
S3イベント検知でLambdaからDynamoDBにデータ格納してみた
初めに
こんにちは。コンサルティング部の津谷です。
皆さんはDynamoDBへのデータ登録をイベント駆動でシームレスに行った経験はありますでしょうか。DynamoDBはAWSが提供するスケーラブルなNoSQLデータベースです。データを格納するテーブルをパーテーションという仕切りで区切ることでデータの読み書きを高速にするスキーマレスなデータべースです。データ特性を厳格に管理する場合や、複雑なSQLクエリで抽出が必要な場合はRDSを使えばよいですが、とにかくスケーラブルで大量のデータ(メタデータなど)を扱え、高速に読み書きできるDynamoDBを使ってみたいので今回検証してみました。パーテーションキーとソートキーだけの検索ではなく今回は作成時のみ設定有効なLSIも活用してDynamoDBの機能を触ってみたいと思います。
DynamoDBの公式情報はこちらをご参照ください。
今回はあらかじめ用意しておいたサンプルデータをS3に格納してイベント通知でLambdaに送り、
DynamoDBが担保するデータ型に加工してテーブル登録してみたいと思います。
構成図
構成図は以下のようになります。
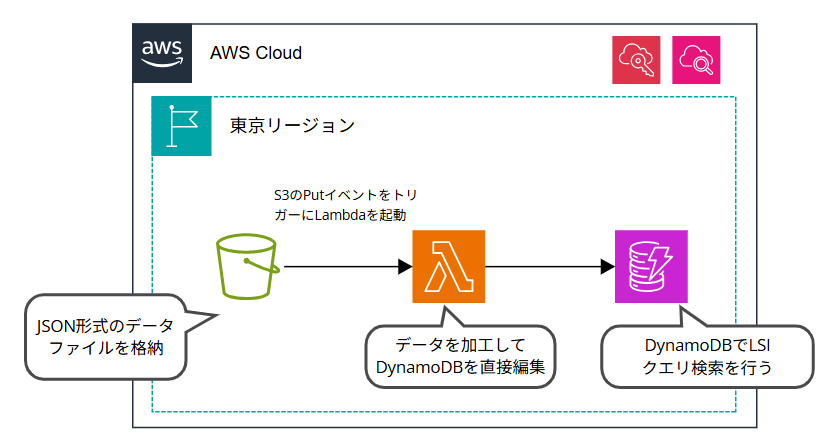
あらかじめ用意しておいたサンプルデータをJSON形式で保存し、S3に格納します。
S3へのPUTイベントをトリガーにLambdaを起動し、データを加工したうえでDynamoDBに登録します。
Lambdaの実行ログはCloudWatchログに出力します。
構築するリソースは下記です。
- S3
サンプルデータを格納するストレージとして格納します。 - Lambda
S3へのPUTイベントをトリガーに起動し、データをDynamoDBに格納できるよう加工します。 - DynamoDB
サンプルデータをテーブルに格納します。 - CloudWatch
Lambdaの実行処理プロセスを出力します。データが正常にテーブルに登録されたかを確認します。 - IAM
Lambdaを実行するための権限を付与します。AWS管理のマネージドポリシーをロールに付与し利用します。使用するポリシーは下記です。
AmazonDynamoDBFullAccess
