
【Glue/Iceberg】S3に置いたデータをIcebergテーブルへ連携するGlueジョブを自動化してみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部の川中子(かわなご)です。
先日サモエド(白くてもふもふの犬)カフェなるものに行ってきました。
寒さに強いはずのサモエドですが、さすがのサモエドの鼻もやや乾いていました。
私も最近は冬の乾燥と春の花粉のダブルパンチによって鼻が世紀末状態になっています。
さて今回は Athenaで作成したiceberg形式のテーブルへ自動データ連携 をやってみました。
構成自体は平易なものですが、実装において躓いた点もあったので、備忘録として残してみます。
本記事は以下のAWSブログを参考にしています。
概要
前提
今回の記事では以下を前提として、ざっくりとした全体像について触れていきます。
- 今回は全てマネジメントコンソール上で作成
- テーブルへのデータ連携は増分ロードの形式で実行
- csv読み込み用のテーブルとiceberg形式のテーブルは手動で作成
- 各ツール実行用のロールや権限については特に言及しない
構成図
今回の構成図は以下になります。
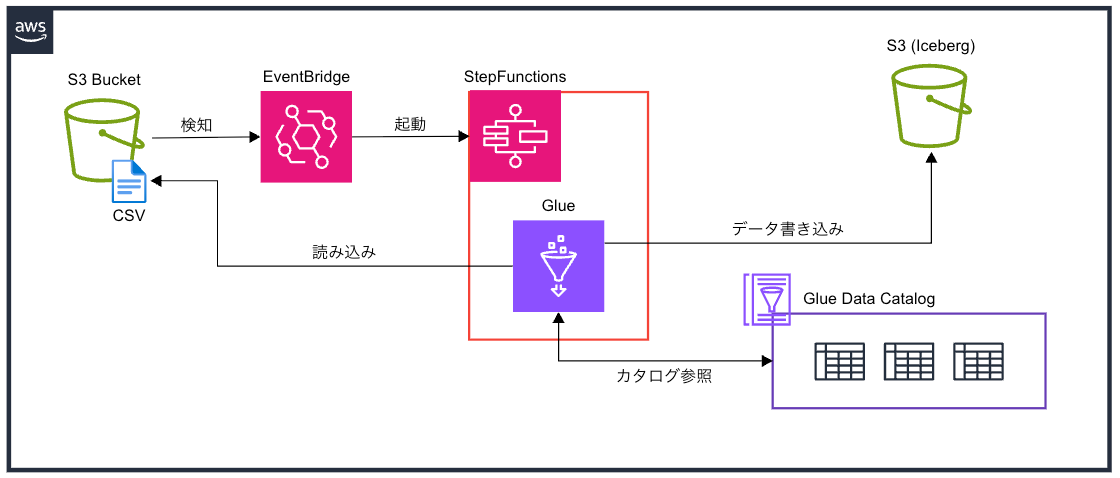
- EventBridgeでS3を監視し、
Object Createをトリガにステートマシンを呼び出す - ステートマシンの中ではGlueジョブを呼び出すだけ
- Glueジョブでソースのcsvを読み込み、Icebergのテーブルへデータを連携する
各アセットの作成
S3バケットと配置するデータ
今回は以下のような構成でバケットを準備しています。
フォルダ名になっているproductsやusersは、後に作成するAthenaのテーブルに合わせてます。
aws s3 ls s3://cm-kawanago-lfa/ --recursive
2025-02-12 18:10:33 0 iceberg_table/
2025-02-12 11:26:48 0 source_data/
2025-02-12 18:08:24 0 source_data/products/
2025-02-12 18:08:06 0 source_data/users/
データは全部で3つで、usersに格納するcsvは増分ロードの検証用に2つあります。
ここではヘッダーにcol_1などと記載してますが、実際のcsvはヘッダーを持ちません。
(門田という名字は高知の土佐地方に多いらしい)
users_data_000.csv
| col_1 | col_2 | col_3 |
|---|---|---|
| 1 | a | nakata |
| 2 | b | yoshida |
| 3 | c | yamada |
| 4 | d | kawata |
| 5 | e | monden |
users_data_001.csv
| col_1 | col_2 | col_3 |
|---|---|---|
| 6 | f | suzuki |
| 7 | g | kobayashi |
| 8 | h | tamori |
products_data_000.csv
