
Next.jsと生成AIでスコーンづくりの技能伝承システムはじめてみました
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
こちらは「クラスメソッド発 製造業 Advent Calendar 2025」の21日目の記事です。
製造業の現場に関わる人たちにとって、「技能伝承」は避けられないテーマです。
ベテランの方が持っている判断の勘どころや、トラブル時のいつもの対応は、データや手順書だけじゃ残らない。それが現場のリアルです。
この記事では、そうした暗黙知を「現場の作業を邪魔せず、自然な形で残す」という視点で、音声入力と対話型AIを使った気軽にはじめられる技能伝承のPoCを紹介します。
この記事を書いたきっかけ
少し前ではありますが、AWS Summit Japan 2024で展示された「生成AIで技能伝承!プロセス製造業デモ」を見て、「これは、おもしろそう!」と思いました。
製造業向けのデモでしたが、ベテラン技術者のKKD(経験・勘・度胸)をAIで引き出し、形式知として次世代へ繋げるコンセプトに強く共感しました。「この仕組みは、業界を問わず技能伝承の普遍的な課題に応用できるはず」と考え、身近な題材で技能伝承システムを作ってみることにしました。
技能伝承が直面する構造的な課題
日本の製造業やサービス業において、「技能伝承」は長年の課題になっています。少子高齢化による労働力不足、ベテラン社員の大量退職により、長年のノウハウが失われつつあります。
製造業の調査によると、事業所の約6割が「指導する人材が不足している」と回答しています。特に問題なのは、ベテランの「暗黙知」—言語化されないカンやコツ—をいかに次世代に伝えるか。
「見て覚える」という従来の指導法では、熟練者が持つ判断基準やポイントが十分に伝わりません。また、多忙な現場では手順書を作成する時間も限られています。結果として、特定のベテラン社員だけが知識を持つ「属人化」が進み、その人がいないと現場が回らない...という状況に陥りがちです。
現場では「分からないことが分からない」状態が技能伝承をより一層困難にしている要因の1つだとも感じます。
生成AIが切り拓く解決へのアプローチ
こうした課題に対して、最近注目を集めているのが生成AIの活用です。要点整理や手順化もこなせるため、ナレッジ管理との相性がいい。
生成AIを「現場で使う前提」で捉え直すと、「音声で集め、対話で引き出し、構造化して蓄積する」という流れが見えてきます。ベテランが口頭で話すだけでAIがテキスト化し、インタビュー形式で暗黙知を引き出し、それを分類・整理して検索可能な形で保存する。この3ステップで「聞き出す/残す/探す」を実現します。
この記事では、こうした生成AIを活用した技能伝承システムのサンプルアプリケーションを、Next.jsを使って作ってみました。題材は、伝統的なスコーン店のベテラン職人から若手への技能伝承。
今回作るもの
今回作るアプリは次のような機能を持っています。
- 音声インタビュー機能 - マイクで話すだけでAIがテキストに変換
- AIチャット機能 - 対話形式でベテランの知識を引き出す
- ナレッジ抽出 - 会話から自動でナレッジを構造化
- ナレッジ管理 - 抽出したナレッジをカテゴリ別に保存・閲覧
- ナレッジQ&A - 蓄積されたナレッジに基づいてAIが質問に回答
実装にはNext.js 16、Vercel AI SDK v5、shadcn/uiを使用し、OpenAIのAPIと連携します。
※ 本記事で紹介するのは、あくまでPoC(検証用の試作)です。技術詳細よりも「どう組み合わせるか」の考え方を中心に紹介します。
※ 動作にはOpenAIのAPIキーが必要となります。
※ 本記事のソースコードは GitHub で公開しています。
技能伝承とAIの可能性
AIインタビュアーの仕組み
生成AIをうまく使うと、技能伝承の進め方を「聞き出す/残す/探す」に分けて設計しやすくなります。
音声入力による知識収集
キーボード操作が苦手なベテランでも、話すだけでノウハウを記録できます。作業中の「独り言」も、そのままナレッジとして残せます。
ベテラン: 「このバターは冷たいまま使うんだ。室温に戻すとダメ」
↓ Whisper APIでテキスト化
↓ GPTで構造化
ナレッジ: {
category: "materials",
topic: "バターの温度管理",
content: "バターは冷蔵庫から出したての冷たい状態で使用する",
tips: ["室温に戻すと生地がベタつく", "サクサク感が出なくなる"]
}
対話形式での知識抽出
AIインタビュアーが「なぜ」「どのように」「どのくらい」を意識した質問を投げかけることで、ベテラン自身も気づいていなかった暗黙知を言語化しやすくなります。
24時間対応の相談役
蓄積したナレッジをもとに、新人がいつでも質問できる相談窓口を用意できます。「忙しそうな先輩に何度も聞きづらい」「同じことを聞いて怒られそう」といった心理的なハードルを下げる用途にも向いています。
スコーン店を題材にした理由
この記事では、製造業ではなくスコーン店を題材に選びました。理由は次の通りです。
- 身近で理解しやすい - 多くの人が経験したことのある「料理」という文脈で、技術継承のイメージが湧きやすい
- 明確なカテゴリ分け - 材料、技法、温度管理、トラブル対応といった分類が直感的
- 具体的なナレッジが豊富 - バターの温度、生地の折り方、焼き時間など、具体的な数値やコツが多い