AmazonS3FullAccess
CloudWatchLogsFullAccess
構築手順
事前準備としてIAMロールは先に作成しておきましょう。
⓪データサンプルの用意
下記のデータをJSON形式で保存しておきます。key-valueの辞書型データをリスト形式にしています。データは、今回は「hogehoge株式会社の従業員データ」という設定にしました。
[
{
"department": "engineering",
"employee_id": "EMPID001",
"first_name": "書映",
"last_name": "田中",
"age": 74,
"generation": "70s",
"position": "シニアエンジニア",
"hire_date": "2020-04-01",
"email": "tanaka.kakuei@company.com"
},
{
"department": "engineering",
"employee_id": "EMPID002",
"first_name": "直子",
"last_name": "菅",
"age": 32,
"generation": "30s",
"position": "テックリード",
"hire_date": "2018-07-15",
"email": "kan.naoko@company.com"
},
{
"department": "engineering",
"employee_id": "EMPID003",
"first_name": "なのだ",
"last_name": "野田",
"age": 25,
"generation": "20s",
"position": "ジュニアエンジニア",
"hire_date": "2022-04-01",
"email": "noda.nanoda@company.com"
},
{
"department": "sales",
"employee_id": "EMPID004",
"first_name": "構文",
"last_name": "小泉",
"age": 29,
"generation": "20s",
"position": "営業マネージャー",
