[レポート] :データレイクのCI/CDを踏まえたデータ統合を再考する(LakeFSの紹介) – Subsurface LIVE Summer 2021
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
米国時間2021年07月21日〜22日の計2日間、オンラインで開催された「Subsurface LIVE Summer 2021」では、主催となるDremio社のサービスやクラウドデータレイクに関する各種サービスやプロダクトのセッションが展開されていました。
当エントリでは、その中から「Rethinking Ingestion: CI/CD for Data Lakes」(データレイクのCI/CDを踏まえたデータ統合を再考する)というセッションについてレポートします。
目次
セッション概要
セッション概要は以下の通り。
Rethinking Ingestion: CI/CD for Data Lakes
(データレイクのCI/CDを踏まえたデータ統合を再考する)
<登壇者>
Einat Orr - Co-founder and CEO @ Treeverse
<発表内容>
At first glance, ingesting data into a data lake may seem like a one-step process — you simply add files to an object store. What else is there to do?!
It turns out that there is more you can do, and blindly writing new data introduces a host of potential problems. For example, how do you know the data you write is accurate and conforms to schema? The truth is, once you’ve written it to the lake, in a sense, it’s already too late.
What we propose and will cover in this talk, is a new strategy for data lake ingestion. One where new data can be added in isolation, then tested and validated, before “going live” in a production table. Finally, we’ll show how git-for-data tools like lakeFS and Nessie enable this ingestion paradigm in a seamless way.
(データレイクへのデータの取り込みは、一見すると、オブジェクトストアにファイルを追加するだけのワンステッププロセスのように見えます。他に何をする必要があるんだ!?
やみくもに新しいデータを書き込むと、多くの潜在的な問題が発生することがわかりました。例えば、書き込んだデータが正確で、スキーマに適合していることをどうやって確認するのでしょうか?実際のところ、データをレイクに書き込んだ時点で、ある意味、すでに手遅れなのです。
今回、私たちが提案し、説明するのは、データ・レイクへの取り込みのための新しい戦略です。新しいデータを単独で追加し、テストと検証を行ってから、本番のテーブルで「稼働」させるというものです。最後に、lakeFSやNessieのようなgit-for-dataツールが、どのようにしてこの取り込みパラダイムをシームレスに実現するかを紹介します。)
セッションレポート
ここからはセッションレポートとなります。それぞれのトピックに関して要点をまとめる形で紹介。

データレイクアーキテクチャリファレンス

データレイクの「利点」と「課題」
利点
- スケーラビリティと費用対効果
- アクセシビリティと使いやすさ
- 高いスループット
- 豊富なアプリケーションエコシステム
課題
- 実験、比較、再現が出来ない
- 例). BIにおける新しい指標の追加、など
- 「データのベストプラクティス」を実施することが困難
- 例). スキーマやフォーマットの実施
- 高品質なデータの確保が困難
- 例). データの統計的特性の検証
考えうる最高の環境とは...
- 『開発から生産までのデータを、コード管理と同じように管理することができる』環境
- それはどういったものになるか?(要望と実現イメージを併記)
- 本番データの"品質"を確認する
$ lakectl revert main^1
- ブランチを分けて作業する
$ lakectl branch create my-branch
- 結果の再現
$ lakectl commit XXXXXX
- 変更の安全性とアトミック性の確保
$ lakectl merge my-change main # CI hooks now run
- 大きな、破壊的な可能性のある変更を実験する
$ Lakectl branch create experiment-spark-3 $ ./run_crazy_job_that_night_delete_everything.sh $ git branch reset experiment-spark-3
- 本番データの"品質"を確認する
データの開発環境として必要な要件
- 実験 - ツールやコードを個別に試すことができる
- 再現性 - コードとデータの両方を任意の時点に戻すことができる
- 比較 - ツール、コード、データの異なるバージョンを比較する


継続的データ統合(Continuous Data Integration)
- 新しいデータを安全に取り込む
- ベストプラクティスの実施
- メタデータの検証 - 本番データ環境への破壊的な変更の混入を防ぐ
- ベストプラクティスの徹底


継続的なデータデプロイメント(Continuous Data Deployment)
- ユーザーやコンシューマーに公開する前に本番データをテストすることで、データの品質問題を防ぐことが可能
- DAG内の中間結果をテストし、品質問題の連鎖を回避
- データの変更を即座に元に戻す
- 周期的なパイプライン:Airflow DAG
- QD後にデプロイ
- Revert
- コレクション間の一貫性を確保するRevert