- 最近スコーンにハマっている:) - サムネイル画像はお気に入りのスコーンです
もちろん、同様のアプローチは製造業の設備メンテナンス、品質管理、トラブル対応など、あらゆる分野に応用できます。
製造業への適用例
- 設備の異音判断、調整のコツ
- 品質検査での目視判定基準
- トラブル発生時の初動対応
- 季節や環境変化に応じた製造条件の調整
スコーン作りで学んだ実装パターンは、そのまま製造現場の技術継承システムに転用できます。
設備や製品が違うだけで、「技術が人に宿る」という構造は変わりません。
現場環境における音声UIの優位性
特に製造現場において、今回採用した「音声インターフェース」は相性がいいです。
- ハンズフリーでの記録 - 油で汚れた手や、安全手袋を着用した状態でも、作業の手を止めずに記録可能。
- 安全性への配慮 - 画面やキーボードを注視する必要がないため、視線を作業対象から外すことなく、安全に情報を入力可能。
- 多言語対応 - WhisperなどのAIモデルは多言語対応や翻訳機能に優れており、外国人労働者が母国語で話した内容を、日本語のナレッジとして蓄積するといった活用も現実的。
物理的な制約が多い現場だからこそ、音声入力が便利な場面は多いはずです。
音声APIの選択肢
OpenAI Whisper API
Whisper APIは、音声ファイルをテキストに変換する(Speech-to-Text)APIです。
特徴
- 録音した音声ファイルを送信し、テキストを受け取る「非リアルタイム」方式
- 多言語対応(日本語も高精度)
- 比較的シンプルなAPI設計
- コスト: $0.006/分(2025年12月現在)
実装の流れ
1. ブラウザでMediaRecorder APIを使って音声を録音
2. 録音完了後、音声BlobをFormDataに詰めてサーバーに送信
3. サーバーでWhisper APIを呼び出し
4. 変換されたテキストをクライアントに返却
実装がシンプルでコストも読みやすいのが強み。ただし録音が終わるまで変換が始まらないため、長い音声だと待ち時間が発生します。
OpenAI Realtime API
Realtime APIは、WebRTCまたはWebSocketベースのリアルタイム双方向の音声対話を実現するAPIです。
特徴
- リアルタイムでの音声入出力が可能
- 話しながら応答を受け取れる
- 低遅延(100ms級)
- 従量課金制(音声入出力のトークン数に応じて課金)
実装の流れ
1. WebRTC/WebSocketでOpenAIサーバーに接続
2. 音声ストリームをリアルタイムで送信
3. AIからの音声応答をリアルタイムで受信
4. 必要に応じてテキストも取得
話し終わるのを待たずにAIが応答を始めるため、自然な対話体験が得られます。音声での応答も可能。ただし、WebRTC/WebSocketの知識が必要で実装は複雑になります。コストも従量課金のため予測しにくい点に注意が必要です。
今回の選択
今回はWhisper APIを採用しました。理由は次の通りです。
- 学習コストの低さ - 初めてAI音声機能を実装する方でも理解しやすい
- デバッグのしやすさ - 非リアルタイムなので、各ステップの確認が容易
- コスト予測 - 従量課金の計算がシンプル
- 十分な実用性 - インタビューのユースケースでは、リアルタイム性よりも精度が重要
Realtime APIは「発展的な話題」のセクションで紹介しています。本番環境でより自然な対話体験を求める場合には、そちらの採用を検討してみてください。
技術スタックの選定
Next.js 16 (App Router)
フレームワークにはNext.js 16を採用しました。
App Routerの構造
app/
├── page.tsx # / (ダッシュボード)
├── interview/
│ └── page.tsx # /interview (インタビュー画面)
├── knowledge/
│ ├── page.tsx # /knowledge (一覧)
│ └── [id]/
│ └── page.tsx # /knowledge/[id] (詳細)
└── api/
├── chat/
│ └── route.ts # POST /api/chat
├── transcribe/
│ └── route.ts # POST /api/transcribe
├── extract/
│ └── route.ts # POST /api/extract
├── ask/
│ └── route.ts # POST /api/ask (ナレッジQ&A)
└── knowledge/
├── route.ts # GET/POST /api/knowledge
└── [id]/
└── route.ts # GET/DELETE /api/knowledge/[id]
Vercel AI SDK v5
AIとの連携にはVercel AI SDK v5を使用しています。
選定理由
- ストリーミング対応 - AIの応答をリアルタイムで表示
- useChat Hook - Reactでのチャット実装を簡素化
- 複数プロバイダー対応 - OpenAI、Anthropic、Google AIなど
- 型安全 - TypeScriptとの統合が優れている
shadcn/ui
UIコンポーネントにはshadcn/uiを採用しました。
コンポーネントのソースコードを直接プロジェクトに配置するため、カスタマイズしやすくアクセシビリティも考慮されています。
