダ
セッションは以下の構成で進められました。
- Introduction
- Failure case 1 - Resilience (レジリエンス)
- Failure case 2 - Security + Operational excellence (セキュリティと運用の卓越性)
- Failure case 3 - Multi-account + Cost efficiency (マルチアカウントとコスト効率)
- Final thoughts

「Real architectures, real failures, real lessons」(実際のアーキテクチャ、実際の失敗、実際の教訓)というテーマで、実例に基づいた内容が紹介されました。

Failure Lesson 1 - Resilience(レジリエンス)
アーキテクチャの概要
最初の事例は、ブラジルのECサイトを運営する企業の3層Webアプリケーションでした。

- ブラジルのE-commerceフルフィルメント会社
- 2つの主要モバイルキャリア企業のECサイトをホスト(iPhone、Motorola、アクセサリーなどを販売)
- 平均3,000リクエスト/日
- 基本的な3層アプリケーション(ロードバランサー、Web層/アプリ層、データベース)
理想的な3層アプリ
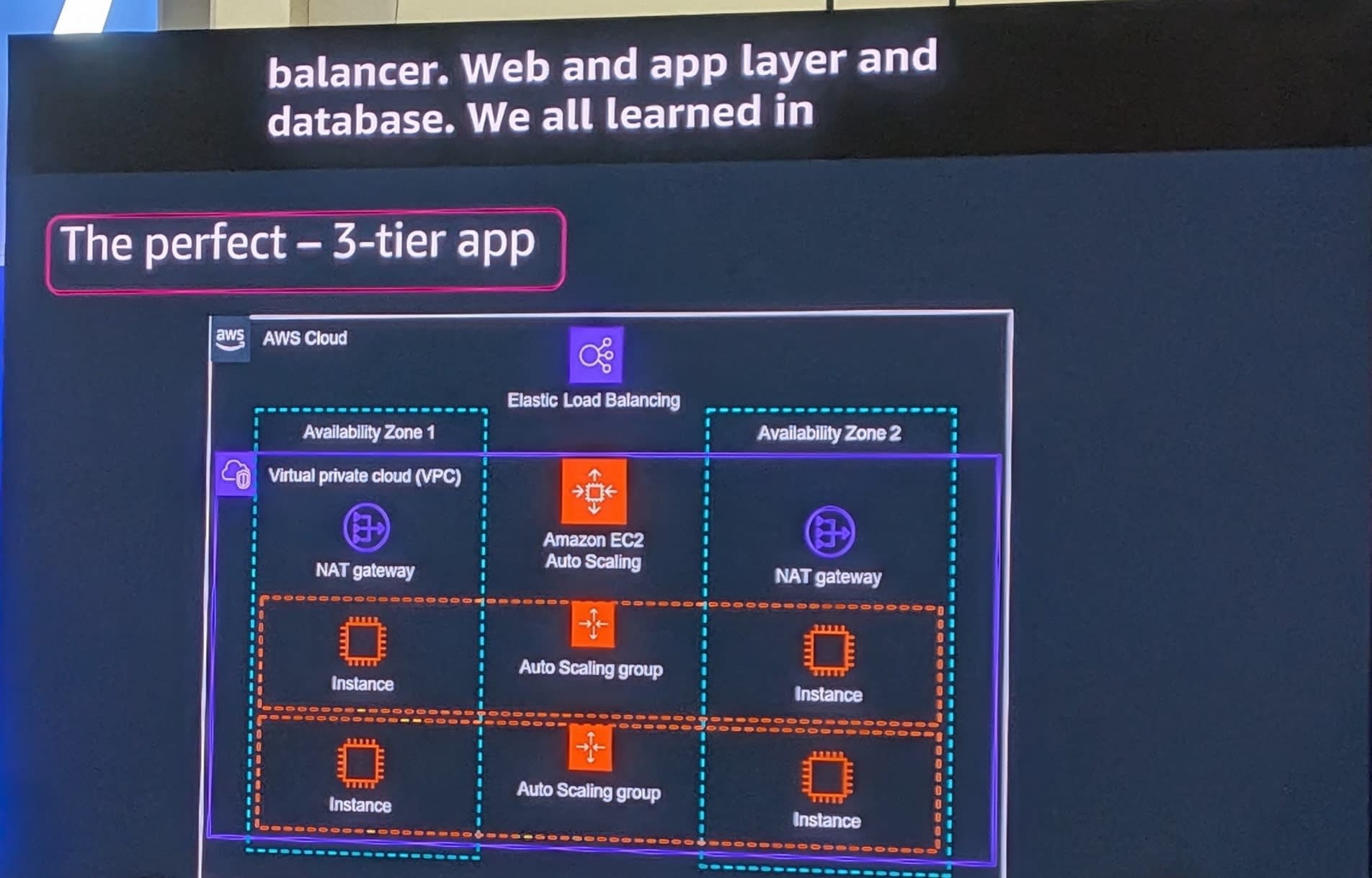
皆さんが学んできた「理想的な3層アプリ」はこのような構成です。
- Elastic Load Balancing
- 2つのAvailability Zone(AZ)にまたがるVPC
- 各AZにNAT Gateway
