[レポート] Apache Hudiのテーブル形式の紹介 – Subsurface LIVE Summer 2021
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
米国時間2021年07月21日〜22日の計2日間、オンラインで開催された「Subsurface LIVE Summer 2021」では、主催となるDremio社のサービスやクラウドデータレイクに関する各種サービスやプロダクトのセッションが展開されていました。
当エントリでは、その中から「Introducing the Apache Hudi Table Format」(Apache Hudiのテーブル形式の紹介)というセッションについてレポートします。
目次
セッション概要
セッション概要は以下の通り。
Introducing the Apache Hudi Table Format, Purpose-Built for Low-Latency Data Lake Use Cases
(低遅延データレイクのユースケースのために作られたApache Hudiテーブルフォーマットの紹介)
<登壇者>
Sivabalan Narayanan - Lead for Network Infrastructure @ Uber
Nishith Agarwal - Engineering Manager @ Uber
<発表内容>
Data lakes are one of the fastest-growing trends in managing big data for any organization. Data lakes offer massively scalable data processing over vast amounts of data. Additionally, as businesses have evolved, there have been many more demands of features from data lakes such as the ability to use change-data-capture (CDC) at low latencies to serve business needs, perform data deletions to meet compliance requirements while continuing to ingest new data, and reduce costs of storing and accessing data (and metadata) while at the same time scaling the data infrastructure for business continuity.
Apache Hudi is a data platform technology that provides several functionalities needed to build and manage your own data lake. To provide users with more flexibility, we recently introduced a set of low-level APIs that help to directly program against our table format. In this session, we will describe the Apache Hudi table format that is designed to improve canonical table layouts that are popularly used to build modern data lakes. We will discuss the data and metadata layout of Hudi tables that realize primitives such as upserts, deletes and incremental pulls. We will go over ways to access Hudi timeline (a sequential audit log of actions performed on the table) to assist in monitoring and managing the pipelines and tables. We will dive into Hudi’s concurrency models and how Apache Hudi’s table format also supports lock-free concurrent writing from multiple applications.
As datalake ecosystem evolves, table services are becoming an integral part of an efficient data lake architecture. This involves services such as cleaning and compaction for efficient storage management of data and metadata, data clustering for intelligent and dynamic re-clustering of data for better storage management and faster query times. We will talk about how compaction policy/scheduling and dynamic data clustering can be used with out-of-the-box solutions or can be plugged in based on one’s needs to get the best out of their Hudi tables. Similarly, locking services for multi-writer support can be plugged in if some users have their own lock service for all data infrastructure in their organization. To conclude, we will discuss our ongoing efforts to add column indexes to the table format to assist in trimming down the read latency with commonly predicated columns.