データ保存(JSONファイル)
今回のPoCではシンプルさを重視して、JSONファイルでデータを永続化しています。
選定理由
- データベースのセットアップが不要
- コードの可読性が高い
- 開発・デモ環境での動作確認が容易
本番環境への移行
本番環境では、次のような選択肢があります。
- PostgreSQL / MySQL などのRDB
- MongoDB などのドキュメントDB
- 類似検索が必要な場合はベクトルDB(後述)
アプリケーション設計
機能要件
今回のアプリケーションは以下の機能を提供します。
| 機能ID | 機能名 | 概要 |
|---|---|---|
| F-01 | 音声録音 | ブラウザで音声を録音 |
| F-02 | 音声テキスト変換 | Whisper APIでテキスト化 |
| F-03 | AIインタビュー | チャット形式で対話的に知識を引き出す |
| F-04 | インタビューモード選択 | フリートーク/ガイド付きの2モードから選択 |
| F-05 | ナレッジ抽出 | 会話からナレッジを構造化 |
| F-06 | ナレッジ保存 | JSONファイルへの永続化 |
| F-07 | ナレッジ一覧 | カテゴリフィルタ付き一覧表示 |
| F-08 | ナレッジ詳細 | 抽出されたナレッジの詳細表示 |
| F-09 | ナレッジQ&A | 蓄積ナレッジに基づくAI質問応答 |
画面構成
| 画面 | パス | 概要 |
|---|---|---|
| ダッシュボード | / |
概要とナビゲーション |
| インタビュー | /interview |
音声/テキストでAIと対話 |
| ナレッジ一覧 | /knowledge |
保存済みナレッジの一覧(タブ切替でQ&A) |
| ナレッジ詳細 | /knowledge/[id] |
個別ナレッジの詳細 |
データモデル
ナレッジ
type KnowledgeCategory =
| 'materials' // 材料に関する知識
| 'technique' // 技法・手順
| 'temperature' // 温度・時間管理
| 'troubleshooting'; // トラブル対応
interface Knowledge {
id: string;
createdAt: string;
category: KnowledgeCategory;
topic: string; // タイトル
content: string; // 本文
tips: string[]; // コツ・ポイント
source: 'interview' | 'manual';
}
システムアーキテクチャ
実装詳細
それでは実際にコードを見ていきましょう。
プロジェクトのセットアップ
# プロジェクト作成
pnpm create next-app@latest scone-knowledge-transfer --yes
# 依存関係のインストール
cd scone-knowledge-transfer
pnpm add ai @ai-sdk/openai @ai-sdk/react openai lucide-react
# shadcn/uiの初期化
pnpm dlx shadcn@latest init --defaults
# 必要なコンポーネントの追加
pnpm dlx shadcn@latest add button card input textarea badge tabs scroll-area separator
型定義
lib/types.tsにアプリケーション全体で使用する型を定義します。詳細は「アプリケーション設計」セクションの「データモデル」を参照してください。
AIプロンプトの設計
lib/prompts.tsにAIへの指示を定義します。プロンプトは出力のブレを減らす鍵なので、ここでは「役割」「出力形式」「ルール」を明示します。
// インタビュアーのシステムプロンプト
export const INTERVIEWER_SYSTEM_PROMPT = `あなたは伝統的なスコーン店のベテラン職人から技術やノウハウを引き出すインタビュアーです。
【あなたの役割】
- 職人の経験や知識を丁寧に聞き出す
- 具体的な数値や手順、コツを引き出す質問をする
- 暗黙知を言語化する手助けをする
- 相手の話を尊重し、深掘りする
【質問のポイント】
1. 材料の選び方や配合のコツ
2. 生地の扱い方、こね方、成形のポイント
3. オーブンの温度や焼き時間の見極め方
4. 失敗しやすいポイントとその対処法
5. 季節や湿度による調整方法
【会話のルール】
- 日本語で丁寧に対話する
- 一度に多くの質問をせず、一つずつ深掘りする
- 相手の回答を要約して確認する
- 「なぜ」「どのように」「どのくらい」を意識した質問をする`;
// ナレッジ抽出用プロンプト
export const KNOWLEDGE_EXTRACTION_PROMPT = `以下のインタビュー会話から、スコーン作りに関する具体的なナレッジを抽出してください。
【抽出するナレッジの形式】
{
"category": "materials" | "technique" | "temperature" | "troubleshooting",
"topic": "ナレッジのタイトル(20文字以内)",
"content": "ナレッジの本文(100-200文字程度)",
"tips": ["コツや注意点1", "コツや注意点2", ...]