"hire_date": "2019-10-01",
"email": "koizumi.kobun@company.com"
},
{
"department": "sales",
"employee_id": "EMPID005",
"first_name": "茂雄",
"last_name": "石場",
"age": 35,
"generation": "30s",
"position": "シニア営業",
"hire_date": "2017-03-15",
"email": "ishiba.shigeo@company.com"
},
{
"department": "marketing",
"employee_id": "EMPID006",
"first_name": "ぷみお",
"last_name": "岸田",
"age": 27,
"generation": "20s",
"position": "マーケティングスペシャリスト",
"hire_date": "2021-06-01",
"email": "kishida.pumio@company.com"
},
{
"department": "marketing",
"employee_id": "EMPID007",
"first_name": "大子",
"last_name": "武下",
"age": 41,
"generation": "40s",
"position": "マーケティングディレクター",
"hire_date": "2015-01-20",
"email": "takeshita.daigo@company.com"
},
{
"department": "hr",
"employee_id": "EMPID008",
"first_name": "ゆきお",
"last_name": "鳩",
"age": 38,
"generation": "30s",
"position": "人事マネージャー",
"hire_date": "2016-09-01",
"email": "hato.yukio@company.com"
}
]
①S3を作成していきます。
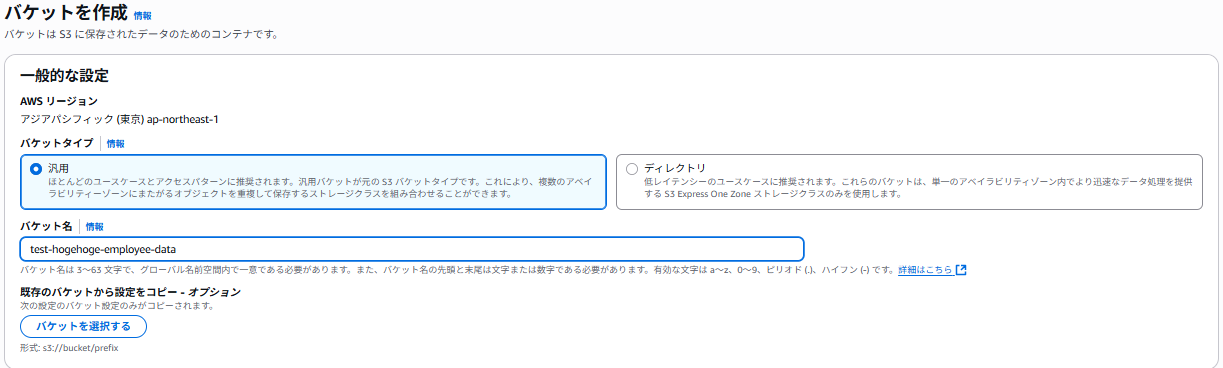
