![[S3] Amazon S3 Files でS3バケットをマウントする [NFS]](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-5b63f451a7e5d6fa957169604dc3060c/db6d476bb2626ff85c8289b743d52ea2/amazon-efs?w=3840&fm=webp)
[S3] Amazon S3 Files でS3バケットをマウントする [NFS]
Introduction
先日、AmazonはS3バケットをNFSファイルシステムとしてマウントできるようにする新機能、S3 FilesをGAしました。
従来、S3のデータをファイルのように扱うには aws s3 sync でローカルにコピーしたり、
FUSEベースの s3fs-fuseなどを使う必要がありましたが、機能の制約などがありました。
S3 Files はこれらを解決し、データを1箇所に置いたまま、
APIとファイルシステムの両方から同時にアクセス可能にします。
この記事ではAWS CLI を使ってファイルシステムを構築し、EC2からマウントして
S3 Filesの動作確認をしてみます。
S3 Files?
S3 FilesはS3バケットをNFSプロトコルでマウント可能にするマネージドサービスです。
AWSエンジニアのAndy Warfield氏は公式記事で、S3がオブジェクトストアとして設計されたために
ディレクトリやアトミックな移動などのファイルシステムの概念を持っていなかったことを指摘しており、
S3 Filesがこの溝を埋めるものだと説明しています。
ではS3 Filesが具体的にどのように溝をうめていくのか見てみましょう。
S3 Filesは単にS3をNFSでwrappしたわけではなく、
ファイルとオブジェクトの性質の違いを考慮したうえで両者をわけた作りになっています。
設計思想:ローカル作業ツリーとリモートを分けて考える
Andy Warfield氏 (S3 Files and the changing face of S3) 曰く、
AWSが過去に「EFS3」というEFSとS3を融合する内部プロジェクトを試みたものの、
以下のような性質の違いによって失敗したとのこと。
- ファイル: mutable / 細粒度更新 / OS連携が重要
- オブジェクト: immutable / 粗粒度更新 / イベント駆動が重要
ファイルとオブジェクトを1つのストレージに統合しようとすると、どちらかに受け入れがたい妥協が生じてしまう。
そこでS3 Filesは統合する道を選ばず、2つのレイヤーを分けました。
- ファイルシステム側 = ローカル作業ツリーのような層: rename / mmap / chmod など POSIX的な細かい操作を自由にできる場所
- S3バケット側 = リモート側の確定スナップショット置き場のような層: ある時点で確定したオブジェクトが並ぶ場所
両者の間は、ファイルシステム側の変更を約60秒ごとにまとめてS3へ反映する Stage and Commitモデルになっています。
Gitで言えば「ローカルで編集した変更が、定期的にまとめてGithubのリモートリポジトリへ反映される」ような感じです。
※明示的にcommit/pushするインターフェースがあるわけではなく、自動的にバックグラウンドで反映されます
この分離のおかげで、ファイルシステム側のPOSIX操作と、
S3バケット側の「確定したスナップショット集合」としての一貫性が両立しています。
Stage and Commit モデルの動作
具体的にはこのレイヤー分離の上で、以下のような動きをします。
- メタデータ同期: S3 → ファイルシステムへは自動でインポートされる(S3バケット側に既にあるオブジェクトはマウント直後から
lsで見える) - ファイルサイズ ≤ 128KB: メタデータと一緒にデータ本体も取得され、高性能キャッシュ層に載る
- 大きいファイル: メタデータのみ取得し、実際に読み出した時点でS3からハイドレーションされる
- Read bypass: 1 MiB 以上の読み取りはキャッシュ層を経由せずS3から並列GETで直接ストリーミング(1台のクライアント=ファイルシステムをマウントしているEC2などのノード1台あたり最大3GB/s)
- ファイルシステム → S3 コミット: 変更は約60秒ごとにまとめられ、1つのPUTとしてS3にコミット