}
【注意事項】
- 具体的な数値や手順が含まれているものを優先
- 抽象的な内容は避け、実践可能な知識のみを抽出
- 複数のナレッジがある場合は配列で出力`;
// ナレッジQ&A用プロンプト
export const KNOWLEDGE_QA_SYSTEM_PROMPT = `あなたはスコーン作りのベテラン職人の知識を学習したAIアシスタントです。
提供されたナレッジを元に、ユーザーからの質問に簡潔かつ的確に回答してください。
【回答のルール】
- ナレッジに基づいた回答を心がける
- 具体的な数値や手順がある場合は明示する
- ナレッジにない情報は「その情報についてはナレッジにありません」と回答`;
// ガイド付きモード用の初期質問候補
export const INITIAL_INTERVIEW_QUESTIONS = [
{ id: 'general', label: '全般', question: 'スコーン作りで最も大切にされていることは何でしょうか?' },
{ id: 'materials', label: '材料について', question: '材料の選び方でこだわりはありますか?...' },
{ id: 'technique', label: '技法について', question: '生地の扱い方で気をつけていることは?...' },
// ... 他のカテゴリ
];
ここは出力品質に直結するため、今回は次の3点に絞って設計しています。
- 具体性の追求 - 「なぜ」「どのように」「どのくらい」を聞き出す
- 構造化の指示 - JSONフォーマットで出力させることで、後続処理が容易に
- カテゴリの定義 - 明確な分類基準を提供
音声録音コンポーネント
components/audio-recorder.tsxで音声録音機能を実装していきます。
'use client';
import { useState, useRef, useCallback } from 'react';
import { Mic, Square, Loader2 } from 'lucide-react';
import { Button } from '@/components/ui/button';
interface AudioRecorderProps {
onTranscription: (text: string) => void;
disabled?: boolean;
}
type RecordingState = 'idle' | 'recording' | 'processing';
export function AudioRecorder({ onTranscription, disabled }: AudioRecorderProps) {
const [state, setState] = useState<RecordingState>('idle');
const mediaRecorderRef = useRef<MediaRecorder | null>(null);
const chunksRef = useRef<Blob[]>([]);
const startRecording = useCallback(async () => {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
const mediaRecorder = new MediaRecorder(stream, {
mimeType: 'audio/webm;codecs=opus',
});
mediaRecorderRef.current = mediaRecorder;
chunksRef.current = [];
mediaRecorder.ondataavailable = (event) => {
if (event.data.size > 0) {
chunksRef.current.push(event.data);
}
};
mediaRecorder.onstop = async () => {
setState('processing');
stream.getTracks().forEach(track => track.stop());
const audioBlob = new Blob(chunksRef.current, { type: 'audio/webm' });
const formData = new FormData();
formData.append('audio', audioBlob, 'recording.webm');
const response = await fetch('/api/transcribe', {
method: 'POST',
body: formData,
});
const data = await response.json();
onTranscription(data.text);
setState('idle');
};
mediaRecorder.start();
setState('recording');
}, [onTranscription]);
const stopRecording = useCallback(() => {
if (mediaRecorderRef.current && state === 'recording') {
mediaRecorderRef.current.stop();
}
}, [state]);
return (
<Button
variant={state === 'recording' ? 'destructive' : 'outline'}
size="icon"
onClick={state === 'recording' ? stopRecording : startRecording}