バケット名は「test-hogehoge-employee-data」にします。
そのほかの設定はデフォルトのまま作成します。
パブリックアクセスは無効で、データ暗号化キーもAWS管理のSSE-S3を利用します。
②DynamoDBを作成します。
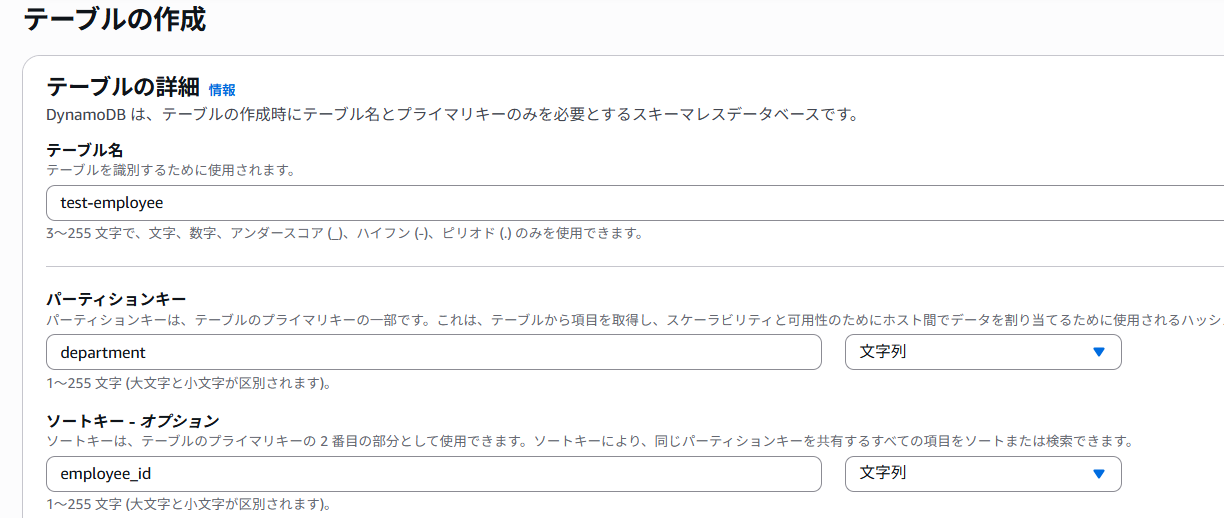
テーブル名は「test-employee」とし、プライマリーキー(パーテーションキー)は「department」を指定します。ソートキーは「employee-id」を指定します。データ型はともに文字列型で問題ありません。
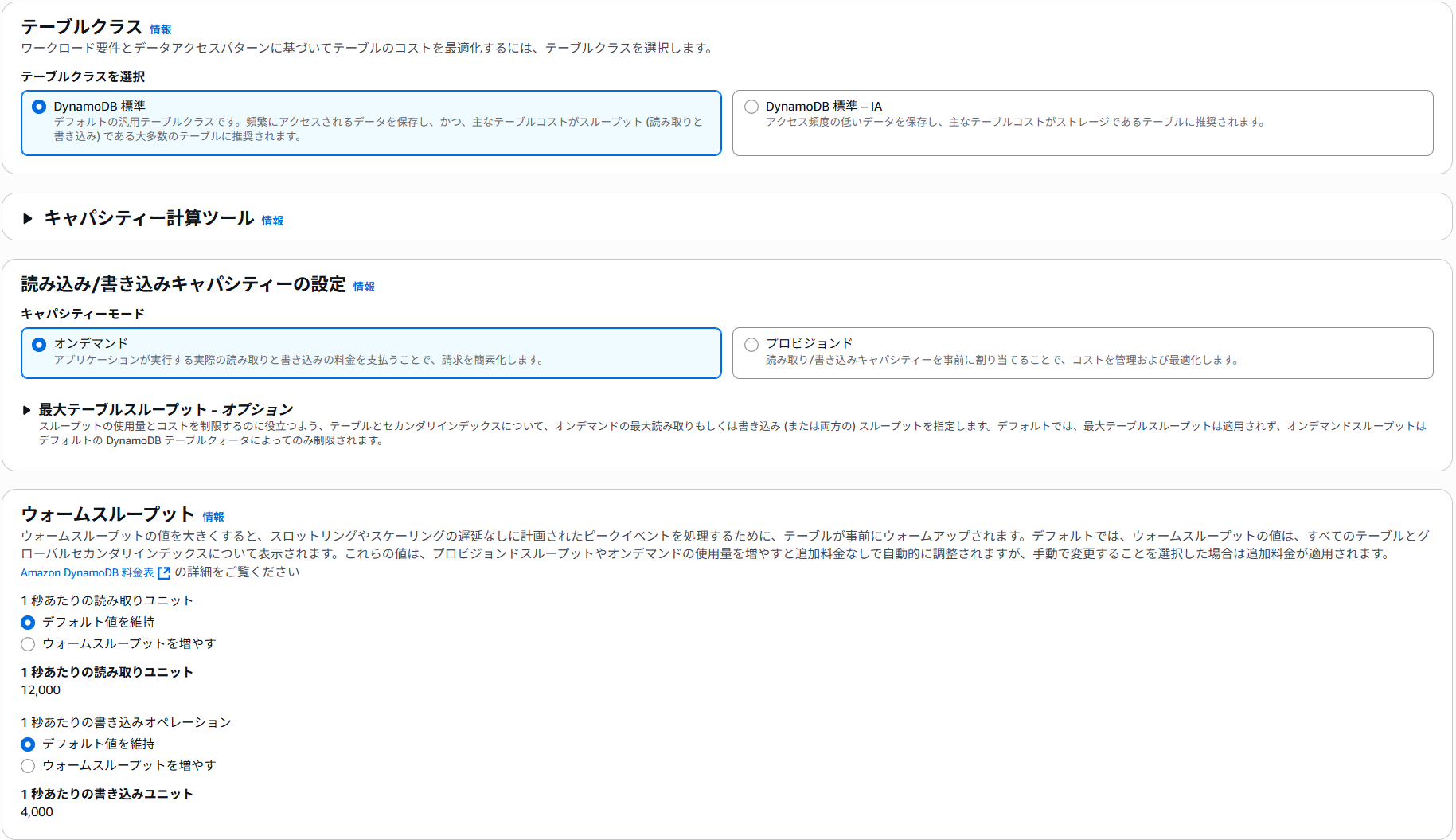
テーブルクラスは標準のものを利用します。また、データの読み書きですが、1ファイルのデータしか取り込まないのでオンデマンドで問題ないです。読み書きのスループットが決まっている場合は、プロビジョンモードを選択してRCU,WCUを直接指定することでコスト管理が可能です。今回はデフォルト設定で行きます。
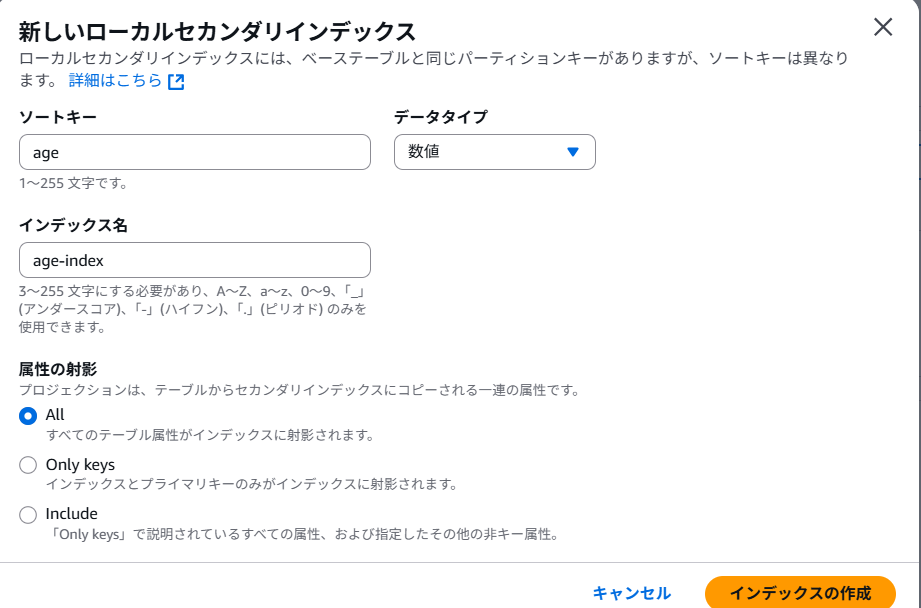
今回はクエリを試してみたいので、LSI(ローカルセカンダリインデックス)を利用します。LSIはテーブル作成時にしか設定することができないので注意しましょう。LSIを設定することで検索時に、ソートキーを別途設定する(パーテーションキーは同じ)ことで特定の属性値のみをヒットさせ、データを効率的に取得することが可能になります。
ソートキーは「age」を指定してインデックスを作成しましょう。
【補足】
テーブル作成後の場合はGSI(グローバルセカンダリインデックス)を追加することができ、テーブル作成時に設定したパーテーションキー・ソートキーに加えて追加で新しいパーテーションキー・ソートキーを設定することが可能です。異なるパーテーションを検索できるので、GSIの方が便利に見えますが整合性の観点だと、更新は非同期なので強い整合性読み取り・書き込みを行う場合は利用できません。
そのほかの設定はデフォルトで作成します。
③データ加工・テーブル編集用のLambdaを作成します。
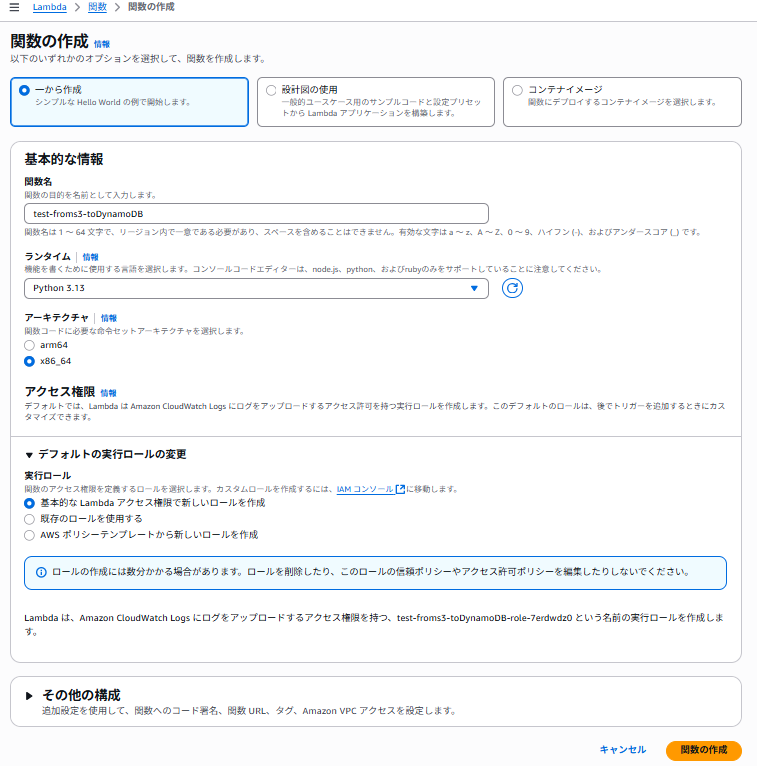
まずは関数の作成を行います。