- 整合性モデル: NFS close-to-open 整合性。あるクライアントがファイルを閉じると、他のクライアントが次に open した時点で変更が見える
これらの動作は Andy Warfield 氏の公式ブログで明言されてます。
実装面でも公式ブログは
「S3 Files integrates the Amazon Elastic File System (EFS) into S3」
と明言しており、EFS の技術基盤を直接統合する形になっています。
S3バケットの実データはそのまま維持しつつ、その上に高性能ストレージをかぶせて、
NFSクライアントからの読み書きを高速に処理する仕組みです。
アクセス経路はVPC内に作ったENIへのNFSマウントで、AWS compute(EC2/ECS/EKS/Fargate/Lambda 等)から
ターゲットへ到達する構成が前提です。
別VPCや別Regionからのマウントも公式ドキュメントに手順がありますが、
任意のオンプレ端末から直接マウントする想定の機能ではないので注意。
名前空間衝突と書き込み競合への対応
ファイルとオブジェクトのレイヤーを分ける以上、名前空間の不一致と
両面からの同時書き込みには適切な対処が必要です。
S3 Filesはこれを無理に統合せず、境界を明示する設計を採っています。
-
ファイルシステムビューに自然に表現できないオブジェクトキー
例えば末尾スラッシュを持つfoo/のように、S3ではオブジェクトとして存在できても
ファイルシステム上ではディレクトリと衝突しうるキーは、ファイルシステムビューには表示しません。
無理にファイルとして見せるのではなく、そうした境界が存在することを制約として明示するスタンス。 -
書き込み競合
ファイルシステムとS3バケットの両方から同じファイルを同時に変更したケースを考えます。
この場合、S3をsource of truthとし、ファイルシステム側のバージョンを
.s3files-lost+found-fs-xxxxディレクトリに退避し、CloudWatch メトリクスで競合イベントを通知します。
※後述の検証でも.s3files-lost+found-fs-xxxxディレクトリ自体が自動生成されていた
前者は「見えないものを無理に見せない」、
後者は「競合したものを lost+found と CloudWatch メトリクスで外に出す」
という違いはありますが、どちらも曖昧なケースを勝手に解決せずにユーザーに明示する設計です。
Stage and Commit と同じく、ファイルシステム層とS3オブジェクト層の境界をはっきりさせています。
主な特徴
- NFS v4.1 / v4.2 プロトコル対応
- 低レイテンシアクセスのためにアクティブデータをキャッシュし、複数テラバイト/sレベルの読み取りスループットを提供
- 通信はTLS で暗号化、保存データはAWS KMS keysで暗号化
- プロビジョニング不要の完全従量課金
- S3バケットへの直接変更がファイルシステムビューに反映される
向いているユースケース
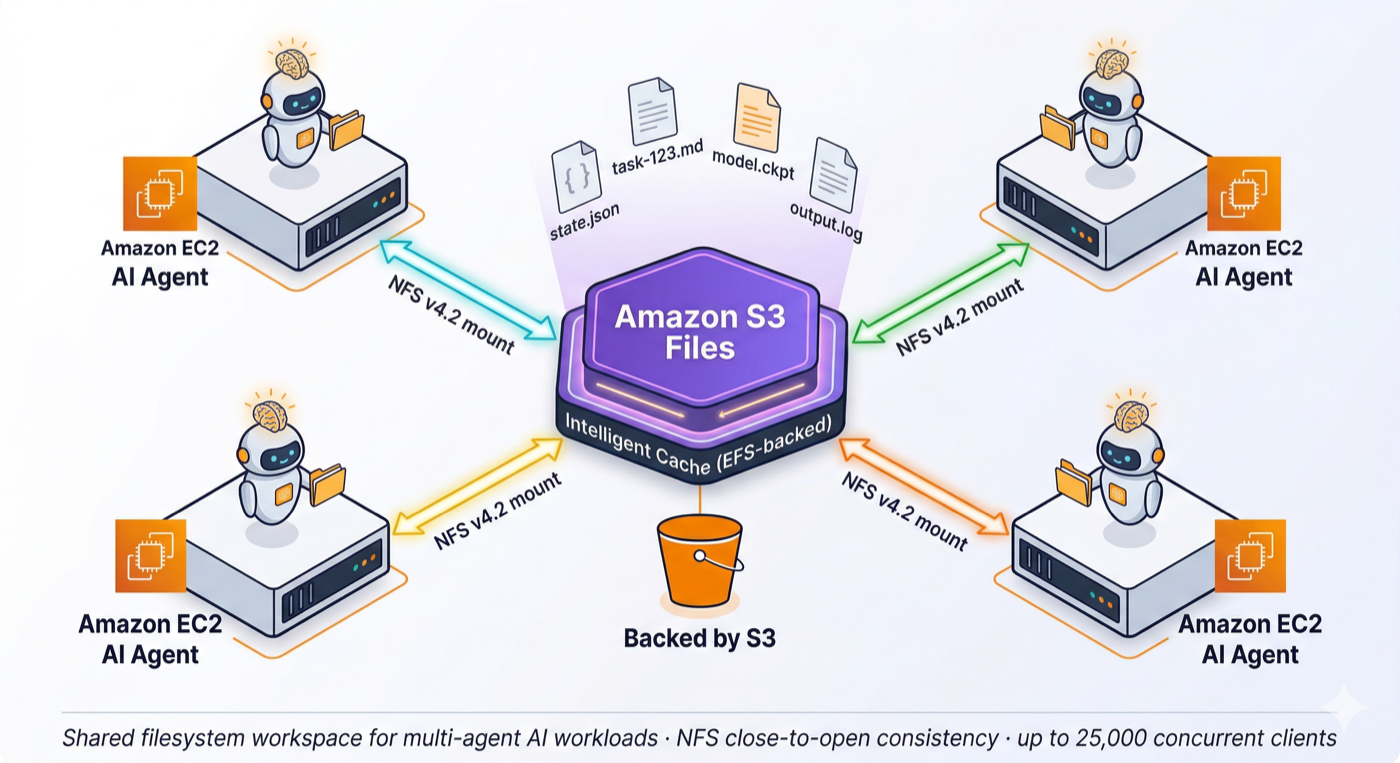
Andy Warfield氏曰く、「KiroやClaude CodeのようなツールがS3データをローカルファイルシステムの一部であるかのように即座に利用できる」
という趣旨を語っており、以下のようなワークロードに向いているとのことです。
- AIエージェントの共有ワークスペース: 複数エージェントが同じディレクトリで状態ファイルや中間成果物を共有する用途。Deloitteの技術者は「エージェンティックアーキテクチャにとって差別化要因」と評価
- 機械学習の訓練・データ準備: S3上のペタバイト規模の訓練データを「コピー&ステージ」なしで直接扱える。PyTorch/TensorFlow がファイルパスでそのまま読める
- レガシーアプリケーションの移行: NFSベースの既存アプリをコード変更なしでS3データレイクに接続
- コンテナワークロード: ECS / EKS / Fargate からボリュームとしてマウント
- ビッグデータ・金融バックテスト・ゲノミクス・VFX レンダーファーム などペタバイト規模の共有アクセス用途
逆に、厳密な同期が必要な用途(分散ロック・トランザクション制御)や、
任意の端末(macOS/オンプレ)から直接マウントする用途には向きません。