disabled={disabled || state === 'processing'}
>
{state === 'idle' && <Mic className="h-4 w-4" />}
{state === 'recording' && <Square className="h-4 w-4" />}
{state === 'processing' && <Loader2 className="h-4 w-4 animate-spin" />}
</Button>
);
}
コンポーネントの状態はidle(待機)、recording(録音中)、processing(変換中)の3つで管理しています。音声の録音にはブラウザ標準のMediaRecorder APIを使用し、Whisper APIがサポートするaudio/webm;codecs=opus形式で出力します。録音停止時にはgetTracks().forEach(track => track.stop())でマイクストリームを確実に解放しておきます(録音後もマイクを掴みっぱなしにしないため)。
音声変換API
app/api/transcribe/route.tsでWhisper APIを呼び出しています。
import { NextResponse } from 'next/server';
import OpenAI from 'openai';
export const runtime = 'nodejs';
export const maxDuration = 60;
let openai: OpenAI | null = null;
function getOpenAI() {
if (!openai) {
openai = new OpenAI();
}
return openai;
}
export async function POST(req: Request) {
const formData = await req.formData();
const audioFile = formData.get('audio') as File;
if (!audioFile) {
return NextResponse.json(
{ error: '音声ファイルが見つかりません' },
{ status: 400 }
);
}
const transcription = await getOpenAI().audio.transcriptions.create({
file: audioFile,
model: 'whisper-1',
language: 'ja',
response_format: 'verbose_json',
});
return NextResponse.json({
text: transcription.text,
duration: transcription.duration,
language: transcription.language,
});
}
getOpenAI()による遅延初期化でビルド時のエラーを回避しています。音声ファイルはマルチパートフォームデータで受け取り、language: 'ja'で日本語を明示しておくと認識結果が安定しやすいです。verbose_json形式にすると、音声の長さなどの追加情報も取れます。
チャットAPI
app/api/chat/route.tsでAIチャットを実装しています。
import { streamText, convertToModelMessages, type UIMessage } from 'ai';
import { openai } from '@ai-sdk/openai';
import { INTERVIEWER_SYSTEM_PROMPT } from '@/lib/prompts';
export const runtime = 'nodejs';
export const maxDuration = 30;
export async function POST(req: Request) {
const { messages }: { messages: UIMessage[] } = await req.json();
const result = streamText({
model: openai('gpt-4o'),
system: INTERVIEWER_SYSTEM_PROMPT,
messages: await convertToModelMessages(messages),
});
return result.toUIMessageStreamResponse();
}
SDK v5ではUIMessage形式でやり取りし、convertToModelMessagesで変換、toUIMessageStreamResponseでストリーミング返却という流れになります。
チャットインターフェース
components/chat-interface.tsxでチャットUIを実装しています。このアプリの操作の中心になるUIです。
'use client';
import { useRef, useEffect, useState } from 'react';
import { useChat } from '@ai-sdk/react';
import { DefaultChatTransport } from 'ai';
import { Send, Loader2 } from 'lucide-react';
import { Button } from '@/components/ui/button';
import { Textarea } from '@/components/ui/textarea';
import { ScrollArea } from '@/components/ui/scroll-area';
