
S3バッチオペレーションを使ってクロスアカウントのS3バケット間コピーをやってみた
データ事業本部のsutoです。
別のアカウントのS3バケットにある大量データを自身のアカウントのS3バケットにコピーするため、「S3バッチオペレーション」を試してみました。
S3バッチオペレーションを採用した理由
S3バケット間コピーの方法は、S3レプリケーション、AWS Datasyncなど様々ありますが、今回やりたいケースは以下の条件があり対応できなかったため「S3バッチオペレーションによるLambda関数の呼出によってコピー処理」を実行させます。
- コピー元のファイルが全てバケット直下に格納されている状態である
- コピー先バケットでは、ファイル名に含まれている日付ごとにフォルダを切って格納させたい
今回、コピー元バケットの状態は以下のようになっています。
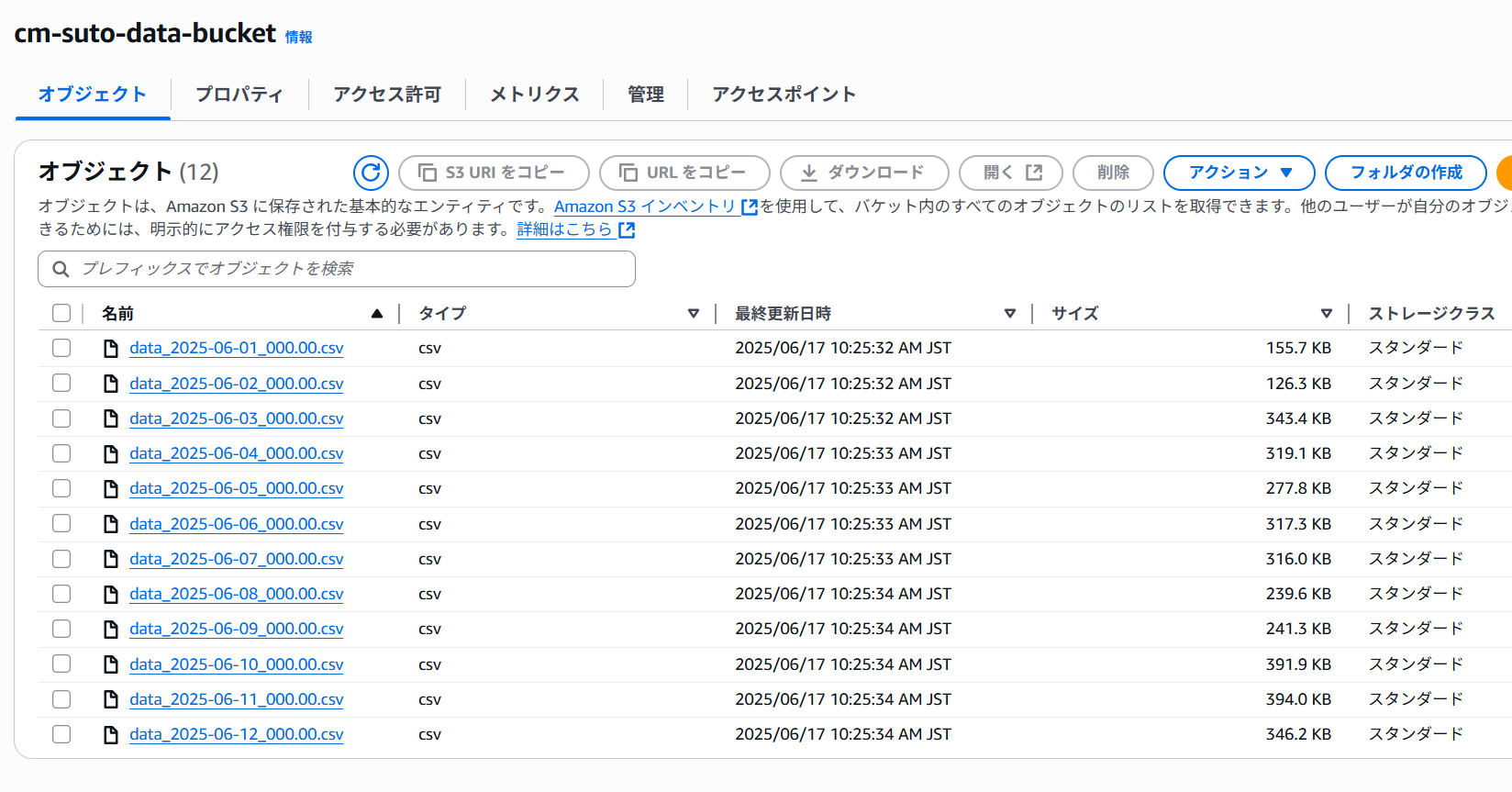
やってみた
登場リソースは以下のとおりです。
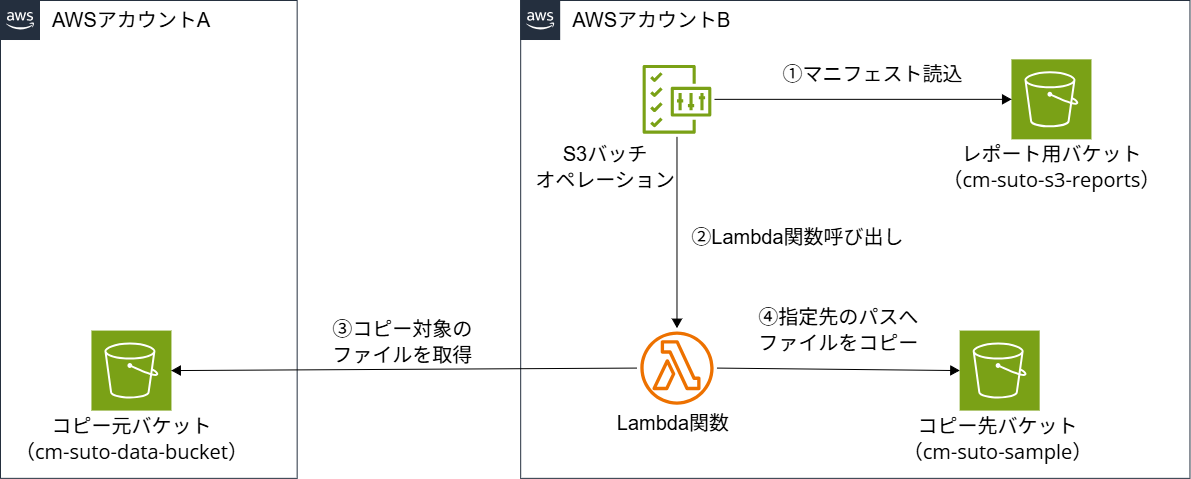
おおまかな流れは以下のとおりです。(基本的に設定リソースを作成するアカウントは「アカウントB」とします)
- 【アカウントB】レポートバケットにバケットポリシー設定
- 【アカウントB】Lambda関数の作成
- 【アカウントB】Lambda関数用IAMロール(ポリシーも含む)作成
- 【アカウントB】S3バッチオペレーション用IAMロール作成
- 【アカウントA】S3バケットポリシー設定
- 【アカウントA】S3インベントリ設定
- 【アカウントB】S3バッチジョブの作成と実行
【アカウントB】レポートバケットにバケットポリシー設定
まず、アカウントBで、S3インベントリレポートとバッチジョブの完了レポートを格納するためのバケットにポリシーを設定し、アカウントAからの書き込みを許可します。
ポリシーの内容は以下です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAccountAToPutInventoryReport",
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::cm-suto-s3-reports/*",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "アカウントAのAWS ID",
"s3:x-amz-acl": "bucket-owner-full-control"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:s3:::cm-suto-data-bucket"
}
}
}
]
}
【アカウントB】Lambda関数の作成
アカウントBで、ファイル名を解析してコピーを実行するLambda関数を作成します。