Environment
今回の検証環境は以下。
- MacBook Pro (14-inch, M3, 2023)
- OS : macOS 15.7.1 (Darwin 25.4.0)
- AWS CLI :
aws-cli/2.34.26 Python/3.14.3 - amazon-efs-utils : v3.0.0(v2.4.2ではマウント不可。後述)
Try
ではAWS CLIを使って実際にS3 Filesを構築・マウントしてみます。
1. CLI コマンドの確認
S3 Files専用のトップレベルコマンドは aws s3files です。
% aws help | grep -iE "s3files"
+o s3files
% aws s3files help
2. バケット作成&バージョニング有効化
S3 Filesはファイルシステムとバケット間の変更同期にS3 Versioning を必要とするので、
バージョニングは必須。
% BUCKET=s3files-demo-bucket
% aws s3api create-bucket --bucket $BUCKET
% aws s3api put-bucket-versioning --bucket $BUCKET \
--versioning-configuration Status=Enabled
3. IAMロール作成
S3 Files が AssumeRole する IAM ロールが必要です。
service principal名は以下です。
elasticfilesystem.amazonaws.com
S3 Files が EFS 基盤の上に構築されていることが、IAMからわかります。
以下のようにTrust policy (/tmp/trust.json)を作成。
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "AllowS3FilesAssumeRole",
"Effect": "Allow",
"Principal": {"Service": "elasticfilesystem.amazonaws.com"},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {"aws:SourceAccount": "123456789012"},
"ArnLike": {"aws:SourceArn": "arn:aws:s3files:us-east-1:123456789012:file-system/*"}
}
}]
}
インラインポリシー (/tmp/policy.json)は以下。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3BucketPermissions",
"Effect": "Allow",
"Action": ["s3:ListBucket","s3:ListBucketVersions"],
"Resource": "arn:aws:s3:::s3files-demo-bucket"
},
{
"Sid": "S3ObjectPermissions",
"Effect": "Allow",
"Action": ["s3:AbortMultipartUpload","s3:DeleteObject*","s3:GetObject*","s3:List*","s3:PutObject*"],
"Resource": "arn:aws:s3:::s3files-demo-bucket/*"
},
{
"Sid": "EventBridgeManage",
"Effect": "Allow",
"Action": ["events:DeleteRule","events:DisableRule","events:EnableRule","events:PutRule","events:PutTargets","events:RemoveTargets"],
"Condition": {"StringEquals":{"events:ManagedBy":"elasticfilesystem.amazonaws.com"}},
"Resource": ["arn:aws:events:*:*:rule/DO-NOT-DELETE-S3-Files*"]
},
{
"Sid": "EventBridgeRead",
"Effect": "Allow",