import { AudioRecorder } from './audio-recorder';
export function ChatInterface({ onMessagesChange }) {
const scrollRef = useRef<HTMLDivElement>(null);
const [input, setInput] = useState('');
const { messages, sendMessage, status } = useChat({
transport: new DefaultChatTransport({
api: '/api/chat',
}),
});
const isLoading = status === 'streaming' || status === 'submitted';
// 新しいメッセージが追加されたらスクロール
useEffect(() => {
if (scrollRef.current) {
scrollRef.current.scrollTop = scrollRef.current.scrollHeight;
}
}, [messages]);
const handleSend = async () => {
if (!input.trim() || isLoading) return;
const message = input.trim();
setInput('');
sendMessage({
parts: [{ type: 'text', text: message }],
});
};
const getMessageText = (message) => {
return message.parts
?.filter(part => part.type === 'text')
.map(part => part.text)
.join('') || '';
};
return (
<div className="flex flex-col h-full">
<ScrollArea className="flex-1" ref={scrollRef}>
{messages.map((message) => (
<div
key={message.id}
className={message.role === 'user' ? 'text-right' : 'text-left'}
>
<div className={message.role === 'user' ? 'bg-primary' : 'bg-muted'}>
{getMessageText(message)}
</div>
</div>
))}
</ScrollArea>
<div className="flex gap-2">
<Textarea
value={input}
onChange={(e) => setInput(e.target.value)}
placeholder="メッセージを入力..."
/>
<AudioRecorder onTranscription={setInput} />
<Button onClick={handleSend} disabled={!input.trim() || isLoading}>
<Send className="h-4 w-4" />
</Button>
</div>
</div>
);
}
AI SDK v5ではDefaultChatTransportを使ってAPIエンドポイントを指定します。メッセージの送信はsendMessageにparts配列を渡す形式に変わり、受け取ったメッセージからテキストを取得する際はmessage.partsを参照します。
ナレッジ抽出API
app/api/extract/route.tsで会話からナレッジを抽出しています。
import { NextResponse } from 'next/server';
import { generateText } from 'ai';
import { openai } from '@ai-sdk/openai';
import { KNOWLEDGE_EXTRACTION_PROMPT } from '@/lib/prompts';
export async function POST(req: Request) {
const { messages } = await req.json();
// メッセージを会話形式のテキストに変換
const conversationText = messages
.map((msg) =>
`${msg.role === 'user' ? '職人' : 'インタビュアー'}: ${msg.content}`
)
.join('\n\n');
// ナレッジを抽出
const { text } = await generateText({
model: openai('gpt-4o'),
prompt: KNOWLEDGE_EXTRACTION_PROMPT + conversationText,
});
// JSONをパース
const jsonMatch = text.match(/\{[\s\S]*\}/);
const result = jsonMatch ? JSON.parse(jsonMatch[0]) : { knowledge: [] };
return NextResponse.json({
knowledge: result.knowledge || [],
});
}
会話履歴は「職人」「インタビュアー」のように役割を付けて整形します。こうしておくとAIが文脈を掴みやすくなります。AIの応答からはJSON部分を正規表現で抜き出してパースし、失敗したら空配列を返しています。雑なエラーハンドリングですが、PoCなのでご容赦ください。