- Auto Scaling groupによるEC2インスタンス
- Multi-AZのデータベース
実際の3層アプリ(問題点)
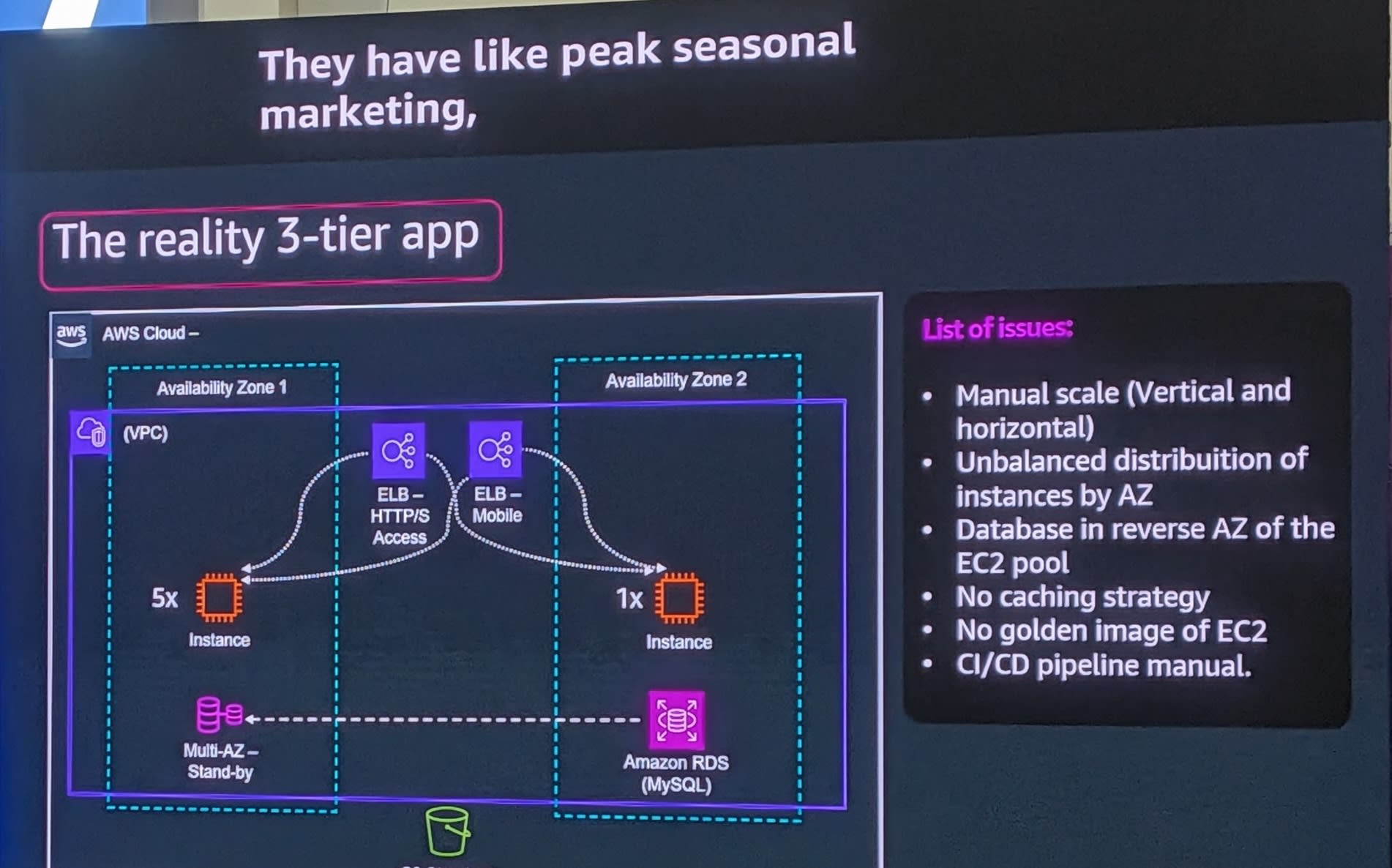
しかし、実装した実際のアーキテクチャには多くの問題がありました。
- Manual scale (Vertical and horizontal) - 手動スケーリング(ブラックフライデーなどの季節キャンペーン時に手作業でスケール)
- Unbalanced distribution of instances by AZ - AZ間でインスタンスが不均衡(AZ1に5台、AZ2に1台)
- Database in reverse AZ of the EC2 pool - データベースがEC2プールと逆のAZに配置(約20ミリ秒のレイテンシが発生)
- No caching strategy - キャッシュ戦略なし(モバイル販売なので大量の商品画像がある)
- No golden image of EC2 - EC2のゴールデンイメージなし(新規インスタンス追加時に毎回手動で依存関係をインストール)
- CI/CD pipeline manual - CI/CDパイプラインが手動
改善後のアーキテクチャ
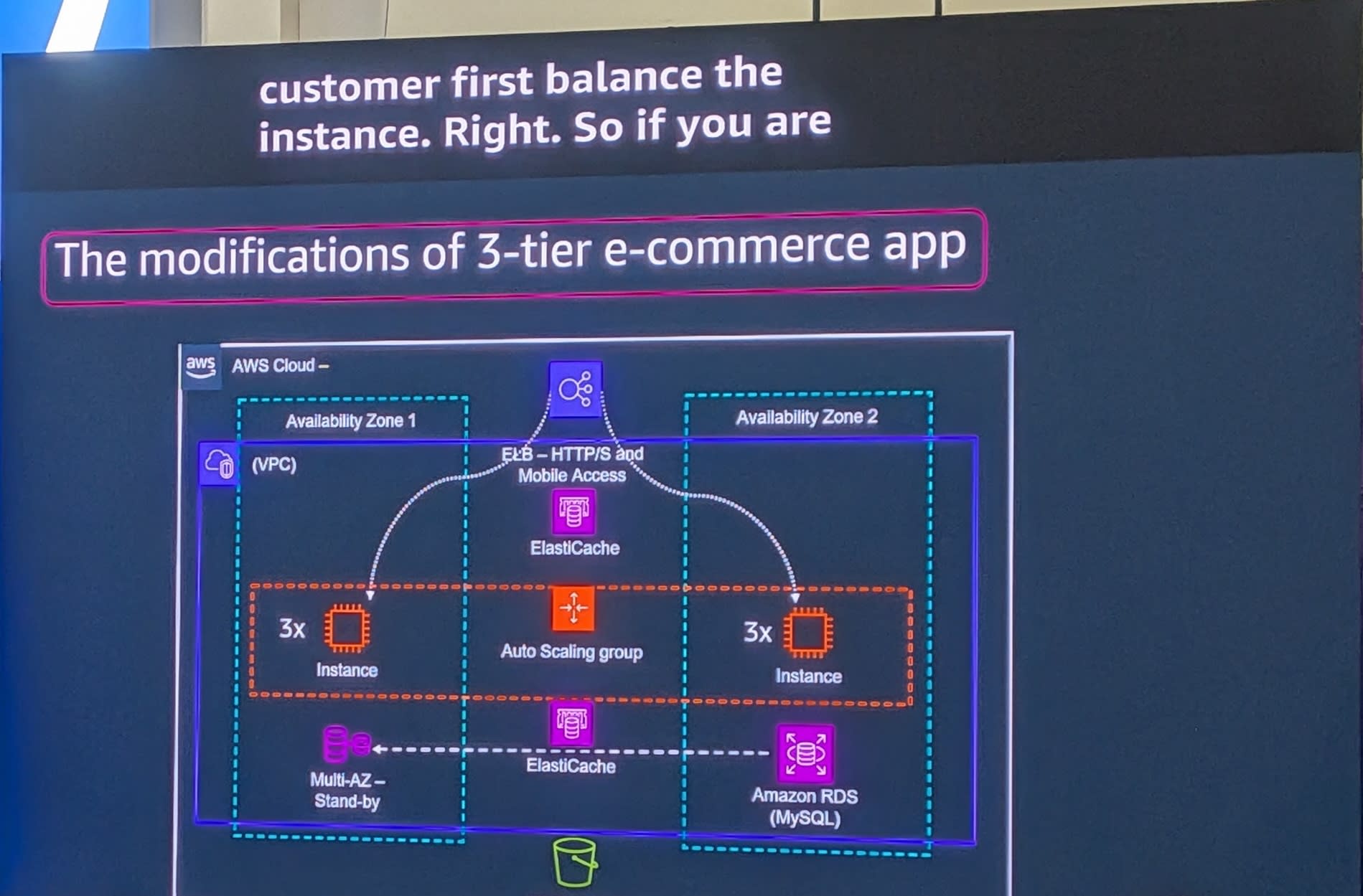
この問題を解決するために、以下の改善を行いました。
- ElastiCacheの追加(Web層とDB層の両方) - 商品画像のキャッシュとDBクエリ結果のキャッシュ
- CloudFrontの追加 - S3に格納された商品画像の配信高速化