"Action": ["events:DescribeRule","events:ListRuleNamesByTarget","events:ListRules","events:ListTargetsByRule"],
"Resource": ["arn:aws:events:*:*:rule/*"]
}
]
}
本検証はSSE-S3前提です。SSE-KMS暗号化バケットの場合は
kms:GenerateDataKey / kms:Encrypt / kms:Decrypt / kms:ReEncrypt*
を追加する必要があります。
公式の Prerequisites for S3 Files では、
サービスロールに対して DO-NOT-DELETE-S3-Files* というプレフィックスを持つ
EventBridge ルールの作成・削除権限を付与するよう指示しています。
S3 Files はマネージドなEventBridgeルールを裏で運用する設計になっていることが、
IAMポリシーの定義をみることで推測できます。
% aws iam create-role --role-name s3files-demo-role \
--assume-role-policy-document file:///tmp/trust.json
% aws iam put-role-policy --role-name s3files-demo-role \
--policy-name s3access --policy-document file:///tmp/policy.json
4. ファイルシステム作成
--bucket はバケット名ではなくARNを渡します。
% aws s3files create-file-system \
--bucket arn:aws:s3:::s3files-demo-bucket \
--role-arn arn:aws:iam::123456789012:role/s3files-demo-role \
--accept-bucket-warning
{
"fileSystemId": "fs-0abcdef1234567890",
"status": "creating",
"bucket": "arn:aws:s3:::s3files-demo-bucket",
...
}
5. マウントターゲット作成
VPC内にENI(プライベートIPを持つネットワークインターフェース)が作られます。
※EFSと同じネットワークモデル
% aws ec2 create-security-group --group-name s3files-nfs-sg \
--description "S3Files NFS" --vpc-id vpc-xxxxxxxx
% aws ec2 authorize-security-group-ingress --group-id sg-xxxxxxxxxxxxxxxxx \
--protocol tcp --port 2049 --cidr 172.31.0.0/16
% aws s3files create-mount-target \
--file-system-id fs-0abcdef1234567890 \
--subnet-id subnet-xxxxxxxx \
--security-groups sg-xxxxxxxxxxxxxxxxx
{
"mountTargetId": "fsmt-0abcdef1234567890",
"ipv4Address": "172.31.x.x",
"networkInterfaceId": "eni-0abcdef1234567890",
"status": "creating"
}
available になるまで待ちます。
6. EC2側の準備:amazon-efs-utils v3.0.0 が必須
私が検証した時点ではAmazon Linux 2023 のデフォルトdnfリポジトリにはamazon-efs-utilsしか無く、
これは mount -t s3files タイプに未対応です。
% sudo dnf install -y amazon-efs-utils
% sudo mount -t s3files fs-xxx:/ /mnt/s3files
mount: /mnt/s3files: unknown filesystem type 's3files'.