ナレッジQ&A API
app/api/ask/route.tsで蓄積されたナレッジに基づくQ&A機能を実装しています。PoCでも効果が見えやすいので、Q&A機能も用意しました。
import { streamText } from 'ai';
import { openai } from '@ai-sdk/openai';
import { KNOWLEDGE_QA_SYSTEM_PROMPT } from '@/lib/prompts';
import { getAllKnowledge } from '@/lib/storage';
export const runtime = 'nodejs';
export const maxDuration = 30;
export async function POST(req: Request) {
const { question } = await req.json();
if (!question) {
return new Response(
JSON.stringify({ error: '質問が必要です' }),
{ status: 400 }
);
}
// 蓄積されたナレッジを取得
const knowledgeList = await getAllKnowledge();
// ナレッジをコンテキストとして整形
const knowledgeContext = knowledgeList
.map((k) => `【${k.topic}】\n${k.content}\nポイント: ${k.tips?.join(', ')}`)
.join('\n\n---\n\n');
const prompt = `
以下のナレッジを参考に、質問に回答してください。
--- ナレッジ ---
${knowledgeContext}
---
質問: ${question}
`;
const result = streamText({
model: openai('gpt-4o'),
system: KNOWLEDGE_QA_SYSTEM_PROMPT,
prompt: prompt,
});
return result.toTextStreamResponse();
}
保存済みの全ナレッジを読み込み、各ナレッジをトピックと内容、ポイントの形式に整形してプロンプトに含めています。streamTextで返しているため、長い回答でも待たずに表示が進みます。
これは簡易的なRAG(Retrieval-Augmented Generation)パターンの実装です。ナレッジ数が増えた場合は、ベクトルDBを使った類似検索へ移行すれば、コンテキストに含めるナレッジを上位N件に絞れます。
ナレッジQ&Aコンポーネント
components/knowledge-qa.tsxでQ&A画面のUIを実装しています。チャットインターフェースと同様のパターンで、useChatフックを使用してストリーミング応答を表示します。実装の詳細はGitHubリポジトリを参照してください。
データ永続化
lib/storage.tsでJSONファイルへの保存を実装しています。シンプルですが、PoCとしては十分な実装です。
import { promises as fs } from 'fs';
import path from 'path';
import type { Knowledge } from './types';
const DATA_DIR = path.join(process.cwd(), 'data');
const KNOWLEDGE_FILE = path.join(DATA_DIR, 'knowledge.json');
// データファイルの初期化
async function ensureDataFile(): Promise<void> {
try {
await fs.access(DATA_DIR);
} catch {
await fs.mkdir(DATA_DIR, { recursive: true });
}
try {
await fs.access(KNOWLEDGE_FILE);
} catch {
await fs.writeFile(KNOWLEDGE_FILE, JSON.stringify({ items: [] }, null, 2));
}
}
// 全ナレッジの取得
export async function getAllKnowledge(): Promise<Knowledge[]> {
await ensureDataFile();
const data = await fs.readFile(KNOWLEDGE_FILE, 'utf-8');
return JSON.parse(data).items;
}
// ナレッジの保存
export async function saveKnowledge(
knowledge: Omit<Knowledge, 'id' | 'createdAt'>
): Promise<Knowledge> {
await ensureDataFile();
const allItems = await getAllKnowledge();
const newKnowledge: Knowledge = {
...knowledge,
id: `KN-${Date.now()}-${Math.random().toString(36).substring(2, 9)}`,
createdAt: new Date().toISOString(),
};
allItems.push(newKnowledge);
await fs.writeFile(
KNOWLEDGE_FILE,