- ELBの統合(6台のロードバランサーを統合し、コスト削減)
- Auto Scaling groupの導入
- AZ間でのインスタンスのバランス調整(各AZに3台ずつ)
- プライマリRDSをインスタンス数の多いAZに移動
結果として、キャッシュ戦略の導入により、顧客がWebサイトにアクセスする際のレスポンスタイムが約80ミリ秒短縮されました。
Failure Lesson 1 - 修正内容
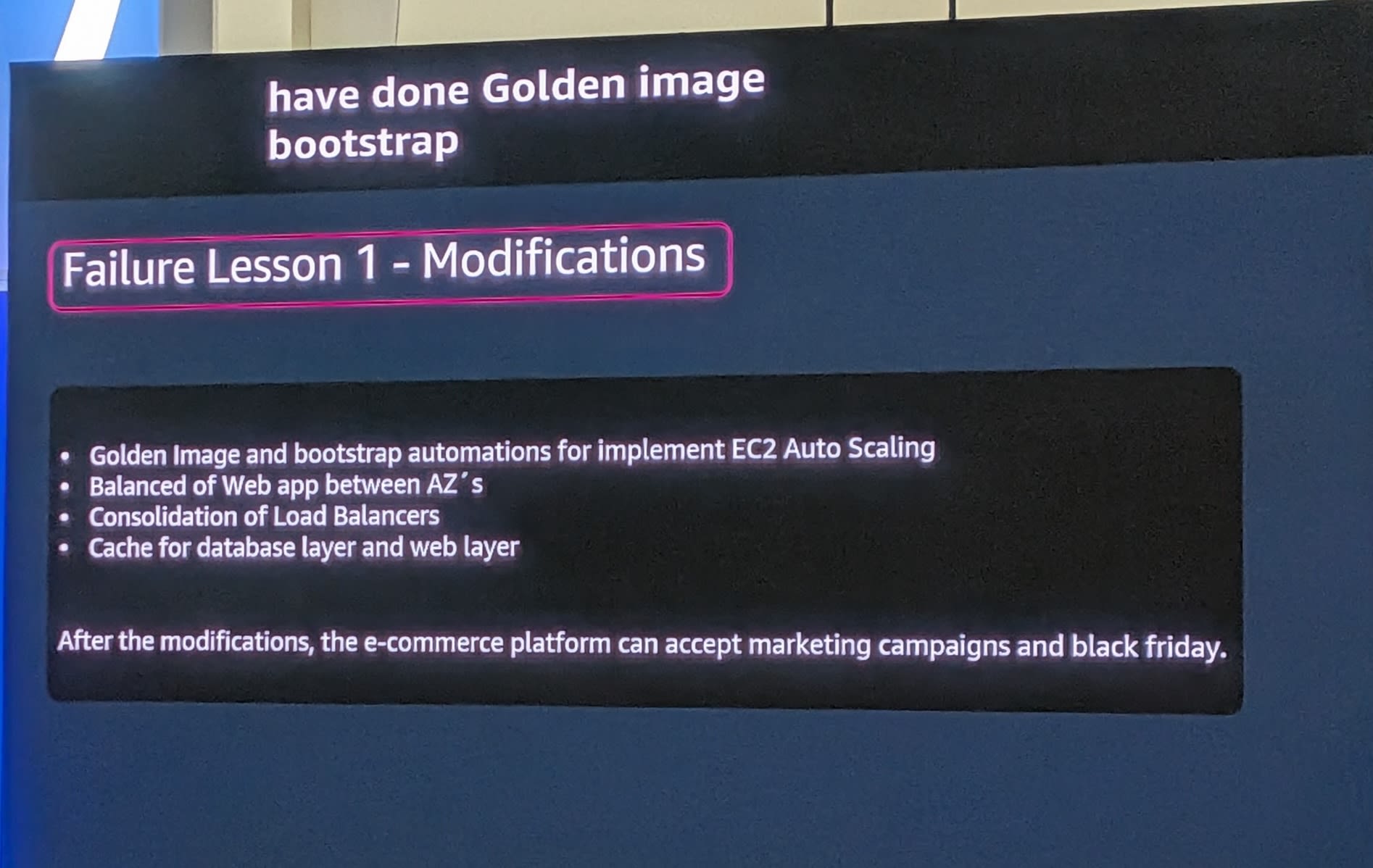
- Golden Imageとbootstrap自動化でEC2 Auto Scalingを実装
- AZ間でのWebアプリのバランス調整
- ロードバランサーの統合
- データベース層とWeb層にキャッシュを追加
After the modifications, the e-commerce platform can accept marketing campaigns and black friday.
(修正後、このE-commerceプラットフォームはマーケティングキャンペーンやブラックフライデーにも対応できるようになりました。)
実は修正前、iPhone 14発売時のブラックフライデーでこのサイトはダウンしてしまいました。
ブラジルで最大手の2社がiPhoneを販売するサイトがダウンしたことで、かなりの損失が発生したとのことです。
その失敗を受けて、上記の改善が行われました。
エンジニアチームは当初「North Virginiaの6つのAZすべてに分散させよう」と提案しましたが、1日3,000リクエスト程度のトラフィックにはそこまでの分散は必要ないというトレードオフの判断がなされました。