(データレイクは、あらゆる組織のビッグデータ管理において、最も急速に成長しているトレンドの一つです。データレイクは、膨大な量のデータに対して大規模なスケーラビリティを持ったデータ処理を実現します。また、ビジネスの進化に伴い、データレイクに求められる機能も多くなっています。例えば、ビジネスニーズを満たすために低レイテンシーでCDC(Change-Data-Capture)を使用する機能、新しいデータを取り込み続けながらコンプライアンス要件を満たすためにデータを削除する機能、データ(およびメタデータ)の保存およびアクセスにかかるコストを削減すると同時に、事業継続のためにデータインフラを拡張する機能などがあります。
Apache Hudiは、独自のデータレイクを構築・管理するために必要ないくつかの機能を提供するデータプラットフォーム技術です。より柔軟性を提供するために、私たちは最近、私たちのテーブル形式に対して直接プログラムするのに役立つ低レベルAPIのセットを導入しました。このセッションでは、最新のデータレイクを構築するために一般的に使用されている正規のテーブルレイアウトを改善するために設計されたApache Hudiのテーブルフォーマットについて説明します。アップサート、デリート、インクリメンタルプルなどのプリミティブを実現するHudiテーブルのデータとメタデータのレイアウトについて説明します。パイプラインとテーブルの監視と管理を支援するために、Hudiタイムライン(テーブル上で実行されたアクションの連続した監査ログ)にアクセスする方法を説明します。Hudiの同時実行モデルと、Apache Hudiのテーブルフォーマットが、複数のアプリケーションからのロックフリーの同時書き込みをどのようにサポートしているかを説明します。
データレイク・エコシステムの進化に伴い、テーブル・サービスは効率的なデータレイク・アーキテクチャに不可欠な要素となっています。これには、データとメタデータの効率的なストレージ管理のためのクリーニングとコンパクション、ストレージ管理の改善とクエリ時間の短縮のためのデータのインテリジェントでダイナミックな再クラスタリングのためのデータクラスタリングなどのサービスが含まれます。ここでは、コンパクションポリシー/スケジューリングやダイナミックデータクラスタリングが、すぐに使えるソリューションとしてどのように使われるのか、また、Hudiテーブルを最大限に活用するためのニーズに応じてどのようにプラグインされるのかについて説明する。同様に、マルチライターサポートのためのロックサービスは、組織内のすべてのデータインフラストラクチャのために独自のロックサービスを持っているユーザーがいれば、プラグインすることができます。最後に、テーブルフォーマットにカラムインデックスを追加して、一般的に予測されるカラムの読み取りレイテンシを削減するための我々の継続的な取り組みについて説明します。)
セッションレポート
ここからはセッションレポートとなります。それぞれのトピックに関して要点をまとめる形で紹介。

アジェンダ
- Hudi概要
- Hudiのテーブル形式
- テーブル形式(Hive → Hudi)
- テーブル形式の主な構成要素
- デザインの選択
- 今後の展開
Hudi概要
- 2017年にオープンソース化
- データレイクにおける幾つかの要件を解決
- インクリメンタルな処理アーキテクチャを導入
- 全ては基礎となる「Hudi Table Format」によって実現されている
- 低レイテンシのデータレイクのニーズに対応
Hudi Data Lake
- トランザクション型データレイクの先駆者
- DFS上の埋込み型、サーバレス、分散型データベースの抽象化層
- HadoopのUPSERT、DELETE & インクリメンタル
- トランザクションによる更新・削除を提供
- レコードレベルのCDCストリームのファーストクラスサポート

Uber社におけるHudi
- Uber社において世界最大級のトランザクション・データ・レイクを実現
- 150PB以上のデータレイクプラットフォームを4年以上にわたり運用
- Presto、Spark、Hive、Verticaなどのマルチエンジン環境を構築
- 15,000人以上のデータユーザーに対して、削除やGDPRのための複数のデータサービスを構築
- データモニタリング、スキーマ、品質管理など、Uber全体にとって重要なミッションを担当
The Hudi Stack
- 完全な"データ"レイク・プラットフォーム
- 緊密な統合と自己管理
- SparkやFlinkを使った書き込み
- Spark, Flink, Hive, Presto, Trino, Impala, AWS Athena/Redshift, Aliyun DLAなどを使ったクエリ
- データ運用のためのすぐに使えるツール/サービス
- ※テーブルフォーマットは1つの部品に過ぎない
- Change Data Capture to Data Lakes Using Apache Pulsar and Apache Hudi…

テーブルフォーマット - 構成要素やメリットなど
そもそも「テーブルフォーマット」とは何か?
- かなり古い概念。Hiveで導入されたテーブル形式
- DFSではファイルをテーブルとして整理する
- テーブル形式の構成要素
- スキーマ
- ファイル構成
- 同時性の制御
- パーティショニング
- 強化されたテーブルフォーマットのコンポーネント
- ゼロファイルリスト
- 最適化されたクエリプランニング
- 行範囲の統計
- よりスマートなパーティショニング
Hiveテーブル形式
構成要素と利点
- ファイルをディレクトリに整理
- スキーマをハイブテーブルとして定義・運用
- ディレクトリは単なるパーティショニング
- パーティション <-> ロケーションのマッピングをHiveMetastore(HMS)に格納
- フォーマットはHiveにしっかりと統合・管理されている - ACID, コンパクションなど
- Apache Hive 3 tables
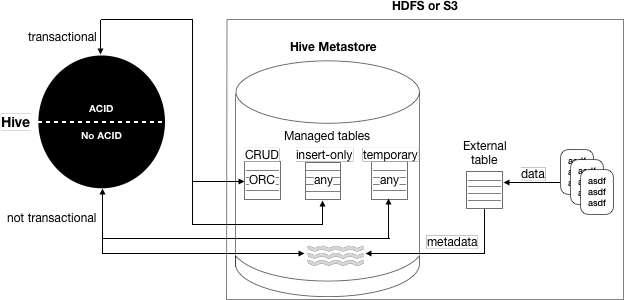
ペインポイント
- HMSに保存されているファイルレベルの統計が同期しなくなる
- パーティションの粒度を細かくするにはHMSの拡張が必要
- HMSは単一のリレーショナルDBであり、スケーラブルではない
- マネージドテーブルの処理エンジンはHiveに限定される
- 第一級のストリーム・プリミティブがサポートされていない
- ユーザーはクエリの書き方を正確に知る必要がある
Hudiテーブル形式
構成要素と利点
- Hudiのテーブルフォーマット:Hiveのテーブルフォーマットの進化版