- アカウントBのLambdaコンソールを開き、「関数の作成」をクリックします。
- 「一から作成」を選択し、以下の通り設定します。
- 関数名: S3BatchCopyToDatePartitioned など分かりやすい名前。
- ランタイム: Python 3.13 (または任意のPython 3.x)。
- アーキテクチャ: x86_64。
- 実行ロール: 「新しいロールを作成」を選択します(次の工程で権限を編集します)。
関数が作成されたら、「コードソース」に以下のPythonコードを貼り付けます。
import boto3
import urllib.parse
import re
import logging
import os
s3 = boto3.client('s3')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# コピー先のバケット名は環境変数から取得
DESTINATION_BUCKET = os.environ['DESTINATION_BUCKET']
def lambda_handler(event, context):
invocation_id = event['invocationId']
invocation_schema_version = event['invocationSchemaVersion']
results = []
task = event['tasks'][0]
task_id = task['taskId']
# ★★★ デバッグ用:taskオブジェクトの全体像をログに出力します ★★★
# logger.info(f"Received task object: {task}")
# 念のための初期化
source_key = "unknown"
try:
source_bucket = task['s3Bucket'].split(':')[-1]
source_key = urllib.parse.unquote_plus(task['s3Key'])
# .csvファイルであり、かつ日付パターンを持つファイルのみを処理対象とする
if not source_key.lower().endswith('.csv'):
result_string = f"Skipped: File is not a .csv file."
logger.info(f"{result_string} ({source_key})")
else:
match = re.search(r'(\d{4}-\d{2}-\d{2})', source_key)
if not match:
result_string = f"Skipped: Date pattern 'YYYY-MM-DD' not found in filename."