Failure Lesson 1 - 教訓

"Availability is an architectural decision, not a checkbox. Do your trade offs!"
(可用性はアーキテクチャ上の決定であり、チェックボックスではありません。トレードオフを検討しましょう!)
Failure Lesson 2 - Security + Operational Excellence
アーキテクチャの概要
2つ目の事例は、大手銀行のEKSアプリケーションでした。

- エンタープライズ銀行のミッションクリティカルなワークロード
- 顧客サービスプラットフォームとしてEKSを運用
- EKSクラスターでミッションクリティカルなワークロードを実行
- Security Hubを有効化(CIS + Foundational Security Best Practices)
- アラートは生成されたが、無視されていた
- バージョンアップデートが数ヶ月遅延
問題の発生
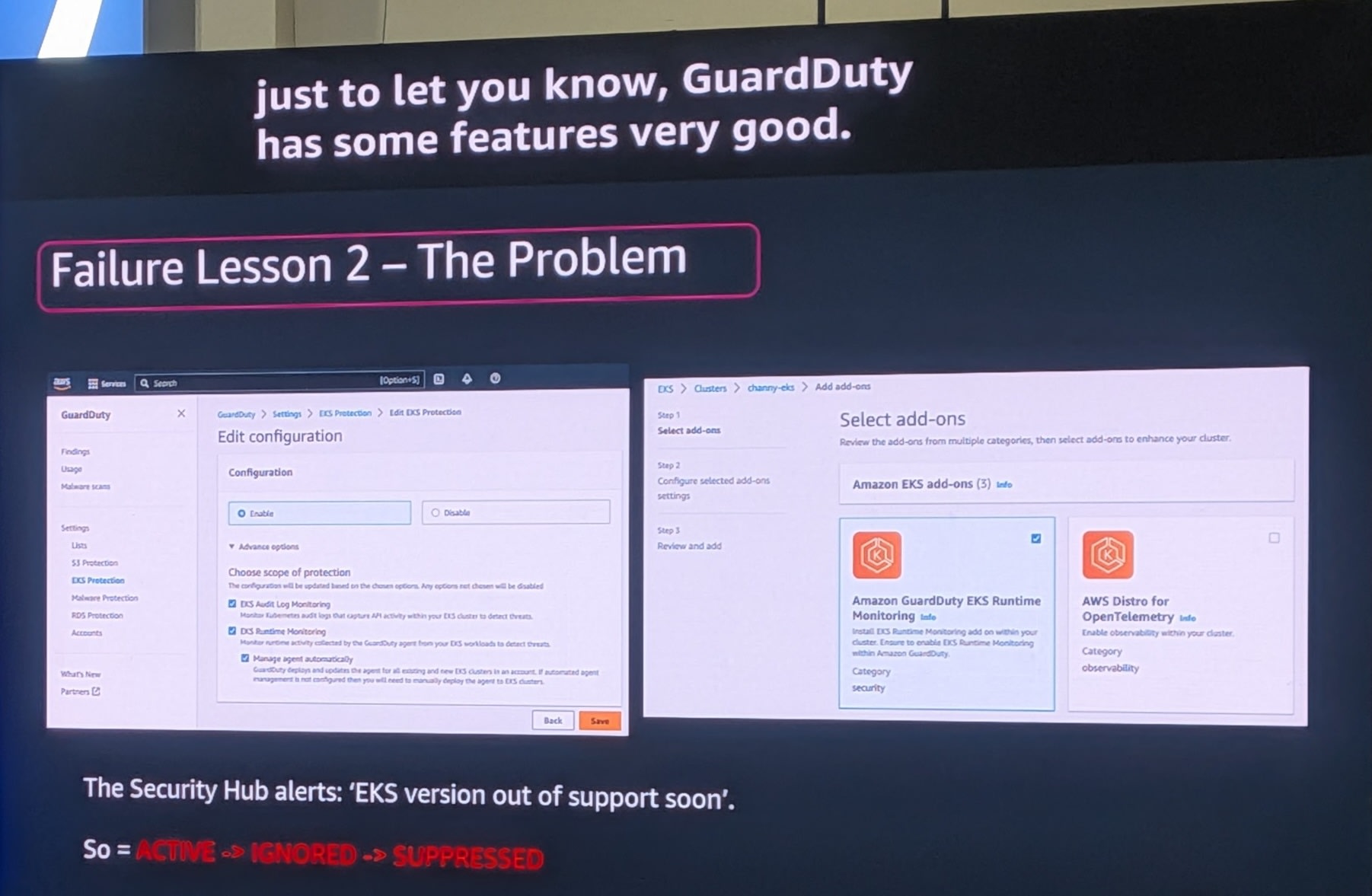
Security Hubから「EKS version out of support soon」(EKSバージョンのサポート終了間近)というアラートが発生しましたが、対応が遅れました。
- アラートの状態遷移
ACTIVE→IGNORED→SUPPRESSED
ここで重要なのは、DevSecOpsサイクルでサイロを壊すための仕組みは整っていたものの、プラットフォームチームとセキュリティチームの間のコミュニケーションがうまくいっていなかったという点です。