コードはPythonで書くのでランタイムは「Python3.13」を指定し、関数名は「test-froms3-toDynamoDB」を指定します。ロールは事前に作成しておいたものを利用するので、「既存のロール」を選択します。
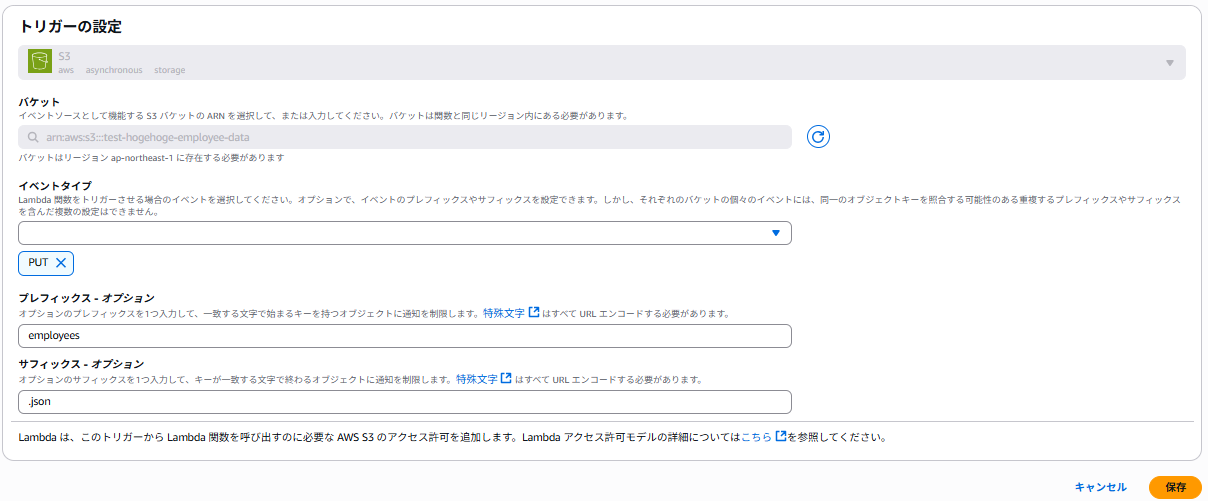
作成後、今度はトリガーの設定を行います。Lambdaのコンソールページからトリガーは「S3」を指定します。
バケットは①で作成した「test-hogehoge-employee-data」を指定します。
イベントタイプはJSONファイルを格納したときなので「PUT」を指定します。
オブジェクトを絞ることも可能です。プレフィックスにはJSONのファイル名である「employees」を指定し、サフィックス(拡張子)は「.json」を指定します。
トリガー設定ができたことは確認できましたね。
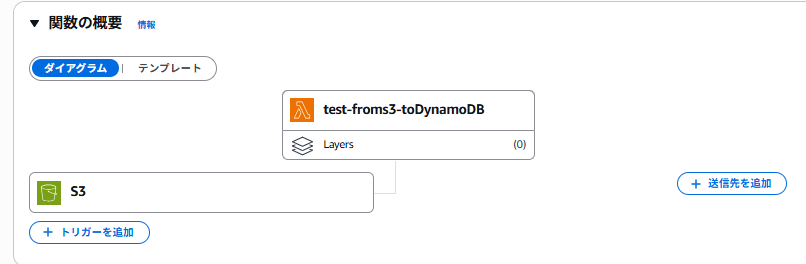
送信先についての補足ですが、DynamoDBのテーブル編集は、Lambdaのコード内で直接しますので、設定不要です。(そもそも「DynamoDB」は送信先としてサポートされていないので、こうするしかないという消極的な理由なのですが、、、)
次に実行するコードを記載します。
import json # JSONデータをPython内で処理する
import boto3 # AWSAPIにアクセスする
from decimal import Decimal # floatなどの不正確なデータ型をDecimalデータ型に変換してDynamoDBに受け渡す
import urllib.parse # URLエンコードされた文字を読み取るため(S3イベント通知ではURLエンコードされたJSONファイル名で来る
import logging # ログを出力する
logger = logging.getLogger() # 取得するログレベルを指定する。
logger.setLevel(logging.INFO) # 今回はINFOレベル(正常処理のログも出力する)
def decimal_converter(obj): # objは変換したいデータを指している→戻り値は数値がDecimal型に変換されたデータ