logger.info(f"{result_string} ({source_key})")
else:
# 条件に一致した場合のみ、コピー処理を実行
logger.info(f"Processing object: s3://{source_bucket}/{source_key}")
date_str = match.group(1)
year, month, day = date_str.split('-')
file_name = source_key.split('/')[-1]
destination_key = f"{year}/{month}/{day}/{file_name}"
s3.copy_object(
Bucket=DESTINATION_BUCKET,
Key=destination_key,
CopySource={'Bucket': source_bucket, 'Key': source_key}
)
result_string = f"Successfully copied to s3://{DESTINATION_BUCKET}/{destination_key}"
results.append({
'taskId': task_id,
'resultCode': 'Succeeded',
'resultString': result_string
})
except Exception as e:
logger.error(f"Error processing task {task_id} for source_key '{source_key}': {e}")
results.append({
'taskId': task_id,
'resultCode': 'PermanentFailure',
'resultString': str(e)
})
return {
'invocationSchemaVersion': invocation_schema_version,
'treatMissingKeysAs': 'PermanentFailure',
'invocationId': invocation_id,
'results': results
}
- 以下の環境変数を設定します。
- キー: DESTINATION_BUCKET
- 値: cm-suto-sample
- タイムアウト設定では「2分」程度に設定しておきます。
- 【注意】オブジェクト数が大量である場合、Lambda関数の「同時実行数」の設定は、アカウントの上限値を考慮して設定してください。同アカウント内の他のLambda関数の動作に影響が出ないようにすることも忘れずに。
- 理由は、S3バッチオペレーションの動作として、1オブジェクトにつき1回Lambda関数の実行となるため。
【アカウントB】Lambda関数用IAMロール(ポリシーも含む)作成
IAMの画面から以下の内容のIAMポリシー(S3BatchCopyPolicy)を作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowReadFromSourceBucket",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::cm-suto-data-bucket/*"