プラットフォームチームはアラートを抑制していましたが、セキュリティチームには伝えていませんでした。
そしてある日、セキュリティチームが「このアラートが頻繁に出るなら、EKSをアップグレードしよう」と判断し、アプリケーションの互換性を検証せずにアップグレードを実行してしまいました。
事前に、GuardDutyのEKS Protection機能や、EKS add-ons(Amazon GuardDuty EKS Runtime Monitoring、AWS Distro for OpenTelemetryなど)の活用も検討すべきでした。
期限切れの結果
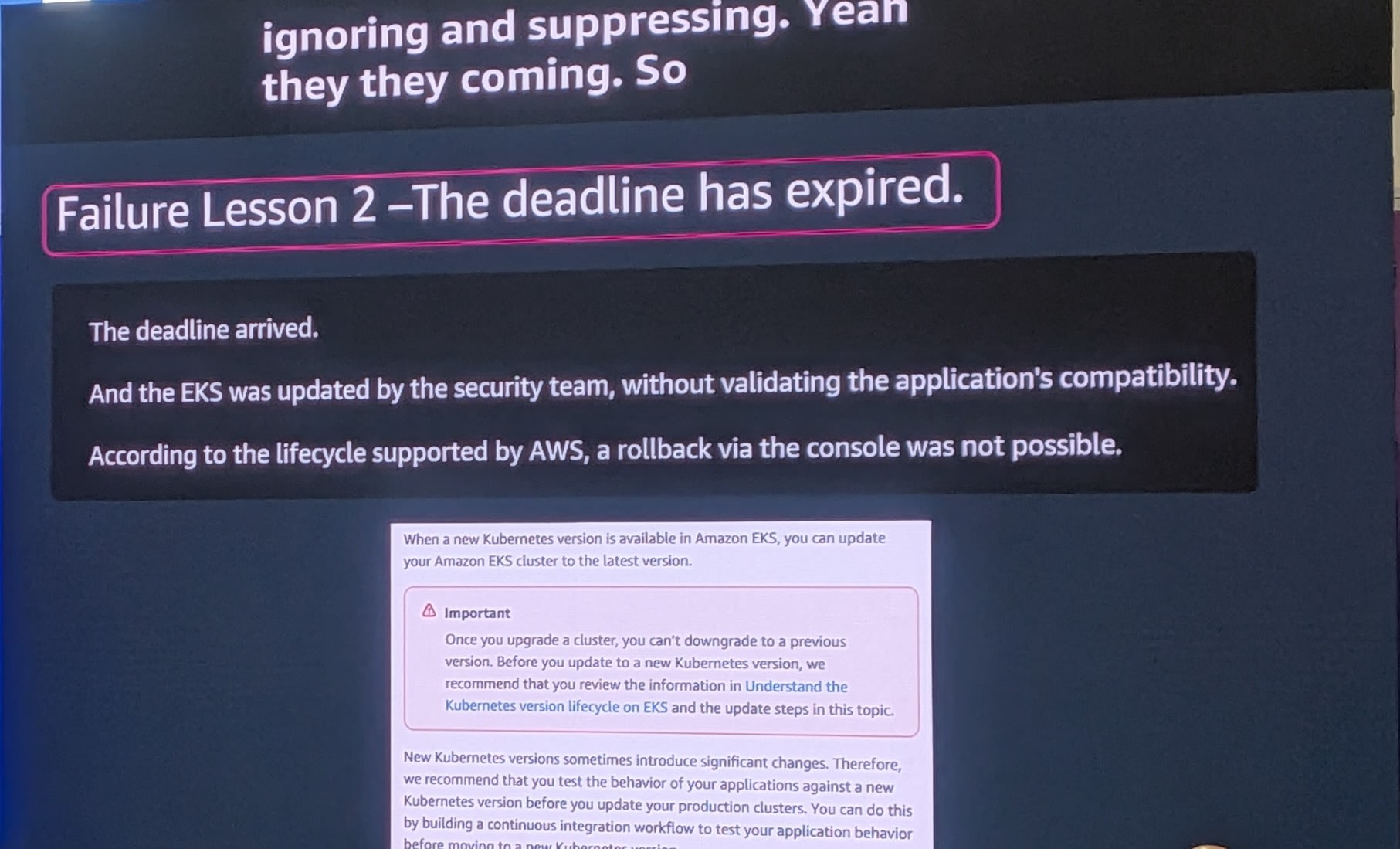
The deadline arrived. (期限が到来しました)
- セキュリティチームがアプリケーションの互換性を検証せずにEKSをアップデート
- AWSのライフサイクルサポートにより、コンソールからのロールバックが不可能に
Important
Once you upgrade a cluster, you can't downgrade to a previous version. Before you update to a new Kubernetes version, we recommend that you review the information in Understand the Kubernetes version lifecycle on EKS and the update steps in this topic.