v3.0.0 以降をソースビルドします。
あまり低いスペックのインスタンスだとビルドに時間がかかるので注意。
(検証ではc7i.xlarge使いました)
% sudo dnf install -y git rpm-build make rust cargo openssl-devel \
cmake gcc gcc-c++ perl python3-devel golang
% cd /tmp && git clone --depth 1 --branch v3.0.0 https://github.com/aws/efs-utils.git
% cd efs-utils && sudo make rpm
% sudo dnf install -y build/amazon-efs-utils*rpm
% rpm -q amazon-efs-utils
amazon-efs-utils-3.0.0-1.amzn2023.x86_64
ビルド依存の cmake と golang は必須(aws-lc-fips-sys が要求)。
7. EC2 インスタンスプロファイルに S3 Files クライアント権限を付与
素のNFS直叩きは access denied by server で弾かれます。
mount -t s3files ヘルパーは実行時にインスタンスメタデータからIAM資格情報を取得して
マウント時にIAM認証を行うので、EC2ロールにS3 Files クライアント権限と
リンク元バケットの読み取り権限の両方が必要です。
# 1. S3 Files クライアント権限(ファイルシステム操作用)
% aws iam attach-role-policy --role-name <EC2-role> \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FilesClientFullAccess
さらに、S3から直接読み取る最適化経路のためにバケット読み取り用インラインポリシーも付与します:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ObjectReadAccess",
"Effect": "Allow",
"Action": ["s3:GetObject","s3:GetObjectVersion"],
"Resource": "arn:aws:s3:::s3files-demo-bucket/*"
},
{
"Sid": "S3BucketListAccess",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::s3files-demo-bucket"
}
]
}
% aws iam put-role-policy --role-name <EC2-role> \
--policy-name bucket-read --policy-document file:///tmp/client-inline.json
8. マウント
% sudo mkdir -p /mnt/s3files
% sudo mount -t s3files fs-0abcdef1234567890:/ /mnt/s3files
% mount | grep s3files
127.0.0.1:/ on /mnt/s3files type nfs4 (rw,relatime,vers=4.2,rsize=1048576,
wsize=1048576,hard,noresvport,proto=tcp,port=20966,sec=sys,
clientaddr=127.0.0.1,addr=127.0.0.1)
% df -h /mnt/s3files
Filesystem Size Used Avail Use% Mounted on
127.0.0.1:/ 8.0E 0 8.0E 0% /mnt/s3files
マウント元が 127.0.0.1:20966(ローカルプロキシ経由)です。
efs-utils が起動時にefs-proxy(公式ドキュメントに記載のmount helperプロキシ)をローカルに立て、
カーネルNFSクライアントはそこへ接続します。
プロトコルはNFS v4.2(公式は v4.1 と v4.2 の両方をサポートと記述)でした。
9. ファイル操作
% echo "hello from S3 Files" | sudo tee /mnt/s3files/hello.txt
hello from S3 Files
% sudo cat /mnt/s3files/hello.txt
hello from S3 Files
# rename動作OK
% sudo mv /mnt/s3files/hello.txt /mnt/s3files/renamed.txt
% sudo ls -la /mnt/s3files/
-rw-r--r--. 1 root root 20 Apr 8 02:08 renamed.txt
POSIX操作(write / read / rename / stat / chmod)は今回の検証ですべて動作しました。
10. S3 API からの可視化
書いたファイルが S3 オブジェクトとしても見えるか確認。
% aws s3 ls s3://s3files-demo-bucket/ --recursive
2026-04-08 02:10:03 0 /
2026-04-08 02:10:03 20 renamed.txt
2026-04-08 02:08:44 11 sync-probe.txt
同じデータに NFS からも S3 API からもアクセスできます。
Various tests
1. ファイルシステム → S3 API 同期レイテンシ
書き込み直後に s3api head-object でポーリングして、何秒でS3から見えるようになるかを計測。
% T=$(date +%s); F=probe-$T.txt
% echo $T | sudo tee /mnt/s3files/$F >/dev/null
% while true; do
if aws s3api head-object --bucket s3files-demo-bucket --key $F >/dev/null 2>&1; then
echo "visible after $(($(date +%s)-T))s"; break
fi
sleep 5
done
visible after 66s
結果: 66秒。
公式にある「約60秒ごとに1つのPUTとしてコミットされる」という設計値とほぼ一致。
2. マルチEC2 ノード間同期レイテンシ(同AZ / 2台)
2台目のEC2(同AZ)を起動し、1台目でビルドした v3.0.0 RPM を scp 経由でコピーしてマウント。
2台目からマウントした瞬間、1台目が既に作っていたファイルが全部見えました。