},
{
"Sid": "AllowWriteToDestinationBucket",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::cm-suto-sample/*"
}
]
}
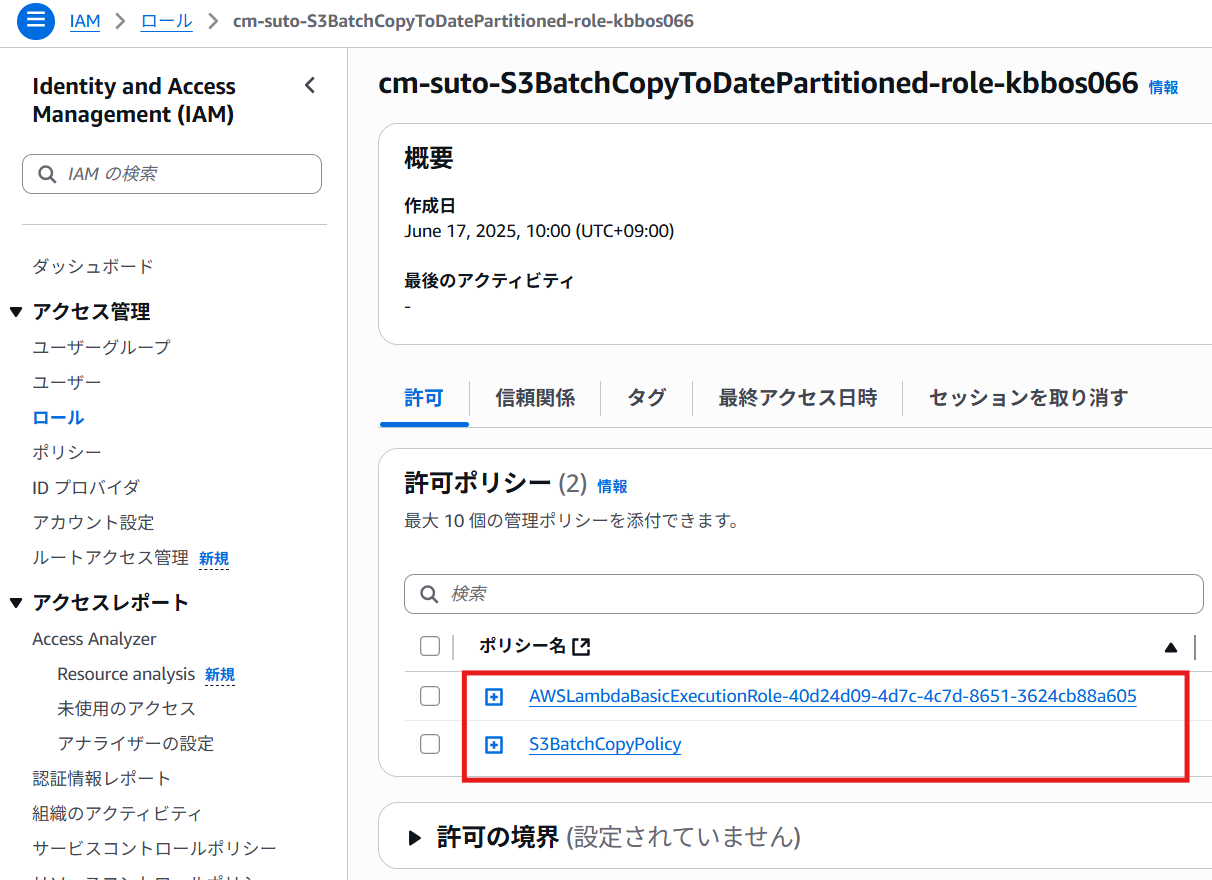
次にLambda関数用IAMロールを編集します。
- ユースケースで「Lambda」を選択し「次へ」
- 許可の追加では「AWSLambdaBasicExecutionRole」と、先ほど作成した「S3BatchCopyPolicy」をアタッチ
- IAMロール名をつけて作成
【アカウントB】S3バッチオペレーション用IAMロール作成
まずロールにアタッチするIAMポリシー(S3BatchJobExecutionPolicy)を作成します。
ポリシー内容は以下です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowReadManifestAndWriteReport",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::cm-suto-s3-reports/*"
},
{
"Sid": "AllowLambdaInvocation",
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "アカウントBのLambda関数のarn"