ドキュメントには「ダウングレードできない」と書かれていますが、スピーカーによると、AWS Partner経由でサポートに連絡することで、クラスターのダウングレードを支援してもらえたとのことです。
結果的にクラスターを復旧させ、アプリケーションを再稼働させることができました。
どうすれば防げたか?

EKS Version Validation Pipeline:
- Preview environment (mirrored staging)
- kube-score / conftest / pluto for API checks
- Cluster upgrade plan with dry-run
- Infrastructure-as-Code with version pinning (Terraform/eksctl)
Governance:
- Security Hub findings → mandatory responses
- SLA for remediation of critical findings
- Review routines by the platform team
Architecture:
- Blue/green EKS cluster upgrade
- Version-tolerant workloads
- Critical components managed via GitOps
Root Cause
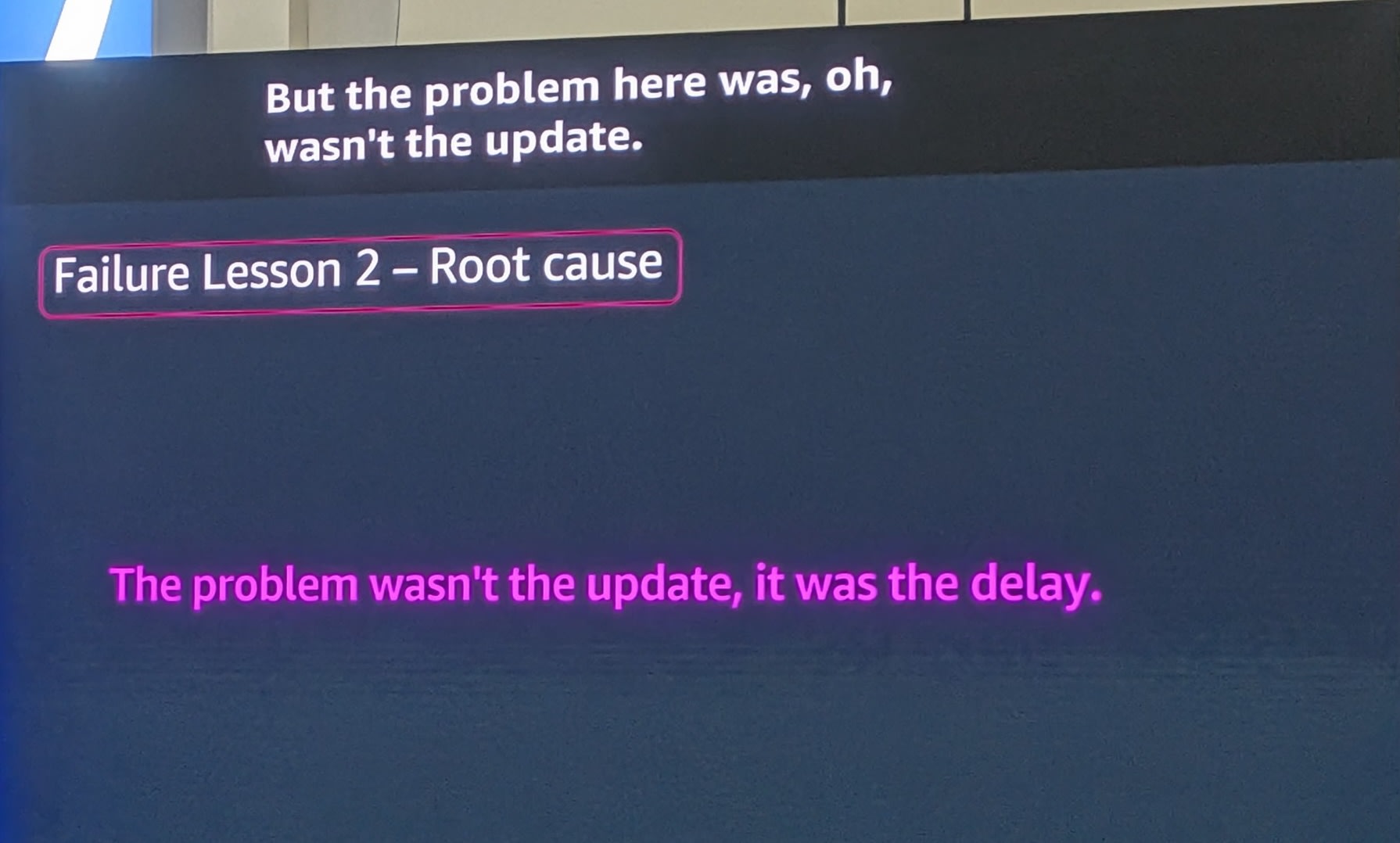
"The problem wasn't the update, it was the delay."