- ストリームプリミティブによるインクリメンタルな処理の実現
- Hudiのテーブルフォーマットは、Spark、Flink、Javaなどの異なる実行モデルで動作
- 堅牢なテーブルパフォーマンスのための最適化された補助メタデータ
-
※Hudiテーブルフォーマットに切り替えた後も、Hiveテーブルフォーマットと同様のメリットを享受することができ、Hiveテーブルとしてテーブルを照会することができる
Schema on Write
- 書込み時にスキーマを強制しない
- データが構造化されていないため、使用できない可能性がある
- 複数のデータバージョンのスキーマを調整するため、読み込みが遅くなる
- Schema on Write
- データの構造・スキーマを維持・管理する
- 読み取り速度の向上
- カラム名の変更
- 全社的なダッシュボードの修正
ファイルの整理・グルーピング
- パーティションごとのダイナミックなファイルグループと、バージョンを維持するためのファイルスライス
- タイムトラベル
- MVCC
- スナップショットの分離
- トランザクティビティ
- ファイルグループへの記録の密着性
- 参考:
- Change Data Capture to Data Lakes Using Apache Pulsar and Apache Hudi…
ファイルレベルでのデルタログ(Delta Logs)
- 各ファイルグループはそれぞれ独立している
- メタデータのサイズは一定で、「保持」パラメータで制御される
- append()があればそれを利用し、メタデータのオーバーヘッドを低減
- 非常に高速な書き込み
- 読み取りに最適化されたクエリ
- 書き込みと読み込みのコストが0になる可能性もある
- マージはファイルグループ毎に行われる
- 参考:
レコードレベルの変化
- レコード単位のメタデータ
_hoodie_commit_time: Kafkaスタイルでコミット順に圧縮された変更ストリーム_hoodie_commit_seqno: Kafkaのオフセットのように、大きなコミットをチャンクで消費する。
- レコードレベルのマージ
- 部分的な更新の記録
- 変更されたばかりのカラムのログ
- 書き込みの増幅が大幅に減少
- ファイルグループの設計 => CDCフレンドリー
- 古い値と新しい値の効率的な取得
- キーに対するすべての値を効率的に取得
- レコードレベルのインデックス
- インデックスはキーをファイルグループにマッピング
- アップサート/削除時
- ストリーミングステートストアのようなもの
MVCC:並行性制御
- Concurrency Control | Apache Hudi!
- 頻繁なコミット => より頻繁なクラスタリング/コンパクション => より多くのコンテンション
- ライタとテーブルサービスの差別化
- データベースの機能に似ている
- テーブルサービスはライタと競合しない
- 非同期のコンパクション/クラスタリング
- "楽観(Optimistic)"は禁物
- ライター間のOCC、うまくいく、いかないまでも
- リトライ、トランザクションの分割、リソースの浪費
- ライター/テーブルサービス間のMVCC/ログベース
- 完全なログベースへの移行
メタデータテーブル
- クラウドストアのボトルネック
- ファイルのリスト化
- ファイルの情報を保存/エンコードするメタデータ・テーブル
- データ:列挙型データ
- メタデータ:インデックス付きデータファイル
- 何千ものファイルを読むのではなく、1つの大きなファイルを読む
- 大規模環境でのクエリのパフォーマンスが向上
Data skipping indices (RFC-27)
-
RFC-27 Data skipping index to improve query performance - HUDI - Apache Software Foundation
-
ファイルグループのプルーニング
- ファイルグループのメタデータ(ブルームインデックス)を読み込んで、不要なデータをトリミングする。
- クエリの計画・実行時に読み取るファイル(メタ)の数が多い
- カラムごとのメタデータのためのグローバルインデックス
- カラムの範囲→ファイルグループ
- 必要なファイルグループ/スライスのみの読み取り
- クエリ述語に対するクエリ時間
今後の展開
Multi-modal indices
- クエリ実行時間の短縮
- 必要なファイルグループのみを読み込むのは困難
- カラムの範囲/値→一致するファイルのマップを保持する
- HudiのネイティブMORテーブルを利用してメタデータテーブルを格納(外部依存なし)
- 非同期コンパクションで書き込み/読み込みのレイテンシを削減
- データとの同期(コミット、ロールバックなど)
レコードレベルのインデックス
- 分割されていないデータセット(グローバル)
- 干し草の中の針
- より細かいインデックスが必要
- コンプライアンスのための削除要求がこれまで以上に速くなる
- 課題:マルチテーブルのTxn
- HudiのネイティブMORフォーマットを活用
Apache Calcite SQL統合
- Apache Calcite • Dynamic data management framework
- クエリの最適化
- クエリパーサとバリデータ
- クエリオプティマイザ(コストベースなど)
- 標準的な関数と集約
- ストリーミングSQL
- エンジン間での活用(flink、spark、javaエンジン)
Hudi関連リソース
- ユーザードキュメント:Hello from Apache Hudi! | Apache Hudi!
- 技術Wiki:Apache Hudi - HUDI - Apache Software Foundation
- GitHub:apache/hudi: Upserts, Deletes And Incremental Processing on Big Data.
- Twitter:apachehudi(@apachehudi) / Twitter
- メーリングリスト: dev-subscribe@hudi.apache.org (空メールを送って購読開始)
- Slack:新しいアカウントへ新規登録する | Slack
まとめ
という訳で、クラウドデータレイクイベント『Subsurface LIVE Summer 2021』のセッション「Introducing the Apache Hudi Table Format」(Apache Hudiのテーブル形式の紹介)のレポートでした。
Apache Hudiについては社内でも評価が高く、色々な局面での利用を想定して色々検証したりもしています。更なる機能追加、改善も期待出来そうなので今後が楽しみですね。