}
]
}
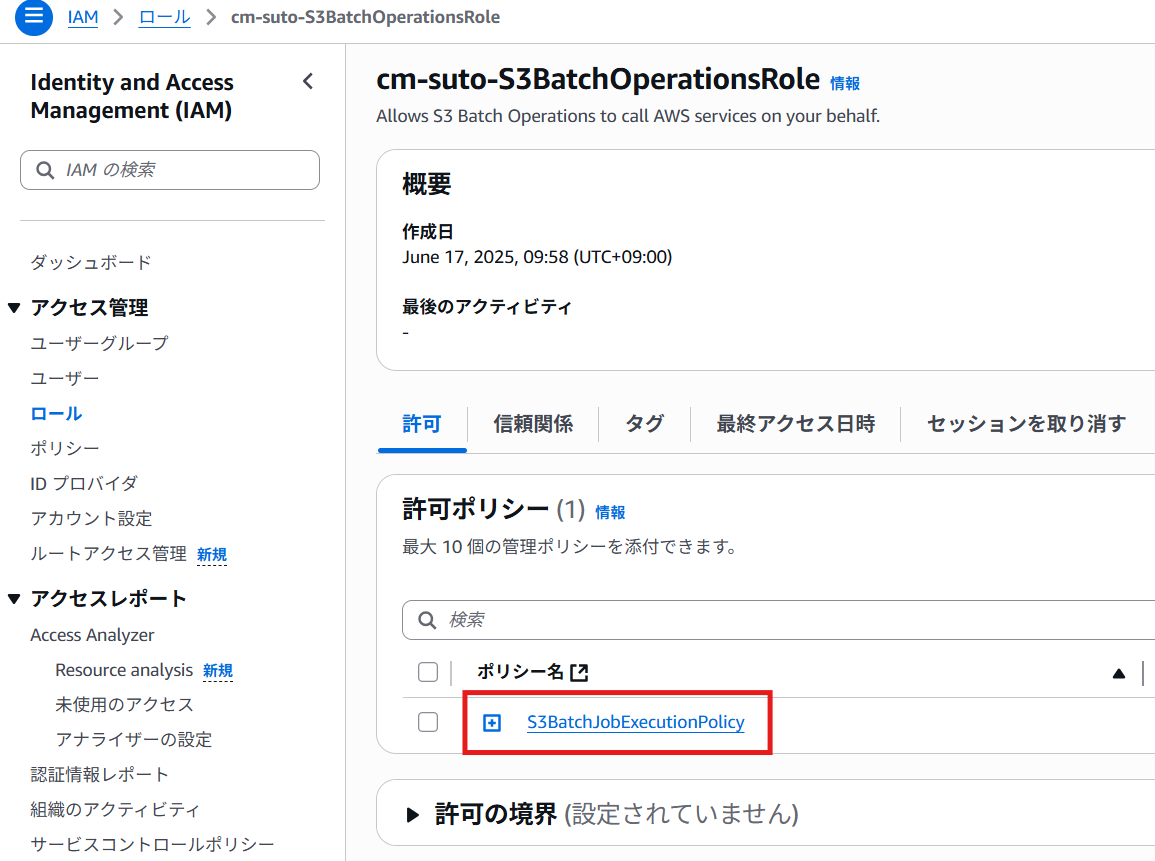
- IAMの画面で「ロールを作成」をクリック
- ユースケースで「S3」 > 「S3 Batch Operations」を選択して「次へ」
- 許可ポリシーの設定画面で「S3BatchJobExecutionPolicy」を選択
- IAMロール名をつけて作成
【アカウントA】S3バケットポリシー設定
アカウントAに切り替えて、アカウントBのS3バッチジョブに呼び出されるLambda関数がソースバケットにアクセスできるようにバケットポリシーを設定します。
ポリシーの内容は以下です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "アカウントBのLambda関数用IAMロールのarn"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::cm-suto-data-bucket",
"arn:aws:s3:::cm-suto-data-bucket/*"
]
}
]
}
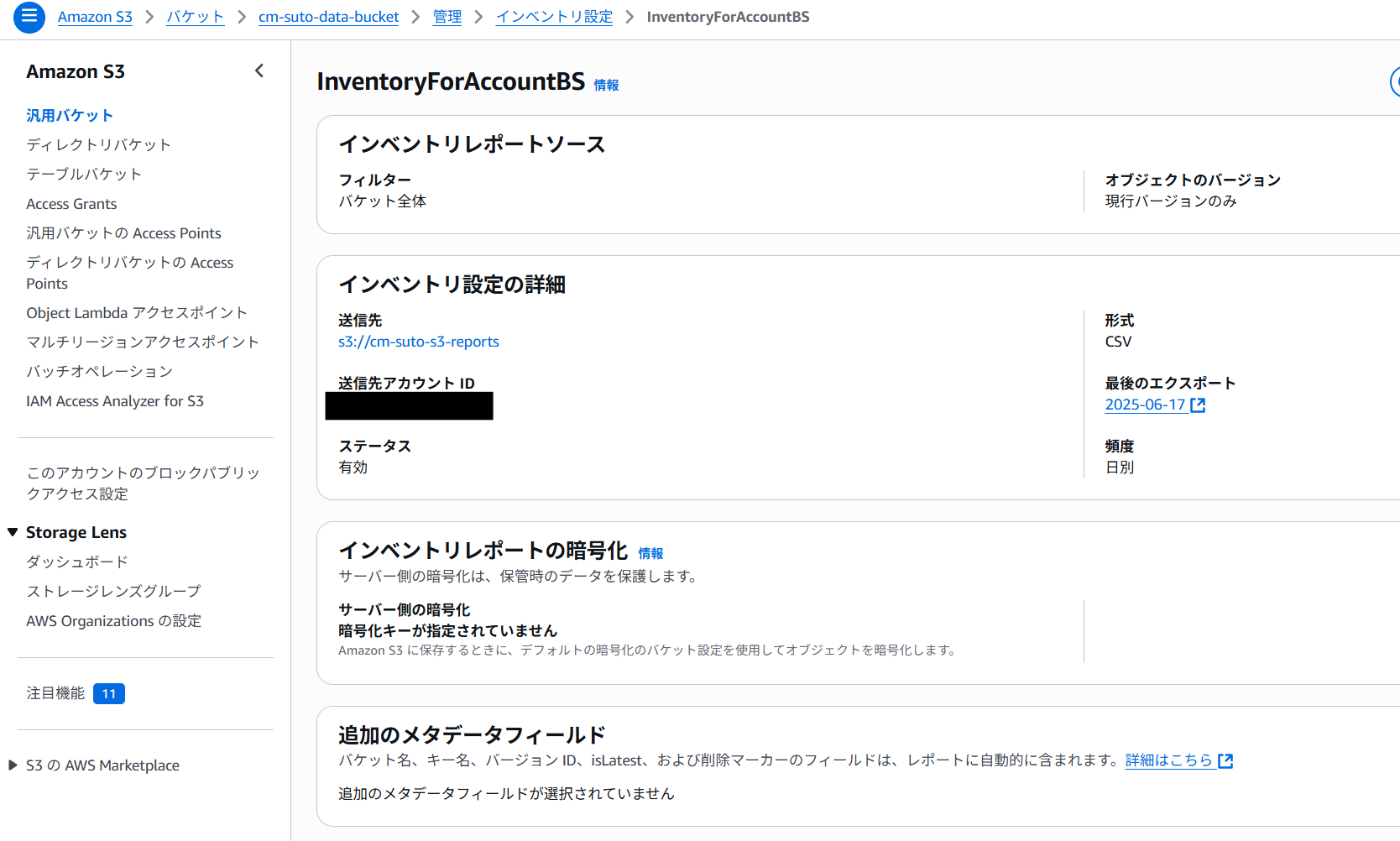
【アカウントA】S3インベントリ設定
- アカウントAのS3バケット一覧で、ソースバケット cm-suto-data-bucket を選択します。
- 「管理」タブに移動し、「インベントリ設定」で「インベントリ設定を作成」をクリックします。
- 以下の通り設定します。