(問題はアップデートではなく、遅延でした。)
ガバナンス、プロセス、アーキテクチャはすべて整っていました。真の問題は、プラットフォームチームとセキュリティチームがアップグレードの計画について話し合い、日程を調整しなかったことでした。
Failure Lesson 2 - 教訓

"Architectures fail when processes fail. Technology is predictable, humans are not."
(アーキテクチャはプロセスが失敗したときに失敗します。テクノロジーは予測可能ですが、人間はそうではありません。)
6 hours of downtime resulted in a loss of R$1.2 million and some SLA agreement penalties.
(6時間のダウンタイムにより、120万レアル(約USD 200,000〜250,000)の損失とSLA違反によるペナルティが発生しました。)
スピーカーは「金額そのものよりも、銀行であるが故のSLA契約違反によるペナルティの方が重大だった」と強調していました。
Failure Lesson 3 - Multi-Account & Cost Efficiency
アーキテクチャの概要
3つ目の事例は、クラウドへの移行ジャーニーを進めている企業でした。
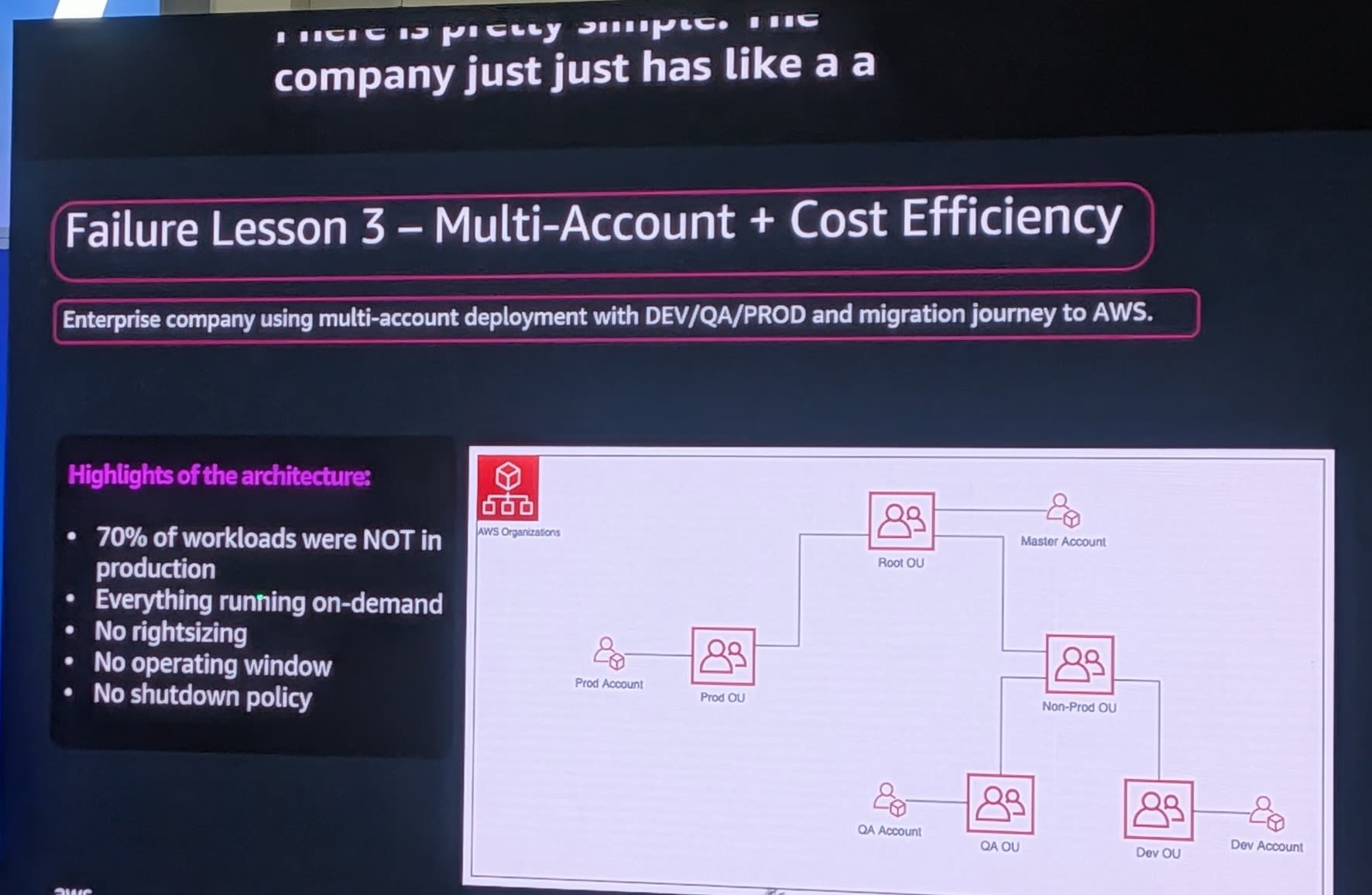
- DEV/QA/PRODのマルチアカウントデプロイメント
- AWS Organizationsによる管理
- 70% of workloads were NOT in production - ワークロードの70%が本番環境ではない(DEV、QA環境)
- Everything running on-demand - EC2、EKS、ECS、RDSすべてがオンデマンドで稼働
- No rightsizing - ライトサイジングなし
- No operating window - 運用時間枠なし
- No shutdown policy - シャットダウンポリシーなし
Dev環境をProdと同等に扱う問題

The company treated all environments as production SLA, even when they weren't.
(企業はすべての環境を本番SLAとして扱っていました。たとえそうでなくても。)
- EC2 on-demand
- EKS on-demand
- RDS Multi-AZ for Dev
- ECS on-demand
- No shutdown automation
- No control over working hours
The Dev environment was on the same SLA, and at the same cost, as Production.
(Dev環境は本番環境と同じSLAで、同じコストでした。)
なぜこうなったのか?

- Lack of FinOps governance - FinOpsガバナンスの欠如
- Fear of shutting down the environment - 環境をシャットダウンすることへの恐怖(明確なポリシーがないと誰も止める決断ができない)
- Team without clear policies - 明確なポリシーのないチーム
- Lack of standardized tags - 標準化されたタグの欠如(コストを誰が負担しているか分からない)
- Communication failure between teams - チーム間のコミュニケーション不足
スピーカーは「誰もコストを気にしない。みんな欲しいものだけを欲しがる」と指摘していました。