if isinstance(obj, dict): # objが指定した型かどうか判定する
return {key: decimal_converter(value) for key, value in obj.items()} # obj.item()でkey-valueのデータの組み合わせを取り出す(for構文で再帰的にデータを取り出す)
elif isinstance(obj, list): # リスト型[]
return [decimal_converter(item) for item in obj]
elif isinstance(obj, (int, float)): # 整数型、浮動小数型
return Decimal(str(obj)) # 文字列型に変換する
else:
return obj # それ以外のデータ型はそのまま返す
def lambda_handler(event, context): # eventの部分は今回のS3イベントを指す(JSONファイルを入れた際の挙動)
s3 = boto3.client('s3') # S3への接続クライアントを作成する。
dynamodb = boto3.resource('dynamodb') # DynamoDBへの接続リソースを作成する。
table = dynamodb.Table('employees') # "employeeテーブルに対して操作を行う。
try:
record = event['Records'][0] # 最初のS3ファイルが格納されたとき
bucket = record['s3']['bucket']['name'] # S3のバケット名を取得する
key = urllib.parse.unquote_plus(record['s3']['object']['key']) # エンコードされたファイル名をデコードして取得する
logger.info(f"Processing file: {key} from bucket: {bucket}") # どのバケットのどのオブジェクトの処理かログ出力する
# S3からファイル読み込み
response = s3.get_object(Bucket=bucket, Key=key) # S3バケットからどのファイルを取得するか指定する