| col_1 | col_2 | col_3 |
|---|---|---|
| 1 | a | banana |
| 2 | b | orange |
| 3 | c | grape |
| 4 | d | peach |
| 5 | e | strawberry |
Athenaのテーブル作成
検証用にデータベースを作成しておきます。
create database database_kawanago;
Iceberg形式のテーブルをusers, productsでそれぞれ作成します。
CREATE TABLE database_kawanago.iceberg_users (
col_1 int,
col_2 string,
col_3 string
)
LOCATION 's3://cm-kawanago-lfa/iceberg_table/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet'
)
CREATE TABLE database_kawanago.iceberg_products (
col_1 int,
col_2 string,
col_3 string
)
LOCATION 's3://cm-kawanago-lfa/iceberg_table/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet'
)
次に、ソースとなるcsvのデータを読み込むためのテーブルを作成しておきます。
CREATE EXTERNAL TABLE database_kawanago.source_users (
col_1 int,
col_2 string,
col_3 string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://cm-kawanago-lfa/source_data/users/'
TBLPROPERTIES (
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'typeOfData'='file');
CREATE EXTERNAL TABLE database_kawanago.source_products (
col_1 int,
col_2 string,
col_3 string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://cm-kawanago-lfa/source_data/products/'
TBLPROPERTIES (
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'typeOfData'='file');
GlueでETL jobsを作成
incremental_load_testという名前でGlueのETL jobsを作成しました。
スクリプトの全体像は以下になります。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.conf import SparkConf