LakeFSの紹介

- Atomic Versioned Data Lake - LakeFS
- 特徴
- オブジェクトストレージベースのデータレイクに耐障害性と管理性をもたらすオープンソースのプラットフォーム
- lakeFSを使うことで、複雑なETLジョブからデータサイエンスやアナリティクスまで、反復可能でアトミック、かつバージョン管理されたデータレイクのオペレーションを構築することができる
- lakeFSは、基盤となるストレージサービスとして、AWS S3、Azure Blob Storage、Google Cloud Storage(GCS)をサポート
- S3とはAPI互換性があり、Spark、Hive、AWS Athena、Prestoなど、あらゆる最新のデータフレームワークとシームレスに動作
- LakeFSの仕組み
- S3、GCS、Azure Blobなどのストレージを利用することで、エクサバイト級のデータにも対応できるGitライクなブランチ・コミットモデルを提供
- このブランチモデルにより、データレイクはACIDに準拠したものとなり、変更は隔離されたブランチで行われ、そのブランチは原子レベルで瞬時に作成、マージ、ロールバックすることが出来る
- lakeFSはS3 APIと互換性があるため、オブジェクトパスにブランチ名を追加するだけで、一般的なアプリケーションはすべて変更なしで動作
- s3://data-bucket/collections/foo
- ↓
- s3://data-bucket/main/collections/foo
# will create an external table using the same partitions and configurations # but pointing at paths under the new branch $ lakectl metastore copy \ --from-table user events \ --to-branch dev-experiment - 1
- 既存ツールとの統合に対応
- LakeFSアーキテクチャ
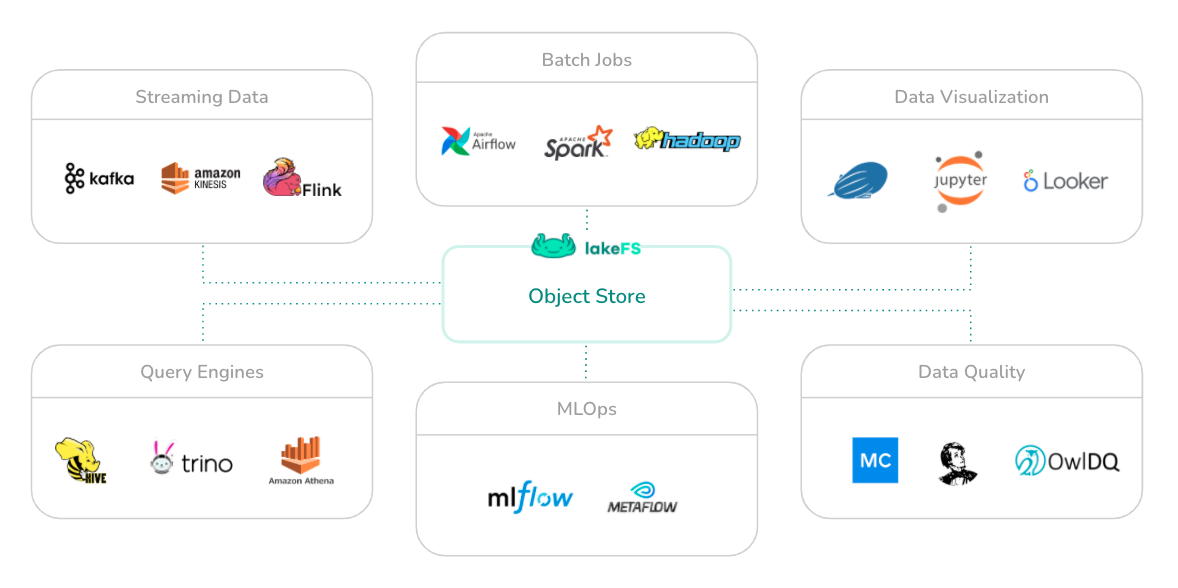
まとめ
という訳で、クラウドデータレイクイベント『Subsurface LIVE Summer 2021』のセッション「Rethinking Ingestion: CI/CD for Data Lakes」(データレイクのCI/CDを踏まえたデータ統合を再考する)のレポートでした。
LakeFSというサービスが後半で紹介される流れのセッション内容でしたが、このサービスも非常に興味深いものですね。時間を見つけて色々調べてみようと思います。