- インベントリ設定名: InventoryForAccountB など分かりやすい名前を入力
- プレフィックス - オプション: 空欄のまま(バケット直下を対象とするため)
- 「別のAWSアカウントのバケット」を選択
- アカウントID: アカウントBのAWSアカウントIDを入力
- 出力先: s3://cm-suto-s3-reports と入力
- 頻度: 「日次」 を選択
- 出力形式: 「CSV」 を選択
- オブジェクトのバージョン: 現在のバージョンのみ を選択
- オプションのフィールド: チェックは不要
【注意】 S3インベントリの最初のレポートが生成されるまでには、最大で48時間かかることがあります。
【アカウントB】S3バッチジョブの作成と実行
レポートが作成されたら、いよいよS3バッチオペレーションジョブの作成です。
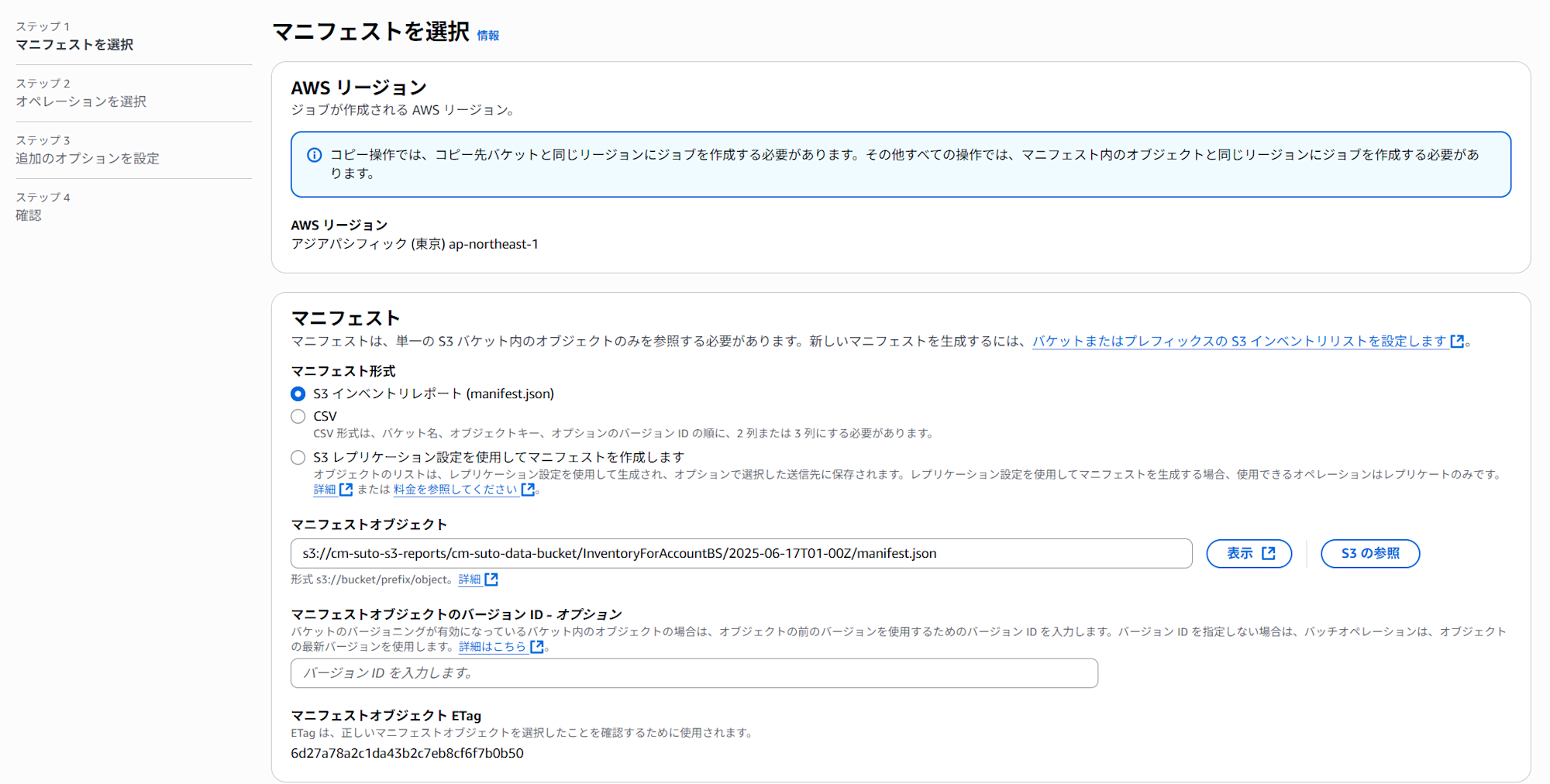
- S3コンソールで「バッチオペレーション」を開き、「ジョブの作成」をクリック
- 「マニフェストの形式」で S3 インベントリレポート を選択
- 「マニフェストオブジェクトへのパス」で「参照」をクリックし、cm-suto-s3-reports バケット内に出力されたインベントリのフォルダを辿り、manifest.json ファイルを選択
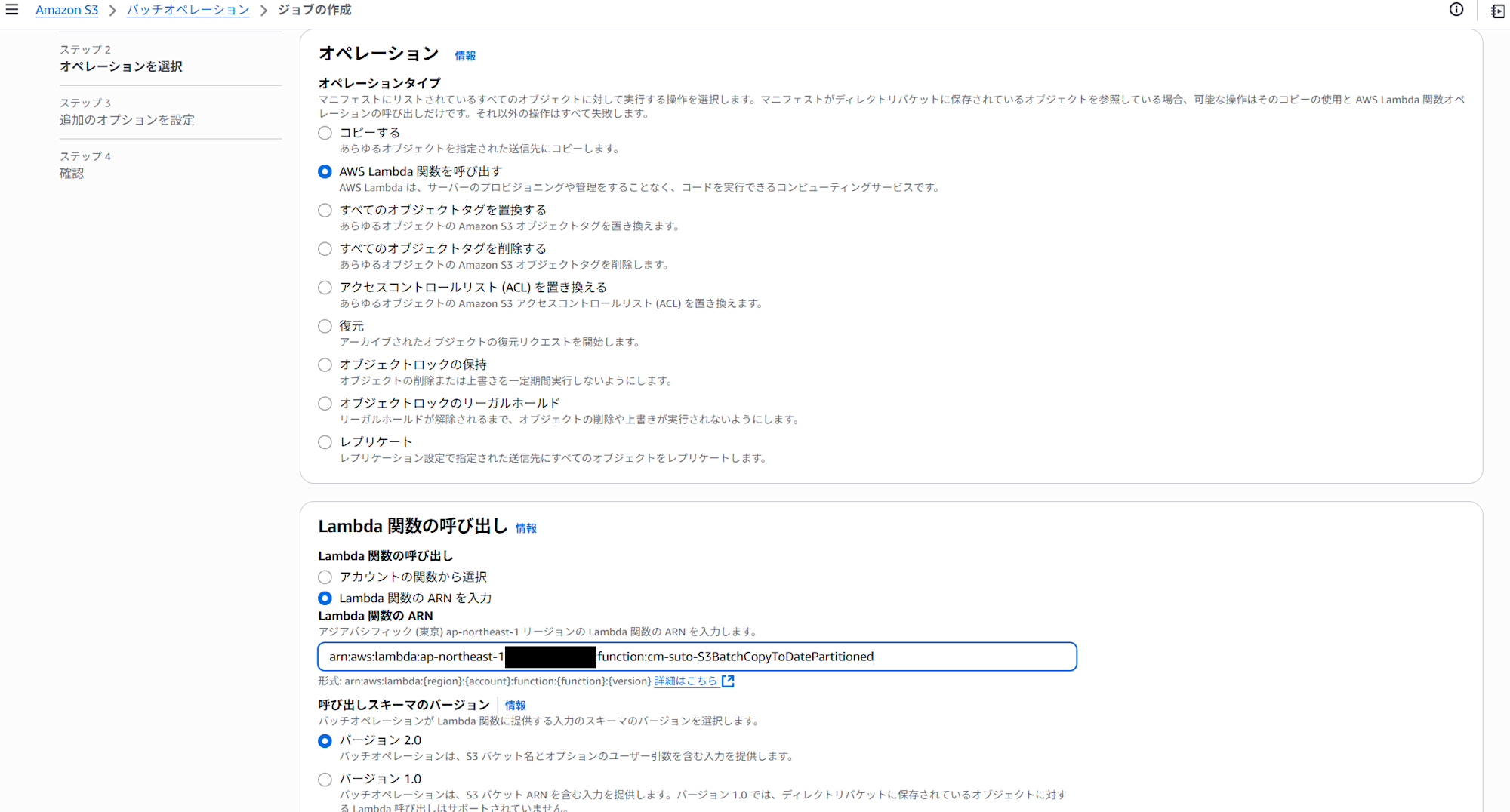
- 「オペレーションタイプ」で「AWS Lambda 関数を呼び出す」を選択し、作成したLambda関数を選択(今回はなぜか一覧に出てこなかったので直接Arnを貼り付けました)