from pyspark.sql import functions as F
from awsglue.context import GlueContext
from awsglue.job import Job
import boto3
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'warehouse_path', 's3_key'])
conf = SparkConf()
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
conf.set("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog")
conf.set("spark.sql.catalog.glue_catalog.warehouse", args['warehouse_path'])
conf.set("spark.sql.catalog.glue_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog")
conf.set("spark.sql.catalog.glue_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
conf.set("spark.sql.catalog.glue_catalog.glue.lakeformation-enabled", "false")
sc = SparkContext(conf=conf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
TABLE_NAME = args["s3_key"].split("/")[-2]
GLUE_DATABASE = "database_kawanago"
GLUE_SOURCE_TABLE = f"source_{TABLE_NAME}"
GLUE_TARGET_TABLE = f"iceberg_{TABLE_NAME}"
source_df = glueContext.create_dynamic_frame.from_catalog(
database = GLUE_DATABASE,
table_name = GLUE_SOURCE_TABLE,
transformation_ctx = "source_df"
).toDF()
if not source_df.isEmpty():
source_df.createOrReplaceTempView("input_table")
merge_table = f"""
MERGE INTO glue_catalog.{GLUE_DATABASE}.{GLUE_TARGET_TABLE} AS target
USING input_table AS source
ON target.col_1 = source.col_1
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
"""
spark.sql(merge_table)
job.commit()