コスト削減効果

適切な対策を講じた結果、大幅なコスト削減を実現しました。
Direct savings:
- R$ 60,000 per month ($USD 11,000.00)
- (EC2 + RDS + EKS + ECS On-Demand reduced)
Annual savings:
- R$ 60,000 x 12 = R$ 720,000/year ($USD 130,000.00)
効果:
- シニアエンジニア2名分の年間コストに相当する節約
- 本番環境には一切手を加えずに実現
- 運用リスクなし
Second Impact: Culture - 2つ目の効果として、組織文化の変革にもつながりました。スピーカーは「クラウドは弾力的であるべきで、コストもそうあるべきだ」というメッセージを強調していました。
Failure Lesson 3 - 教訓
"The cloud is elastic. Costs should be too."
(クラウドは弾力的です。コストもそうあるべきです。)
Final Thoughts

セッションの最後に、3つの重要なメッセージが示されました。
| メッセージ | 説明 |
|---|---|
| Architectures don't fail because of technology. They fail because of a lack of decisions made before the technology was implemented. | アーキテクチャはテクノロジーのせいで失敗するのではありません。テクノロジーが実装される前に行われるべき決定の欠如によって失敗します。 |
| Warnings don't prevent incidents. Actions prevent incidents. | 警告はインシデントを防ぎません。行動がインシデントを防ぎます。 |
| Without visibility, you don't optimize, you guess. And guessing is expensive. | 可視性がなければ、最適化ではなく推測することになります。そして推測は高くつきます。 |
さいごに
以上、「Architecture lessons: Three failures and how to prevent them」セッションのレポートでした。
20分というLightning Talkでしたが、実際のアーキテクチャ失敗事例から学べる非常に実践的な内容でした。
個人的には特に以下の点が印象的でした。
-
Failure 1 (Resilience)
- 「理想的な3層アプリ」と「実際の3層アプリ」のギャップは、多くの現場で見られる光景ではないでしょうか。可用性はチェックボックスではなく、アーキテクチャ上の決定であるという言葉が刺さりました…。
-
Failure 2 (Security + Operational Excellence)
- Security Hubのアラートを無視し続けた結果、6時間のダウンタイムと120万レアルの損失が発生した事例は衝撃的でした。「問題はアップデートではなく、遅延だった」という指摘は、多くの組織に当てはまるのではないでしょうか。
-
Failure 3 (Cost Efficiency)
- Dev環境を本番環境と同じSLAで運用していた結果、年間13万ドルもの無駄が発生していたケースは、FinOpsの重要性を改めて認識させられました。
そして「警告はインシデントを防がない。行動がインシデントを防ぐ」というメッセージは、すべてのエンジニアが心に留めておくべき教訓だと思います。
皆様のアーキテクチャ設計において、この記事が何かの参考になれば幸いです。