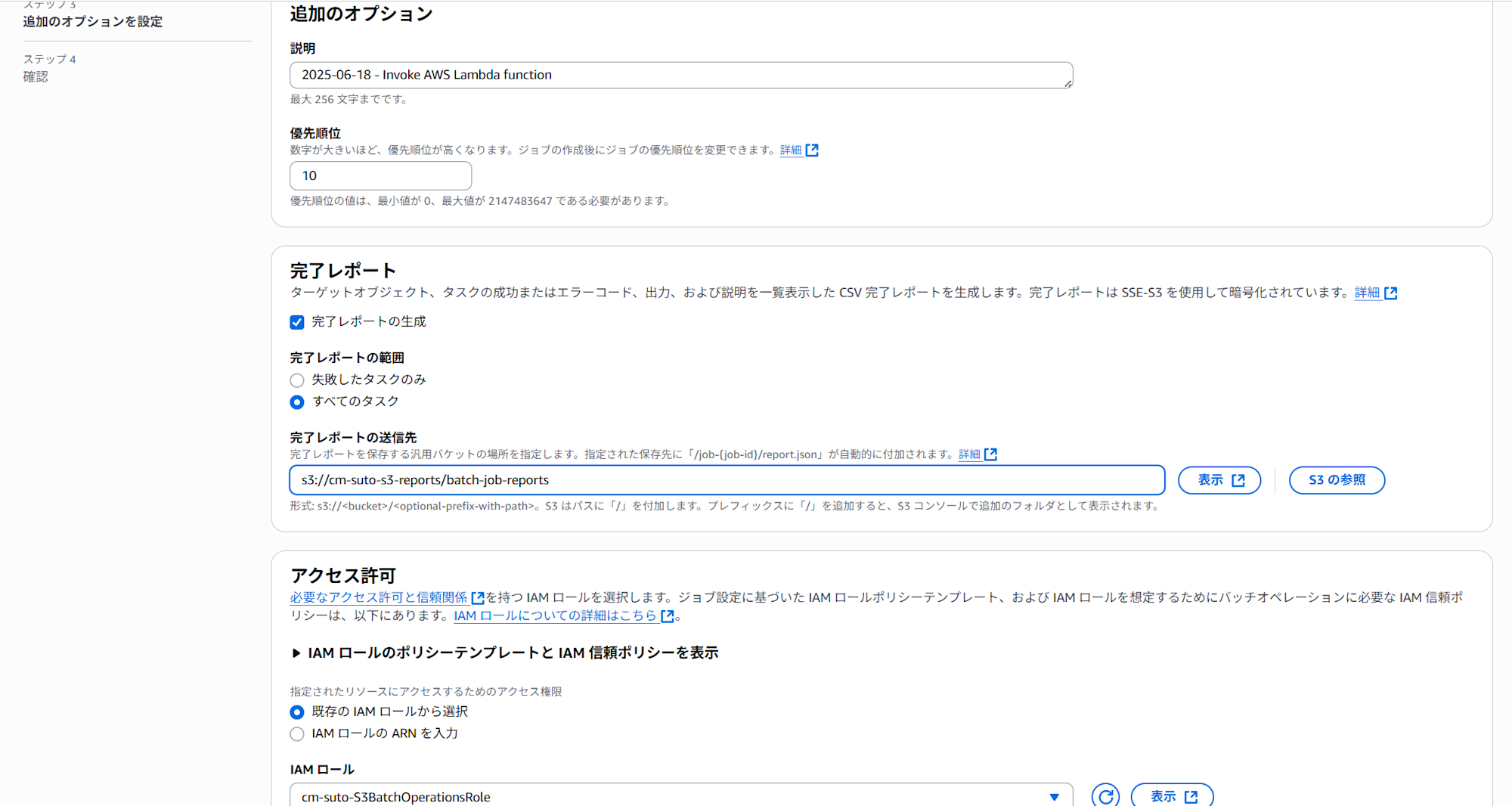
- 「完了レポート」を「完了レポートを生成」にチェックを入れる
- 「レポートのスコープ」は「失敗したタスクのみ」または「すべてのタスク」を選択
- 「レポートの出力先」に s3://cm-suto-s3-reports/batch-job-reports などを指定
- 「IAM ロール」で「既存の IAM ロールから選択」を選び、作成しておいたIAMロールを選択
- 最後にすべての設定を確認し、「ジョブを作成」をクリック
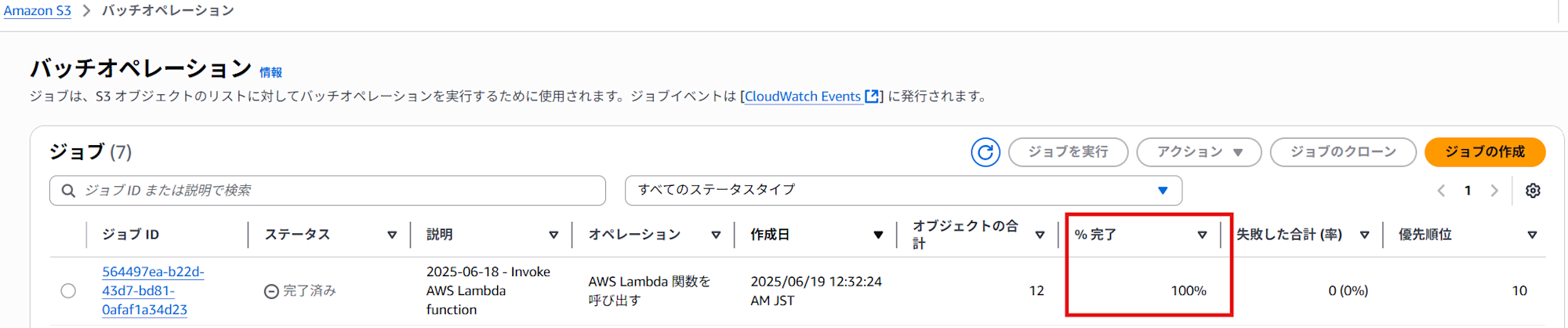
ジョブが「確認待ち」状態になるので、ジョブを選択して「ジョブを実行」をクリックすると、処理が開始されます。
ジョブの進捗はバッチオペレーションの画面で確認でき、完了後には指定したパスに完了レポートが出力されます。失敗したタスクがあればレポートで原因を確認できます。
ジョブが「完了済み」になり、完了が100%であれば成功です。
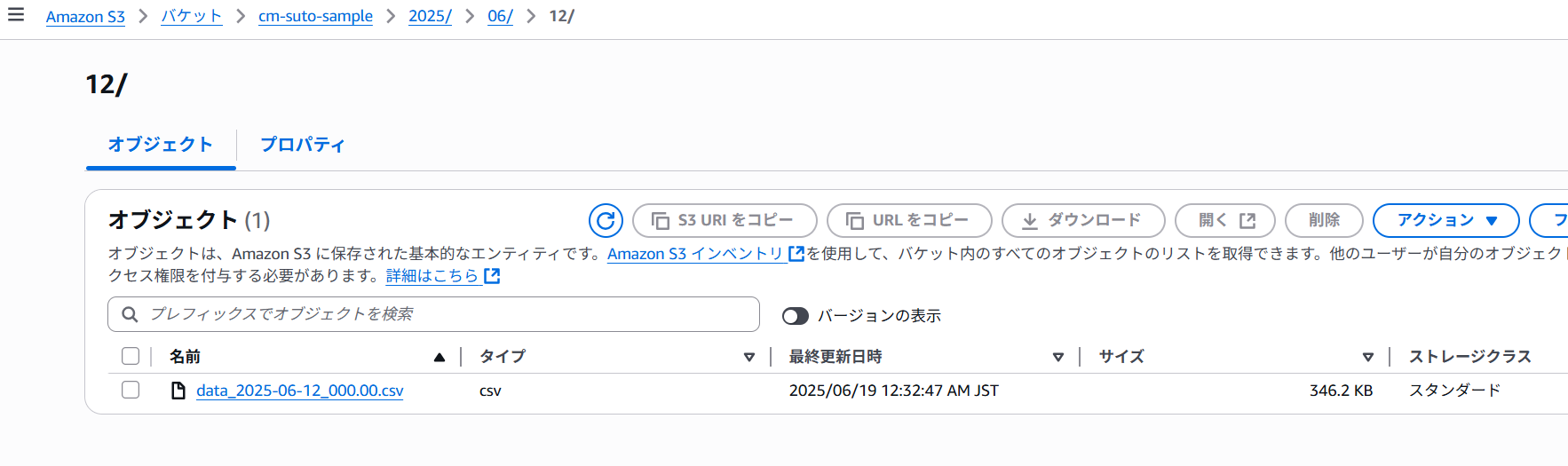
無事、日付フォルダごとの配下にcsvファイルがコピーされたことを確認できました!
さいごに
今回はS3バッチオペレーションでLambda関数を呼び出し、S3バケット間コピーを実行する方法をご紹介しました。
データ分析のために別アカウントのバケットにあるデータを持ってきたいけど、フォルダ構成がぐちゃぐちゃでそのままレプリケーションしたくない時などに応用できるかと思います。