今回はcsvが置かれたS3のフォルダ名に対応したテーブルを指定するため、
getResolvedOptionsでs3_keyを指定して、パラメータを受け取ります。
このパラメータはこの後、StepFunctionsの方でも設定します。
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'warehouse_path', 's3_key'])
受け取ったS3のキーは以下でパスを処理してフォルダ名を取得しています。
TABLE_NAME = args["s3_key"].split("/")[-2]
GLUE_DATABASE = "database_kawanago"
GLUE_SOURCE_TABLE = f"source_{TABLE_NAME}"
GLUE_TARGET_TABLE = f"iceberg_{TABLE_NAME}"
create_dynamic_frameを作成する際にtransformation_ctxを指定することで、
前回実行時以降に配置されたファイルのみを処理対象とするブックマーク機能を有効化します。
source_df = glueContext.create_dynamic_frame.from_catalog(
database = GLUE_DATABASE,
table_name = GLUE_SOURCE_TABLE,
transformation_ctx = "source_df"
).toDF()
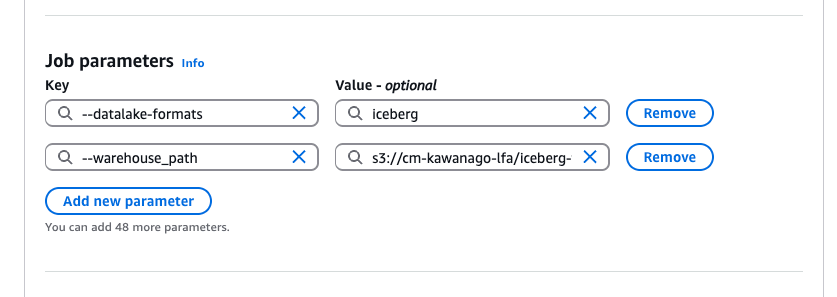
今回は増分ロードを前提としているため、Advanced propertiesでもJob bookmarkを有効化しておきます。

またパラメータ受け渡しのために、Job parametersでは以下を設定しておきます。
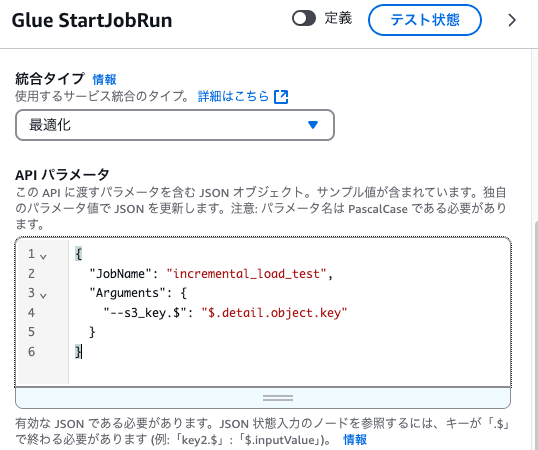
Step Functionsでステートマシンを作成
StepFunctionsでは、Glueジョブを呼び出すシンプルなステートマシンを作ります。
APIパラメータは以下のように設定することで、
発火したイベントのオブジェクトキーをパラメータとしてGlueジョブに渡します。
作成したステートマシンの全体の定義は以下のようになっています。
{
"Comment": "A description of my state machine",
"StartAt": "Glue StartJobRun",
"States": {
"Glue StartJobRun": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun",
"Parameters": {
"JobName": "incremental_load_test",
"Arguments": {
"--s3_key.$": "$.detail.object.key"
}
},
"End": true
}
}
}
Event Bridgeでルールを作成
Event Bridgeではソースのcsvを格納するS3フォルダを監視するルールを作成します。
ターゲットには上で作成したステートマシンを指定しています。