JSON.stringify({ items: allItems }, null, 2)
);
return newKnowledge;
}
動作デモと解説
それでは、実際のアプリケーションの画面を見ていきましょう。
生成AIにデザインとコピーを考えてもらったら何かすごいシステムのようになりました:)
トップページ - 職人の技を未来へ繋ぐシステムの入り口
インタビュー画面
インタビュー画面では、まずモードを選択し、その後チャット画面に遷移します。
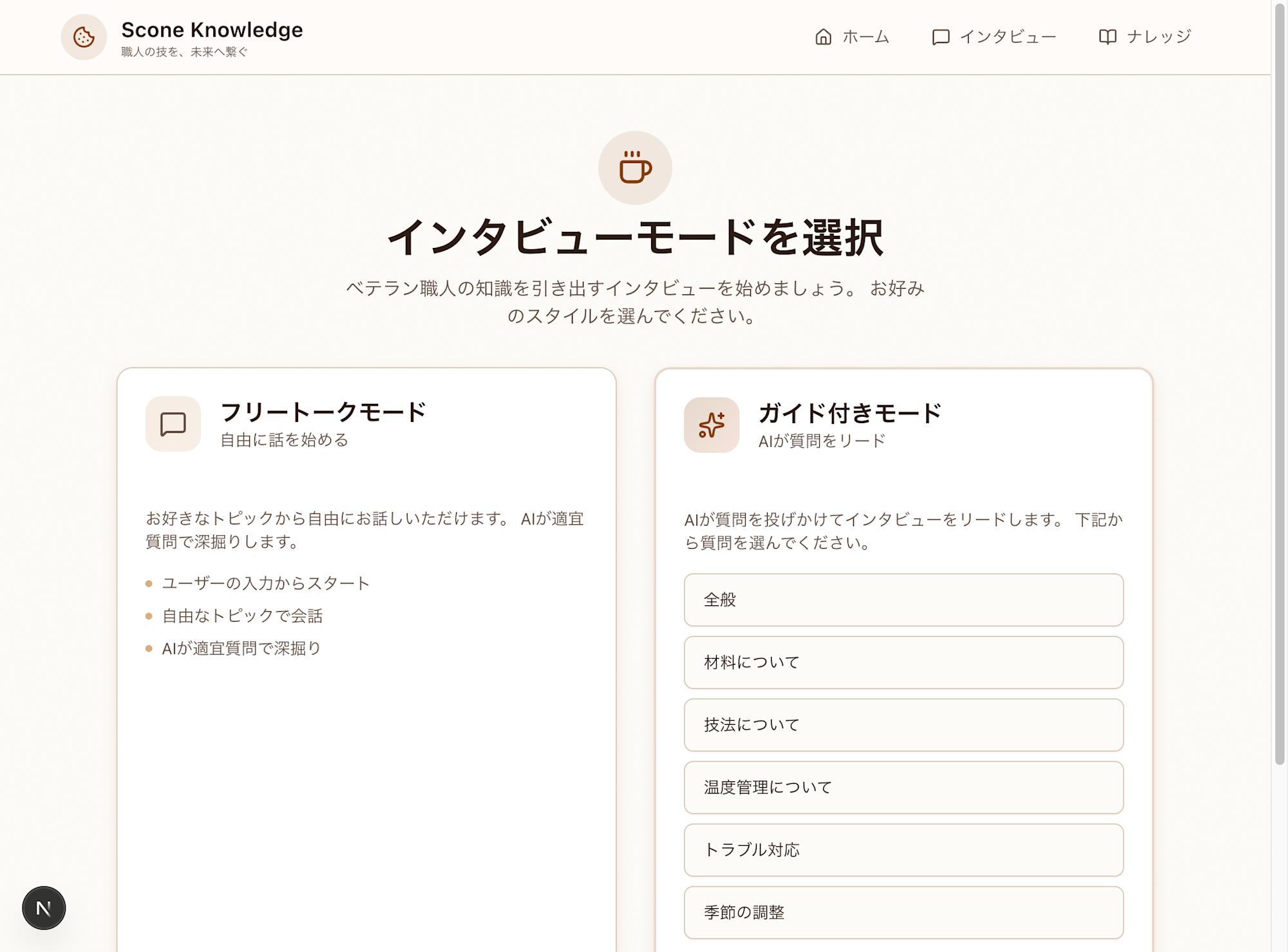
インタビューモード選択 - フリートークとガイド付きモードから選択
モード選択
インタビュー開始時に2つのモードから選択できます。
- フリートークモード - ユーザーが自由に話を始められる。お好きなトピックからスタート
- ガイド付きモード - AIインタビュアーが最初の質問を投げかける。質問カテゴリを選択可能
ガイド付きモードでは、次のような質問カテゴリから選択できます。
- 全般(スコーン作りで最も大切にしていること)
- 材料について(バターや小麦粉の選び方)
- 技法について(生地の扱い方やこね方)
- 温度管理について(焼き加減の見極め方)
- トラブル対応(失敗しやすいポイントと対処法)
- 季節の調整(夏場と冬場での違い)
チャット画面
モード選択後、左右2ペイン構成のチャット画面に遷移します。
- 左ペイン - AIとのチャット領域(戻るボタンでモード選択に戻れる)
- 右ペイン - 抽出されたナレッジ
操作フロー
- モードを選択してインタビューを開始
- テキスト入力または音声入力でメッセージを送信
- AIインタビュアーが質問を返す
- 何往復か会話を続ける
- 「抽出」ボタンをクリック
- 右ペインにナレッジが表示される
- 「保存」ボタンでナレッジを永続化
ナレッジ一覧画面
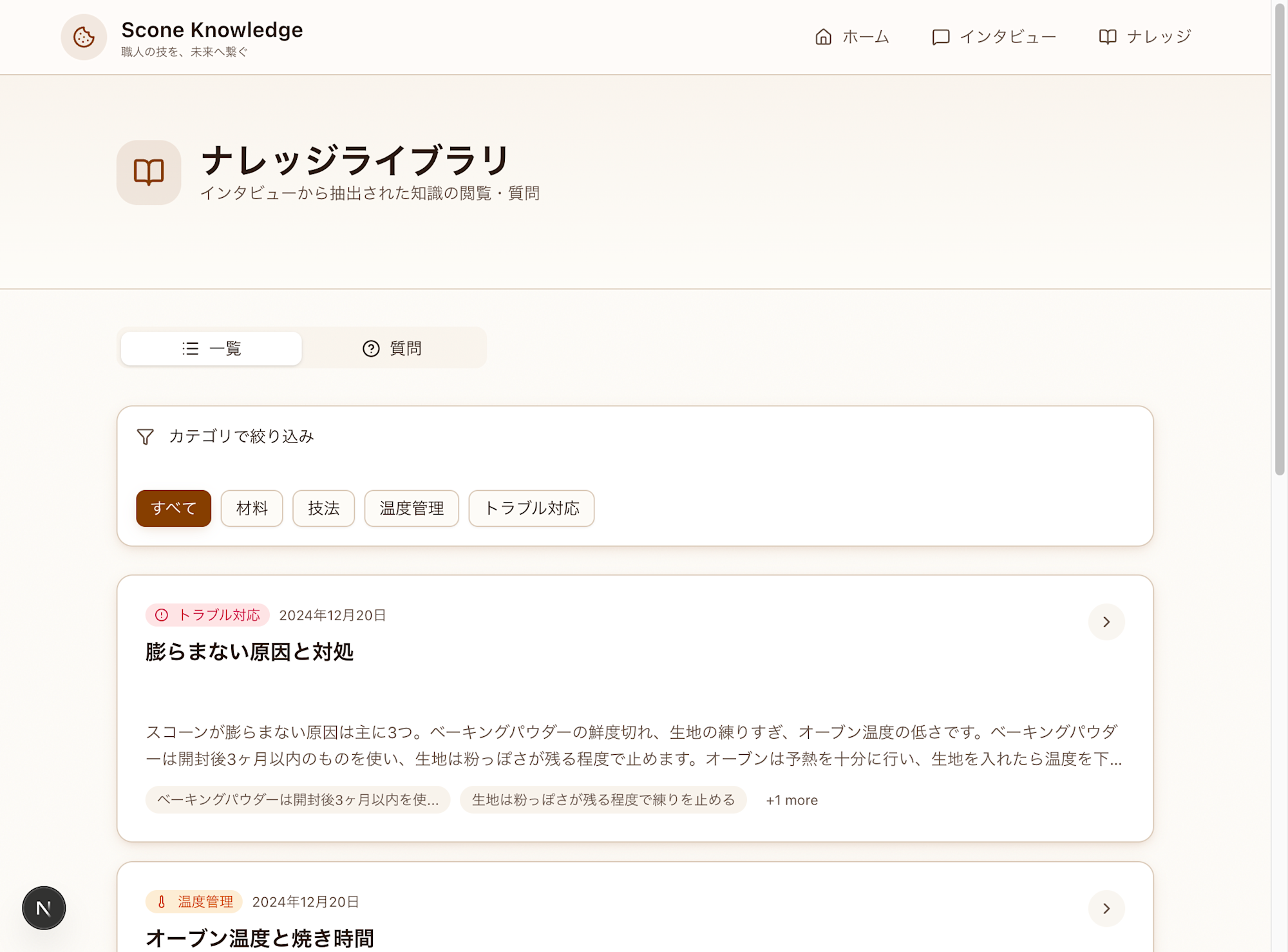
ナレッジライブラリ - カテゴリ別にナレッジを閲覧・検索
タブ切替で「一覧」と「Q&A」を表示できます。
ナレッジ一覧タブ
- カテゴリでフィルタリング(すべて / 材料 / 技法 / 温度管理 / トラブル対応)
- キーワード検索
- カードをクリックすると詳細画面へ
ナレッジQ&Aタブ
- 蓄積されたナレッジに基づいてAIが質問に回答
- 「生地がベタつく原因は」などの質問を入力
- AIがナレッジを参照して的確に回答
ナレッジ詳細画面
個別ナレッジの詳細表示です。
- タイトル、カテゴリ、作成日時
- 本文
- ポイント(箇条書き)
- 削除ボタン
発展的な話題
ベクトルDBとRAGによる高度な検索
今回のPoCではJSONファイルでの単純な保存としましたが、本番環境では「類似するナレッジを検索したい」というニーズが出てきます。ベクトルDBを入れると、たとえば次のようなことがやりやすくなります。
- このトラブルに関連するナレッジを表示したい
- 質問に対して、関連度の高いナレッジのみをコンテキストに含めたい
// ナレッジ保存時にベクトル化
const embedding = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: knowledge.content,
});
// ChromaDBに保存
await chromaCollection.add({
ids: [knowledge.id],
embeddings: [embedding.data[0].embedding],
metadatas: [{ category: knowledge.category }],
documents: [knowledge.content],
});
// 質問時に類似ナレッジを検索してRAGで回答
const relevantKnowledge = await chromaCollection.query({
queryEmbeddings: [questionEmbedding],
nResults: 5,
});
| 項目 | 簡易RAG(本PoC) | 高度なRAG |
|---|---|---|
| ナレッジ取得 | 全件取得 | 類似検索 |
| コンテキスト | 全ナレッジ | 上位N件 |
| スケーラビリティ | 〜100件程度 | 数万件以上 |
| コスト | トークン数が増加 | 最適化可能 |
OpenAI Realtime APIへの移行
より自然な対話体験を求める場合、Realtime APIへの移行も検討できます。
メリット
- 話し終わるのを待たずにAIが応答開始
- 音声での応答も可能(TTS統合)
- 割り込み対応
実装の複雑さ
- WebRTC/WebSocketの知識が必要
- 状態管理が複雑化
- エラーハンドリングの考慮点が増加
まとめ
今回のPoCを通して感じたのは、技能伝承においてAIは「答える存在」である以上に、「問いを投げかける触媒」としての価値が高いという点です。
ベテランの方が日常的に行っている判断は、本人にとっては呼吸をするように当たり前で、意識的に言語化する対象になっていません。AIによるインタビューは、その「当たり前」をすくい上げてくれます。
技能伝承は、システムを導入すれば即座に解決する単純な問題ではありません。しかし、現場の声を残しやすくする「聞き役」として、生成AIは十分に使えそうです。
今後の発展
このPoCをもとに、次のような発展が考えられます。
- ベクトルDBの導入 - 全件取得から類似検索への移行でスケーラビリティ向上
- 高度なRAGの実装 - 関連度の高いナレッジのみを取得し、回答精度とコストを最適化
- Realtime APIへの移行 - より自然な対話体験
技術継承という課題に対して、AIがどのような価値を提供できるか、この記事がその参考になれば嬉しいです。