content = response['Body'].read().decode('utf-8') # utf-8形式でファイルの中身を読み込む
employees = json.loads(content) # 中身のJSONファイルをPython形式のリストに変換する
# データが配列かどうかチェック
if not isinstance(employees, list):
raise ValueError(f"Expected array, got {type(employees)}") # リスト形式に変換されていない場合はエラーを出力する
# 各社員データを1件ずつDynamoDBに書き込み
success_count = 0
for i, employee in enumerate(employees): # enumerateメソッドでリストの項目と一緒に番号も付与する(0から)
try:
# 数値をDecimalに変換
employee_converted = decimal_converter(employee) # 上で定義したdecimal_converter関数を呼び出してリストデータの従業員情報のデータ型を変換する
# DynamoDBに1件ずつ書き込み
table.put_item(Item=employee_converted) # 変換後のデータをテーブルに書き込む
success_count += 1 # 書き込みが成功するごとにカウントを1追加する。
logger.info(f"Inserted employee {i+1}: {employee.get('first_name', 'Unknown')} {employee.get('last_name', '')}") # 追加された人の氏名をログ出力する。
except Exception as e:
logger.error(f"Failed to insert employee {i+1}: {str(e)}")
# エラーが発生しても次のデータの処理を続行
continue
logger.info(f"Processing completed: {success_count}/{len(employees)} employees inserted")