設定したイベントパターンは以下のようになりました。
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["cm-kawanago-lfa"]
},
"object": {
"key": [{
"prefix": "source_data/"
}]
}
}
}
実行
ここまでで各種アセットの作成は完了したので、
実際にS3にcsvファイルを配置して、データが連携される様子を確認してみます。
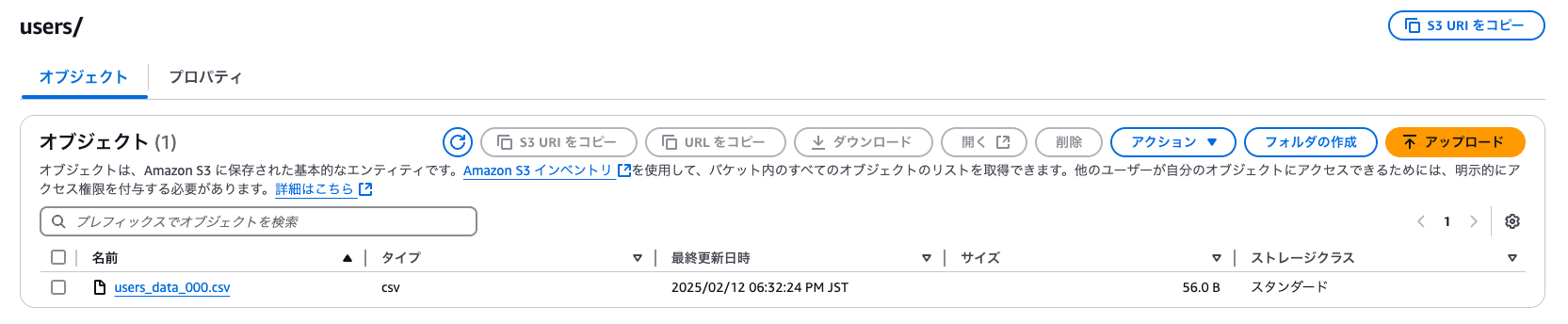
データを配置
usersフォルダにusers_data_000.csvを配置します。
同時刻にStepFunctionsが起動しました。

こちらもほぼ同時刻にglueジョブが起動しています。
s3_keyにもしっかりパラメータが渡っていることが確認できます。
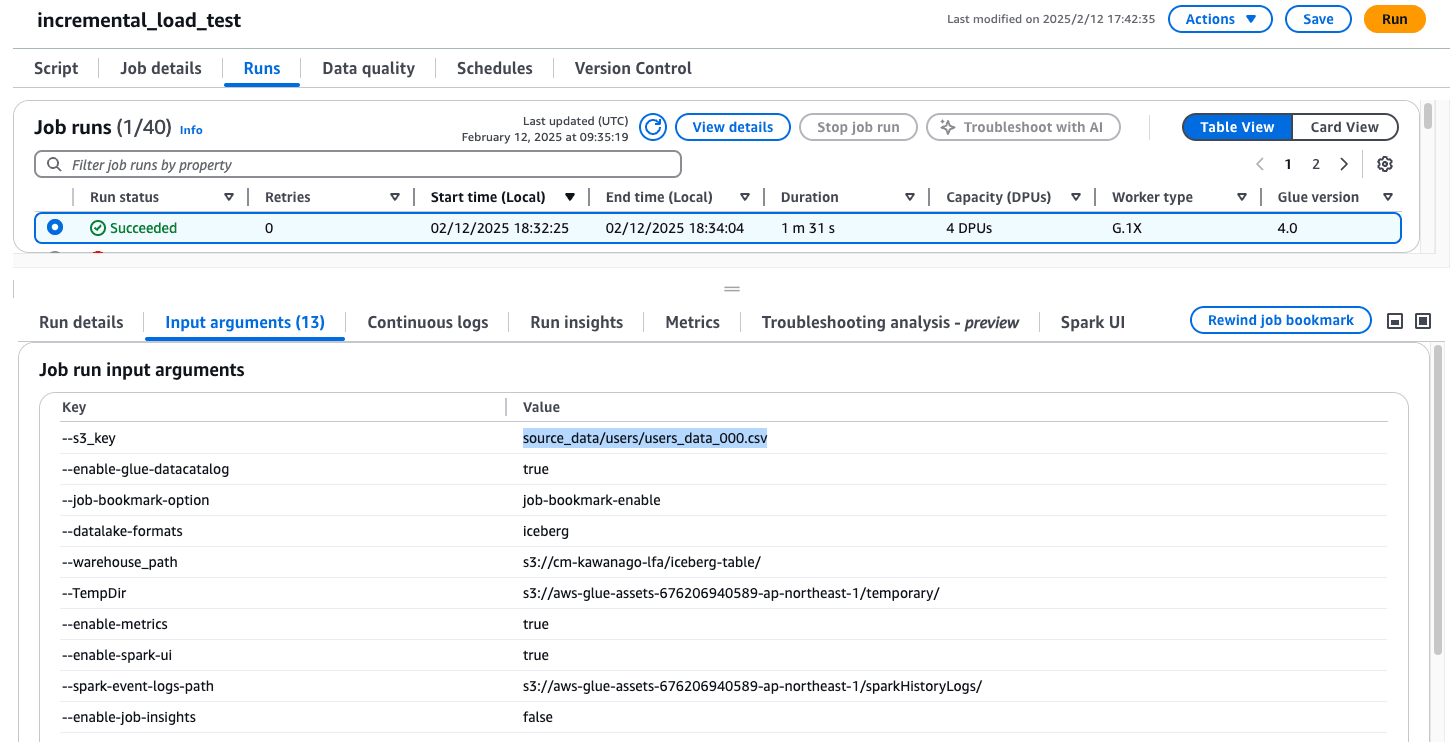
結果を確認
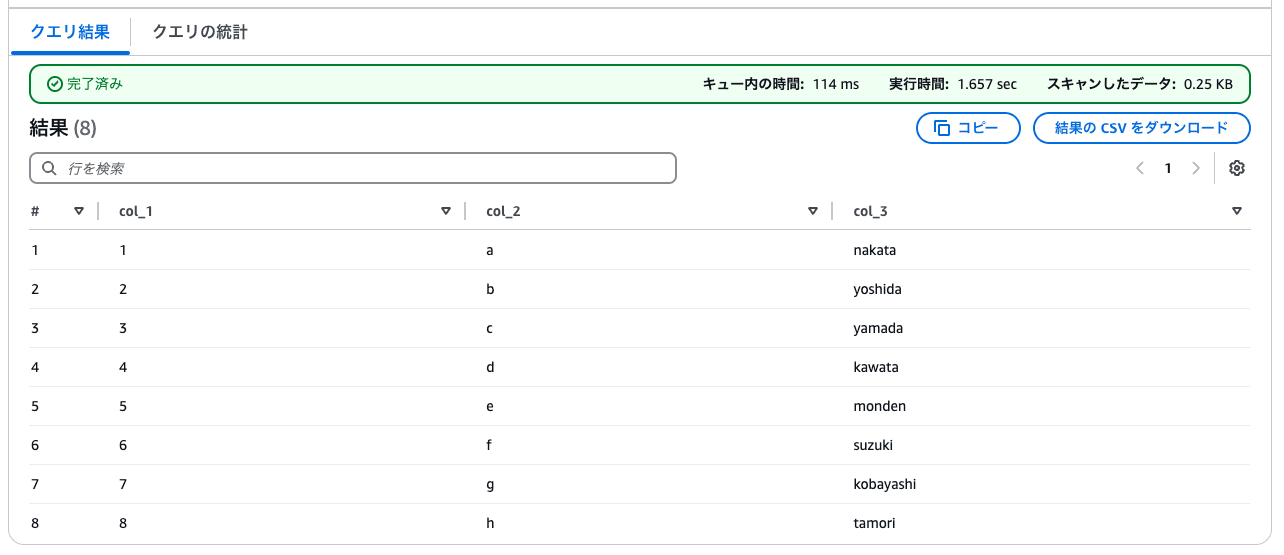
Athenaからiceberg_usersテーブルを確認すると、しっかりデータが格納されていました。
SELECT * FROM "database_kawanago"."iceberg_users"
ORDER BY col_1 desc;

productsのデータを配置
今度は別のフォルダであるproductsフォルダにデータを配置します。
Athenaからiceberg_productsテーブルを確認すると、こちらも正常にデータが格納されていました。
s3_keyをパラメータとして処理することで、1つのジョブでターゲットのテーブルを分岐できました。
SELECT * FROM "database_kawanago"."iceberg_products"
ORDER BY col_1 desc;

増分データを配置
今度は増分ロードの検証として、usersフォルダにusers_data_001.csvを追加で配置します。
再度iceberg_usersテーブルを確認すると、追加分のデータだけがInsertされたことが確認できました。
SELECT * FROM "database_kawanago"."iceberg_users"
ORDER BY col_1 desc;
さいごに
今回の検証では以下の2点について確認ができました。
- S3へのcsv配置をトリガに、icebergテーブルへ増分ロード連携を自動化
- 1つのEventBridge/StepFunction/Glueアセットで、s3のキーに応じて処理分岐
もしターゲットのテーブルに対してUPSERTでデータを連携する場合も、
Glueのスクリプトを少し修正するだけで実装が可能なので、工数もあまりかかりません。
また現状の仕様ではファイルを配置するS3のフォルダ名と、
ターゲットになるテーブル名を一致した状態で作成しておく必要があります。
このあたりはテーブル作成も自動化しておくことで、この構成がより活かせると思います。
最後まで記事をご覧頂きありがとうございました。
ぜひ皆さんも冬の乾燥には気を付けて下さい。