次はWriter が書き、Reader が別ノードでその変更を検知するまでの時間を測ります。
(最初は「同一ファイルを上書きして変化を観測」する方式で試しましたが、NFSのattribute cacheに阻まれて変化が全く観測できず)
以下のように、Writer は書き込み時刻(ナノ秒)をファイル名にした新しいファイルを次々に作り、
Reader は同じディレクトリをポーリングして新規ファイルを見つけた瞬間の時刻との差を記録する方式で計測しました。
# Writer側
% for i in $(seq 1 30); do
T=$(date +%s%N)
echo $T | sudo tee /mnt/s3files/sync-test/$T.txt > /dev/null
sleep 0.5
done
# Reader側
% seen=""
% end=$(($(date +%s)+40))
% while [ $(date +%s) -lt $end ]; do
for f in $(sudo ls /mnt/s3files/sync-test/ 2>/dev/null); do
if ! echo "$seen" | grep -q "$f"; then
now=$(date +%s%N)
ts=${f%.txt}
echo $((now-ts))
seen="$seen $f"
fi
done
done > /tmp/lat.log
結果 (n=30):
| Metric | Value |
|---|---|
| min | 104.2 ms |
| p50 | 186.7 ms |
| p95 | 280.9 ms |
| max | 302.8 ms |
| avg | 180.8 ms |
検証結果は以下。
- 同AZ内で平均181ms、p95 281ms
- 公式の「~1ms」は 「キャッシュ済みデータの単一ノード読み取り」の数値であり、ノード間の書き込み伝搬とは別
- 数百msで伝搬するので、例えばAIエージェント間の状態共有・メッセージングとしては実用的
3. 100MBファイルのスループット
100MBのファイルをWriterで書いて、別ノードのReaderで読み取りました。
# Writer
% sudo dd if=/dev/urandom of=/mnt/s3files/big100m.bin bs=1M count=100
104857600 bytes (105 MB, 100 MiB) copied, 0.498257 s, 210 MB/s
# Reader (cold)
% sudo sync; sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
% sudo dd if=/mnt/s3files/big100m.bin of=/dev/null bs=1M
104857600 bytes (105 MB, 100 MiB) copied, 0.908849 s, 115 MB/s
# Reader (warm, ページキャッシュヒット)
% sudo dd if=/mnt/s3files/big100m.bin of=/dev/null bs=1M
104857600 bytes (105 MB, 100 MiB) copied, 0.0186386 s, 5.6 GB/s
| 操作 | サイズ | 時間 | スループット |
|---|---|---|---|
| write (node A) | 100 MB | 0.50s | 210 MB/s |
| read cold (node B) | 100 MB | 0.91s | 115 MB/s |
| read warm (node B, ページキャッシュ) | 100 MB | 0.019s | 5.6 GB/s |
- 書き込み 210 MB/s は単一ストリームとして高速(S3 Files側キャッシュ層がバッファリング)
- Writerが書いた直後に別ノードから115MB/sで読めた = バックエンドが高速に伝搬(S3本体へのコミットを待たずに高性能キャッシュ層経由)
- warm read は Linux ページキャッシュ = メモリ帯域。同一ノードで繰り返し読む訓練ループではレイテンシほぼゼロ
結果サマリ
- S3バケットがNFS v4.2でマウントでき、オブジェクトAPIとの同時アクセスを確認
- S3 Files = EFSの上物: IAM service principal が
elasticfilesystem.amazonaws.com、mount targetが VPC ENI、amazon-efs-utils がマウントヘルパー。ネットワーク/認証モデルはEFSそのもの - ノード間書き込み伝搬は同AZで平均181ms / p95 281ms。公式の「~1ms」は単一ノード・キャッシュヒット読み取りの数字。
- FS→S3 同期は実測66秒(サイズや数が違えばまた変わるかも)
- 同時マウントも確認: 複数EC2から同じファイルシステムをマウントし、書き込み共有確認
注意点
- バージョニング必須
- amazon-efs-utils v3.0.0+ 必須。AL2023のデフォルトリポジトリ(2.4.2)では不可。
- クライアントEC2に
AmazonS3FilesClientFullAccessIAM権限を付与。素のNFS直叩きはエラーとなる - AWS compute からマウントターゲットへ到達する構成が前提(別VPC/別Regionからのマウントは公式手順あり、オンプレ端末からの直接マウントは想定外)
Summary
Amazon S3 Filesを AWS CLI から構築してマウントし、一通り検証しました。
冒頭の「向いているユースケース」の通り、AIエージェントの共有ワークスペースやML訓練データの準備、
レガシーNFSアプリの移行などといった用途に適していそうです。
S3 Files は「S3をバックエンドに持つ実用的なNFS」というイメージです。
S3のデータをコピーせずにファイルパスで扱えるため、AIエージェントの共有ワークスペースや、
既存のNFS前提アプリをS3へつなぐ用途として使えそうです。
一方、S3とファイルシステムが完全に1つになるわけではないです。
FSからS3の反映には約1分の遅延があり、ノード間の変更伝搬もサブミリ秒ではなく数百ms単位でした。
同一ファイルを複数ノードで細かく書き換えるような設計には向かず、
S3 Filesの整合性モデルに合わせた使い方が必要です。
そのあたりを理解して使うのであれば、プロビジョニング不要&マネージドで、
S3上のデータにNFSインターフェースを足せるのは魅力的です。
「S3にあるデータを、アプリケーション側では普通のファイルとして扱いたい」という場面では
候補にあがる機能ではないかと思います。