return {
'statusCode': 200,
'body': f'Success: {success_count}/{len(employees)} employees processed'
}
except Exception as e:
logger.error(f'Error: {str(e)}')
return {
'statusCode': 500,
'body': f'Error: {str(e)}'
}
上記のコードを関数に貼り付け、デプロイします。
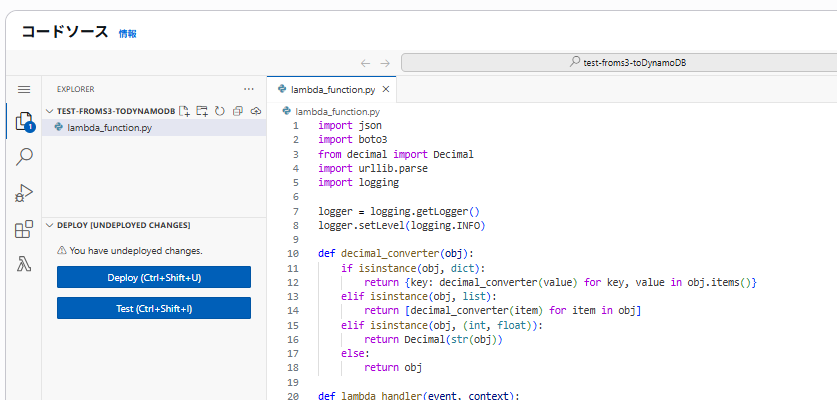
動作確認
DynamoDBテーブルにデータが正常に格納されるか確認していきましょう。
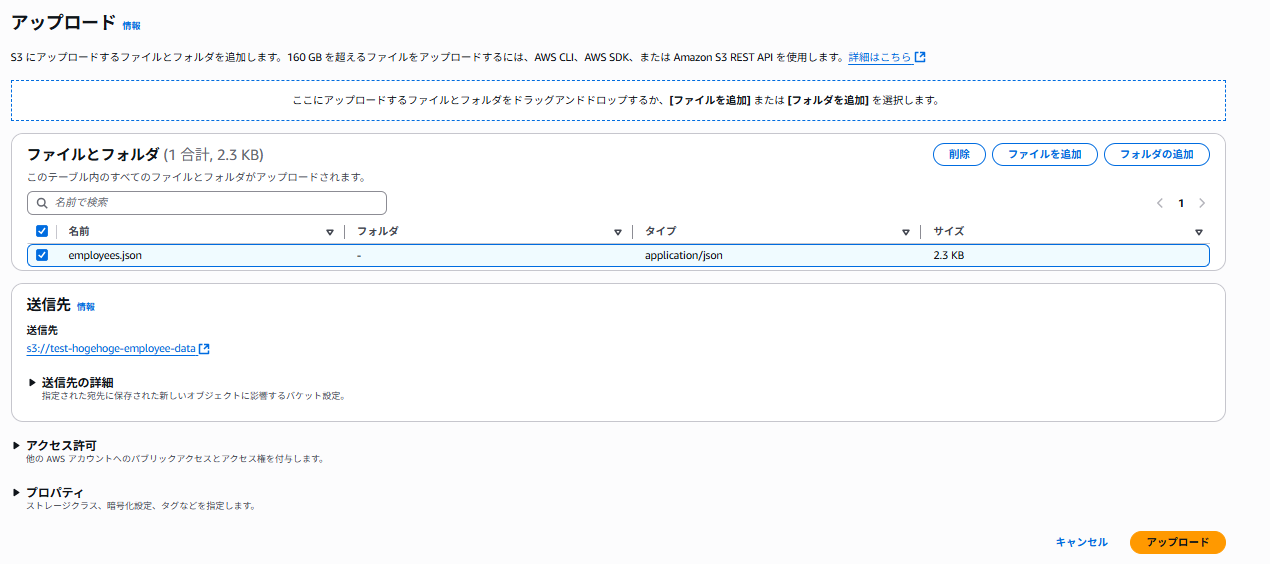
①S3にJSONデータを格納します。
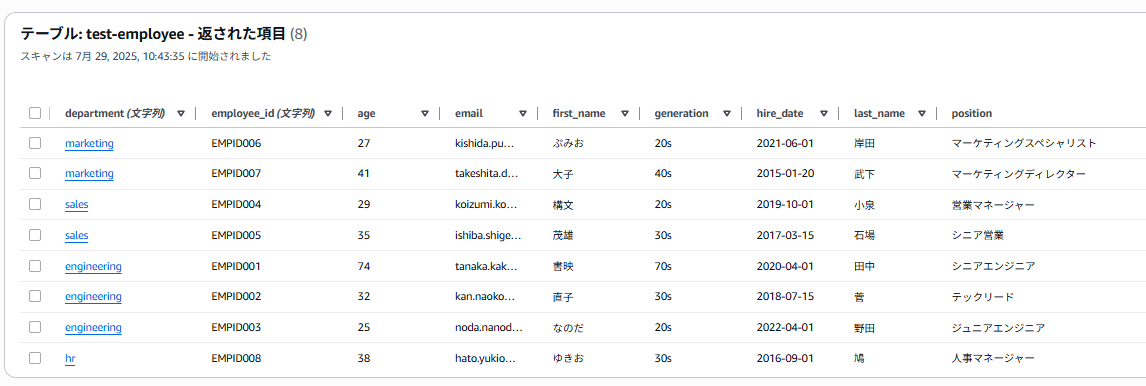
②Lambdaがイベントで起動しているはずなのでDynamoDBにデータが保存されているか確認しましょう。
データ8件の反映まで、約15秒くらいでした。
③CloudWatchでLambdaの実行ログも確認しようと思います。
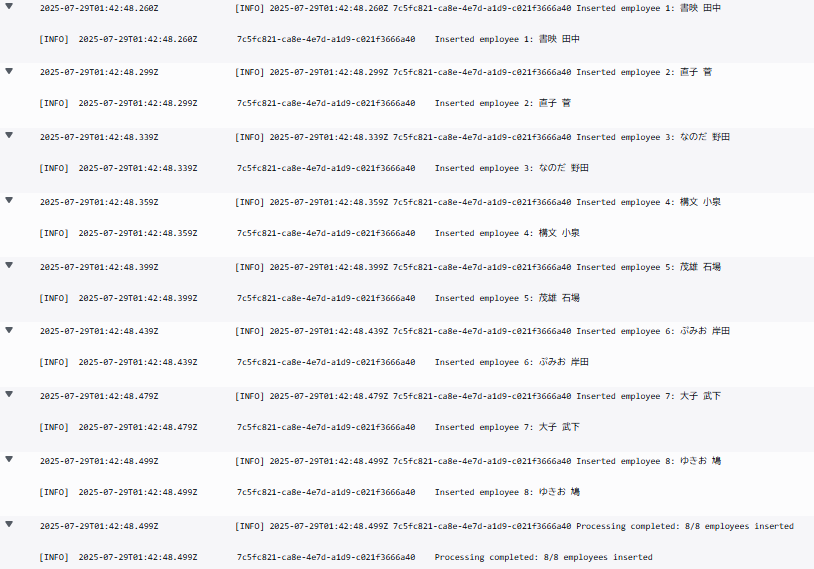
しっかり、登録処理が正常に済んでいますね。
【おまけ】
せっかくLSIを設定したので、クエリでも遊んでみようと思います。
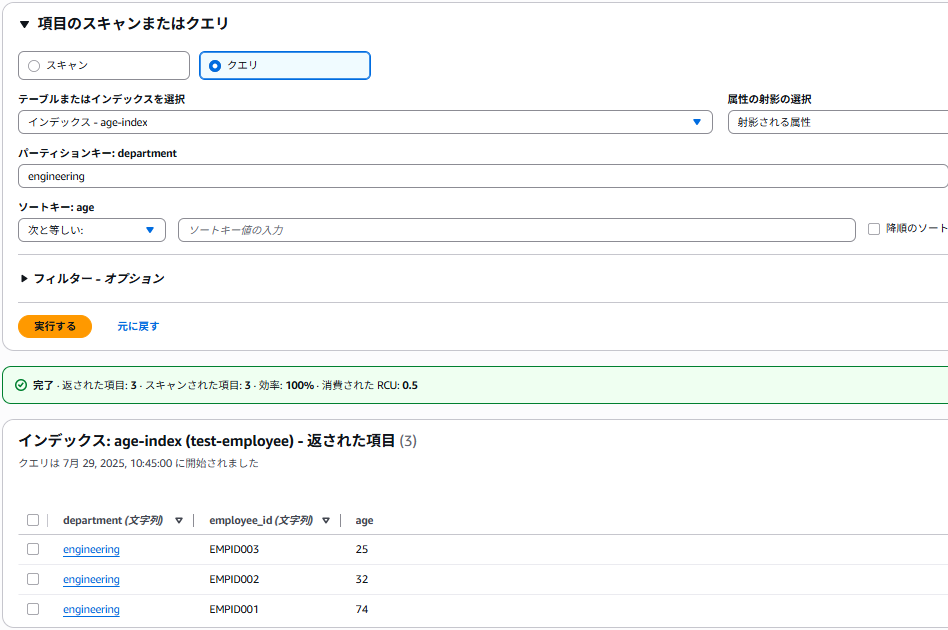
先ほど作成した「age-index」でスキャンを行います。「射影される属性」を選択すると、パーテーションキー+ソートキーに設定した属性値と、追加で設定したage属性値を含むデータのみが出力されていることを確認できました。
最後に
記事をお読みいただきありがとうございました。
RDSとの使い分けや機能を勉強する過程で、検証してみたのですがやはりDynamoDB特有のキーバリュー型のテーブルは最初とっつきにくい印象を自分も持っていました。パーテーションって何?とか、複合キーでクエリ検索?GSI,RSI?とか資格試験等で何となく知識をインプットしていても、やはり自分で一回検証してみる方が何倍も理解度が深まりますね。









